概要
本稿では,環境が視覚的定位に及ぼす影響を分析するために特別に設計されたベンチマークデータセットを紹介.幅広い条件で撮影されたクエリ画像に対して慎重に作成されたグラウンドトゥースポーズを使用して,最先端のローカリゼーション手法を使用した広範な実験を通じて,様々な要因が6DOFカメラの姿勢推定精度に及ぼす影響を評価.
本稿では,環境が視覚的定位に及ぼす影響を分析するために特別に設計されたベンチマークデータセットを紹介.幅広い条件で撮影されたクエリ画像に対して慎重に作成されたグラウンドトゥースポーズを使用して,最先端のローカリゼーション手法を使用した広範な実験を通じて,様々な要因が6DOFカメラの姿勢推定精度に及ぼす影響を評価.

・3つのあたらしいベンチマークデータセットを紹介・Active SearchやCSLなどの構造ベースの方法は,都市環境でのほとんどの条件に対して堅牢.しかし,精度の高い領域でのパフォーマンスは,依然として大幅に改善する必要あり. ・昼間の写真から構築されたデータベースに対して,夜間の画像をローカライズすることは,事前の情報が与えられても非常に困難 ・過去の情報が与えられている場合でも,多量の植生がある場面は困難 ・SfMは上2つの問題を完全に処理しないが,提案したデータセットは解決する機能のベンチマークを容易に提供. ・DenseVLADなどは,自律運転状況で粗いレベルのポーズ推定値を提供が可能. ・姿勢推定に複数の画像を使用することは明確な利点がある.
リンク集に記載している“Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers using a Dynamic Vision Sensor(DVS)”を用いてオプティカルフロー推定,デプス推定,ローテーション推定,モーション推定などの問題に取り組んだ論文.本論文ではDVSを用いて,ピクセルごとに急激な変化を起こした点とその軌道を認識する(論文内では“event”と定義). その点軌道の速さや動いた距離からデプスやオプティカルフローなどの,様々な問題におけるアルゴリズムを提案して評価している.
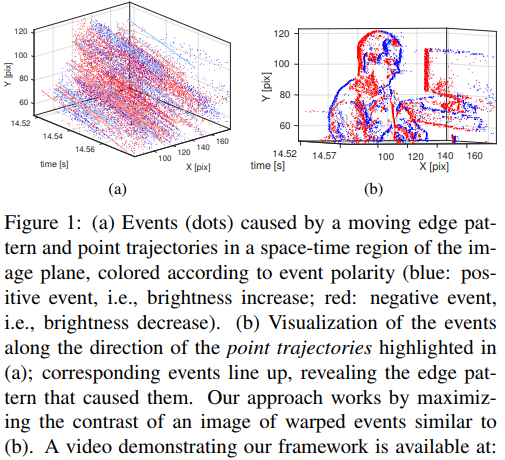
デプス推定において,従来手法であるコントラストからの推定のほうが精度が高いが,1.1~1.8mの距離においては提案手法の方が精度が高いなど,それぞれの問題において提案手法の得意な所を説明し,提案手法のフレームワークの優位性を説明している.
イレギュラー文字の深い特徴を取得するためにarbitrary orientation network(AON)を開発.このネットワークの全体は,画像と単語レベルのみを使用してエンドtoエンドで訓練することができる.様々なベンチマークの実験では,提案されたAONベースの方法が不規則なデータセットでは最先端の性能を達成し,通常のデータセットの主要な既存の方法に匹敵することを示している.
・文字の四角特徴を4方向に抽出するための任意の方向つけネットワークと,文字配置の手がかり・フィルタゲート機構を用いて4方向特徴シーケンス ・文字シーケンスを生成するための注意べ―スのデコーダ の3つを使用 既存研究と異なり,画像からイレギュラー/レギュラーのテキスト両方を効果的に認識できる 通常のベンチマークと不規則なベンチマークの両方を用いた実験では,提案手法の優位性が検証された 将来的には,提案手法を他関連に関するタスクまで拡張する予定
style画像のdeep特徴マップをシャッフルすることにより,任意のstyle transferを行う手法の提案.従来の様々なstyle-transfer手法に対して新しい切り口で分析し,deep feature reshuffleの提案を行なっている.feature domainに於いて逐次的な最適化を行なう.提案手法では,様々な種類の入力画像に対応することができ,質も他手法を超えると主張する.
・neural parametricモデルと neural non-parametricモデルはdeep feature reshuffleというアイデアによって統合される.
・deep feature reshuffleに基づく新しいエネルギー関数を定義.これは,他の手法よりもシンプルで柔軟.
・ピラミッド法で feature-domainエネルギー関数を最適化するために新しく,レベルごとのデコーダを学習する
・textual CNNを使って、画像とセンテンス両方にCNNを適用する
・中間表現を使ってglobal semanticの学習をアシストする
・semantic embeddingがうまくいくことを確認した
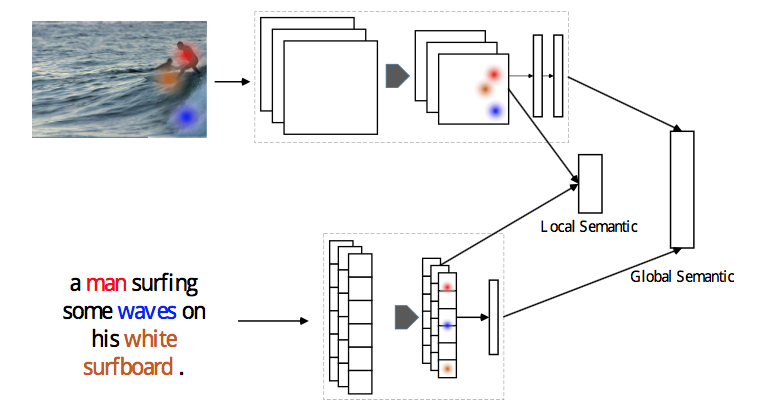
・CNNをvisual and textual semantic embeddingに利用した。このネットワークはend-to-endで学習することができる
・中間の畳み込み特徴と大域的なsemantics特徴を局所的なコンテキスト特徴の学習のために利用する
・Flickr30kとMS-COCOデータセットを使って提案するモデルが効果的であることを実験で示した
ビデオでの領域分割のためのdeep Random Fieldを用いた手法(VideoGCRF)を提案.Deep Gaussian Conditional Random Fields(GCRFs)を利用し,密接に関係する時空間グラフの推論が時間効率・メモリ効率に優れた手法を提案する.
・計算効率,メモリ効率
・固有の大域的最小値を持つ
・end-to-endで学習が可能
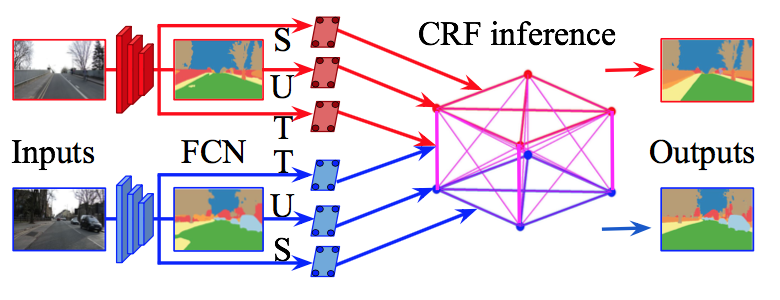
・はじめに,複数枚の入力画像からFCNでピクセルごとのクラスラベルを予測する.同時に空間的な埋め込みベクトルと,時間的な埋め込みベクトルをそれぞれ獲得する
・埋め込みの内積から,時間的な埋め込みと区間的な埋め込みの位置を結合する
・最後に線形システムを解く事で,最終的な予測結果を得る
データ拡張とネットワークの学習を敵対的学習の枠組み取り入れ同時に行う.キーとなるアイデアは,Generator(データ拡張ネットワーク)がDiscriminator(学習対象のネットワーク)にとってのhard exampleをオンラインで生成すること.これによって,GeneratorはDiscriminatorの弱みを探し,よりDiscriminatorの性能を伸ばすことができるようになる.
同時学習を効率的に行うための報酬や罰則のストラテジーも提案する.
この論文では,pose estimationのタスクに適用し,state-of-the-artを超えるデータ拡張ができたことを確認した.
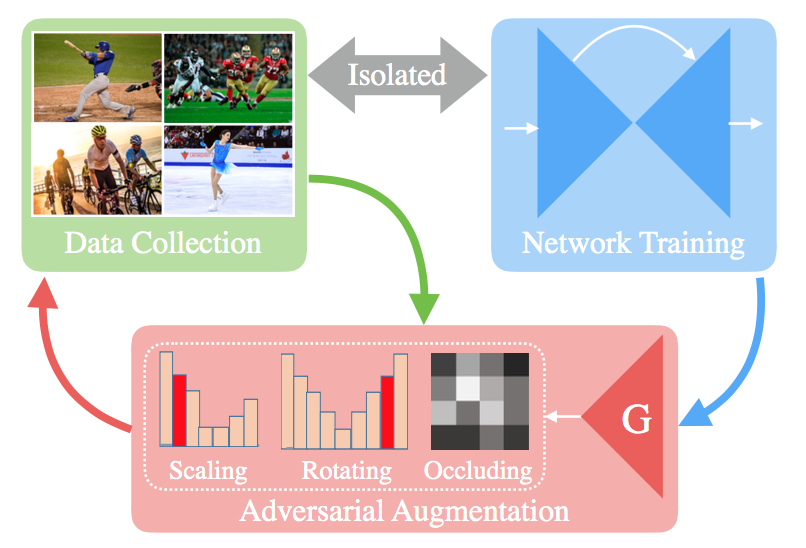
・データ拡張とネットワークの学習は通常切り離されているのに対して,この論文ではこの二つを同時に行うことが新しい.
・敵対的にデータ拡張を行うことが,オンラインでやられていること
・同時学習用の報酬や罰則のストラテジーの提案
・pose-estimationタスクでいいスコア
動的なテクスチャー生成のために two-streemのモデルを導入した.生成される結果は3〜5秒程度の動画で,結果例はプロジェクトサイトに詳しく載っているので参考にされたい. 定量評価として,200人によるUserStudyを行なっている.59組の生成結果と正解動画を見せ,どちらがリアルかの回答を得た.
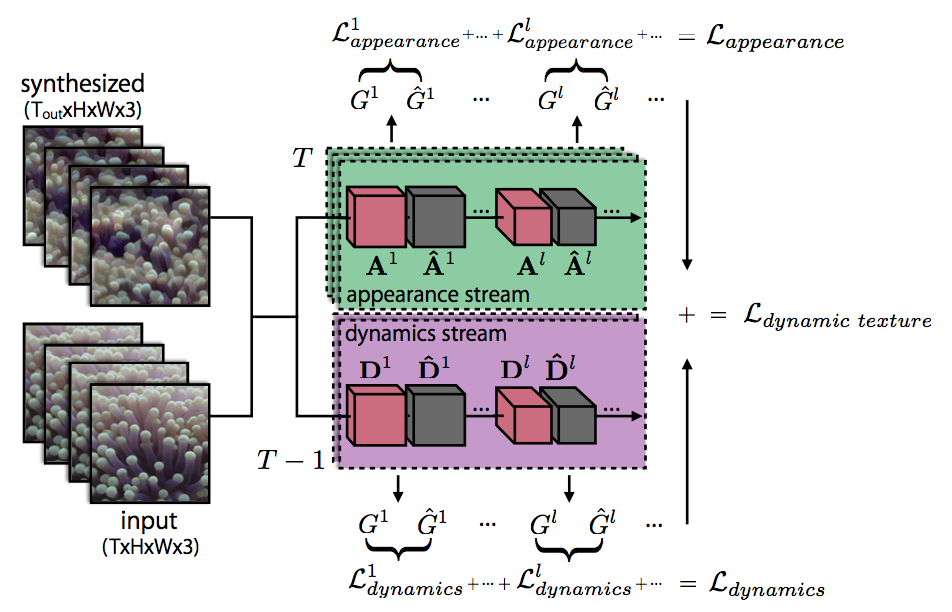
・学習済みモデルを利用し,これを(1)物体認識,(2)オプティカルフロー推定の二つのタスクのために利用.
・物体認識のストリームで入力テクスチャーのアピアレンスの統計的特徴を獲得し,オプティカルフロー推定のストリームで動きの特徴を獲得する.
・入力の動的テクスチャーと生成する動的テクスチャーの二つをスタイルトランスファーと同じようにグラム行列をベースとし,最適化問題として解くことで,動的なテクスチャーを生成する.
影の検出と除去という二つのタスクを同時に学習するend-to-endのフレームワークを提案.提案するST-CGAN は,2つのcGANがスタック構造になっている.一つ目のcGANで影を検出し,二つ目のcGANで影の除去を行う.影の検出と除去の両方に対応したデータセットも公開.
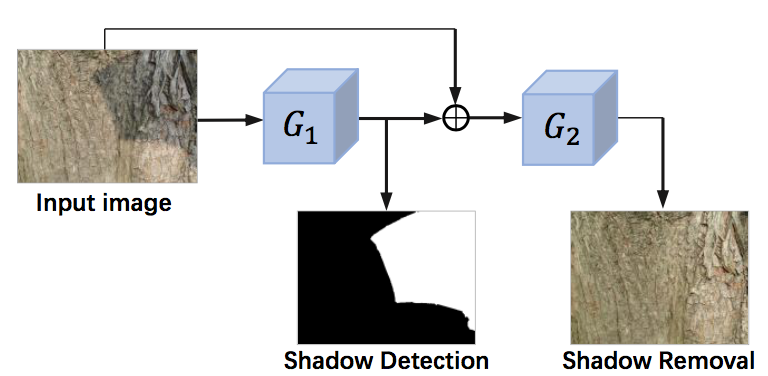
・二つのGeneratorはU-net構造.一つ目のGeneratorは影領域を示すマスクを出力とする.二つ目のGeneratorの入力は影付きの画像と出力されたマスクであり,出力は影を取り除いた予測画像である
・影あり画像,影マスク,影なし画像の3つのペアを持った1870組のデータセットを作成.元々影のない場所で,板や傘を使って自分たちで影を入れて撮影している.そうして上の3つのペアを作成した.
アテンションにより周囲の適切な箇所の画像特徴を利用する生成モデルベースの画像補完手法の提案.大きな領域を補完できるgenerative model-baseのアプローチと,周囲との整合性を取りやすい従来のパッチベースのアプローチのいいとこ取りをする.アテンション機構が,背景側のどの領域を参考にして補完領域を生成すべきか予測する.提案するモデル2つあり,アテンション機構を含まないベースラインモデルとアテンション機構を含むモデルである.モデルはfeed-forwardのFCNであるのでテスト時には任意の場所の複数の穴を補完でき,画像のサイズも任意となる.CelebA-HQの顔写真やテクスチャー,風景写真での実験で高い質の補完が行えることを示している.

各セットの左側が入力画像で,欠損領域が白塗りされている.右側の結果では,木の幹などの構造が崩壊せずに補完できている.
coarse-to-fineの段階的な構造を採用.学習時は,入力,coarse出力,fine出力ともに256x256のサイズの画像である.
従来手法のようにGlobalとLocalのDiscriminatorを持つ.Global Criticが出力画像全体の整合性を評価し,Local Criticが補完領域を中心として局所的な領域の整合性を評価する.Discriminatorが,WGAN-GP adversarial lossを算出するようにしたところが差分.
contextual attention layerの導入.conv層とdeconv層から成る. 前景のパッチと背景のパッチのマッチングスコアを計算するユニットになっている.
2枚の入力画像の中間フレームを必要な数だけ生成することが可能なend-to-end CNNの提案.双方向のオプティカルフローの推定とそれを元にしたフレーム補間のCNNから成る.モーションの補間とオクルージョン領域の推定を同時にモデル化することができる.これらのCNNは時間情報に依存しないので,間のフレームをいくつも作成することができることが特徴.
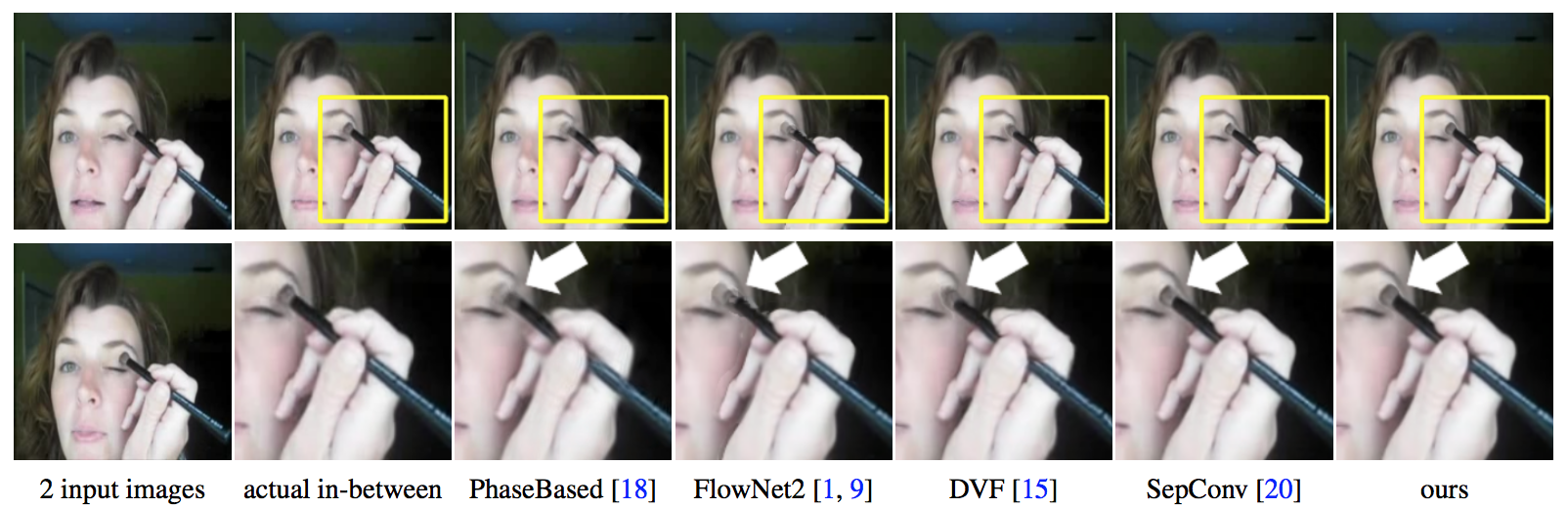
2つの入力フレーム間の双方向オプティカルフローの推定をCNNで行い,その2つのオプティカルフロー場から中間のオプティカルフロー場を近似的に求める.フロー補間のCNNでその近似の質をさらに高め,中間補間のためのsoft visibility mapを予測する.双方向オプティカルフローの推定のCNNも,フロー補間のCNNもどちらもU-net構造をしている. それぞれ30万フレームを含む1132本のビデオクリップ(240fps)を使って学習させている.
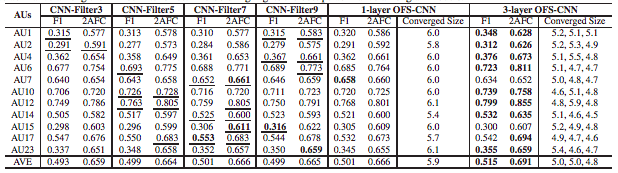
CNNの振る舞いに関する分析は、従来手法のほとんどが入力に対する活性化に対して行っていたのに対して、本論文はフィルタ自体に着目して分析を行った。畳み込み層と全結合層に対して分析を行い、それぞれに対して基底となるフィルタを作ることで、学習に必要なパラメータ数を減らし、また提案手法を適用することでImageNetで学習させたVGG-vd-16の精度を向上させることに成功した。
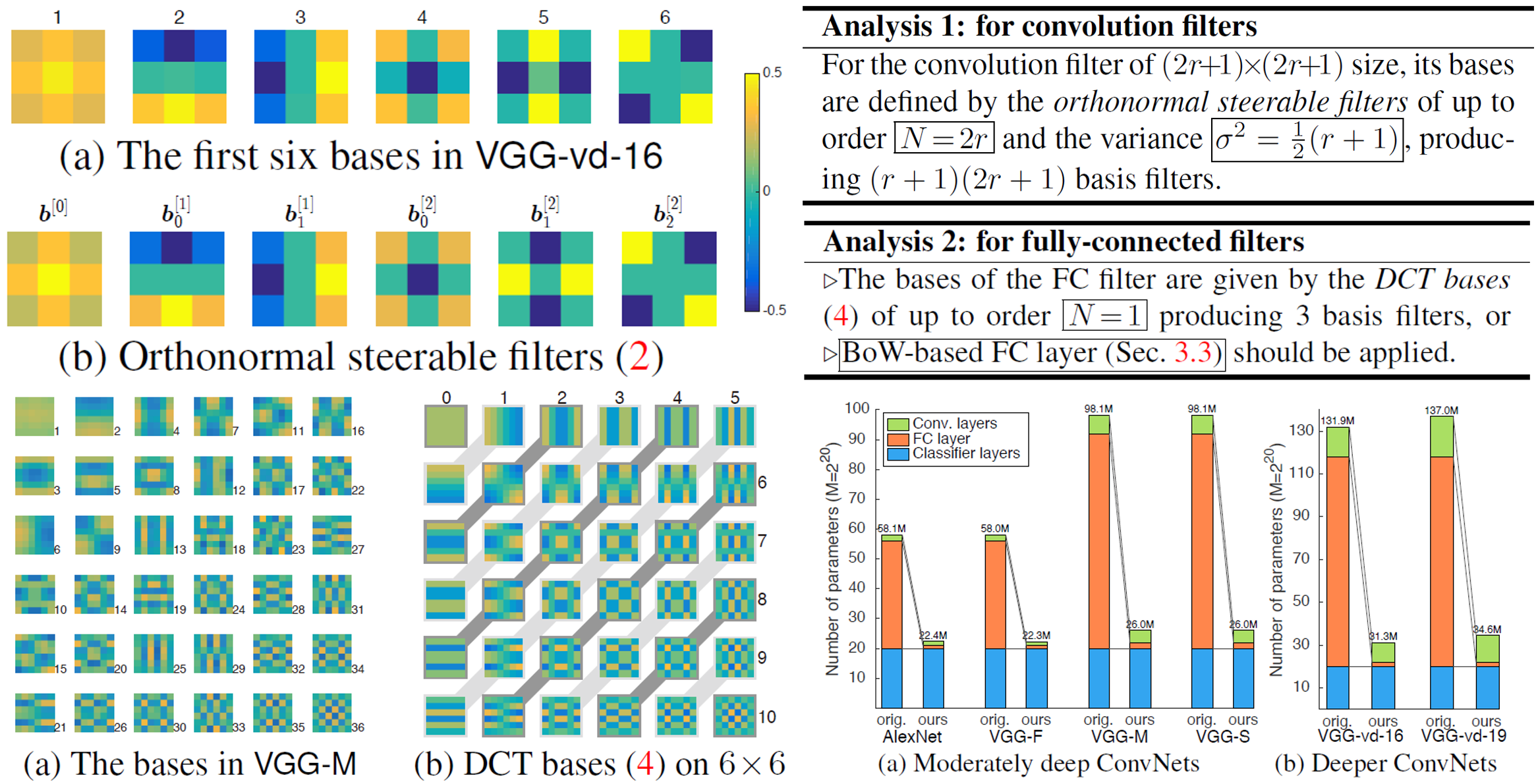
VGG-vd-16の畳み込み層のフィルタに対してSVDを行い主成分を抽出すると、Orthonormal Steerable Filtersと呼ばれる既存の直交するフィルタと非常に類似したフィルタとなっていることがわかった。同様にVGG-Mの全結合層に対してSVDを行い主成分を抽出すると、離散コサイン変換の基底関数と類似していることがわかった。したがって、これらの基底関数の線形和で畳み込み層のフィルタや全結合層の重みが決定できるとすると、従来のおよそ半分の学習パラメータ数に抑えることができる。
本論文は複数の異なる種類の特徴量を効率的に利用するため、DCFを使った複数のexpertを構築し、各フレームごとに適切なexpertを選択することで頑健な物体追跡手法(MCCT:Multi-Cue Correlation filter based Tracking)を提案した。深層学習から得た特徴量を用いた場合においてSoTAを達成し、従来のHandcraftedな特徴量を用いた場合において、最新の深層学習ベースの手法と同等の精度かつCPUで45fpsの速度を実現した。
![]()
HCFがfeature-levelの統合のみを考慮していたのに対して、MCCTはそれぞれ得られた特徴量の強みを効率よく利用するために、decision-levelの統合も考慮する。MCCTはそれぞれの特徴量が分散を持った異なる視点の特徴量を抽出するようにし、また複数のexpertを各フレームごとに評価し選択することで、良い推定結果を得る。expertの評価にはpair-evaluationとself-evaluationを提案し、これらを統合する過程がdecision-levelの統合に当たる。
本論文は、Batch Normalizationに白色化を導入したDecorrelated Batch Normalizationを提案した。通常のBatch Normalizationは標準化を行っているが、白色化を行っていない。したがって、白色化を導入することにより、Batch Normalizationよりさらに早く学習を収束させることが可能になった。
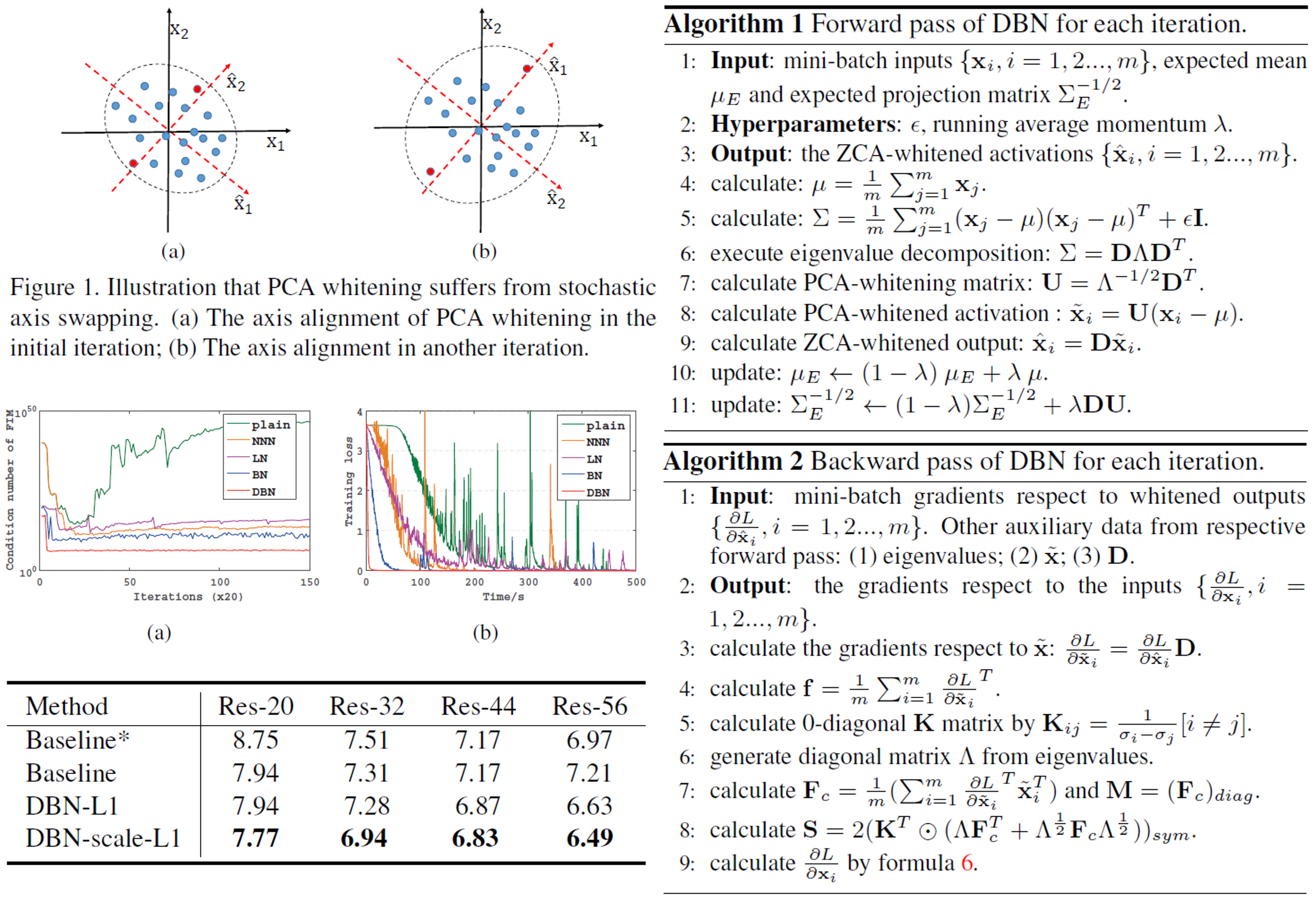
PCAを用いた白色化を行うとstochastic axis swappingという問題が発生する。データxが与えられたとき、それに対する正規直交基底をDとすると、異なるイテレーションから得られたデータx1とx2に対する正規直交基底D1とD2において、D1=D2とならない現象のことをいう。この現象を避けるため、Decorrelated Batch NormalizationではZCAを用いた白色化を行う。
空中画像(aerial image)からオートマッピングするRoadTracerを提案.従来のセグメンテーション手法ではノイジーなCNNの出力では正確なマッピングが難しいことから高いエラーレートの問題があることを述べている. 提案手法ではセグメンテーション手法ではなく, CNNを使った決定関数による探索アルゴリズムで道路をマッピングする. 探索はよく知られている道(大きい道?)のある一ヶ所をスタートポイントとして道に沿って探索していき,各ステップごとにCNNによってネットワークにエッジを追加するか1つ前のツリーに戻るか選択を繰り返しさせて探索していく. 提案手法によりセグメンテーション手法より分岐点などにおいて正しくマッピングできるようになり, DeepRoadMapperやセグメンテーション手法より精度が上昇した.
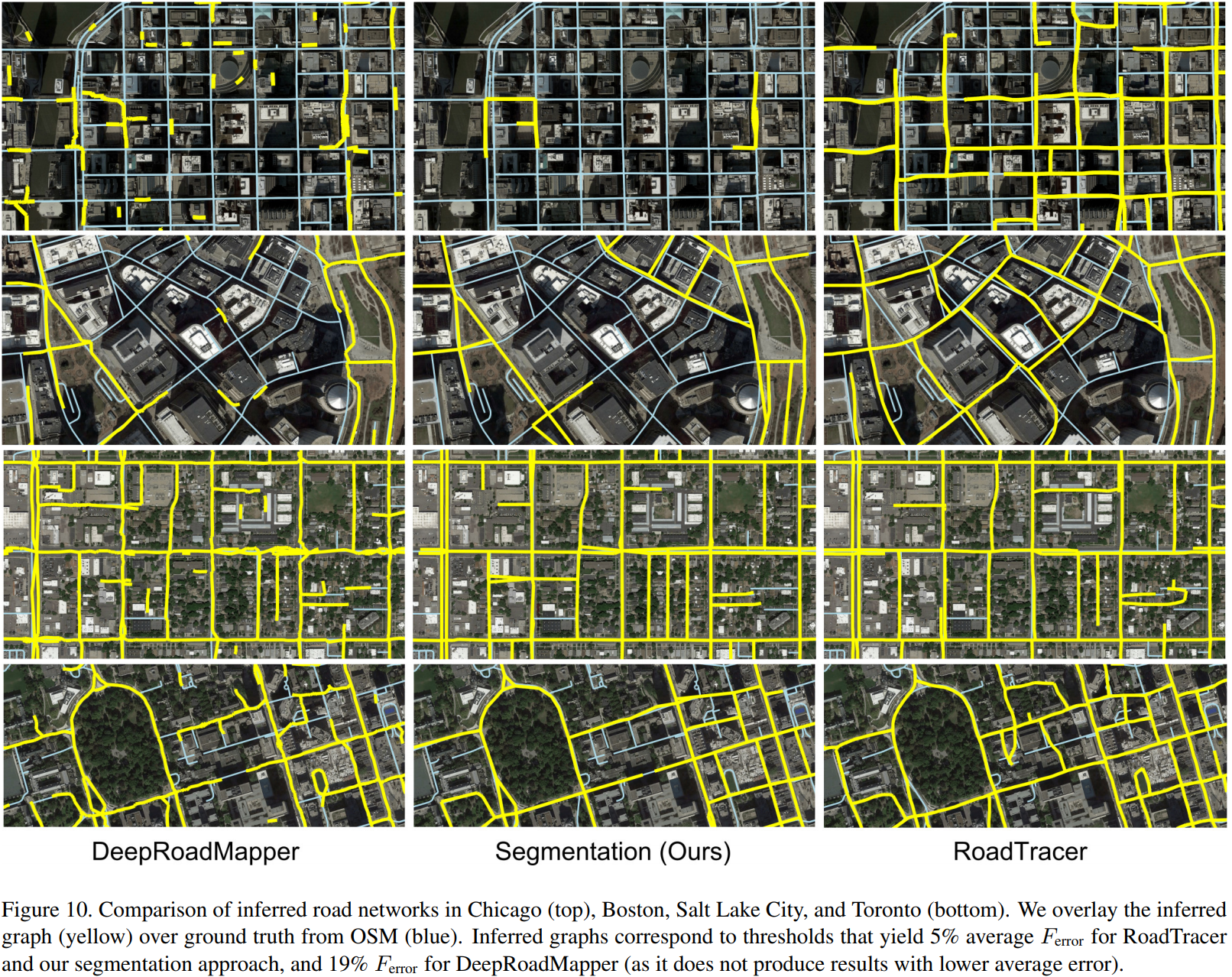
15都市の空中画像を用いて実験した結果,DeepRoadMapperでは21%,セグメンテーション手法では58%正しく道をキャプチャできた一方,RoadTracerは72%正しくキャプチャできた.また,エラー率を5%に抑え,都市に存在する分岐点の45%以上をキャプチャすることが可能となった.
Optical Flow guided Feature(OFF)という動画の行動認識のための運動表現を提案.OFFはオプティカルフローの定義を基に導出され,オプティカルフローに直交している.deepな特徴マップのピクセル単位の時空勾配を計算することで,わずかな追加コストで既存のCNNベースの動画行動認識のフレームワークに埋め込むことができ,CNNの時空情報を抜き取ることが可能になった.
・速くロバストな動作表現であり,RGBのみの入力で200fps以上の速度が出る・OFFを使用したネットワークはend-to-endで訓練させることができる ・UTF-101においてRGB入力のみのOFFを含んだネットワークで93.3%,SoTAな動画認識のフレームワークに埋め込むことで96.0%の精度を達成
構造化されたバイナリエンコーディングの統一的なニューラルフレームワーク内の両方のコンポーネントを学習する1番目のシステムを提案する.
反転されたファイルおよびコンパクトな特徴エンコーダを構築するために教師ありディープラーニング方法を利用する完全な画像索引付けパイプラインを提示する.以前の方法は,教師なし逆ファイルメカニズムを使用したか,または特徴エンコーダを導出するためにのみ教師ありを採用していた. 提案手法が大規模な画像検索において最先端の結果を達成することを実験的に確立した.
本稿では特に,ステレオ問題や3D再構成などのコンピュータビジョンアプリケーションで重要なタスクであるロバストな基本行列推定に焦点を当てている。反復的に再重み付けされた最小二乗(IRLS)を使用するM推定器は,ロバスト推定のための最もよく知られた方法の1つである。しかしながら,IRLSは,初期解が不十分であるために基本行列推定などの頑強な単位ノルム制約付き線形フィッティング(UCLF)問題には効果がない。本稿では,反復的に再重み付けされた固有値最小化(IREM)と名づけられた新しい目的関数およびその最適化を開発することによって,この問題を克服する。
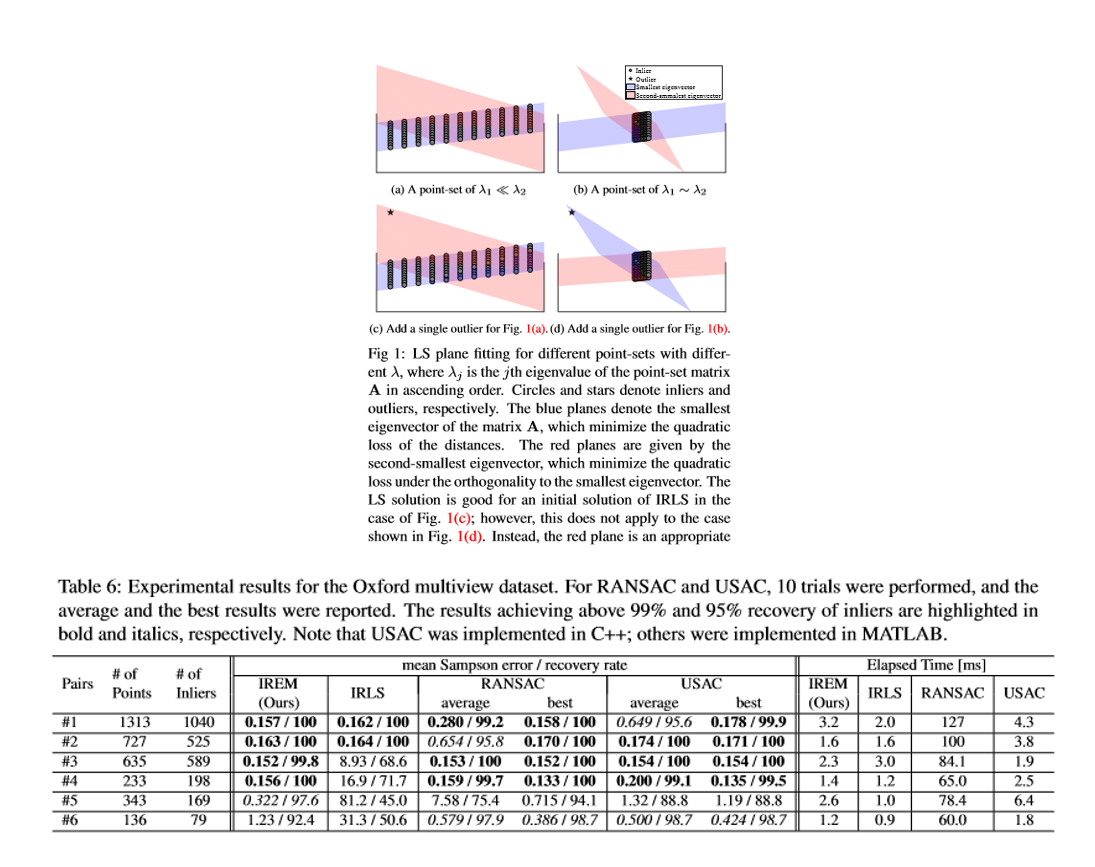
IRLSが強固なUCLF問題ではうまく機能しない理由を明らかにし,IRLSの問題点を解決するためにIREMという名前の新しいアルゴリズムを提案している。
本稿では,光の定位問題について考える。シーンは,観測されていない等方点灯のセットによって照らされる。幾何学,材料,およびシーンの照明された外観を考えると,光の局在化の問題は,光の数,位置,および強度を完全に回復することである。最初に,光の可能性が高いシーン変換を提示する。この変換に基づいて,残りのライトを特定してすべての光強度を決定する反復アルゴリズムを開発する。著者らは,2D合成シーンの大きなセットでこの方法の成功を実証し,合成シーンと現実のシーンの両方で3Dにまで拡大することを示している。
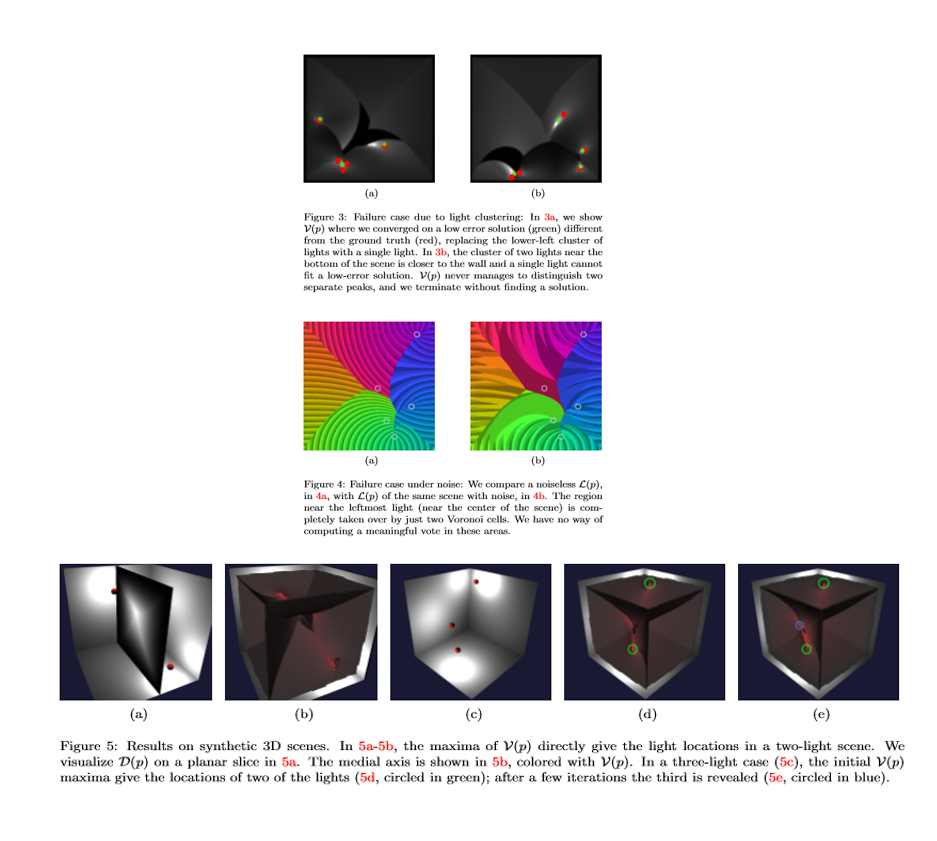
未知数のローカルな離散エミッタの問題の定式化をしている。 シーン内の反射光に基づいて複数の候補光位置を提示する画像変換をしている。位置および強度を含むシーン照明の完全なセットを回復するために光提案を使用する反復アルゴリズムを提案している。
本論文では,畳み込みカーネルの冗長性を排除した効率的な畳み込みニューラルネットワークアーキテクチャの設計問題を検討する。著者らは,IGCV2:Interleaved Structured Sparse Convolutionと呼ばれる連続したグループコンボリューションで構成されるブロックを設計した.このブロックは,構造化スパースカーネルを乗算することとして数学的に定式化されており,それぞれがグループコンボルーションに対応している。相補条件と平衡条件を導入することで,畳み込みカーネルが密集し,モデルサイズ,計算複雑性,分類性能の3つの側面のバランスが良好になる。実験結果は,インターリーブドグループコンボリューションおよびXceptionと比較して,これらの3つの側面のバランス上の利点,および他の最先端のアーキテクチャ設計方法と比較した競合性能を実証している。
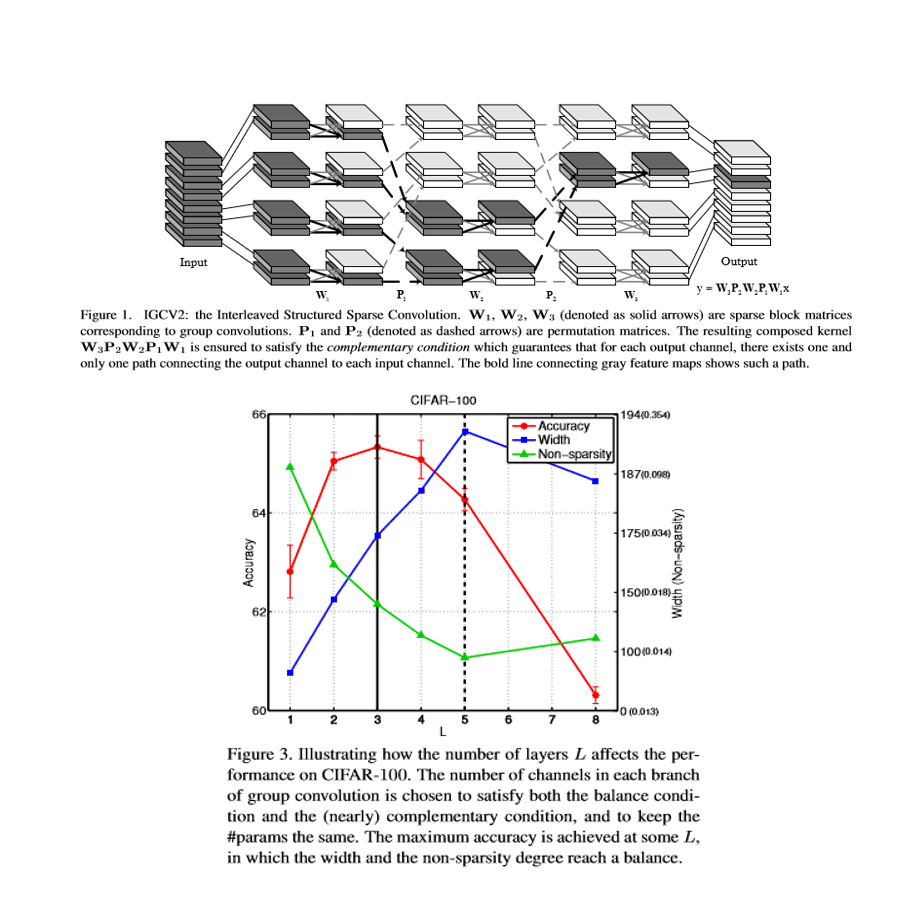
畳み込みカーネルの冗長性を排除し,密集したカーネルを構成している。また密集したカーネルを構成することにより,モデルサイズ,計算複雑性,分類性能の3つの側面のバランスが良好になる。
マルチスペクトル画像は,物体の表面特性の多くの手がかりを含んでおり,したがって,再カラー化およびセグメント化などの多くのコンピュータビジョンタスクで使用することができる。しかしながら,自然なシーンにおける複雑な幾何学的構造のために,同じ表面のスペクトル曲線は,異なる照明および異なる角度のもとで非常に異なって見える可能性がある。本稿では,単一のマルチスペクトル画像からシェーディングと反射を分解する新しいマルチスペクトル画像固有分解モデル(MIID)を提示する。
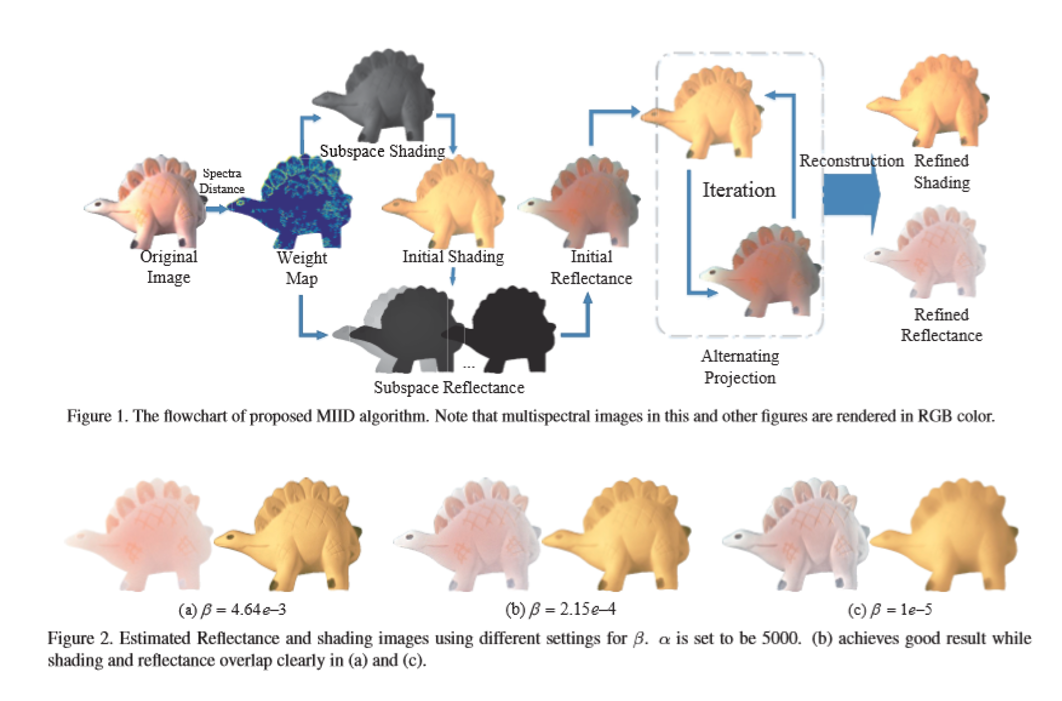
マルチスペクトル画像固有分解モデル(MIID)を提示する。著者らは,マルチスペクトル領域に対して,RGB画像固有分解のために提案されているRetinexモデルを拡張する。これに基づいて,部分空間制約が,シェーディングおよび反射スペクトル空間の両方に導入している。
推論の間により効率的に動作するように畳み込みネットワーク(CNN)を訓練することが望ましい。しかし,多くの場合,推論のためにシステムが持っている計算予算は,トレーニング中に事前に知ることができないか,または推論予算は,変化するリアルタイムリソースの利用可能性に依存する。したがって,推論コストが調整できず,様々な推論予算に適応できない,単なる推論効率の良いCNNを訓練することは不十分である。確率的ダウンサンプリング点(SDPoint)であるCNNにおけるコスト調整可能な推論のための新しいアプローチを提案する。
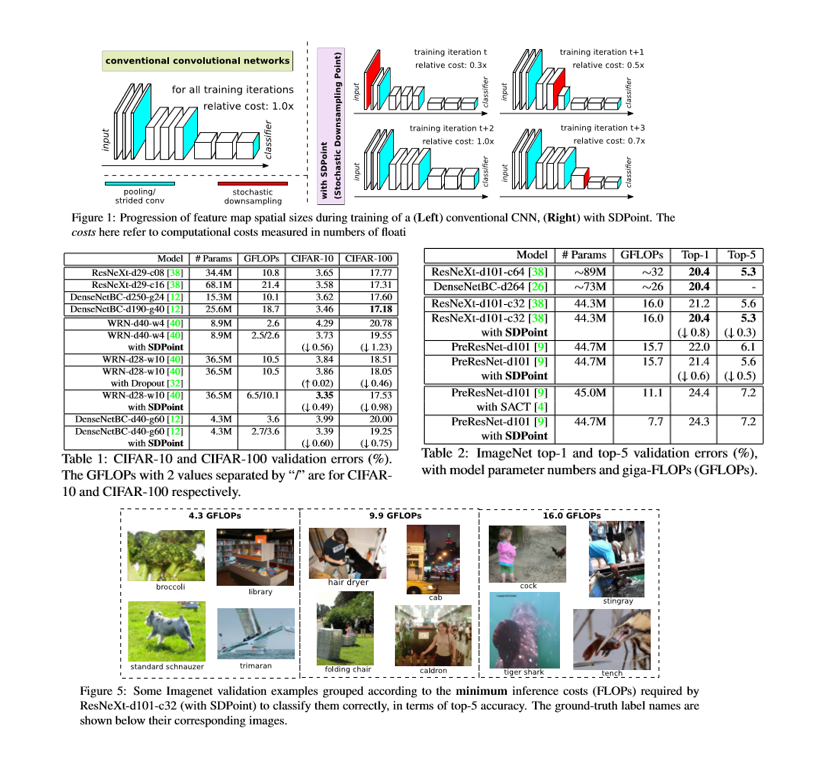
余分なパラメータとトレーニングコストがかからないため,SDPointは効果的なコスト調整可能な推測を容易にし,ネットワークの正則化(したがって正確なパフォーマンス)を大幅に改善する。
ライトフィールド画像は,通常のグリッドで撮影された画像に基づいています。したがって,高品質3D再構成は,エピポーラ平面画像(EPI)の方向を分析することによって得ることができる。しかし,そのようなデータは,オブジェクトの片面のみを評価することを可能にする。さらに,各方位に沿った一定の強度は,ほとんどのアプローチにおいて必須である。本論文では,円環状のフィールドと呼ばれる円形のカメラモーションで得られたデータから奥行き情報を再構築することを可能にする新規な方法を提示する。この手法を使用することで,対象物の全360度のビューを決定することを実現する。

使用する画像は,テレセントリックカメラで撮影した画像と標準の遠近両用レンズで撮影した画像の2種類である。従来の線形ライトフィールドとは異なり,円形のライトフィールドを使用している。
covariance poolingをNewton-Schulz iterationを用いて高速に行う手法を提案。covariance poolingを行う既存手法の多くでは行列の平方根を行う際に固有値分解と特異値分解を行っているが、これらはGPUで十分にサポートされておらずトレーニング時間を効率的に行うことができなかった。提案手法ではcovariance poolingにおける行列の平方根の計算をGPUでサポートされいているpre-normalization、Newton-Schulz iteration、post-compensationで行う手法を提案。Newton-Schulz iterationでは二つの式の最適化を行い、post-compensationはデータの規模に依存する処理であるpre-normalizationの影響をを緩和するために行う。
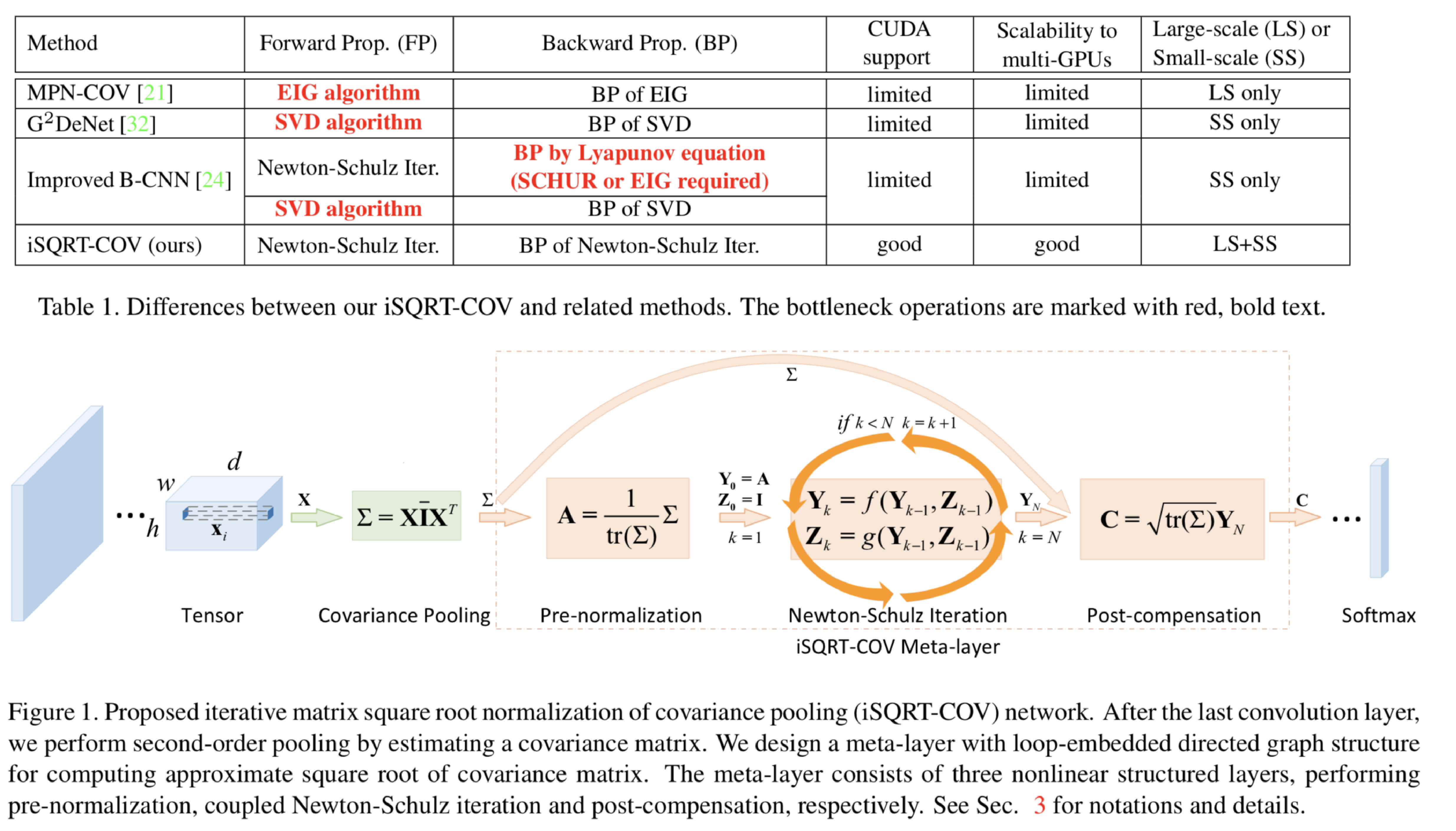
多くのCV分野では、2枚の画像間におけるk-NNFの計算を必要とし、クエリ画像内の各パッチについて、データベース内のk個の最も類似したパッチの位置を決定する。PatchMatchアルゴリズムは、この検索問題を画像パッチの局所的一貫性を利用する共同検索手法によって効率的に近似し、解決した。本論文はこのPatchMatchやその亜種(改良版)について調査している。
確率論的アプローチの変分近似は、閉形式変数更新の分析式を導出するというプロセスを排除し、代わりに対数の勾配を計算するだけでよく、人気が高まっている。しかし、ログ勾配において、標準的な勾配法を用いて最適化することは困難な場合がある。図は、オプティカルフローに応用した結果。 Ground truth (上)、フロー予測(中)、不確実性推定(下)。
オプティカルフロー推定、ポアソンガウスノイズ除去、3D表面再構成の3つのアプリケーションで改善を実証。
・動画の領域分割手法のContent-Sensitive Supervoxels(CSS)の提案・空間次元と同じ方法で動画を単に扱うだけではなくオプティカルフローを使用して、隣接フレーム間のボクセルの接続ブラフを構成し、規則的な3次元格子構造を、高次元の色と時系列空間にマッピングすることによって歪める。 ・K-means++のストリーミングバージョンを適用することにより、一度にメモリにロードすることが出来ない長いビデオを処理可能。

・7つの代表的なスーパーボクセル手法を4つのビデオデータセットで比較し、既存のスーパーボクセル手法より優れている。
グラフカットとグラフマッチングを同時に最適化する問題を定式化し,解決する手法Iterative Bregman Gradient Projection(IBGP)の提案

・実世界の画像と合成データセットの両方で検証し, IBGPは外れ値には脆弱だが,様々な外乱に頑健
この論文では,MorphNetと呼ばれるニューラルネットワーク構造の設計を自動化する手法を提案している。 MorphNetはネットワークを繰り返し縮小して拡張し,アクティベーション時にリソースの重み付けされたスパース化レギュラーを介して縮小し,すべてのレイヤーで均一な乗法係数を使用して拡張する。従来のアプローチとは対照的に,本発明の方法は,特定のリソース制約(例えば推論ごとの浮動小数点演算の数)に適合し,ネットワークの性能を高めることができる大規模ネットワークにスケーラブルである。評価実験では,さまざまなデータセットとシードネットワーク設計での自動構造学習のMorphNetアルゴリズムを評価している。FLOPとモデルサイズの制約の分析では,制約と精度との間のトレードオフの形式は特定のリソースに大きく依存し,MorphNetはFLOPまたはモデルサイズのいずれかを対象とするときにこのトレードオフをうまく乗り越えることができることを示した。
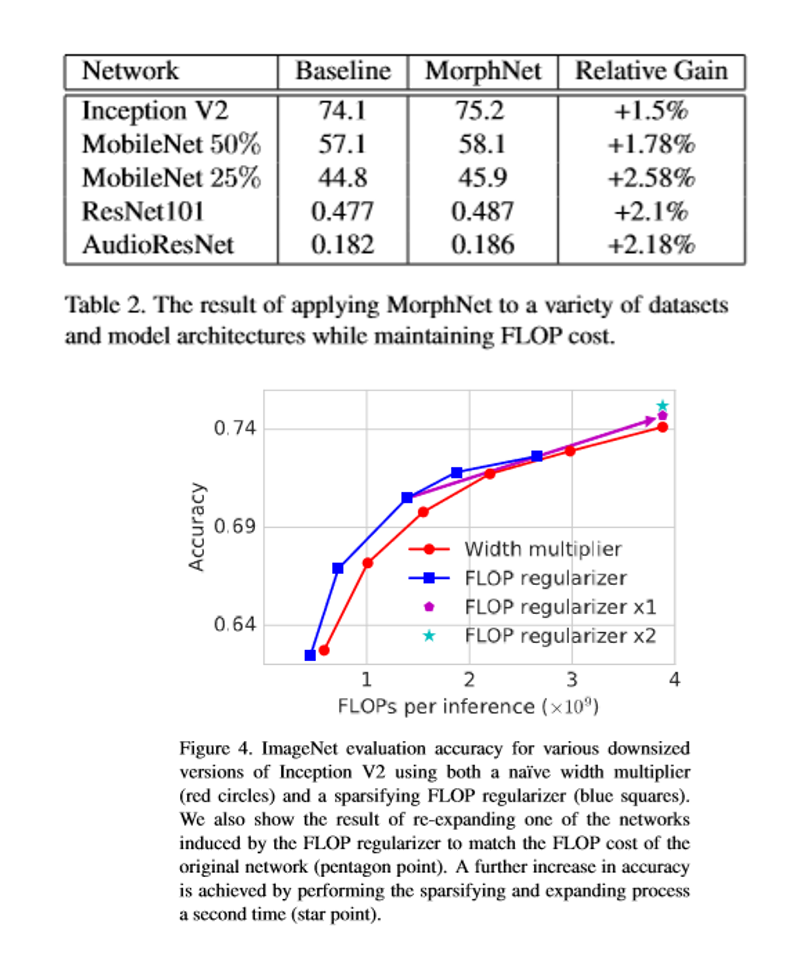
ニューラルネットワーク構造の設計を自動化にしている。またリソース制約をすることにより大規模ネットワークに拡張可能になっている。
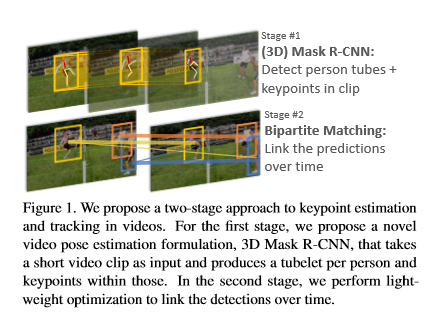
DNNにおいて,システムを混乱させるような攻撃にロバストとなるには,それらの攻撃された画像を学習する必要がある.そこで本稿では,識別する画像に細工を加えることで従来のDNNの識別を間違えさせるアルゴリズムを提案.今回は道路標識の画像に対し環境情報,空間的制約を分析して画像上に細工を加える.作成した画像をLISA-CNNやGTSRB-CNNに識別させ,その間違えた結果を評価している.
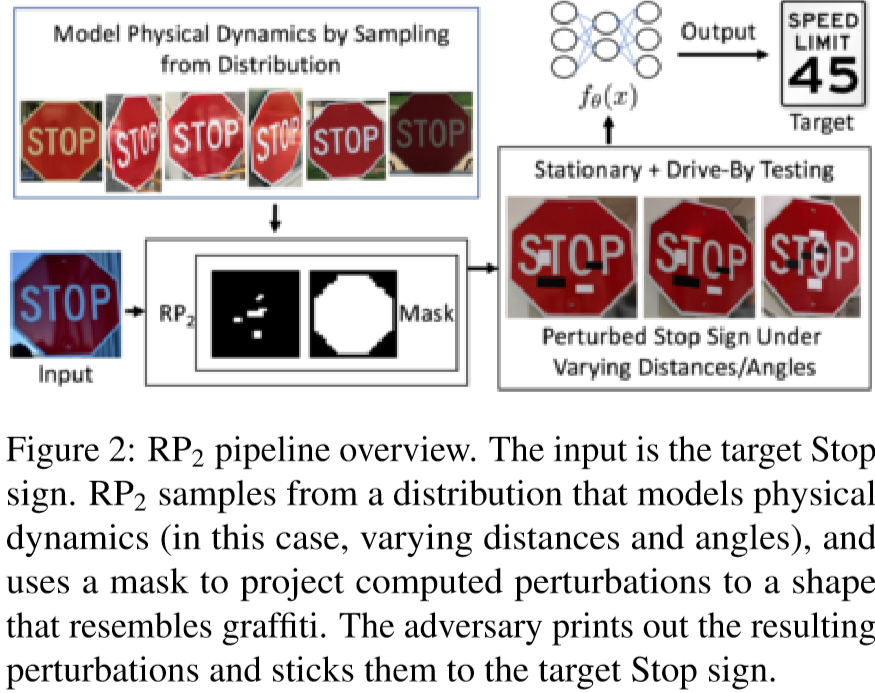
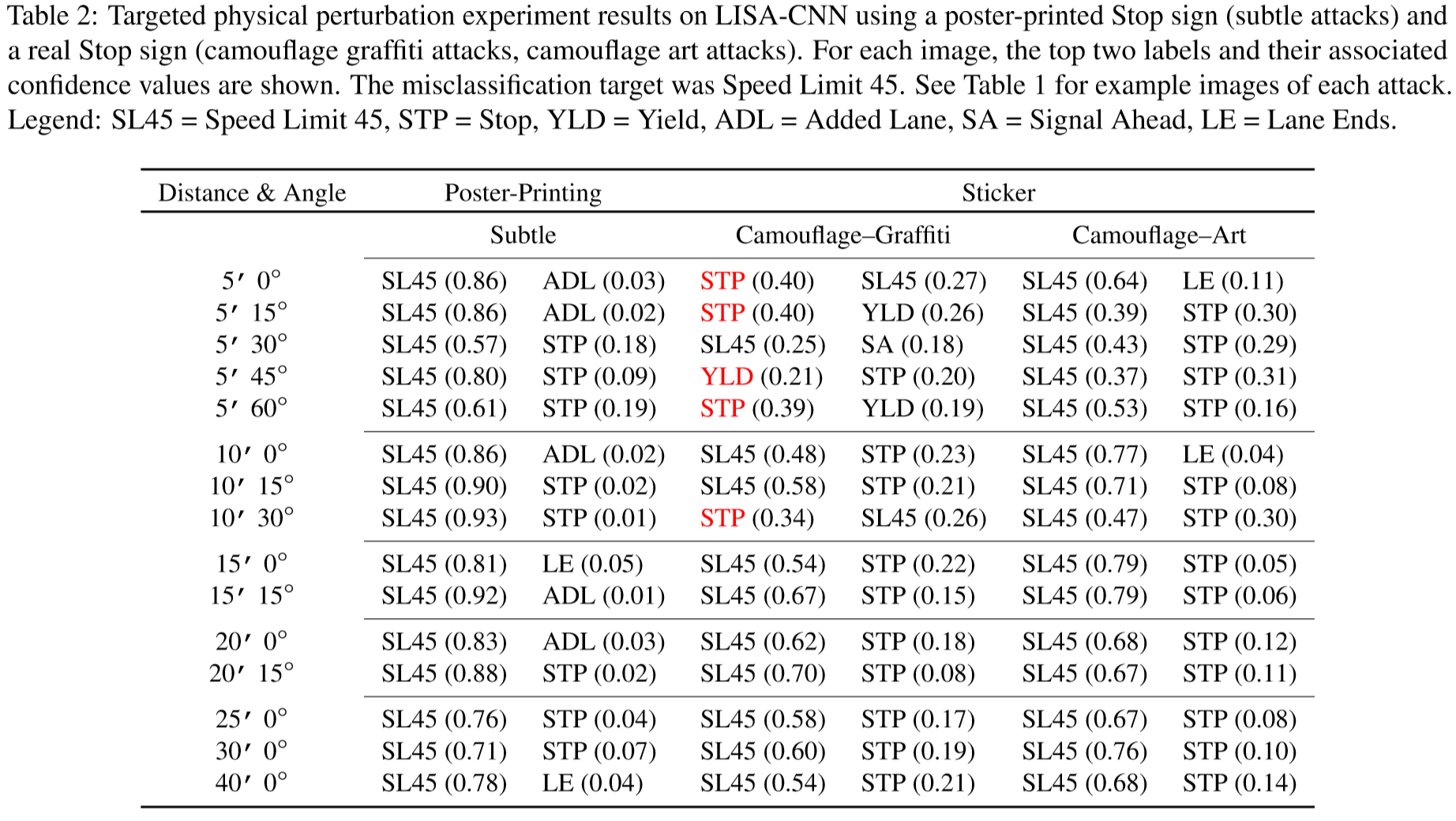
実際に”STOP”の標識を"Speed Limit 45"などに誤認識させており,さらにその識別結果が80%を越えている.この事からかなりの精度で攻撃できていることがわかる.
Pretext taskに特化したNNでのSelf-supervised学習(SSL)により獲得した特徴表現をtarget task用のNNに蒸留する手法。従来まではpretext taskに使用したモデルをそのままfine-tuningしていたのでモデル構造の制約が存在したが、二つのtaskそれぞれに適したモデルを選択することができる。さらにjigsawに対して、tailの一つを他の画像に置き換えることによりさらに難度を上げるjigsaw++を提案。

(a)従来通り何かしらのラベルなし表現学習。(b)ラベルなし特徴抽出&クラスタリング。(c)target taskモデルでクラスタ(pseudo labeling)識別。(d)target taskモデルで本学習。VggからAlexに蒸留した場合は精度向上。 同一モデル同士の蒸留はあまり効果がない。通常の蒸留よりもクラスタ識別させた方が効果がある。
Self-supervisedに獲得した特徴表現ではなくても(HOGでの実験が論文内にあるように)可能なアルゴリズム。単純に蒸留するよりもクラスタ識別にしたほうが良い精度以外での裏付けもみたかった。
Pixel-wiseでの固定ノイズの加算=>ReLU=>1×1convというPerturbative layerを使用したPNNの提案。実験ではPerturbative residual moduleを用いたPNN-Resnetを使用してImageNet, Cifar-10のclassification、Pascal VOCのobject detectionによる評価でそこそこ良い性能を示した。結論としては、今回の実験結果から最適な画像認識用のNNはConvが必要であるとは限らないと言っている。
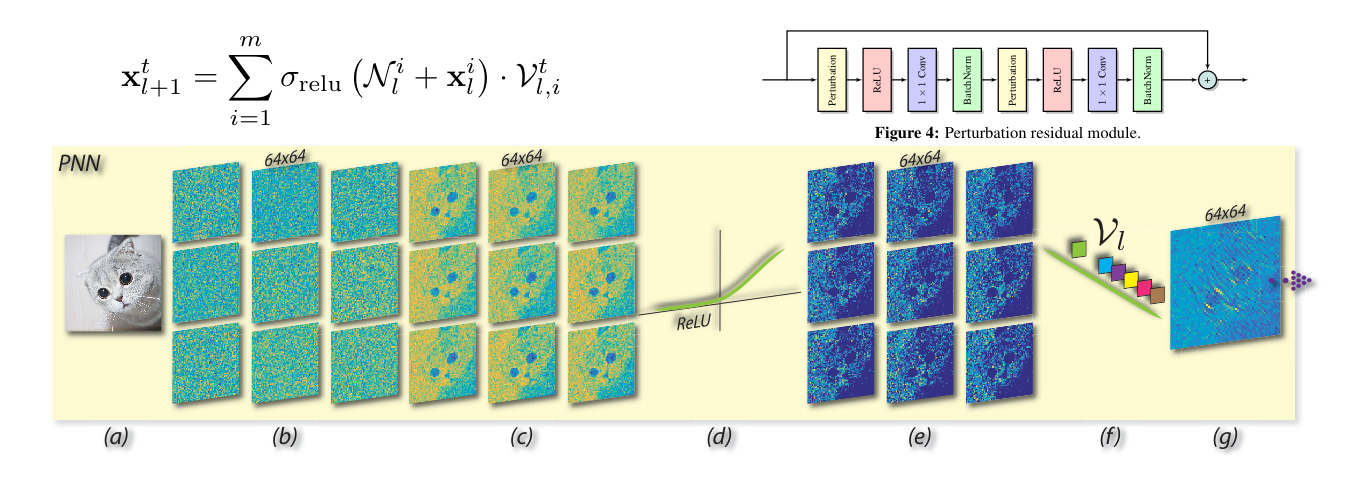
通常のconvの代わりに固定のhand-craftなカーネルを1×1convによる重み付けで近似し、計算コスト・学習パラメータの削減を行うLBCNNを元の発想としている。(固定カーネルがPixel-wiseでの固定ノイズの加算に変わっている)実質、 Perturbative layerでの受容野は1×1領域になるので論文中では(Convは使用しないため)Pooling層などで受容野を拡大すると述べられている。
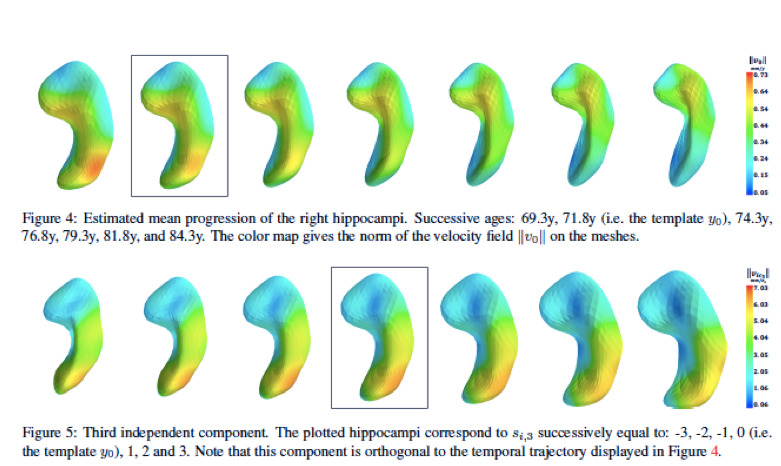
複数の時点で繰り返し観測される個々のオブジェクトの集合から形状軌道の分布を学習する方法を提案.非線形混合効果統計モデルを,マニフォールド値の縦方向データの一般統計モデル,マニホールド構造を持つ有限次元の微分同相写像を用いた形状軌道を定義する.評価実験では,アルツハイマー病の進行に関連した2Dシミュレーションデータおよび3D脳構造の大きなデータセットに関する我々の方法を検証し,時空間パターンを分類する.
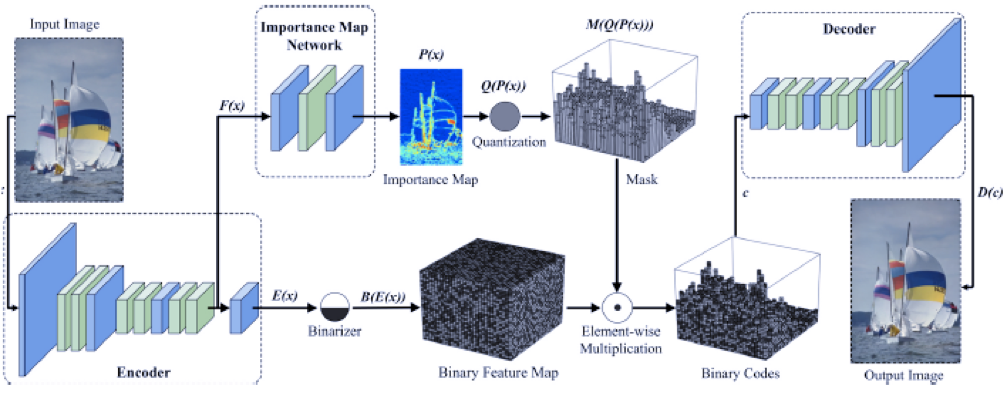
画像圧縮はエンコーダー,デコーダー,量子化器を学習することによるジョイントレート –と歪みとの間の最適化問題として定式化される.CNNベースでの画像圧縮システムを開発することは困難とされているが本論文では,情報コンテンツが画像内で空間的に変わっているという動機づけによって画像空間の重要度マップを作成した,これらの合計を圧縮率を制御するための離散エントロピー推定の連続的代替とした.造類似性(SSIM)における評価としてJPEGおよびJPEG2000よりも著しく優れており,鮮明なエッジ,豊かな質感,および人工っぽさの少ない非常に優れた視覚的結果が得られることが実験によって示されている.
研究指針の1つとして予測の質に加えて推論コストを考慮に入れることがある.本研究では,予測品質とコストの両方に関して効率的なニューラルネットワークアーキテクチャを発見する問題に焦点を当てるためにBudgeted Super Networks(BSN)と呼ばれるモデルを提案.計算コスト,メモリ消費コスト,および分散コストの3つのコストに対応する技術の能力を分析.
本研究では,fine-grained認識でクラス固有の識別パッチを余分な部分や境界ボックスの注釈なしにキャプチャする畳み込みフィルタバンクを学習する.このことで,中間層の表現学習がCNNフレームワーク内で強化されることを示す. 一般的なfine-grained認識のデータセットを対象に評価実験をしたところSoTAを達成.
蛍光灯などの光の見づらいフリッカー模様は市販のカメラと鏡面反射を伴う動く物体の単純な組み合わせによって観測することができることを示し,抽出されたフリッカー模様に基づいて画像内の動きのぼやけを除去するための効率的な方法を提案する.環境光のフリッカー模様により誘発される高い周波数特性と画像のブレを除去することが可能になる.

既知ラベルが利用可能であるときに、深い畳み込みニューラルネットワーク(CNN)のための推論手順を提案.一般的なフィードバックベースの伝搬手法で重なり合わない任意の組のターゲットラベルの値が分かっている場合に,未知のターゲットラベルの任意の組の予測精度を向上.マルチタスクモデルを使って実験し,feedback-propがすべてのモデルで有効であることを示す.
以下の3つのステップで構成されている.
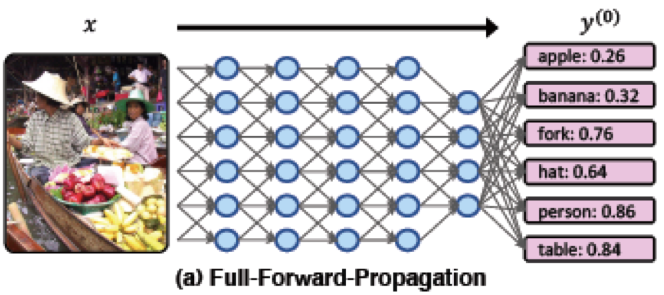
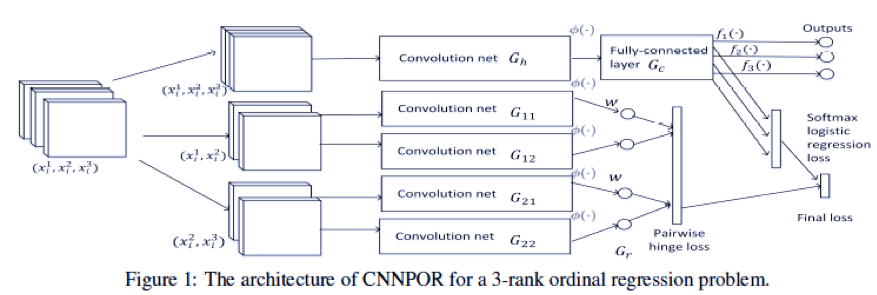
順序回帰は、インスタンスをを順序カテゴリに分類することを目的とした教師付き学習の問題である.クラス内情報を表現するための高次な特徴と,序数関係を同時にクラス分けするための機能を自動的に抽出することは困難である.そのためにCNNによる実装が考えられる.本研究では,インスタンスの順序関係によって制約される複数のカテゴリの負の対数尤度を最小にする序数回帰問題の制約付き最適化手法 convolutional neural network with pairwise regularization for ordinal regression (CNNPOR)を提案.4つのベンチマークを用いて実験し,CNNPORは既存手法よりも良い結果であり,SoTAを示した.
近年画像操作ツールの自動化とリアリティの向上によってソーシャルメディアの誤った情報が増えているため,画像の捜査が重要になる.本手法では画像の人工的なぼかしによる加工を検出し、画像強度と様々な手がかりとの間に非相関な測光関係を生成する.iPhone7Pulsなどのポートレートモードの画像の新しく収集されたデータセットと野外の画像の一般的なデータセットの両方で評価実験をしたところ,既存の手法を上回った.
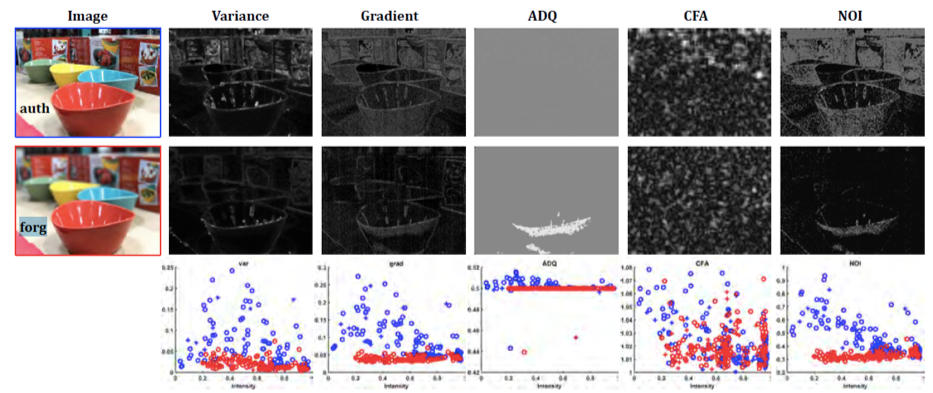
光度ヒストグラム分類のための小さい2つのCNNを融合することで手がかりを統合する.このことで,自然な画像の非対象部分をぼやかせる浅い被写界深度DoFを持つ画像を区別するため画像の捜査方法を提案
DNNsは,アルゴリズムに対するセキュリティ上の懸念をもたらす,敵対的な攻撃に対して脆弱である.敵対的攻撃は,ディープ・ラーニング・モデルが展開される前の頑健性を評価する重要な代理として機能する.しかし,既存の攻撃の大半は精度の低いブラックボックスモデルしかだますことができない.この問題に対処するため,反撃攻撃を促進するために,運動量ベースの反復アルゴリズムの幅広いクラスを提案する.攻撃の成功率を向上させるために,モンテウム反復アルゴリズムをアンサンブルモデルに適用し,強力な防御能力を備えた対抗的に訓練されたモデルも攻撃に対して脆弱であることを示す.提案された方法は,様々な深いモデルや防衛方法の頑健性を評価するためのベンチマークとして役立つと考えられる.

Ensembleの敵対的訓練は、訓練されたモデルだけでなく、他の拘束モデルからも生成された敵対的なサンプルを用いて訓練データを補強する.したがって、アンサンブルの訓練を受けたモデルは、ワンステップ攻撃とブラックボックス攻撃に対して堅牢である.本稿では,ブラックボックスモデルだけでなくホワイトボックスモデルを効果的に欺くことができる反撃攻撃を促進するための,広範なモーダルベース反復手法を提案する.この手法は,一段階のグラジエントベースの方法とバニラの反復法を一貫してブラックボックス方式より優れている.本研究では提案された方法の有効性を検証し,それらが実際に働く理由を説明するために広範な実験を行う.生成された敵対的な例の転送可能性をさらに向上させるため,ログが融合されたモデルのアンサンブルを攻撃することを提案する.アンサンブル敵対的訓練によって得られたモデルはブラックボックス攻撃に対して脆弱であり,より堅牢な深い学習モデルの開発のための新たなセキュリティ問題を引き起こすことを示している.
画像曇り除去は,霧の存在による屋外画像における望ましくない可視性の喪失の除去を扱う.ほとんどのRetinexベースのアルゴリズムは,常に明るさを上げるという特長を持っている.これは、輝度が反転したぼやけた画像にRetinexを直接適用することにより,効果的な画像の曇り除去ができる可能性があることを示している.この論文では、反転強度に対するRetinexが画像の曇りの問題に対する解決策であるという理論的証明を行う.包括的な定性的および定量的結果は,Retinexのいくつかの古典的で現代的な実装が,より複雑なフォグ除去法と対になって競合する画像枯渇アルゴリズムに変換され,この問題に関連する主な課題のいくつかを克服できることを示している.
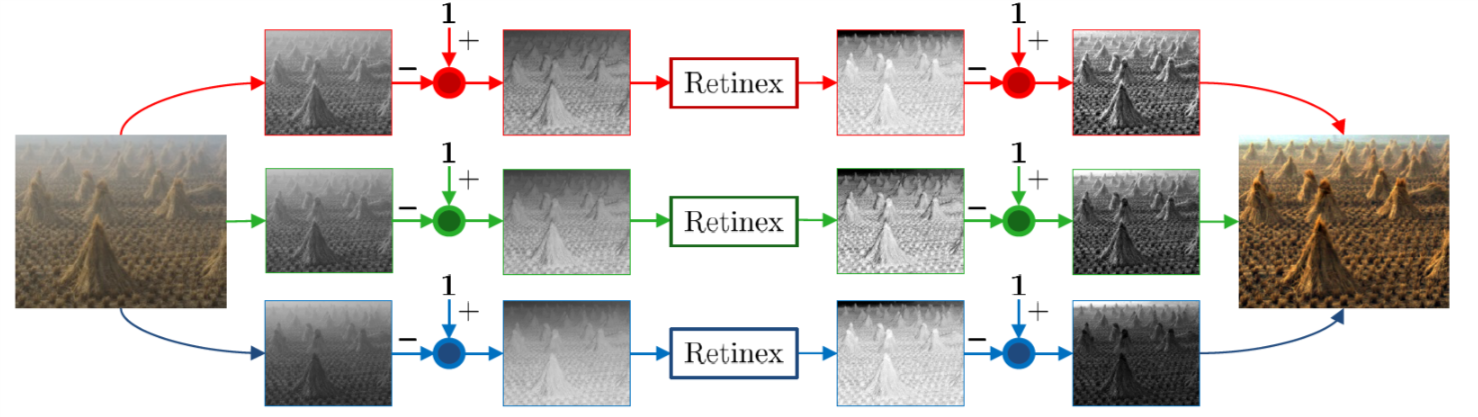
多くの画像枯渇技術は通常、外部の情報源、または同じ場面の複数の画像を必要とする。著者は、2潜在層マルコフランダム場による深度と真の放射輝度の共同確率的推定によって、この必要性を克服する。この論文では、画像の曇りと不均一な照明分離の問題を結びつける二重の関係を厳密に数学的に証明した.倒立画像にRetinex演算を適用した後,結果を再び反転することにより,ぼかし処理された結果が得られ,逆もまた同様であることが示されている.特定のアルゴリズムに限定されるのではなく,Retinexの広範な手法に対してこれが正式かつ実験的に示されている.定性的および定量的実験は,現在の枯渇アルゴリズムと比較して競合結果を示した.
特徴マップの非線形プーリングにパワー正規化(Power Normalization;PN)を実装する新しい層を導入する.PNは,Bag-of-Wordsのデータ表現コンテキストで非常に有用な非線形オペレータである.CNN(ResNet-50)の最後の畳み込み層で生成された特徴マップの特徴ベクトルφとそれを符号化した空間座標cを組み合わせる.このカーネルを線形化すると,特徴ベクトルの2次統計を獲得するpositive definite matrixが得られる.ここでは,MaxExpとGammaの2つのPN関数について研究する.

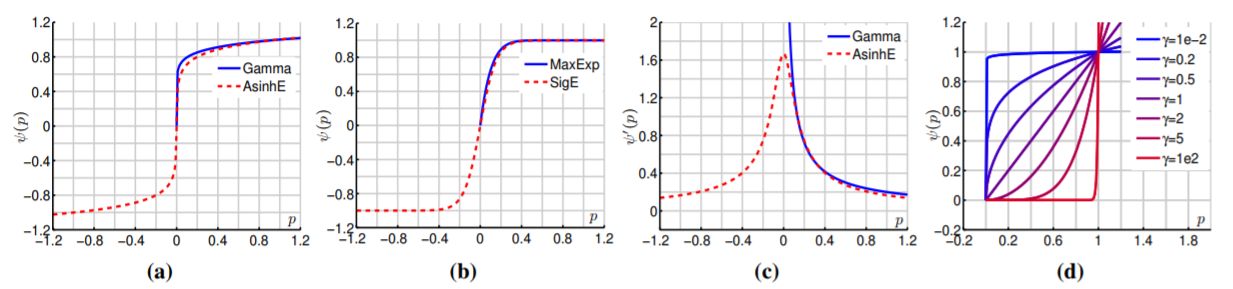
ResNet-50モデルにPN層を実装し,fine-grained認識,シーン認識,マテリアル分類の4つのベンチマークを行い,すべてのタスクでパフォーマンスの向上を行うことができた.
画像のクラスラベルのみを用いてセマンティックセグメンテーションのための高品質な識別器を学習する弱教師あり学習手法を提案.ブートストラップ法を用いて学習画像の正確なピクセルレベルの教師ラベルを作成し,Ground truthの代理として用いる.Domain adaptationのような手法をとり,ターゲットデータはPASCAL VOCなどのラベルつき画像,ソースデータはWebから収集した画像(Web domain)である.Initial-SECを始めに学習して,粗いラベルを作成する.間違ってラベル付けされている画像(ノイズ)はここで除去され,セグメンテーションに適した画像のみ残される.次に,WebSECを学習してWeb画像の粗いラベルを作成し,Grabcutにより細かいラベルを得る.そして,Web-FCNを学習して,Web domain内の特徴を得る.最後に,代理GTを用いてFinal-FCNを学習する.
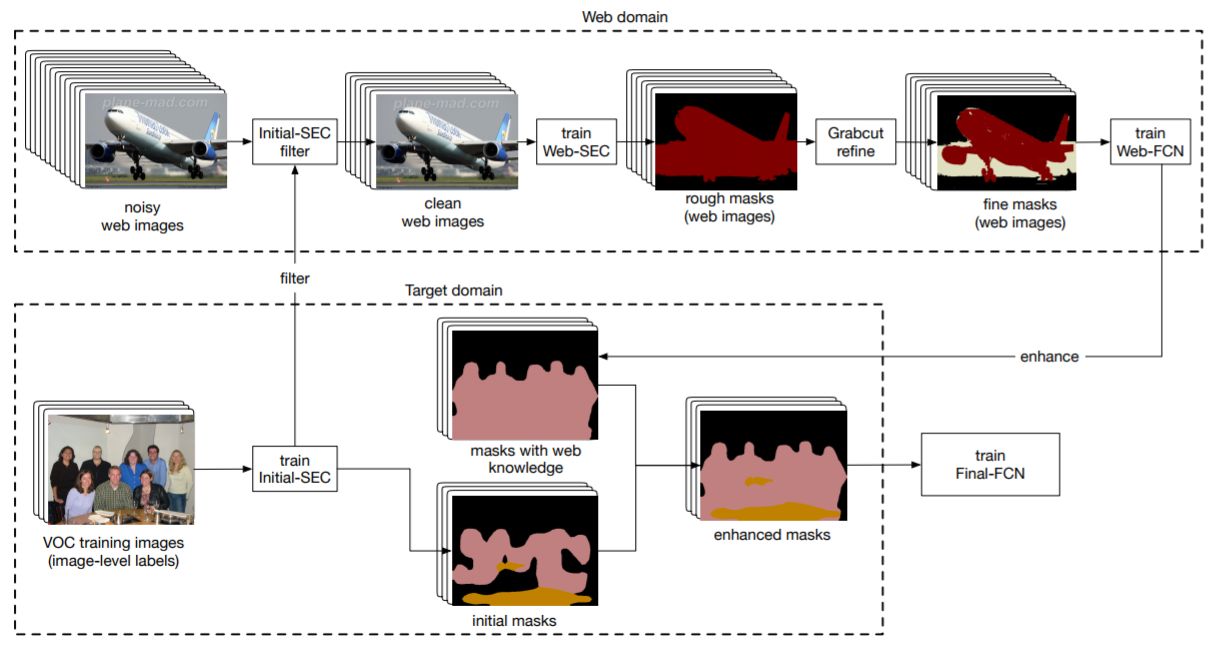
セマンティックセグメンテーションの教師あり学習に必要な,多大な時間をかけてピクセル単位のクラスマスク教師画像を作成する手間を減らすことができる.ResNetをベースに用いることで,他の弱教師あり学習などと同等またはそれ以上の性能を得ることができた.
DNNの教師あり学習時に使用するカスタム正規化関数を提案.アノテーションセットをオートエンコーダーで学習することで,正規化関数を導出.セマンティックセグメンテーション実験では,スクラッチ学習によるモデルおよびImageNet pre-trained modelを用いたファインチューニングによるモデルの両者においてベースライン以上の精度を確認.また異なるCNNにおいても一貫して精度向上を確認.
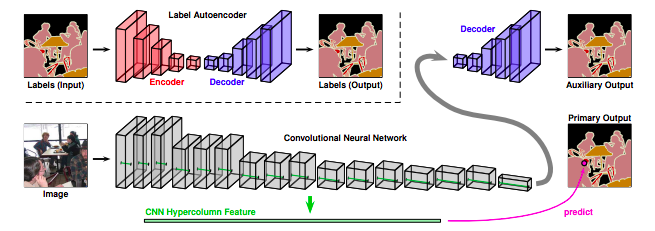
学習の流れは以下の通り
ネットワーク量子化問題において起こる精度の低下に対処するアプローチを提案.学習コードと学習コードに基づく変換を学習の2つのステップに分割量子化を行うTwo-Step Quantization (TSQ) frameworkを構築.CIFAR-10 と ILSVRC-12 datasetsを用いた網羅的な実験によるTSQの有効性,SOTAであることを確認.

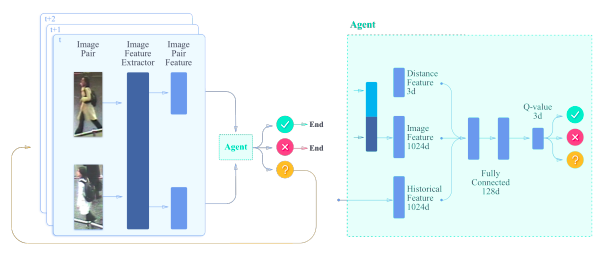
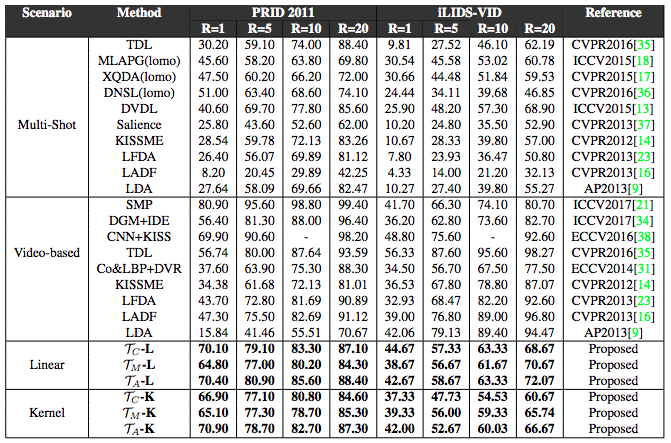
マルチショット(異なるカメラ間)な人物再同定(Person ReID)問題に解釈可能な強化学習ベースのアプローチを組み込んだ手法の提案.3つのベンチマークテストをでは提案手法は他の最新の手法と比較し,3%〜6%の画像しか使用することなく優れた性能を発揮.提案した手法は効率と性能の両面において,他の手法と比べ有利であると提示.
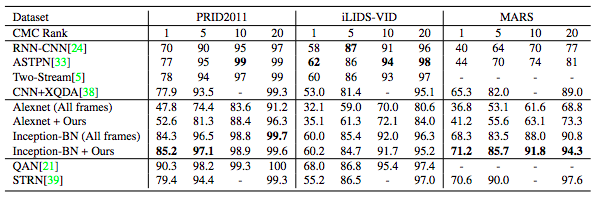
本論文では,CNNの層フィルタサイズと重みを学習データと畳込みフィルタから同時に学習する新規のフィルタサイズ最適化CNN(Optimized Filter Size CNN:OFS-CNN)を提案.実験ではOFS-CNNが様々な画像解像度に対して最適なフィルタサイズを推定し,網羅的な検索によって得られた最良のフィルタサイズを有することを確認.従来手法より優れていること確認.
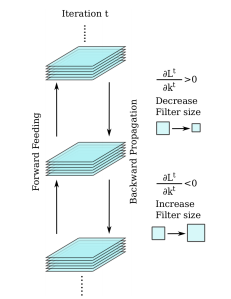
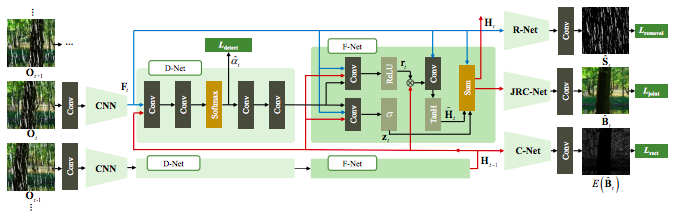
RNNを用いた映像中の雨を除去する手法を提案.雨による画質の劣化分類,空間的テクスチャに基づく雨の除去,時間的一貫性に基づく背景の詳細な再構築を同時に行うJoint Recurrent Rain Removal and Reconstruction Network (J4R-Net) を提案.既存手法を用いた網羅的な実験により,提案手法がSOTAであることを確認.

Multi-shot Person Re-IDentification (MsP-RID)に向けた類似的制約によるモデル学習方法の提案.視覚的指標を学習し,視覚的外観の大きな変化を扱うことで信頼できるモデルを構築.網羅的な実験・ベンチマークテストを行い,識別精度と速度ともに最先端のMsP-RIDの方法に比べ大幅な優位性を確認.
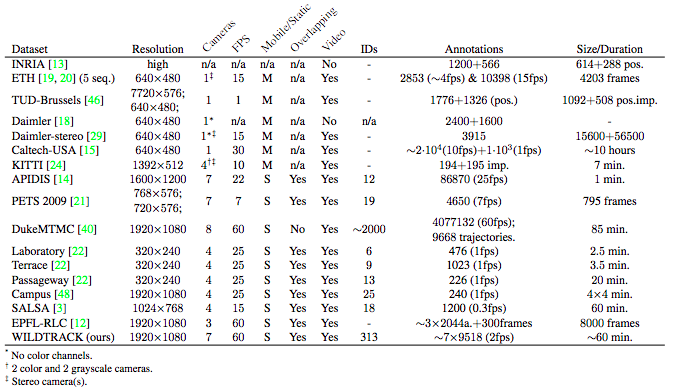
本稿では複数の同期されたカメラを利用した歩行者検出のための大規模かつ高解像度のデータセットを提案.カメラフレームと合わせて,正確なキャリブレーションと2frame/sの速度で検出するための400種類のアノテーション付きフレーム7種類を確保.これにより,40,000を超えるバウンディングボックスが注目領域に存在するすべての人に作成され、合計で300人以上の人物に対してアノテーションを付与.深層ニューラルネットワークを用いた多視点からの人物検出のベースラインアルゴリズムや非マルコフモデルを用いたベースラインアルゴリズムによるベンチマークテストを実施.
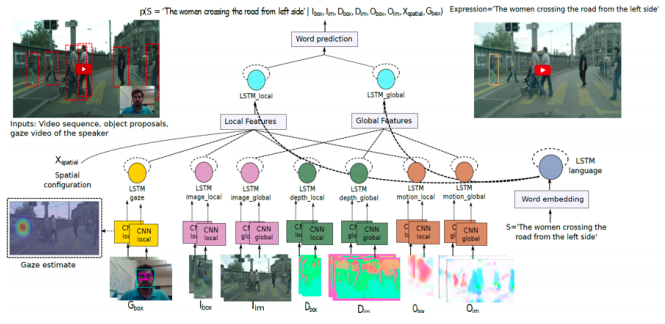
人間の視線情報を用いた動画中のObject Referring (OR)を行う.(OR: 言語記述を伴うシーン内のターゲットオブジェクトのローカライズの問題).物体の外観や動き,注視(視線情報),時空間コンテキストを1つのネットワークに統合する動画におけるORのための新規のネットワークを提案.提案した手法がモーションキューや人間の視線情報,時空間のテキストを効果的に利用可能であることを確認.従来のOR手法より優れていることを確認.
ReIDモデルの学習をより強化するために,Pose transferによるサンプルオーグメンテーションを利用したposetransferrable person ReID frameworkを提案. MARSデータセットのポーズインスタンスを利用し,豊富なポーズバリエーションを持つ新規データを生成,学習することでよりロバストな学習が可能.また従来のGANの識別器に加え,生成した新規データがReIDにおける損失を最適にするguider sub-networkを提案.Market-1501,DukeMTMC-reIDおよびCUHK03において精巧なモデルを使用することなくSOTAであることを確認.
![]()
![]()
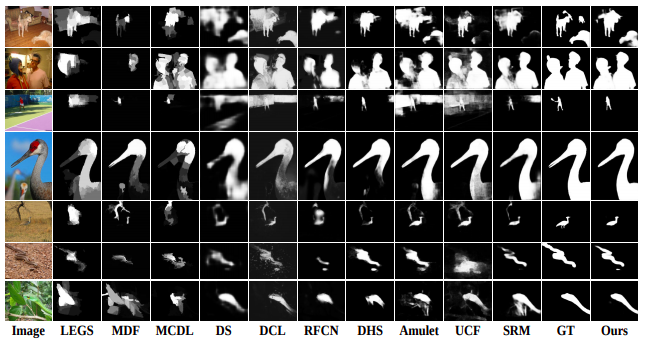
salient objectの位置を正確に特定するために重み付けされた応答マップによってコンテキスト情報を利用可能にするネットワークglobal Recurrent Localization Network (RLN)を提案.また,物体境界を正確に把握するために各空間位置について局所的なコンテキスト情報を適応的に学習するlocal Boundary Refinement Network (BRN)を提案.本アプローチが既存のすべての手法に対してSOTAであることを確認.
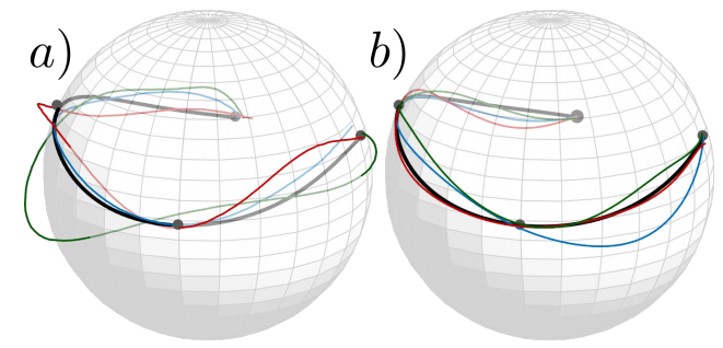
図において、(a)は、通常のGP回帰。黒曲線は予測値であり、他の色の曲線は予測分布からのサンプルであり、球体から大きくずれている。(b)は、データの幾何学的制約を考慮したWGP回帰を使用している結果。
diffusion weighted imaging(DWI)や球上の指向性データ、ケンドール形状空間で検証。多様な値の回帰のための効率的かつ柔軟な手法としてWGP回帰の有効性を示唆。
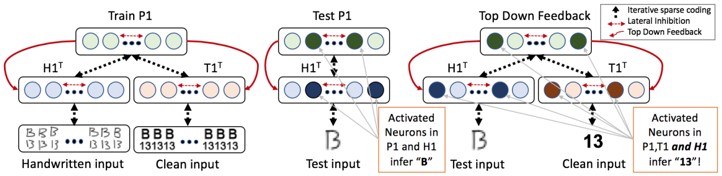
CNNは様々なCVタスクに貢献しており、分類問題では人間を超越しているという結果もある。一般的なアプリケーションでは、やはり人間には及ばない。希薄性、トップダウンフィードバック、横方向抑制など、人間(哺乳類)に見られる脳のしくみに着目し、深層学習においてそれを再現するようにモデリングしている。
CVや機械学習タスク全般における、定性的および定量的な改善を証明。
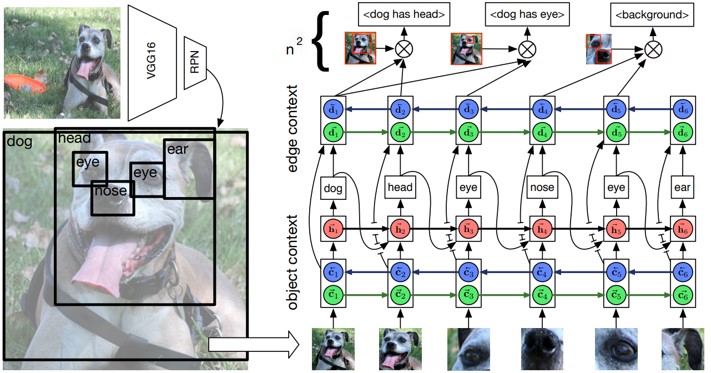
図の犬、耳、目などのバウンディングボックスにおいて、物体間の関係性を構造化する。モチーフという考え方を利用し、Visual Genome datasetを分析。

本マルチグリッド法は、エネルギーベースのCNNモデルを学習することができ、元のcontrastive divergence(CD)とpersistent CDより高精度。
2つの異なるクラスのモデル間の不一致や学習の不安定性などの問題を改善することによって、GAN法の代替え法として有効。
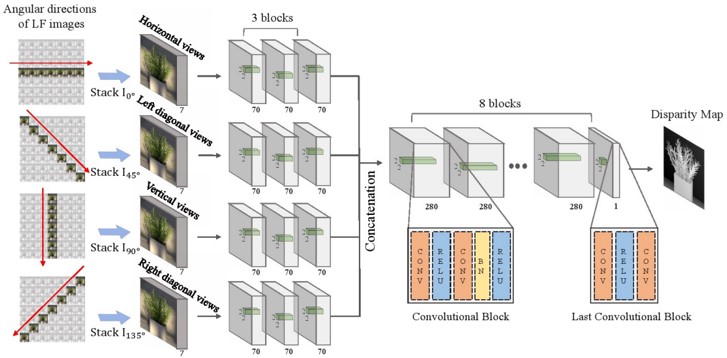
ライトフィールドカメラは、光線の空間的性質および角度的性質の両方を取得できる。様々な照明環境のライトフィールドから深度を計算可能。しかし、ハンドヘルドカメラからのライトフィールド画像は、ノイズが多く深度推定が困難。これらを克服したネットワークを提案。
HCI 4D Light Field Benchmarkにて高精度を確認し、実世界のライトフィールド画像に対する手法の有効性を確認。
CNNの効率化のために、より深く畳み込む手法やグループ化した畳み込みが提案されている。CLC Blockによってネットワークを構成することで、パラメータ数を抑えて計算効率を向上させることができる。
ImageNet-1Kにて効率化の有効性を証明。

入力画像ペア(図上)において、意味的に一致する密な対応を、幾何学変換とおもに出力し(図中) 、幾何学的に一致しないペアを破棄する(図下) CNNを提案。RANSACからインスパイアされた手法によって、ネットワークアーキテクチャとトレーニング手順を設計し、弱教師付き学習で実装可能。
精度は高く、SOTA。しかし、依然として複数のオブジェクトが存在する場合や、違うクラスにおける画像ペアを扱うことができていない。
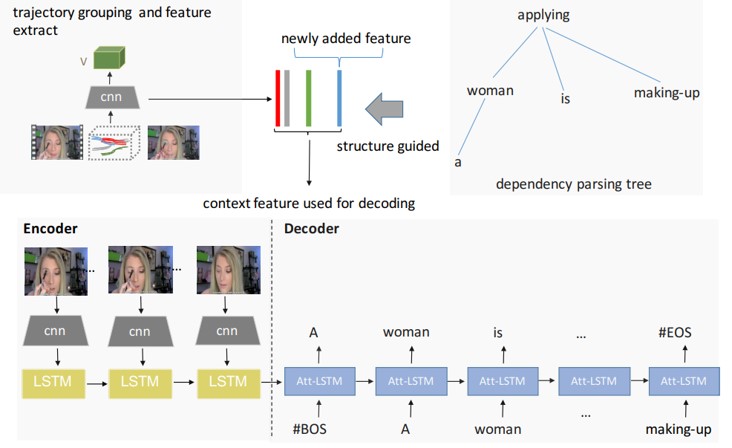
既存の手法では、RNNに入力する前にグローバルな画像特徴を取っているだけであると指摘。異なる時間において、顕著な物体に着目することや、微妙な言語表現を学習するために細かい移動や動きに対する関係性を見出す必要がある。Trajectoryレベルでの特徴を統合して学習することにより、動画中の動く物体を精度よく記述できる。
CharadesとMSVDデータセットで実験し精度向上を確認。また、提案手法は可視化ツールとしてみなすことができ、モデルの解釈能力を向上させることができる。
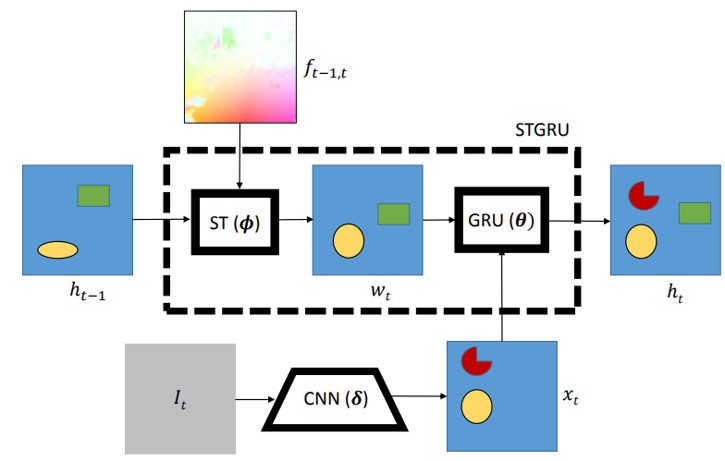
アノテーションなしで余分な計算を減らしつつ学習する。ラベルのないフレームに存在する情報を順番に利用でき、セグメンテーションの精度と時間的一貫性の両方を改善することに成功。
CityScapesやCamVidデータセットにおいて精度向上を確認。
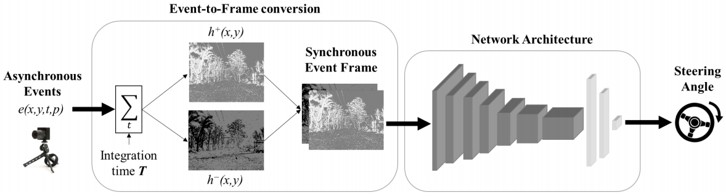
動き推定タスクにおいて無駄のない情報を得ることができるイベントカメラを用いて、そのポテンシャルを示すことにモチベーションを置いている。イベントセンサーの出力と連携して動作するように設計することで高精度に推定できる。
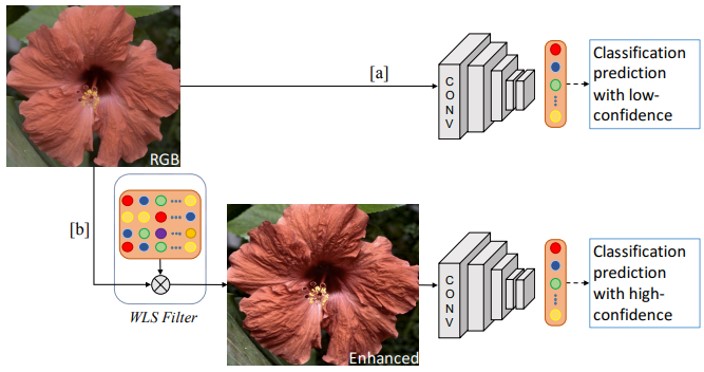
CNNは、画像の質感や構造を利用して、分類するための識別器として使われるが、Image Enhancementによって画像を協調し、CNNの前処理として使用可能。既存の画像強調手法は、人間の画像の知覚向けに設計されている。画像強調のためにCNNを拡張し、画像分類精度が向上するように共同で学習することができる。
CUB 200-2011、PASCAL VOC2007、MIT Indoor、DTDの4つのベンチマークデータセット(fine-grained, object, scene, and texture classification)で実証。全ての一般的なCNNにおいて精度向上を確認。
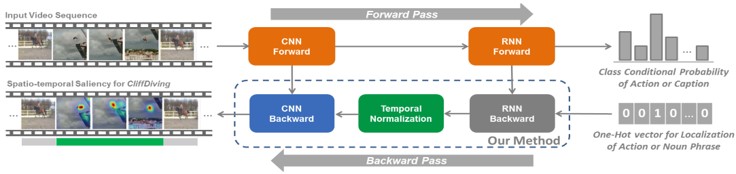
RNNが何を根拠にタスクをこなすのか、GradCamのように出力するモデルの提案。図は、CliffDivingとHorseRidingの両方を含む動画において、アクティブクラスであるCliffDivingの顕著性を強調している例。
ActionとCaptionにて実験。単語に対するローカライズの精度は良い印象だが、キャプショニングの場合の精度は微妙。

コネクトミックという神経の分野におけるセマンティックセグメンテーションでは、エラーがたびたび発生する。これらのエラー部分を人間に提示し、マージとスプリットの候補を自動でクラシフィケーションする。CNNで自動セグメンテーションのエラーを学習することで実現。人間がYes/Noを判定する校正が基本だが、確率に閾値を設けることで自動構成モードにも切り替えられる。
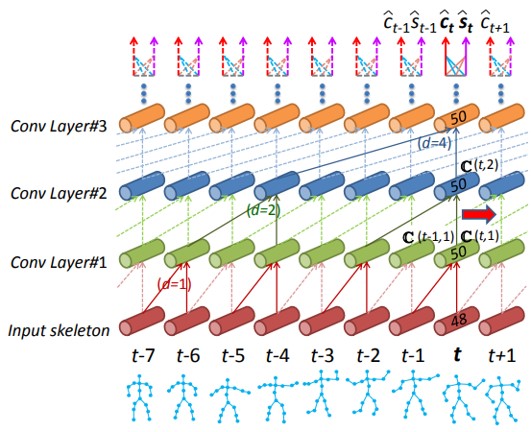
行動に対して、タイムステップごとにラベル付けをおこなう行動予測において問題視されるスケール変動や計算の効率化に着目している。スケルトンを入力とし、行動ラベルや行動開始時間を出力とする。
行動予測用データセットのPKU-MMDとOADにて実験し、従来手法と比較して高精度化を実証。

異なる時間に撮影された2つの画像や異なるモダリティを共通の座標系にマッピングする空間変換を再現しようとするタスクにおいて、2つの画像間の変換を記述するための最も適切なパラメータ化を学習することに焦点を当てたmulti-grid B-spline法を提案
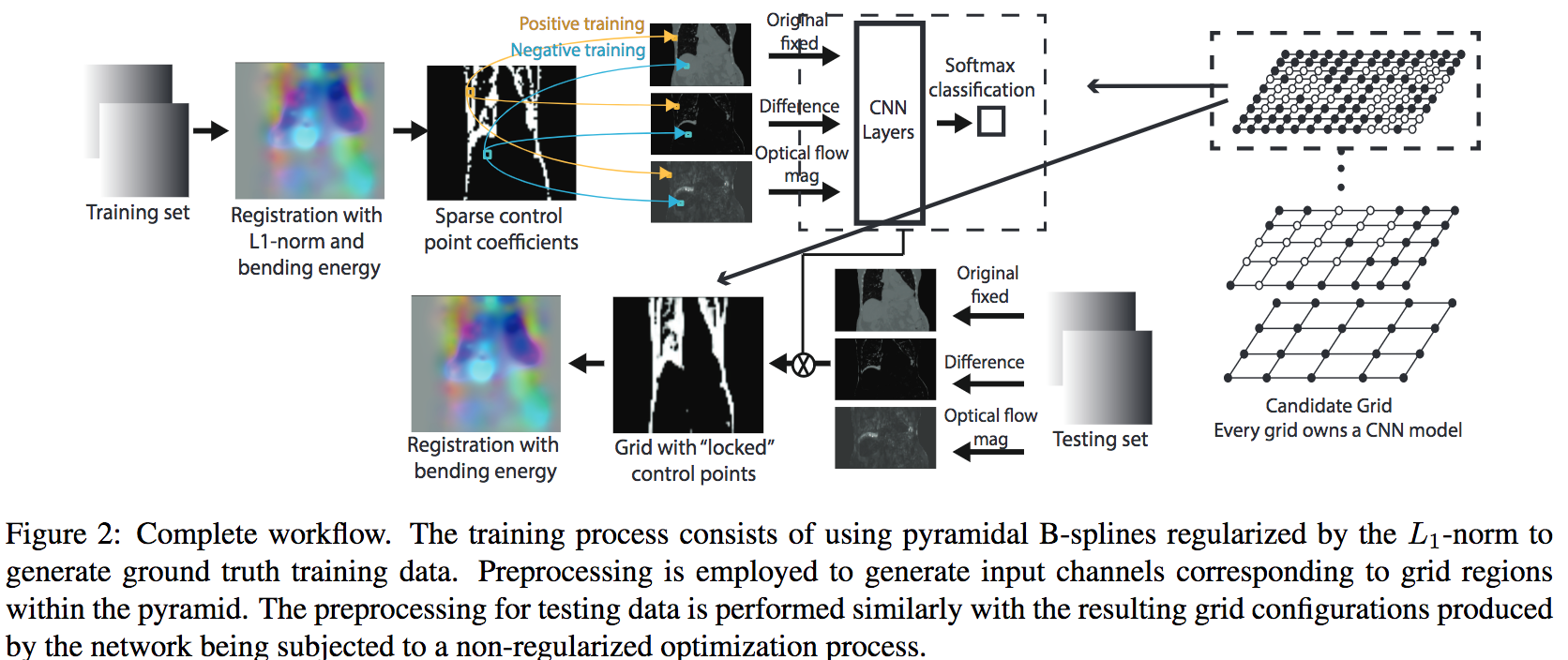
B-splineのパラメータを大幅に削減
複数枚画像の超解像といえば主に時系列画像で行われてきたが,本稿ではステレオで行う. このとき,それぞれのステレオで視差が異なるので, 視差の考慮が必要である. ステレオ画像から視差は計算できるが, これを基に超解像を行う従来法によるとサブピクセル精度が出せずジャギーが出てしまう.
本稿では,End-to-Endにステレオ画像から視差に基づくシフト量と高解像画像の出力を行うDNNを提案する.構造的には,YCbCrにして照度,カラー成分に分けて2段階で学習するNNを構成, 照度画像で,まずシフトを考慮した高解像照度画像を生成.片方の眼の画像のシフト画像を複数枚用意し, もう片方の眼の画像と併せてCNNに入力. 出力の高解像照度画像と,低解像のカラー成分画像からCNNで高解像カラー画像を最終的に出力する.
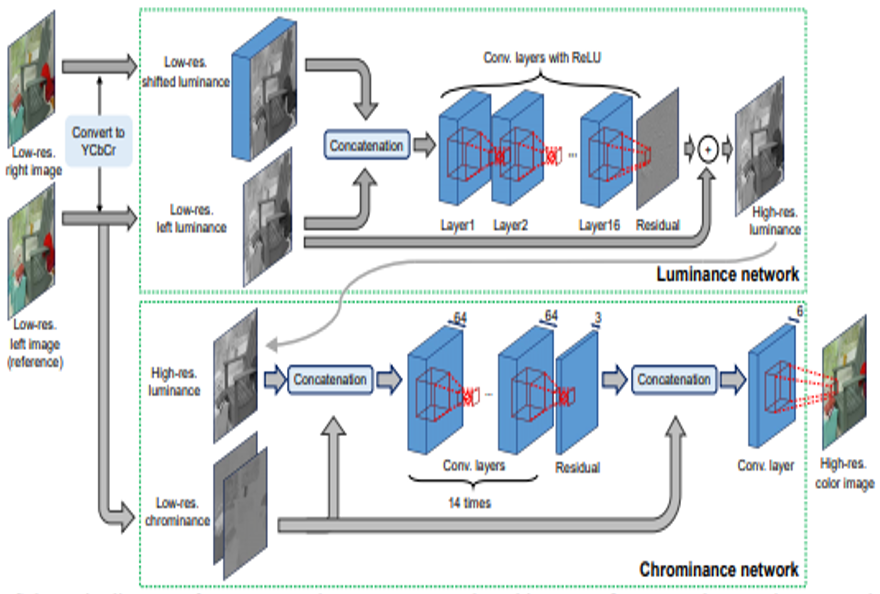
従来のステレオベース手法よりなめらかな高解像画像が出力できている.PSNRでよりよいスコアをマーク.シフト量,シフト画像の枚数についても議論.
テクスチャセグメンテーションにおいて,それぞれのテクスチャ領域において照明条件などの条件に不変な特徴を取りたいが,その時にテクスチャの領域のセグメンテーションがされていないとテクスチャ間の特徴が混ざってしまうという,鶏と卵問題がある.
本研究では,Shape-Tailored Descriptorを提案.様々なスケール,任意の形状領域での向き付き勾配の基本特徴を弁別するNNを学習する. この特徴表現はROIにおける偏微分方程式により定義される. 学習したメトリックにより基本特徴を弁別することで,結合最適化問題の定式化及び最適化を行う. これは学習した特徴のグルーピングで行われる.
形状もちゃんと考慮された領域の特徴抽出を一つの枠組みで提供できている.
入力画像をいくつかのグループに分けて、何百万枚のスケールでglobal SfMを行った。最初に入力画像を相関に基づいて複数のパーティションに分割する。次に、パーティションごとに回転や並進といった変換を求めてから全体の最適化を図り、パーティションの境界を明確化したり、1つの座標系ですべてのカメラを表せるようにした。最後に収束するまで部分最適と全体最適をを繰り返す。
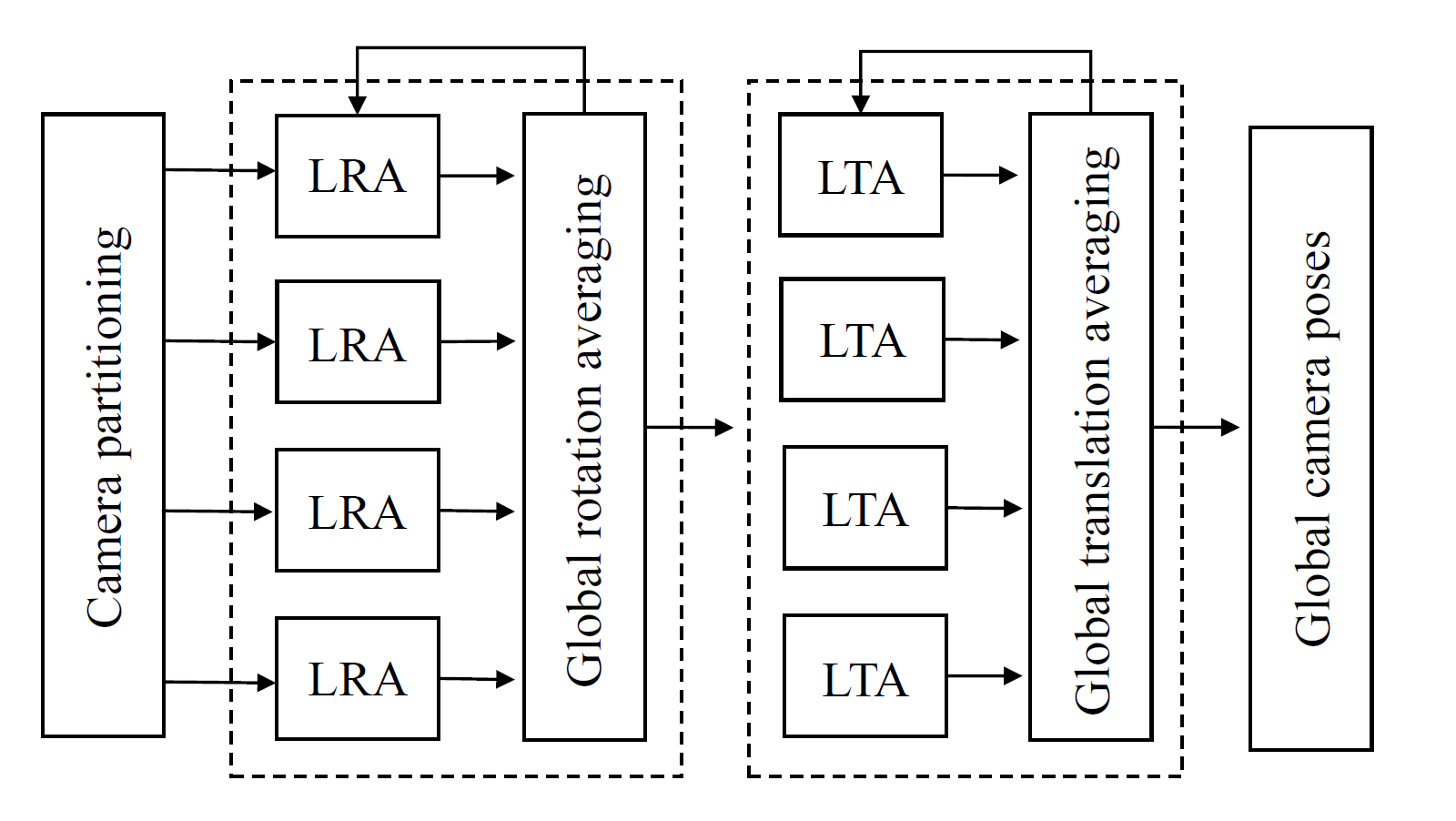
従来手法より多い数百万の入力画像でglobal SfMを行えるようにした入力画像が増加した場合に全体最適化で生じるメモリーの飽和を部分最適化を用いることで回避できるようにした
コンテキストはサリエンシー検出タスクにおいて重要な役割を果たす.しかし与えられたコンテキスト領域において,全てのcontextual informationが役に立つわけではない.この研究では,ピクセルごとにinformative context locationを選択的に関与することを学習するため,新たにピクセルワイズなcontextual attention network(PiCANet)を提案する.これにより,ピクセルごとにattention mapを生成することができる.
![]()
PiCANetにより,サリエンシー検出のパフォーマンスが向上すること確認した.グローバルおよびローカルのPiCANetは,全体的なコントラストと均質性の学習を容易にする.その結果サリエンシーモデルは,物体をより正確かつ均一に検出することができ,SOTA手法に対して有効に機能する.
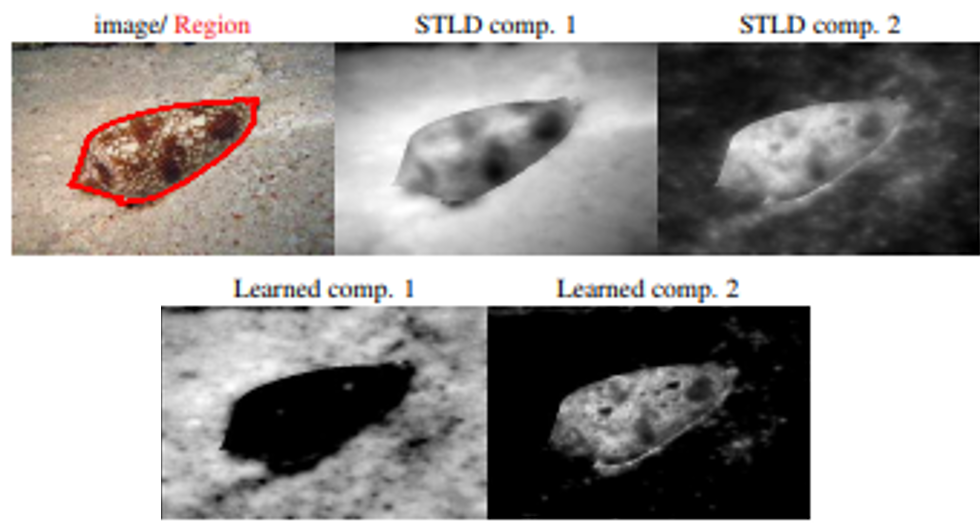
CNNのパラメータが多いため,データセットのサイズが小さいと過学習するという問題がある.この研究ではこの問題を解決するため,SSF-CNNを提案する.これは,フィルタの構造と強度を学習することにフォーカスすることにより,CNNのパラメータ数を減らすことができるという方法である.ここでフィルタの構造は,辞書ベースのフィルタ学習アルゴリズムを使用して初期化され,強度は小さなサンプルトレーニングデータを用いて学習される.これによりアーキテクチャーは,小規模および大規模のトレーニングデータベースの両方を使用した柔軟なトレーニングを提供し,小規模のトレーニングデータでも優れた精度を実現することができる.
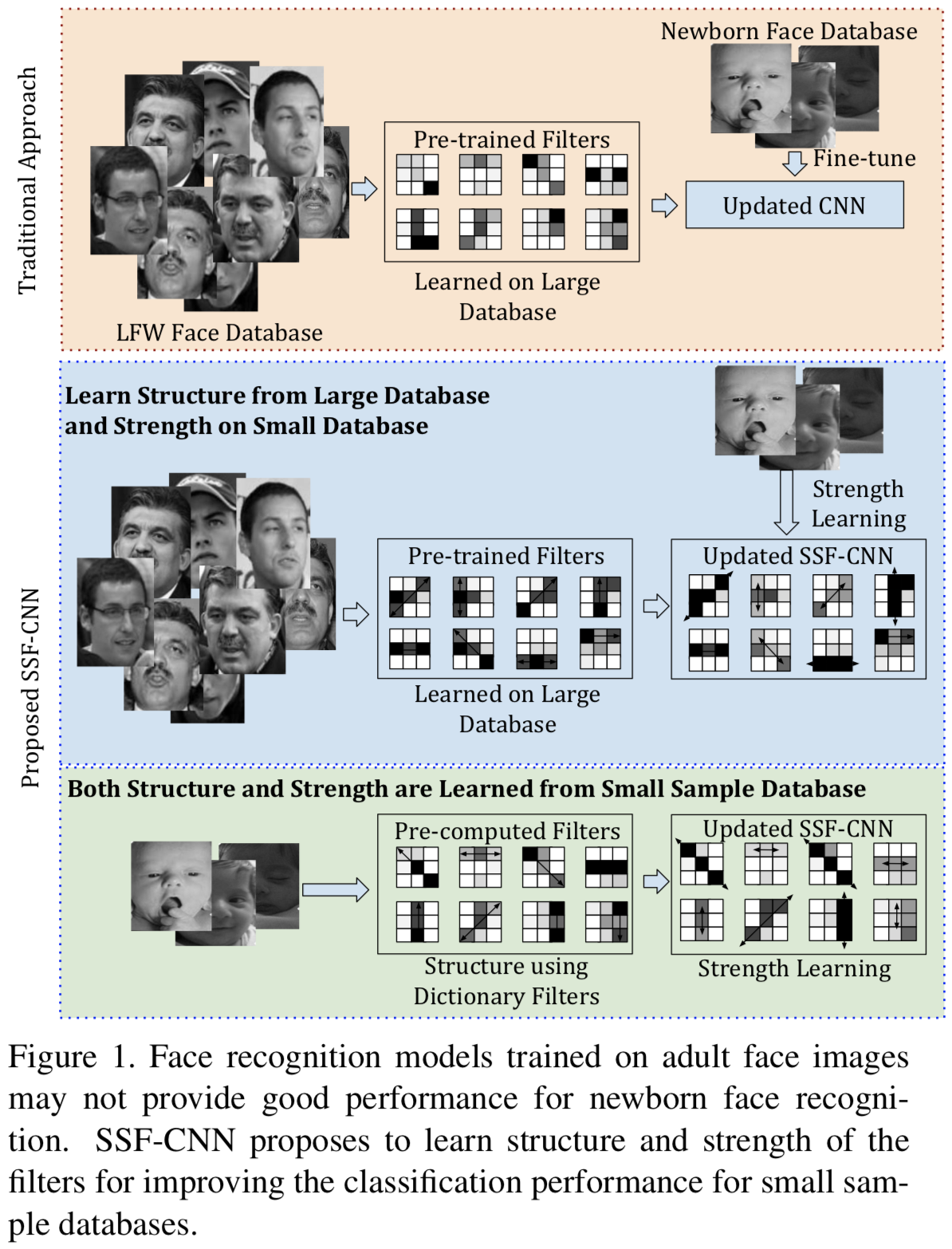
このアルゴリズムの効果を確認するため,はじめにMNIST,CIFAR10とNORBのトレーニングデータ数を変化させながら実験を行った.その結果,SSF-CNNはパラメータの数が減少することを確認した.次にデータセットのサイズが小さいIIITD Newborn FaceとOmniglotを用いて実験を行ったところSOTAな結果を得ることができた.
未知クラスのラベル付きサンプルの必要性を回避するため,画像ではなくCNN特徴量を生成するGAN(f-CLSWGAN)を提案する.クラスレベルのセマンティック情報で条件づけることにより,よりリッチなCNN特徴空間を生成することができるとのこと.
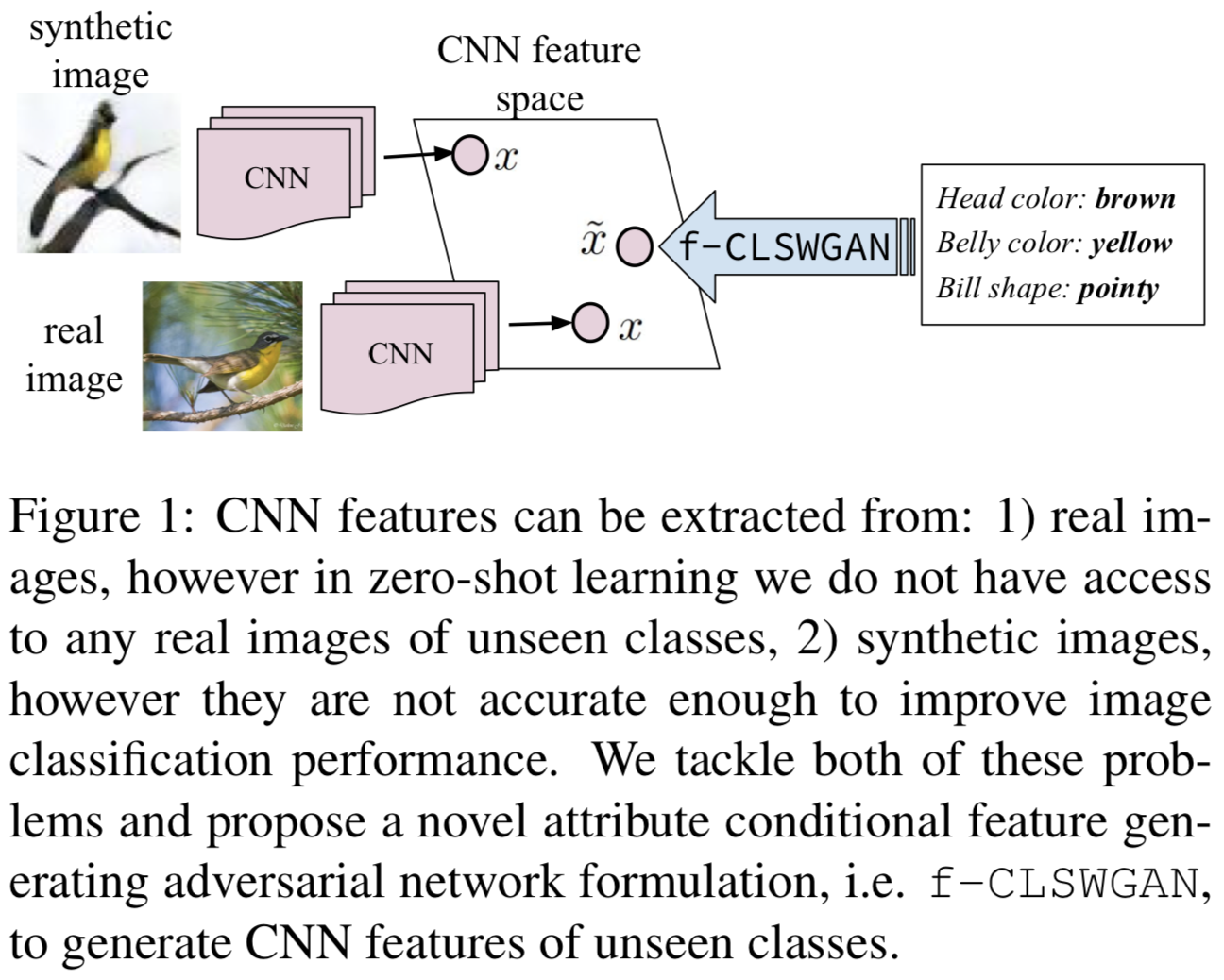
ZSL, GZSLの両方の問題設定において,CUB, FLO, SUN, AWA, ImageNetを用いて実験を行ったところ,提案手法によりSOTA手法の精度が向上した.
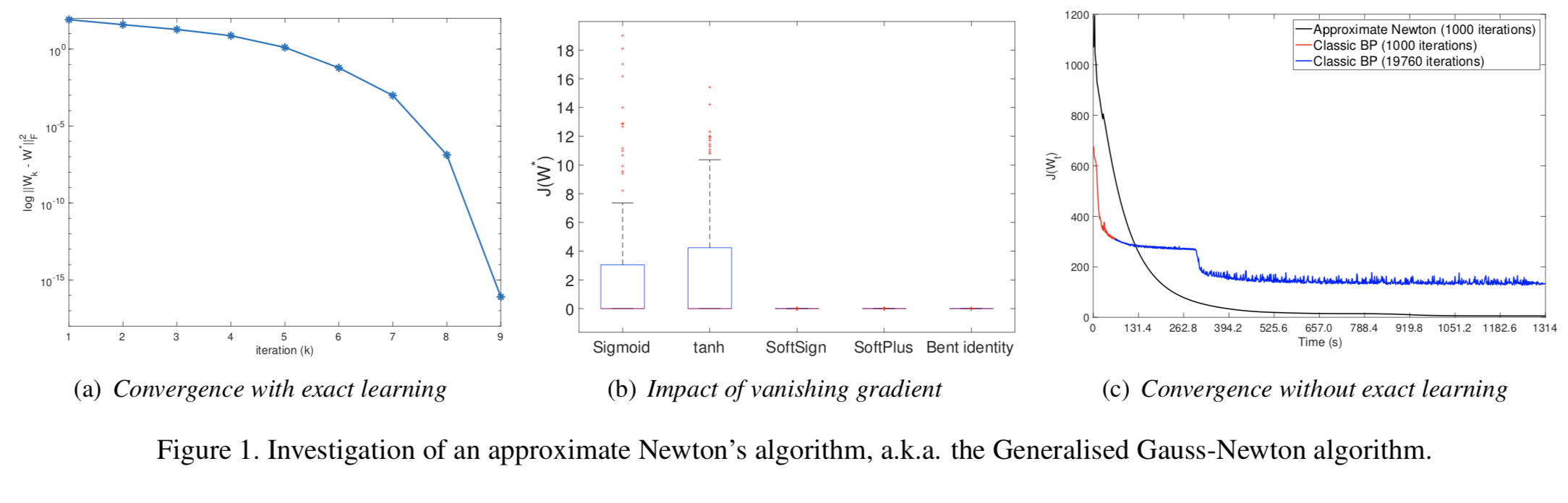
smooth optimisationの観点から、多層パーセプトロンに対する数学的な考察を行なった論文。DNNの学習の際に最もよく使われるアルゴリズムであるバックプロパゲーションは局所最適解に収束する可能性があることと、収束が遅いことが問題視されている。本論文ではロス関数のcritical point(停留点)に対する解析を行うことで、局所最適解に収束することなく帯域最適解に収束する条件を確認。また、より速くネットワークの学習を収束させるために、ヘッシアンに対する解析や、帯域的最適解に二次収束するという点でapproximate Newton’s algorithmと呼ばれるGeneralised Gauss-Newtonアルゴリズムを用いた学習による評価を行なった。
ランダムな3D方向、位置、およびスケールを有する3Dボリューム自然物体の断層を投影された2D画像から推定する3D-POPの提案
従来手法(SPR)よりスケール変化による推定誤差が少ない
MRFにおけるMAP推論の非凸連続緩和法においてADMMに基づく多重線形分解フレームワークを使用し、より効果的な解を求める手法を提案
最先端のMRF最適化アルゴリズムと比較し、変数と制約の数が少ないため、メモリ効率が良い。また、高度に並列化可能なため,分散アプリケーションやリアルタイムアプリケーションにも適している。

・ Light Field Blind Motion Deblurring (LF-BMD)を低次元の部分問題に分解できるMDFベースのブレ軽減手法の提案
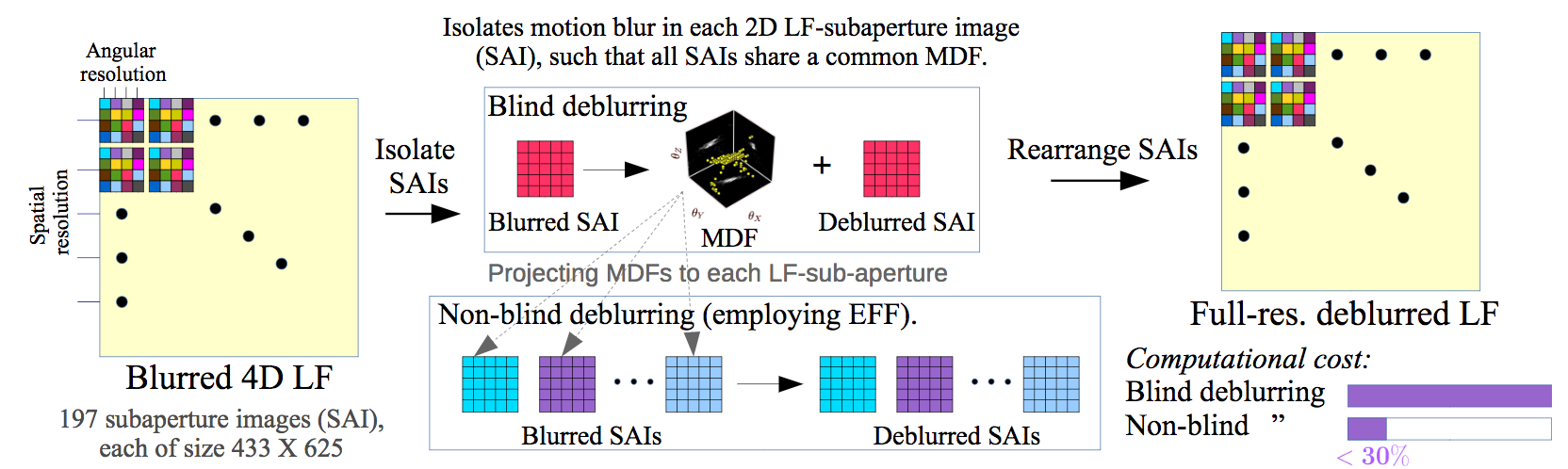
・最先端の手法と異なり、現実的にレンズの屈折効果を捕らえ、広角のアングルや不規則な撮影者の動き対しても適用可能・並列処理可能なアルゴリズムのためGPUなどの並列処理可能
透視投影カメラ画像上の消失点,消失線に関する議論は多く行われてきたが,反射屈折カメラ画像上での消失点,消失曲線を表現する解析的モデルの開発は行われてきていなかった. 反射屈折カメラ画像上では,一つの消失点から発生する平行曲線は別の消失点に再度収束するというところが透視投影カメラ画像のものとは異なる.
そこで,カメラのキャリブレーションパラメータ,鏡形状係数,3D空間の平行線の方向ベクトルのパラメータを用いた パラメトリック方程式を提案. 鏡面は軸対称二次曲面で表現.それを透視投影カメラが観測するような光学モデルのもと,定式化.

今まで行われてこなかった反射屈折カメラにおける消失点・消失曲線のパラメトリック解析手法を与えた.
歩行者ごとで隣接フレーム間の変位を逐次予測するCIDNN(Crowd Interaction Deep Neural Network)を提案.群衆による歩行者の影響のレベルをLSTMによって重み付けをし,従来の手法に比べ, 対象の歩行者への空間的親和性の重要度を高くしている. 提案手法は以下を可能にし公的に利用可能なデータセットにおいて高精度な軌道予測を実現した.

追加のアノテーションやドメイン知識なしに、disentangleな変動要因からなる表現をunsupervisedに学習することが目標。disentangleな変動要因とは、物体の姿勢や色など画像に渡って一貫して識別できる画像特徴に対応する要因のこと(ここではfeature chunkと呼ぶ)。この論文のポイントと提案手法は次の項目。1)disentangleな変動要因表現は、feature chunkの連結によって構成されるということ。2)autoencoderを利用し、不変的な画像属性とfeature chunkをencodeとdecodeすることを促進する目的関数、3)変動要因を見分けられ、各feature chunkが一貫性を持つ表現を確実にするために分類制約したこと。
前述の2)に関して、図のようなmixing autoencoderとadversarial learningを組み合わせたことが新しい。encoderとdecoderが(画像全体を表現するのに十分であれば)ただ一つのfeature chunkで表現できてしまう問題(shortcut problem)を分類制約を加えることで回避したことも新しい。

現在の水中画像形成モデルでは無視されていたより多くの依存関係を実際に導入することにより,画像補正を行う.
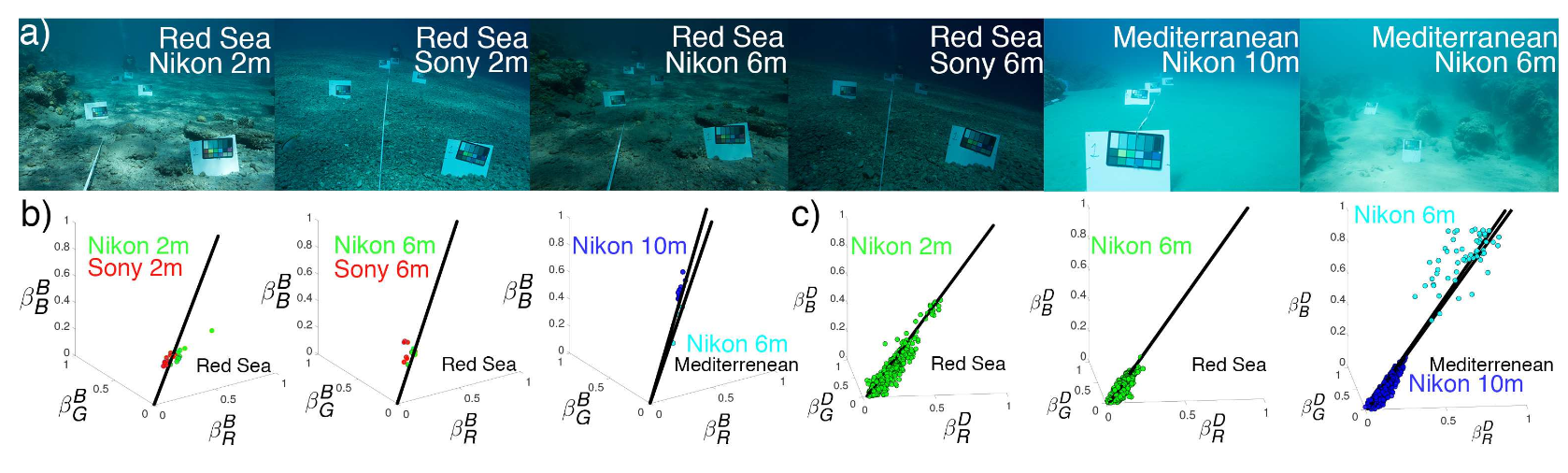
理論的分析と現実世界の実験を通して、一般的に使用される水中画像形成モデルがこれまで説明されていなかった誤差を生じることを実証した。
一般的なMRF-MAP問題はNP-hardだが、ポテンシャル関数がsubmodularのとき、多項式時間で解くことができる。この式を解くためには、フローベースのアプローチと多面体ベースのアプローチがある。その2つのアプローチを組み合わせるフレームワークを提案

Generic Cuts やSOSMNPのようなアルゴリズムを組み合わせることの有効性を確立
適度に歪んだレンズの画像であっても,,ピンホールカメラモデルを使用した平面補正は不正確または無効である.提案するソルバーは,カメラモデルにレンズ歪みを組み込み,精密な整流をワイドアングル画像に拡張する.これは現在コンシューマカメラにおいて一般的である.ソルバーは,放射状のレンズ歪みのための分割モデルと統合された,撮像されたシーン平面の共役変換によって誘発される制約から導かれる.理想的な彩度を持つ隠れ変数のトリックを使用して制約を再定式化し,Gröbner法で生成されたソルバーが安定し,小さくて速くなるようにする.
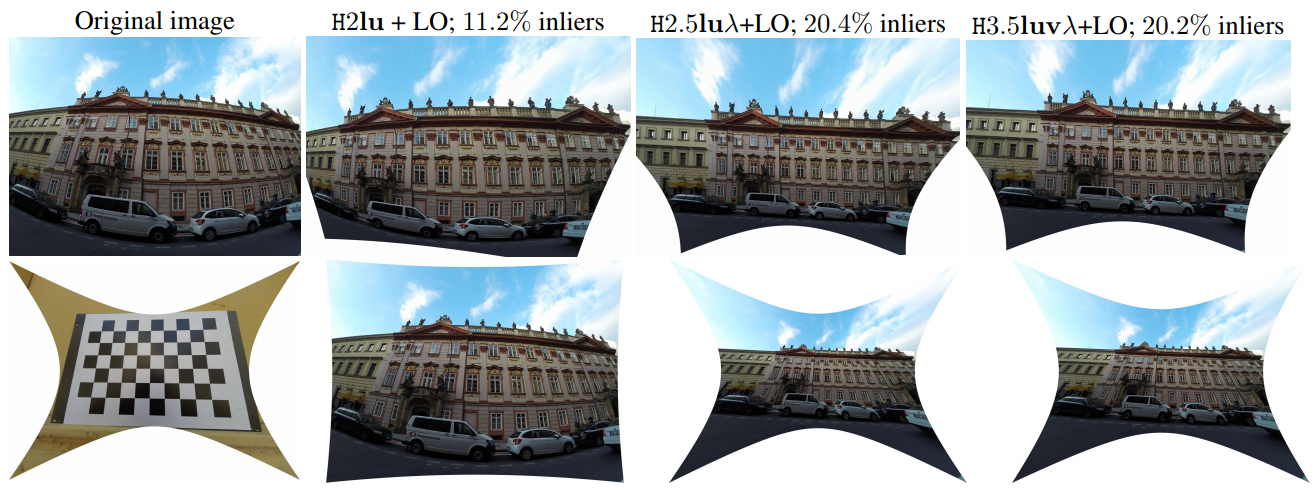
整流およびレンズ歪みは,共役的に翻訳されたアフィン - 共変動特徴または2つの独立して翻訳された類似共変動特徴のいずれかから回復される.提案されたソルバーはRANSACベースの推定器で使用され,少数の反復後に正確な整流が行われる.提案されたソルバーは最先端技術に対して評価され,ノイズの多い測定で大幅に改善された整流を表現する.
合成実験では,最先端技術と比較して,提案されたソルバーの整流精度およびレンズ歪み推定の測定に関して,良好な安定性およびノイズに対する優れた堅牢性を実証した.しかしながら,分割モデルによって歪められた共役変換から生じる多項式制約式は,安定したソルバーを生成するために隠れ変数トリックで変換される必要がある,定性的な実像実験では,高度に歪んだ広角レンズのための高品質の整流を表現した.
RGBイメージングからのハイパースペクトル再構成は,疎なコーディングと深い学習を経て著しい進歩を遂げているが,既存のRGBカメラが人間の三色知覚を模倣するように調整されているため,それらのスペクトル応答はハイパースペクトル再構成に必ずしも最適ではない.この論文では,RGBスペクトル応答を使用するのではなく,(ハードウェアで実施される)最適化されたカメラスペクトル応答関数と,エンドツーエンドネットワークを使用するスペクトル再構成のためのマッピングとを同時に学習する.
私たちのコアアイデアは,カメラスペクトルフィルタが畳み込み層のように効果的に作用するから,標準的なニューラルネットワークを訓練することによって,それらの応答関数を最適化することができる.我々は,空間モザイク処理を用いない3チップ構成と,Bayer形式の2×2フィルタアレイを用いた単一チップ構成の2種類の設計されたフィルタを提案する.数値シミュレーションは,既存のRGBカメラと比較して深く学習されたスペクトル応答の利点を検証する.
深い学習手法を用いて非負の無限大空間におけるフィルタ応答関数を学習する方法を示した.特殊な畳み込みレイヤーをU-netベースの再構成ネットワークに追加し,3つの独立したフィルタとBayerスタイルの2x2フィルタアレイの形で、標準RGBレスポンスより優れた応答関数を確認できた.実際のマルチスペクトルカメラを構築するために,CCDカメラの応答を設計プロセスに組み込んだ.2つのフィルタをうまく設計/実装し,スナップショットハイパースペクトル画像のためのデータに基づいたバイスペクトルカメラを構築しました.
深い畳み込みネットワーク(ConvNets)は,多くのコンピュータビジョンタスクで前例のないパフォーマンスを達成しているが,単一の画像を集める集団への彼らの適応はまだ未熟な状態であり,過度の過度のフィッティングに苦しんでいる.ここでは深い負の相関学習(NCL)によって一般化可能な特徴を生成する新しい学習戦略を提案する.より具体的には,本質的な多様性を管理することによって,健全な一般化能力を持つ無相関回帰変数のプールを深く学習する.
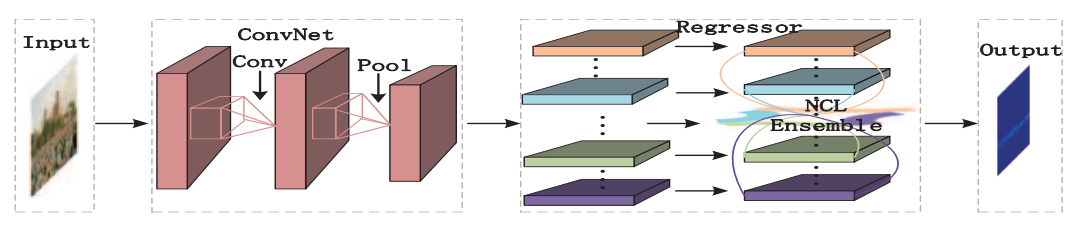
無相関ConvNet(D-ConvNet)という名前の提案方法は,エンドツーエンドで訓練可能であり,バックボーン完全畳み込みネットワークアーキテクチャから独立している.非常に深いVGGNetとカスタマイズされたネットワーク構造に関する広範な実験は,いくつかの最先端の方法と比較した場合のD-ConvNetの優位性を示している.
Decorrelated ConvNet(D-ConvNet)と名付けた提案方法が,固有の多様性を管理することによって健全な一般化能力を有することを示している.DConvNetは,一般的であり,バックボーン完全畳み込みネットワークアーキテクチャから独立している.非常に深いVGGの広範な実験や,いくつかの難しいデータセットでカスタマイズされたネットワーク構造がD-ConvNetの優位性を実証した.
トーンマッピングは,視覚情報が保存された高ダイナミックレンジ画像から標準ダイナミックレンジ画像を再現することを目的とする.最先端のトーンマッピングアルゴリズムは,主に画像を基本レイヤーと詳細レイヤーに分解し,それに応じて処理する.本論文では,これらの問題に対処するハイブリッドl_1−l_0分解モデルを提案する.我々はさらに,我々の層分解モデルに基づいてマルチスケールトーンマッピングスキームを提案する.
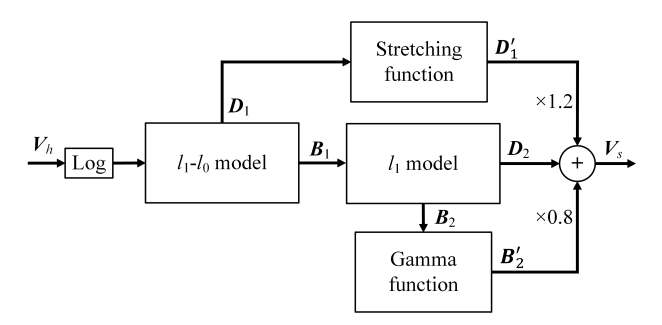
最先端のトーンマッピングアルゴリズムは,主に画像を基本レイヤーと詳細レイヤーに分解し,それに応じて処理します.これらの方法は,2つの層に課せられた適切なプリヤの不足のために,ハローアーティファクトおよび過度の増強の問題を有する可能性がある.本論文では,これらの問題に対処するハイブリッドl_1−l_0分解モデルを提案する.具体的には,基底層には,その区分的な平滑性をモデル化するために,1つの希薄項が課される.ディテールレイヤーには構造優先として「0」の希薄語が課され,これは区分的に一定の効果をもたらす.我々はさらに,我々の層分解モデルに基づいてマルチスケールトーンマッピングスキームを提案する.
古典的なD-ConvNetは,パラメータの数の増加を防ぐために,徐々に分解能を低下させるか,手作業で拡張した畳み込みを適用することによって受容野のサイズを増加させる. 本論文では,手作業を必要としない新しい変位型集約ユニット(DAU)を提案する.固定された規則的なグリッド上に配置された単位(ピクセル)を有する古典的なフィルタとは対照的に,DAUの変位が学習され,フィルタが受容野を所与の問題に空間的に適応させる.通常のフィルタを備えたConvNetsと比較して,DAUを備えたConvNetsは,より速いコンバージェンスと,パラメータの最大3倍の低減で同等の性能を実現します.
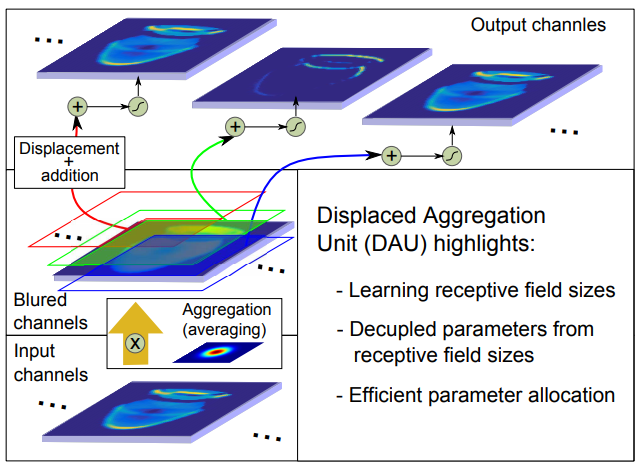
分類およびセマンティックセグメンテーションタスクでDAUの強さを広範に実証している.通常のフィルタを備えたConvNetsと比較して,DAUを備えたConvNetsは,より速いコンバージェンスと,パラメータの最大3倍の低減で同等の性能を実現する.さらに,DAUにより,斬新な視点からDeepNetWorkを研究することができる.DAUフィルタの空間分布を研究し,フィルタ内の空間カバレッジに割り当てられるパラメータの数を分析する.
フィルタごとのパラメータ割り当てに関する包括的な調査では,既存のConvNetsのパラメータの非効率的な割り当てが示された.DAU-ConvNetsは従来のCovnNetsに匹敵する性能をフィルタ当たり3倍少ないパラメータで達成した.分析によれば,増幅係数が最も低いユニットを除去することで,性能を犠牲にすることなくパラメータの10%を節約することができるため,さらなる改善の余地があることがわかる.さらに,完全に接続されたレイヤにDAUを適用するための最近の予備的な作業は,完全に接続されたレイヤのパラメータの節約も可能であることを示している.
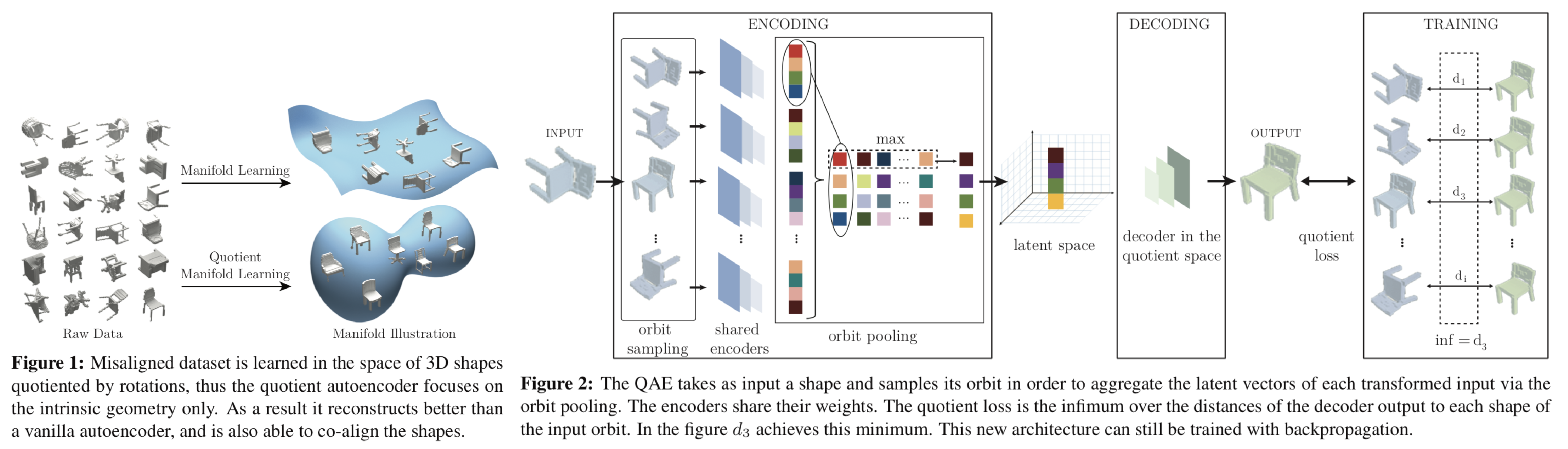
3D shapeを学習する際にposeに独立なgeometryの潜在変数空間を学習するネットワークであるquotient autoencoder(QAE)を提案。通常のAEに加えて、orbit poolingとquotient lossという2つのアイディアを追加した。orbit poolingでは、入力された3D shapeに対して様々な回転を与えそれらから得られる潜在変数のうち、各成分の最大値をその3D shapeを表現する潜在変数とする。quotient lossでは、リコンストラクションされた3D shapeと参照3D shapeの距離の下限をロスとして採用する。この2つの方法によってposeに不変な潜在変数空間を構築する。
本稿では,かすんでいる画像から鮮明な画像を復元する手法を提案する。既存の手法では伝送マップおよび大気光を推定するために,例えば暗いチャネル,色の視差,最大のコントラストといった手作りの特徴を使用することが多い。本稿ではこの問題を条件付き生成的対立ネットワーク(cGAN)に基づいて解決する。ここで,鮮明な画像は,end-to-endの訓練可能なニューラルネットワークによって推定される。基本的なcGANの生成ネットワークとは異なり,本稿ではより良い結果を生み出すことができるように,エンコーダとデコーダのアーキテクチャを提案する。
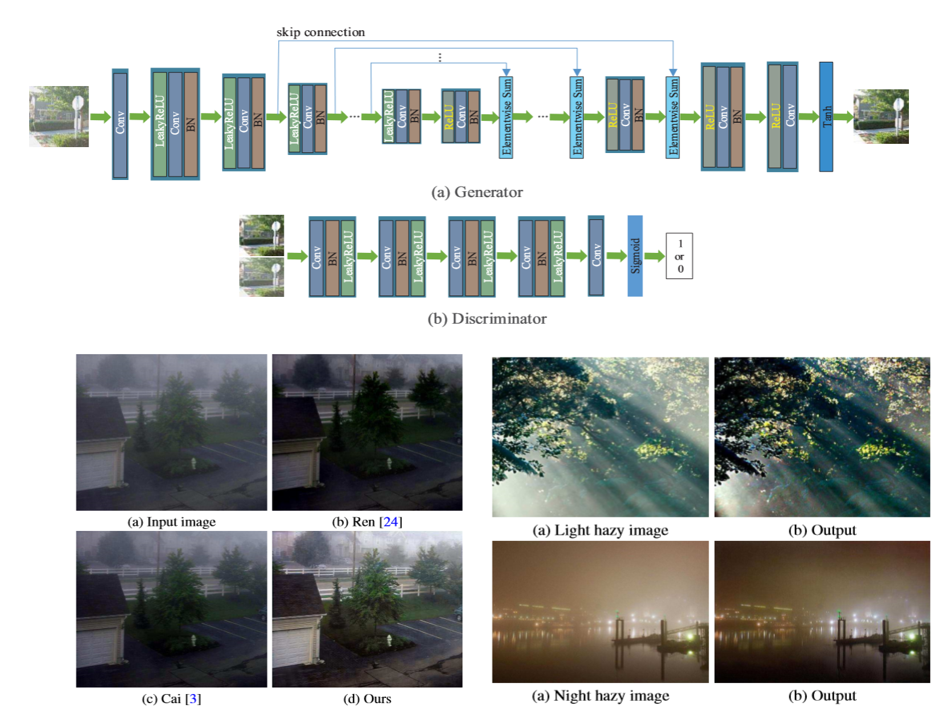
・条件付きGANを用いることにより,かすんでいる画像から鮮明な画像の生成を実現している。・鮮明な画像を生成するためにVGGフィーチャとL1正規化勾配を事前に導入することによって,基本のcGANフォーメーションをさらに修正している。
本稿では高次元のデータと畳み込みニューラルネットワーク分類機を用いたアクティブ学習から最近提案されたいくつかの手法の検討をする.モンテカルロドロップアウト手法と幾何学手法に対してアンサンブルベースと比較する. MNISTとCIFAR-10の結果を示し,約12,200個のラベル付き画像で90%のテストセット精度を達成し,ImageNetで初期結果を得た.
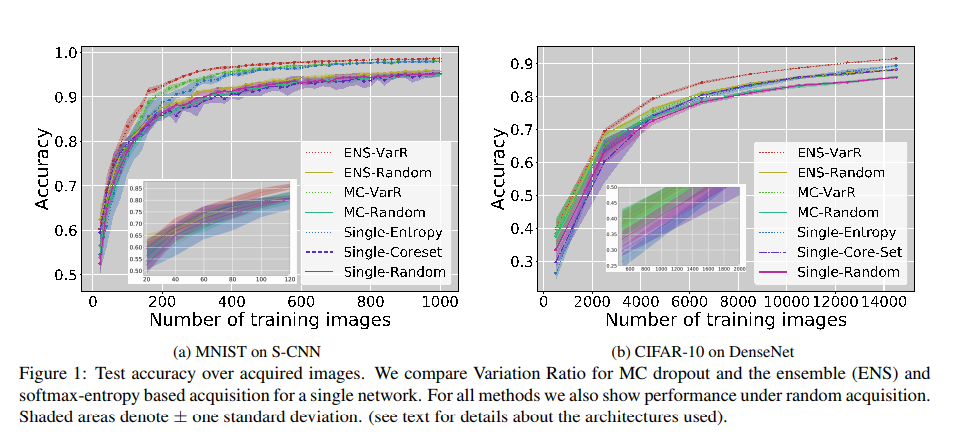
アンサンブルベースの不確かさは,他の不確かさ推定方法(特にMCドロップアウト)よりも一貫して優れていることを示し,MNISTとCIFAR-10の最先端のactivity learningパフォーマンスにつながる.
凸緩和を介して複数の幾何モデルを複数の構造データにフィッティングするための新しい方法を提案.COnvex Relaxation Algorithm(CORAL)を用いて多次元データを適合させ、セグメント化するための新しい最適化を行う.復ごとに同等のアーキテクチャで2桁の速さで最小化されるため、より多くの幾何学的マルチモデルフィッティング問題にリアルタイムで堅牢なパフォーマンスを得た.
既存のテキストの認識手法は,検出と認識を別のタスクとして扱う物が多い,しかし,本研究では,同時に検出と認識をするためのend-to-endで学習可能なFast Oriented Text Spotting(FOTS)を提案する.ICDAR 2015、ICDAR 2017 MLT、およびICDAR 2013を用いた文字の検出,識別の評価実験では既存の手法と比較してSoTAであった.

一組のイメージカーブを用いて,3D直線に対応するという知識に基づき単一画像内のRS歪みを補正するロバストな方法を提案.一様な運動モデル下で移動するローリングシャッターカメラによって出現する3D直線の投影のためのパラメトリック方程式を定式化し,少なくとも4つのイメージカーブを用いて,姿勢パラメータとは別にカメラの角速度を効率的に推定する方法を提案.さらに,3D直線に対応するイメージカーブを選択し,3次元での実際のイメージカーブを選択するRANSACのような戦略を提案.

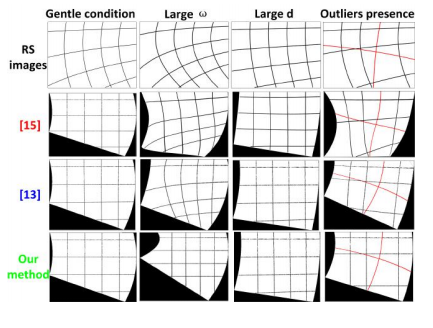
・ 合成データと実データの両方を用いた比較実験によりstate-of-the-art.
高次のMRF(Markov Random Field)によるトランスダクティブ推論のための新しいアルゴリズムの提案.MRFでは単項式のエネルギーは可変分類器によってパラメータ化され,連続的な分類子のパラメータと離散的な変数の共同最適化問題として提起される.問題解決のために,凸緩和などの従来手法と対照的にADMM(Alternating Direction Method of Multipliers)での効率的な最適化手法として関連目的関数を離散的かつ連続的な問題に切り離すことを提案.離散変数の完全性を保ち,臨界点への大域収束性を保証している.

・ MAPの推論問題の準最適解を得ることができ,計算上より困難なMRFを考慮することが可能.・ k-meansと対照的に深層特徴と統合される ・ 従来手法より一貫した結果となり,ランタイム,メモリ消費について効率的.
画像歪みに対するCNNの頑健性を改善する研究.特徴分布の高いモーメント統計は画像の歪みによってシフトする可能性があり,性能低下につながる.この効果を低減するために,特徴量の量子化によるアプローチを提案.1)スケーラブルな分解能を持つ床関数,2)学習可能な指数を持つ累乗関数,3)データ依存指数を用いた累乗関数の3種類の非線形関数をCNNに採用.
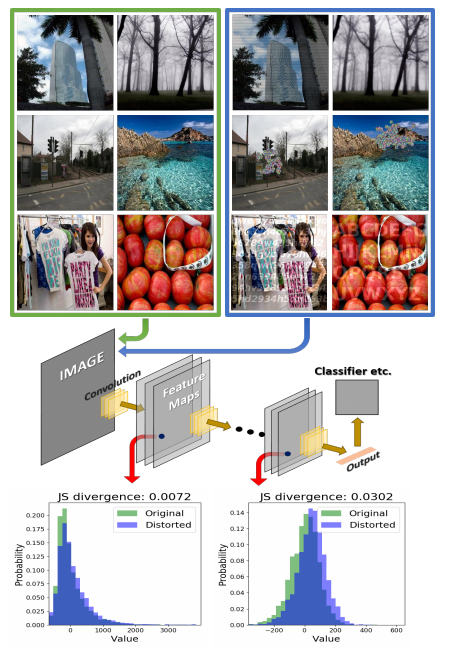

・ 提案手法を用いたResNet-50でモーションブラー,ごま塩ノイズ,それらの複合の歪みで歪んだ画像を用いたILSVRC-12分類タスクでそれぞれ6.95%,5.26%,5.61%の精度向上.
多視点での車両の再識別問題を解決するために,視覚情報のみを用いたViewpoint-aware Attentive Multi-view Inference(VAMI)モデルを提案.VAMIは,任意の視点の車両画像を与えると,入力画像毎に単一視点の特徴を抽出し,その特徴を可変多視点の特徴表現に変換する.また,異なる視点で重要となるコア領域を選択し,敵対的学習で効果的なマルチビューの特徴推論を実装するため,視覚的なアテンションモデルを採用.
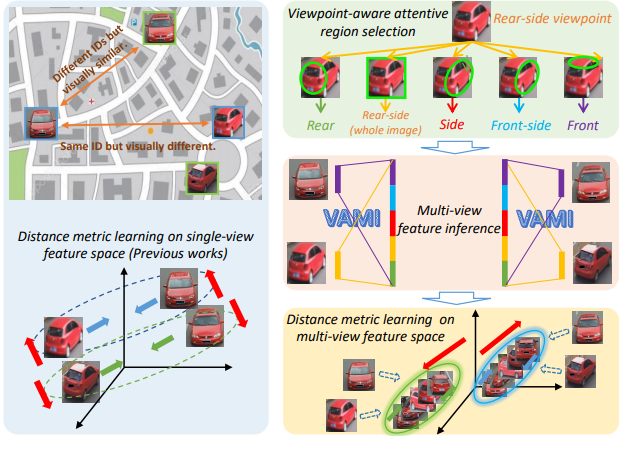
VeRiとVehicleIDの2つのデータセットでの車両の再識別についてstate-of-the-artよりも改善.
MOVIE graphsという新しいデータセットの提案.映画のクリップ中の社会的状況のグラフベースのアノテーションを詳細に行ったデータセットであり,各グラフは現在誰が写っているのか,感情や体格はどうか,複数人写っている場合の関係は,それらの間のインタラクションはといったさまざまなノードで構成されている.また,データセットの徹底的な分析を行い,時間経過とともにシーンの異なる社会的側面の興味深い常識的な相関関係を示す.グラフを用いてビデオとテキストを照会する方法として1)私たちのグラフは各場面をまとめて複数の意味的に関連する状況を取り出す方法,順序付けと理由の理解を通してインタラクションの理解のための方法を提案.
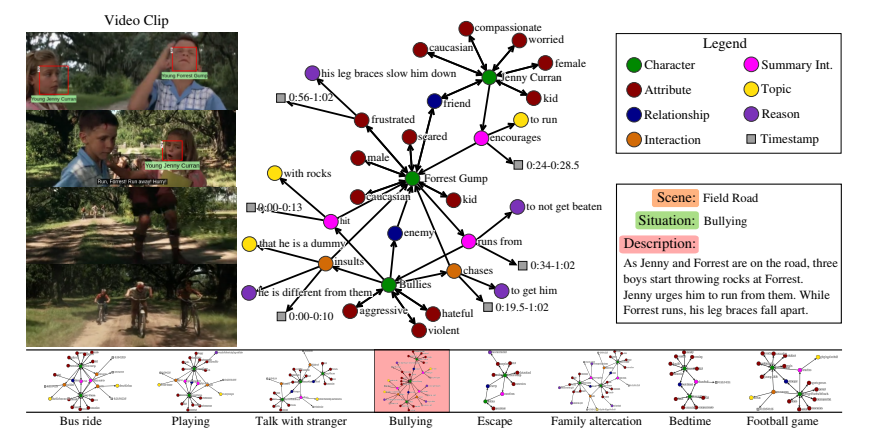
・ 人間中心の状況の推論された特性に焦点を当てた最初のベンチマークである.・ 各クリップには,シチュエーションラベル,シーンラベル,および支援言語の説明がアノテーションされおり,視覚的かつ時間的に接地されている.グラフのキャラクターはクリップの中の顔のトラックに関連付けられ,ほとんどのインタラクションは発生する時間間隔に関連付けられる.
近似的最近傍探索法(Approximated Nearest Neighbor; ANN)をベースにした直積量子化(Product Quantization; PQ)手法を提案する。粗な量子化、直積量子化、回転行列、コードブック計算に量子化法を用い、OpenCL-FPGAを使用したIntel HARPv2プラットフォームにより実装する。
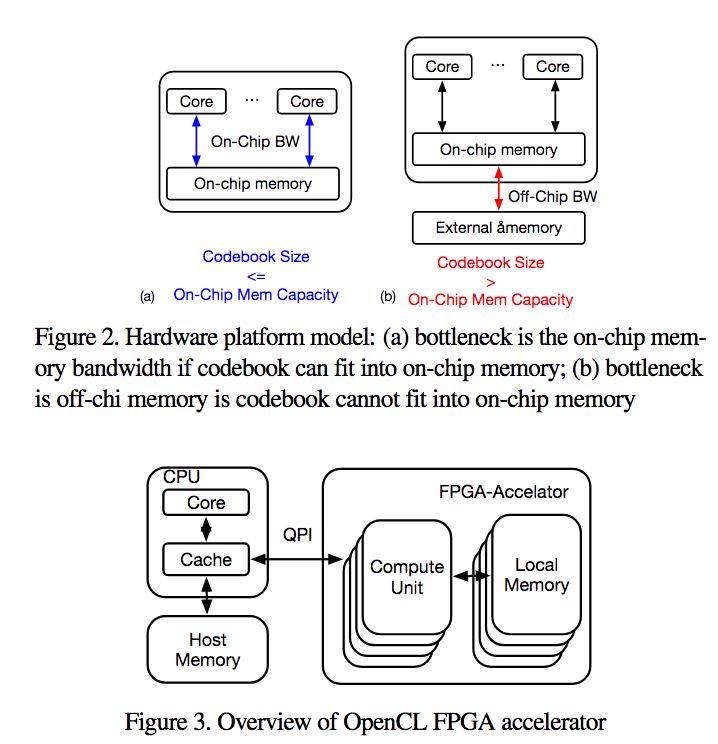
大規模かつ高次元のANNにおいて、FPGAによりCPU/GPUのパフォーマンスを越えることに成功した最初の例である。YFCC100M/BigANN/Deep1Bにおいて検証を行なった。
ビジョンベースの慣性ナビゲーションシステム(Vision-aided Inertial Navigation Systems; VINS)に関して、低コストなステレオビジョンを提案する。通常は2カメラを用いるが、計算的なコストやレイテンシが問題になってしまう。Left-Rightカメラの代替として、片方のカメラのみでカメラ姿勢を推定、もう一方のカメラにより補間を行い、最後にスケール問題を解決。右図のように交互にアクティブなカメラを切り替えて探索を行う。
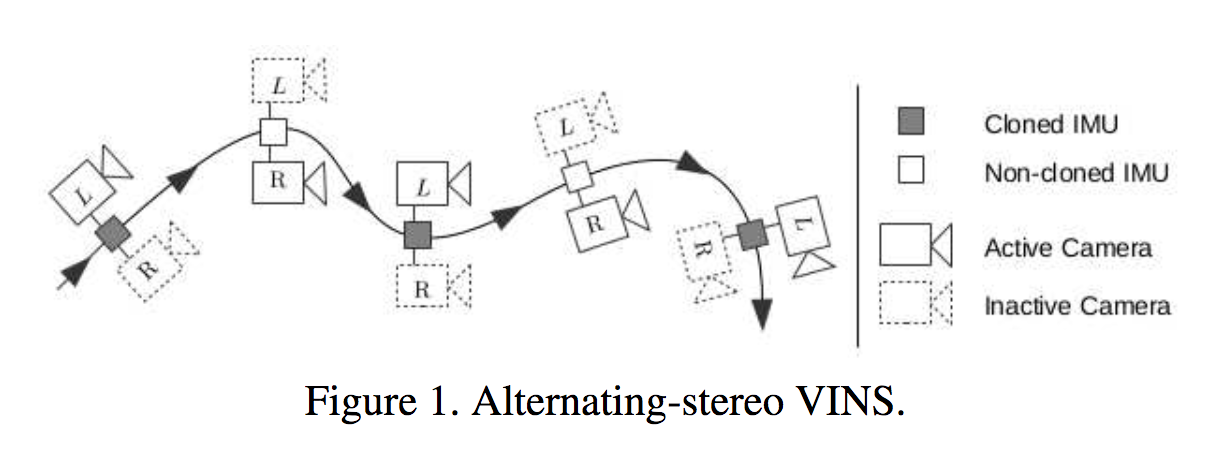
Low-latencyなステレオのカメラを交互に切り替えて慣性ナビゲーションを行うalternating-stereo VINSを提案する。実際にシステムを構築して実験を行なったことも評価されている。
ふたつのネットワークの協調学習であるCoupled End-to-End Transfer Learning(CETL)を提案、デコーダのパラメータを共有して対象ドメインに関してデータが少ないという転移学習の問題を改善する。さらに同ネットワークを最適化させるための誤差関数であるCoupledLossを提案した。ドメイン変換や知識蒸留でも使えることを示した。

転移学習の問題(事前学習には膨大なデータがあるが、対象データが少量)を解決するためのCETLを提案した。汎用フィッシャー情報を提案して複数タスクにおける最適化を実行した。
ハッシングに関するランキングを直接最適化、Average Precision(AP)やNormalized Discounted Cumulative Gain(NDCG)などにより評価できる手法について提案する。Intによるハミング距離をランキングし、AP/NDCGにより評価、勾配を最適化することによりCNNを学習する。ハミング距離による画像検索において新しいベースラインを作ることに成功した。
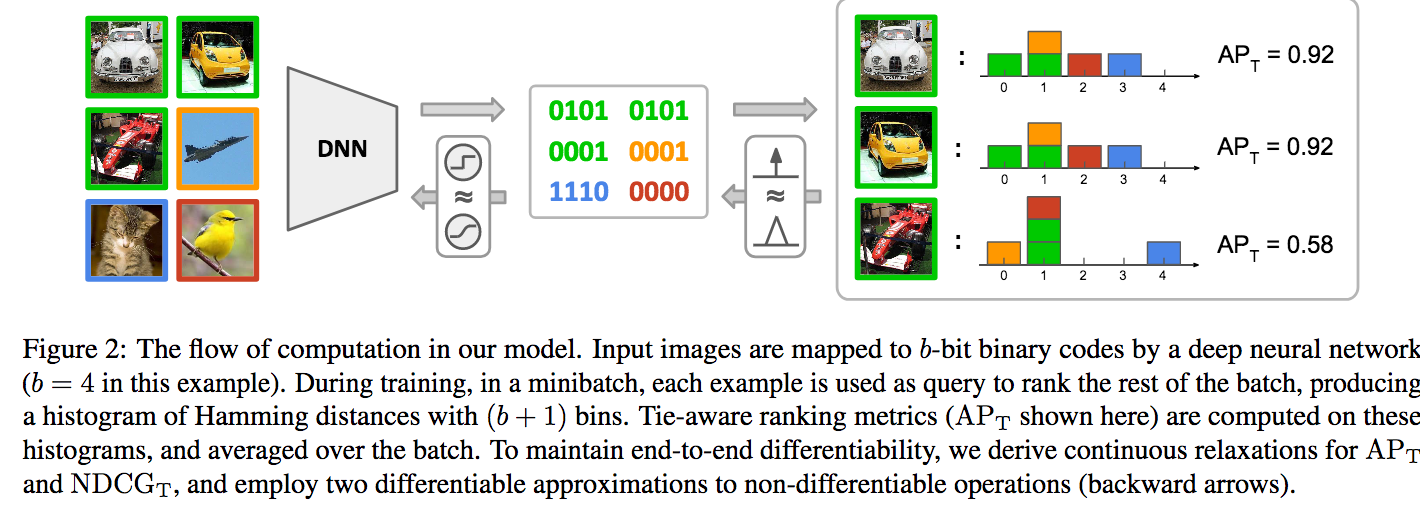
ハッシングによる最適化について、評価指標をダイレクトに誤差に用いることができるTie-aware Learningを提案し、画像検索問題に応用した。CIFAR-10,NUS-WIDE,LabelMe,ImageNet100において新しいベースラインを作った。
CVのアルゴリズムはカメラモーションやシーンにおける3次元構造など幾何的なロバスト推定を要することが多く、RANSACに頼ることも多い。本論文では単項式の選択により高速な多項式計算を実装するための方法について検討する。Grobner基底を利用することにより、効率的な計算を実現する。
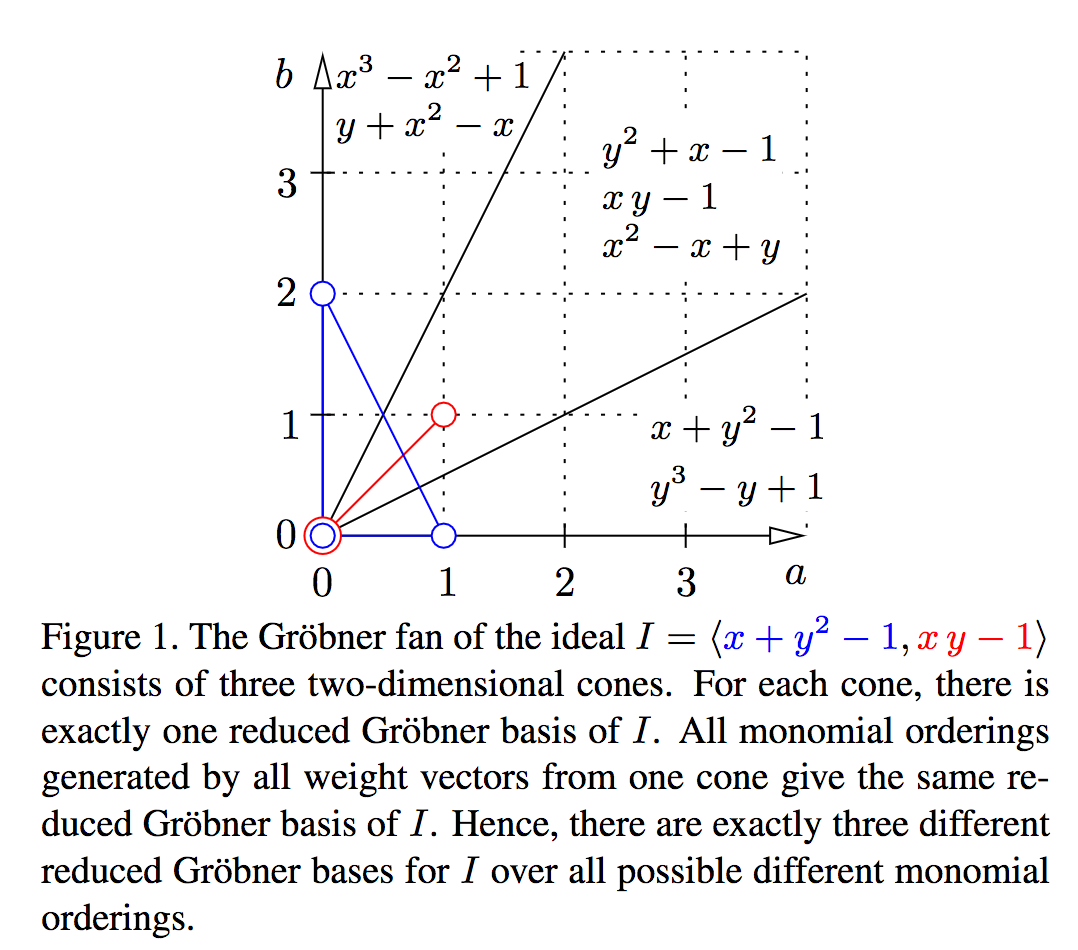
Grobner基底によりロバスト推定を高速化する方法について提案することに成功。単項式によるサンプリングについてヒューリスティックな方法を実現。幾何推定やカメラ校正問題についてState-of-the-artな方法を高速に実装。
CNNによりロバスト性を与えるための学習手法Convolutional Prototype Learning(CPL)を提案する。識別器が騙されるということが少なくなり、識別問題に対して有効である。複数カテゴリに対して条件を与えること、PrototypeLoss(PL)による正則化を与えることでクラス内のコンパクト性を高めた。
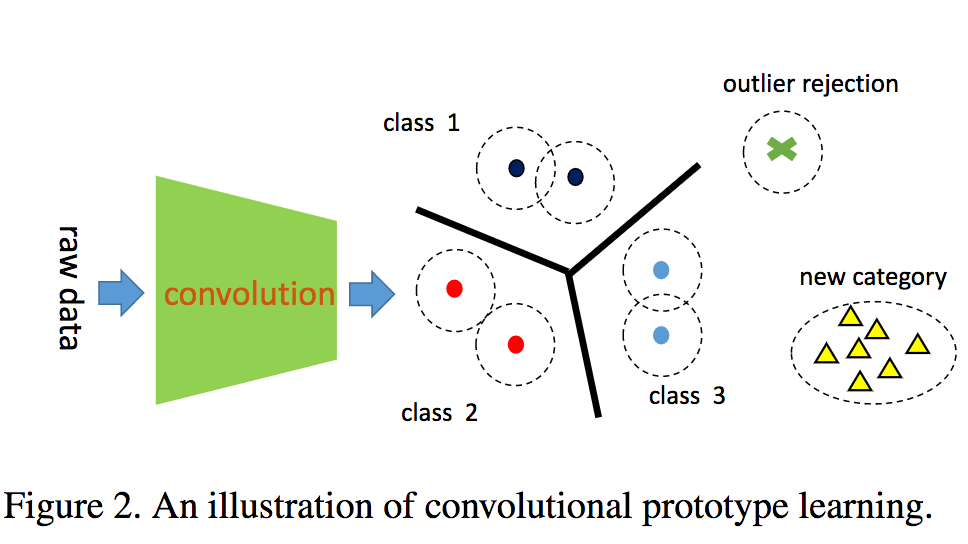
識別のロバスト性を高めるCPLを提案した。CPLではカテゴリを識別するだけでなく、アウトライア除去と新しいカテゴリを追加する機構が備わっている。MNIST/CIFARにて分離性の高い特徴を生成することができた。
Multi-task Learning(MTL; 多タスク学習)について、例えばCNNとGaussian ProcessといったHeterogeneousな学習や推定を同時に行う新しい方法を提案する。タスクに依存しないランダムパラメータを求めることができるため、あらかじめタスクごとの知識を前提としないMTLを実現可能である。実空間における回帰やランキングの問題において良好な精度を実現可能である。
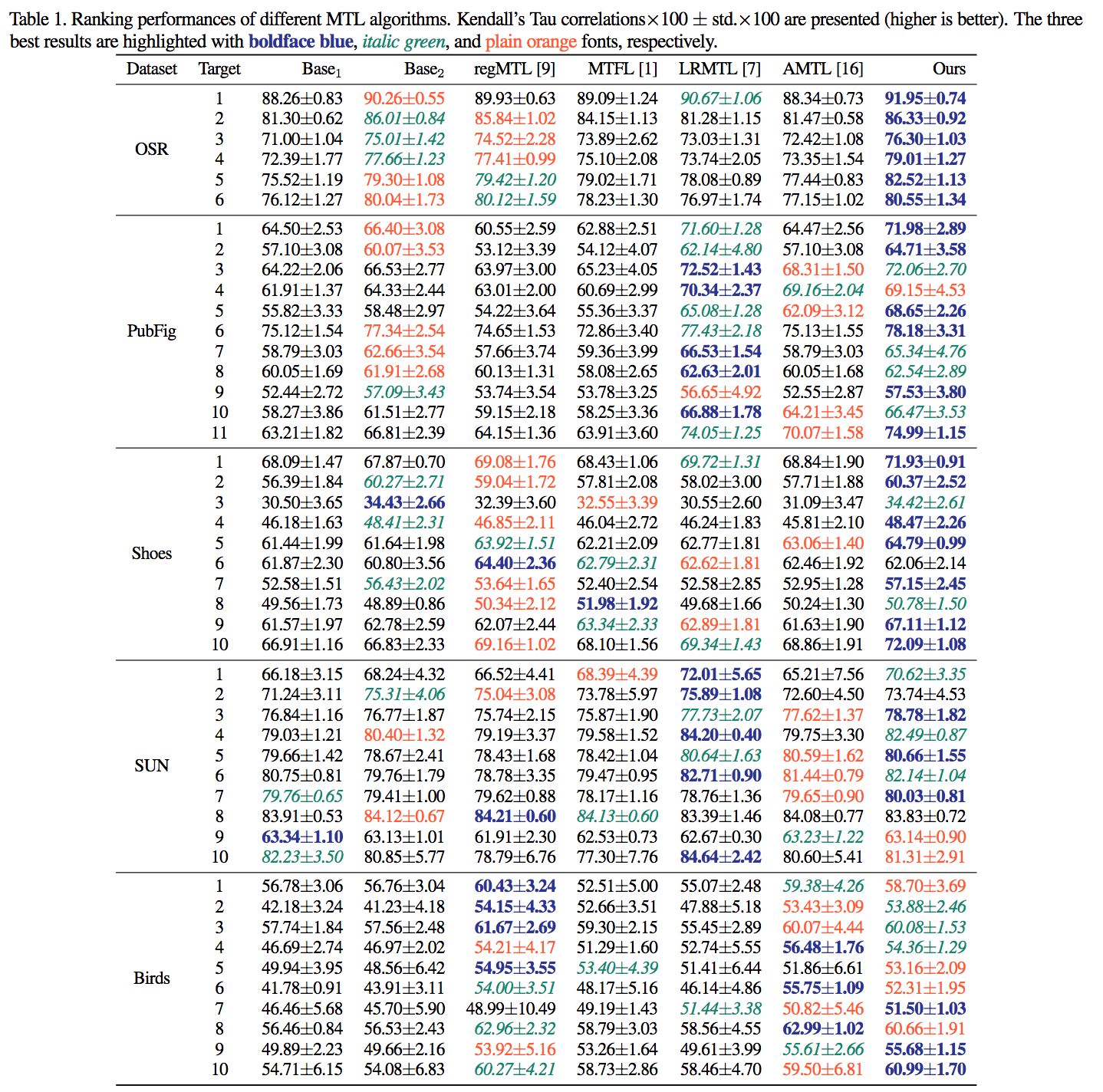
異なるタスク間(CNNとGaussian Processなど)において事前情報を前提としない学習法を提案した。各種データセットにおいて良好な精度を実現した。(表に示す通りであり、大体においてベースラインよりも精度が高い)
グラフベースのクラスタリングに関して、Micro-averageを用いたコスト関数micro average association(micro-AA)を提案。グラフベースのクラスタリングはSpectral Clusteringが従来法の代表例であり互いに素な分類が望ましいが、所望のクラスタより小さな集合を形成してしまい望ましくない。本論文では初期値にも依存しない局所的最適化解を求めることができる。Direct Local Optimization(DLO)により、近似を行うことなく全体最適化を行う。DLOでは初期値に依存するが、Initial-guess-free algorithmを用いることにより解決。

グラフベースのクラスタリングについて、micro-AAを提案、さらに全体最適化する方法や局所最適解に陥らないような最適化テクニックについても紹介したことが大きな貢献である。COIL20 datasetにて100%のクラスタリングを実現するなど、良好な精度を実現することに成功した。
スパースな3次元点群データから道路面(レーン検出レベルで)構造を把握するためのHierarchical Recurrent Attention Networkを提案する。また、3次元点群処理において推定したエッジと正解値の微分可能な誤差関数Polyline Lossも提案する。高速道路にて90km/hで移動する車両から92%の確率でレーン検出を可能にした。右図は提案手法であるHierarchical Recurrent Attention Networkの構造を示したものである。基本的には対称のスキップコネクションを含むEncoder-Decoder方式であるが、Encoderの各層からRecurrent Countingを行う層を追加、Decoderとの整合性をとることで精度を高める。
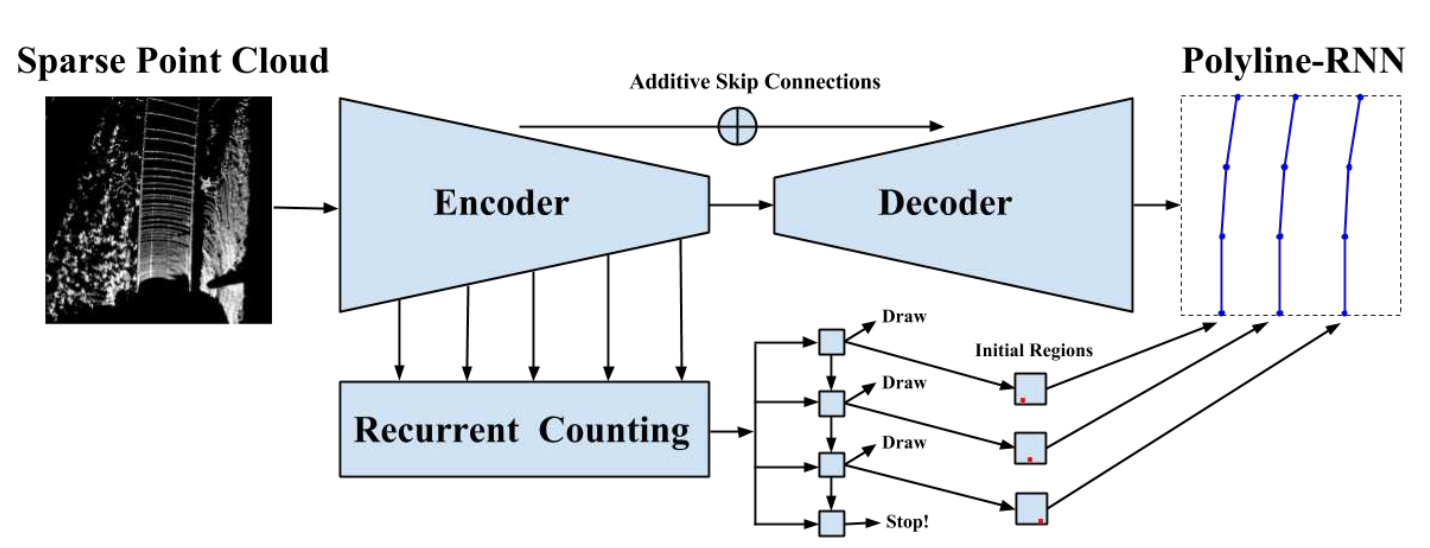
高速道路を想定した環境でも3次元点群処理を高精度に実行するネットワークHierarchical Recurrent Attention Networkを提案した。入力である点群処理からレーン検出を行うことができる。さらに誤差関数PolylineLossを提案することで点群からの推定値と正解値との誤差を計算することができネットワークを学習可能とした。
Product Quantization(PQ; 直積量子化)は与えられたデータを低次元に分解できるため、高次元のエンコーディングに対して有効である。本論文ではPQの直交(orthogonal)時について解析するとともに、Spectral Decompositionについても関係性を調べる。本論文の解析によりスペクトル解析に関する知見が得られることや、計算コストについても言及できる。本論文で提案する定式化により、よりシンプルで効率化されたdecomposition手法を与えることができる。
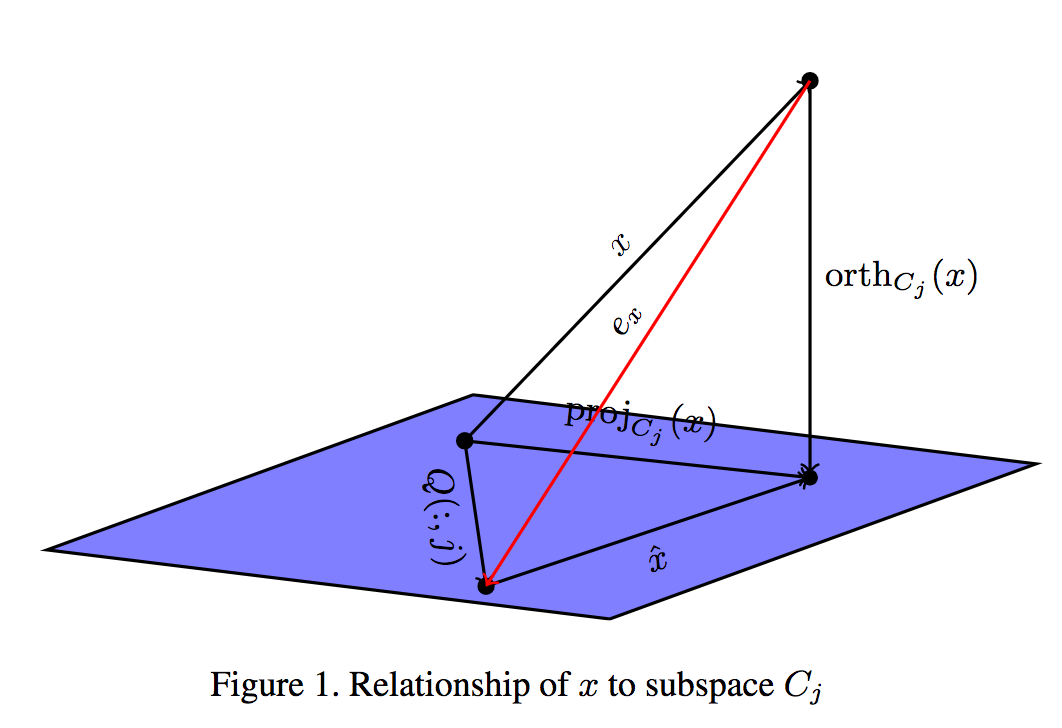
PQの課題においてスペクトル解析と関連することを示した(+定式化)ことが最大の貢献である。各種データセット(Sift25K/1M,Mnist,Cifar,VladLong)にて従来法よりも良好な精度を実現するとともに、効率的な計算ができることも示した。
スーパーピクセル(Superpixels)において多角形形状にて画像領域を近似する問題を取り扱う。従来手法(例えばボロノイマップ)では細い形状にて多角形性を失いがちであるが、本論文では克服することに成功し、サイズや形状によらず柔軟な推定が可能である。事前情報として直線のセグメントを計算しておくことで精度が向上することが明らかとなった。実験ではより少ない多角形で幾何学的な特徴を捉えることに成功した。

画像のスーパーピクセル近似にて、多角形により効率化された計算を可能にした。事前情報として直線検出と組み合わせることにより画像中の情報をよりよく捉えることができる。
自然の中に存在するカーブ(Natural Curves)を想定、認識することで欠損やオクルージョン環境下の補完/インペインティングを実行。与えられた画像中の物体から2つのエンドポイント(End Point)とタンジェント角度(Tangent Orientation)をラベルづけ、推定したカーブの平均値により補完を実行する。
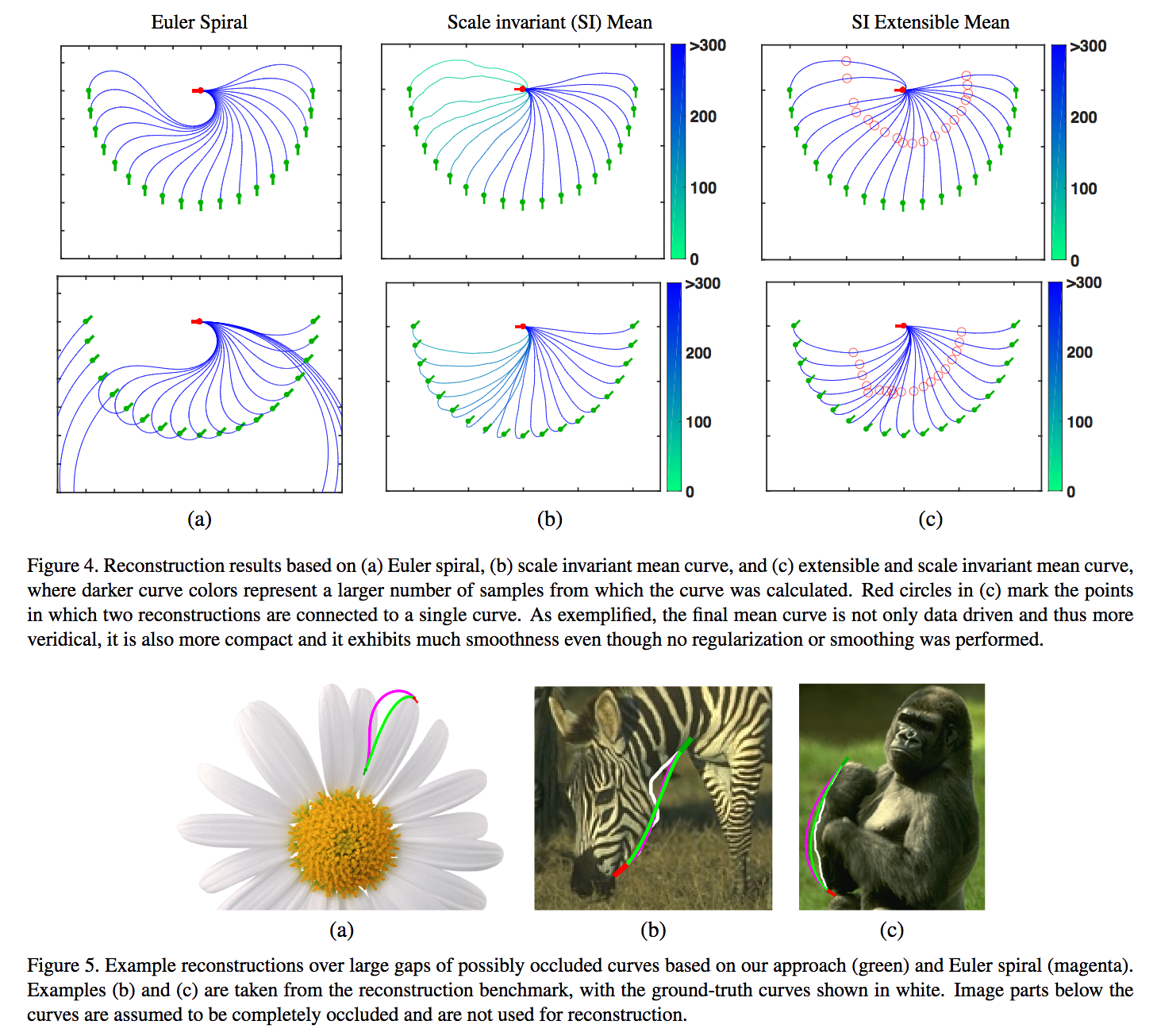
自然のカーブを想定することでオクルージョンや欠損を含んでいたとしても補完をやりやすくした。基本的には2点のエンドポイントをタンジェント角で繋ぐことでカーブを認識し、背景には様々な角度表現やデータを配置している。
低階数の信号モデリングは、画像処理アプリケーションにおける非局所相関をキャプチャーするために広く利用されてきた。グループ化された画像パッチによって生成された多次元配列に対して低階数の多次元配列因子分析を用いる新しい手法を提案する.低階数多次元配列は、画像再構築をさらに改善するために,代替方向乗算法(ADMM)に送られる.動作アプリケーションは圧縮センシング(CS)であり,深い畳み込みアーキテクチャが採用され,CSアプリケーションにおける高級なマトリックス反転を近似する.NLR-TFAと呼ばれるこの低階数多次元配列の因数分解法に基づく反復アルゴリズムが詳しく示される.ノイズのないものとノイズのあるCS測定の実験結果は、特に低CSサンプリングレートでの提案手法の優位性を証明する.
![]()
パッチグループ化に基づいて推定画像から多次元配列を生成する.次に多次元配列を分解後に多次元配列を低階数に設定する. この新しい低階数多次元配列は,ADMMによって解決されるグローバルな目的関数に送られる. これらの2つのステップは,何らかの基準を満たすまで繰り返し実行される.
本稿では、双方向検索モデルを学習するための非常に簡単で効果的な文字レベルのアーキテクチャを示す.マルチモーダルコンテンツを整列させることは、画像と記述との間の意味的対応を見つけることの難易度を考慮すると特に挑戦的である.そこで実際の文字を明確な粒度レベルで畳み込むことによって、テキストセマンティック埋め込みを学ぶために設計された効率的な文字レベルのソースモジュールを示す.私たちのアプローチで生成されたモデルは、単語埋め込みに基づく最先端の戦略よりもはるかに入力ノイズに対して堅牢である. 概念的にもかかわらずはるかに単純であり,より少ないパラメータしか必要としない.テキスト分類,特に多言語およびノイズが多い分野での堅実なパフォーマンスを示す.
CHAIN-VSEという生の文字に基づいてテキスト埋め込みを学習できる双方向検索のためのシンプルなアーキテクチャによって,概念的には関連研究よりもはるかに単純なアーキテクチャであってもMS COCOなどを考慮して,テキストからイメージへとテキストからテキストへの両方で最先端の結果が得られる.
3値や2値などの非常に低ビットのパラメータ値を持つDNNモデルを顕著な損失なく32ビットの浮動小数点数に近似させる新しい方法であるELLS(Explicit Loss-Error-Aware Quantization)を提案
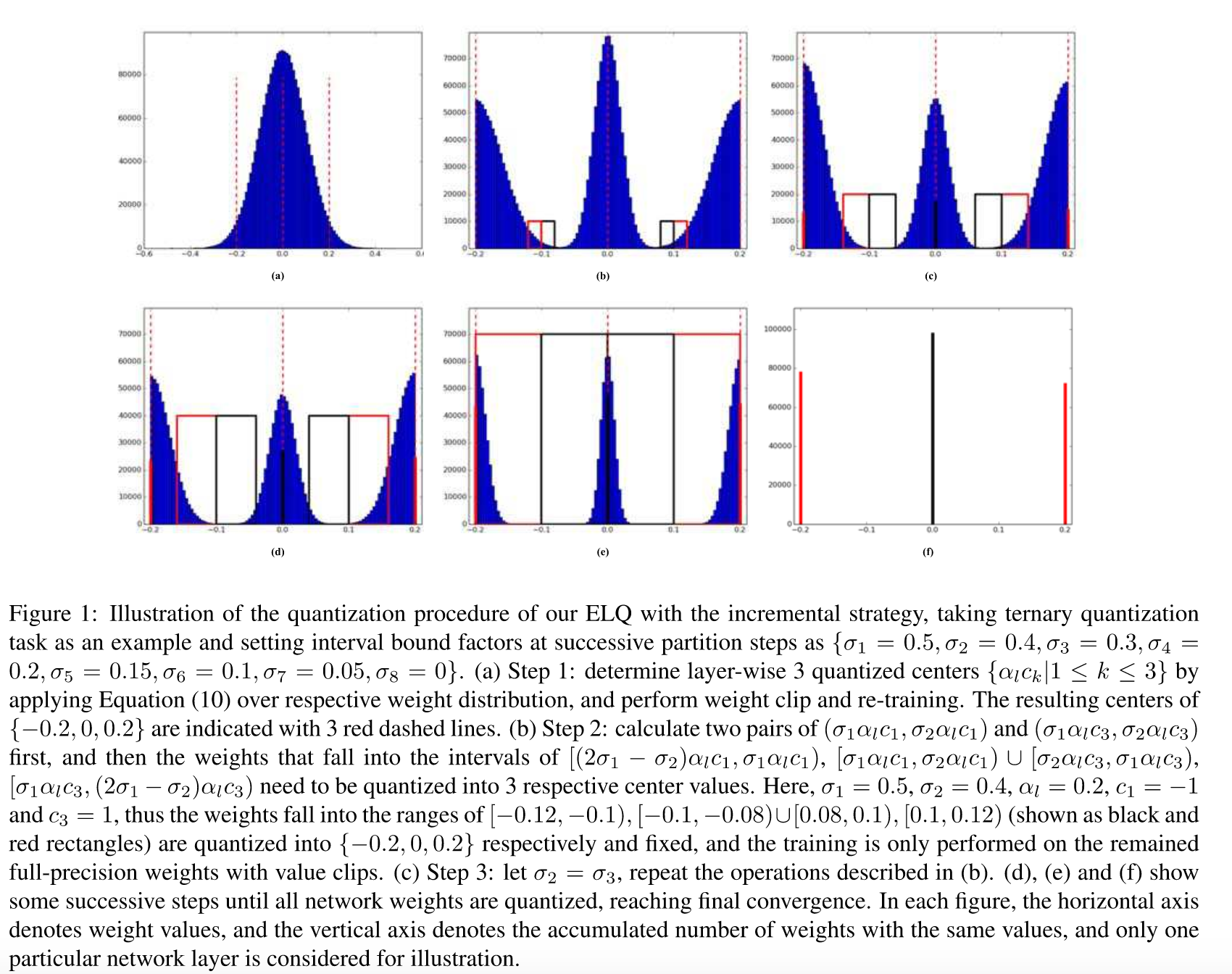
Imagenetでの実験では量子化を行ったことによる精度の低下の少なさでstate-of-the-art
熱画像における経時変化の光伝送分解手法を提案.熱の伝播の速さは光よりも非常に遅く,遠赤外光の過渡遷移がサーマルカメラで観測可能である. 近似的ににコントロールされた環境における可視光画像と似ているため, 従来のCV技術をストレートフォワードに熱画像に適用できるのが肝.
熱画像における散乱光成分は分離可能で,したがって物体の表面の法線を推定可能である.
熱画像を用いれば,黒色,透明,半透明物体に適用可能である.
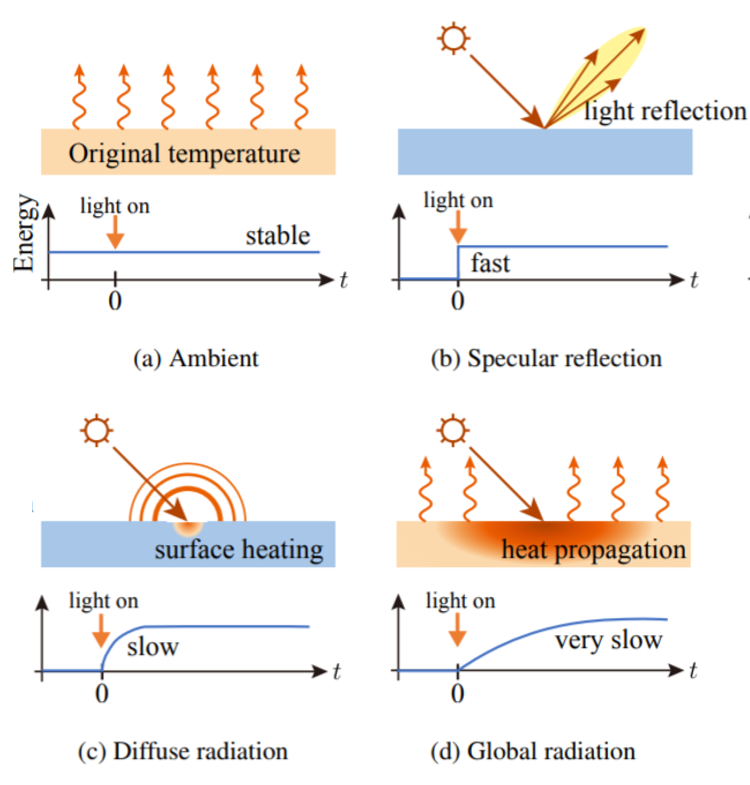
可視光と熱の伝播モデルの差を考慮したCV技術転用のモデル化方法を与えている.また,遠赤外光の伝播特性の差異を用いた手法は新しい.
熱変化は実際経時変化が人間にも認識できるレベルの速さなのが特徴的で,研究には実際専用の知見が必要そう. 適用可能かどうかは実際やってみないと分からないところが多いと思う.頑張ってほしい.
可視光以外を使っている研究の「黒色,透明,半透明OK」は実際キラーワード.
デジタルカメラで実行される重要な操作の1つに、センサ固有の色空間を標準の知覚色空間にマッピングすることがある.この手順は、ホワイトバランス補正の後に色空間変換を適用することを含む。 この比色マッピングの現在のアプローチは、2つの決まった照度(すなわち,2つのホワイトバランス設定)について計算された事前にキャリブレーションされた色空間変換の補間に基づく. 異なる照度の下で取り込まれた画像は,この補間処理の使用により,色の再現精度が低下する. 本稿では,現在の比色マッピング手法の限界について議論し,色再現精度を向上させる2つの手法を提案する.7つの異なったカメラでアプローチを評価し,色再現誤差の点で最大30%(DSLRカメラ)と59%(携帯電話カメラ)改善した.
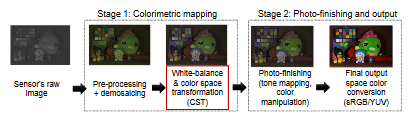
比色マッピング手順を改善する2つの方法として,1つ目は,補間方法における追加のキャリブレーションされた照度を含む補間方法の単純な拡張を行う. 2つ目は、フルカラー補正マトリクスに依存した,すべての入力画像に対して固定CSTマトリクスを使用する方法である.
学習ベースのサブピクセルリファインメント手法Linear Predictiorsにおいて,効率的な計算方法を提案. テンプレート画像をワープさせて誤差が小さくなるようにワープパラメータを最適化するやり方について扱う.
新手法Symbolic Linear Predictorsにより,学習ステップの効率化を実現.一度計算すると複数回異なる画像パッチに対し使いまわせる. これにより,性能を落とさずにオンラインで実行可能に.SLAMなどで使えるようになる.学習ベース手法の実行時効率性のの恩恵がうけられる. また,推測可能な誤差尺度を提案.推測することで,テンプレートの位置合わせ時の誤差を小さくすることができるようになる. 従来手法によれば何百も存在するキーポイントにおいて評価が必要であったが, これにより最良のキーポイント達だけ使えばよくなる.
![]()
SLAM等における有用な手法をアプリケーションレベルに効率化した.
Subpixel Refinementが共通認識のように語られているが,まとめ人的には画像上の位置合わせにおけるサブピクセル精度での精整のことだと気づくのに結構時間かかった.勉強不足だろうか.
コントリビューションの明示的主張のない,CVPRでは珍しい論文.
カメラレディ原稿のフォーマットの不備がある.校正頑張ってほしい.
世の中のデータはマニフォールド上にある事が多いので,ユークリッド空間のような環境空間ではなく,データの表すマニフォールド幾何を考え, その正規化によって学習できると性能を向上できる. 実際,マニフォールド幾何はテンソルで扱えるのだが, 既存手法ではテンソルの学習における微分可能なマニフォールド幾何の正規化ができていない.
本稿では,テンソルの正規化・学習ができるように,リーマン多様体上での学習を考え, サロゲート(代理)目的関数を導入. テンソルが表す幾何特徴をカプセル化する. これにより,非対称かつ高次テンソルの学習ができるようになる.

多様体におけるテンソルの学習ができるようにした.実際やってみたら予想通り学習もうまくいった.
マニフォールド(多様体)局所的にはユークリッド空間とみなせるような空間.地球は丸いけど住民にとっては平面.
リーマン多様体(超粗く言うと)隣は次どっちにどれだけ離れてるかという情報が定義されている多様体.多様体の基本の表し方の一つ.
既存の動画超解像方法とは根本的に異なるフレームワークとして,動的にアップサンプリングフィルタや残差画像を生成するディープニューラルネットワークを新たに提案する.このアプローチにより,入力画像から直接高解像度画像を得ることができる.新しいデータオーギュメンテーション方法と大量の学習動画を用いることにより,SOTAなパフォーマンスを達成.
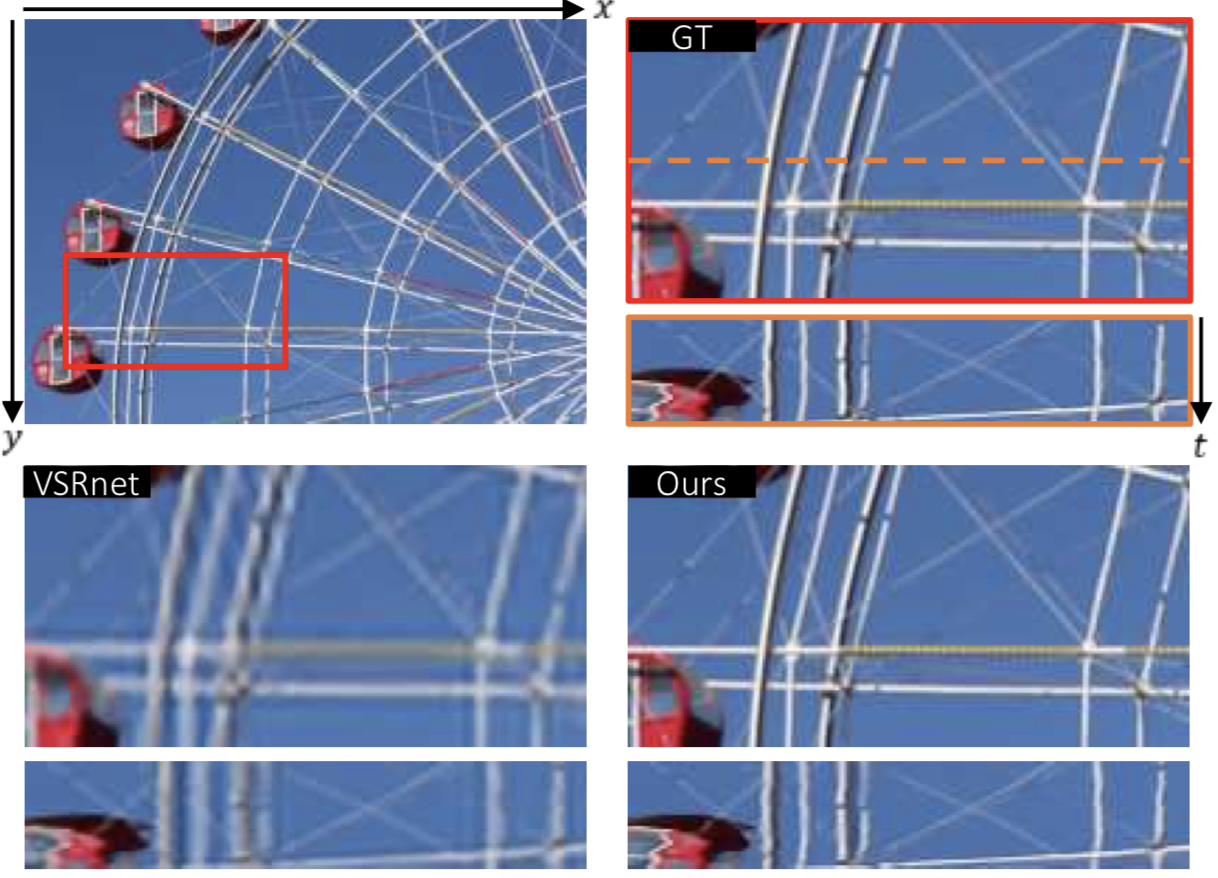
図に示すように,提案手法はSOTA手法の一つであるVSRnetと比較して,チラツキが減少していることがわかる.さらにバイキュービック法やVSRnet,VESPCN等と比較し提案手法は,PSNR,SSIMの両方においても優れていることがわかった.
バイオメディカルアプリケーションにおいて,人間の血液中の細胞を検出,測定,分類は重要である.しかし,広範囲に及ぶ細胞の変動や画像を使用した診断にも解像度の限界があるため非常に難しいタスクとなっている.そこで本稿では,ホログラフィックイメージにおける白血球の検出,測定,分類に新たな手法を提案した.具体的には細胞集合の確率生成モデルをベースとしている.それぞれのクラスのテンプレートは血液の細胞についての静的な分布情報から作られる. 分布についてのパラメータは,患者から得た血液の情報(実際に数えた結果?),セルテンプレートは辞書形学習を拡張させたものを使ってセル分類のクラスから得たセルの画像で学習している.
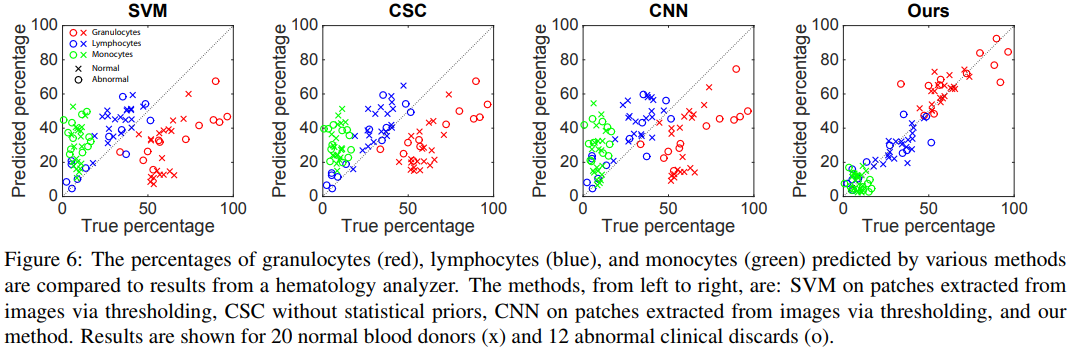
実際に20の正常な血液サンプルと12の正常でない血液サンプルを使って実験しており,従来手法ではエラーが30%ほどに対し,提案手法ではを6.8%以下に抑えた.
眼カメラで撮影した動画をデプス推定する論文.従来のデプス推定では,CNN姿勢予測器を用いてデプス予測を行っているが,従来までの手法だけでは単眼カメラで撮影した動画のデプス予測に最適な手法ではない.そこで本稿ではDirect Visual Odometryを改良したDDVO,Pose-CNN,DDVO+Pose-CNNの3つの手法を用いて姿勢予測し,さらにデプスを教師なし学習で推定する手法を提案している. 構造としては一度の入力に3つの連続した画像 I1,I2,I3を使用する.それらの入力からまずI1,I3からデプスの逆数の値を取ったinverse depth mapと,すべての画像の姿勢推定を行い,I2とそれ以外の画像の姿勢の関係性を推定する.そしてI2とI1,I3とのwarped imageの相違性を比較しロスを求め評価する.
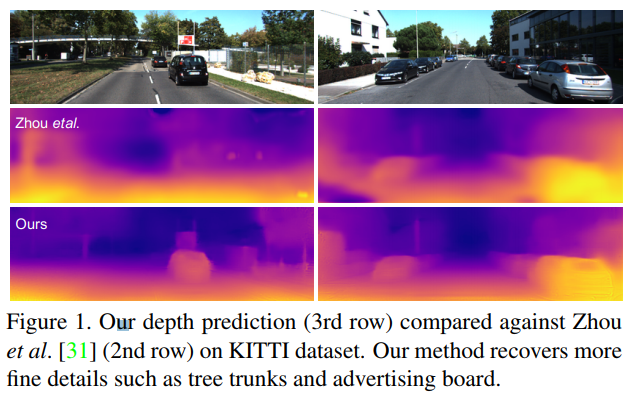
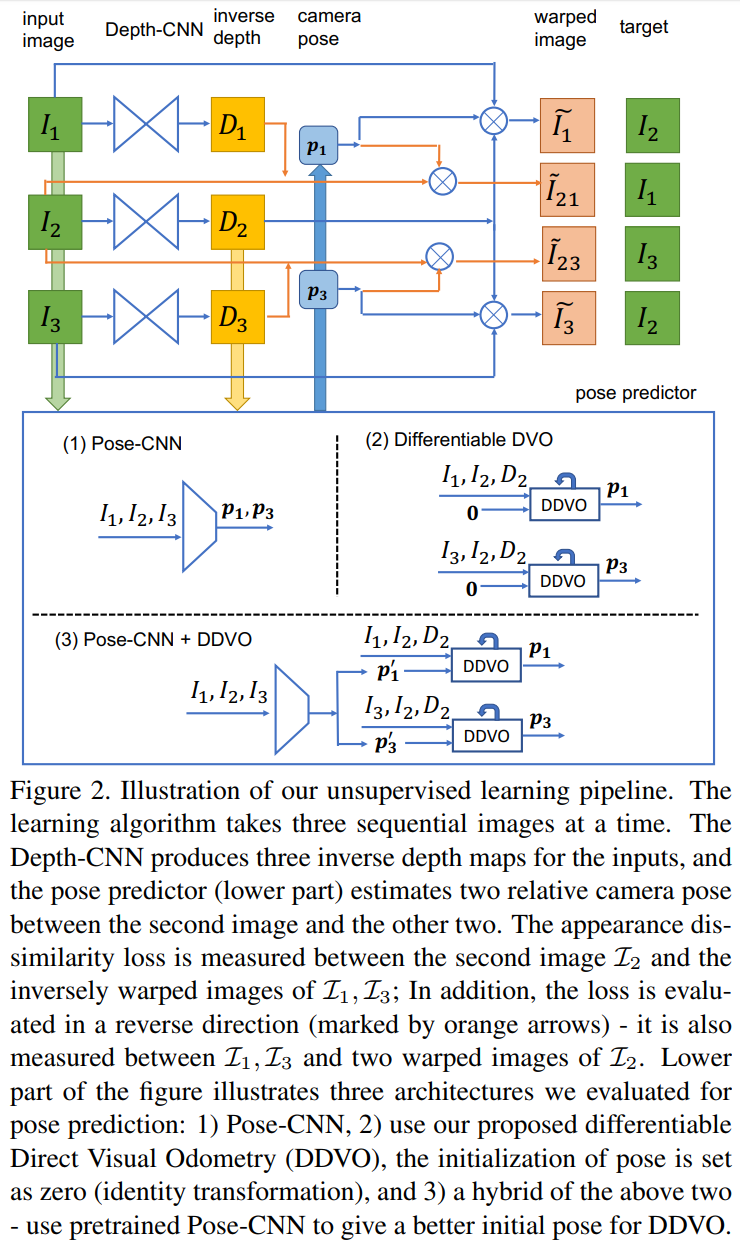
実験の評価方法としてKITTIデータセットを使用しており,従来手法と比較し,単眼カメラで撮影した動画でありながら,提案手法のPose-CNN+DDVOを使用したものが最も高い評価値である.
モバイルカメラなどで実際に撮影したレシートや文章などの歪んだ画像をフラットな画像に修正するネットワークを考案.手法としてはセマンティックセグメンテーションに似ており,画素単位で判別していく. ネットワークアーキテクチャとしては2組のU-Netを用いて実現している. 1つ目のU-netでは逆畳み込み層部分を分割して,特徴マップを抽出したものとフォワードマップy1を出力する. これらを合成して2つ目のU-netの入力にする.2つ目のU-netではフラットな画像に修正した画像1枚を出力する. この処理をLossが小さくなるまで繰り返し行う. 評価方法としては実際にモバイルカメラを用いて論文などのプリントを撮影した画像とそのプリントをスキャンしてGround truthにしたものを90Kほど用いてトレーニングを行っている.
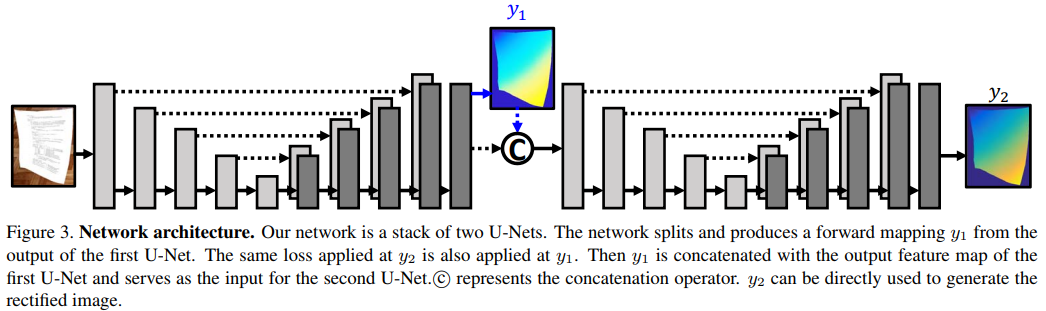

折れ曲がっている部位や極度に撮影の仕方が悪いものは歪んでしまっているが,それでも文字が読み取れるレベルまで画像が修正できている.
地形認識はロボット分野や自動運転に対し重要な処理である.しかしテクスチャを使った地形認識では,例えば"grass"と"leaves"は似ているために間違った認識がされることがある. そこで地形認識のためのDeep Encoding Pooling Network (DEP)を提案した. 事前に学習したCNNを特徴抽出器として利用し,CNNからの出力をtexture encoding layerとglobal average pooling layerに送る. texture encoding layerではテクスチャのdetailを持ちつつ,global average pooling layerが持っていたローカル空間情報を出力する. 30000枚以上の画像を40クラスに分類したGTOSデータセットで学習し,よりリアルな条件下で評価するために,テストデータには携帯のビデオで撮影した81個のビデオをasphaltやsandなどの31クラスに分類したGTOS-mobileデータセットを作成した. ネットワークの評価はGTOS-mobileだけでなくMINCやDTDも使用し評価している.
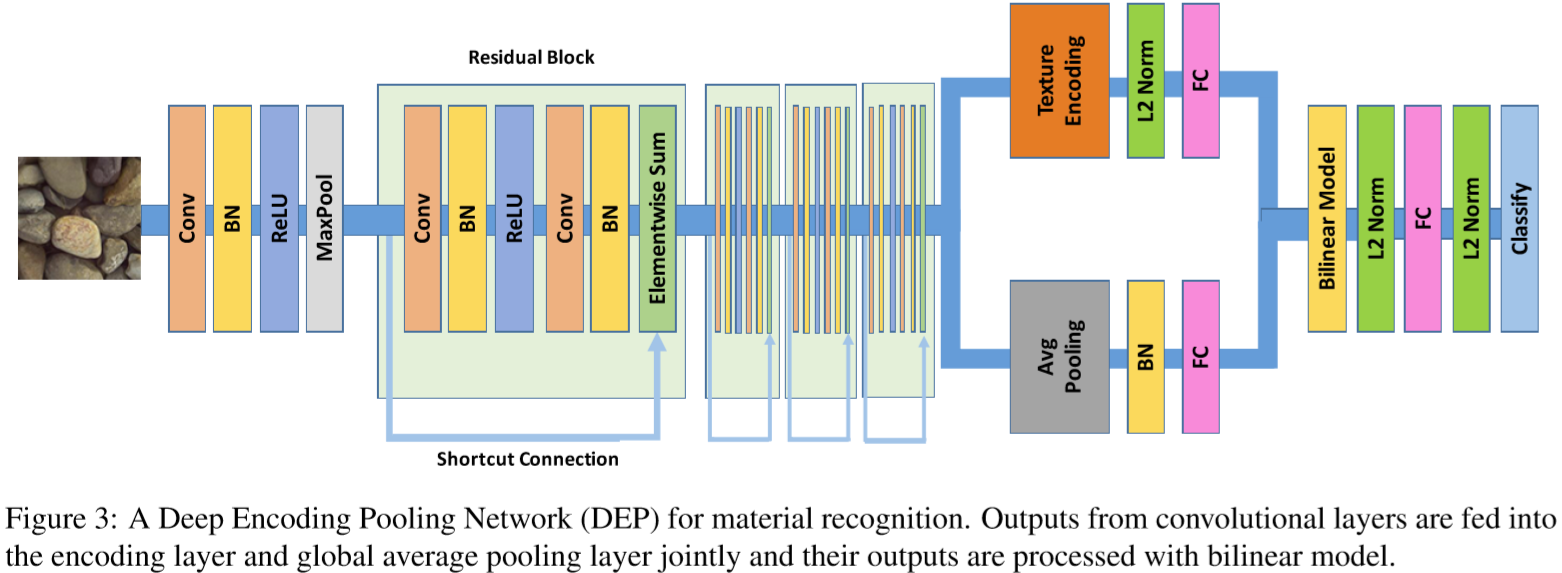
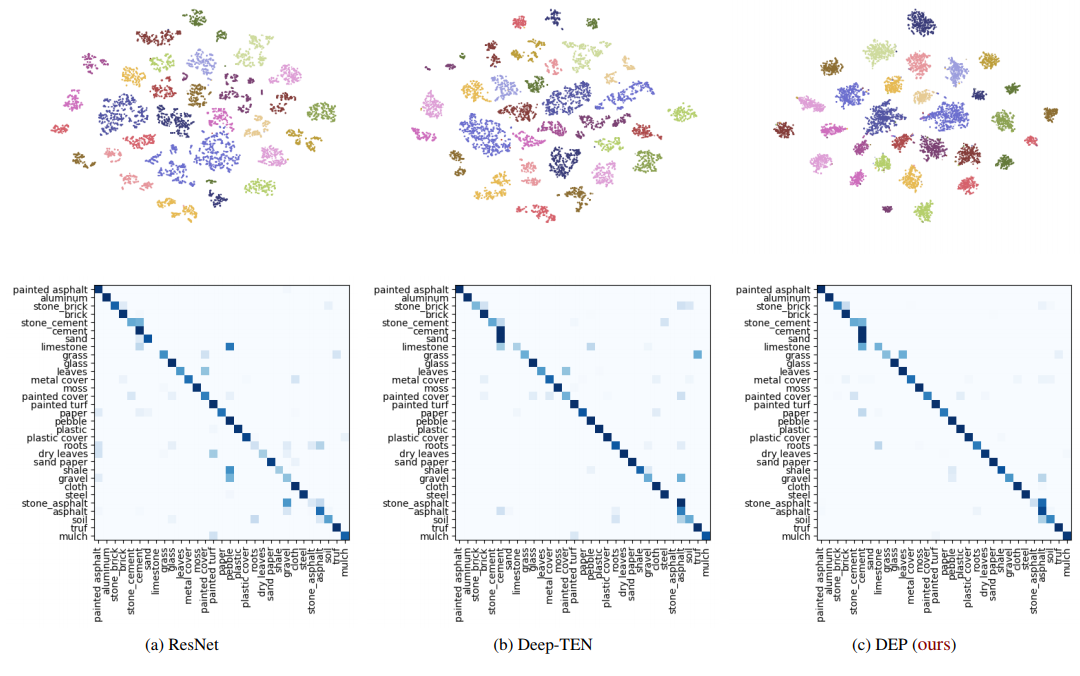
ランダムに10000枚の画像を選び,ResNetや著者たちの従来手法であるDeep TENと提案手法で識別させ比較すると,提案手法がもっとも分類がうまくいっている.
実際にテストデータにGTOS-mobileを使用した結果も,ResNetやDeepTENより2~5%ほど精度が向上している.
品種などの微妙な違いでカテゴリを区別されるような細かい画像のクラス分けは膨大なカテゴリ分けの高いコストにより難しいタスクとなっている.これにより起こるトレーニングデータの不足に対処する研究として以下の二点が存在する. (1)人のアノテーションが加わっていないフリーなウェブイメージを利用. (2)Zero-shot Learning(ZSL)を利用. しかし,(1)ではウェブイメージにラベルノイズ付きが多いこと,(2)ではZSLは未だに従来の学習に比べて精度が良くないという問題点が存在する. そこでウェブイメージと補助的なラベルデータを用いてトレーニングデータに関連付けられていないテストカテゴリを予測するフレームワークを提案した. 評価にはZSLの評価にもよく使われる3つのデータセット,CNB, SUN, Dogsを使って評価している.
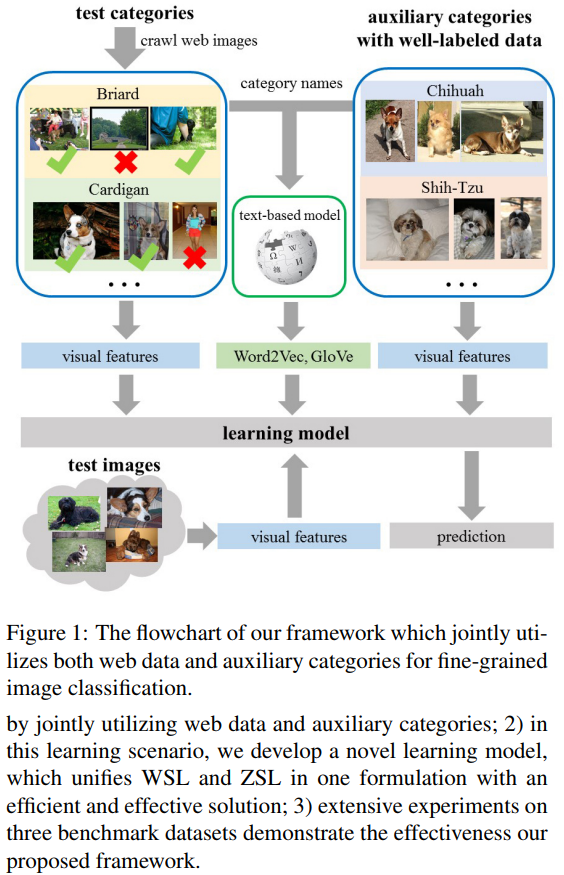
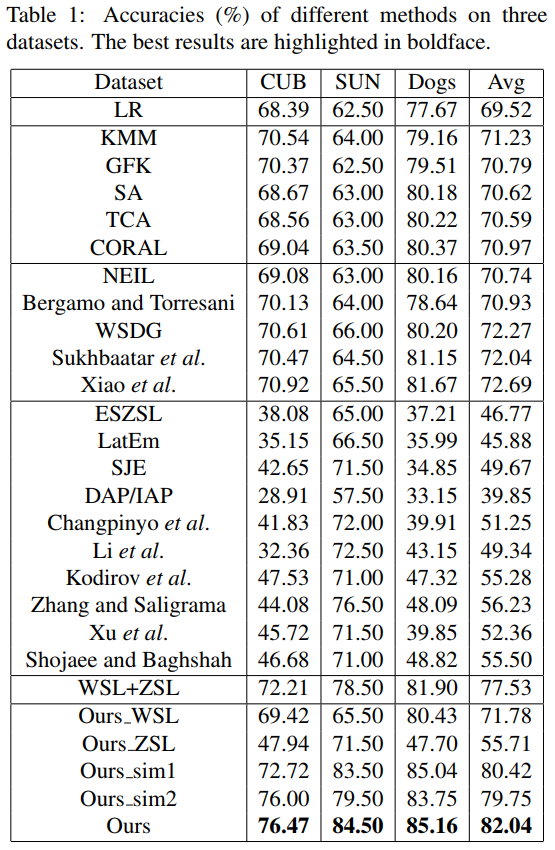
従来手法(特にZSL)に比べ格段に精度が上昇している.
室内の2Dパノラマ画像1枚から3Dモデルを推定する研究.本稿ではパノラマ画像から18視点の画像(パノラマの中心点から対象を普通に撮影したような画像),sub-viewを生成する. それらを入力とし,sub-viewごとに顕著生マップ(Saliency map)とオブジェクト検出から前景と背景を分けると同時に直線検出(Line segment detection)を行いパノラマ画像を解析し,geometric cueとsemantic cueを推定する. これらから地面の推定,オクルージョンの推定を行い,形状の復元を行う.
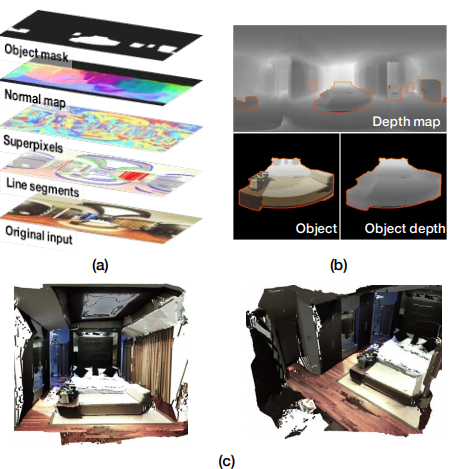
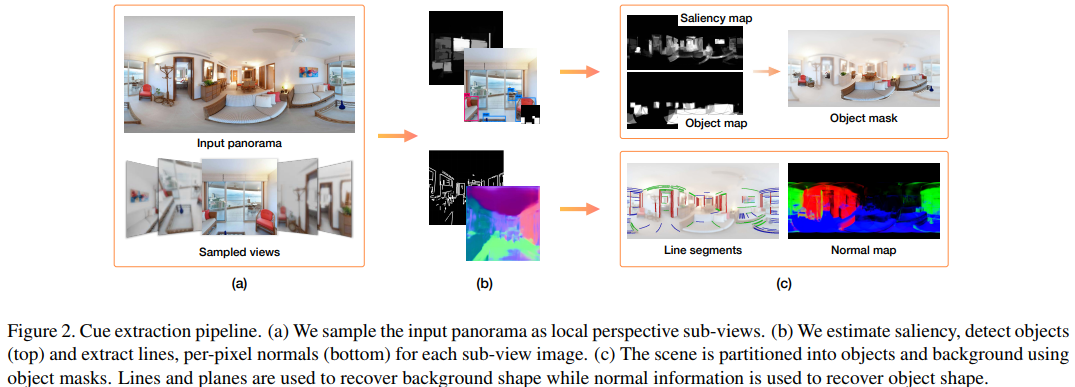
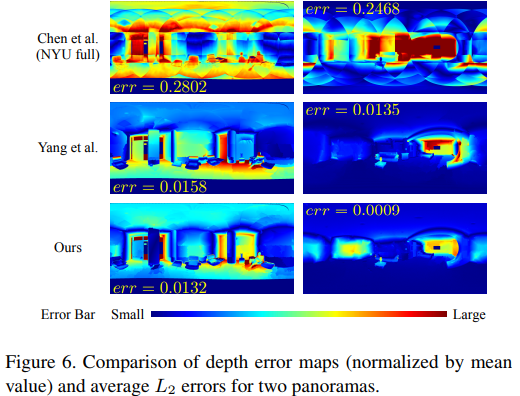
FAROとsyntheticデータセットを使って評価した結果,背景とオブジェクト検出におけるdepth cosine distanceが従来より最先端な結果となった.
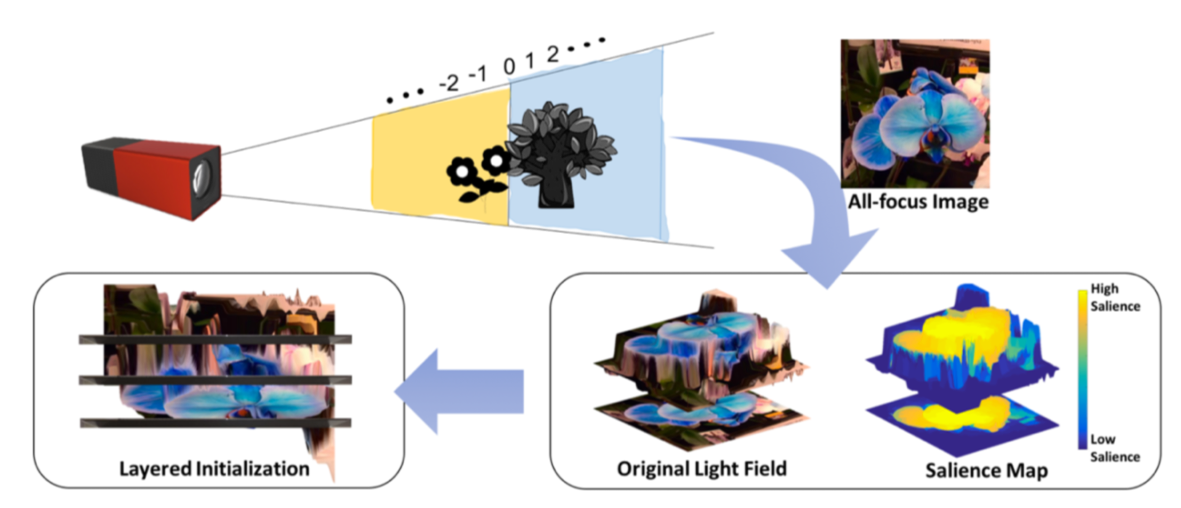
Multi-layer light field 3D display のための depth calibration の研究. Saliency の高い領域を推定し, その領域の深度を可能な限り表現出来るように calibration することで, Multi-layer light field 3D display の持つ深度表現の制限の元で知覚的に最適化された depth calibration を行う手法を提案. 主観評価実験では既存手法よりも最低でも12%以上良いという結果を達成.
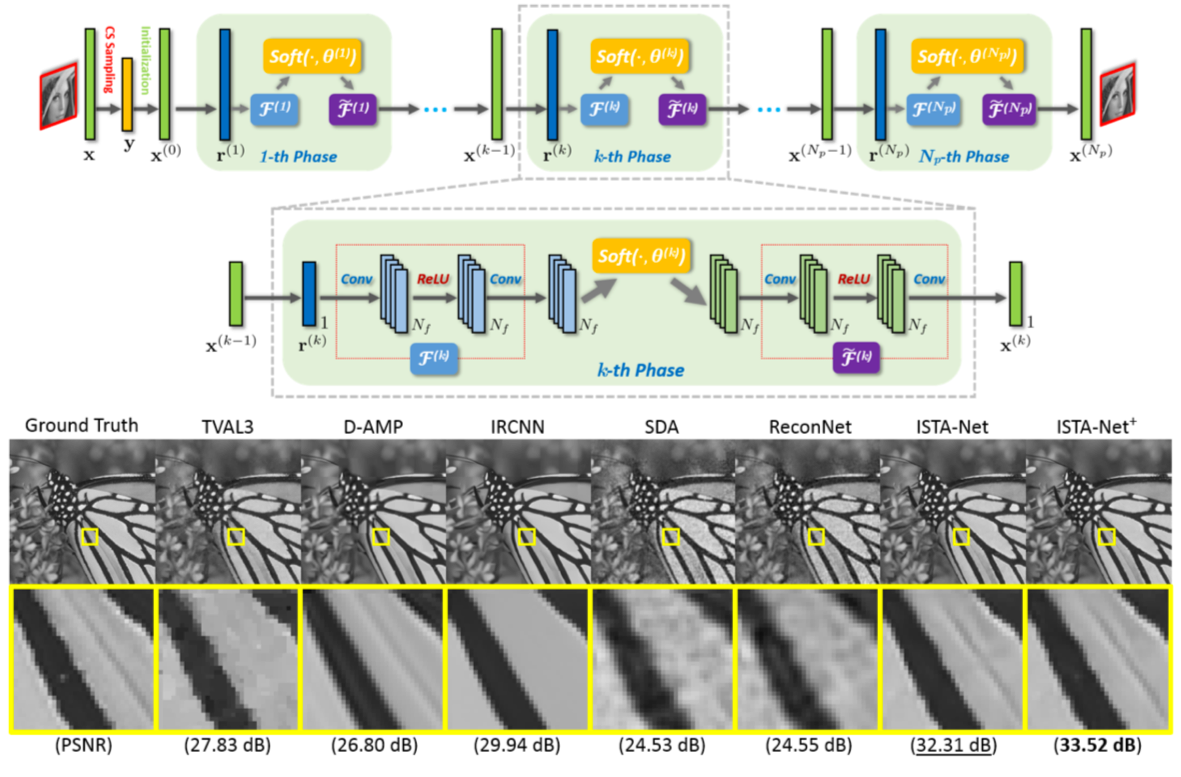
Compressive sensing (CS) reconstruction の研究. 従来の Iterative Shrinkage-Thresholding Algorithm (ISTA) のイテレーションを end-to-end で学習可能なネットワークに置き換えた, ISTA-Net を提案. 評価実験では幅広い CS Rate において既存の最適化に基づく手法とネットワークに基づく手法の両者よりも優位な結果を達成した.
アノテーションには対象領域を矩形で囲むのとその確認作業の2つのステップがある。画像がシンプルで検出領域の信頼性が高い場合は手作業で矩形を付ける作業を行わず、確認作業のみを行ったほうが時間を短縮できる。一方、検出領域が小さく、数多くあると確認作業に時間がかかってしまうため、手作業で矩形をつけたほうがよい。このように画像ごとに最適なアノテーション戦略を練る必要があり、Intelligent Annotation Dialogs (IAD) はこの手助けをする。本論文では2つのIAD手法が提案されている。1つ目は検出領域がアノテーターに受け入れられる確率を考慮して、アノテーション時間をモデル化することで最適化する。2つ目はモデリングを行わず、強化学習により最適な戦略を見つける。
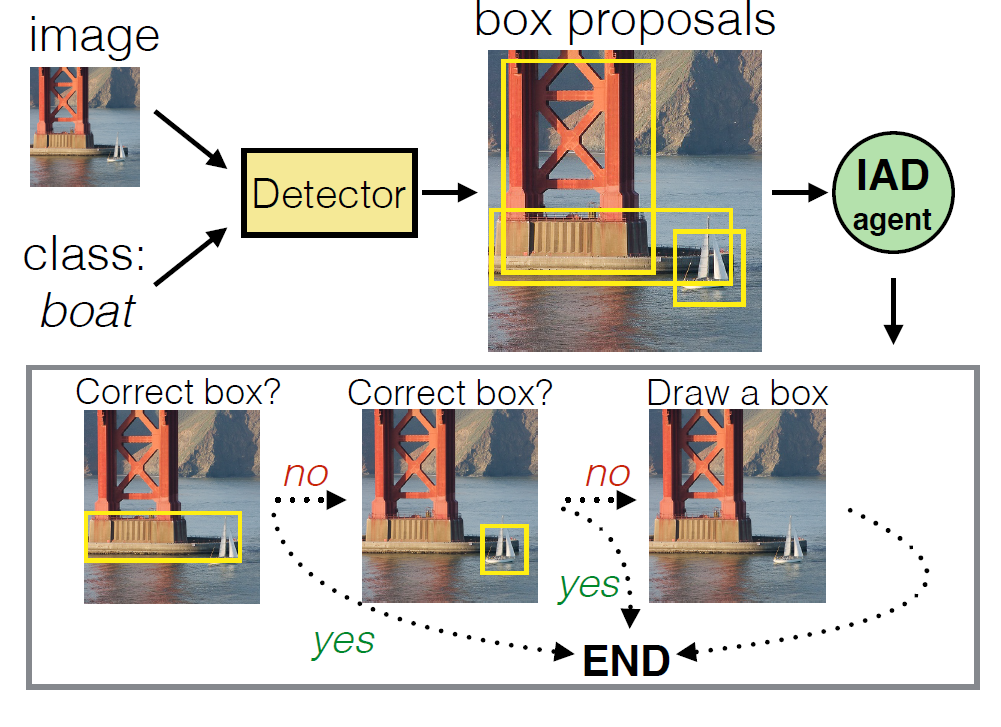
物体検出等において精度の高いアノテーションは重要であるがそのコストは高いままである中で、IADを利用することにより既存手法に比べてアノテーション時間を短縮できると示した。
**論文
Object retrievalにおけるManifold searchの計算コストをEuclidean searchまで下げるためのembeddingを提案した。nodeが特徴量に対応するものをグラフとして扱い、観測ベクトルyから類似度を表すランキングベクトルxを予測する線形システムを扱う。
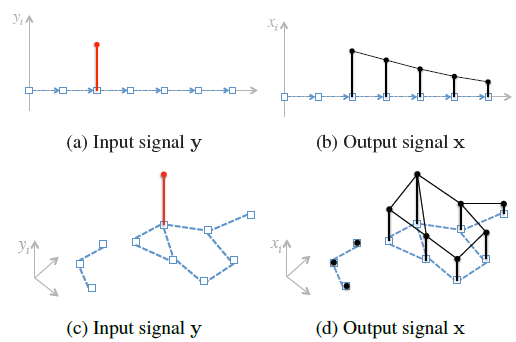
10^5オーダーの数ある画像に対して、オフラインプロセスを2,3時間で、オンラインプロセスは従来手法と同等に処理することが可能に。精度は従来手法と同程度である。 mAPはrank-1kあたりで収束している。
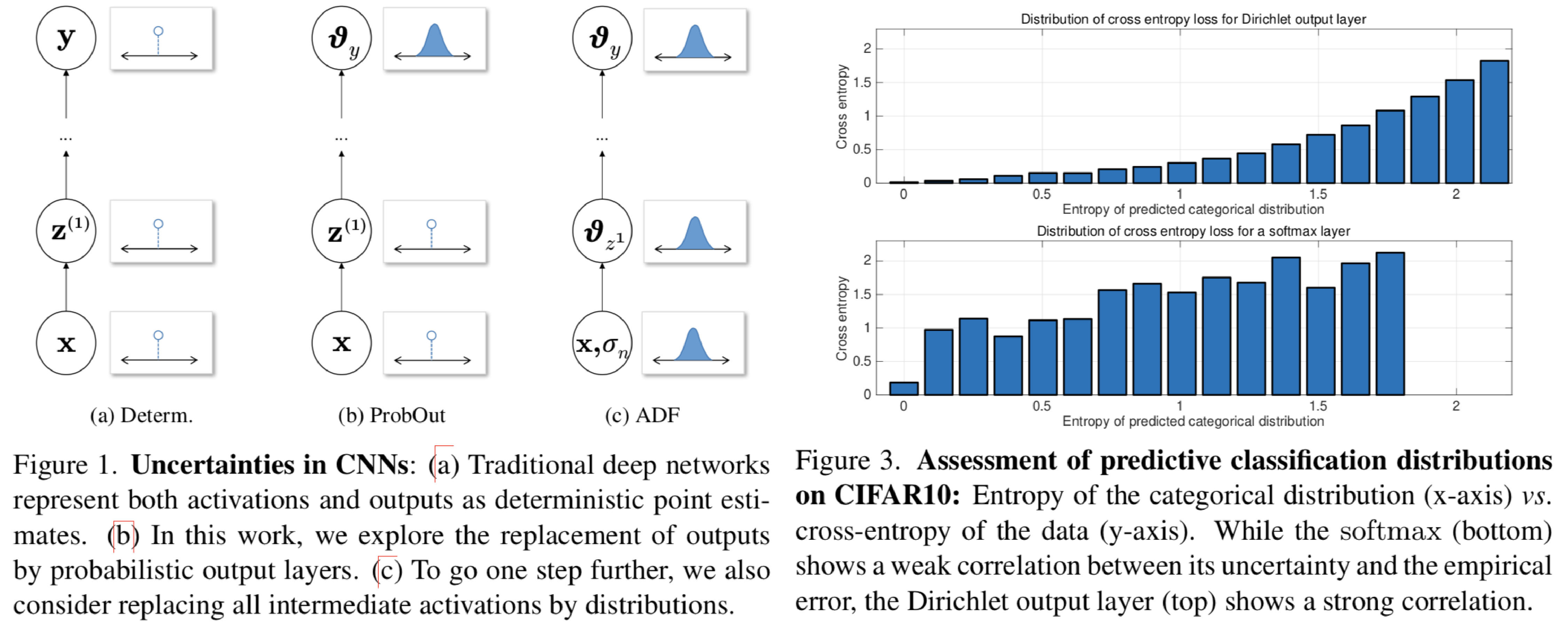
DNNに対して活性化や最終層の出力を確率分布で置き換えるモデルを提案。DNNでは要所要所で確率モデルを使用しているが、多くのモデルでは活性化や最終層の出力はサンプリングに終わっている。一方でfull Bayesian networksではパラメタ自体を確率分布に置き換えているが、テストの実行に長い時間がかかってしまう。提案手法ではネットワークの最終層の出力を確率分布で置き換えるprobabilistic output layers (ProbOut)と、assumed density filtering(ADF)を導入することで活性化を確率分布で置き換える2つの方法を提案。これを既存のネットワークに組み込むことで、テスト時の実行速度を落とすことなく識別・回帰の両タスクで高い精度を実現。特に識別ではディリクレ分布に基づく出力を行うモデルを提案。
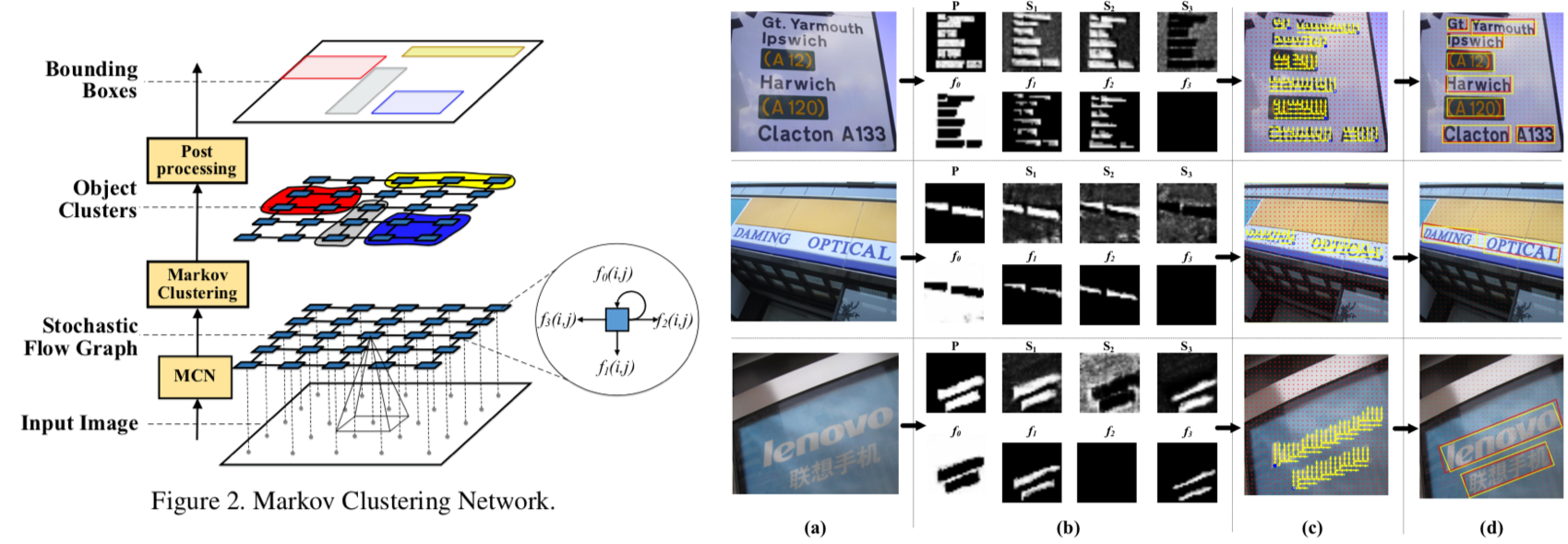
ボトムアップに Scene Text Detection を行う手法を提案. 物体検出を Stochastic Flow Graph のクラスタリングとして定式化した. ボトムアップな手法の恩恵として, スケールや回転に頑強になると共に, 並列化による高速化が可能となった. 評価実験では MSRA-TD500 dataset で SOTA を達成し, かつ既存手法の1.5倍(34FPS)高速に動作.
stero matching に用いる mathching volume の推定を学習データに依存せずに, ロバストに行うモデルを提案. 4つの matcher から得られた mathching volume から確信度の高い部分(確信度の計算は双方向から行う)をそれぞれ抽出し, random forest classifier を用いて最終的な mathching volume の生成を行う. 評価実験では MC-CNN と同等の高い精度を達成すると共に, 高い汎化性能を確認した.
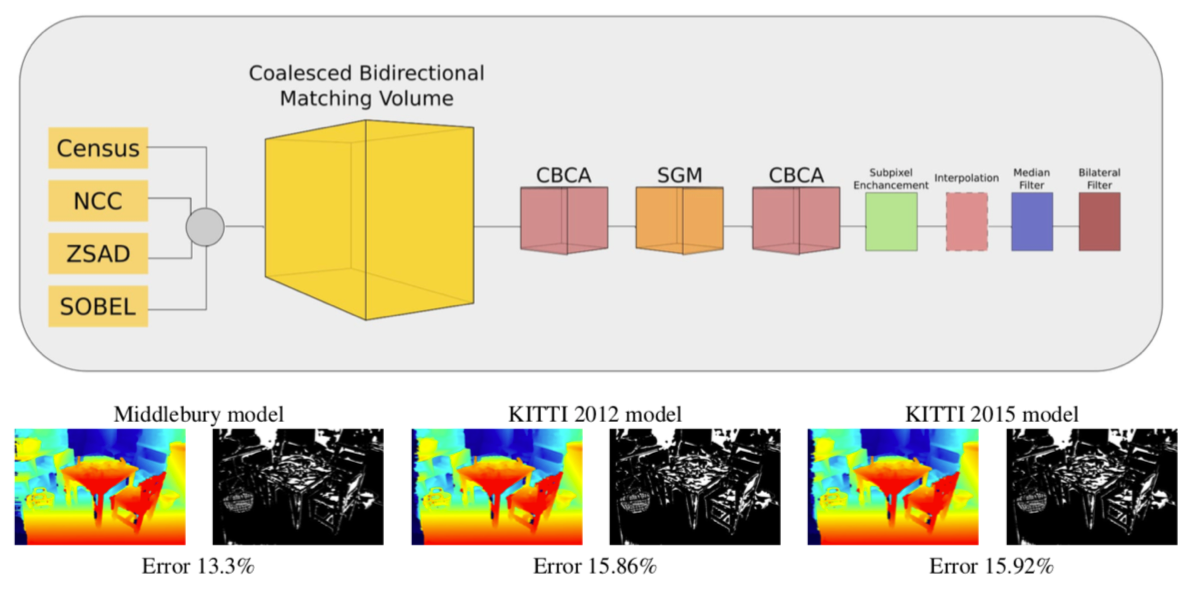
Image-specific な saliency map を得るために, 既存の saliency detector を強化する問題を zero-shot learning として定式化. DNNを用いて, 画像の特徴量マップと各画素のアトリビュートを同じ計量空間に射影し, アトリビュートが射影された点をアンカーとして最近傍探索によって新しい saliency map を得る. ECSSD や PASCAL-S など5つのベンチマークで評価を行いSOTAを達成した.

Multi-view stereo(MVS)による3次元再構成の問題を取り扱う。事前確率による画像パッチにより少量のデータで3次元形状を復元、より高速な処理を可能とした。右図のように3次元再構成を行うために重要なデータを予め抽出することで16%のデータで約6倍高速にMVSによる3次元データを復元するに至った。ニューラルネットベースの手法(I2RNet)やDepthから3次元復元のための重要なデータを選定。
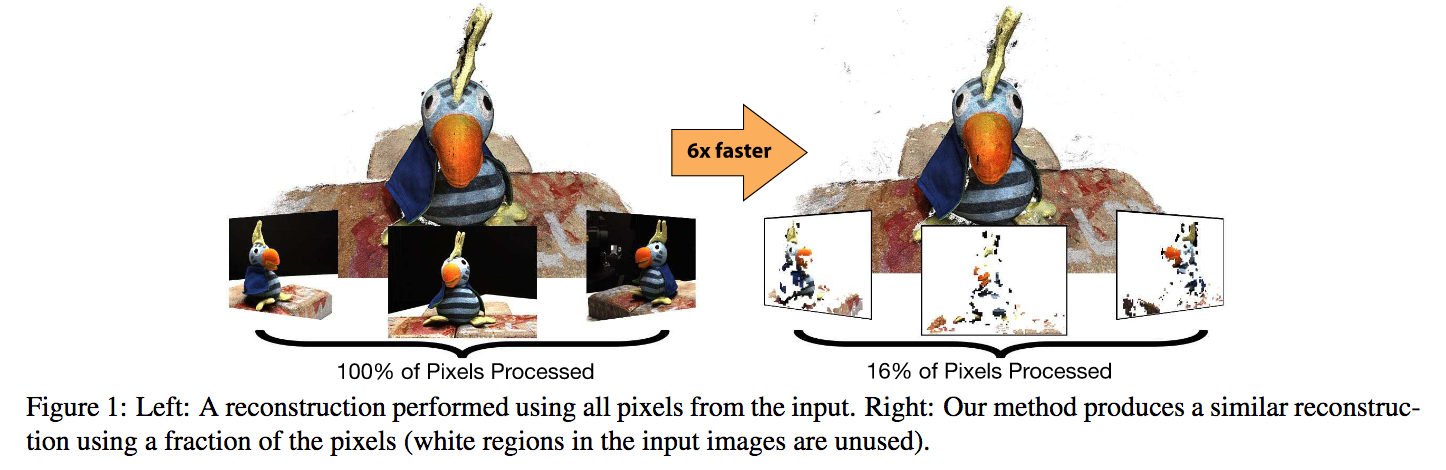
MVSにて事前確率(w/ Depth, I2RNet)を用い少量の重要なデータを用いることで高速な3次元復元を可能とした。
動画像の入力から非剛体に対するSfM(Non-Rigid Structure-from-Motion)に対して再帰的に繰り返し動的行動を復元できる新しい手法を考案する。非剛体の形状変化は再帰的になる傾向があるという性質を利用して形状復元を実施した。この性質を用いると、従来の剛体形状復元の方法をほぼ改編しなくても同じようなモデルで復元を可能とした。右図は再帰性を用いた非剛体推定の例である。フレームによりほぼ同じ姿勢が表れており、この知識を用いると剛体推定と同じような枠組みで非剛体を推定できる。
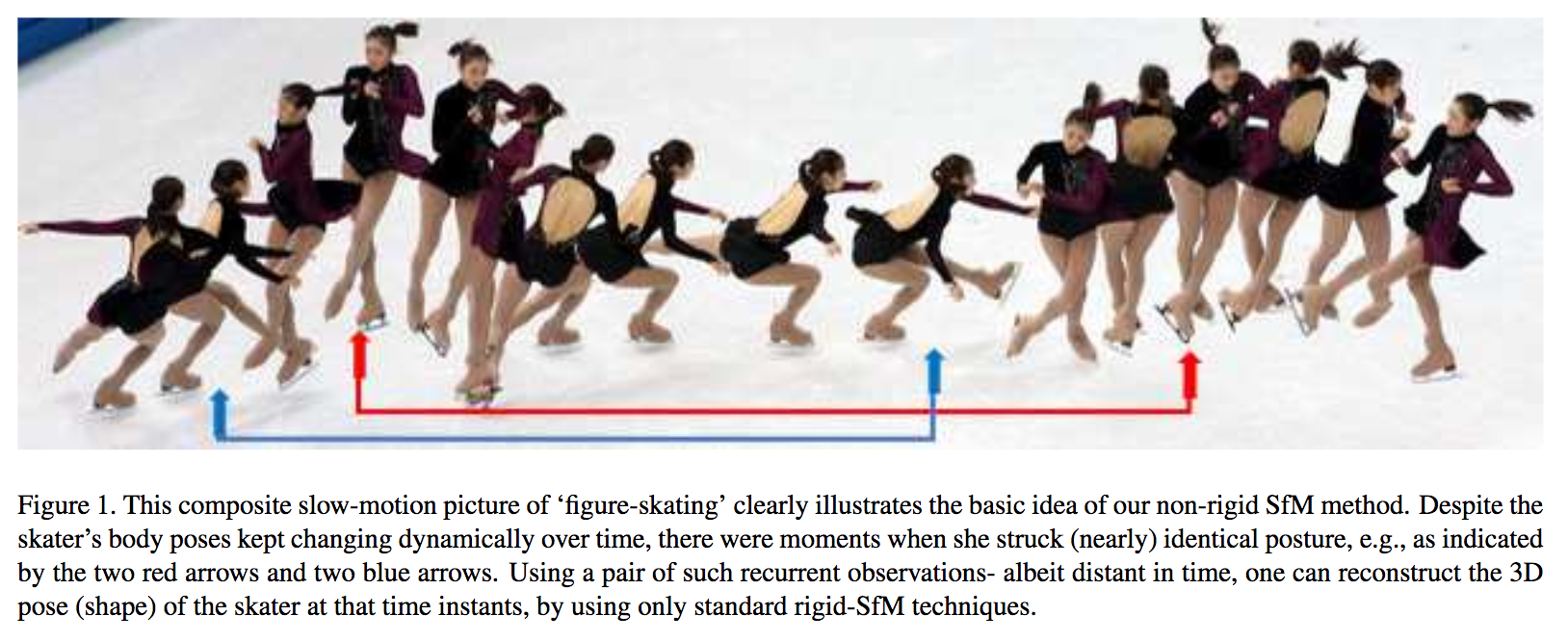
再帰的な動作を捉えることで、従来の剛体推定とほぼ同じモデルで動画からの非剛体推定ができるという知見を与えた(ことが大きな貢献であり、採択された理由である)。
カメラ姿勢の中でも角度が既知であるというStructure-from-Motion(SfM)の中でも特殊な問題を扱う。再投影誤差(Reprojection Errors)に関してMini-Max問題を想定し、この問題について擬似凸プログラミング問題(Pseudo-Convex Programming)として解決する。従来では非常に処理時間がかかる同問題に対して、本論文では(比較的)大規模なデータにおいて高速化を図った。最適化の更新処理においてMinimum Enclosing Ball (MEB)を用いることでメモリ低減と同時に高速化を実現した。
SfMにおいても特殊と言われる、カメラ角度が既知の状態における擬似凸最適化の問題で、繰り返し最適化手法を考案することで比較的大規模な問題において高速な演算を行うことに成功した。
剛体の3次元点群のレジストレーション(位置合わせ)を行うための手法Inverse Composition Discriminative Optimization(ICDO)を提供する。従来のICPはローカルの位置合わせに着目しているために、局所最適解に陥りやすく初期値やアウトライアに依存して位置合わせが失敗してしまう。提案手法であるICDOでは合成トレーニングデータにより学習を行い、繰り返し最適化を行うことでより全体的な最適解に近づけるという戦略を取っている。(本手法はDOの拡張であると位置付けている)
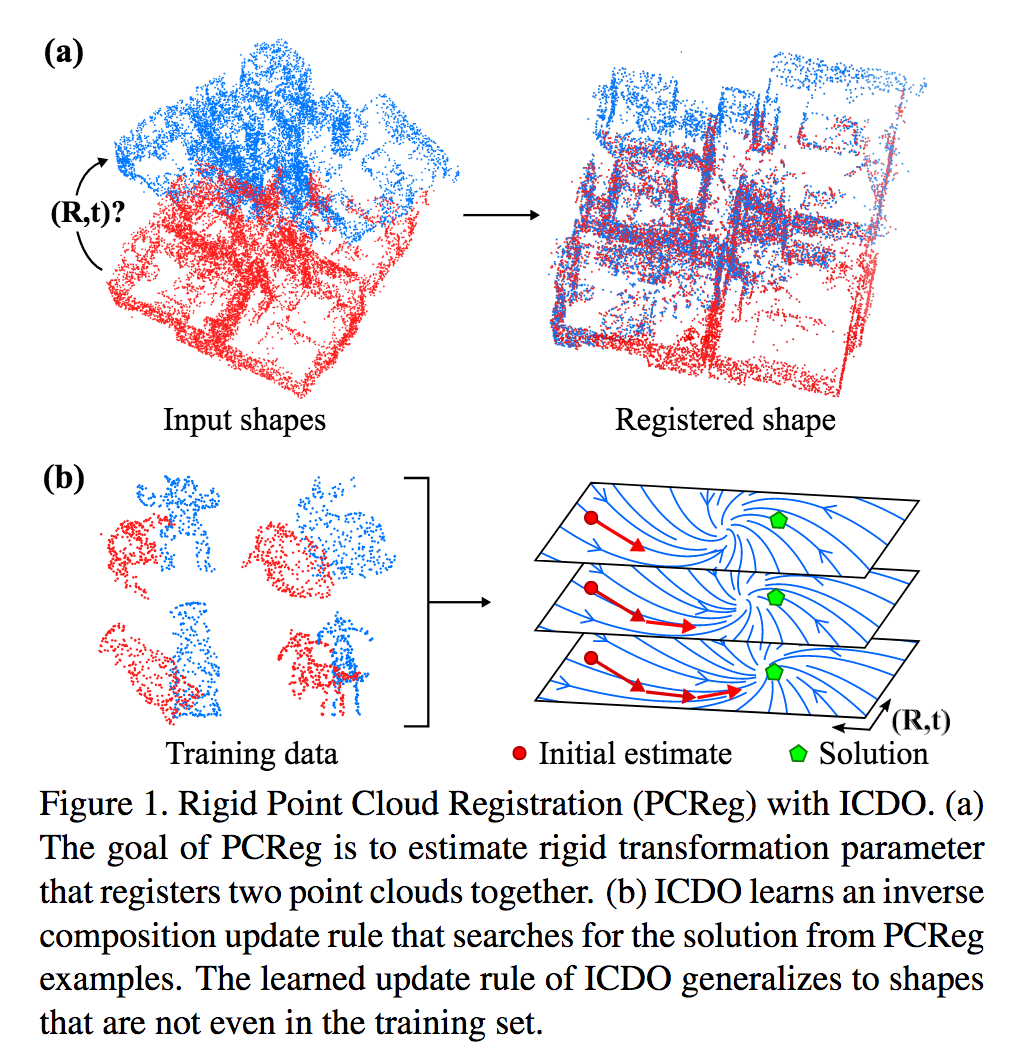
3次元点群の位置合わせ問題において、合成データを用いて学習を行うことにより、全体最適解に合わせやすくした。従来法であるDOの拡張であると主張していて、学習した物体に依存するDOに対してICDOでは物体に依存せず全体最適解に位置合わせすることができる。
Structure-from-Motion(SfM)やカメラ位置推定の一種である6DOFの姿勢推定の問題について取り組む。大抵の場合、中心座標(Principal Point)は画像の中央と決めているが、ここでは対応する4.5点(P4.5Pfuv)を基にして中心座標や焦点距離を推定する。さらにはアスペクト比を5点対応から、中心座標とレンズディストーションを7点対応から推定する。

カメラ行列に関して多項式の拘束を与えることで、4.5点対応で中心座標や焦点距離を、5点対応でアスペクト比を、7点対応(特にこれが難しい!)からは中心座標とレンズディストーションを推定した。
未校正(w/o calibration)かつ未知照明環境(unknown natural illumination)にてフォトメトリックステレオを実現するため、Equivalent Directional Lighting Modelを提案。滑らかに変化するような表面形状の復元や回転に対する曖昧性を許容した復元を可能にした。回転を考慮することでパッチの統合による曖昧性を排除して全体の表面を最適化した。図は提案手法のフロー図である。最初に光源を推定(Equivalent Directional Lighting)し、次にSVDしつつ局所的な(回転による?)曖昧性を除去、法線の空間にて行列計算・補完を行い出力する。
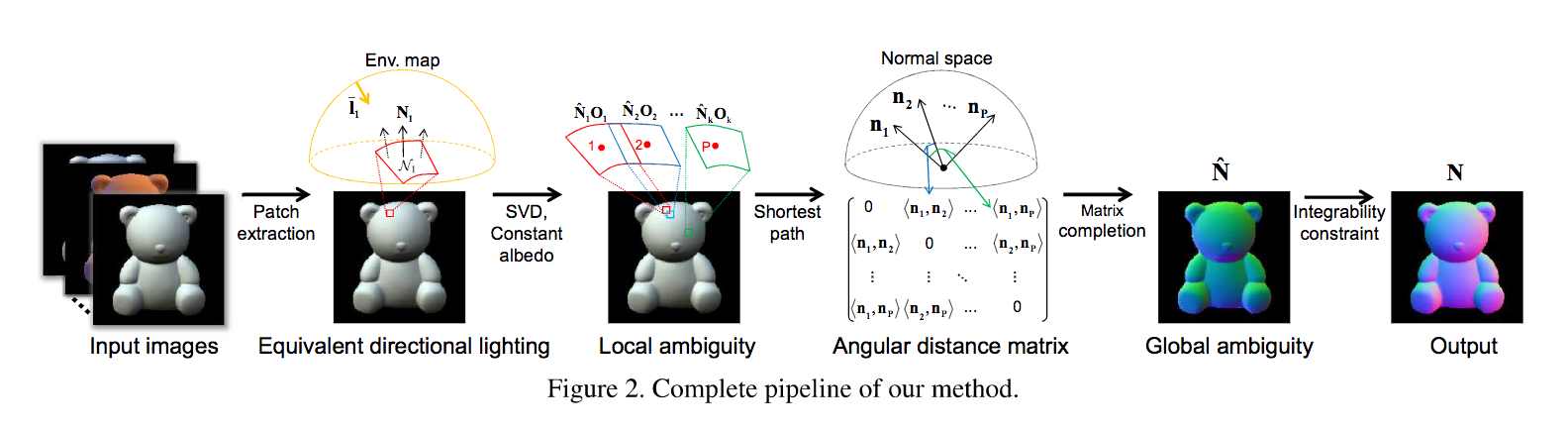
未校正かつ未知照明の環境にて、滑らかな表面形状変化を捉えるフォトメトリックステレオ手法を考案した。パッチ毎に回転の曖昧性を推定して全体の構造を把握することに成功した。
細い(Thin)構造の物体を3次元復元するためのMulti-View Stereo手法を提案。トポロジーや連結性を考慮して復元を行ない、3次元メッシュ構造を復元することに成功した。3次元カーブ再構成、4面体系(tetrahedra)を復元してCurbe-conformed Delaunay Refinementを実施する。さらに、メッシュが4面体系上に復元される。

形状が細い構造物を合成データ/リアルデータ両方のデータセットにおいて3次元メッシュ復元を可能にした。また、図に示されている通り、(細い形状を含め)表面形状を保存したままの復元に成功した。
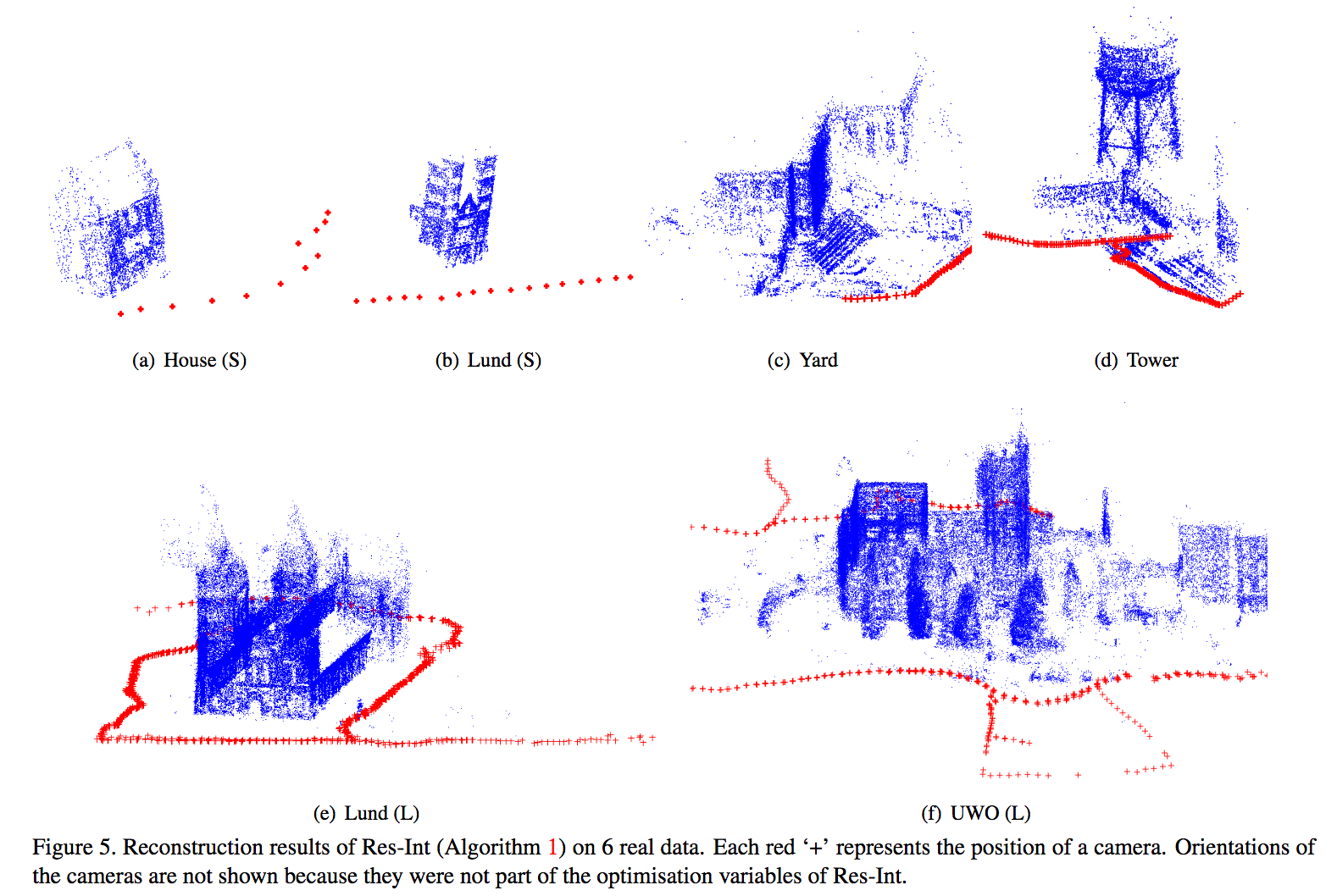
Structure-from-Motion(SfM)にてカメラ位置推定を改善する手法について、本論文ではAll-About-that-Base (AAB) Statisticを提案、重み付けの方法について検討し、カメラ方向についてずれのレベル(ここでいうCorruption levelとは?)を推定しながら位置推定を実現。これによりカメラ方向(Camera Orientation)推定、重み付けについて理論的な証明を行うこと、より高速な手法の提案が展望として考えられる。
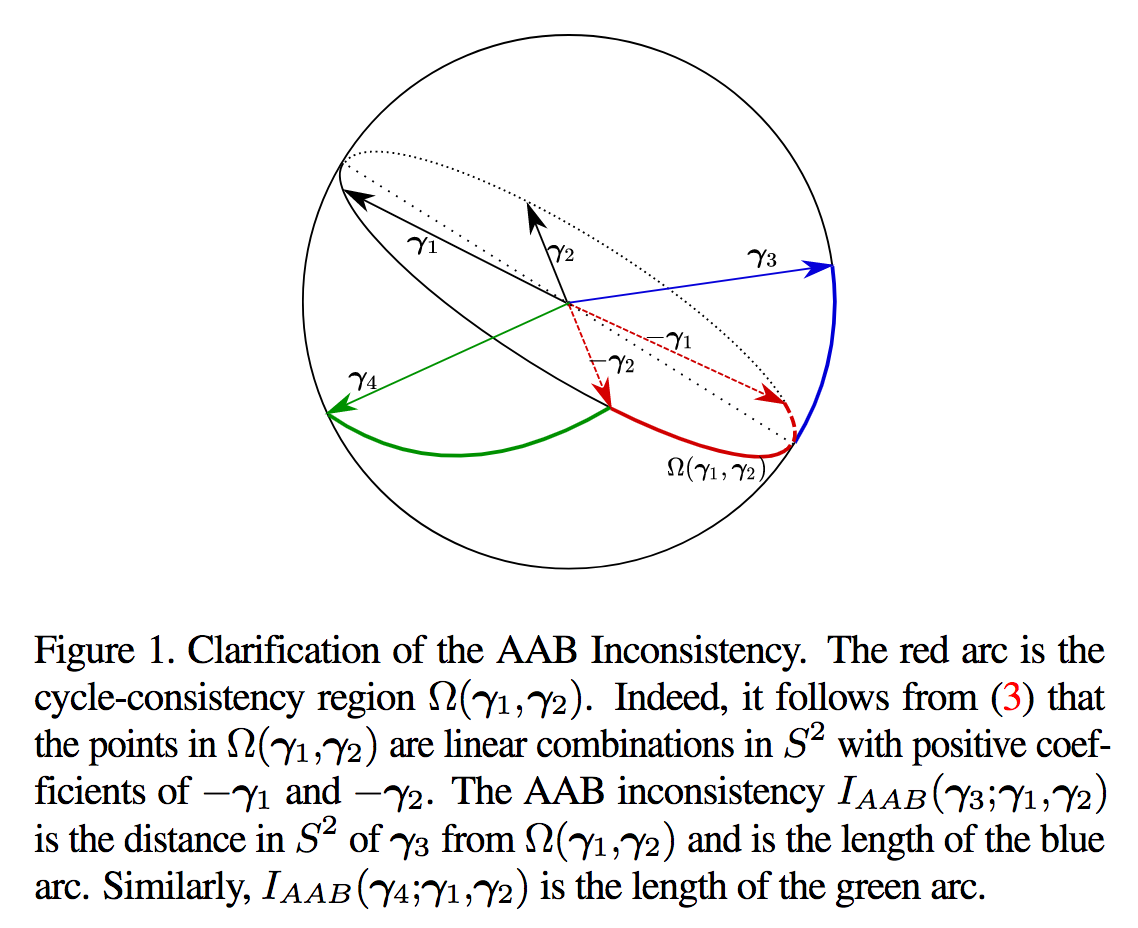
2つのカメラにおける誤差を推定して復元する重み付け方法について提案し、カメラの位置推定に寄与した。
動的環境のモーションセグメンテーションにおいて幾何的な情報をホモグラフィとして抽出、平面などをインライアとして扱いマッチングの精度を補間的に高める。従来の基礎行列の手法では(動的環境下では)困難でも、マルチビューのスペクトラルクラスタリングとの統合で相補的にモデルを改善する。

既存の基礎行列やホモグラフィといったモデルに対してマルチビューのスペクトラルクラスタリングを用いて空間の幾何構造を把握する研究である。Hopkins155, Hopkins12, MTPV62, KITTIデータセットにてSOTAな性を実現している。
本論文では3次元形状において、膨大な空間からマッチングする領域の探索問題を考える。従来では低ランク近似(Low-Rank Approximation)による手法、例としてMDS(Multidimensional Scaling)を適用してきた。本論文ではBiharmonic Interpolationによる測地距離行列を用いたSparse Biharmonic MDS(sBMDS)を提案することでより効率的な探索を実施することができる。sBMDSではデータの多様体を捉えて探索する点を大幅に抑えることができる(1.8Mx1.8M, 26TB => 50,000 landmarks, 20.9GB)。
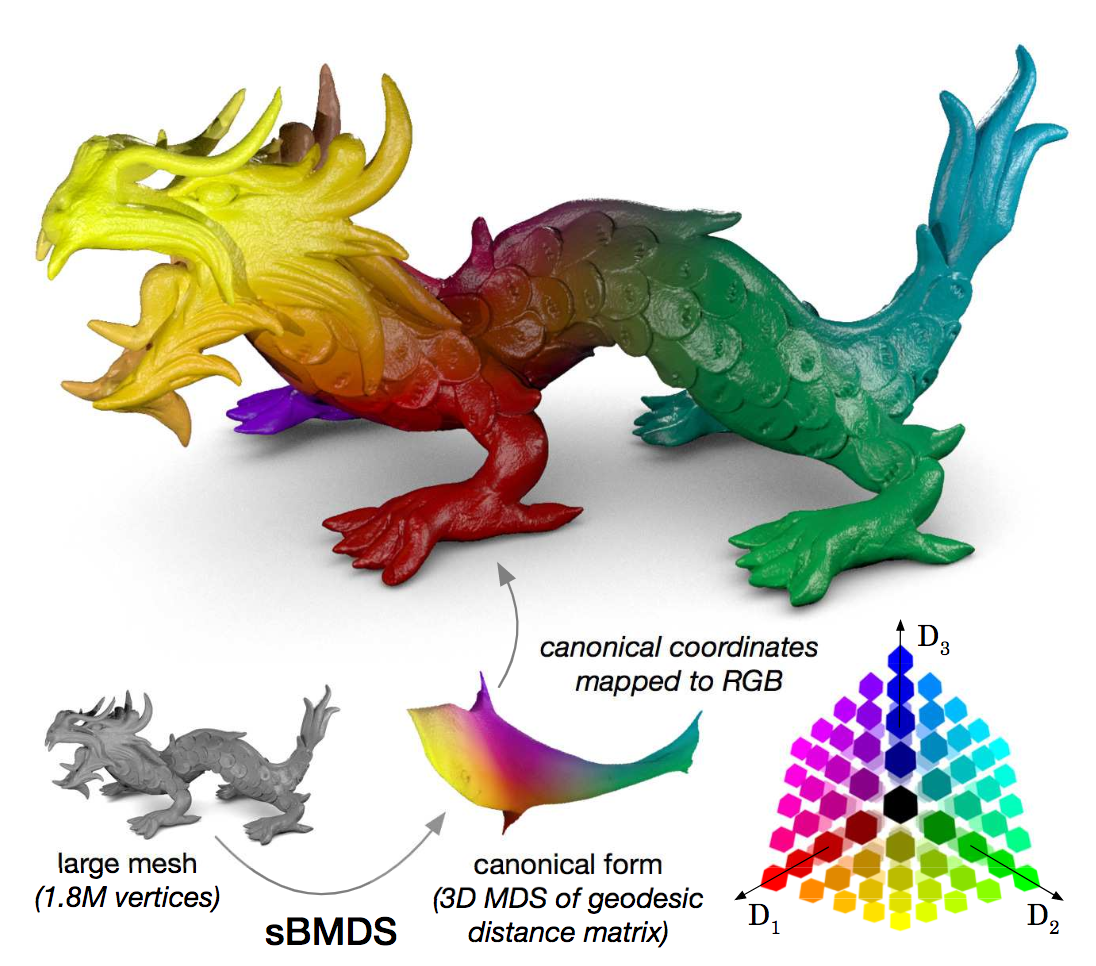
スパース補間技術であるsBMDSを提案したことで、マッチングする領域を大幅に減らすことに成功。非剛体のマッチングに要する時間は半分、メモリは20分の1になったと主張。
本論文ではスパースコーディング/辞書学習として著名なKendall's shape spaceを用いて3次元関節点を入力とした人物行動認識に取り組む。Riemannian幾何による形状空間を構築してスパースコーディング/辞書学習を提案。行動認識を実現するために、Fourier temporal pyramidを施した後にBi-directional LSTMやLinear SVMを適用する。
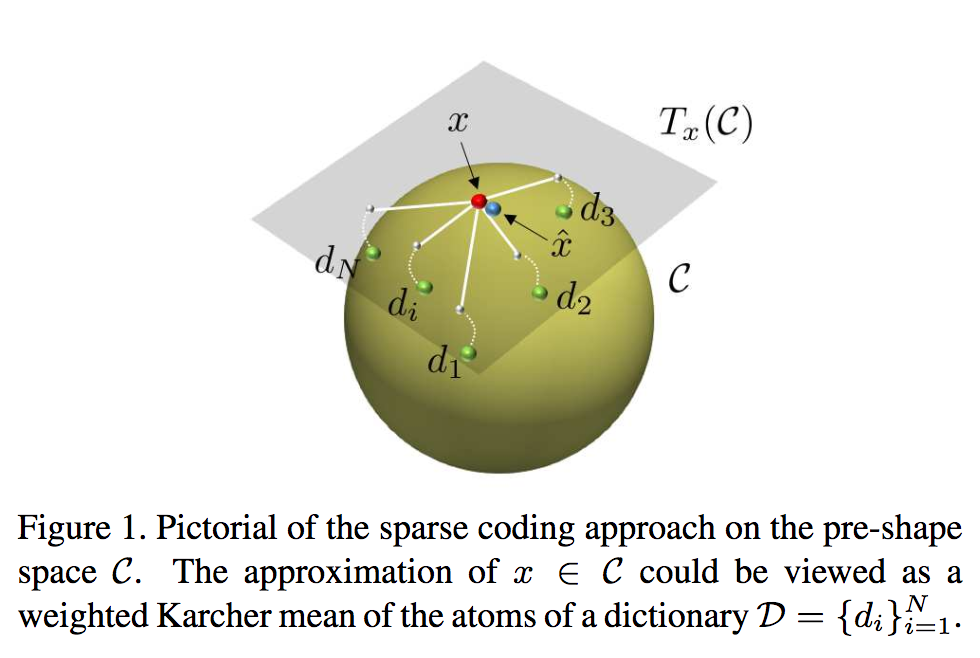
3次元関節点を入力とした人物行動認識の文脈において、Riemannian辞書によるスパースコーディングを実装したことで非線形空間をスパースかつ時系列情報のユークリッド空間にて取り扱うことができた。
紙やシャツなど柔軟な物体に対する形状変化を3次元的に捉える手法を提案した。従来法とは異なり、表面形状に関してテンプレートを準備する必要がないこと、テクスチャ欠損や部分的オクルージョンに対して頑健である。幾何的な変化を捉えるために、基本的に深層学習をベースとしており、2次元画像でのメッシュ検出、3次元形状の復元を実行する。形状変化、材質、テクスチャや照明条件の変化が入る空間を含んだ大規模データセットにて深層学習アーキテクチャをEnd-to-Endで学習。右図は提案手法の概要を示している。ネットワークは主に2次元画像中で位置を特定する2D Detection Branch、3次元的な幾何情報を復元するDepth Branch、非剛体形状を復元するShape Branchから構成される。
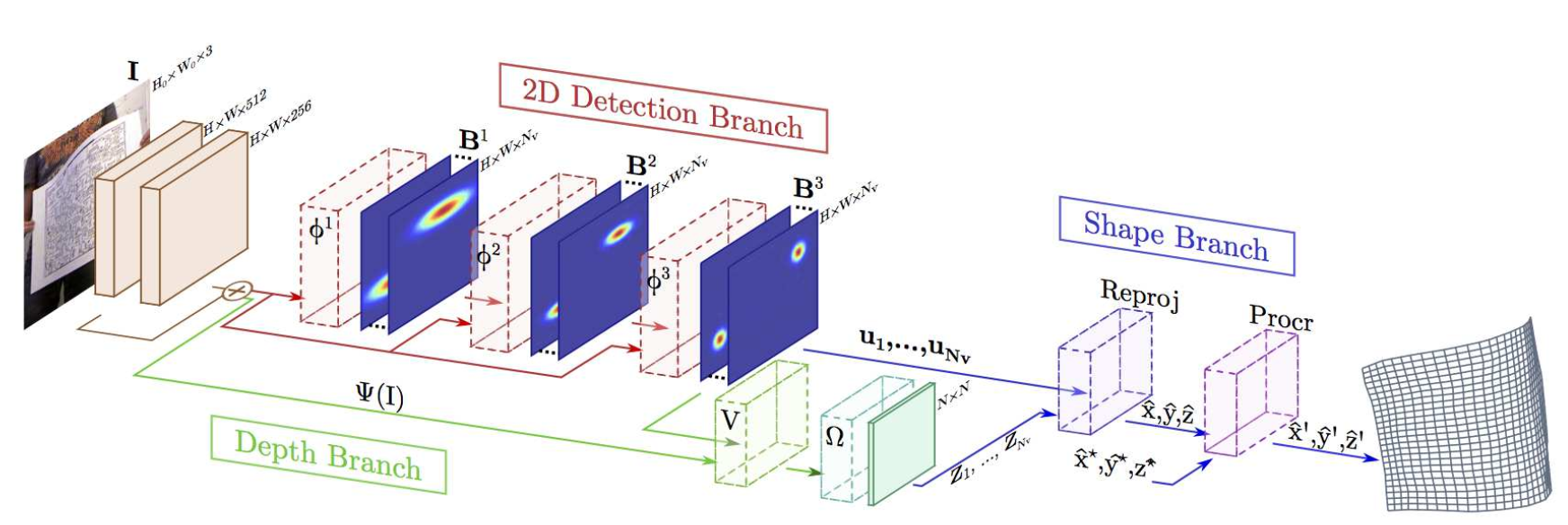
End-to-Endかつリアルタイムな3次元表面形状復元手法を提案。実空間にて撮影したベンチマークにてState-of-the-artな表面形状トラッキングを実現した。現在まではEnd-to-Endな学習が難しいとされていたが、幾何的な情報を復元するに特化した構造とそのためのデータベースを構築したことが評価された形となった。
CNNのフォワード(のみ)によりステレオマッチングの出力である距離画像を出力する取り組み。従来のステレオマッチングでは左右画像マッチング、視差計算、距離画像修正により構成されていたが、CNNにより大幅に処理コストを削減する。提案のネットワークでは4つのパーツから構成され、マルチスケールで重みを共有しながら特徴計算を行い(Multi-scale Shared Features)、左右画像のマッチング(Disparity Estimation)、距離画像修正(Disparity Refinement)、距離画像の最終出力(Disparity)を実施する。アーキテクチャについては右図に記載されている通りである。
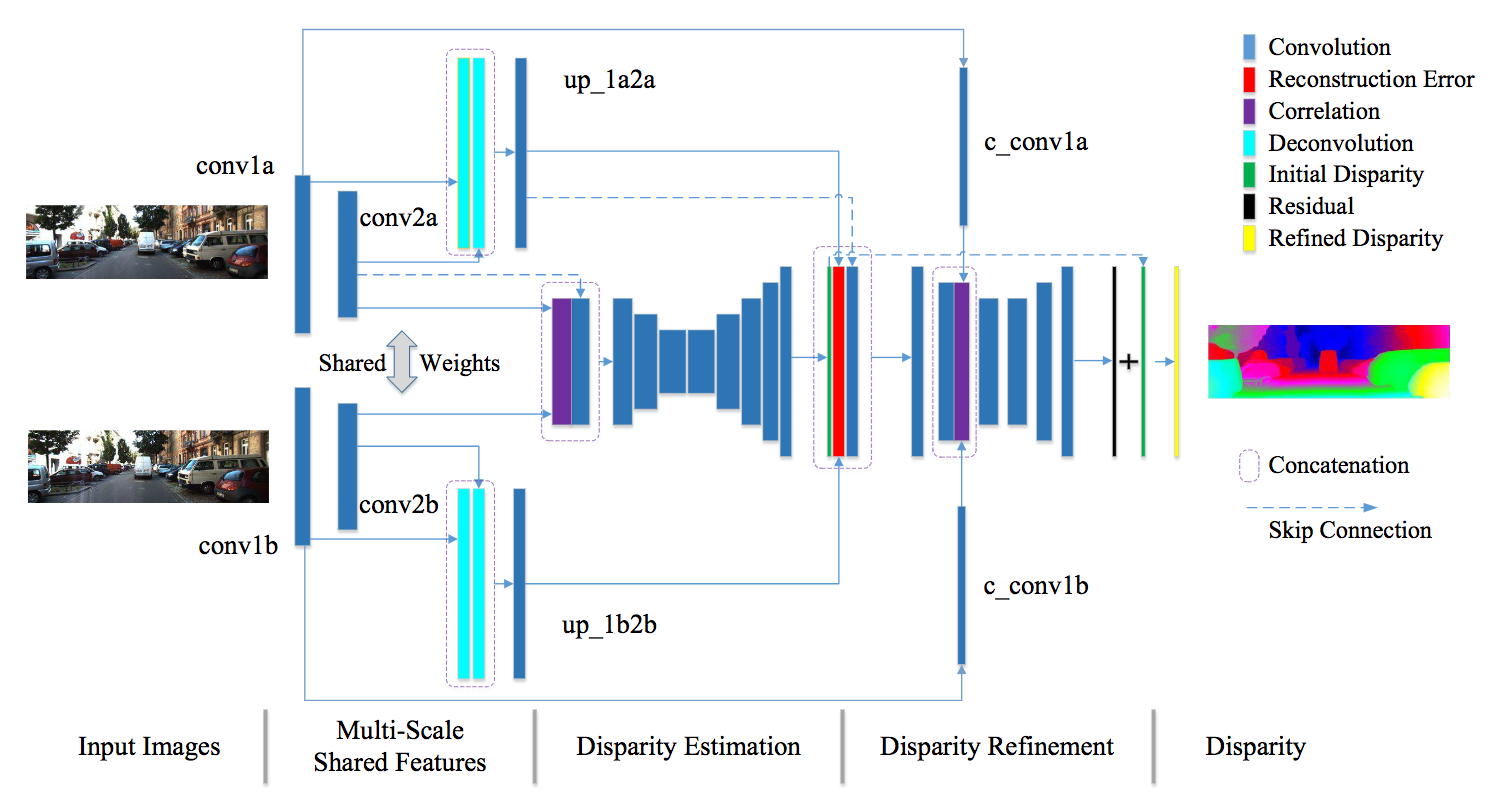
距離画像計算を一回のCNNのフォワードで実施するネットワークを構築し、ベンチマークであるScene FlowやKITTI datasetにて(論文投稿時)State-of-the-artな精度を実現した。グレースケールの色の一致性、勾配の一致性や特徴空間における恒常性(Feature Constancy)を考慮した結果、CNNによるステレオマッチングの出力が向上したと主張。
データの数や質によってはオーバーフィッティングを起こしてしまうが、本論文ではLow-Dimensional Manifold-Regularized Neural Network (LDMNet; 低次元の多様体により正則化を実行するネットワーク)を提案することで特徴量や入力データに対して正則化を行う取り組みである。外的なパラメータなしに多様体を探索することが望ましいが、ここではEuler-Lagrange方程式は計算的な複雑性を上げることなくポイントクラウド計算にてLaplace-Beltrami方程式と等価(ここ自信ない)であることを示した。実験においてLDMNetは異なるモダリティ、例えばCross-spectralな顔認識において有効であることが判明した。右上図はweight decay/DropOutなどによる正則化手法と比較した結果である。LDMNetは特徴量をもっともよく識別する空間に配置する多様体を構成できている。
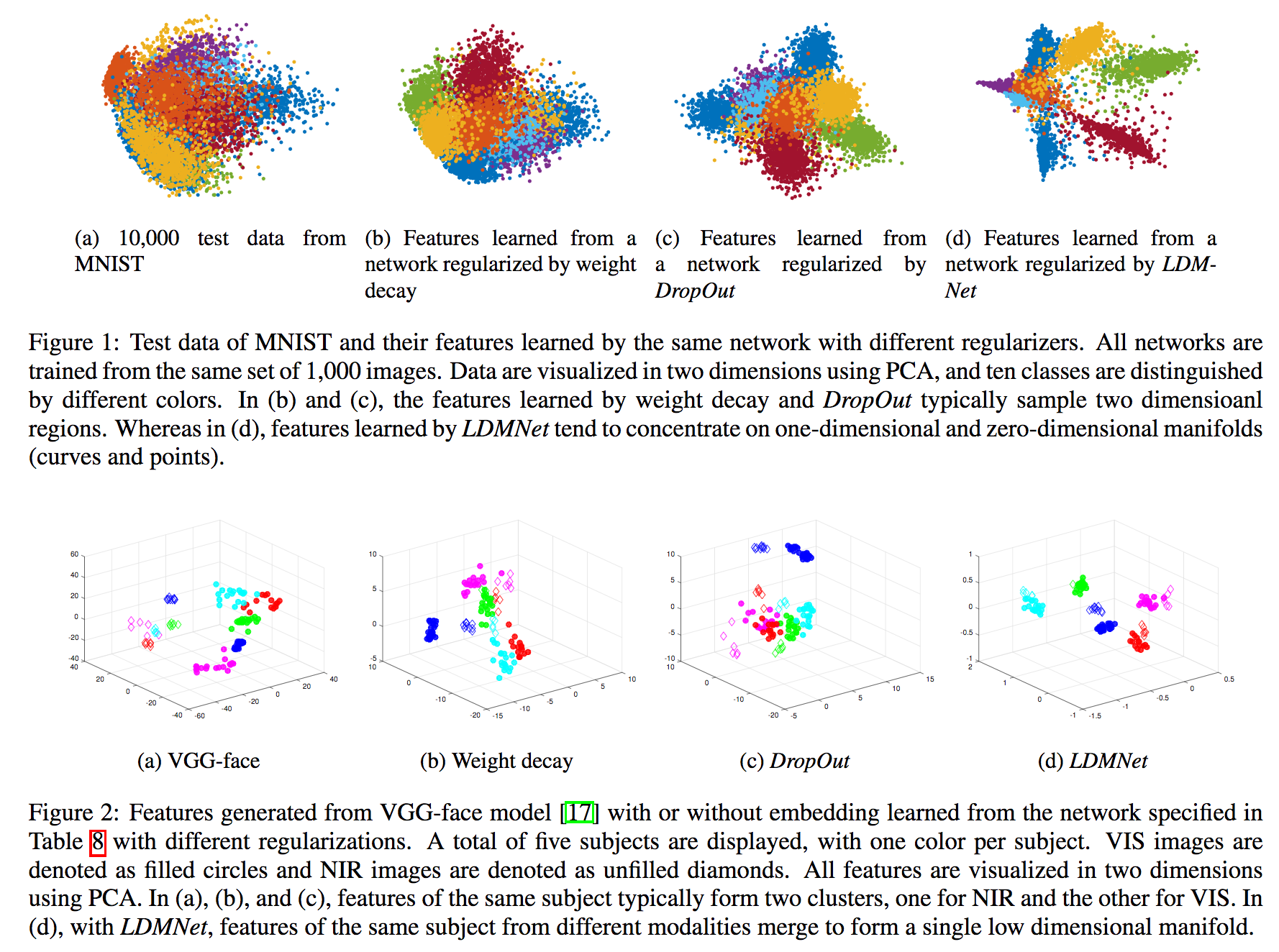
低次元の多様体空間を構成することで、入力データには(できる限り)依存せずデータ/特徴空間に関する正則化を行うことができるLDMNetを提案した。より少ない画像枚数の学習にて良好な精度を実現することが明らかとなった。各カテゴリ50枚のMNIST学習にて95.57%を実現(ベースラインは91.32%/92.31%)した。
Integer(int)演算によるニューラルネットの効率的な量子化および学習の提案である。Int演算でFloat演算よりも効率的な計算を可能とした。同様に、End-to-End学習についても精度を保持しつつ演算の高速化にも成功、accuracy/latencyのトレードオフについても効率的な解決策となった。関連研究であるMobileNetについても効率化に成功し、ImageNet/MSCOCOにてCPU実装をデモした。
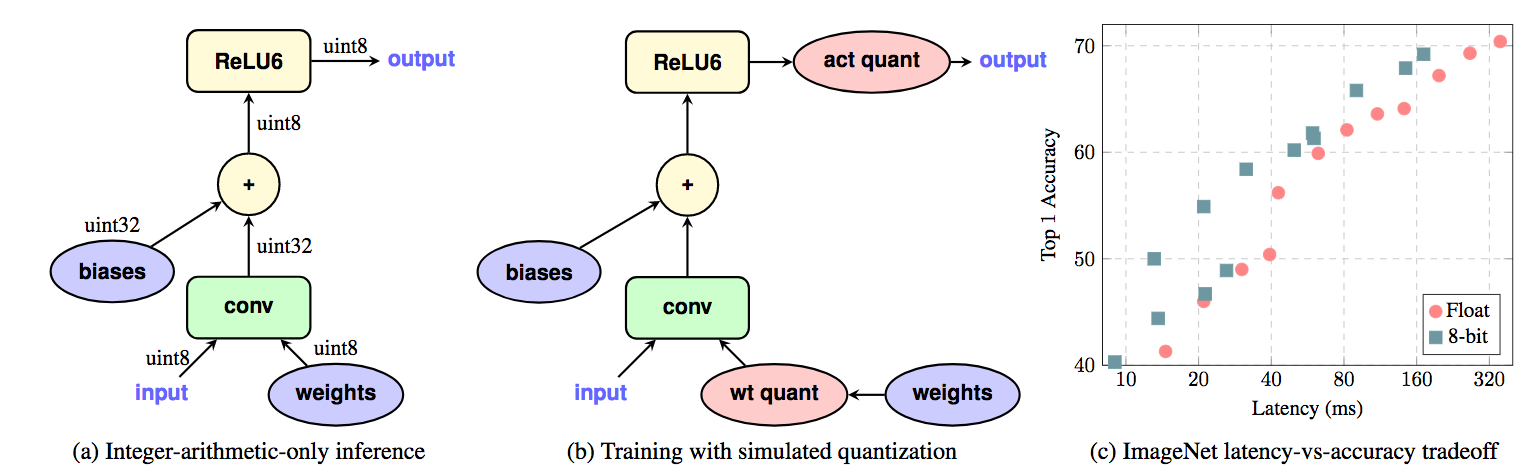
8ビットInt型の演算のみでニューラルネットの学習を実施。学習/推論においてFloat型の精度/速度を凌駕する性能を発揮した。さらに、MobileNet等の効率化されたアーキテクチャについてもより効率化を実現した。
さすがにGoogleは保有データのみでなく、アルゴリズム面においてもトップを行っている。データあり、資源あり、人ありでその上分野を網羅的に攻めることができている。
非剛体物体の3次元再構成について、人物のみでなくインタラクションしている物体に対しても密な復元を行う手法SobolevFusionを提案。さらに、従来法とは異なり、勾配をL^2の内積で定義し変化をSobolev spaceで扱えるようにしたこと、RGBのテクスチャも貼り付けることが可能になった。Variational Level-setにて領域の切り抜きを実施し、復元方法はTruncated Signed Distance Field (TSDF)を投影することで行われる。この流れはDynamicFusionやKillingFusionから来ている。
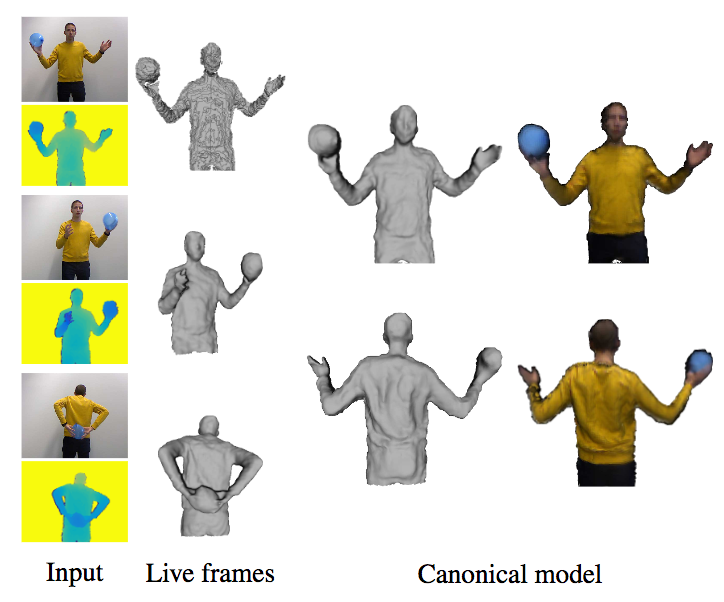
DynamicFusion/KillingFusionを改良したSobolevFusionを提案した。変化した3D空間をSobolev空間で扱えるようにして動的な空間に関して詳細まで復元することに成功した。
ピクセル同士のマッチングをピクセルの共起性に着目して行う手法を提案した。ピクセルの出現頻度で正規化された共起行列を用いることでテンプレートマッチングを行う。 その際、Multi-dimensional scalingを用いてマッピングを考えることで、画像を別空間に投影して扱うことを可能にする。
![]()
RGB空間だけでなくDeep featuresなどピクセルとして表現されるあらゆるものに適用可能である。したがって、これまでに提案されてきたあらゆるCVの手法(論文中ではLucas-Kanade法及びKCF trackerを紹介)を使用することが可能である。
霞んだ大気が写っていると認識タスクなどではノイズとなりうるケースがあり、除去する必要がある。そこで以下の手法を用いてSoTA達成し、End2Endで学習を行える除去方法を提案した。 画像を数式化し、それを解く手法をDensly Connected Pyramid Dehazing Networks(DCPDN)とした 霞んだ画像のEdgeなどの構造(TransmissionMapEstimation)と、霞など(AtmosphericLightEstimation)に分離して特徴量を獲得し、それら2つからDehazeImageを作成。 その後、DehazeImagerとEstimation、2つのペアの構造が似ているかをJoint-Discriminatorで識別し学習する。 また、Edgeは画像に分け目でありImageGraduentsに特徴付けらること、輪郭やEdgeのようなlow-levelな特徴量はCNNの最初の方の層で抽出されることの2つの背景から Edgeの特徴量を豊富に学習できる、ImageGradientを取る関数、VGGでcontent featureを取る関数の和であるEdge-preserving Lossを提案を提案した。
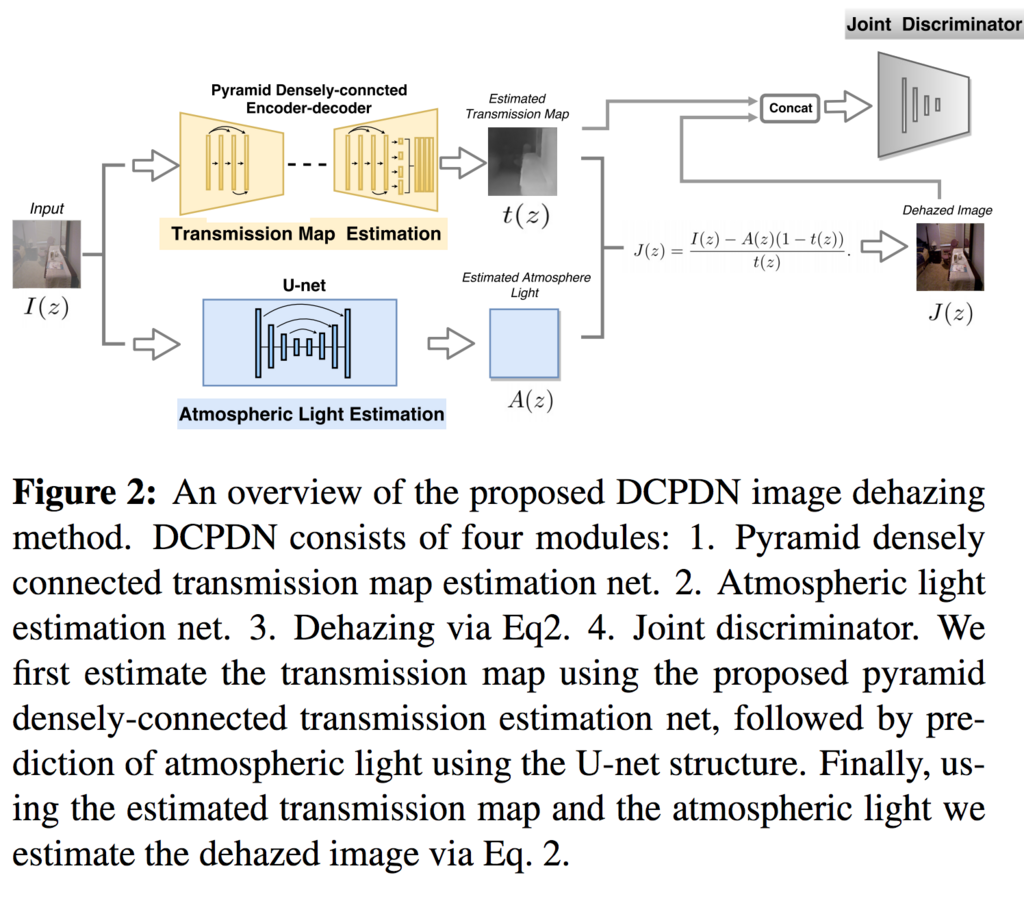
SSIMでの比較結果が最も高く、結果を見ても綺麗であった。Edge-preserving LossとJoint-Discriminatorがうまく寄与していた。
画像内のガラスの反射は,CV分野にとって脅威となる.この問題を解決するためにConcurrent Reflection Removal Network(CRRN)を提案.人間の知覚に影響を考慮したロス関数を用いて、画像の外観情報とマルチスケールの勾配情報を統合し、多様な実世界のシーンで撮影された3250枚の反射画像を用いて学習したものである.公開されているデータセットを用いて実験したところSoTAを示した.
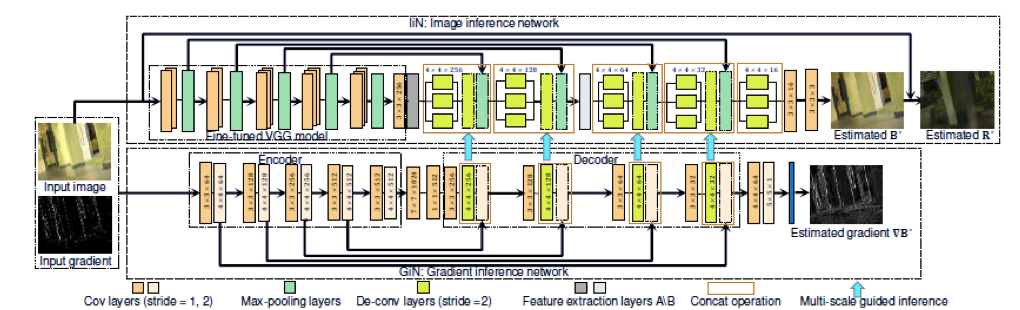
Person re-identification(ReID)のためのdata augmentationの方法を提案した。ReIDの難しさの一つとして、カメラの違いなどにより様々なocclusionが発生することである。 そこでocclusionを発生させた学習データを作ることで精度向上を計る。 始めに、通常通りReIDの学習を行うことでネットワークが画像のどの領域に注目するかを調べる。 明らかになった注目領域を塗りつぶすことでocclusionとし、学習しなおすことでocclusionに頑健な学習を実現する。
従来手法では上半身など画像の一部の領域にのみに注目していたため、注目領域にocclusionがあると精度が下がったのに対して、提案手法により画像全体に注目するようになりocclusionに頑健になった。実際、Rank1 accuracy, mAPどちらもベースラインと比べ数値が向上したことを示した。
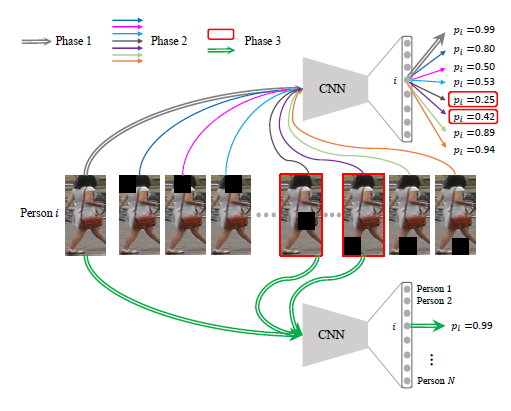
1枚画像からの行動認識を、類似する動作の記憶を手がかりに行うHybrid Video Memory(HVM)を提案した。 人間は未知の光景に遭遇したとき、過去の記憶を手がかりに類似したものから類推することができる。 HVMは人間のこのプロセスを模倣し、数枚しかない学習データを類似する動作と関連付けることで学習を可能にする。 学習済みTwo-stream CNNに1枚画像を入力し、Memory動画とSpatial Featureを比較することにより類似する動画へ重み付けを行う。 この類似する動作から得られるTemporal Featureの重みつき和を入力画像のTemporal Featureにする。 行動の予測は得られたTemporal Featureと学習画像及びMemory動画のTemporal Featureの類似度により各動画への重みを決定し、学習画像及びMemory動画のラベルの重み付き和を出力ラベルとする。
UCF101をMemory動画として、WEB101, VOC, DIFF20の3つの画像データセットに対する行動予測を実施。いずれのデータセットに関しても、従来手法と比べ提案手法が最も精度が高い(WEB101 35.4%, VOC 42.2%, DIFF20 60.2%)結果が得られた。
動画認識のために物体同士のinteractionを表現する方法を提案した。画像中の物体同士の関係を記述する方法は多く提案されているが、動画の場合全フレームに適用してしまうと情報量が多すぎて現実的ではない。 そこで動画に写っている物体同士の関係を高次な特徴として取得することで動画認識に利用する。 動画の各フレームから物体認識によりROIを取得し、K個のMulti Layer Perceptronに画像特徴とLSTMの過去の出力を入力する。 得られた各特徴をLSTMに入力することで物体同士の関係を表すattentionを得る。

論文中ではAction Recognitionとキャプショニングの2つのタスクを提案した。Kineticsを用いたAction Recognitionは、既存手法(1FPSにサンプリングした)よりもTop1, 5共に提案手法の方が精度が高い。 キャプショニングはMETEOR, ROUGE-L, CIDEr-D, BLEU@Nの4つのデータセットで実験をし、Validation setの精度は向上したがTest setの精度が高いLSTM-A3には劣る部分がある。
動画中からコンテキスト情報を取り除き動作そのものから行動を推定する手法を提案。行動認識において、背景などのコンテキスト情報は識別のための重要な手がかりである。 しかし、学習データが似たようなコンテキストのものを多く含んでしまうと、実際には動作が違うにもかかわらず背景などによって異なる動作を認識してしまう。 そこで動画を行動とコンテキストに分解し、行動のみから識別を行う。 行動とコンテキストそれぞれのラベルをつけた学習データを用意するのは困難なため、同じ動画からアクションを含む部分(action sample)と含まない部分(conjugate sample)を考える。 ネットワークとして行動に関する特徴とコンテキストに関する特徴を抽出するものを考える。 行動特徴に関しては、conjugate sampleには注目のアクションを含まないため2つのsampleから抽出した特徴が類似しないように学習する。 一方でcontext sampleに関しては2つのsampleは背景などを共有しているため類似するように学習する。 これに加えてaction sampleから得られる2つの特徴を用いた行動識別を考え、classification lossとする。
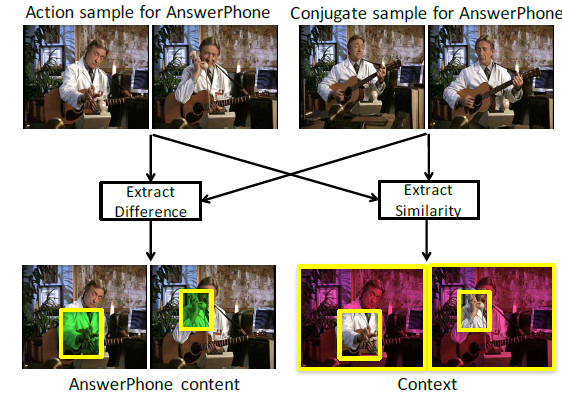
ActionThread datasetで実験し、13の行動のうち10の行動が提案手法のprecisionが最も高かった。UCF101, Hollywood2を用いてconjugate sampleをaction sampleの隣接するセグメントにとして行った実験も提案手法の精度がベースラインを上回った。
action segmentationのためのネットワーク、Temporal Deformable Residual Networks(TDRN)を提案した。動画の各フレームからCNNにより抽出した特徴を入力とし、two-streamの構造で特徴を処理していく。 Temporal Residual Streamは、動画のfull scaleのコンテキスト情報を解析する。 Temporal Pooling Streamは、時間方向のPooling, Unpoolingを複数回施すことにより時間方向に関して様々なスケールのコンテキスト情報を解析する。
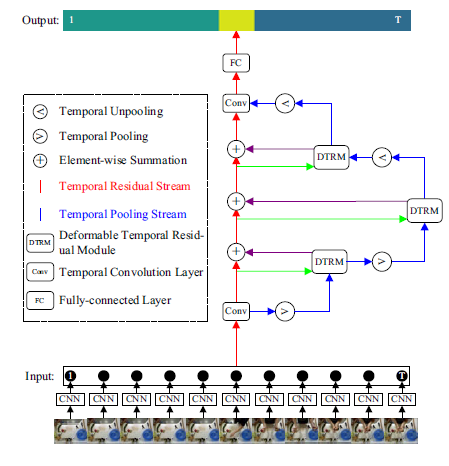
従来のネットワークは1つのstreamで処理するのに対して提案手法は2つのstreamで処理する。さらに2つのstreamは独立してるのではなくTemporal Pooling Streamに逐次Temporal Residual Streamから得られた特徴を入力していく。 50Saladas, GTEA, JIGSAWSの3つの動画データセットで評価し、F1, Edit score, Accuracyの3つの指標いずれも従来手法よりも向上した。
Kantorovich-Wasserstein metricに基づいて高次元データを微分同相写像により表現する手法を提案した。K-meansによりクラスタリングされたK個の接平面毎にテンプレートとなるベクトルをprobablistic PCAにより学習する。
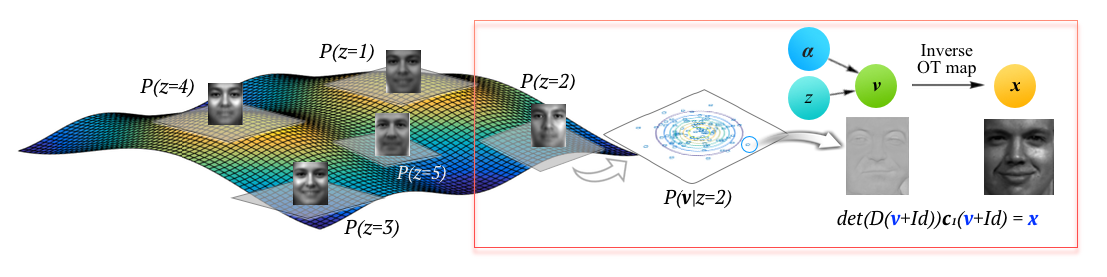
MNIST, ADNI PET, NUCLEIの3つのデータセットにより評価。少ない学習データから提案手法によりデータ数を増やし識別タスクの精度を上げることに成功した。 確率モデルを考えるためBayesian Classificationを可能とし、Logistic Regressionより精度が高いことを確認した。
DayとNight、OutdoorとIndoorなど2種類の3次元モデルのregistrationをする手法を提案した。入力として3次元のsemantic labelを考え、各ラベル領域の点郡を楕円によって近似する。 このとき、点郡から得られるConvex Hullの内側の楕円Inner Ellipsoidと外側の楕円Outer Ellipsoidを考える。 2つの3次元モデルsourceとtargetの楕円をそれぞれInnerとOuterと考え、InnerがOuterの内部に存在する場合をラベル同士が対応していると考える。 この対応してる楕円の数が最大になるような変換を考えることでモデル間のregistrationを実現する。

合成データのテストでは、楕円数が少ないときは1秒以下で計算が可能であり、多い時でも従来手法よりもoutlier ratioが70%程度までは早い計算が可能である。精度に関してもICPよりRMSEが小さいことを確認した。 リアルデータのテストではrotation errorは最大で3°以下、translation errorとscale errorは3%以下であった。 計算時間はおよそ2から5分程度である。 何故Analyzing Humansのセッションなのだろうか?
3次元の曲線を3次元の表面にregistrationするための手法を提案した。曲線(表面)上の点を、点に加え微分情報を表すvector(法線もしくは接平面)のpoint+vector(2-tuplesと呼ぶ)と考える。 2点の2-tuplesを考え、4つのパラメータにより表現して対応曲線と表面上の点が対応しているかの判定を行う。
ノイズがある場合、ない場合どちらにおいても、元のデータよりも点の数が減っていると従来手法は精度が下がるのに対して提案手法は点の数が少なくなっても精度が下がりにくい。計算時間は、オフラインのプロセスが0.3~1.9sであり、オンラインのプロセスは10^0から10^-1のオーダーで計算できる。 curve vs curveやsurface vs surfaceのregistrationにも発展させることが可能である。
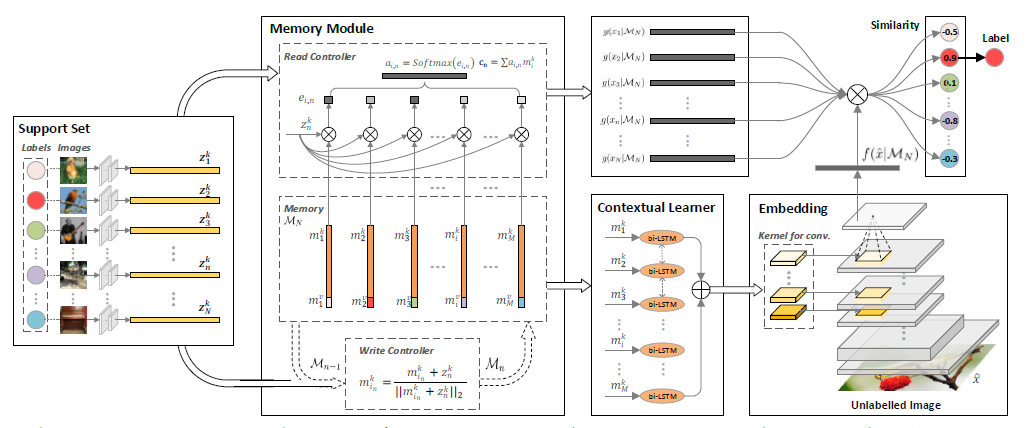
One-shot learningでよく用いられる評価時の設定(C-way k-shot, Cカテゴリで各カテゴリk枚の画像を教師に,入力画像のカテゴリを推定する)と同じ条件で学習を行うため,Memory Networkとbi-LSTMを用いたMemory Matching Networks(MM-Net)の提案. 学習時,学習データから数カテゴリ・カテゴリ毎数枚の画像が教師データとして選択され(support set).embeddingされたrepresentationがmemoryに書き込まれる. 入力画像のカテゴリ推定は,メモリから読み出した各教師画像のrepresentationと,入力画像から得たrepresentationの対応(matching)を取って行う. この際,入力画像からrepresentationを得るCNNのフィルタのパラメータは,メモリから読み出した教師画像のrepresentationの列からbi-LSTMで推定する. 評価時も,学習データからsupport setを選択する操作を除いて,学習時と同じ手順で行う. Omniglotの多くの条件でSOTA,miniImageNetにおいてもSOTA.
・ 超解像やノイズ除去などのLow-level VisionのためのDualCNNの提案・ DualCNNでは全体の構造の推定,細部の推定をそれぞれ行い超解像やノイズ除去などのタスクに応じた定式化を行い画像の生成を行う

・従来の超解像やノイズ除去はそれぞれタスクに特化したアーキテクチャが考案されていたが,本手法では1つのネットワークで最先端の手法と同等の精度を実現
密集した物体を追跡するタスクを行うため、蜂の巣を撮影し、映像中の蜂についてそれぞれの位置と方向がラベル付けされたデータセットを構築したのち、CNNで追跡するタスクを行った論文。実験の結果、人間と同等の精度で密集した蜂を追跡することに成功した。
![]()
セグメンテーションを行うU-Netの構造と類似しているが、ネットワークサイズを94%削減したネットワークに対して、物体の同定と向いている方向に関する損失関数を設計した。向いている方向の精度を向上させるため、再帰的なフレームワークを導入することで人間と同等の精度を達成した。
クラス分類タスクに対してLow-Shot Learningを行うためのWeight Imprintingという技術を提案した論文。Low-Shot Learningは予め十分な量のデータが与えられて学習した後に、データ数が非常に少ない分類すべき新しいクラスが与えられ、その上でそれらを分類するタスクである。Weight Imprintingはすでに学習したクラスの部分に変更を加えないため、学習コストが少なく、少ないデータ数で学習可能である。
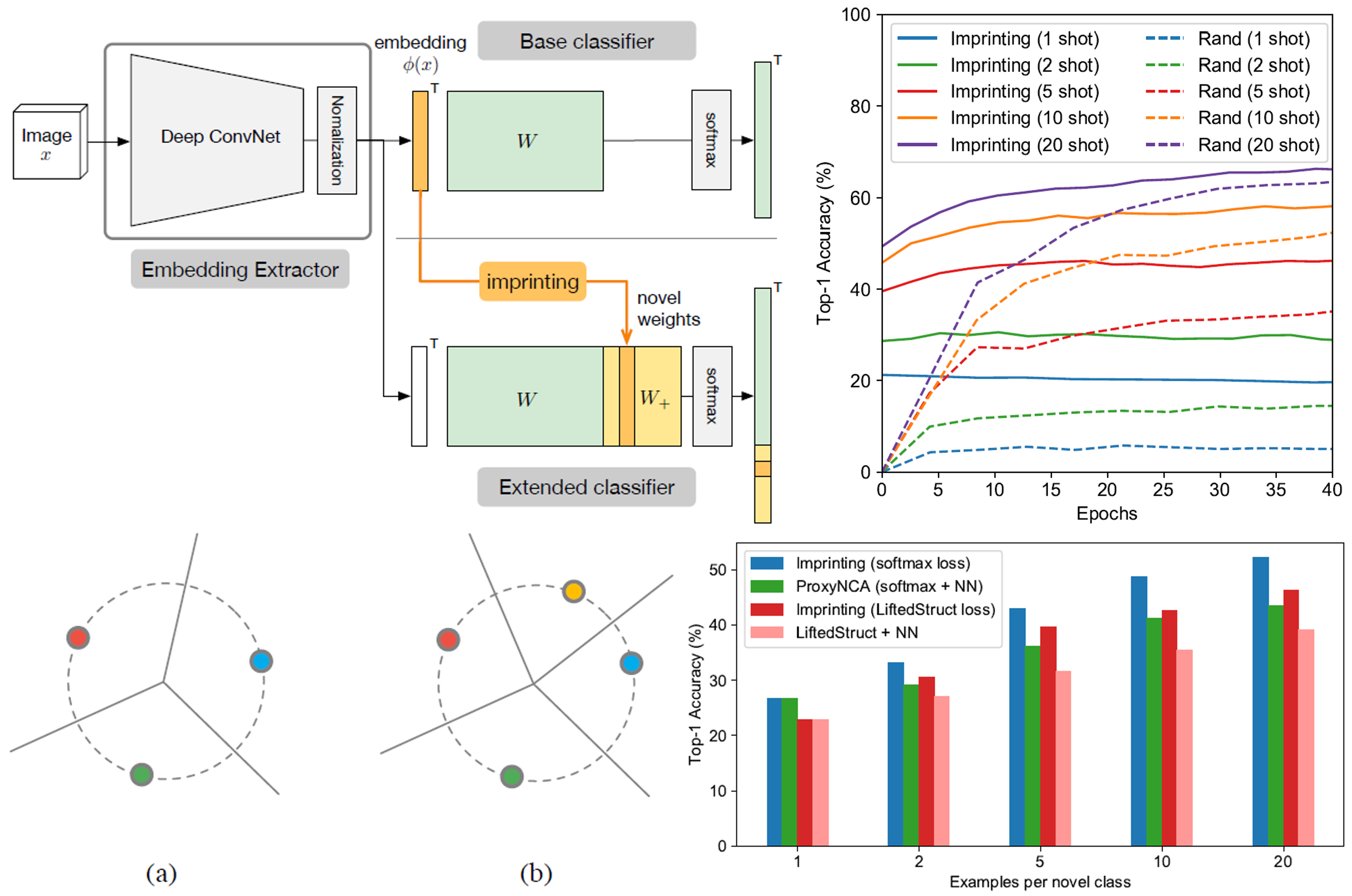
Weight Imprintingはクラス分類器に適用する手法である。通常のCNNによるクラス分類器と異なる点は、畳み込み層から得られた特徴量を正規化する点と、バイアス項のない全結合層である点である。バイアス項がないため、重み係数は正規化された特徴量のテンプレートとして機能する。したがって、分類すべき新しいクラスが与えられたときに、その正規化された特徴量をそのまま重み係数とすることができる。複数のサンプルが与えられた場合は平均を計算して、重み係数とする。Weight Imprintingはテンプレートとして機能する重み係数との内積をが最大となるクラスを推定結果とするため、Nearest Neightborと同等の機能を持っている。
データサイズに依存せず、RANSACを定数時間で行えるようにした論文。RANSACのボトルネックはサンプリングした仮説を検証するステップにあるため、従来その検証を高速化する手法が提案されてきたが、提案手法は検証を行う前に潜在空間でフィルタリングを行うことで妥当な仮説のみを検証することで高速化を行った。
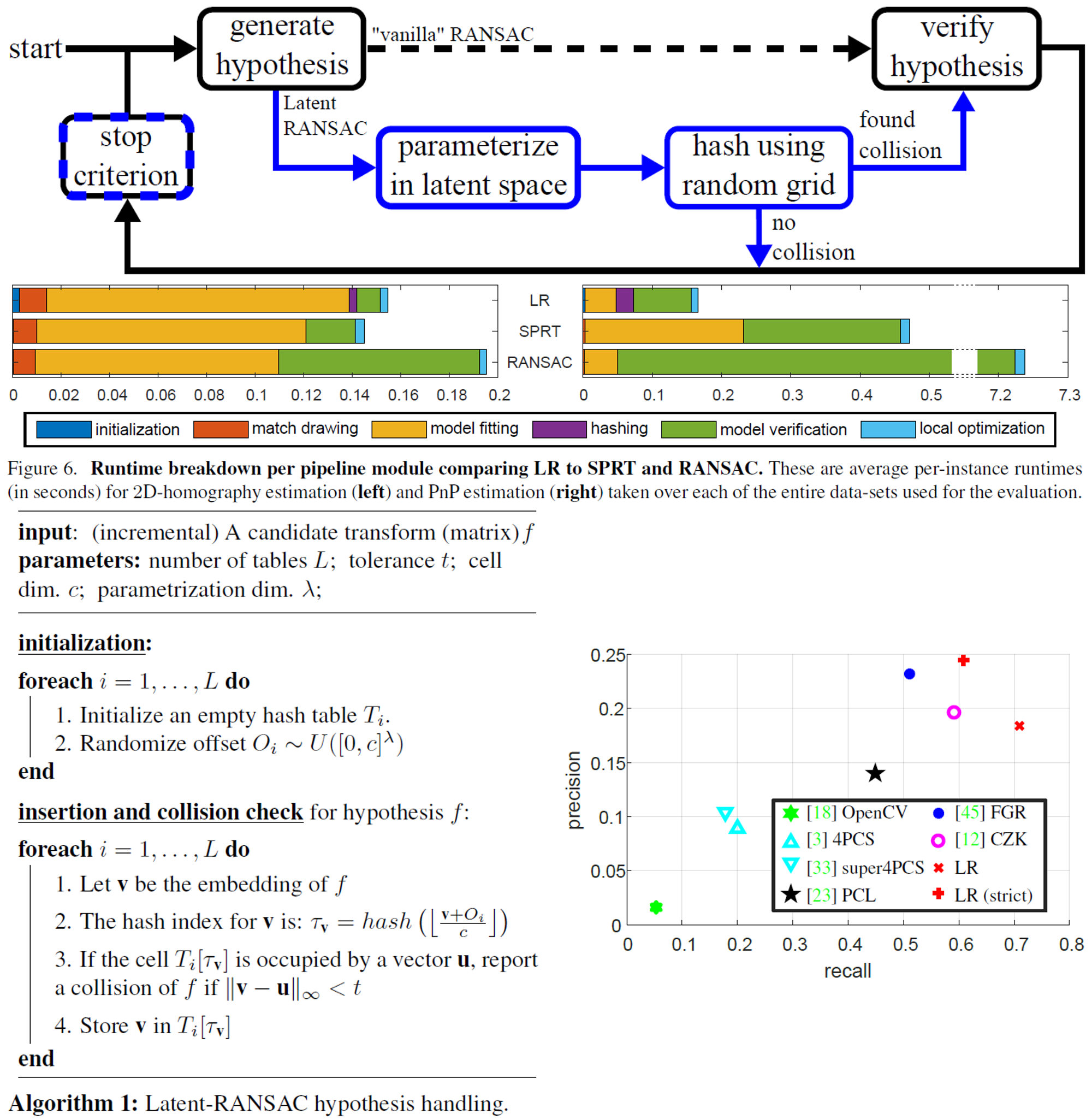
従来のRANSACでは全ての仮説を検証していたが、提案手法ではそれを高速にフィルタリングする。このフィルタリングのプロセスは、まず潜在空間上にパラメータ化し、それに対してRandom Grid Hashingを用いて、現在の仮説がそれ以前に生成された仮設と衝突するか否かを検証することで行われる。この検証前のプロセスの改良に伴い、それに適した探索を終了する基準も提案した。
ニューラルネットワークにおけるTemporal Match Kernelを再考し、動画の比較や位置合わせができる学習可能なTemporal Layerを用いた手法(LAMV:Learnable to Align and Match Videos)を提案した論文。Video Alignment、Cody Detection、Event RetrievalのタスクでSoTAを実現した。
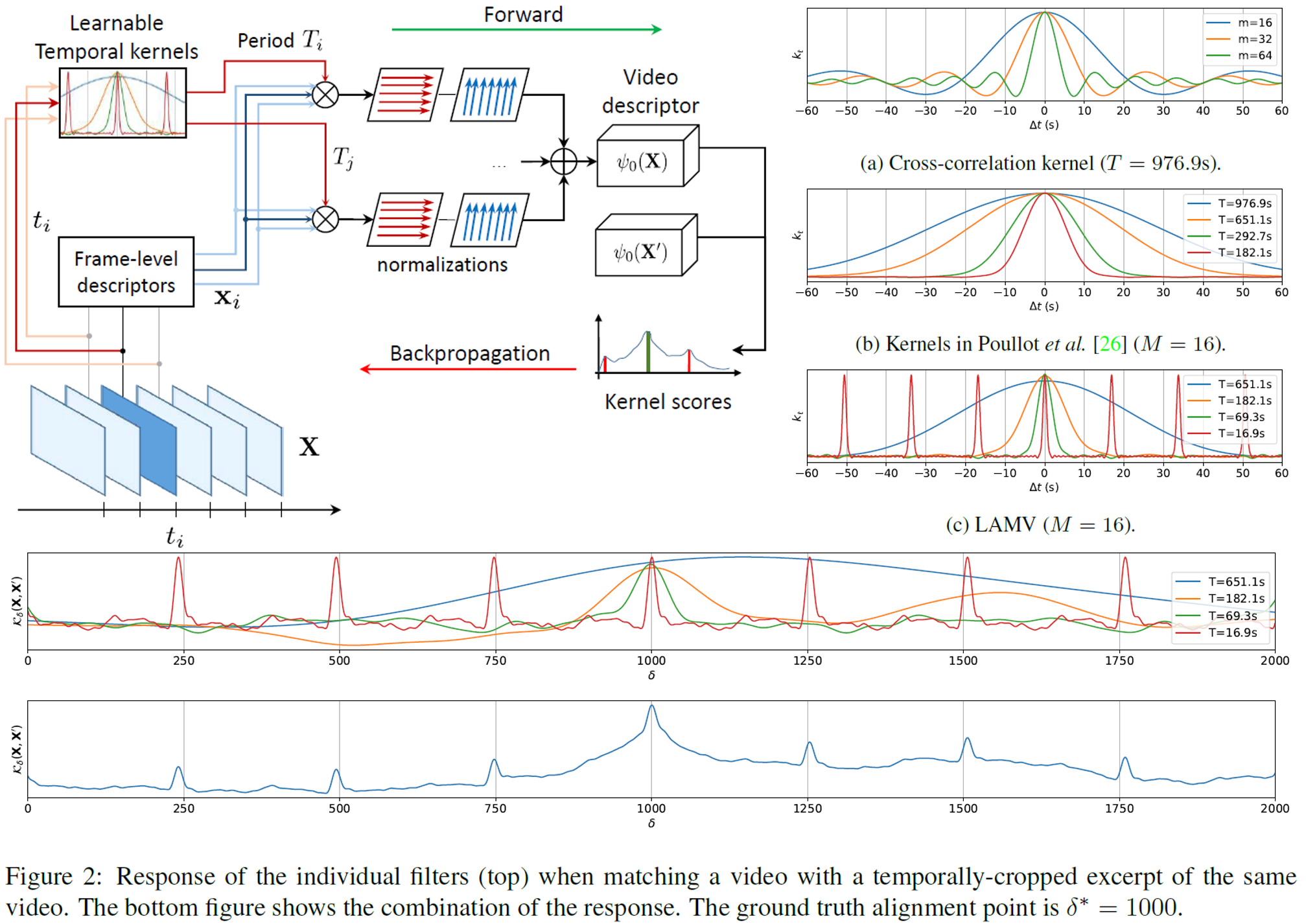
同じネットワークを通して得られた特徴量を比較するという意味では、LAMVはSiamese Networkと類似したアプローチである。Temporal Match Kernelを微分可能なレイヤーとすることでニューラルネットワークの導入する。損失関数はベースとなる動画と重複部分を持つ動画と重複部分を持たない動画に対してTriplet Lossを取る。
CNNの特徴量表現の識別性能を向上させるため、幾何学的変形に不変なプーリング手法であるSubspace Poolingを提案した論文。さらに精度を向上させるため、Marginal Triplet Lossにカーネル法を適用し、Bilinear Poolingより良い精度を少ないメモリ容量で実現した。
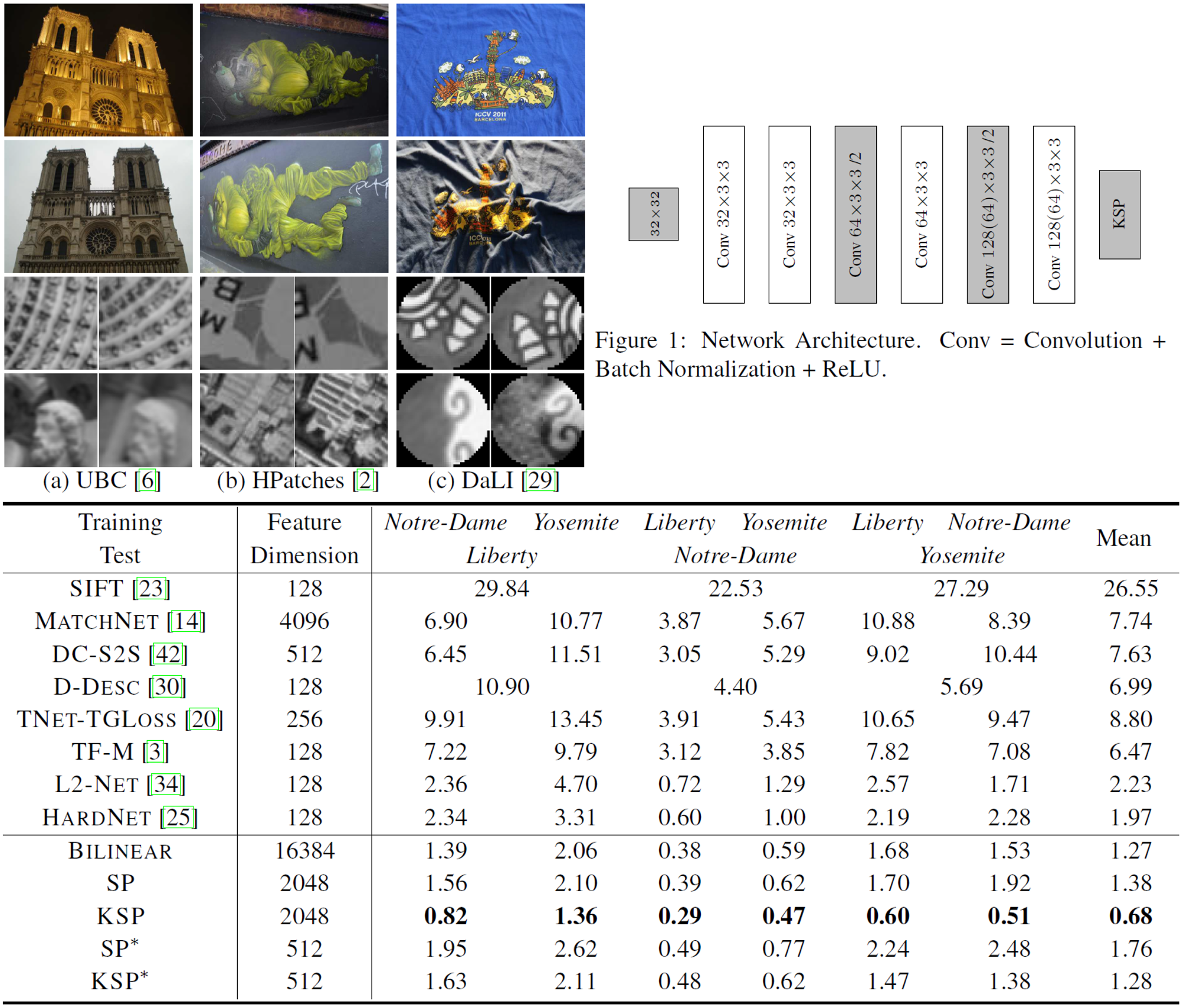
Subspace Poolingは特徴量マップを列成分に並べた行列に対してSVDによって次元圧縮を行う。この方法は、行列の行成分の順列(位置に関する入れ替え)に対して不変である。Patch Matchingのような2点距離を測るようなタスクに対しては、Subspace Poolingで得られた特徴量をガウシアンカーネルを用いたカーネル法を適用することができ、これによりさらに精度を向上させた。
Disentanglementタスクを敵対的ネットワークの構造を利用して行った論文。Disentanglementとは要因を分解するようなタスクであり、手書き文字であれば何の文字が書かれているかという情報と書かれている文字のスタイルを分離するようなタスクである。提案手法は最初に正解ラベルを与えられるようなタスクを学習させた後、それ以外の要素を抽出するようにもう一つのネットワークを学習させることでこれを実現した。実験では、分離した2つの要因を補間したり、掛け合わせたりする検証と2つの要因に相関が無くなっているかを確認するための検索タスクを行った。
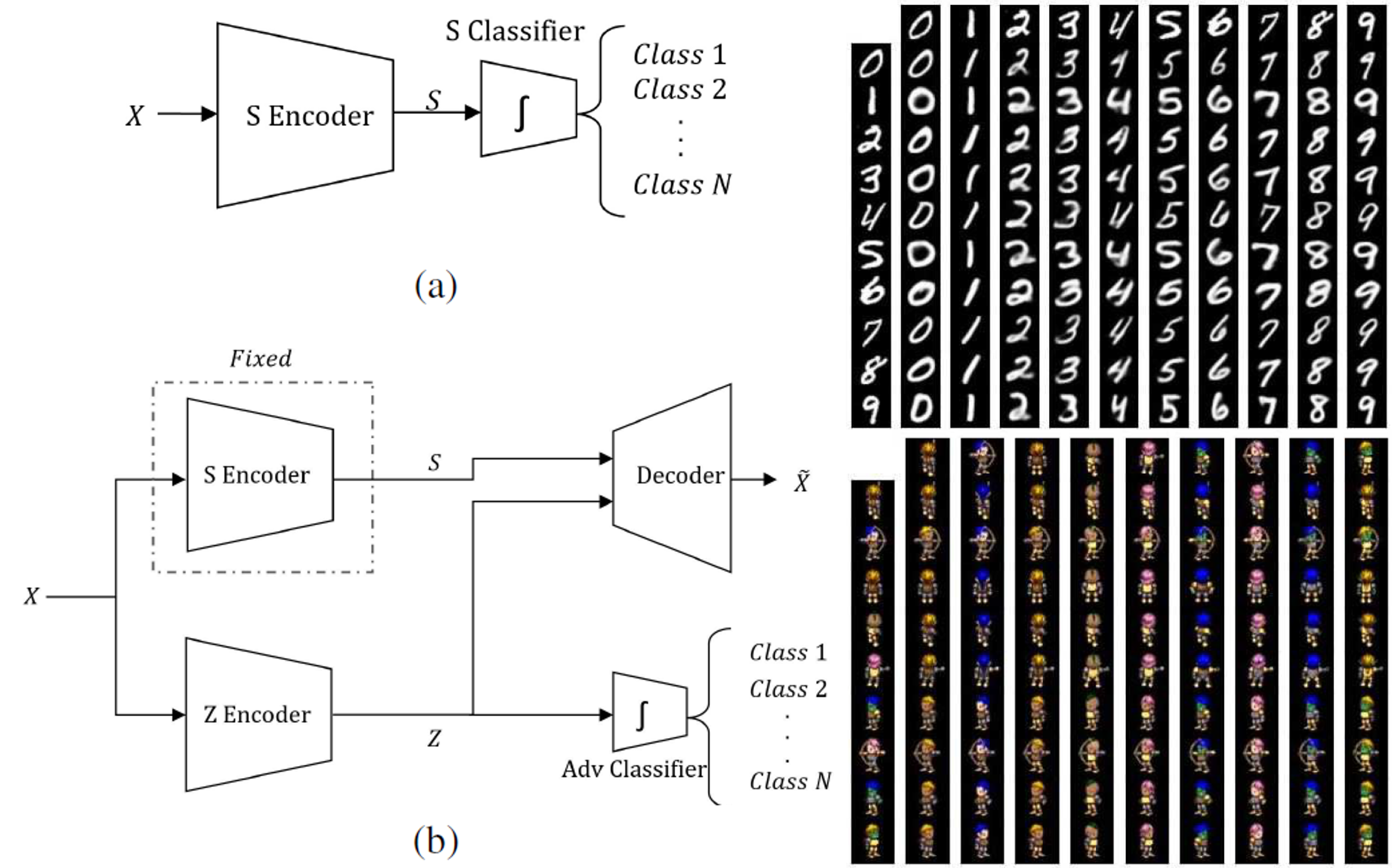
まず初めにネットワークSを正解ラベルの存在するクラス分類のタスクで学習させる。次にSとは異なるネットワークZを学習するのだが、SのエンコーダとZのエンコーダから得られた特徴量からReconstructionするように学習するブランチと、Zのエンコーダから得られた特徴量からできるだけクラス分類の精度が下がるように学習するブランチで学習する。特にクラス分類の精度を下げるように学習する方は、クラス分類に必要な情報をできるだけ忘れるようになっており、Disentanglementのタスクに効いている。
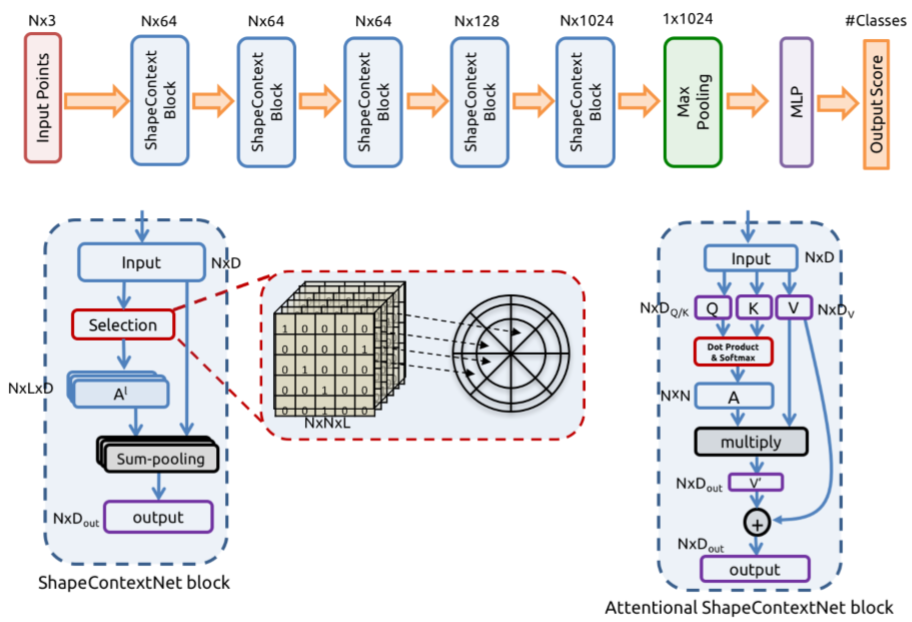
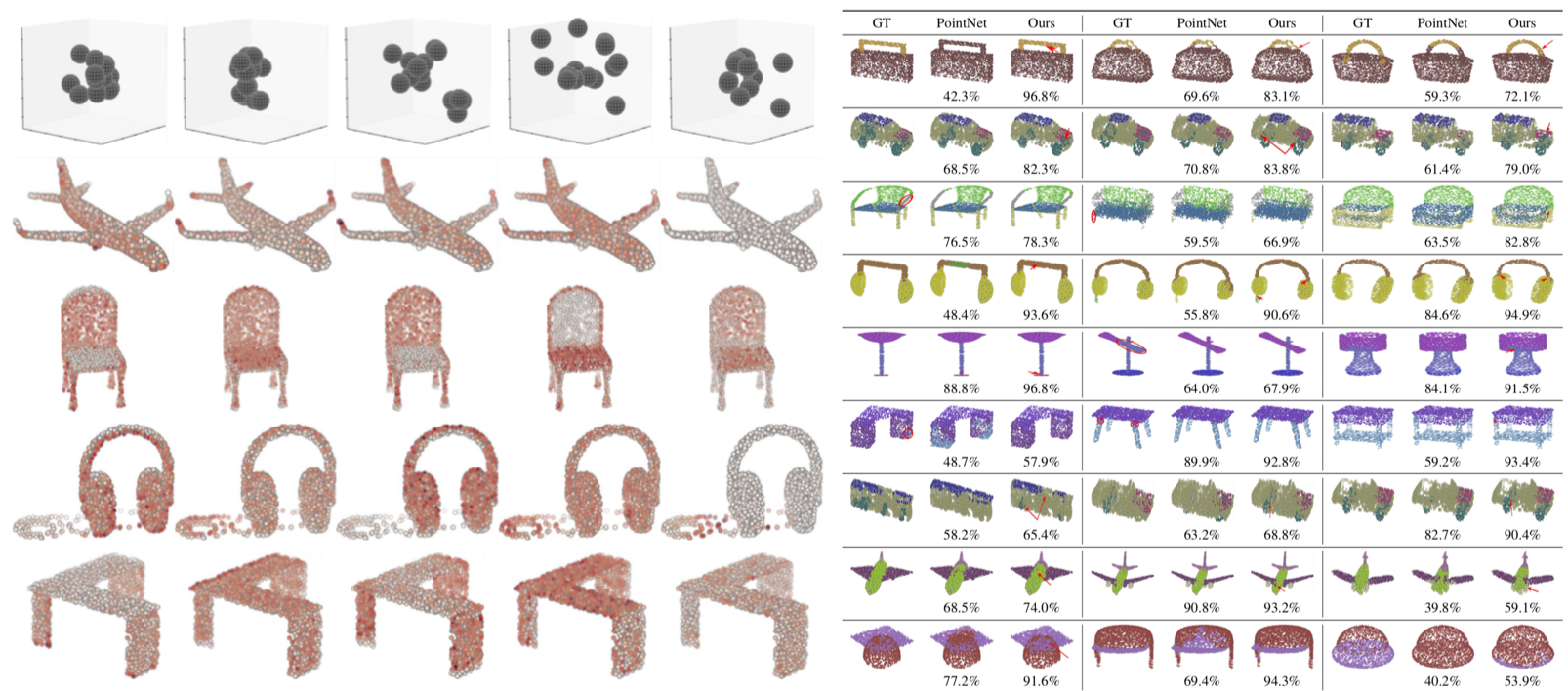
PointNetでは考慮出来ていない, PointCloud の局所的な構造を抽出するために, 新しい2つの演算 (kernel correlation と graph-based pooling) を提案. classification と segmentation のタスクで行った評価実験では PointNet++ と同等以上の結果をより少ないパラメータ数で達成した.
この研究では以下に示す3つのことを行なった.
DHF1Kデータセットは,1000個の動画から構成されており,シーン,モーション,アクティビティ等が既存データセットよりも幅広くカバーされている.

DHF1K, Hollywood2, UCF sportsデータセットを用いて実験を行なった結果,提案モデルがSOTAモデルよりも優れていることがわかった.評価指標としては,Normalized Scanpath Saliency, Similarity Metric, Linear Correlation Coefficient, AUC-Judd, shuffled AUCを用いた.
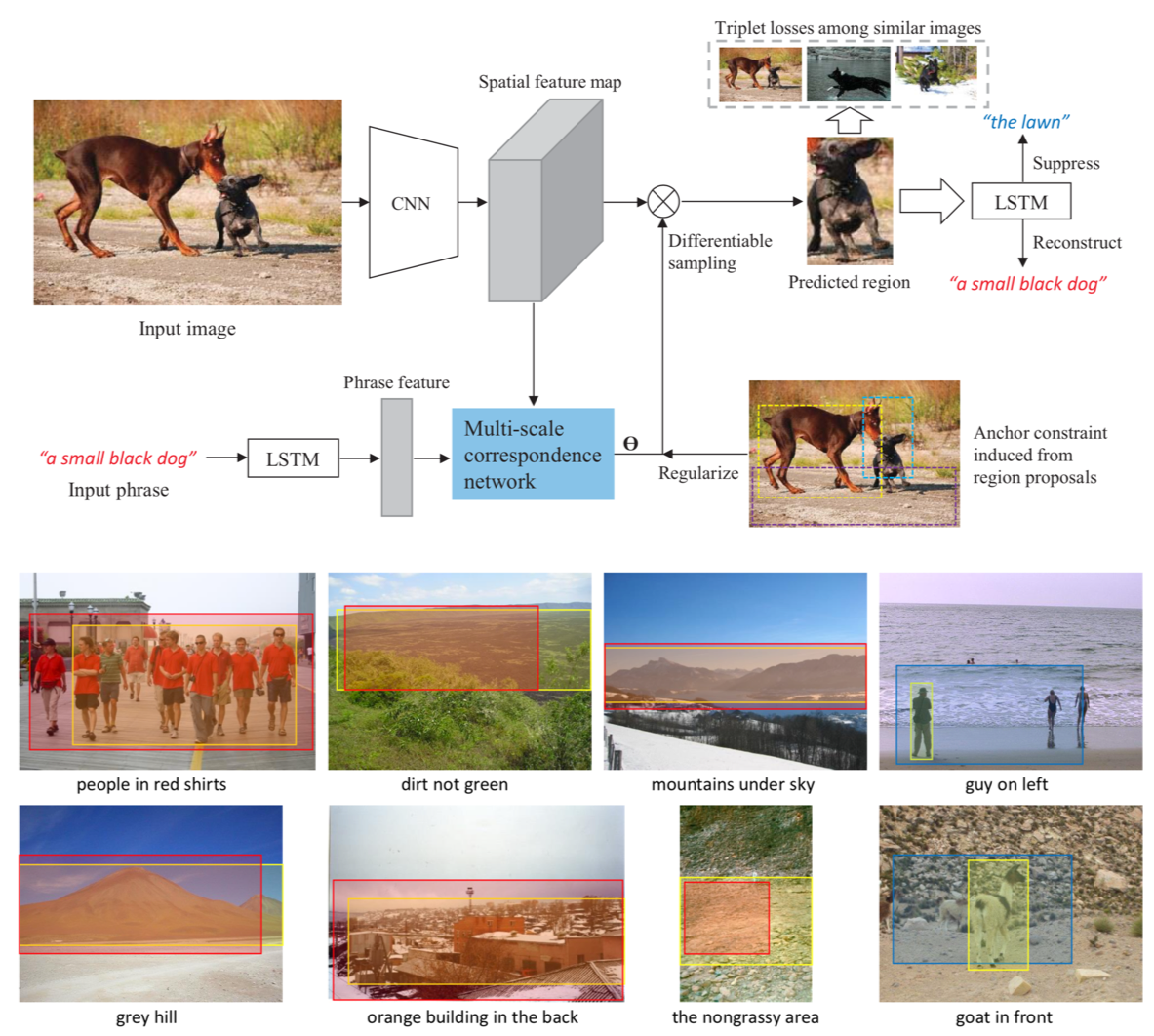
弱教師(画像レベルのアノテーション)によって Textual phrase localization を行う研究. 提案手法では anchor constraint の元で fine-grained な Bounding Box を連続的に探すことが可能. Flickr30K Entities と ReferItGane datasets を用いた評価実験では, 既存の弱教師に基づく手法に大きな差をつけてSOTAを達成した.
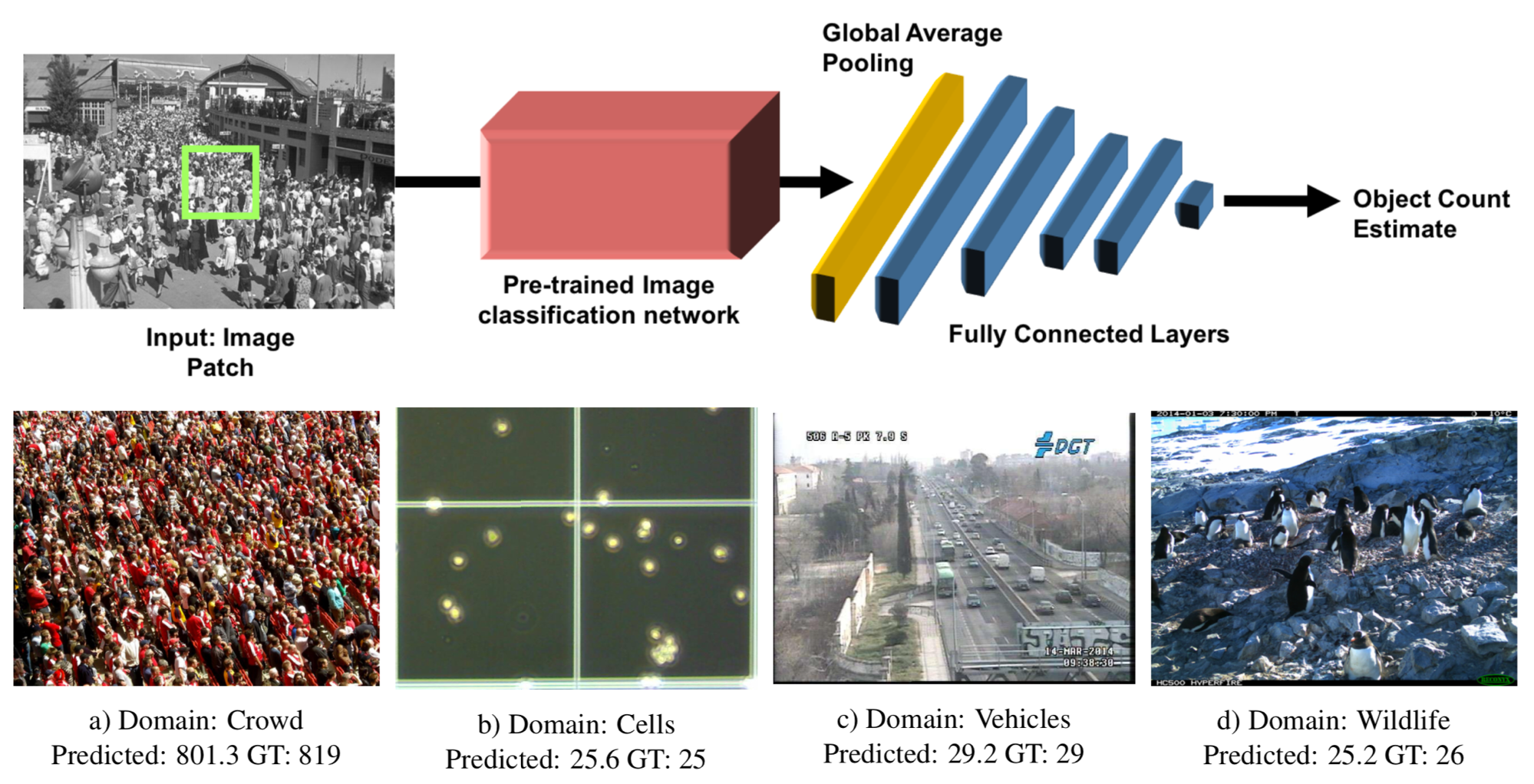
Multi-domain なパッチベースの object counting の新しいモデルを提案. 提案手法は multi-domain に対応するための domain specific modules を内包しており, 全体のパラメータの内 5% を追加で学習するだけで新しい domain に対応することが出来る. 評価実験では, 単一のモデルで異なる domain に対する数え上げのタスクでSOTAを達成した.
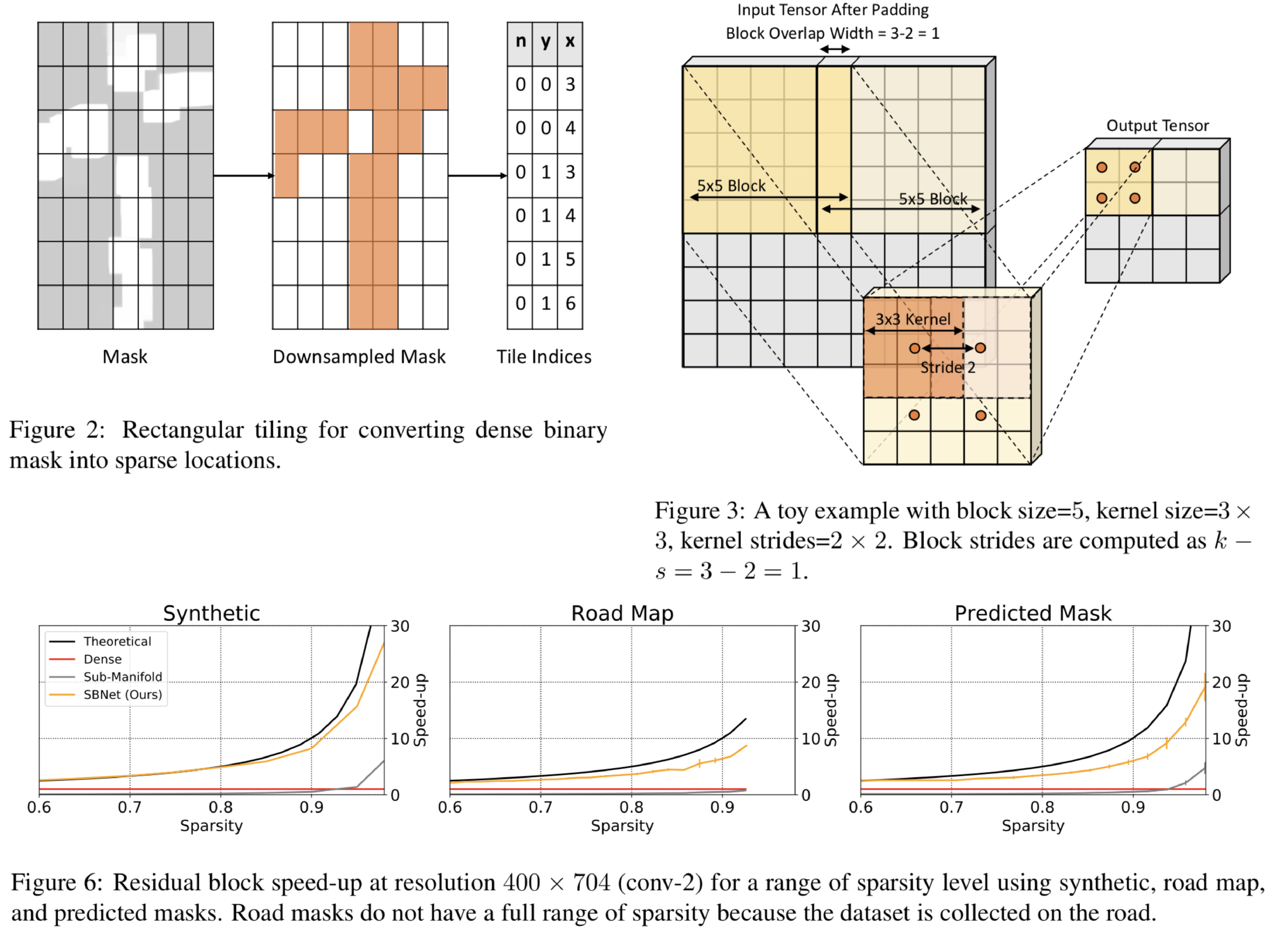
オブジェクト画像に対するCNNの計算コストを削減するために、画像の前景に対する離散的なマスクを生成し、convolutionを行うSparse Blocks Networks (SBNet)を提案。従来のCNNでは画像全体に一様にconvolutionの操作を行うため計算コストが高い。また、既存手法では構造的な離散化を行なっていないために、計算コストは小さくなっても実行時間が短くならないという問題点があった。提案手法では多くのオブジェクト画像は周りを背景で囲まれており、一部の領域にオブジェクトが存在するという構造情報に基づいて、前景の可能性が高い領域に対する離散的なマスクを形成する。これを入力テンソルに適用することで小さい計算コストで精度を落とすことなくCNNの学習を行う。
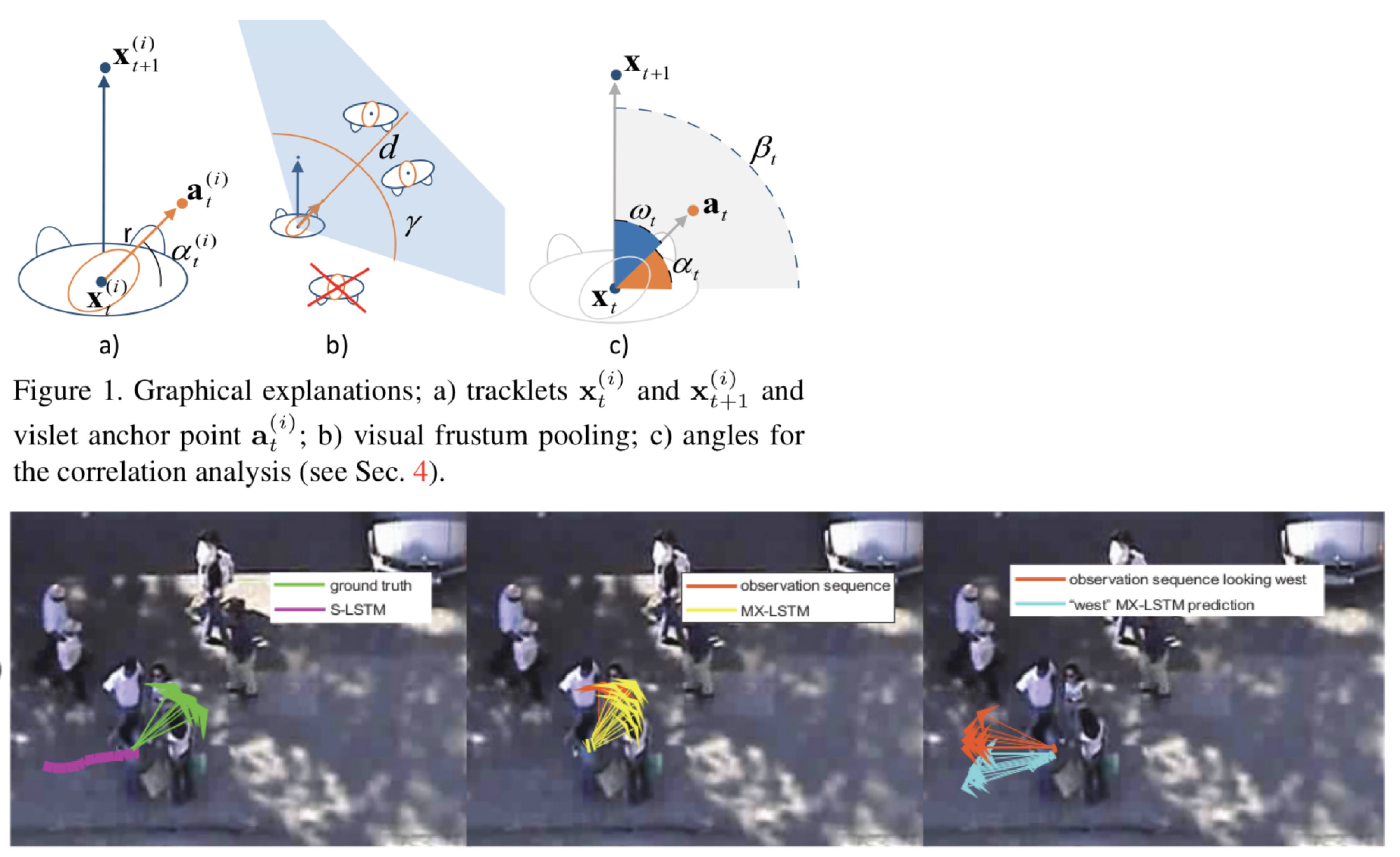
人間の軌道予測を行う際に、頭部の向き情報を加えたLSTMベースのネットワークMiXing LSTMを提案。事前実験により人間の歩行軌道と頭部の向きが関係することを明らかにした上で、手法を提案。xy平面状の軌道(tracklets)と頭部の向き(vislets)の両方のstreamを考慮する。また、既存手法であるSocial LSTMでは周りの歩行者の軌道を隠れ変数として考慮していたが、提案手法では推定された頭部の向きを中心とした視野角内に存在する歩行者のみを考慮することで精度の向上を図っている。最適化にはd-variate Gaussian parametersを用いた。
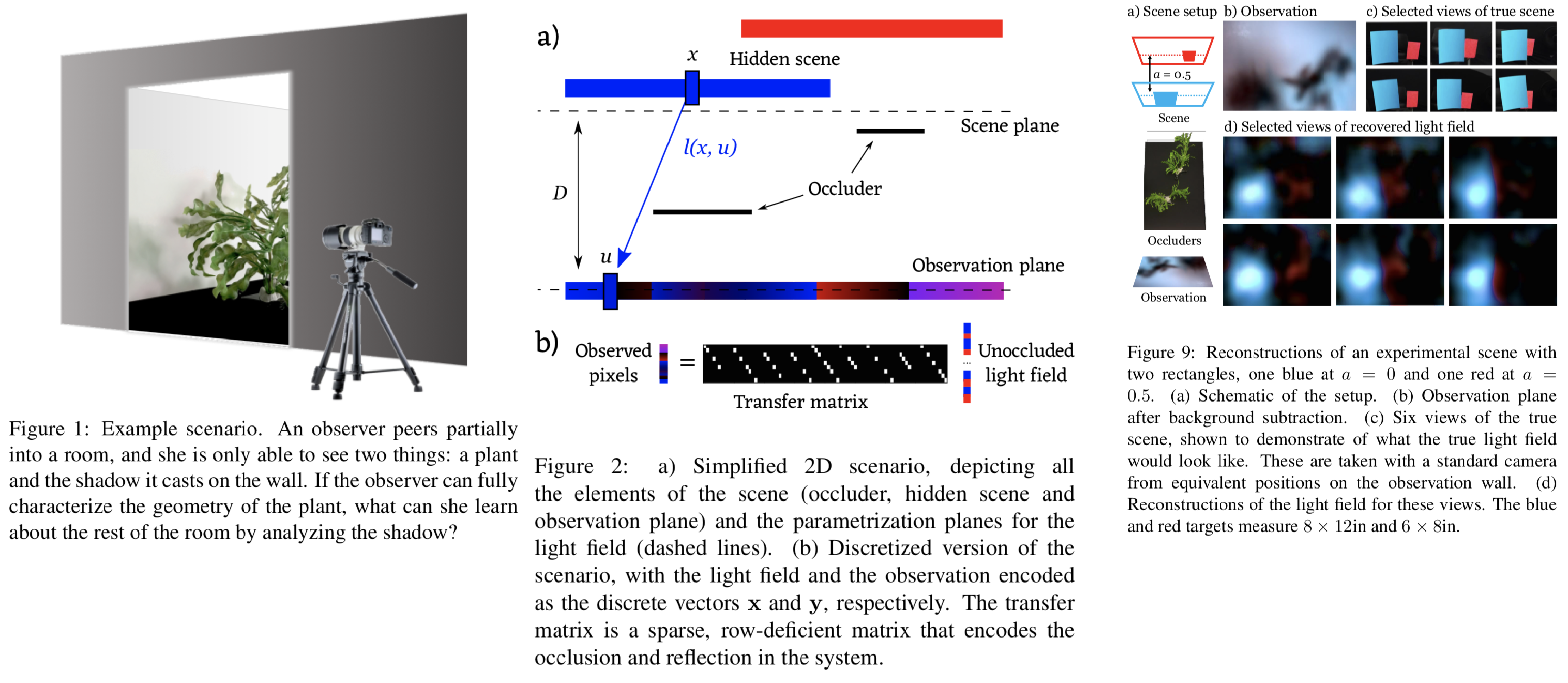
直接観測していない四次元light fieldを観測可能な物体によるディフューズ面に投影された二次元平面上の影から推定する手法を提案。既存研究としてtime-of-flightカメラを用いて二次反射光による観測可能な反射と見えていないシーンを含んだ全てのシーンとの関係性と、ありえそうなシーンの構造を事前情報として用いて観測できないシーンのオブジェクト数を数えるnon-line-of-sight (NLoS) imagingをあげているが、この研究ではよりチャレンジングな目的を達成する。提案手法ではNLoSで使用されている二次反射光に加えて、現実のシーンではスペクトルが低周波成分に集中するという情報を用いることで平面上の影から観測不可能な四次元光を推定する。
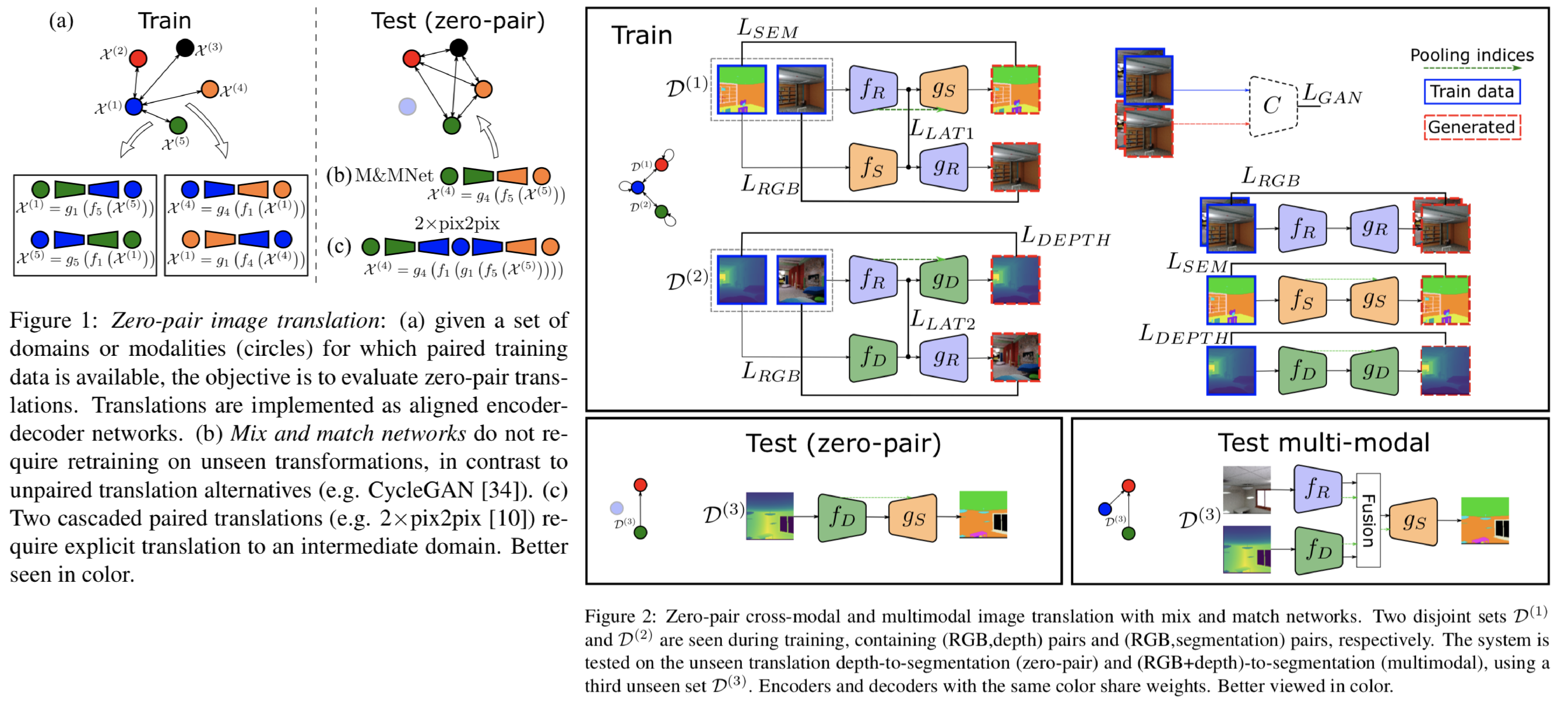
異なるドメイン間の画像変換において、ある一つのドメインとその他のドメイン間の画像変換をトレーニングすることで、テスト時にはトレーニングを行っていないドメイン間の画像変換を行うmix and match networksを提案。提案ネットワークはautoencoderによって構築される。以下ではdepth(D) to semantic segmentation(S)を行うために、RGB(R) to D, R to Sをトレーニングするロス関数を説明する。
GANの学習を安定して行うことができるwasserstein distance(WD)から導出されるsliced WDを導入することで、安定したGANの学習方法を提案。一次のデータに対する二次のWDを式(5)に示す。このままでは最適化が難しく、計算コストも大きいが、式(7)、(8)のようにソーティングを行うことで、WDは式(10)のように簡単な数式に置き換えることができる。この式(10)のことをsliced WDと呼ぶ。しかし実際には画像データは一次元ではなく、高次元であるため、random projectionによって画像データを任意の一次元ベクトルに射影することでsliced WDによる学習を行う。
自然画像が持つ類似パッチを利用した、自然画像のデノイジングを行うWNNMを一般の画像の任意のdegradation(ブラー、ピクセルの欠損など)に対するdistortionへ拡張した手法を提案。提案手法では以下のステップを踏んで画像のdistortionを行う

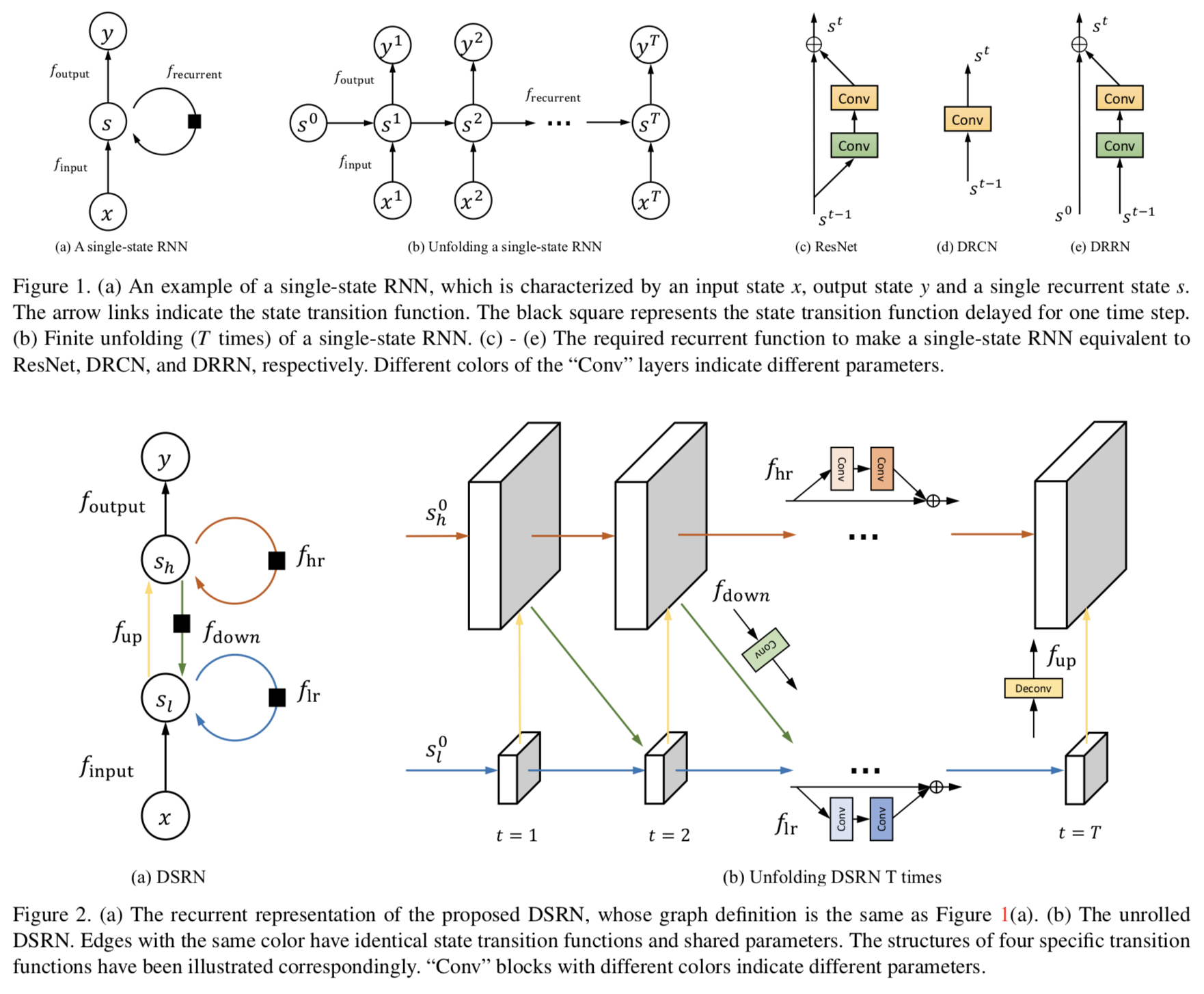
画像の超解像を行うために、高解像度(HR)と低解像度(LR)の2つのstateを持ったRNNベースのモデルであるDual-State Recurrent Network (DSRN)を提案。画像の超解像はCNNで行われることが多いが、パラメタ数が多く、これを削減するためにRNNに着目。RNNを用いた画像の超解像を行うDRRNと異なる点として、提案ネットワークではbottom stateでLRを、top stateでHRをキャプチャし、 delayed feedback mechanismを用いることでLRとHRの双方向のマッピングを行う。
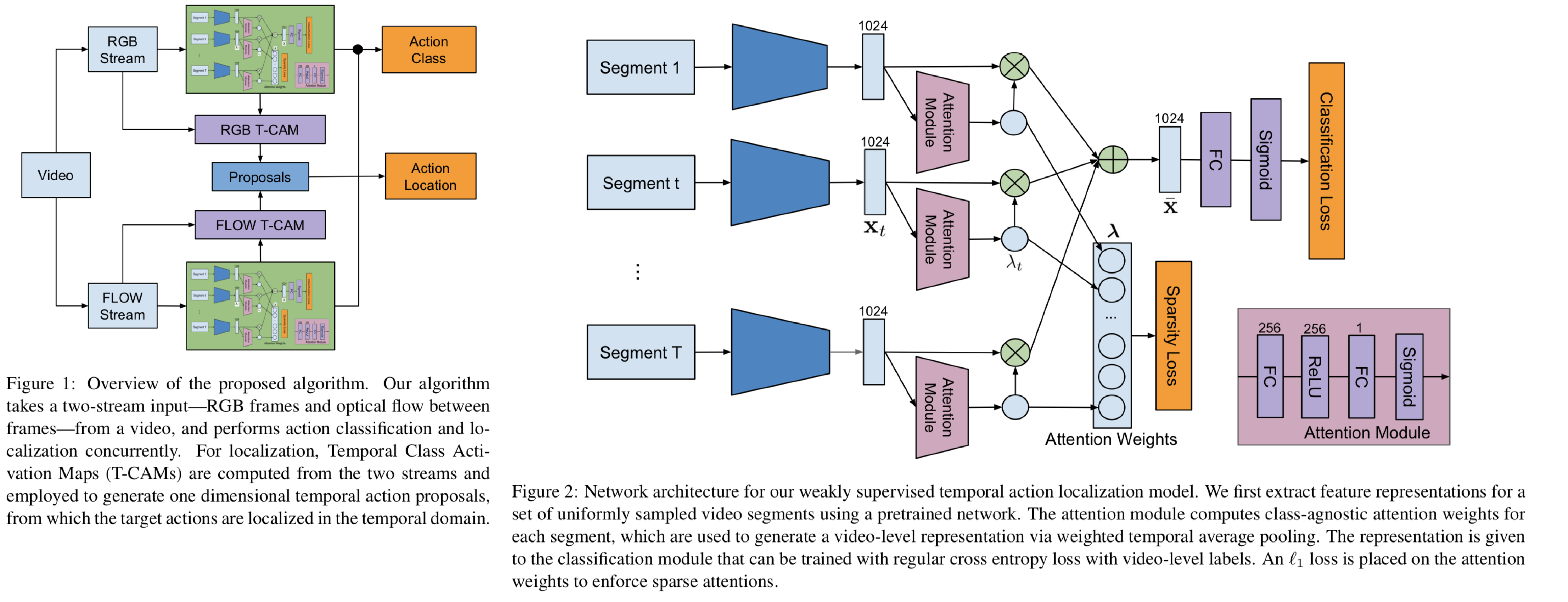
トリミングがされておらず、かつvideo-levelのactionラベル(動画内に存在するactionのラベル)を用いた弱教師学習によって、時系列上のaction localizationを行うSparse Temporal Pooling Network (STPN)を提案。提案手法では一定間隔で取り出された動画のセグメントに対してactionのclassificationロスと、各セグメントごとの、クラスに関わらず、actionのsparsityをL1ロスを用いて考慮することで、actionが存在し得るセグメントをプールしていくことでネットワークのトレーニングを行う。上記をRGBの入力とoptical-flowの入力を用いたtwo-streamで行う。
facial action units (AUs)のアノテーションを用いず、顔画像から得られるAUsの確率分布を用いてAUsの識別を行う手法を提案。AUsは表情や個人に依存するため、専門家がアノテーションしなければならずデータセットの構築が難しい。提案手法では、解剖学てきな知見から得られるAUsの確率分布と表情に関する研究から得られるAUsの確率分布を使用し、それぞれのAUsの識別器を同時に学習する手法を提案。
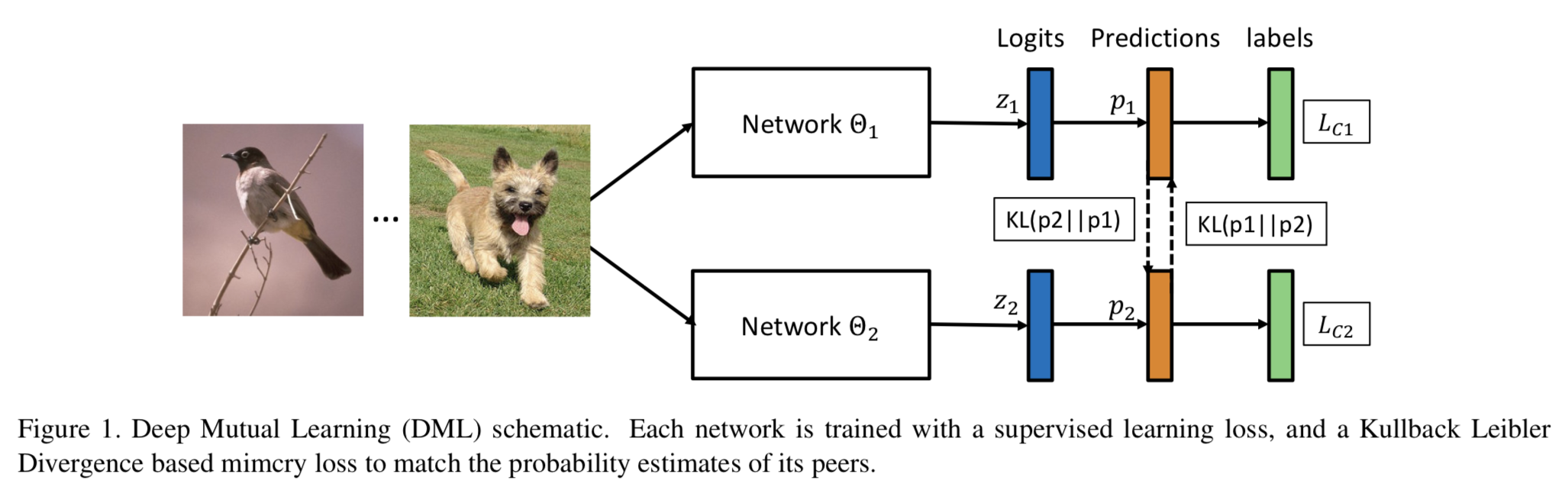
複数のネットワークを同時並行で学習し、お互いの情報を共有することで最終的な精度を向上させるDeep Mutual Learning(DML)を提案。論文中では特に識別タスクを扱っている。それぞれのネットワークを通常の識別に関する教師あり学習のロスと、他のネットワークによる推定ラベルの確率分布を事前情報としたKL divergenceをロスとして用いることで学習を行なっていく。比較手法としてネットワークの蒸留をあげており、上流ではteacherネットワークはstudentネットワークよりも小さくなければいけないが、DMLでは小さなネットワークだけで学習を行うことでき、ネットワークのサイズにとらわれない枠組みとなっている。
暗号化によるデータ圧縮とグラフ構造を用いた画像の類似度探索手法L&C(link and codeを提案。DNNなどで得られた特徴量をそのまま使用するとデータ容量が大きく、既存手法では精度が低いことを主張。提案手法ではデータ容量を小さくしつつ、検索精度を上げ、検索時間短くする手法を提案。各データベースで与えられている画像特徴量を暗号化を用いて圧縮し、次にHSNWというグラフベースのインデックス手法を用いてグラフを構築。グラフの精度向上のためにエンコードされた画像を復元し、近傍のデータから十分探索可能な場合には余計なデータを付加せず、そうでない場合には周囲のデータによる回帰をオフラインで行い、その回帰係数を格納する。

顕微鏡で撮影された細胞に対して画像的な見た目と生物学的な関係性を推定するために、CNNに対して半教師学習を行う。論文中に行われる実験では変異肺がん細胞の画像から遺伝子を推定するために、化学処理された変異肺がん細胞の画像を用いた化学処理のラベル推定をCNNで学習する。しかし化学処理は対象となる細胞が異なる場合には反応しないこともあるなど、ラベルとしてはかなりノイジーである。そこでRNN-based regularizationとmixup regularizationという2つの正則化を行う。RNN-based regularizationでは同じ化学処理や同じ細胞からは似たような特徴量を得るように学習し、mixup regularizationでは2つの画像をアルファブレンディングした時に、そのソース画像の識別とブレンド率の推定を行う。
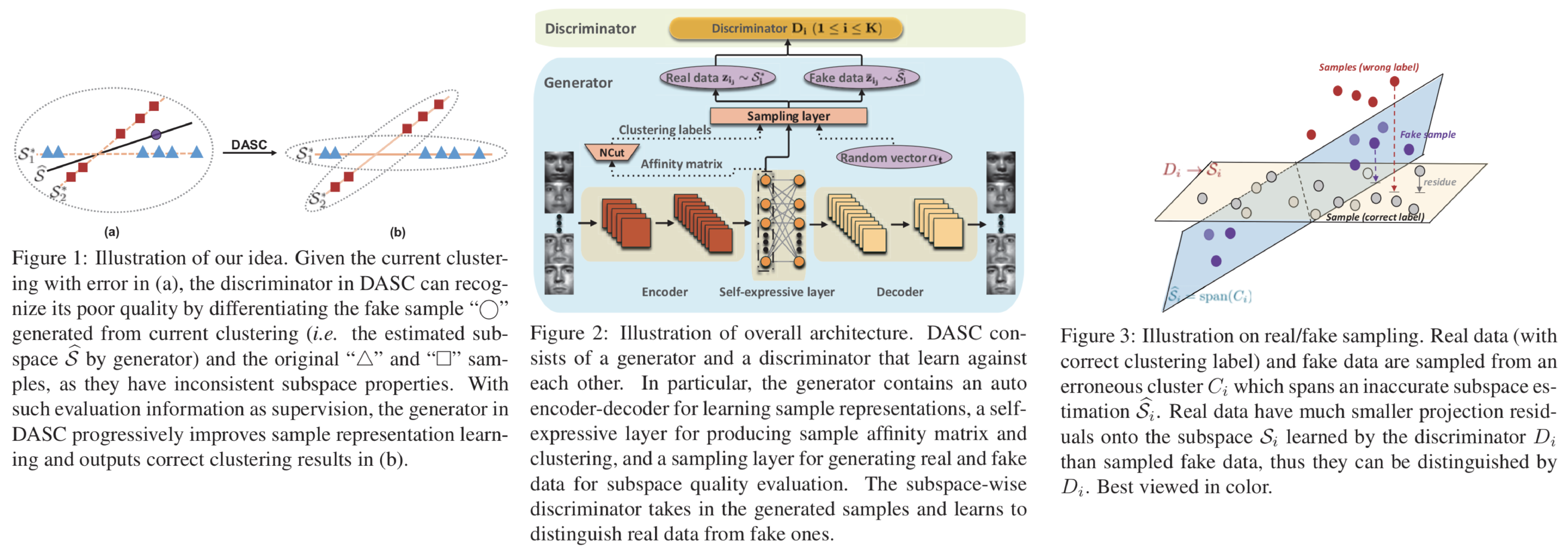
サブスペースクラスタリングを敵対的学習によって行うdeep adversarial subspace clustering (DASC) modelを提案。多くの既存手法ではハンドクラフトな特徴量を使用していたが、提案手法では初めて敵対的学習を教師無しの手法を提案。ネットワークは特徴量を抽出するencoder、画像のリコンストラクションを行うdecoder、sampling layerから得られたfakeデータと実際のデータ(real)を識別するdiscriminatorからなる。discriminatorはデータの識別を行う際に、realを超平面状に射影するような行列を作成しつつ、realは射影するエネルギーが小さいが、fakeは射影するエネルギーが大きいという過程のもとデータを識別。より良い射影行列を作成することでサブスペースクラスタリングを行う。
Bilinear Poolingは2次の統計量を用いているため非常に良い精度を出す一方で、出力の特徴量の次元数が膨大になるといった問題点がある。本論文はBilinear Poolingの次元数をコンパクトにしたネットワークMoNetを提案した。MoNetはSoTAと同等の精度を保ちながら、特徴量の次元を4%にまで落とすことに成功した。
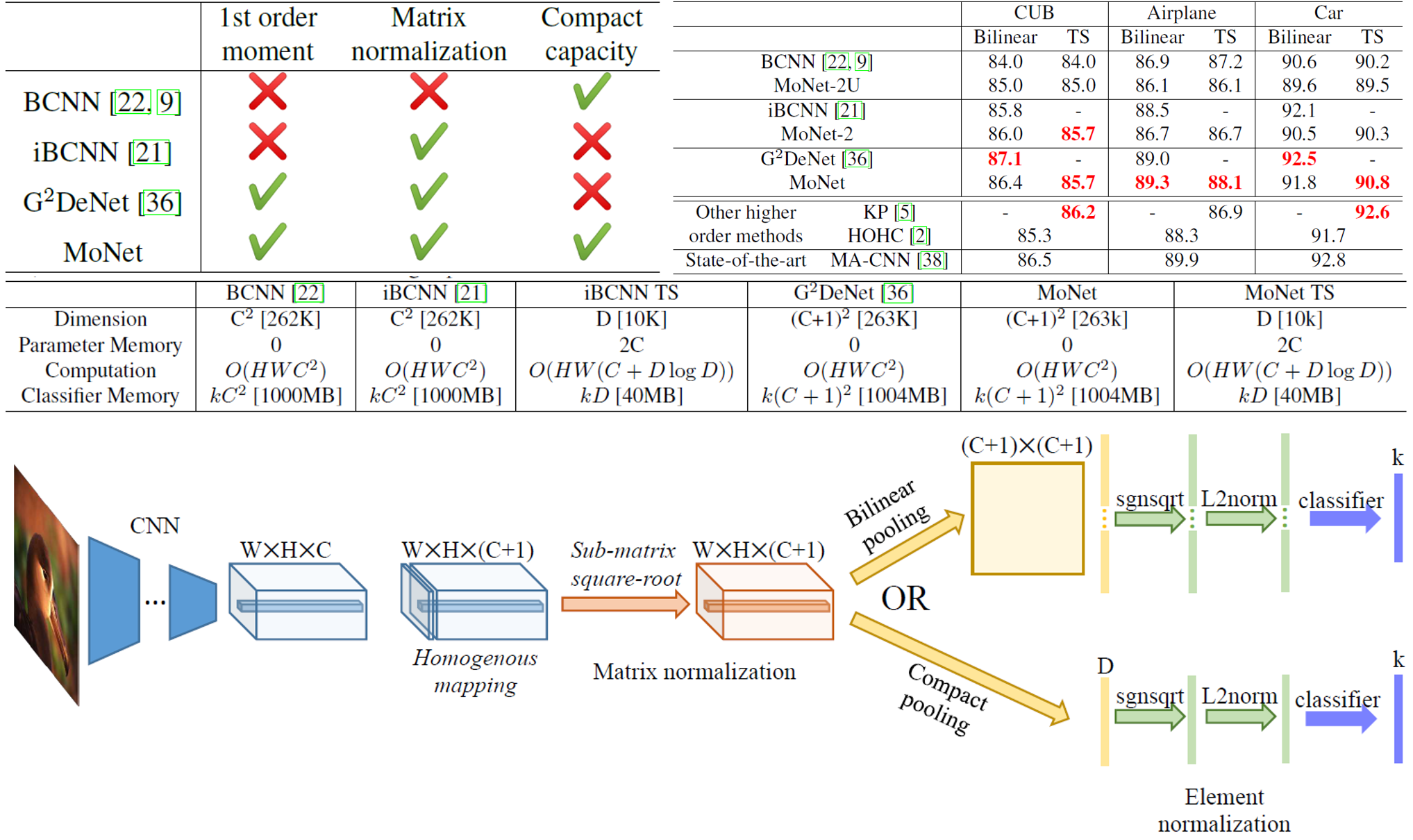
Bilinear Poolingの次元数を減らすためCompact Poolingが提案されたが、通常のBilinear Poolingをさらに拡張したiBCNNやG2DeNetに対しては、Gaussian EmbeddingとBlinear Poolingが絡んでいること点と行列の正規化が必要な点から適用することができない。そこでMoment Matrixを用いてGaussian EmbeddingとBilinear Poolingを別にし、sub-matrix square root layerを追加してBilinear Poolingの前に正規化を行うことでCompact Poolingを適用可能にした。
そもそも要約動画として1つの最適解が存在するわけではないことを主張し、それぞれの視点に合わせて要約動画を行った研究。本研究では、動画間の類似度に着目し、フィッシャー判別から着想を得て、inner-summary variance、inner-group variance、between-group varianceに関して最適化を行うことで要約映像を生成した。また評価のためのデータセットを構築し、質的評価・量的評価を行った。
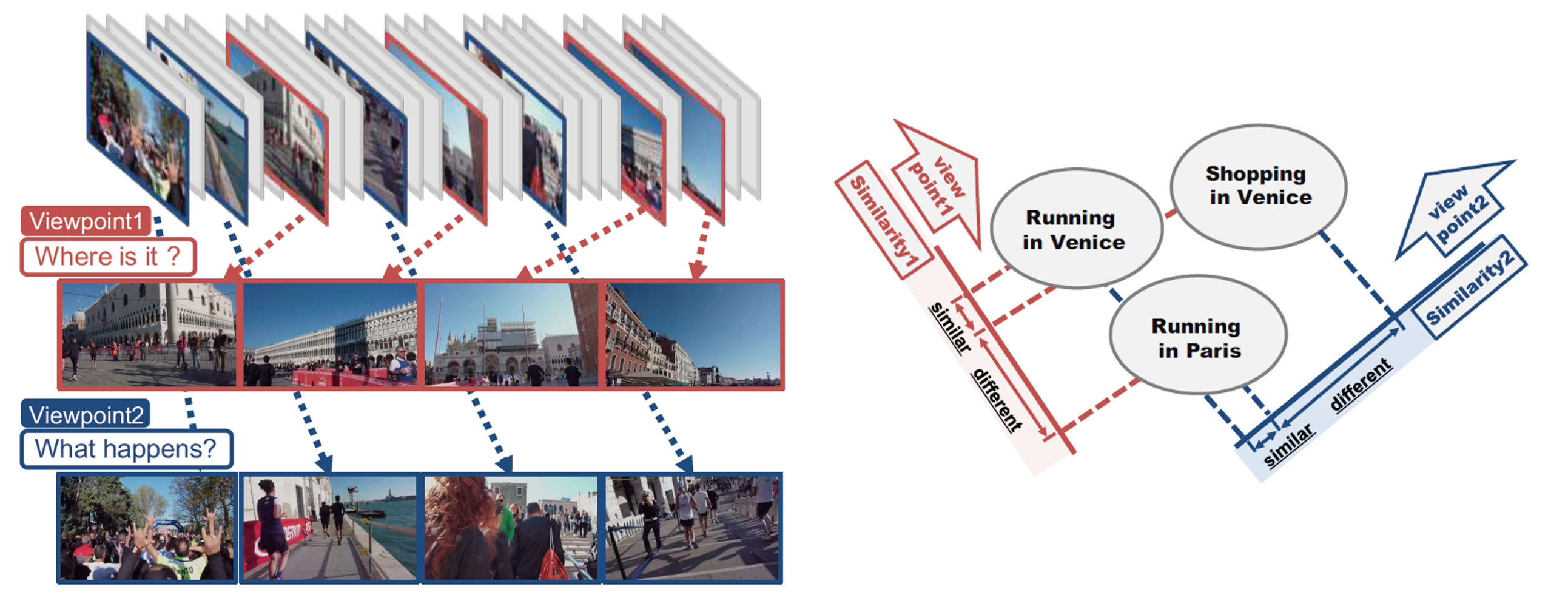
要約動画として満たすべき条件として(1)要約動画内で分散があること、(2)同一グループ内の動画を代表することができること、(3)他のグループの動画と識別できることを挙げている。これらに対応する要素がフィッシャー判別から着想を得たinner-summary variance、inner-group variance、between-group varainceである。これらをC3Dで抽出した特徴量に対して計算し、最適化することで解を得る。
高解像度化タスクはill-posed problemであるため取りうる解が複数あり、GANを用いてもリアルなテクスチャを生成できていないが、特定のカテゴリに特化して学習させたネットワークを用いればリアルなテクスチャが生成できるという事実から、セマンティックセグメンテーションを利用した高解像度化に着目した。しかし、すべてのカテゴリごとに学習したネットワークを用意することは非現実的であるため、Spatial Feature Transform(SFT)層を導入することで、単一のネットワークでカテゴリ情報を考慮した高解像度化を行った。
SFT層は特徴量をアフィン変換をする層である。そのアフィン変換はスケールとシフトのパラメータで定義され、これらは各カテゴリごとの確率マップから与えられる。SFT層は従来のネットワークに導入することが可能であり、さらにセマンティックセグメンテーションに限らず、あらゆる事前知識(デプス情報など)に対しても適用可能である。
CNNのニューロンの冗長性を軽減するため、分類タスクにおいて分類する直前の層(FRL: Final Response Layer)の復元誤差を最小化するようなPruning(特定のニューロンを削除)するアルゴリズムNeural Importance Score Propagation(NISP)を提案した。如何に精度を落とさず、ネットワークに必要なFLOP数を減らせるかの実験を行い、AlexNetにおいては67.85%のFLOP数を削減したネットワークが1.43%しか精度を落とさないようにすることに成功した。
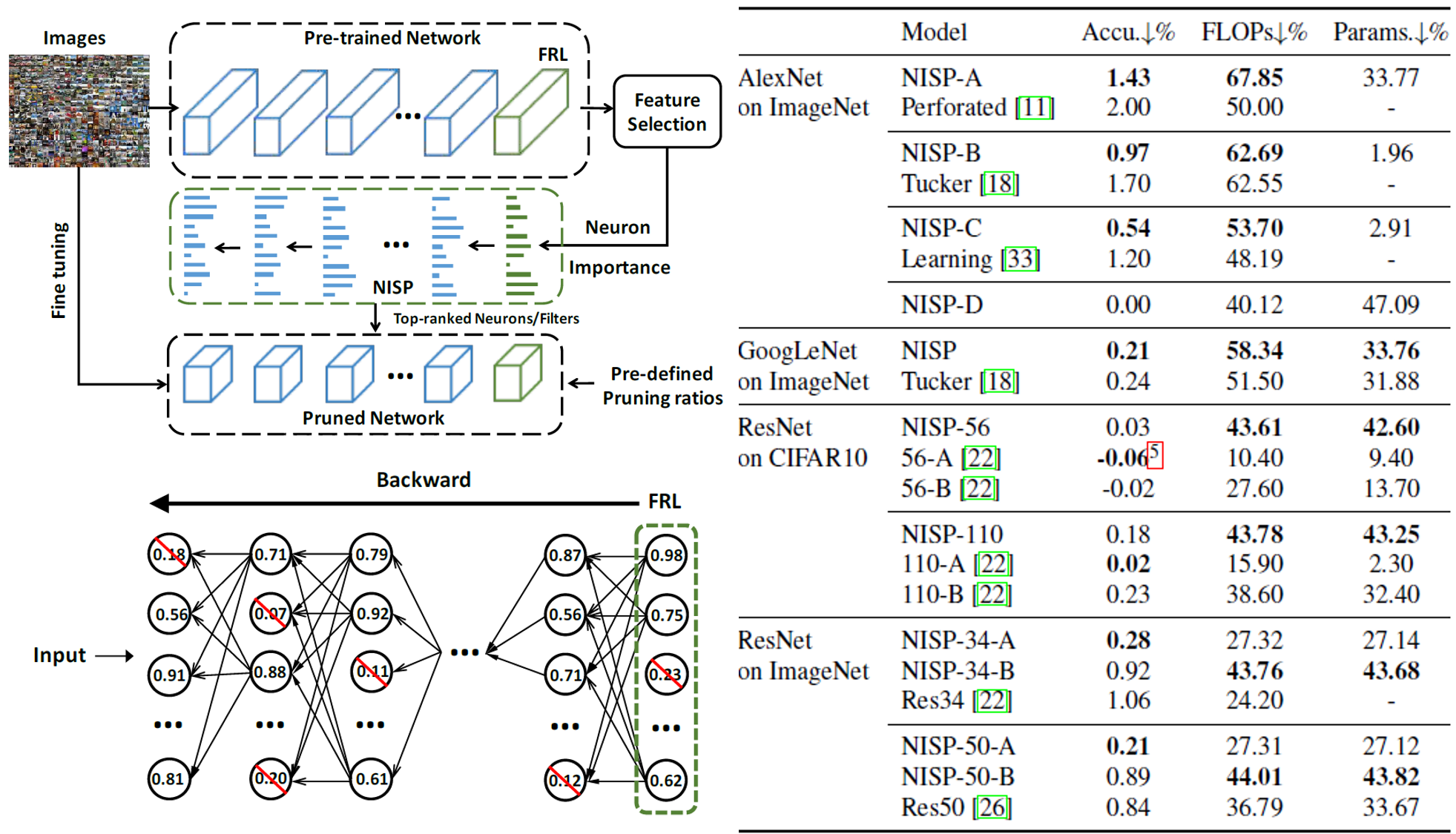
従来手法のほとんどは層ごとに独立して考えるか、次の層までを考慮にいれてPruningをする問題を解いていたが、重要なのは最後の層に与える影響であり、提案手法はそれを直接的に考慮している。提案手法はネットワークのPruning問題を、各ニューロンを削除すべきかいなかの0-1整数計画問題として定式化し、FRLの復元誤差を最小化する最適化問題を解く。実際には、目的関数を解析的に解くことはできないため、最適上限を求める問題に帰着させることで、閉経式で解くことが可能となった。
GANで教師あり学習をするタスクにおいて、DiscriminatorにSiamese Networkを適用することで直接教師データを損失関数に導入することが可能なMatching Adversarial Network(MatAN)を提案した。MatANは様々なGANで行う教師あり学習のタスクに適用することが可能であり、実験においてはsemantic segmentation、road network centerline extraction、instance segmentationのタスクに適用し、良い精度を出した。

DiscriminatorをSiamese Networkにする。2枚の画像ペアのうち、1枚はground truthであり、もう1枚はnegative sampleはGeneratorによって生成された画像もしくはground truthに摂動を加えた画像である。学習の方法自体は、通常のGANと同様に、Discriminatorはrealかfakeかを識別できるように学習し、GeneratorはDiscriminatorの識別率を下げるように学習する。
動的に映像内容が変化する360°動画における視線推定を行った論文。まず動的に映像内容が変化する360°動画の大規模データセットを構築し、そこから視線推定には過去の視線のパスと映像内容が重要であると分析し、その上でCNNとLSTMを組み合わせて顕著性と過去の視線のパスの両方を考慮した視線推定手法を提案した。
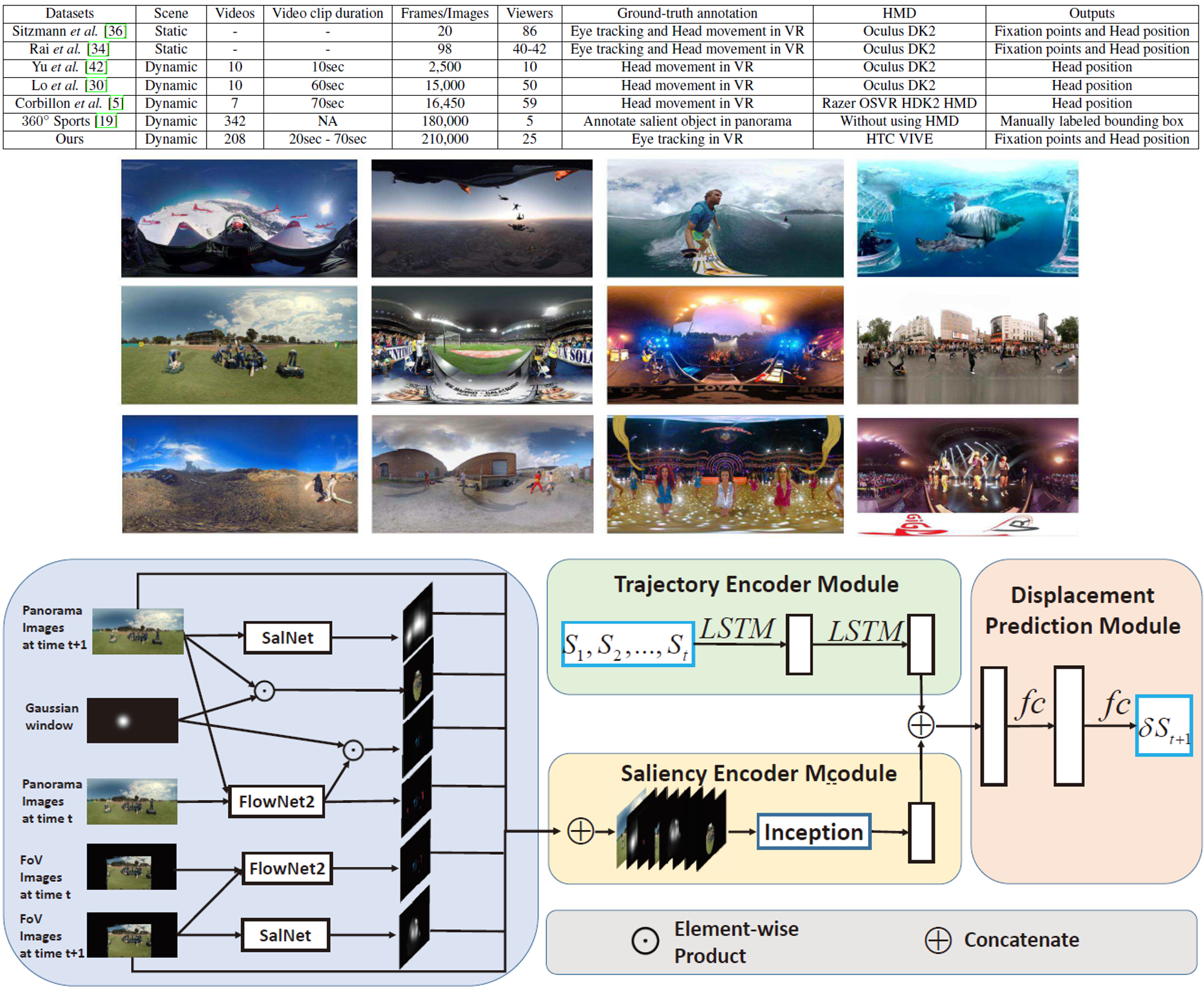
論文で対象としている動画と従来研究が使用している動画の違いとして、1) 通常の映像では受動的に動画を視聴しがちであるが、360°動画では能動的に視聴しようとする点。2) 従来の360°動画は静的な映像内容のものを扱っていた点。3) 提案手法ではHMD内に搭載可能な7invensu a-Glassを用いており、頭部の動きに加えて注視点の情報を取得している点を挙げている。データセットには音声情報もついており、360°動画における音声情報を考慮した研究も今後行っていくとのこと。
高解像のタスクに対して、アップサンプリングとダウンサンプリングを交互に繰り返す構造を持つDeep Back-Projection Networks(DBPN)を提案した。従来のネットワークはアップサンプリングを行う方向(feed-forward connection)しか考えておらず、それをダウンサンプリングする方向(feedback connection)を考えていなかったため、大きなスケール変化に対応できていなかった。本論文は1991年のCVGIPで発表された論文に発想を得て、アップサンプリングとダウンサンプリングを交互に繰り返す構造を取り、SoTAを達成した。
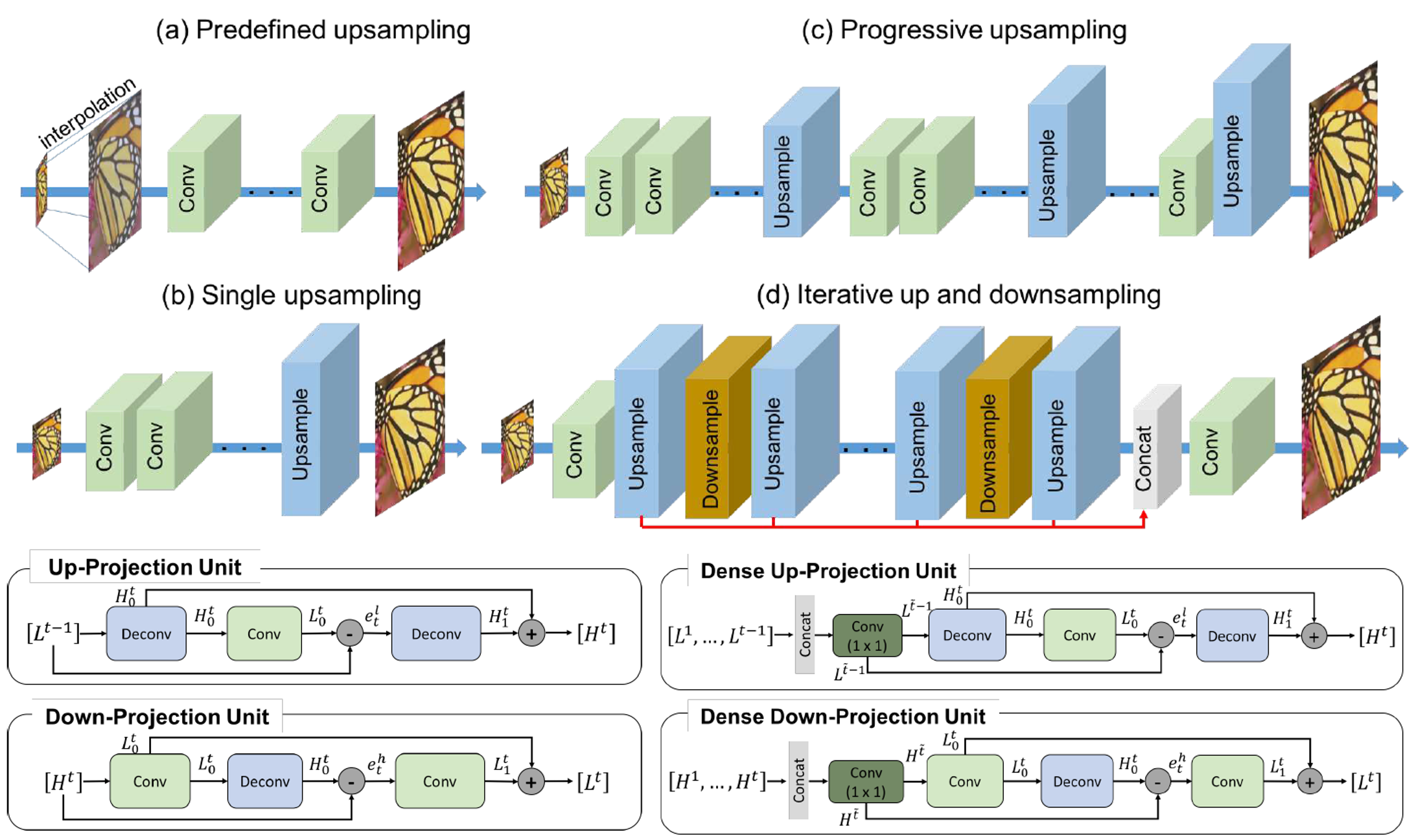
DBPNはup-projection unitとdown-projection unitからなる。up-projection unitの手順は、1) 一つ前の状態の低解像度画像(LR)をスケールアップし高解像度画像(HR)を生成し、2) 次にHRをスケールダウンさせたLRを得る、3) スケールアップとスケールダウンを経て得られたLRと入力のLRの差分を計算した後、4) その差分を元に再度スケールアップをすることでHRを得る、5) 最後にこのHRと最初にスケールアップで得られたHRを足し合わせたものを最終的なHRの出力とする。down-projection unitはこの反対の操作を行う。
属性を階層的に選びながら画像生成できるDTLC-GANを提案.階層的な構造を課すために,我々はDTLCと呼ばれる新しいアーキテクチャを生成器入力に組み込む.DTLCとは,教師データなしまたは,最上位層の教師データだけで改装の表現を自動で発見できるアルゴリズムである.DTLC-GANをMNIST,CIFAR-10,Tiny ImageNet,3D Faces,CelebAなどのさまざまなデータセットで画像生成や画像検索のタスクの有効性を確認した.
アウトライヤのあるデータについての部分空間クラスタリングでは,正則化最適化による従来法によればデータサイズに対して計算複雑性が多項式スケールで伸びる. また,手動チューニングが必要.
本稿では,データから直に計算できる二乗和の多項式の評価に基づく外れ値除去アルゴリズムを提案する. 計算量がデータサイズに依存しない特異値分解は2回だけ求めればよく,効率的に計算できる. インライヤ・アウトライヤ分類の誤り率を出力する枠組みも提供.
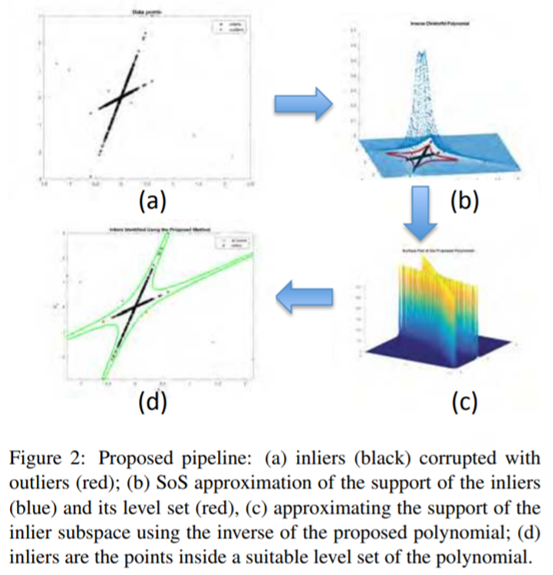
外れ値除去について,理論的な枠組み,効率的な計算を提供.
種々のデータセットにおいてSoTA性能を確認.その時の計算時間は従来法より10~50倍速い.
深層学習において大域最適解に導くソルバー(BPGrad)の提案.Branch & Pruning(分枝限定法)を導入している.
リプシッツ連続性の概念で説明している.DLの関数がリプシッツ連続になっている,あるいはリプシッツ連続になるように 近似して滑らかにすると,小さくて急峻な崖に陥るのを防げると説明している. リプシッツ連続を考えると,大域最適解の上限・下限がうかがい知れ,かつ 滑らかにできてよいらしい.
Branch(枝分け):次に移動すべき勾配方向を提案,Pruning(枝刈り): 理論的に大域的最適解が無いと分かっている領域には行かない.
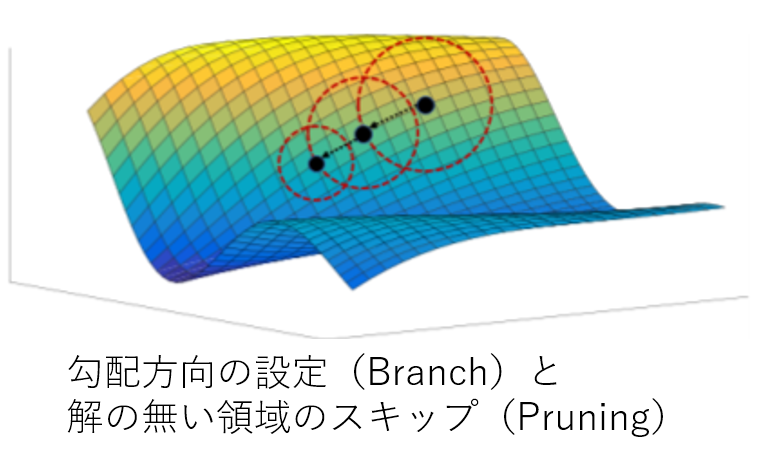
理論的に大域最適解にアプローチする手法として初出,と主張.(本当?)
認識,検出,セグメンテーションのタスクにおいて,従来のソルバーより性能が良いことを確認.
画像中の(曲)線の構造理解(delineation)において,常習的に用いられているピクセルワイズのロス(バイナリクロスエントロピー)では行われていない, 穴あきや隣接線の数などの,トポロジカルな構造を考慮したロス(Topology-aware loss)を提案する. Imagenetで学習済みのVGG19を特徴記述子に使い,それと推定されたdelineationの差を見る. このペナルティ項をバイナリクロスエントロピーに追加してロス関数を設計する.
また,計算の複雑さを維持したまま,同モデルにおいて反復的に適用するリファインメントのパイプラインも提案.
![]()
いくつかのケースではバイナリクロスエントロピーの2倍の性能が出せた.顕微鏡画像から空撮画像までの幅広いレンジにおいてSoTA性能が出る.
確かにトポロジカルな構造を見るべきだろうと思うが,その特徴はImagenetで学習済みなのでそれを使うというのが注目すべきと感じる.
画像のノイズ除去のためのネットワークを提案。ネットワークはlocalな情報を見るものとnon-localな情報を見るものの2つを提案した。 ネットワークの評価関数としてはPSNRを用いた。

従来手法と異なり、ノイズのレベルに依らない手法である。CNNベースの従来手法よりも浅いネットワークにもかかわらず、PSNRの平均は最も高いという結果が得られた。
Person Re-identificationのラベル付けを最小化する手法を提案した。教師有りの手法は最も頑健であるが、カメラの数が増えるにつれてアノテーションの負担が増える。 そこで、少ないアノテーションからアノテーションのないペアの関係を推定することで問題を解決する。 例えば、カメラ1と2、カメラ1と3の間で同一人物と判定されたペアは2と3でも同一人物と推測される。 頂点を人物画像、エッジを同一人物であるかのスコアとしたグラフを考えることでアノテーションの補完を行う。 解くべき問題はNP困難であるため、計算量削減のための手法を2つ提案した。
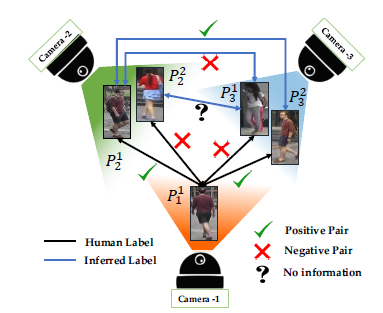
2つの計算量削減手法はいずれも1/10にすることに成功した。WARD,RAID,Market1501の3つのデータセットにて数値評価し、ベースラインよりも少ないラベルでも全てラベルが存在する場合と同等の精度を出せることを確認した。
画像に対するアノテーションを自動で生成するdiverse and distinct image annotation(D2IA)を提案した。クラウドソーシングなどで人間の手によってアノテーションをする場合、人によって基準が異なる。 例えば、同じものを対象にしてもある人は教会と具体的にアノテーションするのに対して別の人には建物とより抽象的にアノテーションする。 他にも、ある人は建物の色に着目をするが別の人は写っている人の持ち物に着目する。 このように、人間のアノテーションの特徴を反映したモデルの構築を目指す。 アノテーションの生成はGANベースのモデルにより学習する。 Generatorは画像からアノテーションを出力し、Discriminatorは画像とアノテーションのペアから適切なアノテーションかを判定する。
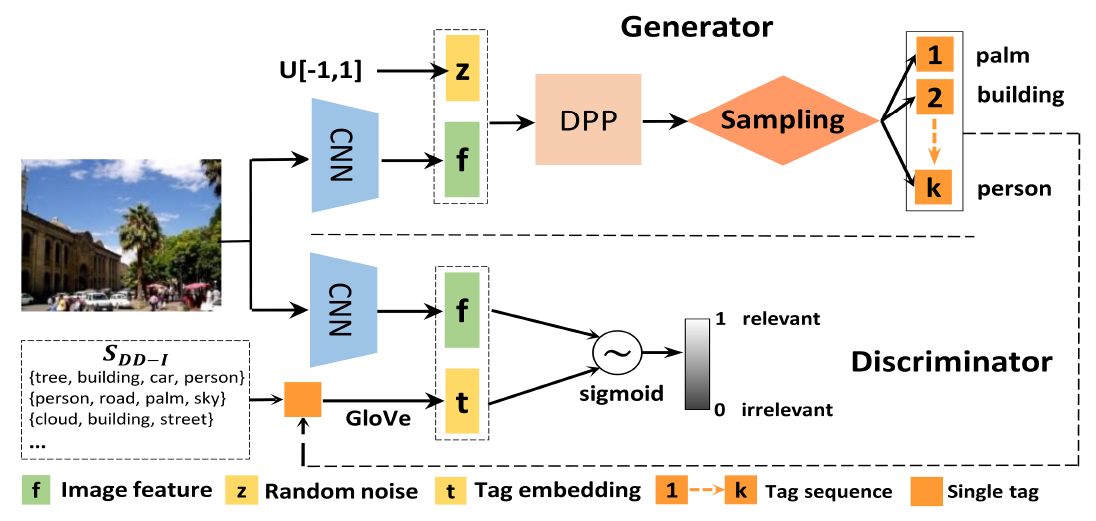
Precision, Recall, F1で評価し、RecallとF1は従来手法と比べ最も良く、Precisionも最も良いものと比べ差が1%以内だった。ユーザースタディにおいても提案手法の方がいいと答えた人の方が多かった。
人間の判断に基づいた新たな画像キャプショニングの評価指標を提案した。画像、正解となるキャプション、生成したキャプションの3つを入力とし、生成キャプションが人間の作ったものであるかを判定することで学習を行う。 これにより評価時にはキャプションに対するスコアを出力する。 また、data augmentationの方法として他の画像のキャプションを使う、単語の一部を並び替える、単語の一部を置き換えるの3つを提案した。
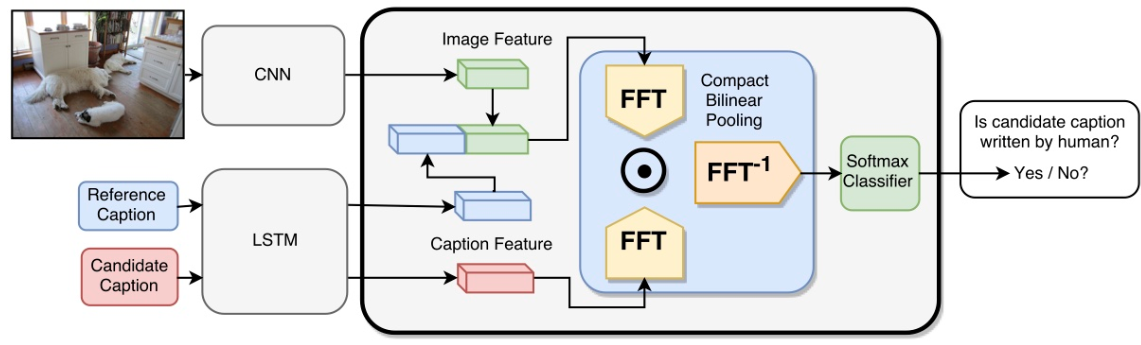
従来提案されてきた評価指標と比べ人間の評価と相関が高く、Pearson's correlationが0.9を超えた。(従来のものの最大は0.75程度)
画像(orテキスト)からそれに対応するテキスト(or画像)を検索する手法を提案した。学習の過程はLook, Imagine, Matchの三つのステップに分けられる。 Lookでは、queryとして与えられた画像(orテキスト)から特徴量抽出を行う。 Imagineでは、得られた特徴量からテキスト(or画像)を合成する。 Matchでは、合成したテキスト(or画像)との類似度によってテキスト(or画像)の検索を行う。
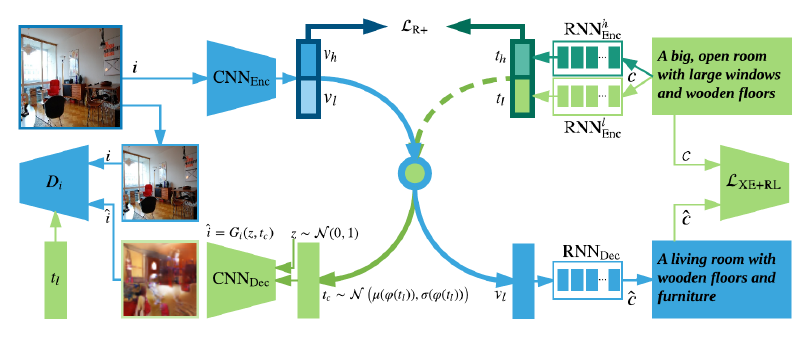
従来手法では画像とテキストの特徴を共通の空間にマッピングしていたのに対し、それぞれを別に扱うことで画像の詳細を考慮することを可能にした。上位1位、10位のどちらの検索においてもベースラインよりも高い精度での検索を実現した。
車の車載カメラから、人間(歩行者や自転車)の動きを予測する手法を提案した。人間の動きを予測するBayesian Bounding Box Prediction Streamと、車自体の動きを予測するOdometry Prediction Streamの2つにより構築されたモデルにより長期的な予測を実現する。 人間のBounding Box(BB)は、過去のBB、過去及び予測される車の動きから推定する。 車の動きは、過去の車の動き及び車載カメラの画像特徴から予測する。
人間の動きの不確かさを含めて予測することが可能となった。Kalman Filterと比べ、提案法はBB、車の動きどちらも高い精度で予測することが可能である。
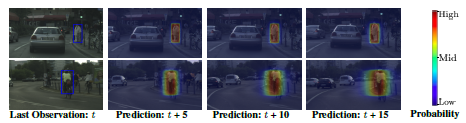
動画中に映る関連した一連のeventの集まりであるsuper-eventsという概念を導入し、Super-eventsに含まれる検出する方法を提案した。例えば、バスケの試合においてシュートを打つという行動とブロックするという行動は連続して起こる行動であり、関連しあっている。 このような一連の行動(シュートを打つ、ブロックする)をsuper-eventsと呼ぶ。 始めに、動画の各フレーム(or segment)からCNNにより特徴抽出を行う。 得られたCNN特徴から、context情報を考慮するためのTemporal Structure Filterというものを導入することでsuper-eventsを表す特徴を得る。 最後に、各フレームのCNN特徴とsuper-events特徴を用いてフレームごとのイベントを検出する。
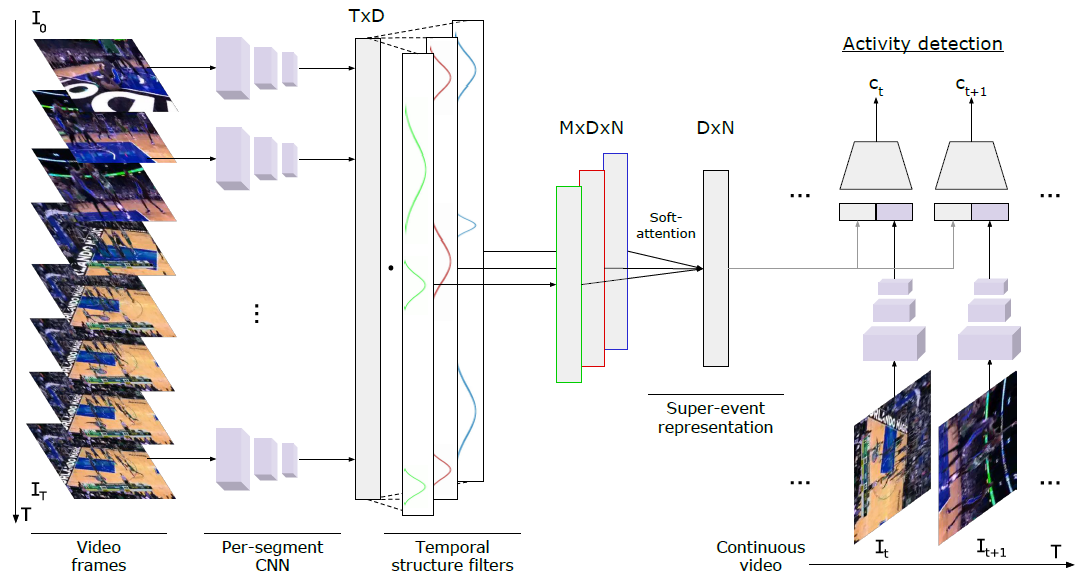
MultiTHUMOS、Charades、AVAの3つの動画データセットにより実験を行った。Super-eventsを抽出することで、ベースラインでは検出されないイベントが検出することができるようになった。 I3Dにsuper-eventsを導入したものが最もmAPが高いという結果が得られた。
ファッションアイテムを検索するネットワークとしてFashionSearchNetを提案した。 FashionSearchNetは、クエリ画像に対して、襟の色のみ変えたものなど局所的なattributeを変えたものを検索することを実現する。 入力のファッション画像に対して、各attributeが画像中のどの領域に存在するかを示すAttribute Activation Maps(AAMs)を得る。 次に、AAMsより推定したROI内のconv5層の特徴を取得し、全結合層により各attributeを表す特徴量を得る。 最後に各attributeの特徴を結合して4096次元の特徴ベクトルを得る。

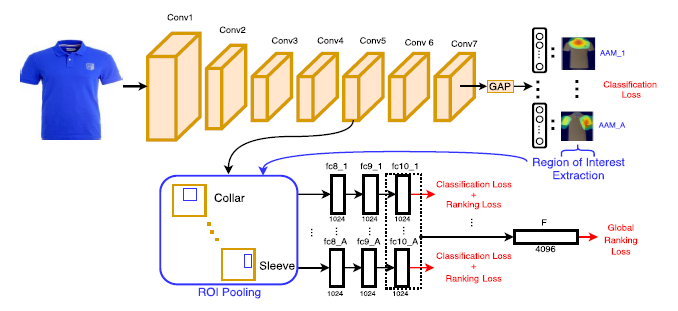
ベースラインの手法と比べ、FashionSearchNetは16%正確度が向上した。GPU計算の場合、60秒で1万枚の画像を処理することが可能である。
顔向きの違いを含めて学習するGANベースの表情認識手法を提案した。顔画像から、個性、表情、顔向きをそれぞれ表す特徴量を抽出する。 Generatorによってこれらの特徴量から表情、顔向きを変化させた画像を生成する。 Discriminatorは、個性とアトリビュートを判定する2つを用意する。 個性を判定するものは、顔画像から抽出した個性特徴によって判定を行う。 アトリビュートを判定するものは、顔画像及び表情・顔向き特徴によって判定を行う。 表情の識別器は、学習データに加えGeneratorによって生成した画像を用いて学習する。
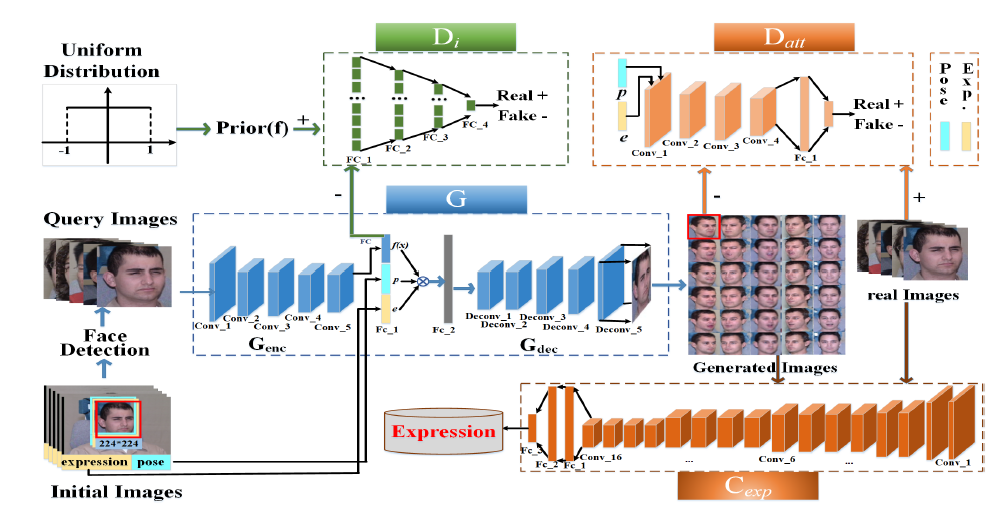
Generatorによって表情、顔向きを変化させた画像を生成することによって、少ない学習データでも表情識別器の学習が可能となった。Multi-PIE、BU-3DFE、SFEWの3つのデータセット全てにおいて平均の識別率は従来手法と比べ最もよい数値を記録した。
Visual-Inertial SLAM(VI-SLAM)の最適化計算に関する研究。画像情報と慣性情報を用いたポーズ推定は、VI-SLAMの計算時間を大きく左右する。 SLAMはその応用先ゆえにリアルタイムで動くことが求められるため、高速化にはポーズ推定の高速化が求められる。 そこで、従来手法と比べより効率よく最適化する手法を提案した。
従来法では短期間の情報しか最適化に用いることができなかったのに対し、計算効率を10倍に向上することでより長期的な情報を使用して精度を向上することに成功した。
他の人種や性別(source)による学習結果を用いることで、学習データが少ないグループ(target)に対しても適用可能な年齢推定手法Deep Cross-Pupulation(DCP) age estimationを提案した。始めに、データが多いグループ(source)を用いてranking problemとして学習することでグループに依らない共通の特徴(low-level aging features)を取得する。 次に、得られたパラメータからsource, targetそれぞれのネットワークを更新していく。 ここでは、source, targetそれぞれの顔画像を入力として2枚の画像が年齢が同じか異なるかを学習していく。 これにより、グループごとの年齢特徴(high-level aging features)を得る。
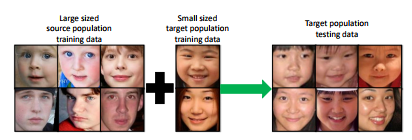
従来手法はグループごとに学習していたため、データが少ない人種などには適用が難しかったが、提案手法によりデータが少ない人種への適用が可能になった。Morph Ⅱ,WebFaceで実験をしてMAEがベースラインと比べ最も小さく(3.1~4.6程度)なった。 targetのデータ数が10%程度の場合でもMAEが5.3となった。
動画の初期フレームと、モーションの軌跡を入力することで動画を生成する手法を提案した。入力画像とフローベクトルから、Flow、Hallucinated output、Maskの3つを予測するネットワークにより実現する。 予測フレームの情報が、入力画像に含まれている場合はFlowによる変形によりピクセル値を取得する。 一方で、初期フレームに映っていない情報や、色の変化についてはFlowによる変形では実現できないため、Hallucinated outputにより取得する。 上記2つの画像のうち、どちらの情報を用いるかをマスクによって指定することで出力を取得する。
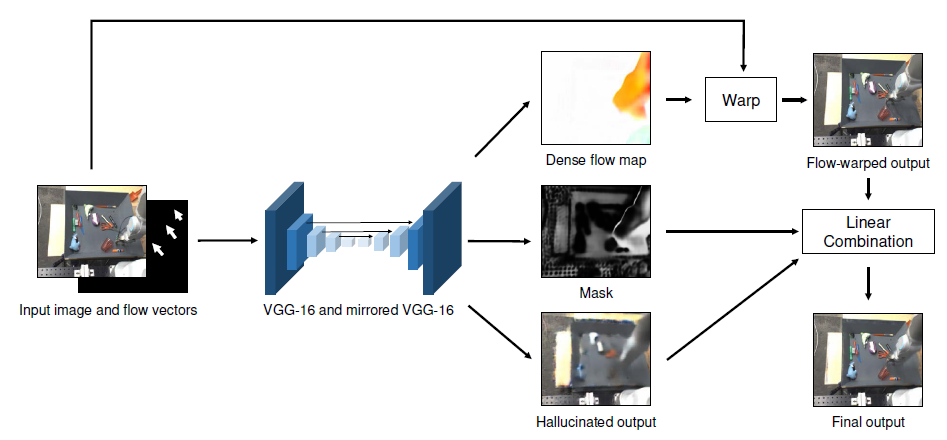
KITTI、Robotic Pushing、UCF-101の3つのデータセットにより実験を行った。各データセット中の動画から得られるFlowを入力として実際の動画中のフレームと予測フレームを比較したところ、PSNR、SSIMいずれの手法も提案手法が最も良いことを確認した。 ユーザースタディの結果、Flow、Hallucinated outputのいずれかがない場合よりも両方ある場合の方が圧倒的に高い評価を得られた。
Action Unit(AU)の強度を推定するための弱教師学習手法を提案。表情認識の分野でAUは広く研究されているが、アノテーションの難しさから強度のラベルが付いた大規模データベースは存在しない。 そこで、比較的アノテーションが容易であるピークと谷のアノテーションのみから学習する弱教師つき学習手法を提案する。 アノテーションのついていないフレームについては、ピークと谷とのrelevalenceを考える。 その際、時系列的に近いフレームはrelevalence及びAUの強度は近い値になるようにすることで平滑化する。
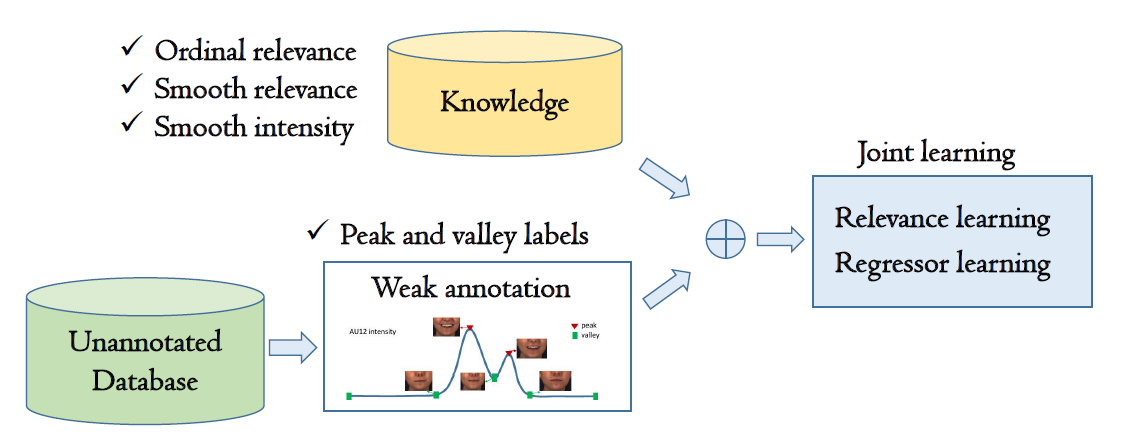
FERA 2015, DISFA, PAINの3つのデータベースにより実験を行い、PCC, ICC, MAEの3つの指標を評価した。FERAは、1つのAUを除いて全ての指標がベースラインよりも良いという結果が得られた。 DISFAについてはPCC, ICCは多くのAUで最も良い数値となったがMAEは12のAUのうち4つのみが最も良い数値となった。 PAINについては、弱教師つきの従来手法よりはPCC, ICCが良いという結果が得られた。
人間の3次元モデルの時間変化を、頂点の対応付けを行うことによってデータ量を圧縮する手法を提案した。多視点のdepthマップから作成した、Panoramic Depth Mapsを入力とすることで、3次元モデルの頂点の対応付けを行うネットワークを構築する。 得られた対応付けに基づき、頂点の時間変化を考える。 この時間変化に対するAuto Encoderを考え、中間層の出力を3次元モデルの時間変化として取り扱う。
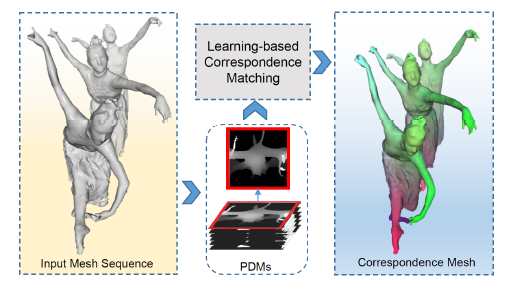
従来手法と比較して、対応付けの誤差が小さく高い圧縮率を実現することに成功した。PCAベースの圧縮手法と比べ、圧縮の際の誤差を小さくすることに成功した。
この研究で行われたことは以下に示す3つである.

GOPRO datasetを用い提案ネットワークを定量的(SSIM, PSNR)に評価した.また,定性的評価には参考文献のreal blurry imageを用いた. その結果,提案手法がSoTAアルゴリズムと比べ,精度,スピードとモデルサイズにおいて優れていることがわかった.
スプライン曲線あてはめにおいて,異なるタイプの残差のバランスがとれるような確率ベースの重みづけについて提案.スプライン曲線あてはめの近似誤差の推定を統合するところが新しい.
また,スプライン曲線あてはめの質の尺度を提案.スプライン曲線の中間点のスページングの自動化などに貢献できる.

ディープ系ではないが,先に行った推定結果を処理に使うというあたり,イマドキ感を感じる.
複数視点系の話題で,非線形の設定においては,Canonical Correlation Analysis (CCA) という手法が一般的になってきた.この既存のDeepなCCAにおいては,典型的には, 一般潜在空間における異なるアピアランスの相関が最大化される前に, 最初にそれぞれのアピアランスにおける特徴次元の間の相関除去を行っている. このCCAでは,学習イタレーション毎に,逆行列計算に依存する計算コストの高い相関除去の計算が求められる. しかも,この相関除去のステップは勾配効果最適化の枠組みからは離れており,その結果準最適解に落ち着いてしまう.
本稿では,Soft CCAを提案する.Softといっているのは,CCAの計算途中に直交性が求められるところの条件を,SGDで最適化されるソフトなコスト関数に置き換えるというところ. ミニバッチベースの確率的相関除去ロス(Stochastic Decorrelation Loss; SDL)を導入. これは,その他目的関数と結合的に最適化される.
このSDLはマルチビュー問題以外にも適用可能である.
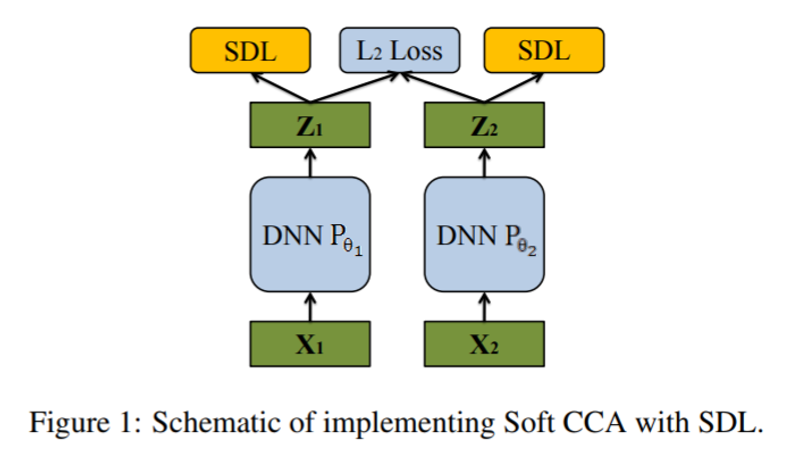
流行の手法の確かな発展.
ネットワークの計算省力化に,ネットワークパラメータのデータビット数を下げるやり方がある.重み・活性化パラメータの分布をコードブックで近似表現することで行われるが, 1-8bitまで量子化すると,フォワード・バックワード関数の大きな勾配ミスマッチが起こるために著しい精度低下が起きていた.
本研究では,この損失を,特定の重みサブグループにおけるシンメトリックなコードブックの学習によって問題を解決する. サブグループは,重み行列の中での局所性に基づいて考慮される.
1-2 bitの重み,2-8 bitの活性化でもうまくいくことを示す.
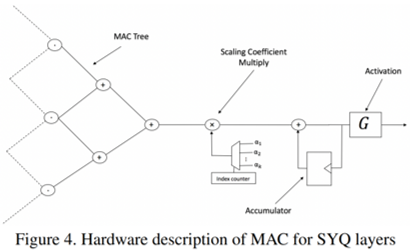
ひどく量子化してデータ削減してももうまく行っちゃうというすばらしさ.
domain adaptationの一般的なフレームワークの提案.エンコーダーネットワークによって抽出される特徴に制約をかけるために,最近提案されたペアなしのimage-to-image変換に対する新しい利用方法を提案する. このように制約をかけて得たい特徴は以下のような性質を持つ ・抽出された特徴は2つのドメインでの画像に再び戻せる ・2つのドメイン画像から抽出された特徴の分布は区別できない(Dを騙せる) 実験では,domain adaptationの問題として数字の分類や車載動画のセマンティックセグメンテーションのタスクを取り上げ,state of the artを超えた.
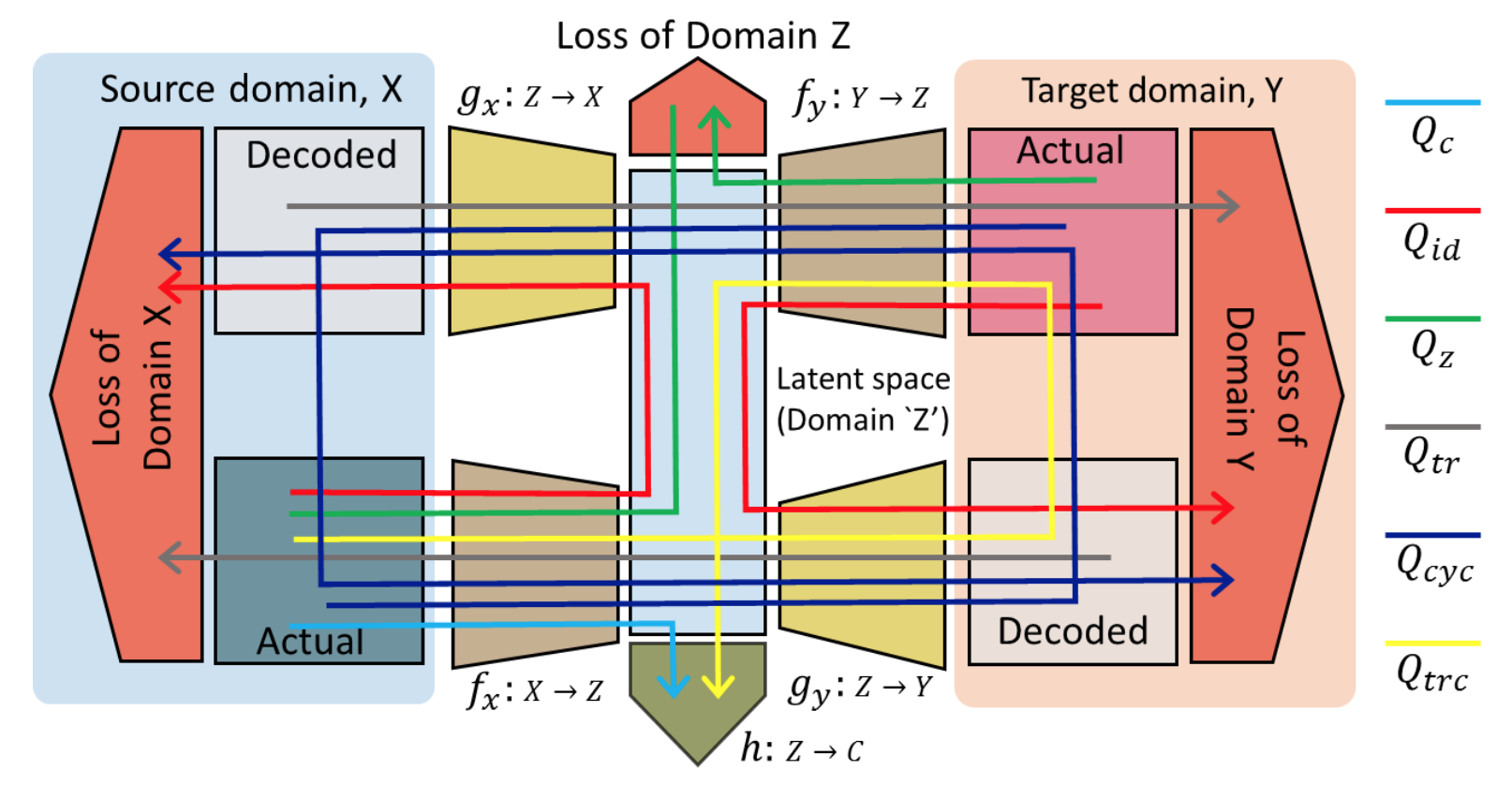
一つのフレームワークの中で,image-to-imge変換とソース側の分類問題,そしてdomain adaptationを行なっている.
3次元点群のおけるセマンティックセグメンテーションや物体認識のための、新しい畳み込み操作を提案した論文。これはpointwise convolutionと呼ばれ、点群の各点々に適応可能である。この操作を用いることにより実装が簡単になり、他のネットワークと同程度の精度を実現できる。 Fig.1に示すように、注目点を中心としてカーネルを設置し、分割されたセル(Fig.1では3X3X3)ごとに平均を計算し、畳み込むという計算を行う。
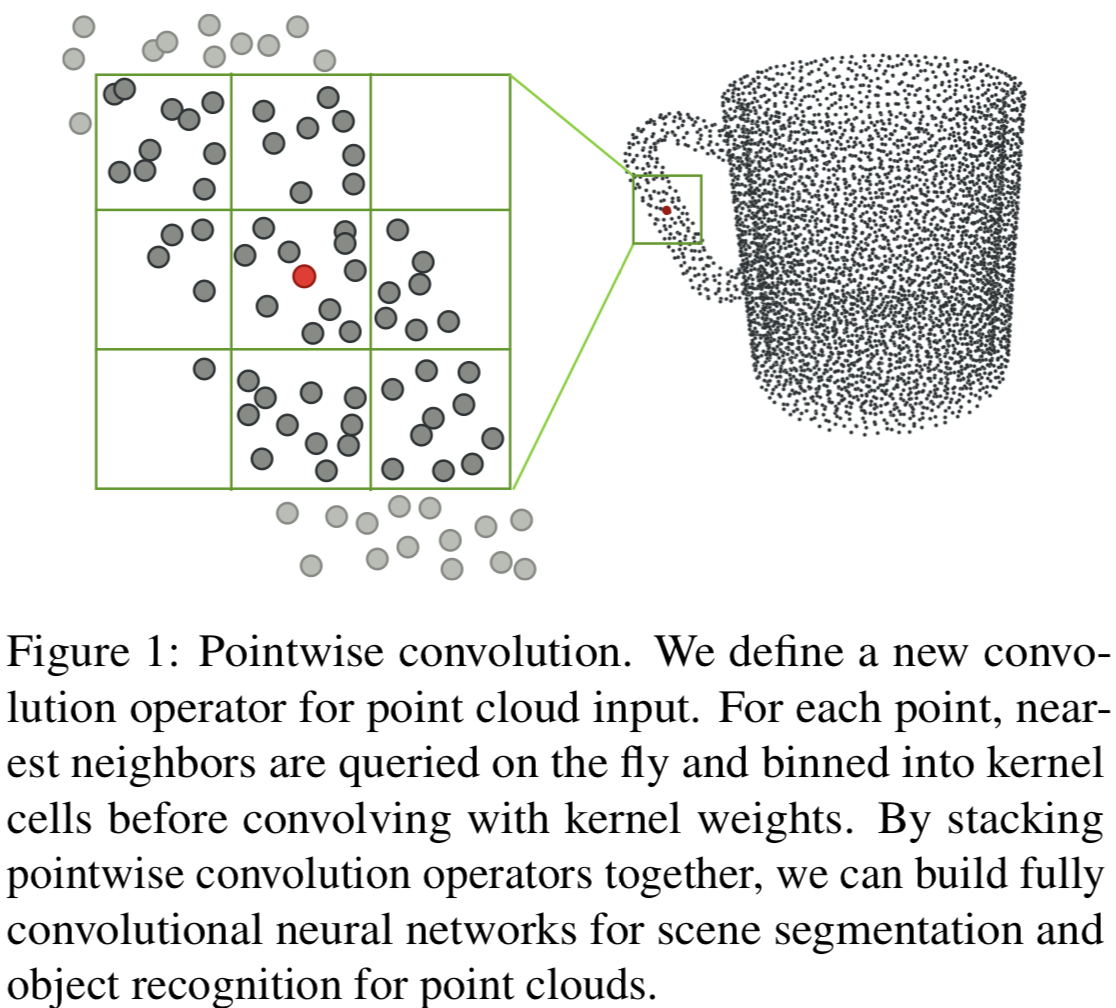
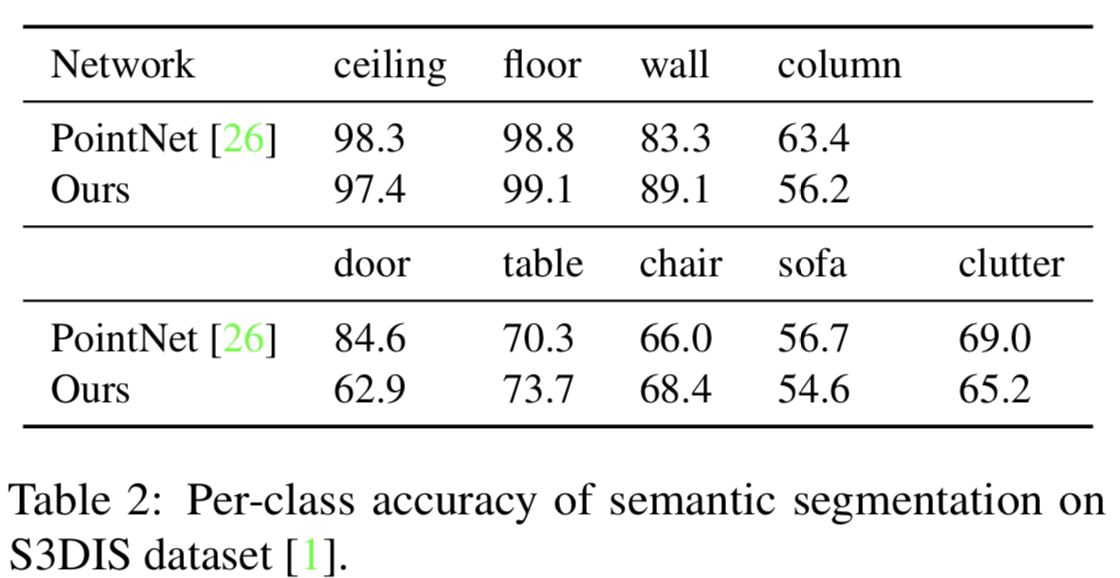
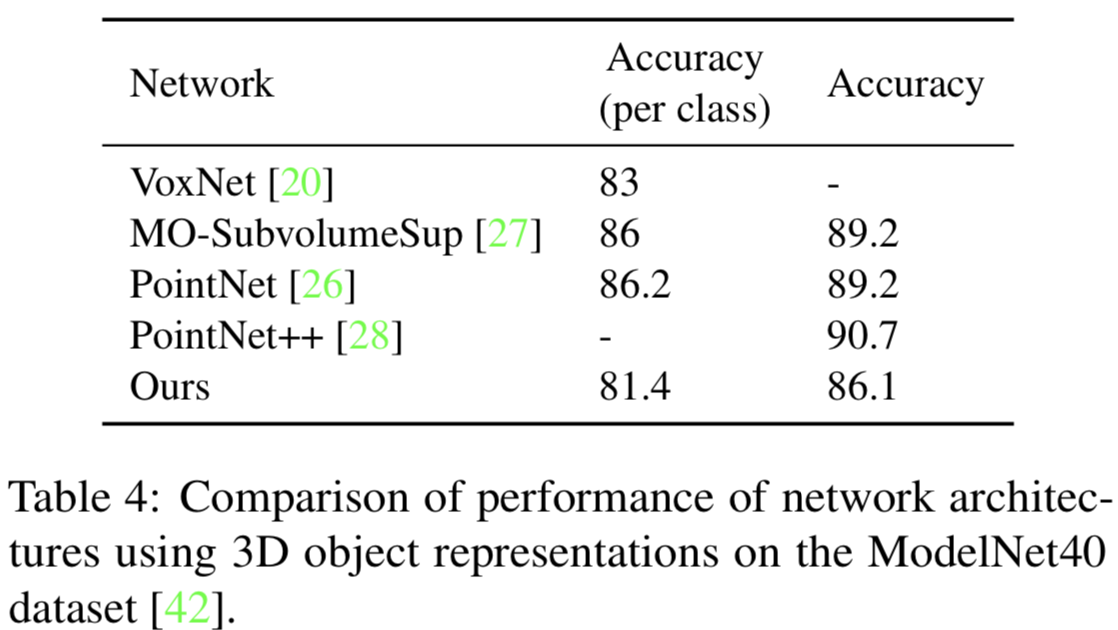
セマンティックセグメンテーションの結果をTabl2に示す。これより、PointNetと比べて同程度の精度を達成していることが分かる。ここで、評価用データセットにはS3DISを用いた。物体認識の結果をTable4に示す。これより、SoTAな手法と比べ同程度の精度を達成していることが分かる。ここで、評価用データセットにはModelNet40 datasetを用いた。
zero-shot learning(ZSL)で問題となっているソースデータとターゲットデータに対する識別精度のバイアスを緩和するための手法をtransductive ZSLの設定で新しいロス関数を提案。transductive ZSLとはトレーニング中にラベルをもつ画像から成るソースデータと、ラベルを持たない画像から成るターゲットデータを扱う設定である。提案手法では既存研究で用いられている、ソースデータに対するclassificationロス(+正則化項)に加えて、ターゲットデータに対するロス関数として、ターゲットデータがどのターゲットカテゴリに所属するのか、という確率を足しあげlogを取ったものを加える(正確には減算をする)。 実験ではターゲットデータに対する識別精度を算出するZSLの設定と、ソースデータとターゲットデータの両方に対す識別精度を算出するGZSLの設定を検証する。
テスト時にトレーニングでは扱わなかったクラスのインスタンスを扱うzero shot learning(ZSL)において問題視されていたsemantic lossを解決するモデルSemantics-Preserving Adversarial Embedding Network (SP-AEN)を提案。semantic lossとはトレーニングで使用されたデータであるseen classesとテストで初めて扱うデータであるunseen classesにおける分布の違いから、トレーニングされたモデルがテスト時にうまく機能しない問題である。これに対して提案手法ではZSLでそれぞれ独立に提案されていた画像のリコンストラクションを行うencoder E, decoder Dとラベルの識別を行うclassifier C、EとCから得られる特徴量を識別するDを組み合わせたモデルを提案。EとCを用いることでリコンストラクションとラベル識別を独立に行い、かつDをGANベースに学習することで、Cはインスタンスごとの学習に重きを置くEの効力を得ることができるモデルとなっている。

Generalized Zero-Shot Learning(GZSL)のバイアスを小さくするためのCVAEとクラスラベルのclassifierを組み合わせたモデルを提案。GZSLとは、テストの際にトレーニングで使用した(seen)クラスとトレーニングでは使用していない(unseen)クラスの両方を扱う問題を指す。既存手法ではトレーニングされたモデルを用いた識別などにおいて、seenクラスに対するバイアスが高いことが問題であった。提案手法ではclassifierのロスをdecoderに流し、かつdecoderによって合成された画像をラベルなし画像として扱い半教師学習を行う。テスト時にはseenクラスとunseenクラスの画像を合成し、合成された画像を用いてSVMを学習しその識別精度を比較する。
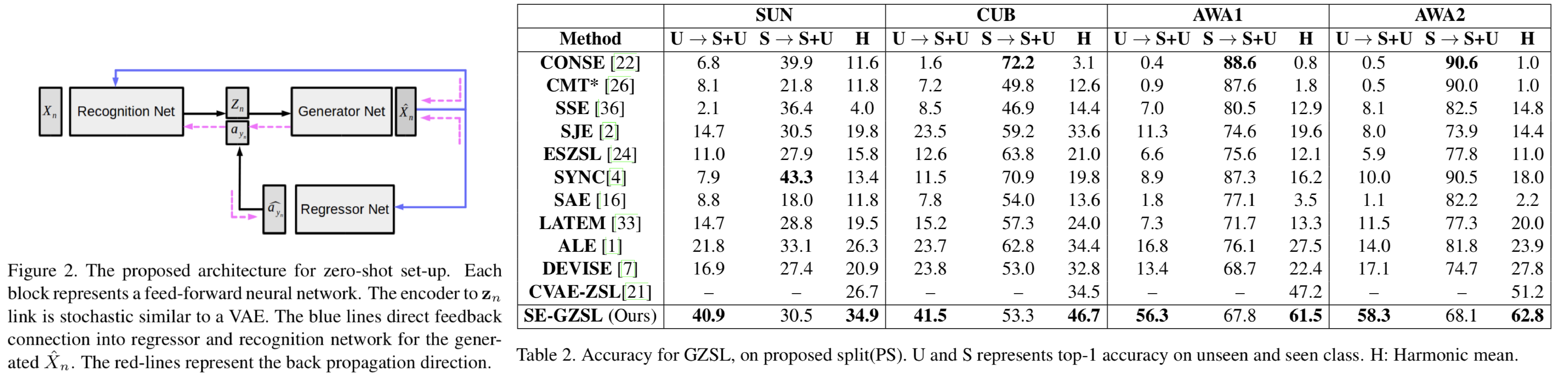
低解像度画像と高解像度画像で同じ特徴量を得るために新しいロス関数focal lossを導入したFeature Super-Resolution Generative Adversarial Network (FSR-GAN)を提案。提案ネットワークは図の通りfeature extractorと低解像度画像の特徴量を高解像度画像の特徴量に似せるgenerator、特徴量のドメインを識別するdiscriminatorからなる。focal lossとはインスタンスごとのL2距離をr乗するというもの。adversarial lossとしてWGANで導入されたEarth-Mover distanceを使用。
大規模データセットを用いた古典的な手法による半教師学習の有効性を調査。古典的な手法としてkNNグラフを用いた拡散アルゴリズムを使用し、半教師学習としてlow shot learningを扱った。low shot learningとはデータ中にクラスなどのアノテーションが施された画像がごく一部であり大半の画像にはアノテーションがないデータセットを扱う問題を指す。大規模データセットであるImageNetなどでlow shot learningを行い、low shot learningのSoTAと古典的な手法による精度の比較を行った。
大規模データセットに対する新しい解析方法であり、データセットの使用方法の知見を深めた論文。2003年の手法が2017年の手法に優っているケースはCVでは特に珍しいのではないか?
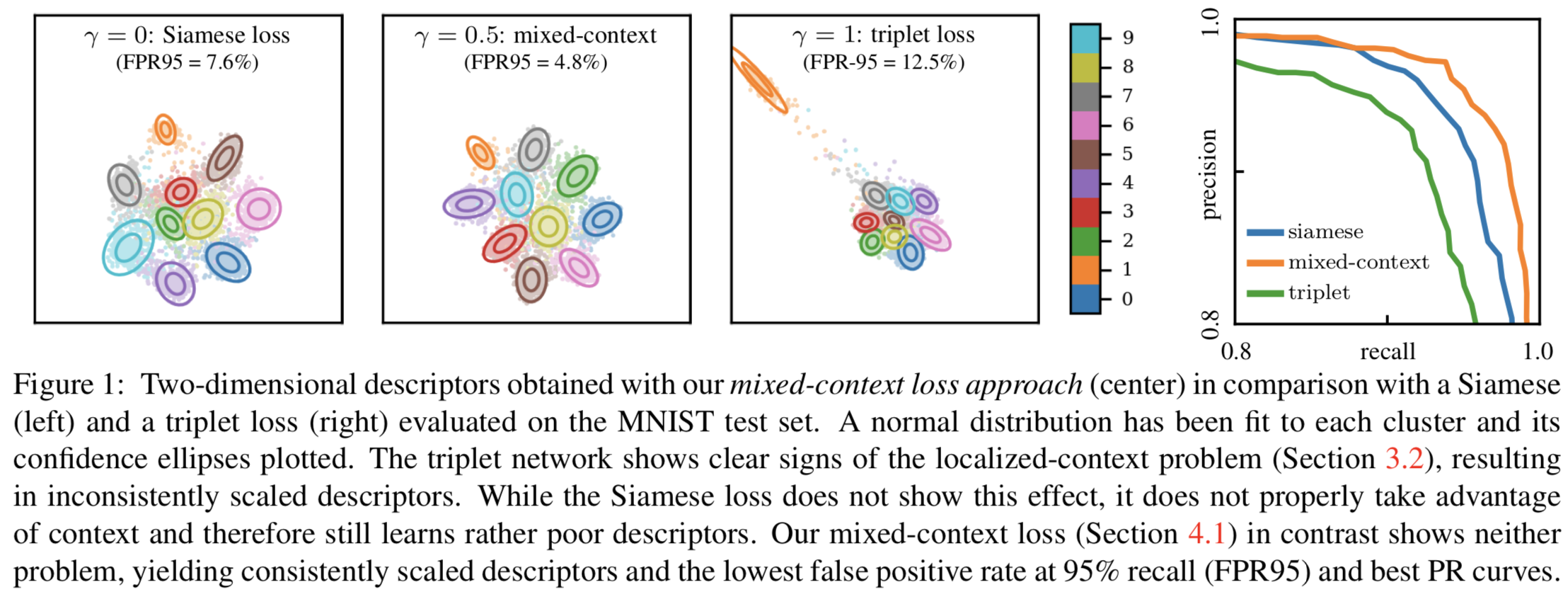
triplet lossをアップデートしたmixed-context lossとサンプリング手法であるscale-aware samplingを提案。triplet lossではサンプルに対するpositiveとnegativeの両方の特徴量距離を同時に学習するため、片方ずつ学習するsiamese lossよりも高い精度を出しやすいことがわかっている。しかしtriple lossで扱う特徴量距離はサンプルごとにローカルに決定されるため、場合によっては右図右から2番目の結果のように、特定クラスに対する結果が良く無い場合がある。提案するmixed-context lossでは、この測定される特徴量距離にバイアス項を加えたtriplet lossとsiamese lossの中間表現をとる。またscale-aware samplingは各バッチごとにpositiveとhard negativeをサンプリング手法であり、ロス関数のスケールを調整することが可能。
convolutionと同じ働きを持ち、パラメタやfloating point operation(FLOPS)が必要ないshift operationを提案。convolutionをshift operation に置き換えることでモデルサイズを小さくすることができる。Shift-operationはconvのようにカーネルをもち、どれか1ピクセルだけ値を1を格納し、それ以外は0を格納しており、1を格納している位置はチャンネルごとに異なる。またカーネルを動かす方向もチャンネルごとに異なる。これに対して1x1convを組み合わせることで、convolutionと同じ機能をもつ。Shift-operationと1x1convを組み合わせたものをshift moduleと呼び、実験では従来のCNNに対してshift moduleを組み込んだネットワークを用いてimage classification、face verification、style transferを行った。
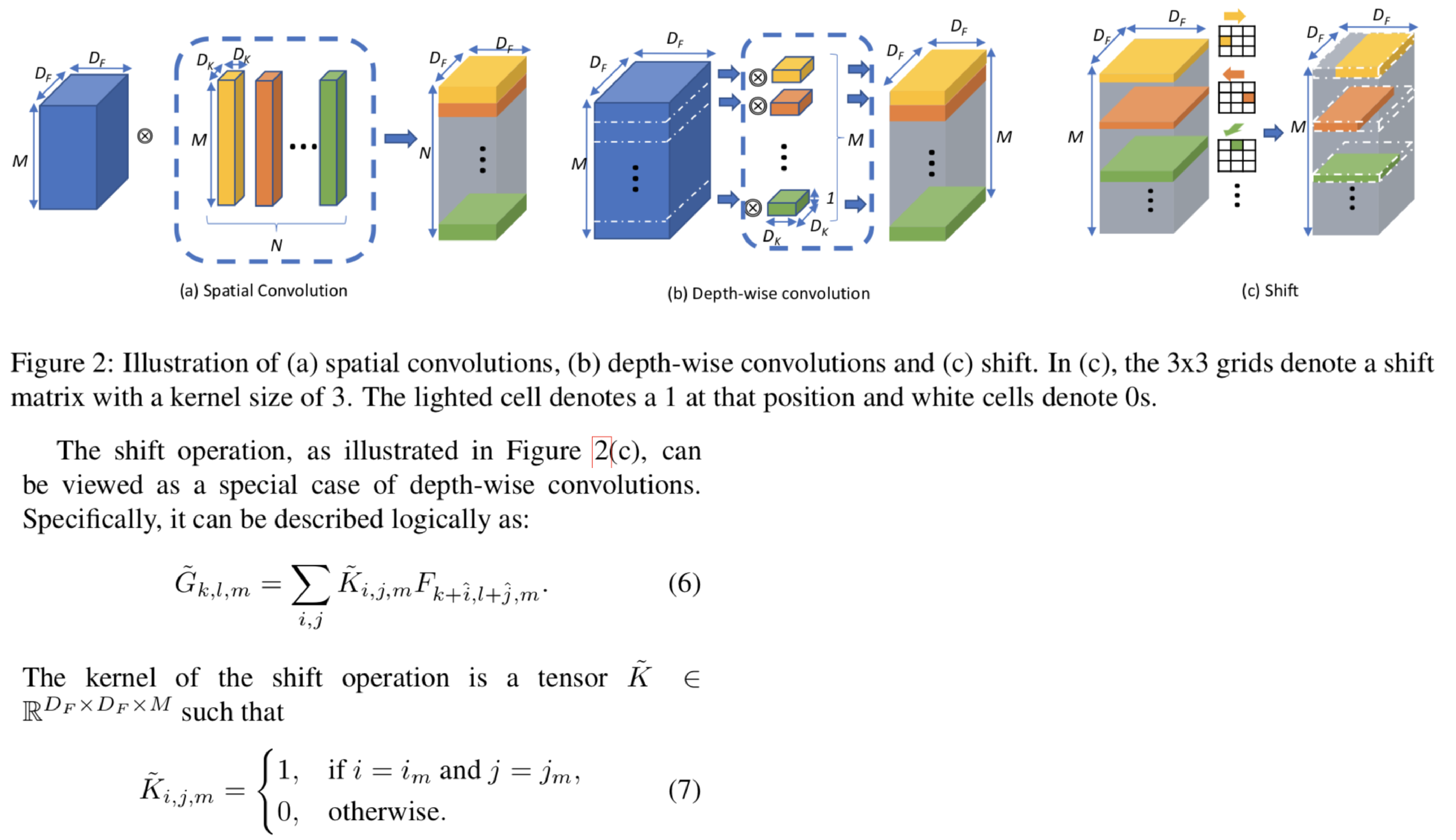
異なるデータ間同士のアラインメントを4つのLSTMモジュールで行うNeuMATCHを提案。one-to-oneやone-to-manyのアラインメントや、既存手法とは異なり、マッチングの順番が必ずしも時系列通りではないnon-monotonic alignmentを扱うことができる。提案手法では様々なデータを扱うことができるが、特に動画とそのストーリーのアラインメントを行う。提案ネットワークは動画のクリップごとの特徴量を持つLSTM (Video Stack)、ストーリーの各センテンスの特徴量を持つLSTM (Text Stack)、過去にどのようなアラインメントを行ったのかを記憶するLSTM (Action Stack)、過去にマッチングした動画クリップとセンテンスを記憶するLSTM (Matched Stack)の4つのモジュールからなる。提案手法の強みとして、Action StackとMatched Stackによって過去の情報を再利用すること(3番目の動画クリップには必ずセリフを対応させる、など)を主張している。また、動画とテキストのアラインメントに対するデータセットの構築も行った。
入力データの形式や種類に柔軟かつ、ネットワークのサイズを学習し直すことなく柔軟に変更することが可能なnested sparse network (NestedNet)を提案。従来の手法ではネットワークの重みやチャンネル数を削除することで新たなデータ形式やサイズの縮小を行っていたが、新たに学習をし直す必要があった。NestedNetはネスト構造をもつnetwork-in-networkの構造をもち、レベルが低いネットワークはレベルが高いネットワークの一部となる。マルチタスクラーニングを行うことで、低レベルのネットワークはタスクごとに共通な特徴量を学習し、高レベルのネットワークはタスクに特化した特徴量を持つ。そのため、データやサイズの制限によって使用するレベルの上限を変更することで以前学習した内容を保ったままファインチューニングが可能。
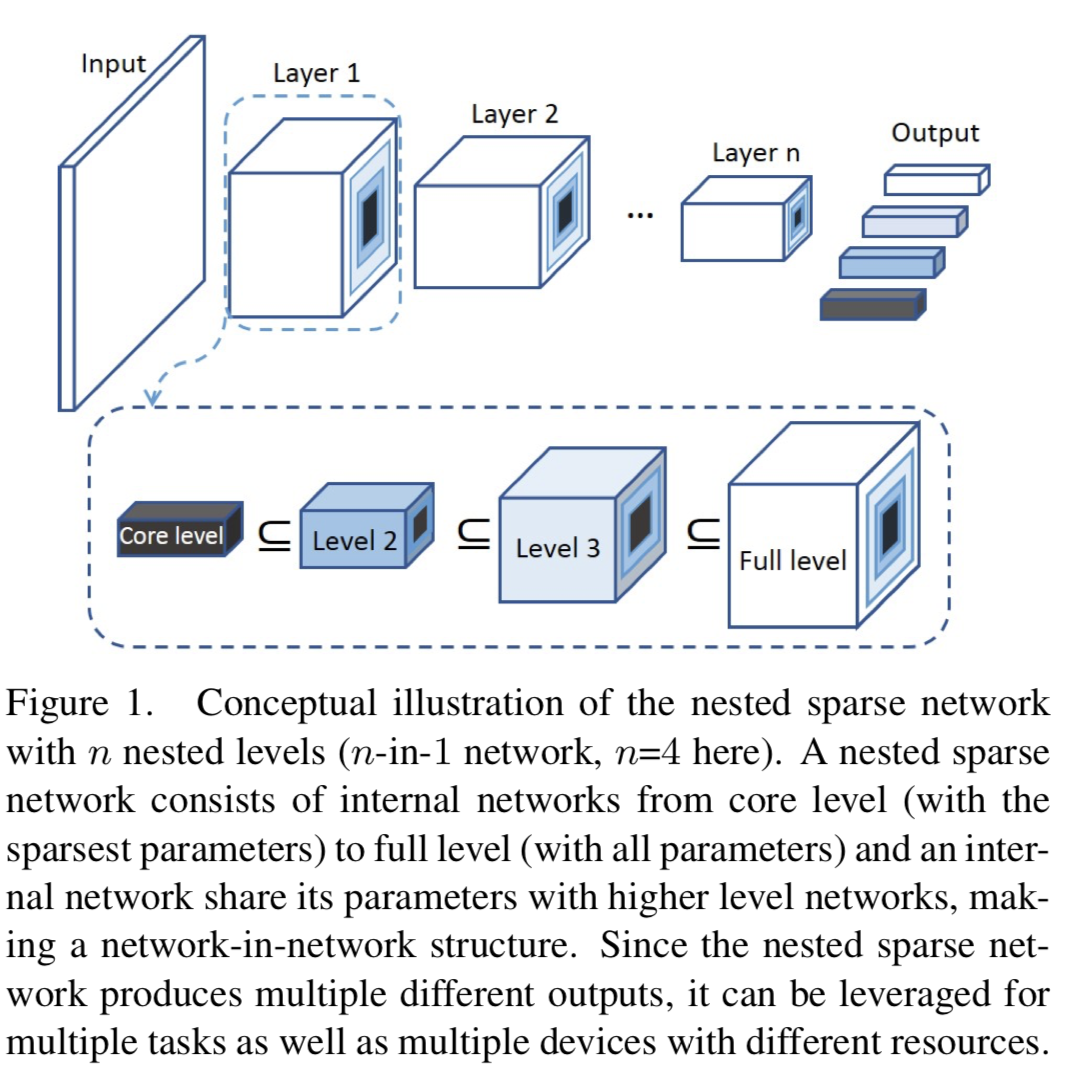
ネットワークの有効性を確認するために、adaptive deep compression、knowledge distillation、hierarchical classificationを行った。
“handbag vs. shoe”と“photo vs. edge”など複数のconceptを学習する際に、いずれかのサブドメイン(photo handbagなど)のトレーニングデータが無い場合にも、他のサブドメインの学習によって画像を生成することが可能なConceptGANを提案。論文では2つのコンセプトで、一つのサブドメインのトレーニングデータない場合を主に説明してる。CycleGANをベースにサブドメイン間のconsistencyを保つために以下のlossを設定
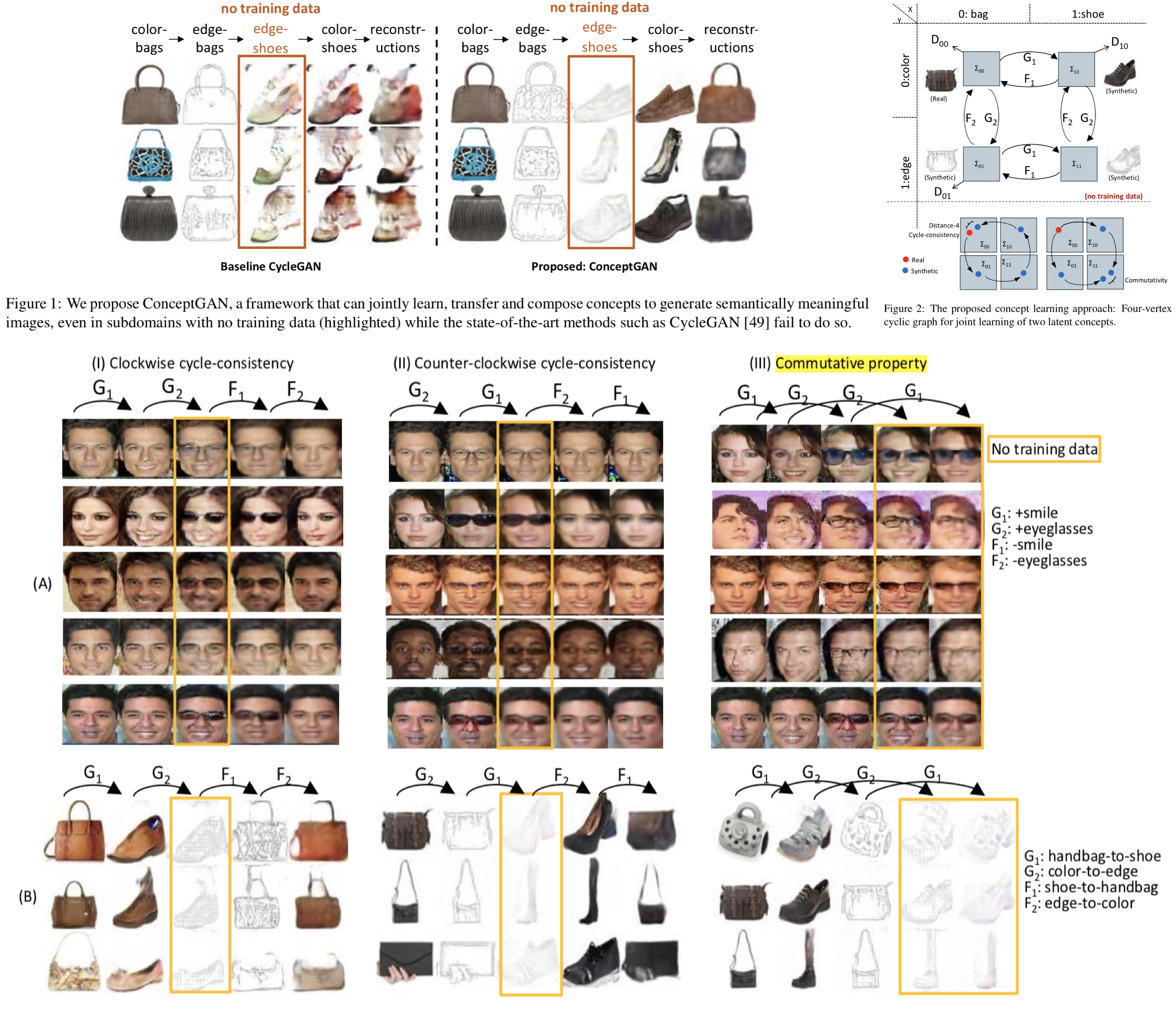
初のストロークレベルのスケッチ抽象化モデルを提案した. 強化学習の Agent がストロークセグメントを観測し, それを残すか消すか決定する. また, 提案手法を用いた新しい写真からのスケッチ合成手法を提案し, fine-grained SBIR (FG-SBIR) のタスクに置いて upper bound(実際に写真とスケッチの対応データから学習したもの)に類する精度を, 写真だけから学習したモデルで達成した.
動画認識における特徴空間の学習で,RGBからAppearanceとRelationを効率的に学習するAppearance-and-Relation Network(ARTNet)を提案.ARTNetは,SMART Blockという複数のブロックから構築されており,このブロックはAppearanceとRelationをそれぞれ学習ブランチから構成されている. Appearance branchは2D Conv.をベースに構築し,Relation branchは3D Conv.をベースに構築している. 3D Conv.と2D Conv.の組み合わせによりAppearanceとRelationを効率的に特徴を抽出できるため,より良い特徴を得ることができる. 最終的に,それぞれのブランチから出力された特徴を結合することで,最終的な特徴を抽出していく.
2D Conv.と3D Conv.を効率的に使ったモデルの提案で,Kinetics,UCF101,HMDB51 Datasetで評価し,従来のC3Dより高精度な特徴抽出が可能であることを示している.
時系列を考慮したAttention機構を導入したRe-identificationを提案.手法としては,各時刻の人物画像をMultiple Spatial Attention Modelsに入力して人物画像からAttentionを得る. Multiple Spatial Attention Modelsでは,ResNetにより特徴マップを抽出してグリッド状に分割し,分割した獲得した各グリッドの特徴からAttentionを施して新たな特徴(Spatiotemporal Gated Feature)を抽出する. このAttentionにより,各時系列で異なる領域にAttentionが強く反応するAttentionを得ることができる. また,オクルージョンに対しても頑健になる. PRID2011,iLIDS-VID,MARS Datasetで評価し,高い性能を達成している.
これまでのAttention機構とは異なり,Attentionが強く反応する領域をばらけさせるためにMultiple Spatial Attention Modelsを導入.かつ,誤差関数にHellinger距離を追加して正則化している. これらの工夫点から3つのRe-identificationのデータセットで高い性能を示している点が評価されたと思われる.
様々な回転や変化に頑健なSteerable Filter CNNs(SFCNNs)を提案.SFCNNsの主の構造は,1枚のカーネルを様々な方向に幾何変化したカーネルを用意し,それぞれのカーネルに対する特徴マップを出力&統合する(Rotation equivariant layer). ここで,SFCNNsのカーネルはCircular harmonics(球面調和関数)をベースに作成しており,カーネルとの線形結合により畳み込むカーネルを決定する. そして,畳み込み層の学習ではこの結合重みを学習により更新する.
回転や変動に頑健なCNNを提案しており,rotated MNIST Dataset(回転込みのMNIST)とISBI 2012 2D EM semantic challenge(脳の細胞壁の境界をセグメンテーションするタスク)において高い性能を達成している.
カーネルの組み合わせでCNNを最適化するアイディアは面白いと思う.2つのタスクにおいて高い性能を示しているが,データセットのタスクとしては少し簡単なのでは?という気がする(この分野ではメジャーなデータセット?)
Deep Neural Networkによる特徴量記述で,ランキングベースでリスト状にパッチの平均精度を直接学習するアプローチを提案.従来の特徴記述ではTriplet+ランキングベースで正負の3つのパッチで学習する方法が多いが,本手法では最近某探索で検索した複数のパッチから,ランキングベースでクエリとの距離を算出していく. ランキングベースの最近某探索で学習する際に,Average Precisionを基準に学習する. UBC Phototour, HPatches, RomePatches Datasetで高い性能を達成.
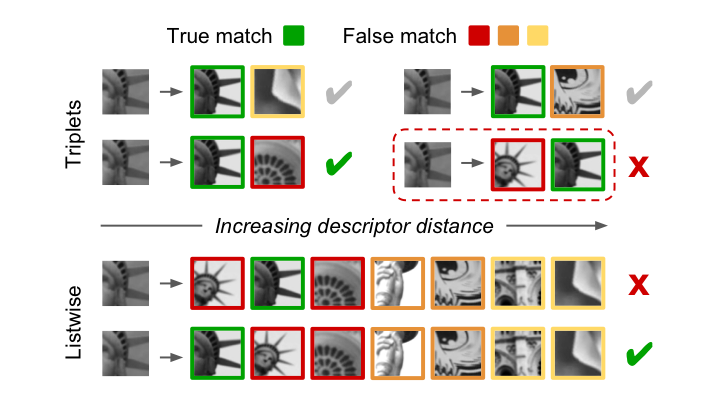
Triplet Lossではパッチの特徴空間の距離に依存しないが,1つのペアで誤認識が発生すると他のペアの学習に影響を与えやすい(らしい.特に類似性の高いパッチのペア).しかし,リストベースだと一部のパッチのランキングが入れ替わった場合でも,学習の悪影響を抑制できる. リストベースにする際にランキングを評価する際に最近某探索をベースにAPを最適化させることで,効率的に大量のパッチを学習できる.
一人称視点における(カメラ着用者以外の手も含む)手領域のセグメンテーションに関して包括的な調査、評価した論文。評価のために、一般シーンでの手領域が含まれている一人称視点データセット(EgoYouTubeHands)と、手と顔という似た外見を持つオクルージョン環境下での評価するためのデータセット(HandOverFace)、EgoHandsから詳細な行動を追加したEgoHands+を作成し、新たに提供している。

HandOverFaceによる手と顔領域の関係の問題設定が良く、結果より肌の色や形状以上のことをCNNが詳細に認識していることがわかる。また大きな手と比較して小さな手はセグメンテーションが困難なことが検証されている。人間にとってもっとも身近なオブジェクトである手に着目して、かつ起こりうる状況を網羅的に実験を行い、手同士のオクルージョン、小さな手、照明条件など新たな問題を提示しており、興味深い論文だった。
既存手法が主に目的としているメモリや計算量の削減のための量子化手法ではなく、FCNの高精度化のためover-fittingを減らすことを目的とした量子化手法を提案。著者らは、元の学習データセットから代表的なアノテーションサンプルを抽出するsuggestive annotationに焦点を当てており、これをベースとして、提案するframeworkは、suggestive annotationでの量子化(QSA)と、高精度化のためのネットワークの学習の量子化(QNT)と2つの量子化手法から構成される。
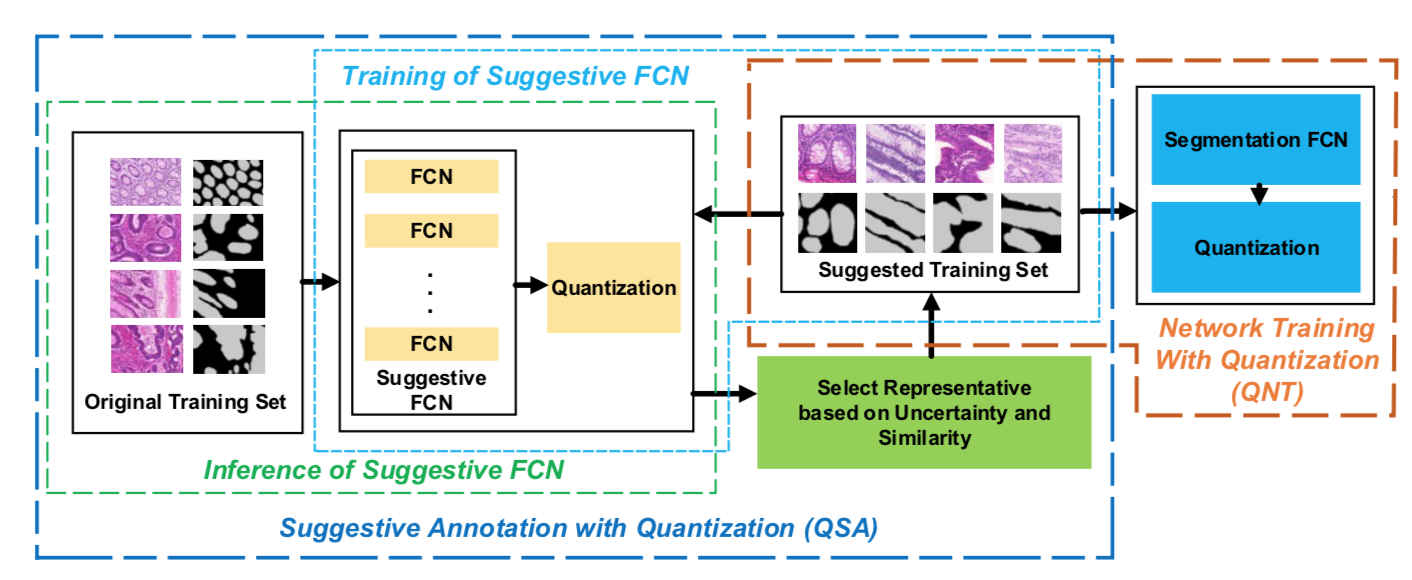
医用画像(suggestive annotation)においてFCNはパラメータが余剰であり、これにより過学習に陥り精度の低下を招くことに着目して、量子化を行っている点が賢く、従来手法とは異なる点である。MICCAI Gland datasetで両方の量子化手法が性能向上を示すことを確認し、提案手法がsotaの性能を1%超えているうえ、メモリ使用量を6.4倍削減している。
Adversary perturbationsは機械学習で脅威となりうる.最近の研究では,画像にとらわれずほとんどの自然画像で分類を騙すことができる.本研究では,Adversary perturbationsの分布をモデル化する生成的アプローチを提案.アーキテクチャはGANと類似.我々の訓練されたジェネレータネットワークは、与えられた分類に対するAdversary perturbationsの分布を捉えようと試み、そのようなAdversary perturbationsの幅広い多様性を容易に生成する.
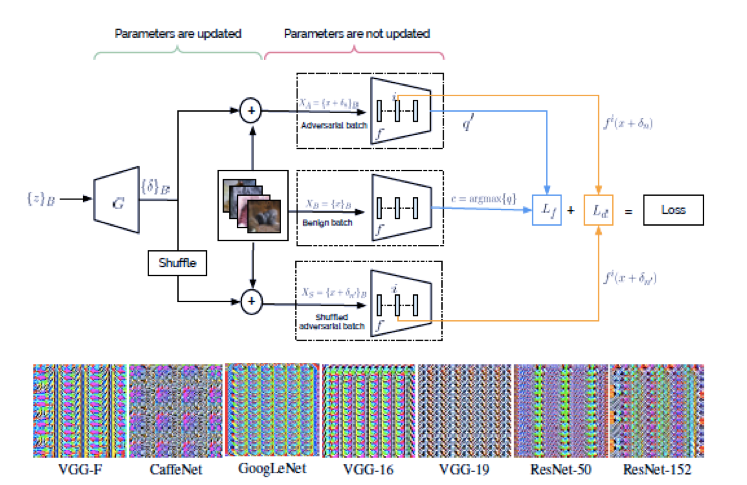
人物再同定のタスクは人物画像間の類似性を測定する.画像中の人物の姿勢や視野角の違いによってこのタスクはチャレンジングになる.本手法ではend-to-endで学習可能なDNNを用いた異なる人物の特徴マップを一致させるKronecker Product Matching(KPM)モジュールを提案する.データセットとしてMarket-1501, CUHK03, DukeMTMCを用いて実験したところSoTAを示し,本手法の有効性と一般性を示すことができた.
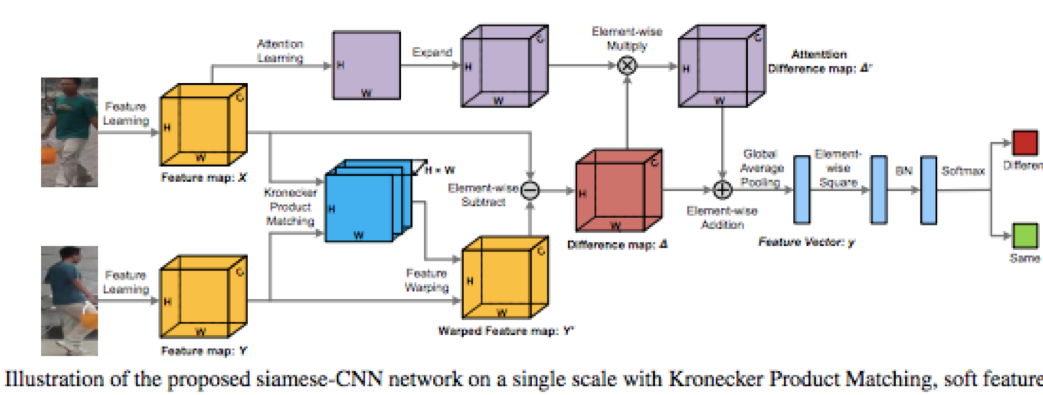
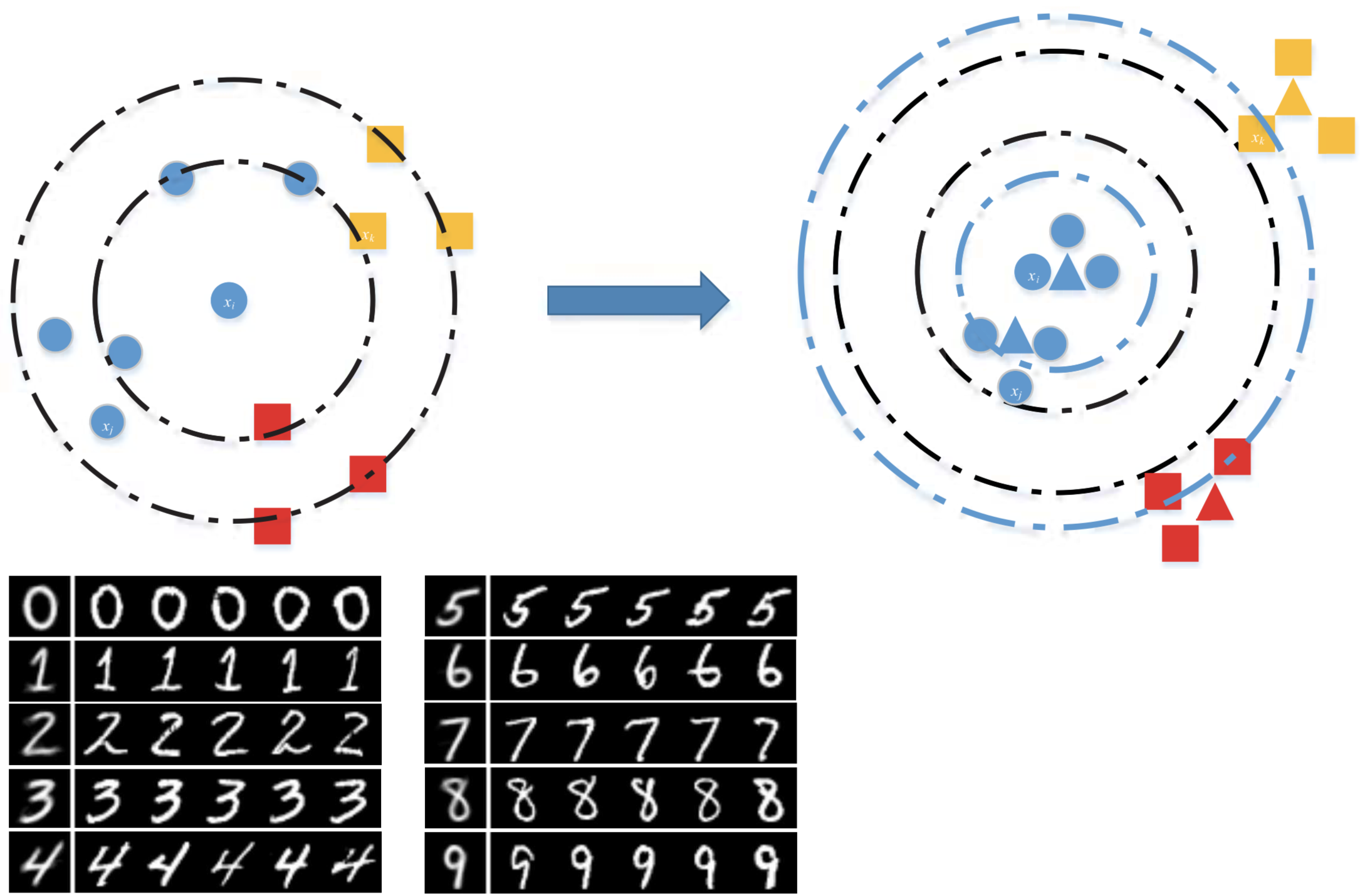
・人物再同定のためのネットワークBraidNetの提案・BraidNetはカメラ間の不整合や色の違いに頑健なWconvをカスケード構造に設計 ・学習画像の不均衡問題や勾配消失問題に対応した新しい学習方法Sample Rate Learning (SRL)とChannel Scaling (CS) layerの提案
・人物再同定の多くのデータセット(CUHK03-Detected, CUHK03-Labeled, CUHK01, Market-1501 and DukeMTMC-reID datasets)でstate-of-the-art
細かな動作や境界でも高精度に検出できるvideo prediction手法の提案.このアルゴリズムは,高頻度なビデオコンテンツ(細かい物体や関節運動など)と低頻度なビデオコンテンツ(位置や移動方向など)を別々のストリームで扱う2ストリーム生成アーキテクチャ(図中左側)に加えて,時間で変化する動作パターンやシーン内の小さい物体を取得するtemporal-adaptive畳み込みカーネルを用いたRNN(LSTM)構造(図中右側)を持つ.2ストリームアーキテクチャでは,1段階目ではベースのEncoder-decoderモデルのみ学習し,2段階目および推論時はLSTMブロック部分も学習および推論に用いる.
既存のアルゴリズムでは満足な結果を得られなかった,物体境界のような構造情報を持つ場合や,関節運動のような細かな動作でのvideo predictionの精度を向上した.データセットにはUCF-101(のうち,Clean-Jerkと呼ばれるデータ),Human3.6M(人間の細かい動きのデータ),CityScape(市街地動画のセマンティックセグメンテーションのデータ)を用いて評価し,他の手法よりも良い性能を得た.特に,物体境界や細かい動作に頑健な検出が可能である.
固定サイズのグリッドでは扱えない3次元の情報(ここではメッシュデータ)において本論文では新規のGraph Convolutionを含むFeaStNetを提案。3次元情報同士の繋がりを動的かつネットワークにて内的に計算する部分に新規性がある。FAUST 3D Shape Correspondence Benchmarkにて他手法の精度を超える性能を実現した。
固定のフィルタを準備する2D画像の畳み込みに対して、3D空間の畳み込みはコネクションが曖昧であり畳み込みが困難だが、本論文では近傍との繋がり自体を動的に計算できるGraph Convolution Networkを提案した。FAUST 3D Shape Correspondence BenchmarkでもSoTAを実現していることも採択された理由である。
任意の位置に配置されている3D点群を処理するためのParametric Continuous Convolutionを提案。近傍の点群をまとめて畳み込むためにNon-Gridなカーネル関数を定義して連続的な空間からでも処理できるように改良した。屋内外の3D点群セグメンテーションにおいて高精度な処理を実現した。右図はセマンティックラベリングのためのアーキテクチャである。KD-Treeにより点群の探索と対応付けを計算して、各近傍の畳み込み処理の際に参照。全結合層や畳み込み層の特徴を統合、Softmaxを通り抜けてCross-Entropy誤差を計算。
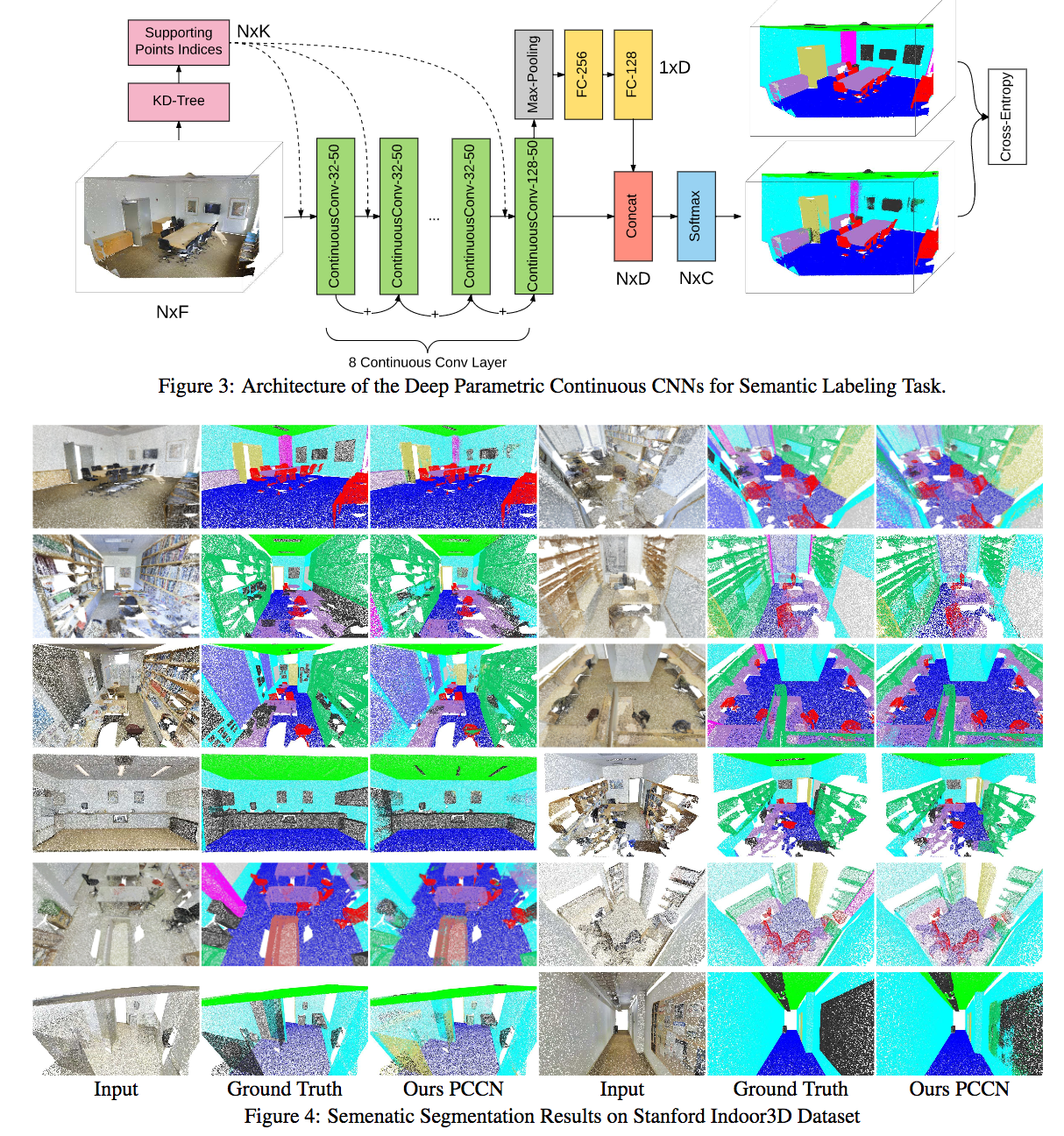
3D点群のような連続的な空間内での畳み込みを実施するアーキテクチャを考案し、屋内外環境におけるセグメンテーションタスクにてState-of-the-artを達成した。
変形をできる限り小さくなるように画像圧縮を行う手法を提案する。予め形状変換(Deform)を施してから圧縮(Compress)することで画像容量を抑えつつも形状変化が少なく済む。右図は元画像をそのままJPEG2000形式で圧縮した方式と、形状変換してから圧縮した方式を比較した図である。本論文中では、JPEG、WebP、BPGやDeepNetによる方式において圧縮を行い評価した。

そのまま画像圧縮するのではなく、人間の見た目にできる限り自然になるよう形状変化させておいてから画像圧縮する。画像圧縮した後も変形が少なくなるようになっていると主張。
活性化関数であるxUnitを提案し、画像復元タスクを行う論文であり、実際にReLUを置き換えて実験したところPSNRが向上した。提案のxUnitは学習可能であり、より複雑な特徴量を獲得できることで畳み込み層の数を比較的少なくしても同じような精度に到達することが可能である。画像復元タスクでは、ノイズ除去、雨除去、超解像を含んでいる。右図ではReLUとxUnitの構造の比較である。xUnitではReLUを含み、その他BN層Conv層など含まれていて学習可能な非線形活性化関数となっている。
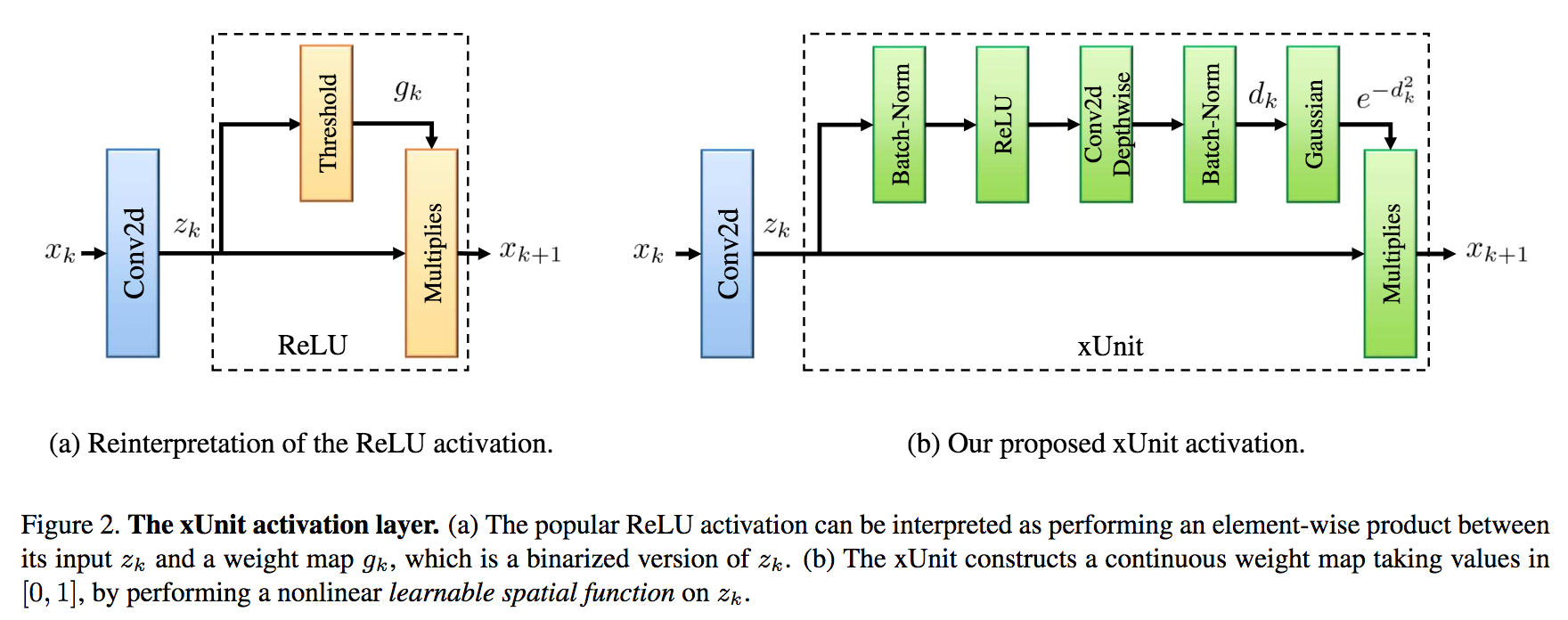
学習可能な非線形活性化関数であるxUnitを提案して画像復元問題(ノイズ除去、雨除去、超解像)に取り組み、より少ない層で比較的高い精度の画像復元に成功した。ベースラインと比較して、3分の1程度のレイヤ数で同程度の精度を実現している。
複数階層の構造で類似度を計算するEnd-to-EndのFully-Convolutional Siamese Networkを提案して人物再同定(Person Re-identification; ReID)。Siamese Networkは複数画像を入力として、出力を行うネットワークである。また、空間的なアテンションを計算するためにSpatial Transformer Netoworks (STNs)を使用し、Ranking Lossによりネットワークを最適化する。State-of-the-artとは言わないが、コンパクトなネットワークで良好な精度を実現した。右図は2枚の画像入力から類似度計算や複数誤差(ranking-loss/classification-loss)を計算するための構造である。
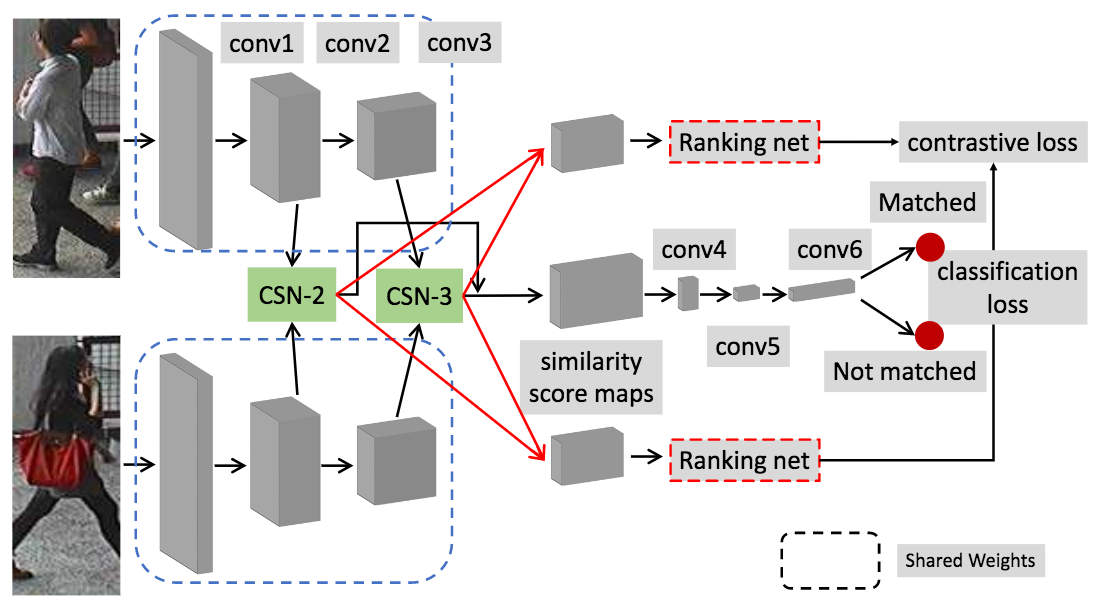
ReIDを効果的に行うためのFully Convolutional Siamese Networkを提案した。特徴量を階層的に抽出し、最適化するためにRankingLossやClassificationLossを計算した。CMCによる評価において、CUHK03では86.45@TOP1, 97.50@TOP5, 99.10@TOP10という数値を出した。
動画から顔認証のための教師なし学習を提案する。メモリベースの学習を顔特徴抽出と同時に行い、時系列の相関性を計算して行く方法で個人認証に関する強力なモデルを構築。手法としてはReverse Nearest Neighbour(サンプルからクラスタを求める逆を行う; 具体的にはせんとロイドからの距離の比が小さくなるようなカテゴリに割り当てる)や冗長な特徴表現に関しては忘却する構造を用いた。
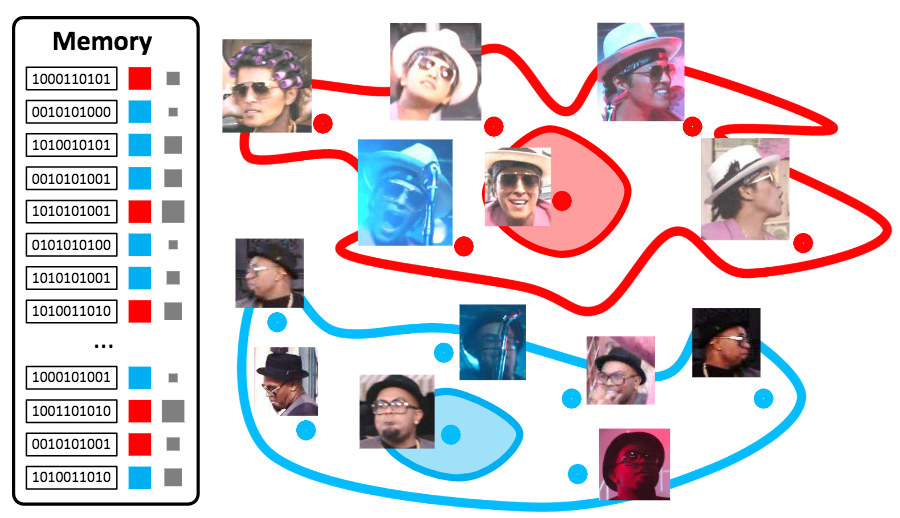
オンラインかつ教師なしの動画に対する顔認証を行なった。Reverse Nearest Neighbour(ReNN)や冗長特徴の忘却を実装して高精度な顔認証に寄与した。
本論文ではSemi-supervised CNNを提案し、Action Unit(AU; 顔表情の基礎単位をモデル化したもの)推定とその度合いを推定する。ここでは少量のアノテーションを元手に、多量の弱教師を用いて学習することでAU推定+尤度推定を成功させる。弱教師としては、自然に存在するAUに関する拘束条件(相対的なアピアランスの類似性、時間的な尤度の滑らかさ、顔類似度、連続的なアピアランスの相違度)を用いる。FERA2015は2%、DISFAは1%のアノテーションのみを用いた学習でより良い推論に成功した。
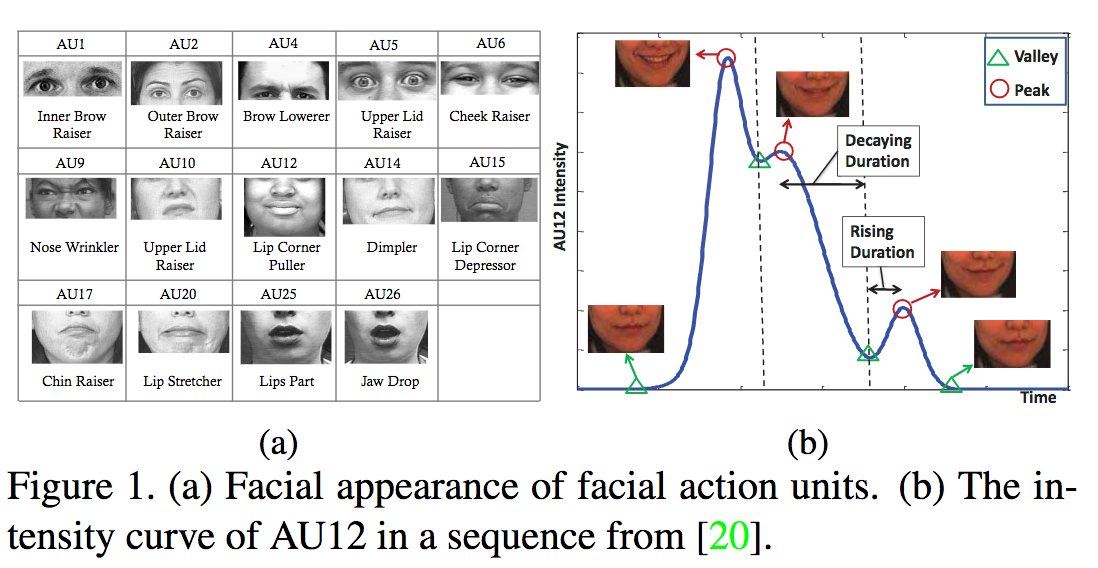
少量教師学習{Semi-,Weak-} Supervisionにより顔表情の基礎単位であるAUを学習し、その尤度の推定も同時に実行した。AUに関する弱教師としてアピアランス類似度、時間的滑らかさなどを実装して、その有効性が認められCVPR採択に至った。
顔からの年齢推定は非線形回帰問題であり、この問題をDeep Regression Forests(DRFs)を提案することで解決する。また、DRFsとCNNを中間層で結合して特徴生成や識別を同時学習することで非整備の(inhomogeneous)データにも対応する。同時学習について、まずはDRFsの葉ノードを(CNNの誤差逆伝播法と合わせて)最適化、次にVariational Bounding(参考文献33, 57)によりリーフノードを最適化。複数のスタンダードなデータセットにて良好な精度を実現した。(豆知識:顔年齢の変化について、少年時代は顔の形状、大人になると肌の見えが変化する)
深層回帰木(DRFs)とCNNを組み合わせ、さらに同時学習による最適化手法を考案した。MORPH, FGNET, Cross-Age Celebrity Dataset (CACD)にてState-of-the-art。
本論文では人物再同定(Person Re-identification; ReID)においてアテンション機能を用いてbbox中からより良く人物特徴を評価できるような構造とした。従来のReIDはよくも悪くもbbox中から特徴量を抽出しているため、余分な領域が発生して背景特徴が混在したり、人物検出に失敗すると必要な情報が欠落する欠点があった。提案ではHarmonious Attention CNN(HA-CNN)を提案してゆるくピクセルごとに評価(soft pixel attention)と強めに領域を評価(hard regional attention)
ReIDのためのアテンション機能を実装したネットワークHA-CNNを提案。CUHK03, Market-1501, DukeMTMC-ReID datasetにてState-of-the-art。
従来の人物再同定(Person Re-identification; ReID)においてはProbe画像を入力として、Gallery画像内を探索してランクづけを行うことで探索を行う(P2G)。本論文では、Gallery同士の関連性(G2G)も含めて評価することでよりProbe自体の探索を強化させるためのGroup-Shuffling Random Walk Networkを提案。提案のネットワークはEnd-to-Endかつ単純な行列演算でG2Gの関連性からP2Gをより正確に推定するためのリファインメントを行う。特徴のグルーピングとグループのシャッフルを行うことでより良い人物特徴を学習可能とした。
入力と検索画像群を比較するのみならず、検索画像群同士の関連性も記述しておくことで、ReIDのためのよりよい画像検索を実施することに成功した。特徴のグルーピング/ランダムシャッフルにより、より良い特徴評価を行えるように学習した。Market-1501,CUHK03,DukeMTMCデータセットにおいてState-of-the-art。
SenseTimeが誇る44の研究のうちの一つ。CUHK-SenseTimeは(ひとつ前の会議の)自らの精度を打ち破ればState-of-the-artと言える。世界一である強みを活かしてこれからもどんどんReIDの論文を書いて欲しいと思う。
入力された短期(数秒レベル)の動画像から、グループ行動・インタラクションとして未来の姿勢の状態を推定する枠組みを提案する。モデルとしてはBi-directional LSTMを適用し、グローバル/ローカルな行動を評価できるようにする。ここでは、Bi-directional LSTMに与える情報として関節点と姿勢全体を入力として、内的に動線と行動(action)を予測するように学習される。誤差は行動推定や動線予測との推定の差分により計算する。
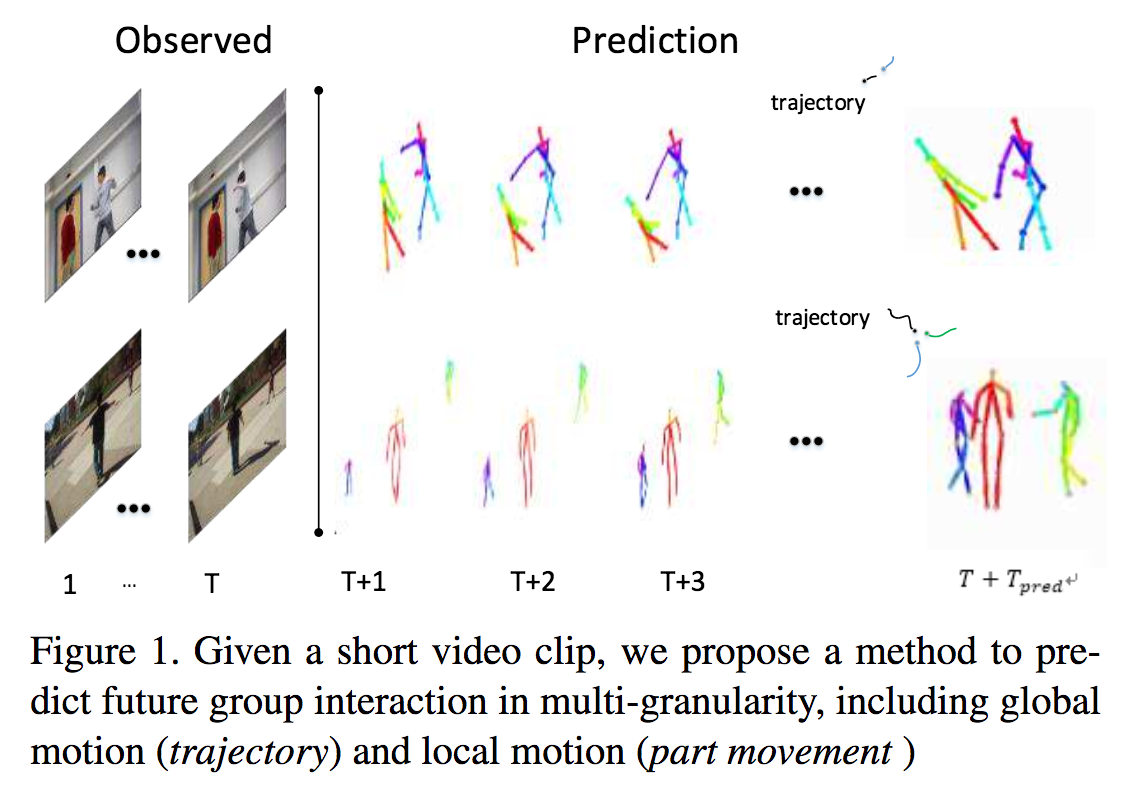
従来の行動予測は単一人物に着目されがちであったが、本論文では姿勢としてグループ行動を予測するところに新規性がある。平均誤差(displacement)ではSocial-LSTM、単純なBidirectional-LSTMなどと比較しても提案手法(マルチタスクにより学習するBi-directional LSTM)が総合的にもっとも小さい値となっている(行動ごとにおいても大体において誤差が小さい)。
顔に関するランドマーク検出を効果的に行うための誤差(に対する重み付け)関数WingLossを提案。L2,L1とSmoothL1と比較して、より小領域や中領域に対してアテンションをつけるべきというところから発想されており、(-w,w)。の区間でL1誤差からLog関数に切り替えるべきと主張。もうひとつの主張はData Imbalance(顔中心を境に左右どちらかが欠ける問題?)に対して、データ拡張(bboxを並進させるといった解決策)を用意。さらに確実性を高めるため、two-stepによるランドマーク検出を行った。データとしてはAFLWや300Wデータセットを適用した。
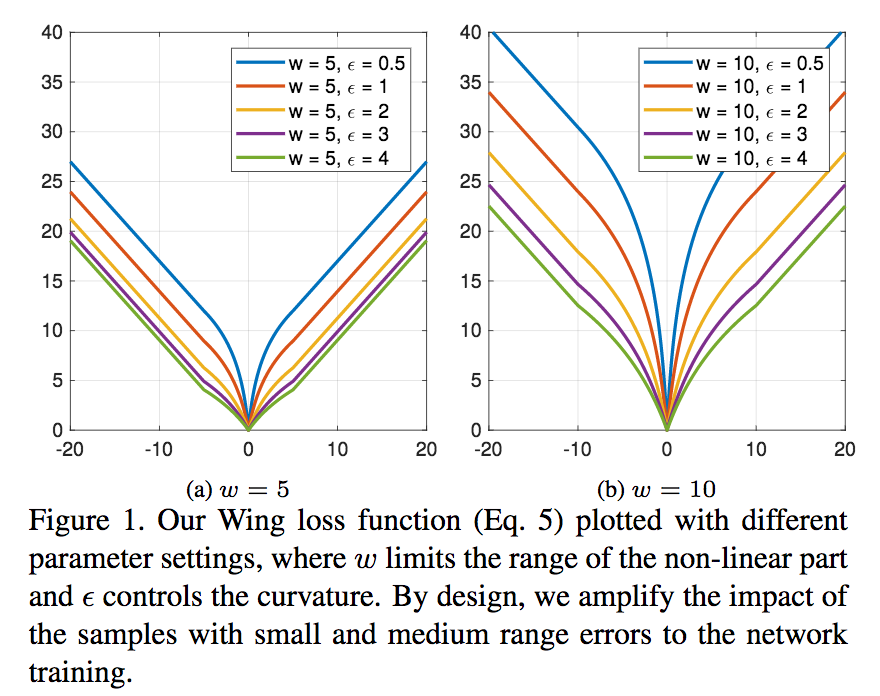
誤差関数が重要と言われる深層学習の中で、顔ランドマーク検出の問題についてはあまり効果的な策がなかったが、本論文で提案するWingLossは打開策になると主張(従来のL2誤差ではアウトライアに対して弱い)。
人物自体(e.g. 個人同定、頭部推定)の推定のみでなく、人物に関連するコンテキスト(e.g. イベントと人物、人物間)についても学習できるようなモデルを提案する。本論文ではRegion Attention Networkを提案し、インスタンスごとに関連する視覚特徴を対応づける学習を行う個人の認識だけでなく、個人間やイベントとの関連付けを行う。右図は本論文で行おうとしていることが書かれており、従来型の顔認識(Face)のみでは個人認証に失敗する可能性が高いが、提案のVisualContext/SocialContextを用いることにより、個人認証を成功させる確率が高くなると主張。データセットとしてはPIPA(参考文献27)、本論文にて提案のCast In Movies(CIM)を用いた。
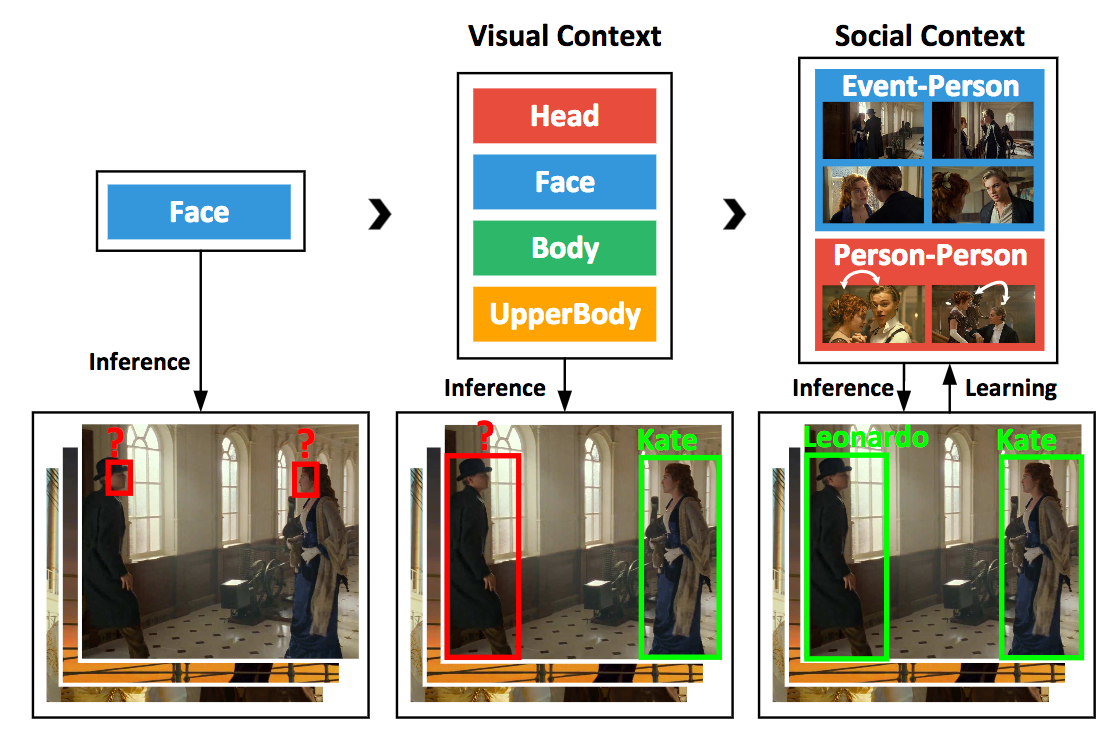
データセットとしてはPIPA(参考文献27)、本論文にて提案のCast In Movies(CIM)に対して処理を実行し、いずれのデータセットについてもState-of-the-artな精度を達成した。
・GAN-CNNベースのノイズ除去手法のGAN-CNN Based Blind Denoiser (GCBD)を提案・GANを用いてノイズ画像生成し,ノイズが無い画像とセットでCNNでノイズ除去

・未知ノイズの除去に対して初めてGANというアプローチを用いた.・ノイズ除去のGANのアプローチではノイズ無し画像とノイズ有りのペアが必要だが本手法ではノイズ有りの画像を生成するので,ペア画像を準備する必要ない
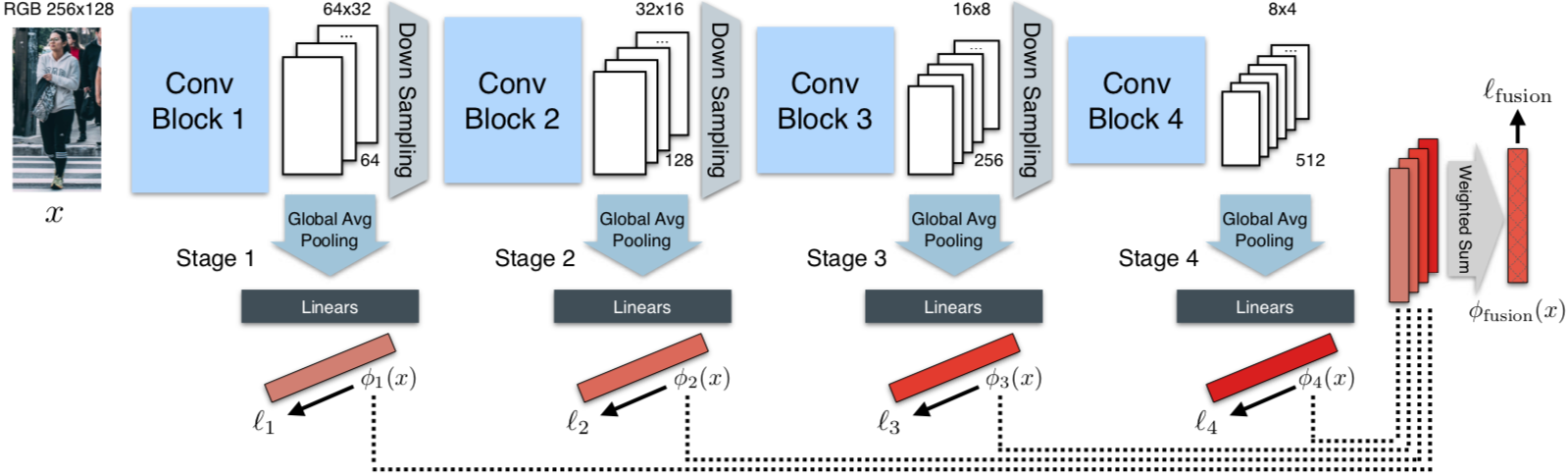
Salient object detection(SOD)のために,マルチレベルの特徴を統合するbi-directional message passing modelを提案.Multi-scale Context-aware Feature Extraction Module (MCFEM)を用いて豊富なコンテキストの情報を得て,双方向構造によりマルチレベル特徴の間でメッセージをやり取りするように設計される.その間にはゲート機能があり,メッセージの通過率を制御する.最終的にマルチレベル特徴を統合してsaliencyを予測し,それらを融合して出力を得る.
SODの研究で未解決課題だったマルチレベルの特徴を統合する手法を提案した.ECSSDやPASCAL-Sなどの5つのデータセットを用いてF値とMAEを比較した結果,全てのデータセットにおいて提案手法が最も良い性能となった.
Defocus blur detection (DBD)をEnd-to-endで行うBTBNetを提案.FCNを用いて,入力画像からピクセル単位のDBDマップを直接推論する.Defocusやblurの程度がスケールに影響されやすいことから,異なるスケールの入力画像に対応したマルチストリームBTBNetを用いることで性能を向上させた.また,ボトム・トップにエンコードされたマップをトップ・ボトムにエンコードされたローレベル特徴をマージする.評価用のデータセットの作成も行い,既存のデータセットとあわせて性能評価を行った.
DBD:画像内の焦点が合った領域と焦点が合っていない領域の分割.
DBDをEnd-to-endで行う最初の試みである.データセットはShiによるデータセットのみであるため,自らでデータセットの収集を行った.提案データセットは低コントラストの焦点ボケや複雑背景を含むので,非常に挑戦的である.他の手法とF値とMAEを比較して性能が良いことを示した.
Fixation prediction(FP)を用いてSalient object detection(SOD)を行い,画像内の顕著な物体を識別しセグメンテーションするAttentive Saliency Network (ASNet)を提案.FPによって得られるFixation mapは,画像シーンの高レベルでの理解を行い,SODで細かい物体レベルでのセグメンテーションを行う.ASNetはconvLSTMを階層構造にしたもので,トップダウンに最適化される.
※FP:人間がひと目見て焦点を当てる場所を予測する.SOD:画像内の顕著な物体領域を強調(検出)する.
Visual saliencyの主要なタスクのFPとSODについて,あまり探求されていない両者の関係について焦点をおいて新しいネットワークを開発した.学習用と評価用で別のデータセットを複数用いている.SOTAを含む他の手法と比較して同等またはそれ以上の性能(F値,MAE)を示した.正確なSODのために,Fixation mapが補助になっていることも示した.
動画のsalient object detection(SOD)をend-to-endで学習するflow guided recurrent neural encoder(FGRNE)を提案.Optical flowとsequential feature evolution encodingの情報をLSTMで用いることで,フレームごとの特徴量の時間的コヒーレンスを強化する.これは,FCNベースのstatic saliency detectorを動画のSODに拡張する普遍的なフレームワークであると言える.
SOTAのsaliency detectorを画像から動画に拡張した.DAVISとFBMSデータセットを用いて比較した結果,様々な手法と比較して最も良い性能を達成した.
半教師ありの高速なVideo object segmentation(VOS)手法の提案.VOSでよく使われる物体マスクの伝搬と物体検出の2つを用いたdeep siamese encoder-decoder networkを設計した.少ないデータでも良い精度が出るように,学習時は合成データで事前学習を行い実データで微調整する2段階学習を行い,オンライン学習や後処理は不要である.合成データは,1枚の画像内で物体マスクを用いて物体位置を変更した画像の生成と,背景と物体マスクのペアを用いて背景に物体を合成した画像の2種類を用いている.
速度を上げながらもSOTAと同等の性能を達成した.DAVIS-2016/2017,SegTrack v2を用いて評価し,性能はSOTA同等だが速度はSOTAが0.3~13secに対して,本手法は0.13secで処理可能である.
パラメトリックな身体形状表現とノードグラフによって表された外側のレイヤーを用いることで、単眼のデプスカメラのみから詳細なジオメトリの復元、非剛体のモーション、人間の内部のshapeの復元をリアルタイムで行う手法を提案。外側のレイヤーで使用されるノードグラフは、体付近の変形を表現するための事前に定義されたものと、体から離れたスカートなどを表すfree-form dynamically changing graphからなる。身体形状表現にはSMPLを使用する。身体形状と、外部のノードグラフの最適化を同時に行うことで、身体形状と外側のジオメトリの2つのトラッキングを可能にした。
ターゲットオブジェクトの初期フレームのマスクが与えられた状態で、動画内のターゲットオブジェクトに対するセグメンテーションをMarkov Random Field (MRF)とCNNを組み合わせて行う手法を提案。CNNを用いた従来の手法では各フレームごとに対してのみしか処理できなかったことに対し、提案手法ではCNNによってエンコードされる空間特徴量をMRFに利用する。また、時間的な情報をもつオプティカルフローを用いることでさらなる精度を向上を達成。

実画像のshape-from-shadingをDNNに学習させる際のデータとして、CGのシンプルなプリミティブを用いて作成されたshapeデータを用いる手法を提案。既存手法では全て人手で作成されたデータを用いていた。提案手法ではシンプルなプリミティブを組み合わせて複雑な形状データセットを適宜作成して、DNNの学習を行うことでデータ不足を解決。またバリデーションは実画像で行うため、実画像がもつ形状とかけ離れた形状を持つトレーニングデータは捨てられて行くため、合成画像に対する過学習を防ぐ。ネットワークはstacked hourglass networkを使用。
実画像に対するマルチクラスアノテーションをクラウドソーシングで行う際に有効な方法を提案。1枚の画像に対して複数のワーカーがアノテーションを行うが、既存手法ではアノテーションに対する各ワーカーの重みは均等に決められていた。これに対し、提案手法ではユーザのスキルやそれまでのアノテーションの実績を考慮して重みを決定する。ワーカーのスキルによるアノテーションのラベルを条件付き分布として扱う。スキルとアノテーションラベルが独立なモデルに加えて、スキルとラベルが独立でないモデルを構築することで、よりワーカーのスキルを反映したクラウドソーシングを行うことが可能。また、スキルとラベルを線形SVMで学習することで、より効率的にデータセットの構築を可能にした。
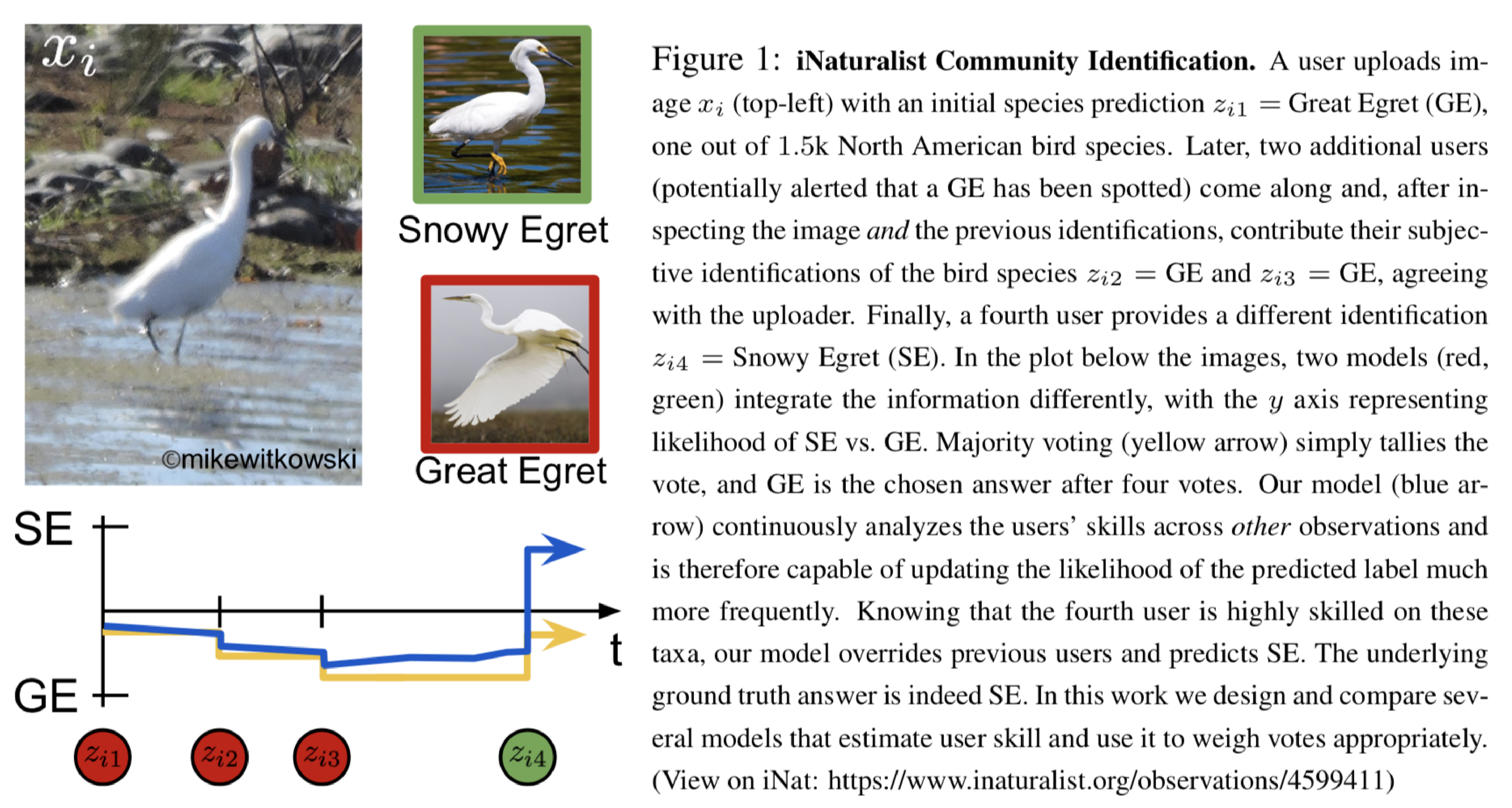
(Affine, ReLU, Affine)から構成されるpiecewise linear (PL) network(e.g. LeNet)のガウシアンノイズに対する平均値と分散を解析することで、DNNの性質を調査した論文。理想的には出力される値の確率分布を観測したいがそれは難しいため、平均値と分散に対する解析をおこなう。実験の内容は以下の通り。また以下の実験を通してadversarial attackの生成法についても提案している。
動画内のターゲットオブジェクトに対するセグメンテーションをオンラインかつ正確に行うために、ターゲットの各パーツに対するトラッキングとセグメンテーションを行う手法を提案。既存手法ではターゲット全体に対するセグメンテーションを学習する必要があったため、動画ごとにネットワークのファインチューニングが必要など、オンラインでセグメンテーションを行うことができたなかった。提案手法は以下の3つの要素から成る。
![]()
デプスがアノテーションされた人間の手のポーズのデータオーギュメンテーションを行うために手の骨構造とCycle GANを用いた手法を提案。オーギュメンテーションを行う際に、デプスを変更してしまうと実際にはありえない手の形状になってしまう。そのため、提案手法では手の骨構造を変更することで、データオーギュメンテーションを行う。提案手法はデプスから骨構造を推定するhand pose estimator (HPE)、骨構造からデプスマップを生成するhand pose generator (HPG)、実画像と合成画像を識別するhand pose discriminator(HPD)からなる。まず既存のデータセットを用いてHPEを学習し、次にHPE、HPG、HPDでデプスマップ、骨構造に対してcycle consistencyが保たれるようにGANによる学習を行う。実験では骨構造の推定精度を既存研究と比較する。
Person Re-Identification (Re-ID)に対して有効なtriplet lossによってトレーニングしたCNNによってRe-IDとMulti-Target Multi-Camera Tracking (MTMCT)を行う手法を提案。Re-IDとはカメラに写っている人物をクエリの中にある人物と対応させること、MTMCTとは複数のカメラで撮影された映像を用いて同時刻の複数人の位置を把握することである。CNNをトレーニングする際のtripletの重みをアンカーとの類似度におけるsoftmax/minとする。各バッチにはアンカー画像と、アンカー画像にもっとも類似度が高いhard-negatives、ランダムにサンプルされた画像によって構築する。また、よいトラッキングとよいre-IDのスコアの相関関係を算出することで、両タスクの関係性を調査。
![]()
ターゲットとなるファクターを認識するmulti-task learningを行う上で、ターゲットとなるファクター(content)を識別可能かつ、それ以外のファクター(style)を識別不可能な特徴量を学習するmulti-task adversarial network (MTAN)を提案。従来のmulti-task learningではファクターごとに共通の特徴量表現を学習していた。提案手法ではencoderから得られた特徴量に対してターゲットとなるファクターの識別が可能なように識別器を学習させる一方で、それ以外のファクターについてはdiscriminatorとadversarial gameを行うことで、識別が不可能なように学習を行う。またターゲットとなるファクターをよく学習するように、ターゲット以外のファクターをアトリビュートとした画像生成を行っている。
person re-identification(RE-ID)を行うために、グラフモデルであるCRFによって構築されたデータセット内の画像全ての類似度を用いる提案。RE-IDとは異なる映像から同一人物を検出することである。既存手法では2組~4組の画像の類似度を学習する手法をとっていたが、データセット全ての関係性を学習する。DNNによって得られた画像特徴量を用いて画像ペア類似度を学習し、このペア類似度とCRFによってグループ類似度を計算する。
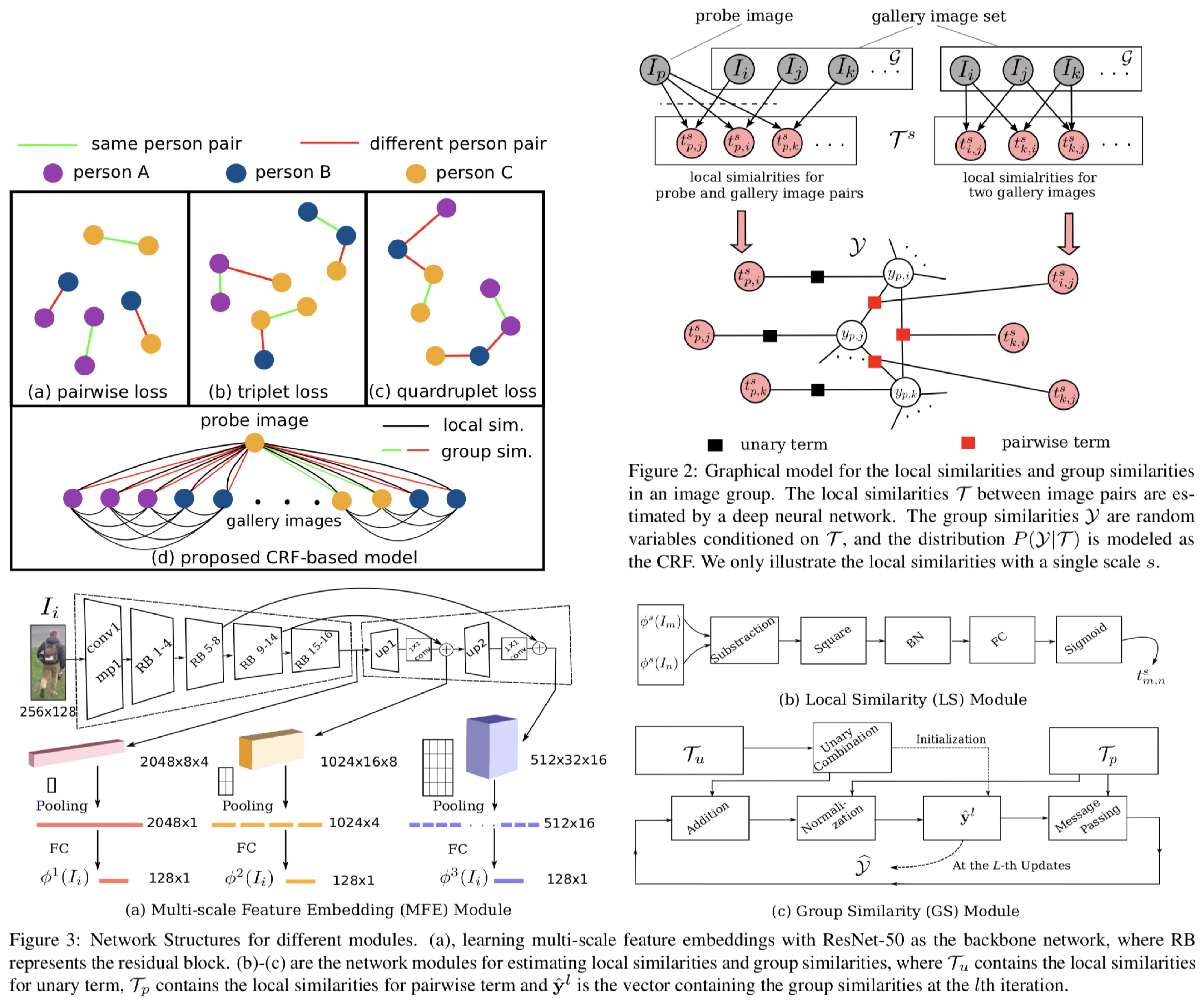
実画像と線画のオブジェクトに対するパーツ位置推定をCNNによるone-shot学習で行うStructured Set Matching Network (SSMN)を提案。ソース画像とターゲット画像はどちらもパーツのラベルとカテゴリクラスを持つが、ソース画像はラベルとともにパーツ名を持つが、ターゲット画像はパーツ名を持たない。またソース画像は各カテゴリに対して1枚のみ。SSMNではラベルのマッチングを画像の変形で行うことができると仮定し、ラベル位置の局所特徴量と、全ラベルの相対位置の一貫性を考慮することでパーツラベリングを行う。データセットの構築も行っている。また線画を入力とする際には、distance transformationが有効であったと主張。
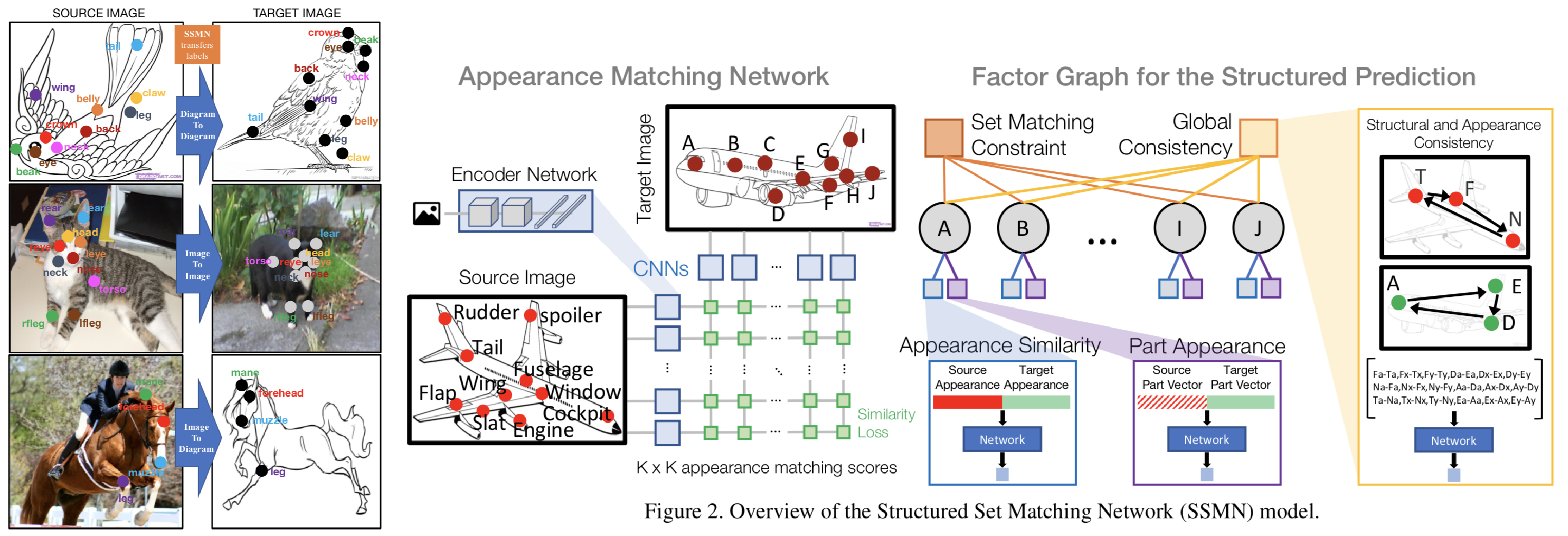
CNNのコンボリューションにおける内積計算について、より識別精度を高くするためのノルム関数、角度関数を提案。CNNは画像パッチとconvolutional layerとの内積を行い、右図のように、角度方向に異なるクラスを、動径方向に同一クラスを並べる。これに着想を得て、CNNの内積計算を行う際にL2ノルムやcosineの代わりとなるノルム関数、角度関数を提案。ノルムについては大きさが有界な3つの関数、非有界な3つの関数、角度関数については3つの関数を提案。ノルム関数が有界な場合にはadversarial attackに頑健になり、ノルム関数が非有界な場合には様々な種類のインスタンスに対応することが可能となる。モデルに不変であるため、様々なCNNに適用することが可能。
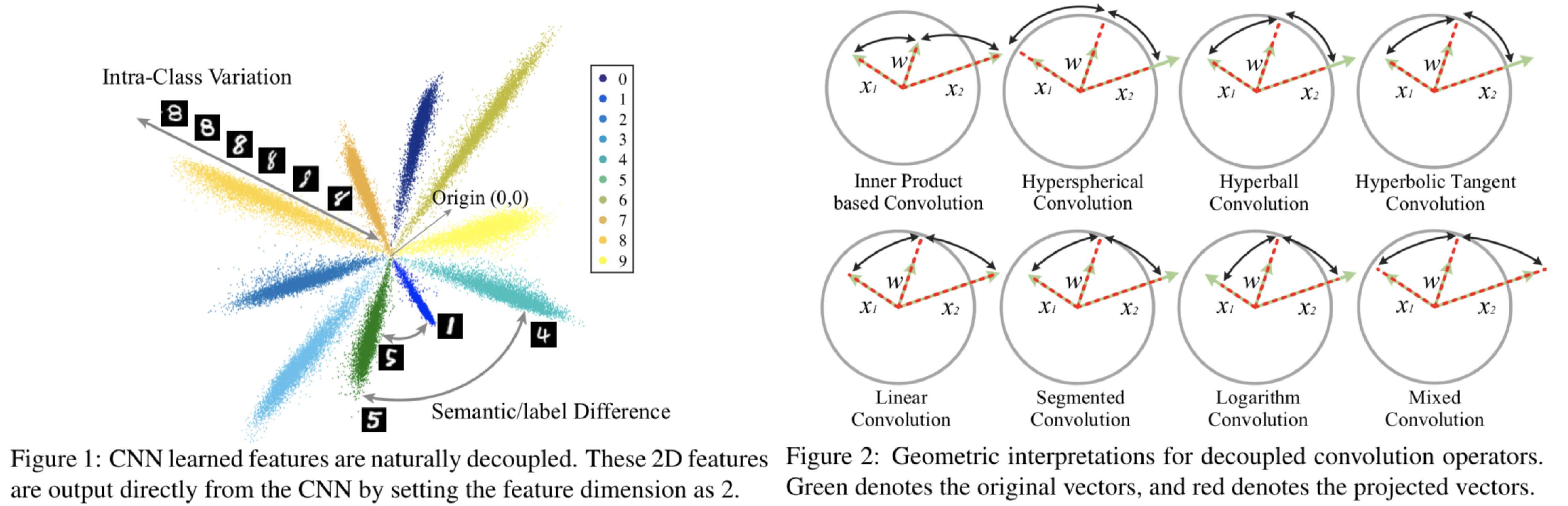
大規模なデータセット(ソースドメイン、SD)で学習したclassifierを、そのデータセットの一部のクラスをもつラベルなしデータセット(ターゲットドメイン、TD)へのdomain adaptationをGANで行うPartial Transfer Learningを提案。既存手法ではデータセットのもつラベル数に関わらずdomain adaptationをおこなっていたため、adaptation後のclassifierが前のclassifierよりも悪い精度をもつnegative transferが起きてしまっていた。提案手法では、右図のように、generatorから得られた特徴量をclassifierは学習するため、SDのインスタンスで識別率が悪いもののクラスはTDに所属していない可能性が高い。そのため、識別率を重みとすることでSDから学ぶべきインスタンスを学習することで、TDへのnegative transferを防ぐ。
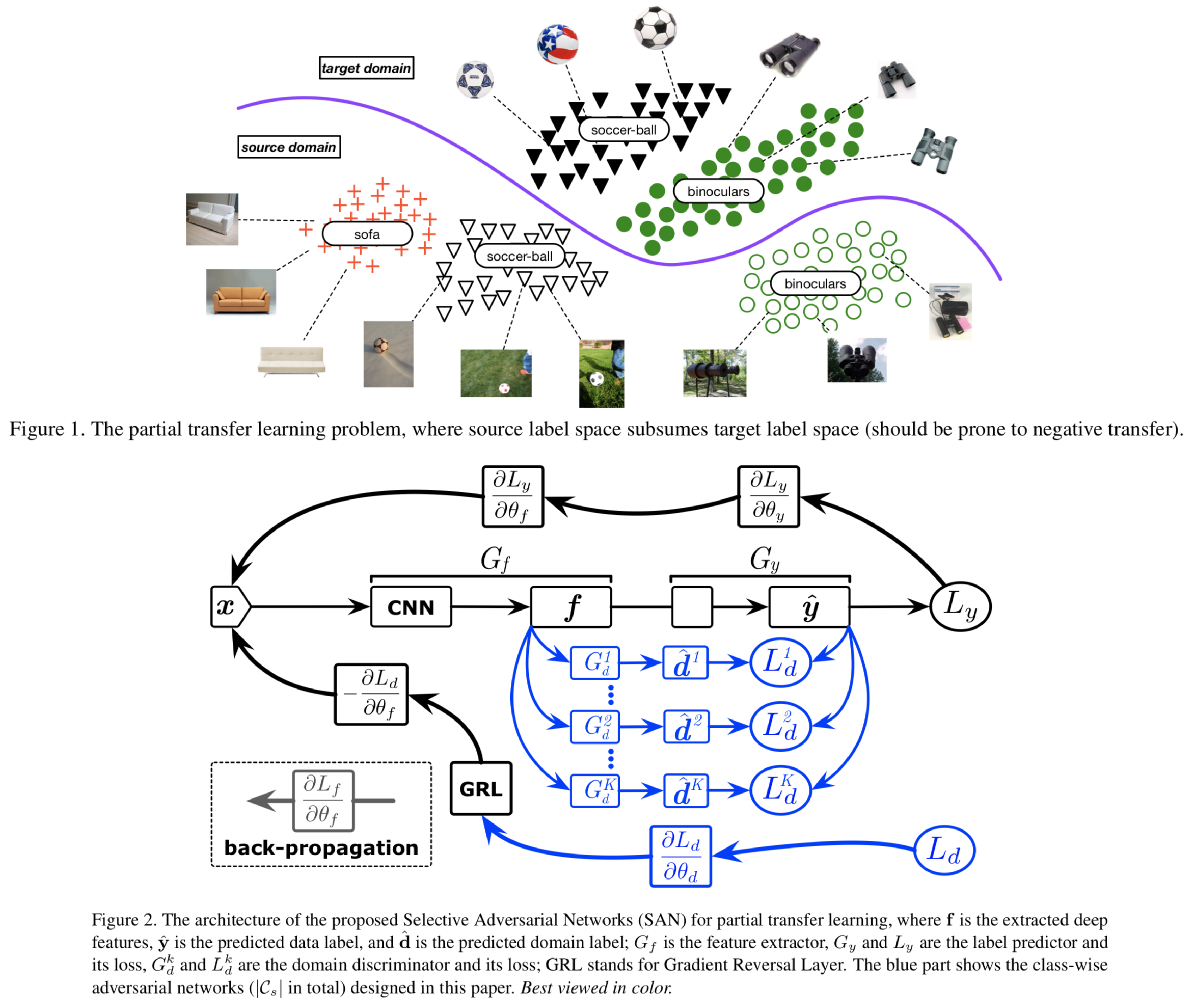
各データセットに対して最も有効なCNNを構築する手法NASNetを提案。大規模なデータセットを扱う際にはそのまま学習するのではなく、小規模なデータセットで学習したアーキテクチャを用いてスクラッチで学習する。論文では小規模なデータセットとしてCIFAR-10、大規模なデータセットとしてImageNetを使用している。NASと呼ばれるアーキテクチャ探索手法を用いてCNNの各ブロックを構築しており、CNN全体を構築するよりも7倍速く構築することができると主張。
ソース画像に不変なadversarial pertubationをCNNの特徴量マップを近似して得られる特異値によって生成する。adversarial petubationとはDNNが画像識別などにおいて誤認識を起こさせるように画像に加えられるパターンのこと。CNNから得られる特徴量マップはヤコビ行列によく近似できることが知られているため、特徴量マップをヤコビ行列に近似し、(p, q)特異値によってpetubationを生成する。行列Aの(p, q)特異値は以下の最適化問題を解くことで得られる。
||Av||q → max, ||v||p = 1
映像要約を行う際に、ショットセグメンテーションを映像に対して事前に行うHierarchical Structure-Adaptive RNN(HSA-RNN)を提案。既存手法では一定間隔で切り取られたフレーム群をショットとしていたが、提案手法ではショットセグメンテーションを行うことで要約の精度向上を主張。ショット検出はsliding bidirectional LSTMを、映像要約ではショット特徴量とBidirectional LSTMを用いる。映像要約だけでなくショットセグメンテーションでもSoTAを獲得。
各々のフィルタの活性化マップによりフィルタが学習できているセマンティックコンセプトに関する研究が多い.この文章で識別する際のcriticalルートからinterpretを行う視点が新しい.今後同じような視点でのinterpretに関する研究が多くなるように思う.
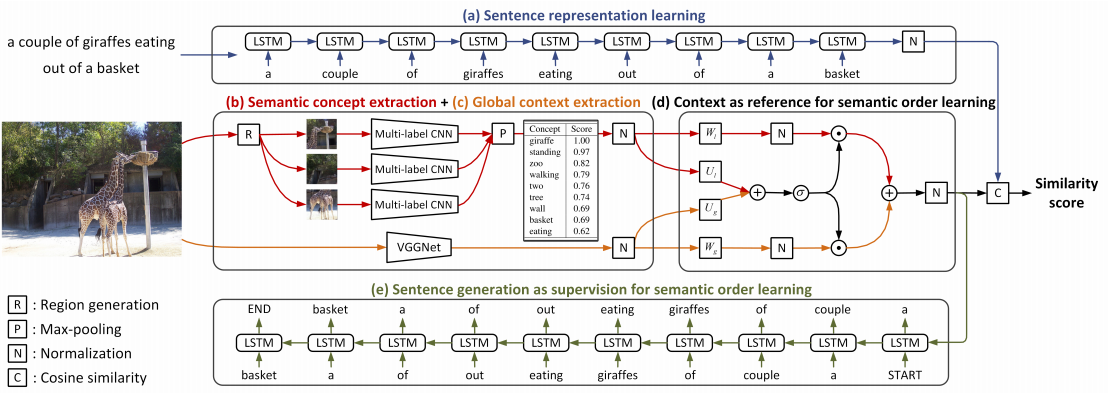
自然言語の面の理解が画像の理解より未だに深いような気がして,Language-and-visionの分解でいかに画像から有用な情報を抽出することが重要と感じている.セマンティックコンセプトだけだはなくて,画像側のもっと深い理解がこの分野に需要されているように思う.
行動をグラフ構造によりで更に細かく分解することによって,ほかのタスクに用いることがもっとflexibleになる.

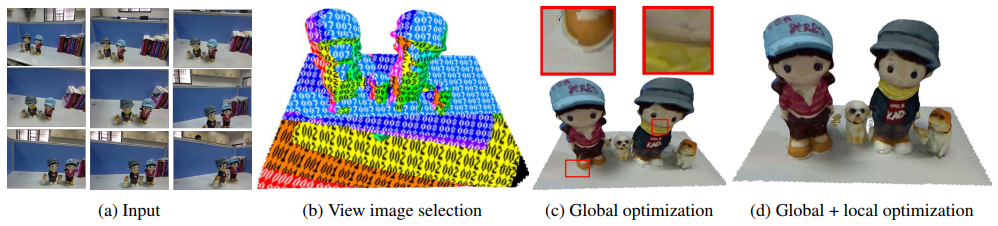
提案手法は複雑なPre-processingが必要で,ほかの分野の人が使いにくい気がする.
RGB-Dセンサーの3Dモデルのテクスチャーマッピングを高精度でできるEnd-to-Endな手法が期待している.
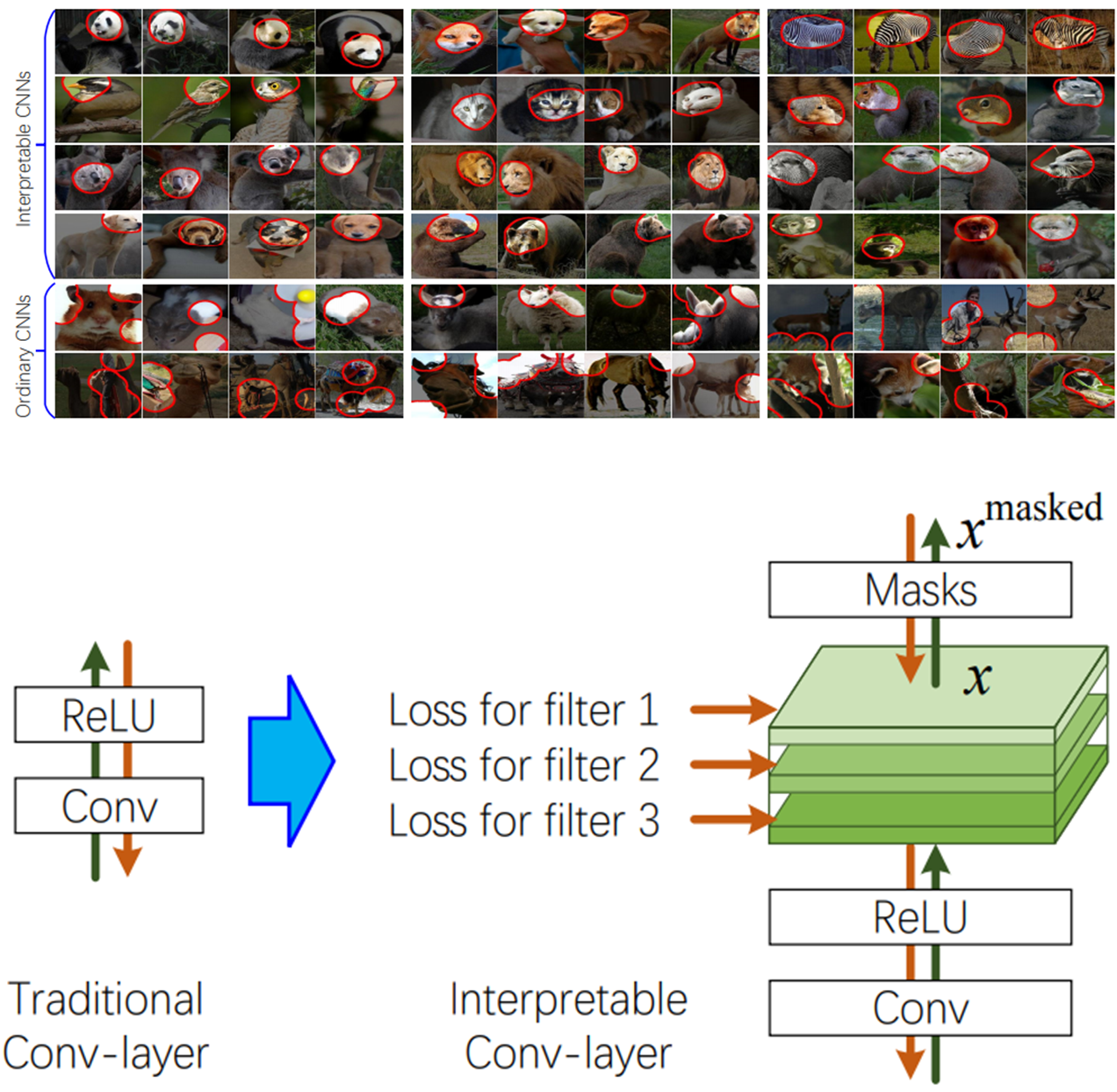
人物を含む画像から人物の3Dメッシュをend-to-endで推定するframeworkの提案.画像中の人物のキーポイントがアノテーションされたデータと,人物の3Dモデルのパラメータのデータを用い,推定した3Dモデルを画像に投影した際におけるキーポイントの誤差と,3Dモデルが画像から推定したものか,人物の3Dモデルのデータセットから持ってきたものかを識別するDiscriminatorのAdversarial lossの2つを損失関数として学習を行う.Adversaial Lossは,推定した3Dモデルが人物の3Dモデルと自然かどうかの弱教師として働く.
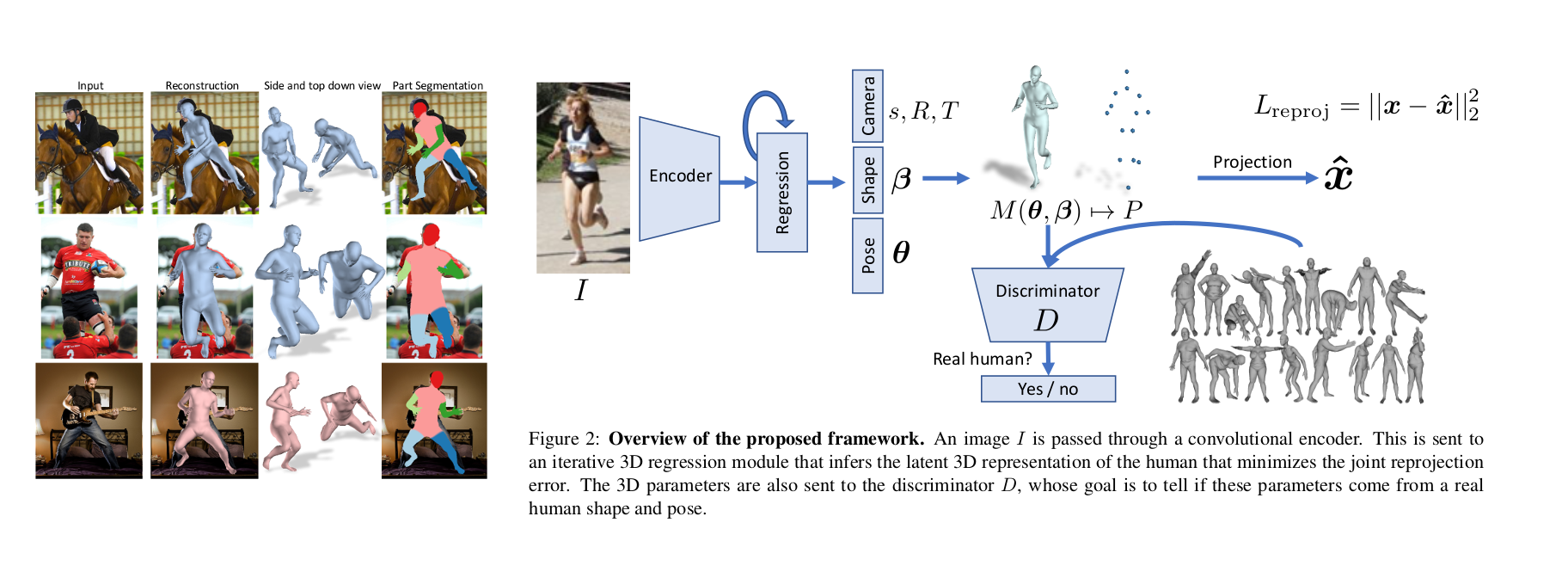
画像レベルのラベルから Semantic Segmentation の学習で使用する画素レベルのラベルを生成する研究. 隣接する領域の意味的な親和性を推定する, AffinityNet を提案. 入力画像の CAM のアクティベーションの情報を AffinityNet で推定された意味的親和性に基づいて伝搬することで, 完全なマスクを生成する. 提案手法によって作成されたラベルによって学習した Semantic Segmentation 手法は PASCAL VOC 2012 において弱教師の手法の中でSOTAを達成した.
![]()
既存手法のSparse Feature Propagation、 Dense Feature Aggregationをアップデートした動画に対する物体検出手法を提案。提案手法は以下の3つの要素からなる。1) recursively aggregate feature for key frames:隣合うキーフレームごとに特徴量を抽出する。隣合うキーフレームではフレーム内に大きな変化は少ないため効率的に特徴量を抽出することができる。2)partially update feature for non-key frames:キーフレーム出ないフレームに対して、キーフレームと異なる部分のみに対して特徴量を抽出する。3)temporally-adaptive key frame scheduling:ここまでの処理ではキーフレームに主に学習してしまっているため、過学習を防ぐためにトレーニング動画全体で特徴量抽出器を調整する。なおここでのキーフレームは10フレームごとのフレームを指す。
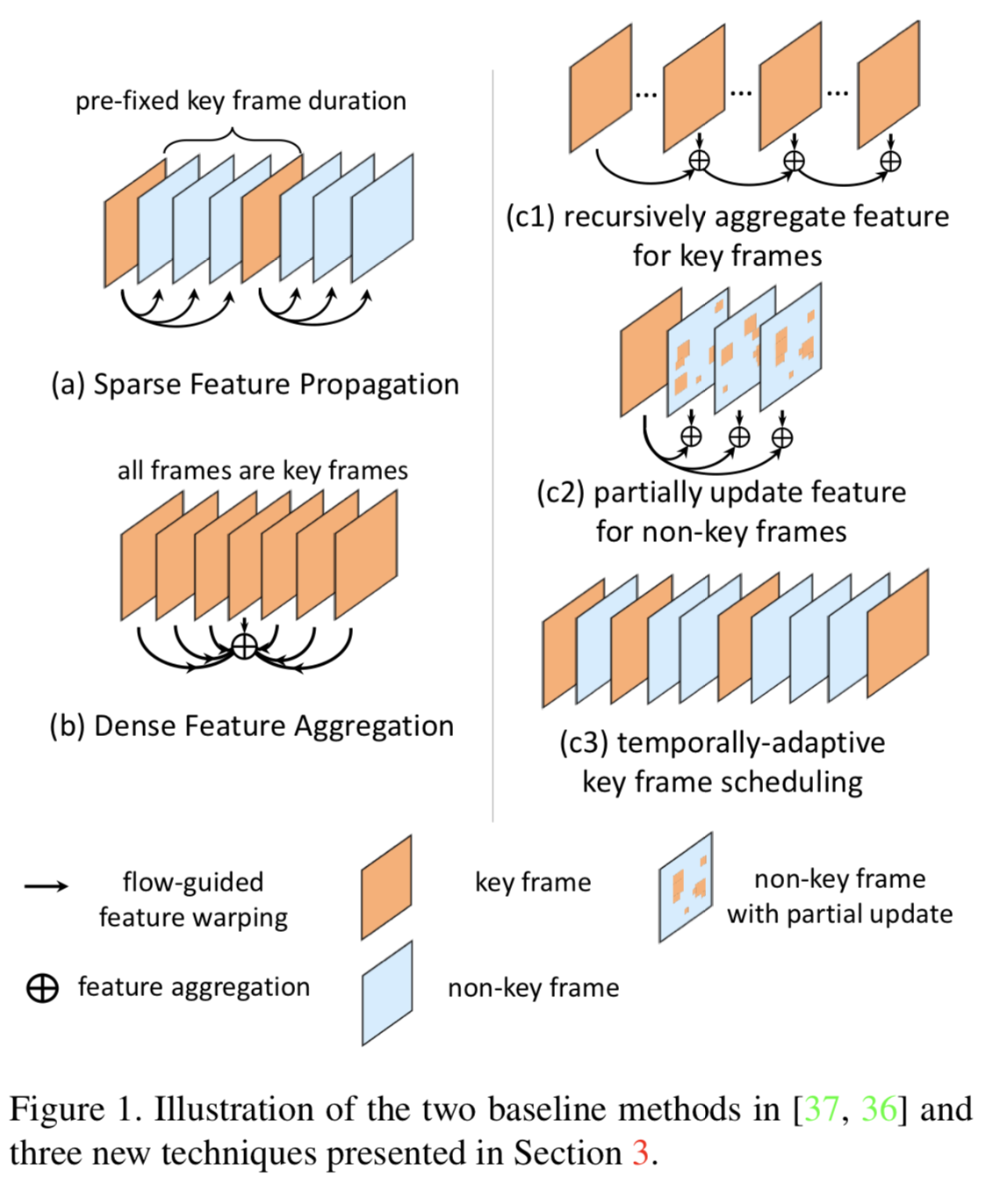
動画のaction labelingとactionごとのtemporal segmentationをactionラベルと確率モデルによる弱教師学習で行う手法を提案。既存研究では弱教師とはいえほとんどの手法ではactionの順序は与えられていたが、提案手法ではactionラベルのみを用いる。手法は大きく3つに分けられ、context modelによる起こりうるactionの順序の推定、length modelによるactionのtemporal segmentation、multi-task learningによる各actionラベルの推定からなる。context modelの構築方法として以下の3つを検証。1)Naive Grammer、2)Monte-Carlo Grammer:行動が様々な順番で並び替えられた動画を学習3):Text-Based Grammer:ネット上の本やレシピなどのテキストを利用して順番を学習する。length modelでは以下の2つを検証。1) Naive Approah:全ての行動クラスが一様に同じ時間的長さをもつ、2)Loss-based:行動クラスごとに時間的長さが異なるため、行動クラスごとの平均値を求める。
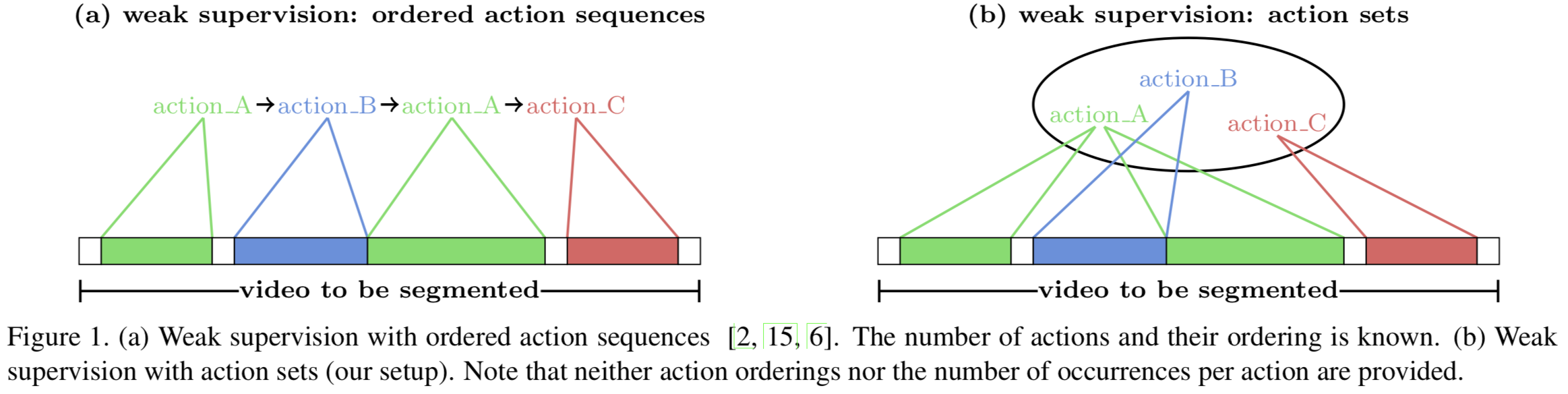
phrase groundingを弱教師学習で行う際に、検出された領域と入力された名詞句から推定されるオブジェクトとのvisual consistencyを使用するKnowledge Aided Consistency Network (KAC Net)を提案。phrase groundingとは入力名詞句に相当するオブジェクトを画像中から検出するタスクである。既存手法では検出されたオブジェクトから名詞を推定し直すlanguage consistencyを用いていたが、提案手法ではlanguage consistencyとvisual consistencyの両方を用いる。具体的には、いくつかのカテゴリにおける画像識別をプリトレインしておくことで、オブジェクトの検出精度を高めることができ、かつ言語と画像の対応精度も高くなる。
弱弱教師によるスペクトルクラスタリングによってembedding空間を再形成し、アノテーションを貼り直すことで顔のaction unitの手法を提案。提案手法ではネット上の画像とそのアノテーションを使用することで、画像の見た目とアノテーションのどちらも考慮した手法を提案。教師ありの手法ではどちらか一つの要素しか考慮できず、弱教師だとノイズや外れ値の影響を受けてしまうが、提案手法ではどちらも要素も考慮する。
深層学習によってLight Stageから得られる1Kの顔のUVテクスチャを入力として4Kのディスプレイスメントマップを推定する手法を提案。事前実験により、テクスチャから全てのディスプレイスメントを推定するのではなく、中周波数帯、高周波数帯のディスプレイスメントをそれぞれ推定した方が精度が高いことを確認しているため、周波数帯ごとに二つのブランチで推定を行う。提案手法ではimage-to-image networkによって1Kのテクスチャを1Kのディスプレイスメントに変換し、super-resolution networkによって高周波数帯のディスプレイスメントを高開画像度化し、中周波数帯に対してはバイキュービック方で高解像度する。最終的には顔の3D meshにディスプレイスメントマップを統合することでリアルな3Dジオメトリモデルを得る。
複数のカーネルサイズのdilation conv層をclassification networkに付け足すことで、image-levelのオブジェクトラベルから、オブジェクトごとの密なlocalization mapを生成し、これを元にセマンティックセグメンテーションを行う手法を提案。image-levelのラベルのみが与えられていても、複数サイズのdilated convolutionを組み合わせることで様々なスケールでオブジェクトを探索することが可能。最終的なlocalization mapはとdilated conv層の平均と通常のconv層の推定結果を足し合わせた物を使用する。このlocalization mapとonline mannerのそれぞれから得られたセグメンテーションとを教師とすることでセグメンテーションネットワークを訓練する。localization mapの汎用性を示すために、weakly/semi-supervisedの両方を行っている。
画像に対するimage-levelのラベルのみを用いてセマンティックセグメンテーションを行う際に、ラベルを貼る領域をイテレイティブに増やす手法を提案。既存手法ではシードの初期値から一気にラベルを貼っていくが、提案手法では自信が高い領域にのみラベルを貼り、これを繰り返すことでセマンティックセグメンテーションを行う。ラベル(背景含む)の初期値としてclassificationから得られるヒートマップを用いてconfidenceが高いピクセルを使用する。DNNを用いてラベルごとのヒートマップを作成し、一つ前のイテレーションで推定したラベル領域と照らし合わせることでラベルの更新を行う。ロス関数は各ピクセルが各クラスに所属する確率と、物体境界の推定誤差からなる。
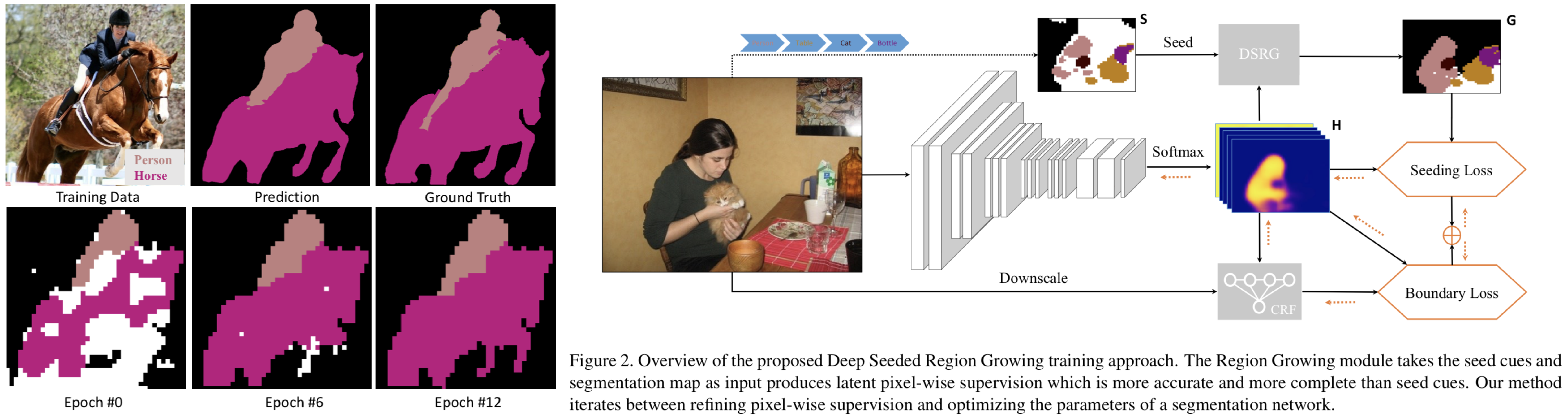
画像とテキストのそれぞれから得られるハッシュを用いたクロスモダリティな検索において、中間的な情報である画像のラベルを自己教師として噛ませる手法を提案。DNNによって画像、ラベル、テキストのそれぞれから得られる特徴量をV、L、Tとすると、Lから得られるハッシュを自己教師とすることでVとTのそれぞれから得られるハッシュを同一のものにする。また特徴量分布を近づけるためにVとL、TとLそれぞれについてadversarial learningを行う。ハッシュ化するネットワークのロス関数としてハッシュ値の類似度、ラベルに対するclassificationのロスをとる。
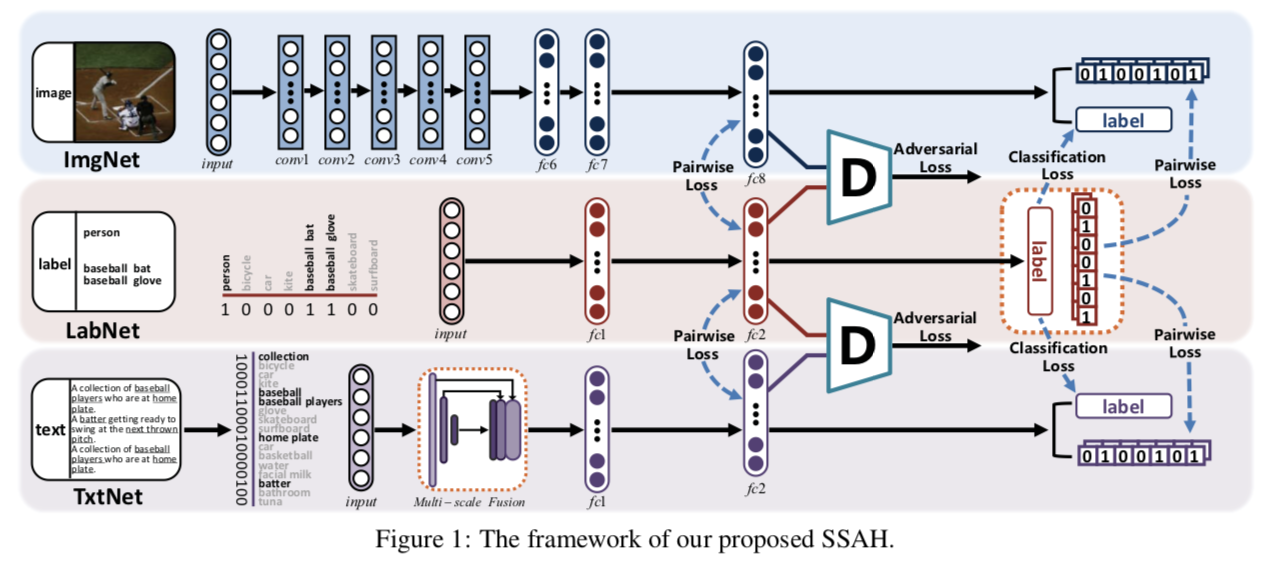
画像復元手法に対する評価尺度であるdistortion quality(DQ、MSEなど)、peceptual quality(PQ、主観評価、KL-divergenceなど)は反比例関係(どちらの尺度も値が低いほうが良い結果であると設定)にあることを様々な実験により示した論文。DQは復元された画像とオリジナルの画像との類似度を表し、PQはオリジナルの画像とは関係なく復元された画像がいかに自然かを表す。
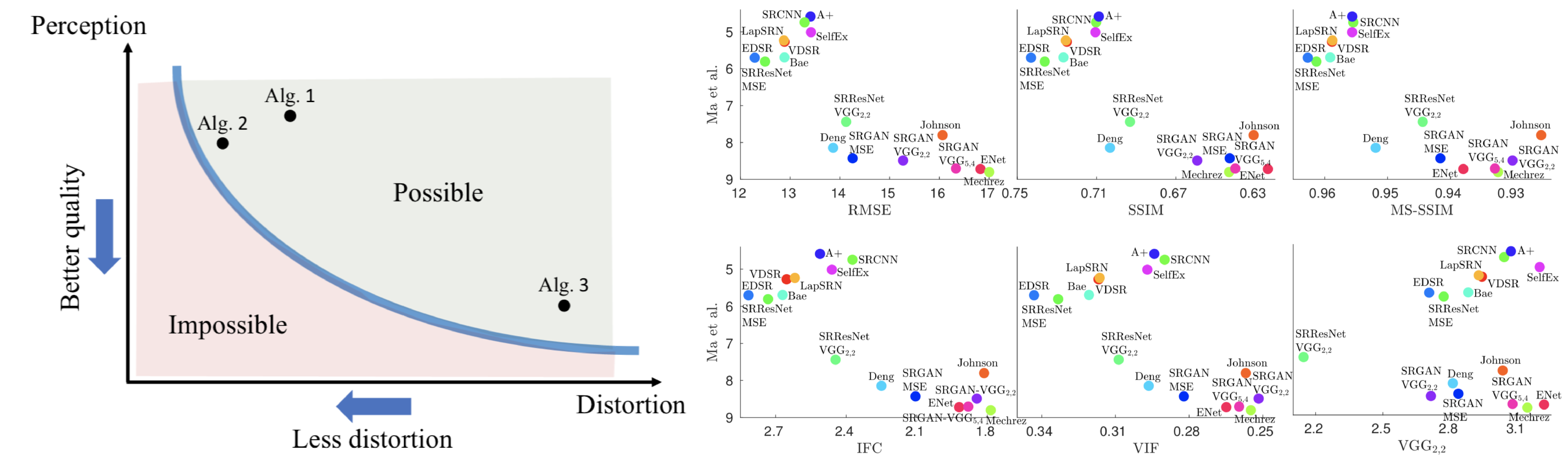
骨格のtissue-depth vector(ランドマークにおける皮膚と骨格のデプス)を用いてMCMCによって顔と骨格の統計的形状モデルの同時分布を推定する手法を提案。顔の統計的形状はPCAによって次元削減したものを使用し、求めるべき同時分布をベイズの定理によって骨格の統計的形状に対する事前分布と顔の事後分布に分ける。骨格の事前分布を30の骨格のCTスキャンを使用することで作成。tissu-depth vectorを用いてGTの骨格と推定された顔形状の交差、対応点の一致度を用いて顔に対する事後分布を推定する。
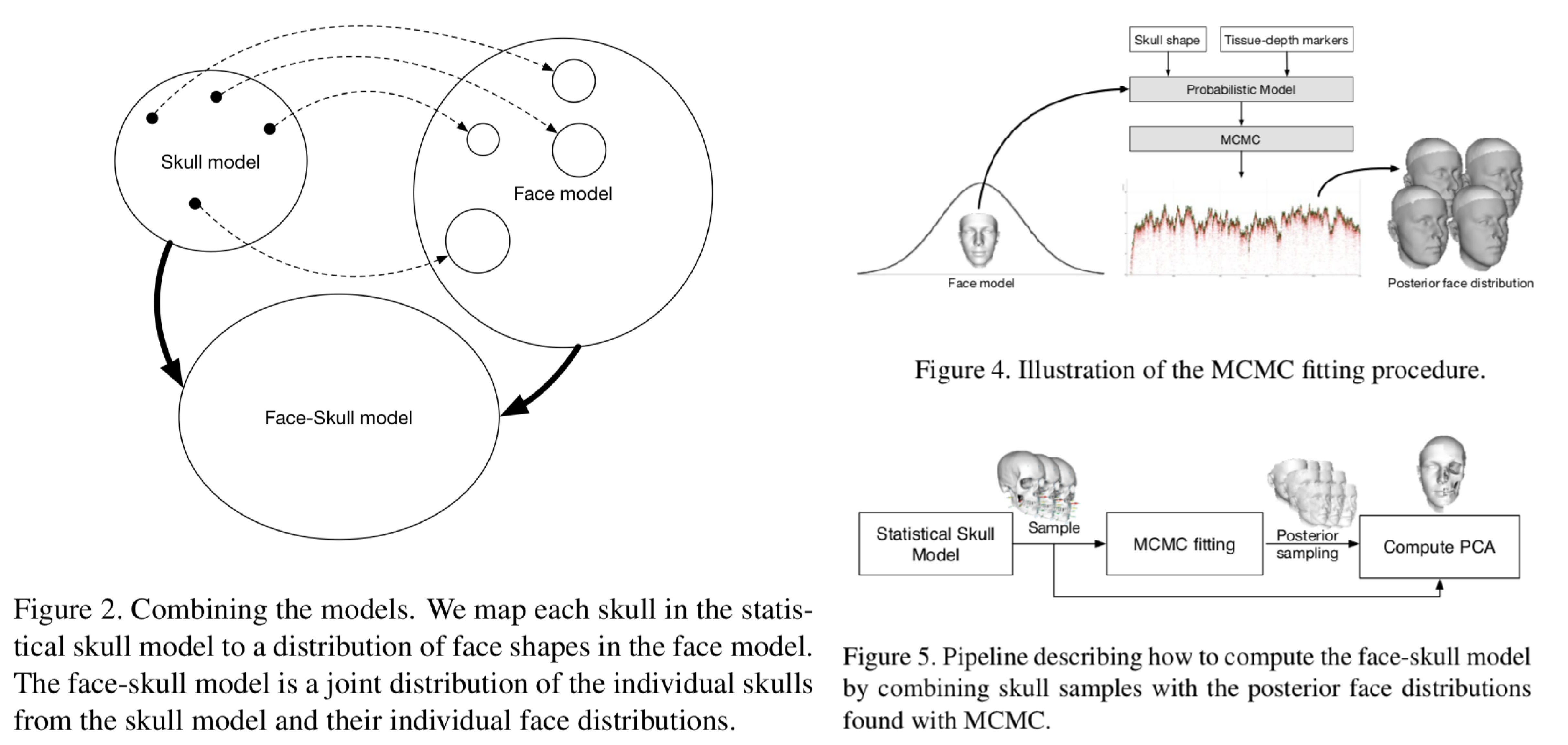
動画内の人数を指定することなく、動画内でメインで登場する人物のIDを保ったmulti-faceトラッキングを行う手法を提案。提案手法は三段階に別れている。まずショット内で顔、頭、胴体、全身の重心、幅、高さを算出しグラフ構造を用いることでショット内、間でIDを保ったトラッキングを行う。次に同一フレーム内のトラッキング軌道を繋げるためにVGG-face descriptorと既に存在する軌道の接続性を見て繋げる。最後にGaussian processによってVGGの特徴量を18次元まで削減した特徴量を使用することで、メインで登場していない人物に対する外れ値認定やトラッキングのリファインメントを行う。検証には人物の見た目の激しい動画やカメラモーションが激しい動画を使用する。
![]()
Unsupervised domain adaptationにおいて、ソースドメイン(SD)とターゲットドメイン(TD)の識別に加えてAuxiliary Classifier GAN(AC-GAN)による画像生成を用いた手法を提案。F networkでドメインに普遍な特徴量を取得した後、GANによってドメインに固有な表現を獲得。Generatorによって生成された画像に対して、Discriminatorではドメインの識別とSDに対してはクラスの識別も行っている。
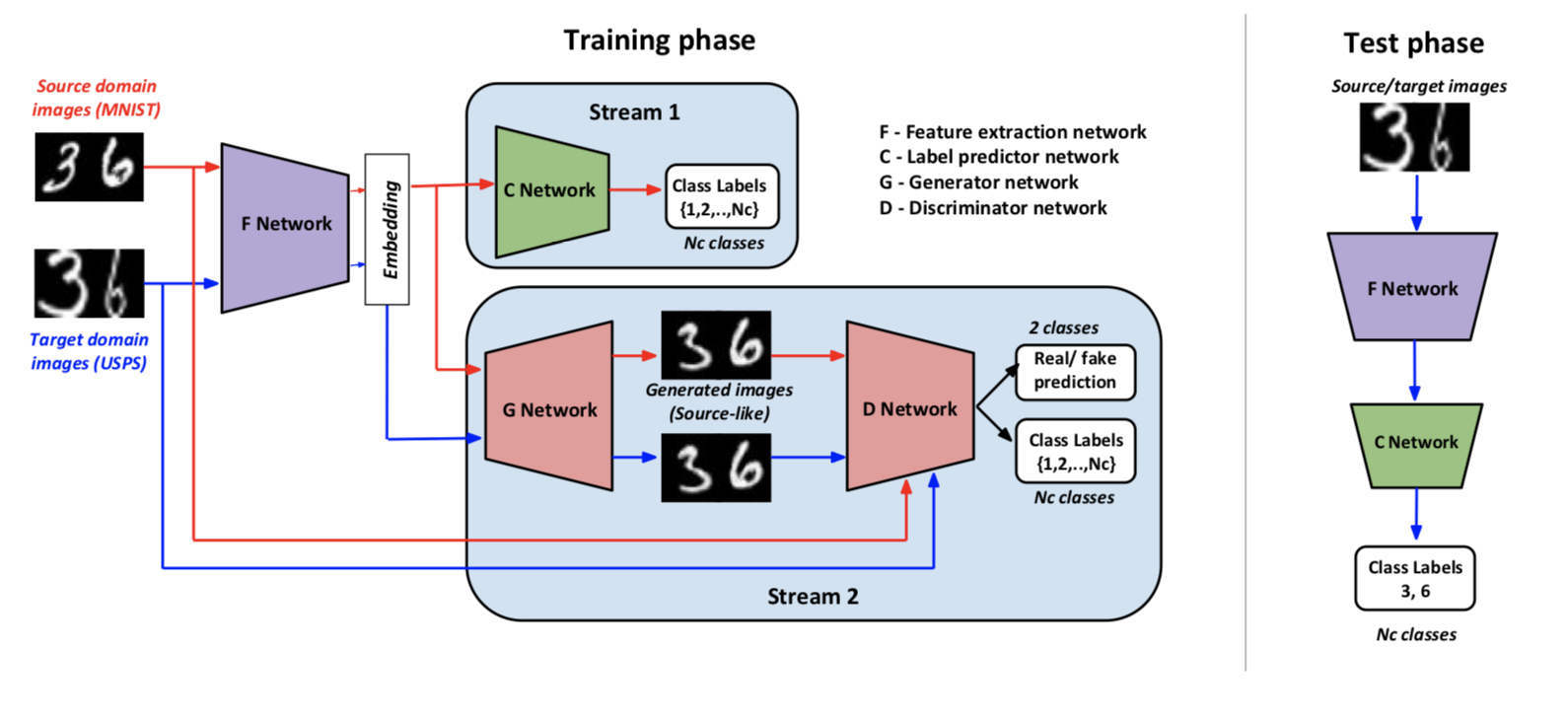
マルチドメインな学習を行うために、少量のドメインに固有なDNNのパラメタを学習する手法を提案。既存手法のresidual adaptorと呼ばれるドメインに固有なパラメタを学習する機構を改良しており、提案手法ではドメインごとに学習すべきパラメタが普遍特徴量に対するバイアス項となっている。既存研究のモデルでは不変特徴量に対する係数となっているので、提案手法の方がより学習が容易になっている。
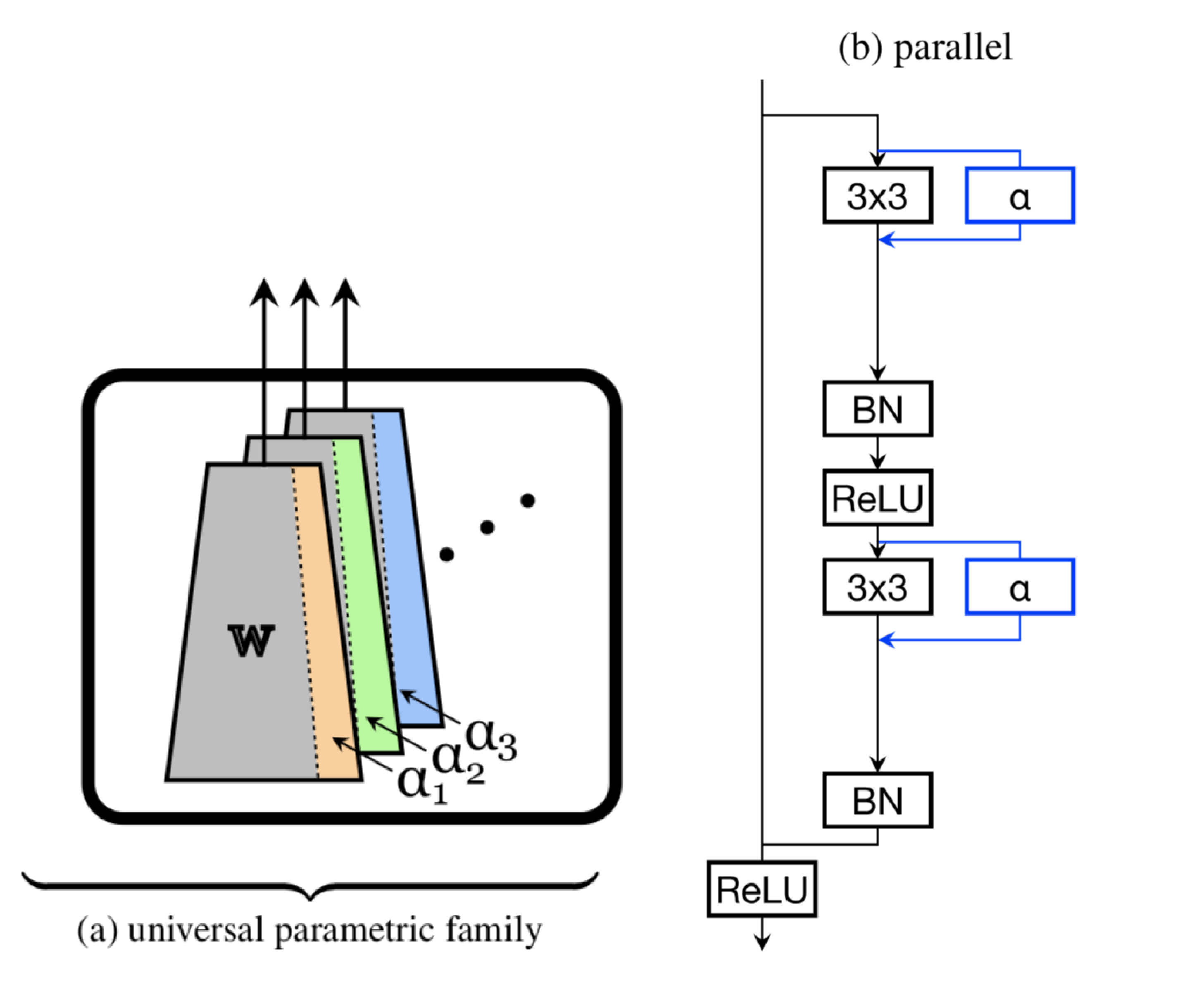
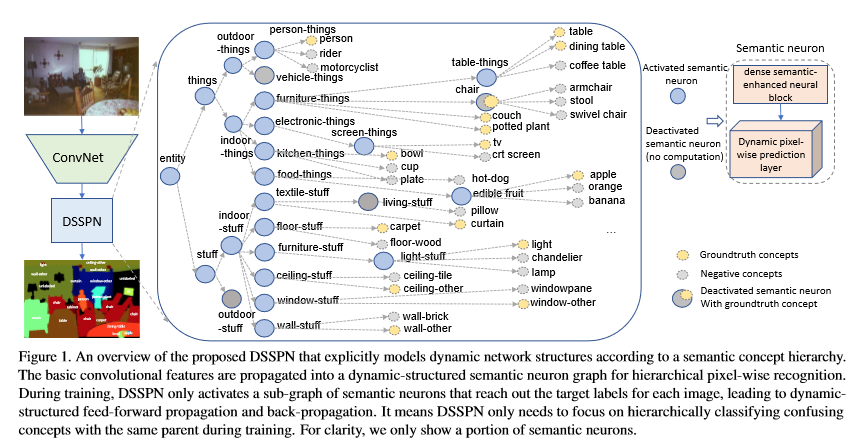
弱いラベルを付与する関数から、出来る限り厳選したラベルを教師として与えるAdversarial Data Programming(ADP)を提案してデータを生成しながら識別器を学習する。マルチタスク学習と同様に、ドメイン変換についても効果的に行えるGANの学習とした。生成Gに相当するタスクではデータラベルの分布を生成して、識別Dに相当する部分では相対的精度の向上、ラベリングの依存性を考慮しながらラベルづけの正当性を確認する。
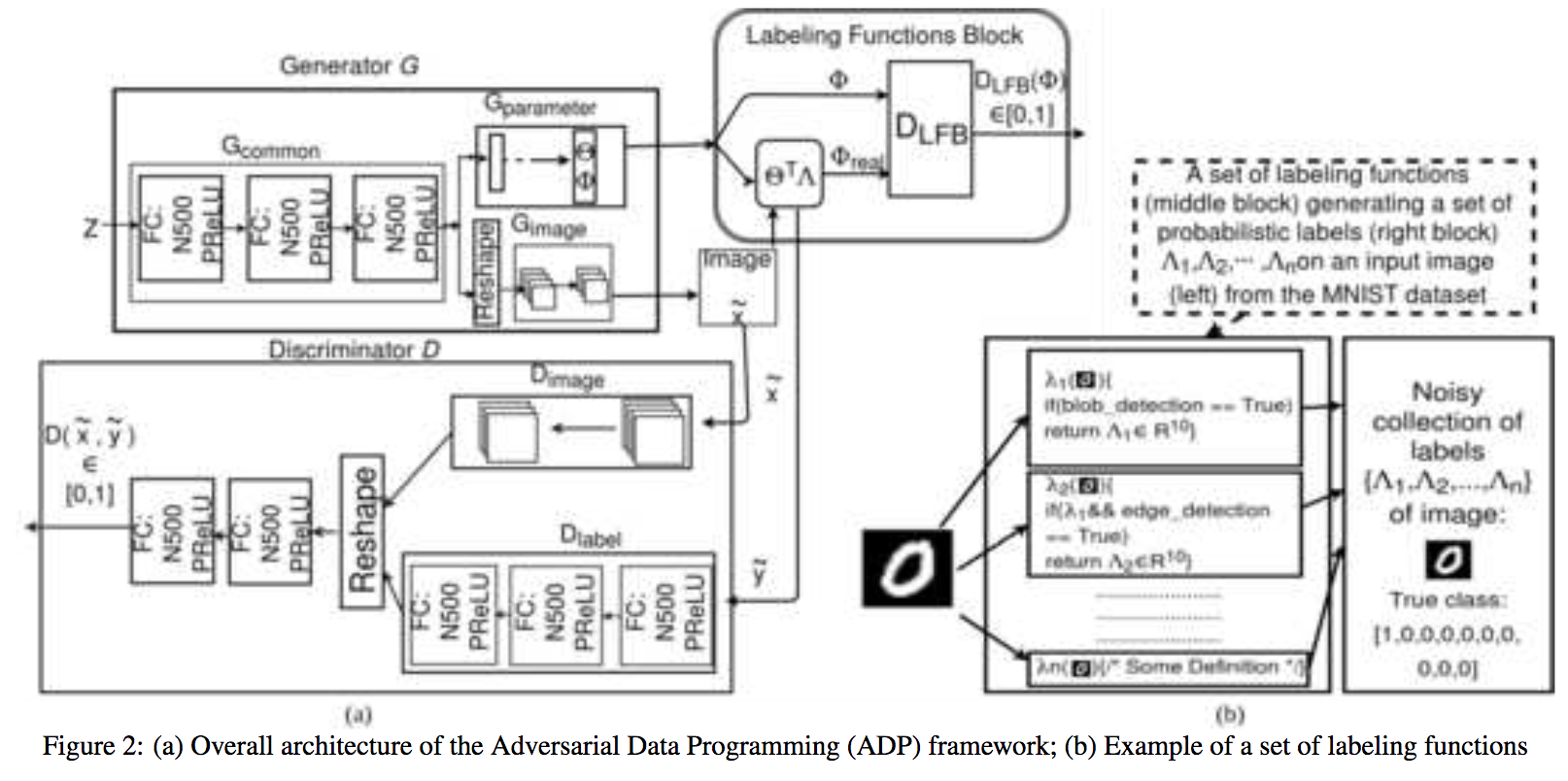
従来のDPは最尤推定により条件付きモデルP(y|x)を推定する問題であったが、本論文で提案するADPは同時確率モデルP(x,y)を推定する問題(データとラベルのペアを評価すること)に相当し、GANにより最適化する。MNIST, Fashion MNIST, CIFAR10, SVHN datasetにて実験を行い、多くの比較手法を抑えてstate-of-the-artなモデルであることを確認。マルチタスク学習やドメイン変換にも有効である。
部分的にのみアノテーションが手に入る比較的少量のデータにおいて、顔ランドマーク検出問題にてSemi-Supervised Learningの手法を提案。ラベルなしのデータに対してキーポイントを推定して、誤差逆伝播ができるように構築。さらに、教師なし学習の枠組みでもキーポイント推定ができるようにした。右図は顔キーポイント検出の枠組みであり、上から順に(S)ラベルありのデータにて学習、(M)顔キーポイントからの属性(Attribute)推定、マルチタスク学習により間接的にキーポイント検出を強化、(N)正解画像に対して画像変換を施してデータ拡張。
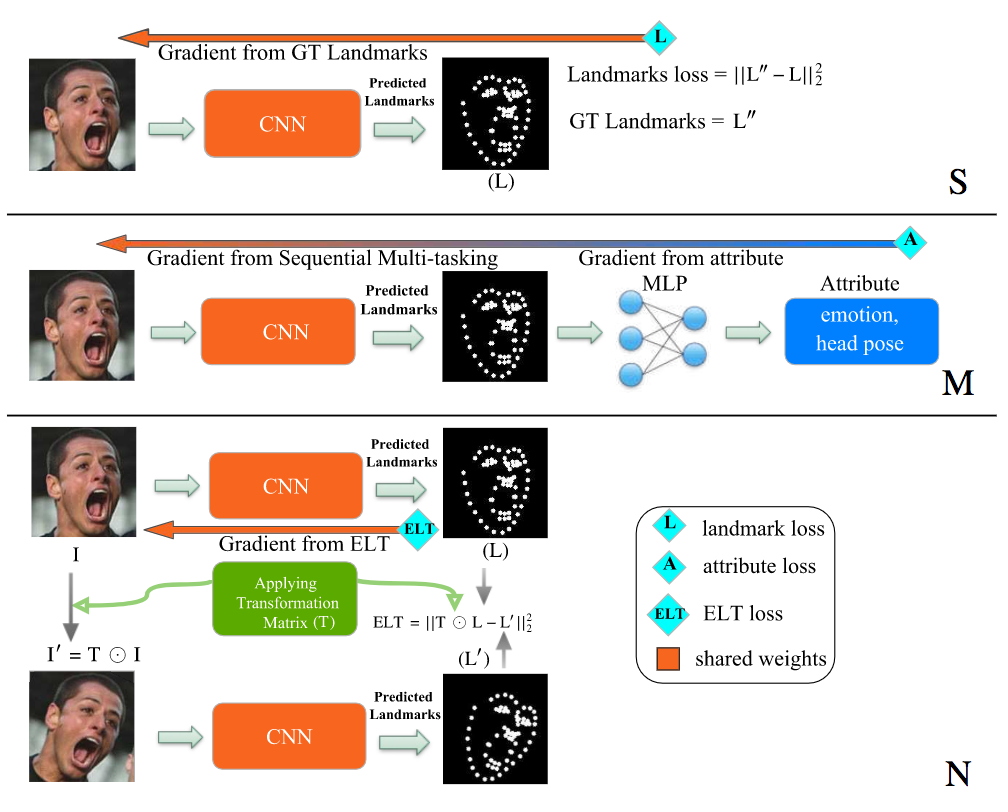
半教師あり学習(Semi-Supervised Learning)の枠組みで顔キーポイント検出を実行することを可能にした。特に、AFLW datasetで5%のみのラベルありデータで従来法を超えてState-of-the-artを実現した。
高速に動画処理をできるようにするRecurrent Residual Module(RRM)を提案。計算時間を大幅に削減するために、連続するフレーム間で畳み込みによる特徴マップを共有。AlexNetやResNet等と比較すると約2倍は高速であり、ベースラインであるDenseModelと比較すると8--12倍は高速であった。それだけでなく、XNORNetsなどの圧縮モデルにしても9倍高速であることが判明。この枠組みを用いて姿勢推定や動画物体検出のタスクに適用。右図は提案であるRRMの構造を示している。DenseConvolutionは最初のフレームのみであり、後続のフレームは差分の把握とSparseConvolutionによりforwardを実行。
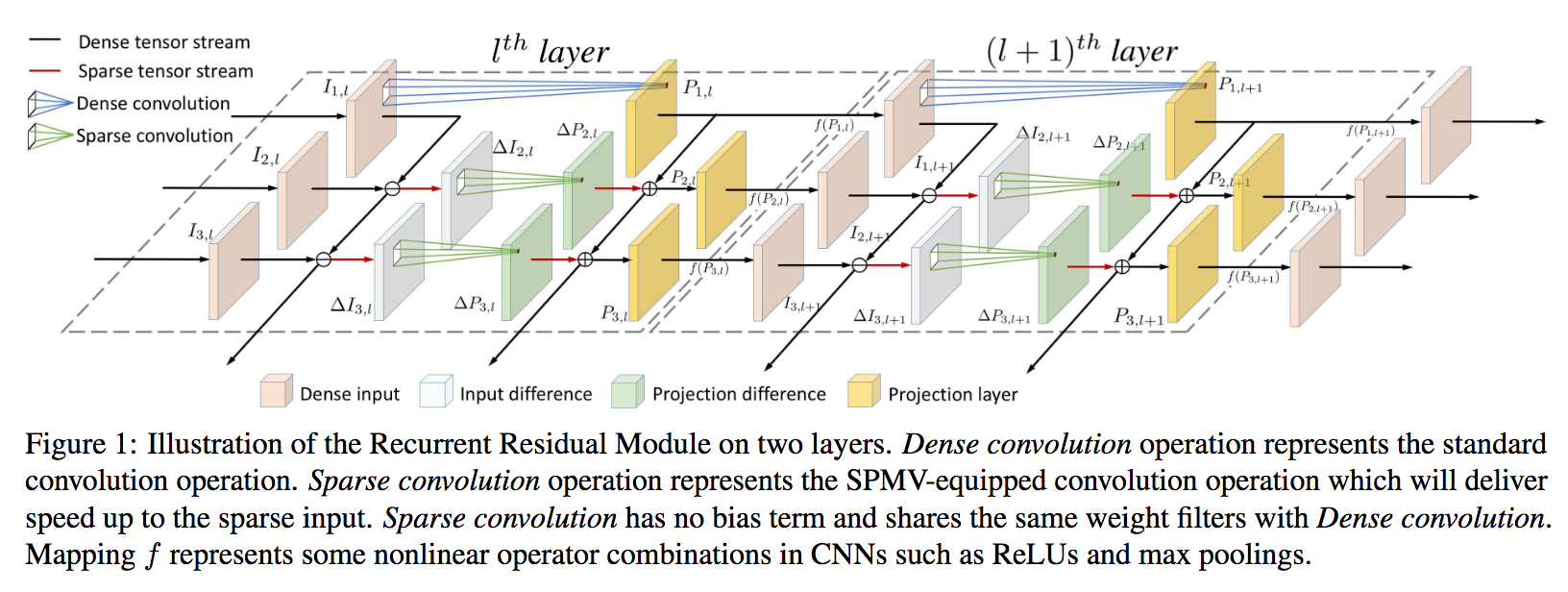
一番の新規性は動画の連続フレーム間でパラメータを共有して高速かを図るRecurrent Residual Module(RRM)である。同枠組みを姿勢推定や動画物体検出に使用して高精度な推論を実現した。動画物体検出ではYOLOv2+RRMにて61.1@Youtube-BB、姿勢推定ではrt-Pose+RRMにて46.2@MPII-Poseを達成し、ベースラインから精度をほぼ落とさずに高速な処理を実行。
実環境データの多様体を学習するための敵対的学習(GAN)を実現するLocalized GAN(LGAN)を提案。従来の多様体を表現するGANと比較して、LGANはいかに多様体間を変換するかの学習が効率よく行えている。同学習はMode Collapseを避けるためにも有効であることが確認され、さらにはロバストな識別器にもなることが実験により明らかとなった。図は任意の3次元空間に埋め込まれた多様体空間であり、Normal Vector(法線ベクトル)とTangent Vectors(タンジェントベクトル)が示されている。このTangent Vectorが多様体空間M内にて点xの位置の局所的変換を可能にする。
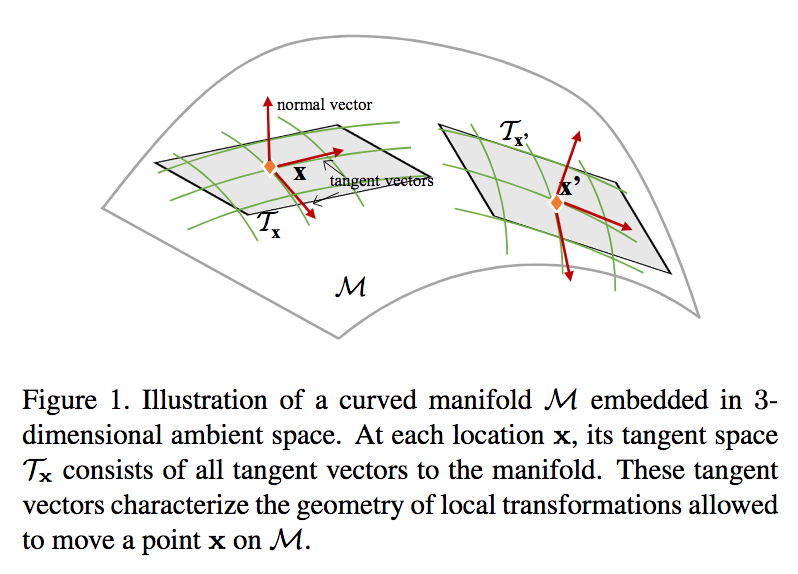
LGANの利点は主にふたつ、(1)多様体において、グローバルな点を参照することなくローカルな参照にて所望の結果を得ることができる。多様体であるが、局所的な探索で良い。(2)Local Tangentにて正規直交基底による事前情報を入れることができ、局所的なCollapseをケアできるという意味で有用である。GANのMode Collapse問題にも有効。また、提案する多様体空間構築は、画像識別においても有効であることが示された。

Dual-taskを利用して,精度向上を図る手法が多そう

かなり良い精度でblurを除去できる.推定したblur kernalにより動画像生成するのができそう.
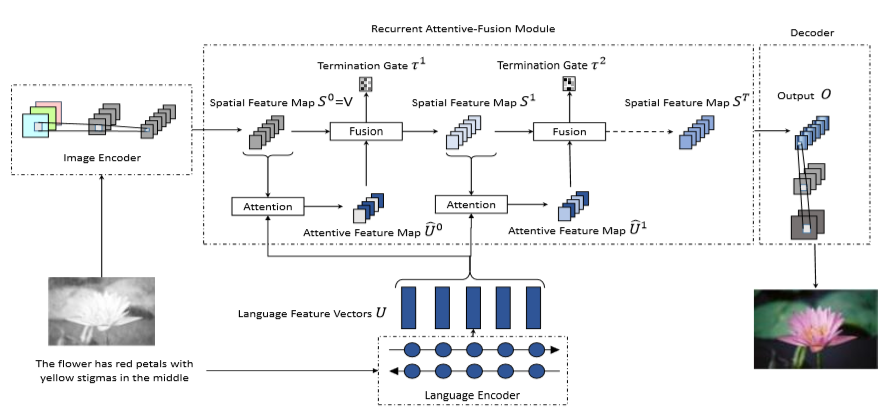
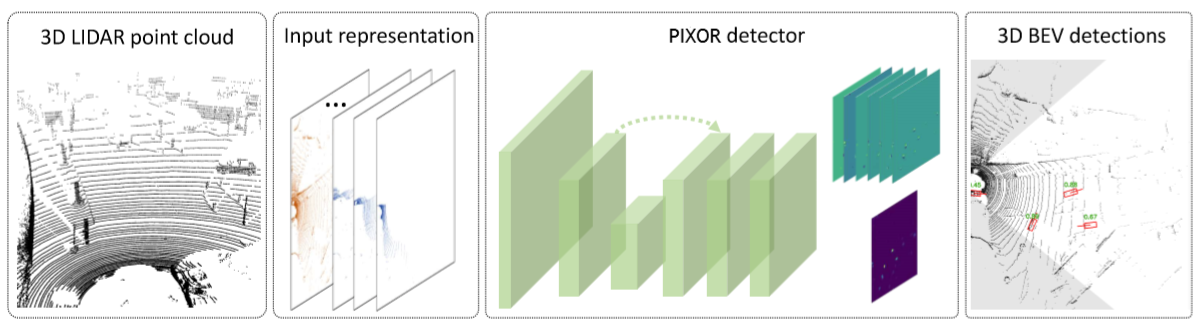
BEV視点の3次元表示が自動運転に使いやすいと感じた.
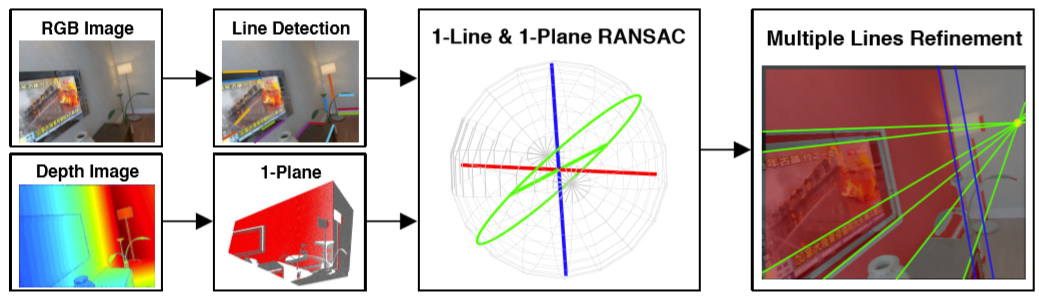
DNNを用いないカメラ姿勢推定の手法を紹介した.伝統的手法及びDNNを用いた手法のロバスト性の比較に関する実験が期待している.
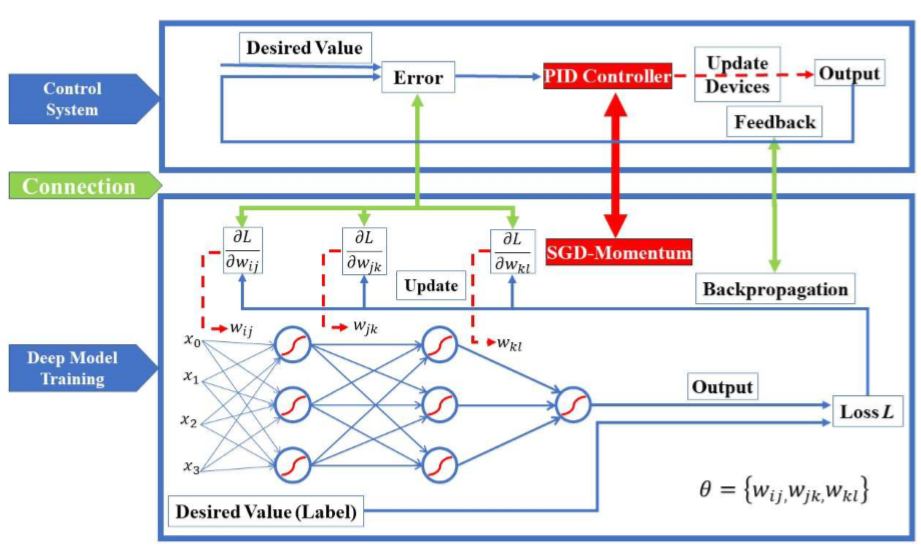
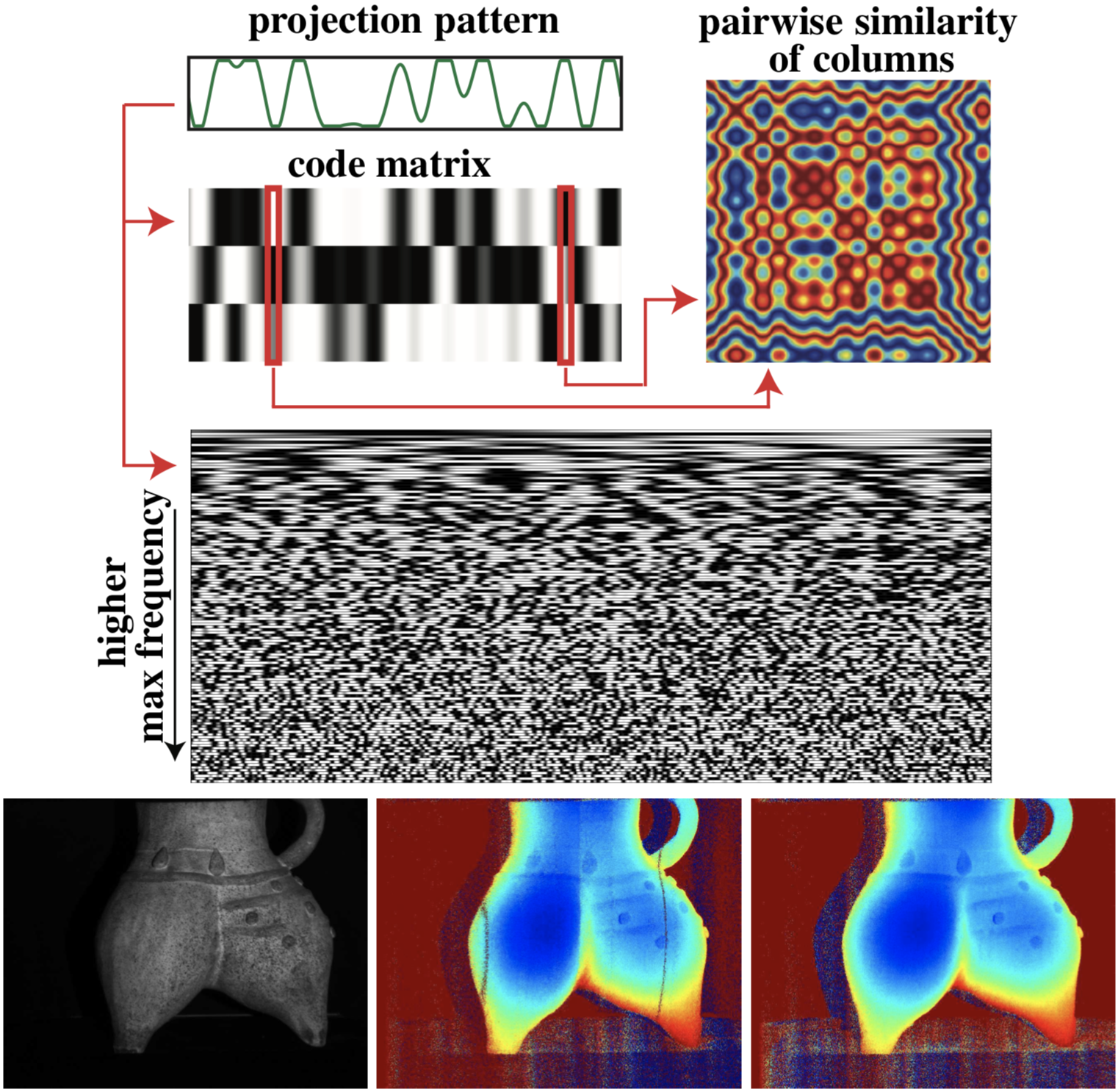
Person Re-Identification(ReID)をするためのEnd-to-Endなネットワーク(Dual ATtention Matching network: DuATM)を提案した論文。DuATMのコアとなる要素はdual attention mechanismであり、映像内と映像間のattentionを特徴量の補正とペアリングに用いる。また実験では、いくつかのベンチマークでSoTAを達成した。
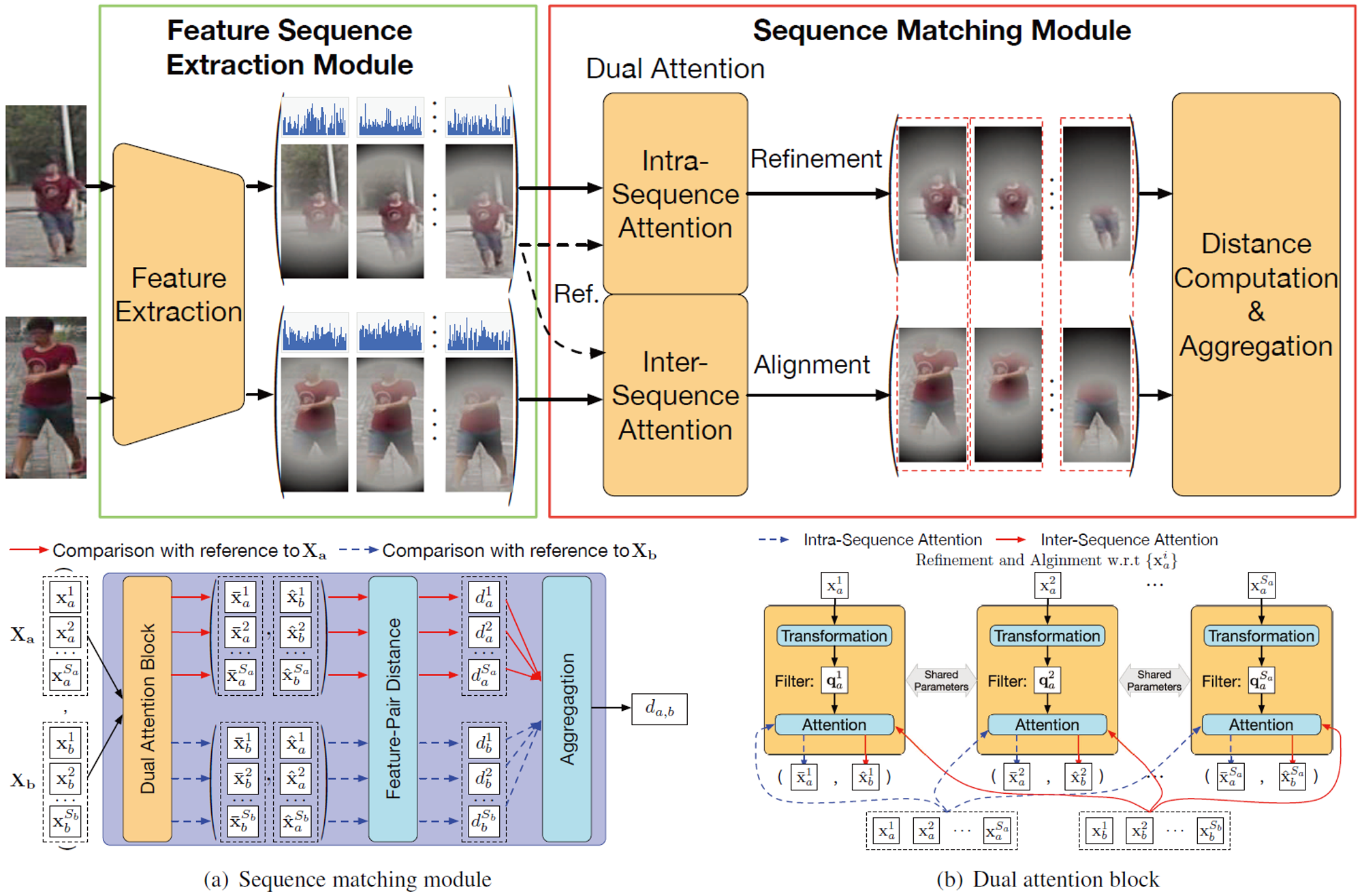
DuATMは大きく2つの構成要素からなる。1つは動画内から特徴量を抽出する要素であり、もう1つはそれらの特徴量のマッチングを行う要素である。後者にdual attention mechanismが導入されており、1つはコンテキストに応じて映像内の特徴量を補正するものでありもう1つは映像間の割り当てを行うものである。DuATMの損失関数はtriplet lossに加えて、de-correlatoin lossとcross-entropy lossを用いており、これに対してsiamese networkを学習する。
スペックル・イメージングを利用して見えていない(non-line-of-sight: NLOS)複数の物体を追跡する手法を提案した論文。安価なコストで角付近に存在する複数の物体を10マイクロメートル程度の精度で追跡可能にした。拡散反射する壁を通して間接的にしかセンシングできない環境において、スペックル・イメージングの方法と動きのモデルを提案した。
![]()
スペックルとはコヒーレント光が荒い表面で反射した際に発生する高周波なノイズのような画像である。提案手法では、このスペックルの動きと実際の物体の動きの関係をモデル化することで、拡散反射する壁から得られる情報から物体追跡を行う。実際には参照画像とそこから物体が移動したことで得られた画像の相関を取り、ピークを得ることで、物体の移動量を得る。
より少ないインタラクションで高精度なInteractive Image Segmentationを行う論文。インタラクションが少ない場合に発生する曖昧さ(multimodality)の問題に取り組んだ。また従来の手法と同様のインターフェースと互換性のあるシステムとなるような設計を行った。実験では、従来手法より少ないクリック回数で良い精度のセグメンテーションを得ることができるようになった。

ネットワーク構造はユーザの入力を考慮した複数の異なるセグメンテーション結果を出力するネットワークとそれらから1つのセグメンテーション結果を選択するネットワークで構成される。複数のセグメンテーション結果をランク付けし、それに伴った重み付けを行った損失関数を用いる。
異なる視点から撮影された映像から、CNNとMRFを用いて物理的制約を考慮可能な密な3次元復元を行った論文。CNNはタスクに対してネットワーク全体をデータから学習可能であるが、物理的制約を考慮することができない。一方でRay-Potentialを用いたMRFはモデルに陽な物理的制約を与えることができる一方で、大きな表面を上手く扱うことができない。本論文ではこの2つの手法の良いところをそれぞれ活かした手法であるRayNetを提案した。
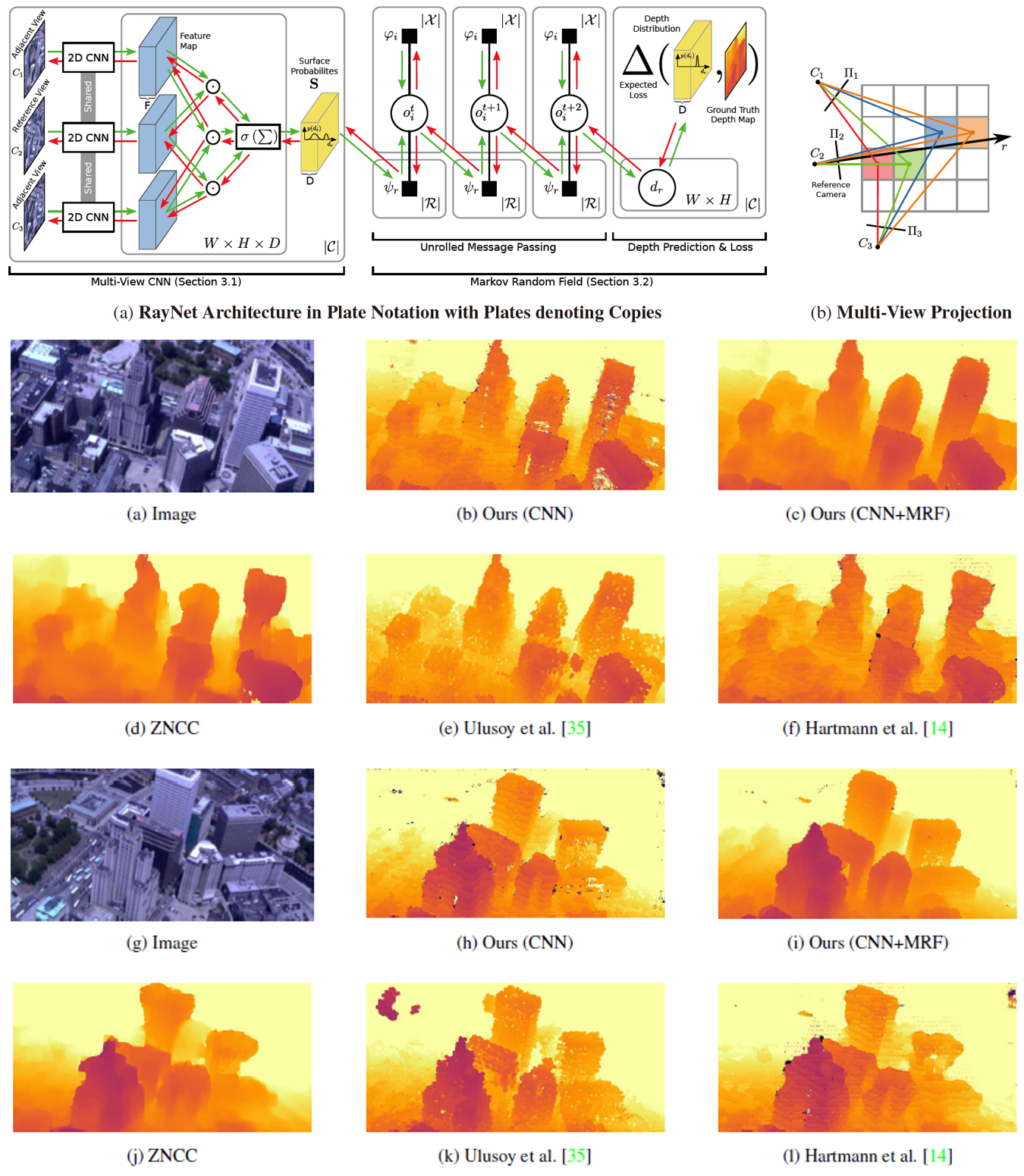
構造としては、Multi-View CNNとMarkov Random Fieldから構成されている。Multi-View CNNは入力として複数の画像とそれに対応するカメラの姿勢を受け取り、視点による影響が小さい特徴量を抽出し、Rayごとにデプスの分布を出力する。Morkov Random Fieldは各視点からにおける遮蔽を考慮して、CNNから出力されたデプスの分布のノイズを除去する。

オンラインの弱教師あり物体検出(WSD)に敵対的生成学習を用いて高速な検出を行う.Generator(G)は画像からb-boxを生成し,surrogator(F)はannotation情報からb-box分布を推定する.GおよびFからの検出結果はdiscriminator(D)に入力される.Dはb-boxおよび分布が真(Fからの出力)であるか偽(Gからの出力)であるか区別する.各モジュールを学習して,推論時は学習されたGのみを用いる.
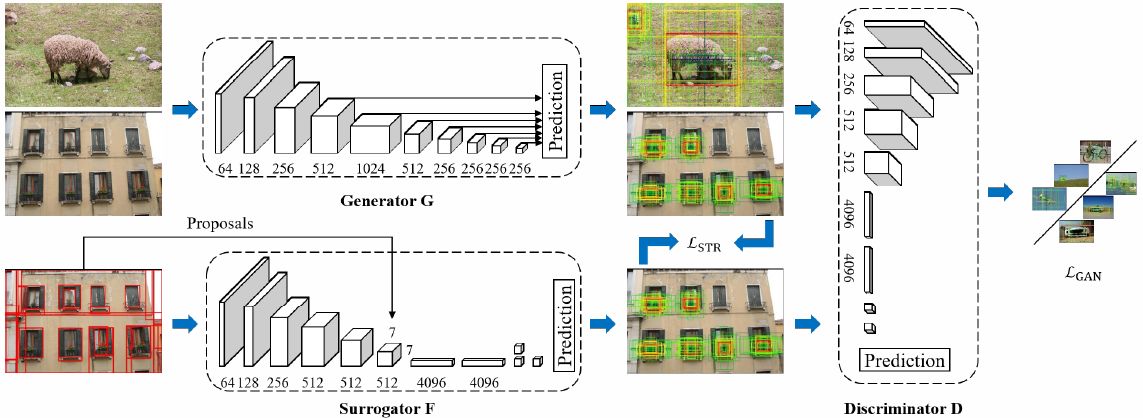
作者らの知る限りでは,弱教師あり学習でYOLOやSSDのような1ステージ物体検出を用いる最初の手法である.VOCを用いて実験を行い,ほとんどのクラスでSOTAと同等またはそれ以上の性能を達成し,平均では47.5mAP,66.1CorLocを達成した.検出速度は入力画像サイズが300のとき8.48ms,512のとき19.93msとかなり高速(1080Ti, i7-6900K).
多視点画像から3次元物体検索手法を提案。クラスの重心に近づくように最適化するcenter lossと、同一クラス同士の距離を小さくし他クラスとの距離を大きくするtriplet lossを組み合わせたcenter-triplet lossを導入した。 triplet-center lossにより、正解クラスの重心との距離を最小化しつつ、他クラスの重心との距離は最大化する。 triplet,centerそれぞれ単独よりtriplet-center+softmaxが一番いい。 他の手法よりも3d shape、sketchどちらにおいても精度がいい。
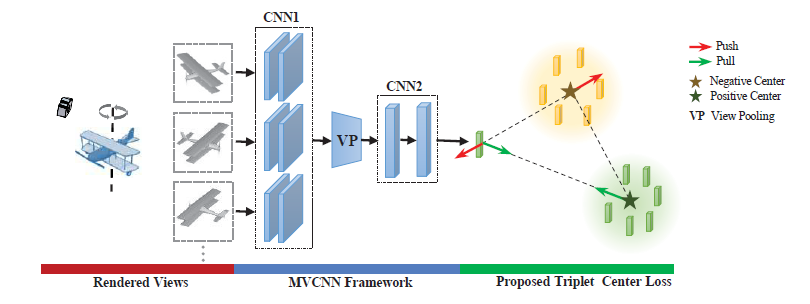
triplet loss、center loss単独で最適化するよりcenter-triplet loss及びsoftmax lossを組み合わせたものがAUC及びmAPが最も良くなることを確認した。従来手法と比べ、generic 3D shape retrieval及びsketch-based 3D shape retrievalの2種類いずれのタスクにおいて、F1、mAP、NDCGの三つの指標が最も良いという結果が得られた。
Future workとして書かれているが、手法自体は他のタスクにも試せそう。3D Object Retrievalに特化して構築された手法でないにも関わらず他のタスクが紹介されていないのは他のタスクがうまくいっていないということだろうか?
医療画像から、病名の特定及び異常箇所の特定を行う手法を提案した。ResNetにより抽出した特徴を、パッチに分割し各パッチが異常箇所であるかを予測する。 予測したパッチ情報を用いて、病名の判定を行う。 学習時には、病名のみラベルがついていて異常箇所のラベルが付いていない場合がある。 そこで、病名のみしか存在しない場合は少なくとも1つのパッチが異常箇所であると仮定して学習を行う。
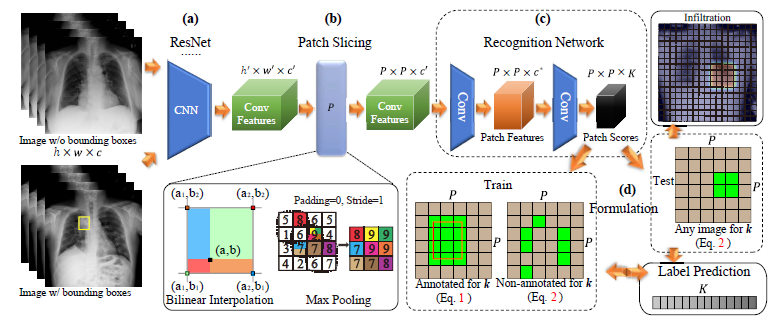
病名診断については、14の病名のうち12の病名においてベースラインよりも精度が向上した。異常箇所の特定については、従来手法と比べ8つの病名全てにおいて精度が向上している。
カメラモーションによって生じるdistortionをなくすための手法を提案。市販のカメラの多くは、撮影時に行ごとに処理を行うためカメラが動いている場合同じ画像であっても各行のカメラの位置は異なるため、distortionが生じてしまう。 そこで画像の各行が異なるカメラ位置として扱い、distortionのない状態への復元を行う。 具体的には、動画の各フレームからdepth mapを推定することで、backgroundの復元を行う。 続いて3次元空間をlayer分けして考え、background以外のlayerに対するマスクを作成することでocclusion領域を埋めていく。

従来手法と比べ、ピクセルの推定値を評価するPSNR、カメラモーションの推定値を評価するAPMEどちらも向上した。特にカメラモーションの推定は従来手法と比べて格段に向上している。
学習データのラベルにノイズが含まれている場合の学習方法を提案した。ネットワークのパラメータを求めるのみならず、ラベルそのものも更新していくことでラベルからノイズを取り除くことを可能とする。 ネットワークのパラメータとラベルの一方を固定した更新を繰り返すことにより最適化していく。
CIFAR-10 dataset及びClothing1M datasetにより評価を行った。CIFAR-10の結果は、ノイズの割合に関わらず提案手法がベースラインと比べ精度が向上し、ノイズが50%含まれる場合でもTest Accuracy84.7%、Recovery Accuracy88.1%を記録した。 Clothing1M datasetもベースラインよりaccuracyが良く、72.23%を記録した。
1枚画像から視点を変えた画像を生成する方法を提案した。有限の数の平面の存在を仮定し、各平面の組み合わせによって新たな視点の画像を生成する。 入力画像に対してピクセル単位でdepthとnormalを推定し、平面の数と同様のHomography変換を考える。 同時に入力画像からピクセル単位でどの平面を出力画像の生成に用いるか決定することで、出力画像を得る。
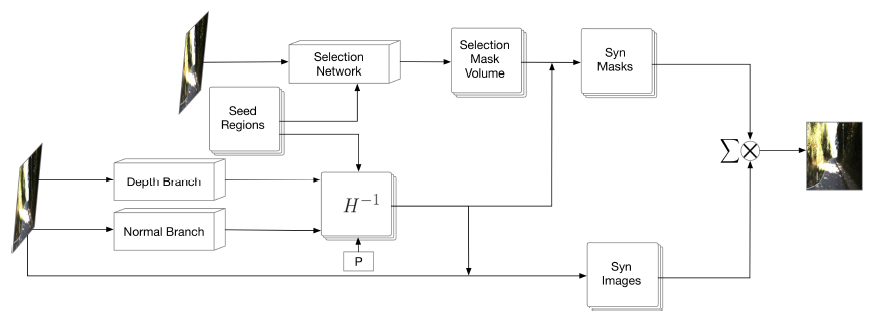
従来手法が考慮していなかった3次元的な特徴を考慮することで、歪みなどが存在しない画像を出力することに成功した。数値評価においても、ground truthとのL1ノルムがベースラインと比べ小さくなっている。
グラフカットの問題において、edgeの重みが他よりも小さい場合そのedgeで切断してしまいnodeが1つしかないクラスができてしまう。この問題を解決するために、Compassionately Conservative Balanced (CCB) Cut costsを提案した。 クラス間のnode数のバランスを取るための方法として、Compassionately Conservative Ratio CutやCompassionately Conservative Normalized Cutなどが提案されているが、CCBはこれらを一般化したcostとなる。
従来手法が考慮していなかった3次元的な特徴を考慮することで、歪みなどが存在しない画像を出力することに成功した。数値評価においても、ground truthとのL1ノルムがベースラインと比べ小さくなっている。
Positiveデータが1枚のみであり、Negativeデータが存在しないOne-Shot One-Class(OSOC)問題を解く方法としてCulmulative LEARning(CLEAR)を提案した。人間が学習する際、同じことを何度も繰り返すこと、似たような技能を既に修得している場合はそうでない場合よりも上達が早いことに着目した。 学習済みの特徴抽出器から得られた画像特徴より、識別の境界を決定するネットワークによって識別器を構築する。 学習の際には、ImageNetから取って来た1枚の画像に対して境界を決定し、その画像が得られた境界によって正しく識別できているかを見ることで学習する。
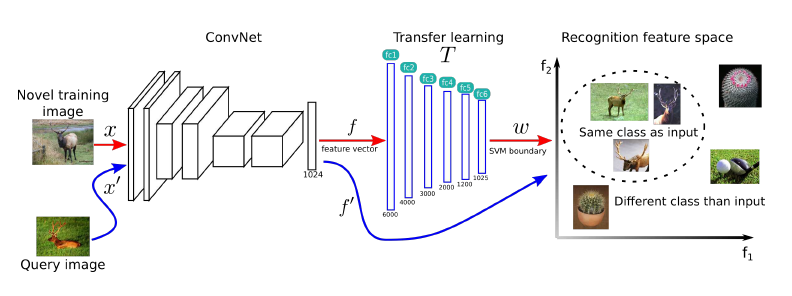
5種類のデータセット(Caltecb-256, Oxford Flowers, Caltech-UCSD Bird-200-2011, MIT Indoor scene recognition and SUN attribute database)で実験した。実験の結果、MAP及びF1の指標がランダム出力、One-ClassSVMと比べ精度が良いことを確認した。
与えられた視線方向から視線画像を生成してくれるHierarchical Generative Model(HGM)を提案.HGMは2つのネットワークから構築されており,KnowledgeベースのHierarchical Generative Shape Model(HGSM)とData-drivenなconditional Bidirectional Generative Adversarial Network(c-BiGAN)から構成されている. ここで,入力する視線方向は,yaw, pitch, rollである. HGSMは,与えられた視線方向から目の形状のパラメータを推定する. c-BiGANでは,2種類の入力によりDiscriminatorを学習する. Generatorが出力したsynthesized imageとHGSMの出力と,real imageとEncoderで出力した目の形状パラメータであり,これらの入力を用いてDiscriminatorを学習する.
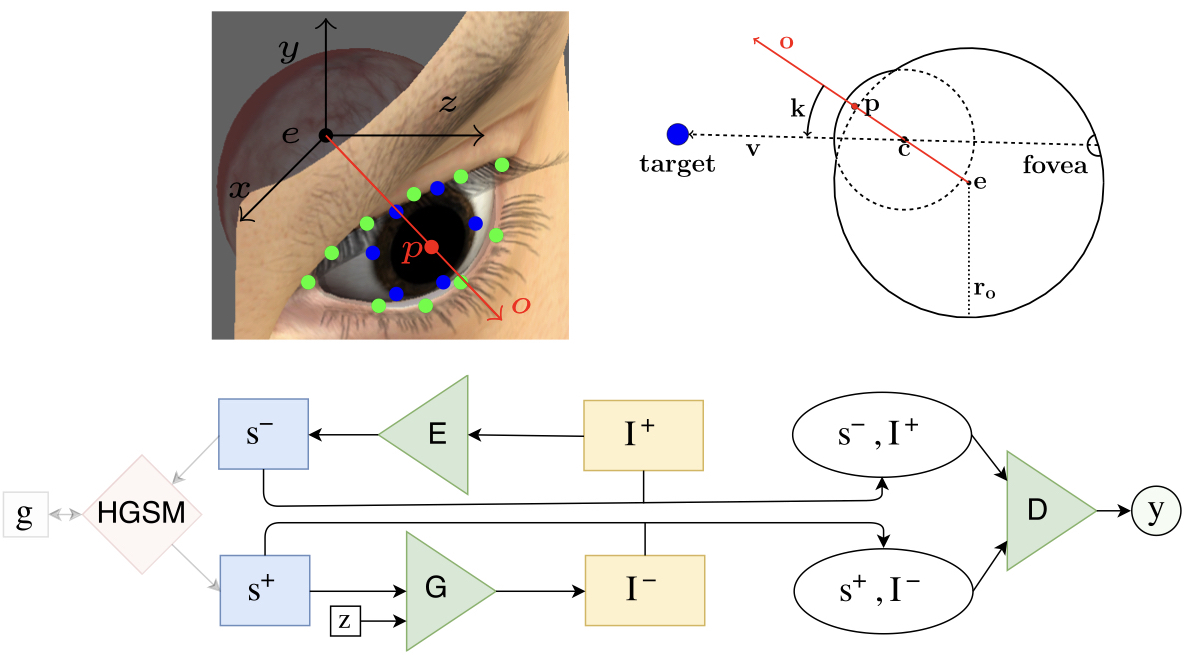
生成されたCGを用いて学習するアプローチ.SimGANではCGを作った後に学習しているが,この手法では視線方向等のサンプルパラメータのみで学習サンプルの生成&推定が可能である. この論文では,視線推定だけでなく,表情推定にも応用することができる.
DNNの高い精度を保持したまま計算コストの削減が可能なHydraNetを提案した。HydraNetには推論時に入力に対して良い精度を出すようにネットワークアーキテクチャの部分集合を選択するsoft gating mechanismが組み込まれている。このような動的な構造を持たせることでaccuracy-per-unit-costを向上させた。実験では、画像分類タスクにおいてResNetやDenseNetと同等の精度をより少ない計算コストで出した。
HydraNetは複数のbranchで構成され、各branchは特定のsubtask特化するように学習されている。その後、gating mechanismによって動的に適切なbranchを選択し、その選択されたbranchから来る特徴量を統合し、最終的な推論を行う。HydraNetでは、各branchは最後の推論までは行わず、subtaskに対応する特徴量だけを計算するような構造になっていることが計算効率の向上につながっている。
右脳と左脳で視覚情報を処理している解像度が異なるという人間の脳の仕組みを模倣したネットワークDual Skipping Networksを提案した。このネットワークは2つのサブネットワークで構成されており、それぞれ同様の構造を持つが、左右でスキップ可能な層のパラメータが異なっており、その結果、左右非対称なネットワークがそれぞれglobalな推論とlocalな推論をするようになっている。画像分類の問題において、既存のデータセットに加えて、小さな文字で他の文字を構成するsb-MNISTデータセットで実験を行い、可視化によってそれぞれがglobalな情報とlocalな情報を保持していることを確認し、また非常に良い精度を出した。
Dual Skipping Networksのネットワーク構造は、右脳と左脳に対応する2つのサブネットワークとそれらが共有するCNNから構成される。共有されているCNNは脳におけるV1領域に対応しており、2つのサブネットワークはそれぞれ右脳と左脳に対応し、globalな推論とlocalな推論をするようになっている。各サブネットワークはSkip-Dense BlockとTransition Layerを交互に重ねた構造になっており、Skip-Dense Blockにおけるスキップ率の違いが2つのサブネットワークの差になっている。Skip-Dense BlockはDense LayerとGating Networkで構成され、Gating Networkがスキップをするか否かを司っている。またglobalな推論をするネットワークからlocalな推論を行うネットワークへの情報を伝達するGuideにより、coarse-to-fineな推論が可能になった。
物体検出の弱教師あり学習において,overfittingを防ぐためにretrain・relocalizeを繰り返すジグザグ学習を提案.特定の対象物を参照して学習画像の難しさを自動で測定する指標「mean Energy Accumulated Scores(mEAS,下図)」を導入し,これに基づいて検出ネットワークを学習する.また,学習中に特徴マップのマスキングを行い,細部に集中するだけでなく,ランダムにoccludeされたpositive-instanceを導入することでoverfittingを防ぎ,汎化性能を高める.
対象物体がわかりやすいかわかりにくいかの単純な戦略を用いて検出モデルを学習し,信頼性の高いインスタンスを検出することができる.弱教師あり学習の物体検出手法でSOTAを達成.VOCデータセットを用いた評価により,ほとんどの物体が他の手法よりも良い性能を達成し,総合のmAPは3~6%程度向上した.
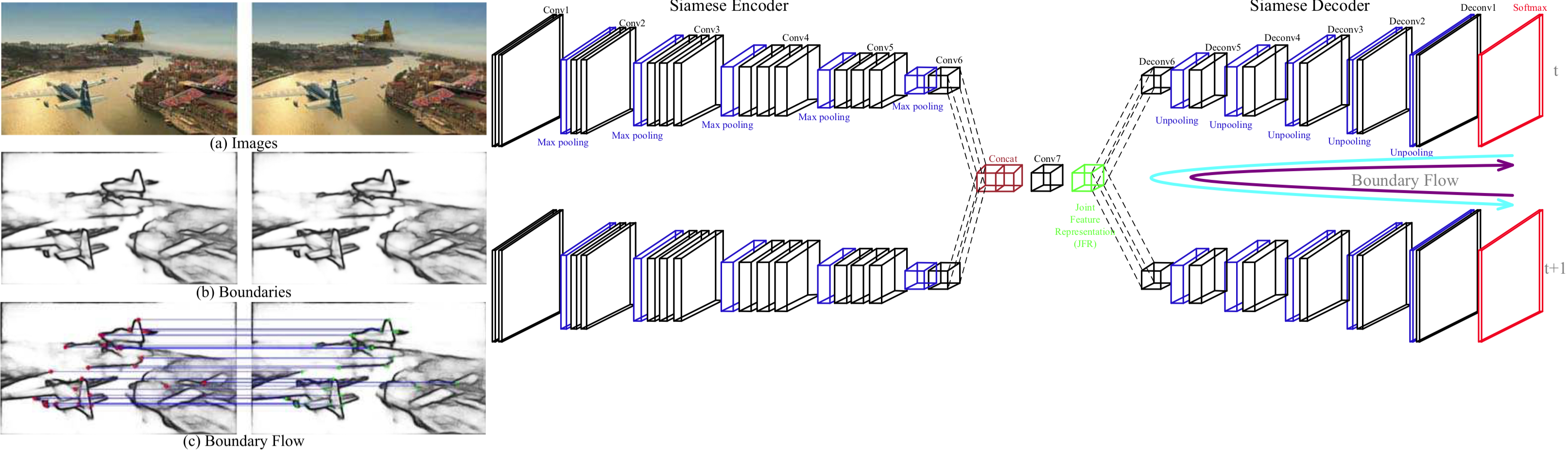
人間の目はサッケード運動をしていることが知られている.これは,意識的に目を動かしていなくても,無意識的に注視点(fixation point)を決めて そこの間を移動するように高速に眼球運動しているというものである. このモデリングは過去より行われており,近年では深層学習によって劇的に向上した.
しかし,静止画の上で行う上では,顕著性マップを通じた非清冽な注視点の推定に大きく依存していた. 人間のようなサッケードの時間的整列済み系列を生成できる改善モデルはほぼない.
そこで,STAR-FCを提案.これは 中心視野・高レベル物体ベース顕著性と, 周辺視野・低レベル特徴ベース顕著性 の統合による.
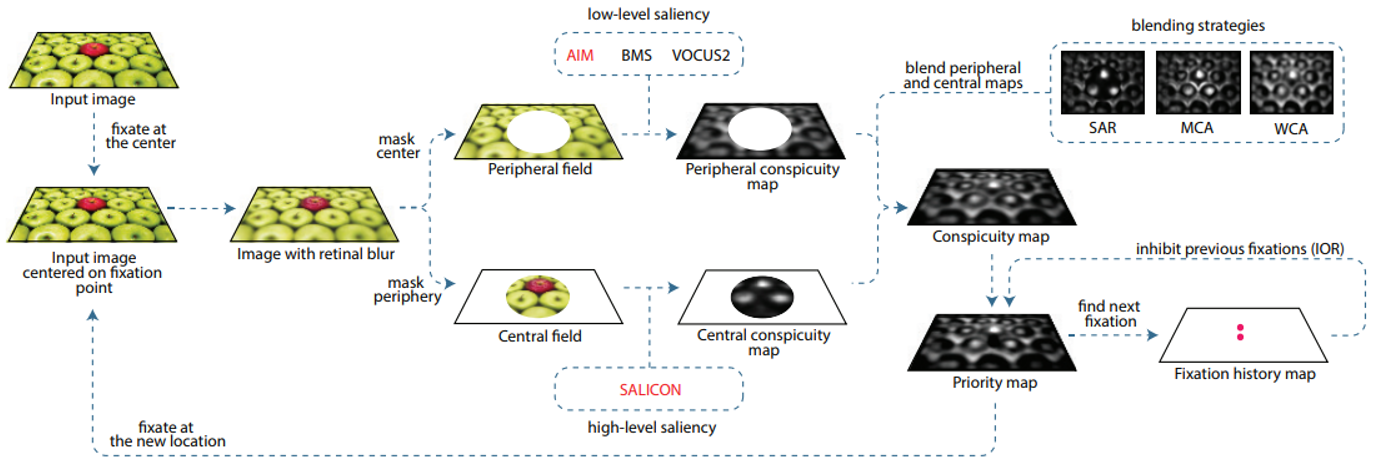
注視点推定において人間レベルの性能を達成.
自動移動エージェントの実世界での走行が成功するには,環境における将来のイベントや状況の緩和が鍵を握る. この問題は,系列の外挿問題として定義された. 系列からの将来の推定に,観測の数が使われる.
実世界シナリオにおいては,不確定さのモデリングが必要となる.それは時間が経つにつれて不確定さが増大する.
未来の系列の上で複数モーダルの分布を誘発するシナリオは挑戦的である.
この研究では,Gaussian Latent Variableモデルによって系列推定に挑戦する.その中心的なアイデアは,「Best of Many」(多くの中から最良を)である. これにより,より正確かつより多様な推定を導く.
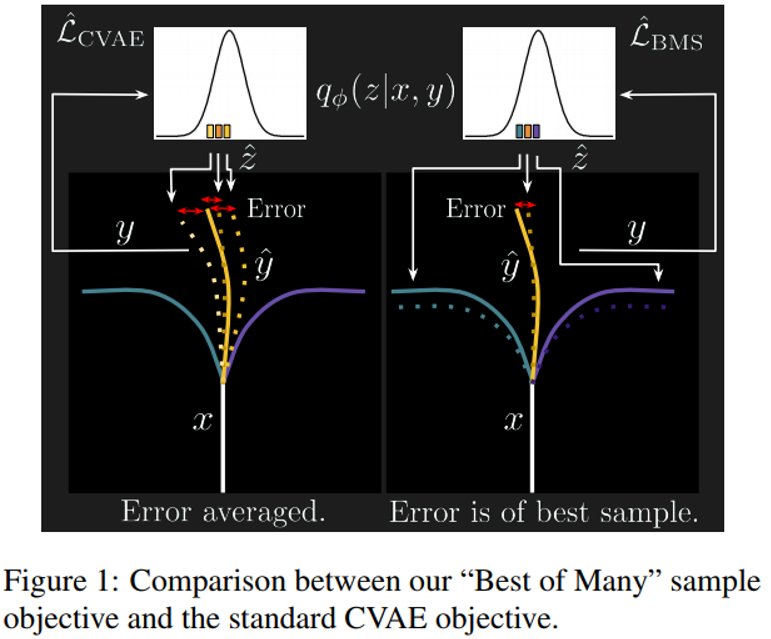
実験により,交通シーン,天気データなどの3つの多様なタスクにおいて従来手法を越えたことを示した.
シンプルで強力だが新たな考え方を示している.
繰り返し構造・パターンを持つような同じシーンの複数画像の間での,小さいNon-local Variationを修正する手法を提案する.
異なる視点,異なる照明条件で撮影された画像間の一貫性を保つように修正を行うのがポイント.独立にやってしまうと,繰り返し構造を持っている場合,一貫性が壊れ,幾何学的構造が歪むことを示す.
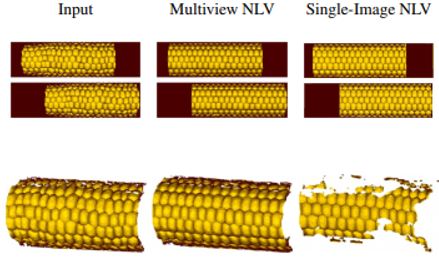
少しニッチだが,注目されていなかったところで発生する問題を報告し,更に解決策を正しく与えている.
RANSACのバリアントに,一番よく見えるモデルが見つかった時に局所最適化でリファインするLO-RANSACがあるが, この局所最適化の部分を2クラス分類の雄であるGraph-Cutに代替した. 従来法における,ただ最小二乗で局所最適化するより局所最適化の評価回数がかなり少なくなる(理論的にはlog(サンプル+検証の数))ようになっており,その結果,CPUでミリ秒単位で動く高速性がある. 実際には,空間的コヒーレンスが効いて理論値より評価回数が更に少ない模様.
ユーザ定義パラメータは少なく,連結とみなす距離r,局所最適化適用しきい値ε_confを決めればよい.これらは学習可能である.
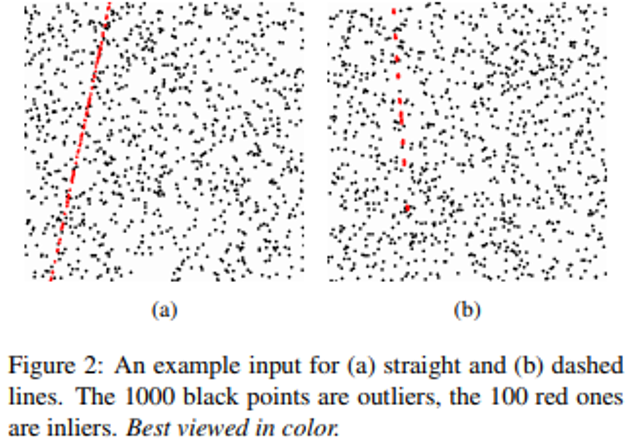
特徴として,1.インライヤ・アウトライヤが空間的コヒーレント,2.パラメータは直感的かつ学習可能,4.計算効率がよい,3.収束性がよい.
タイムリミットを置いて比較したとき,ノイジーなデータにおいての正解数が他のLO-RANSAC系手法より優れていることを示した.
シンプルで強力な手法に感じたので熟読したが,重複表現が多かったり誤植があったりして読解性が低く感じた.900本強あるCVPR論文の中, 時間を浪費するのでポスターといえど論文としてのクオリティは最低限維持してほしいと 完全読破チャレンジャーとしては思う.
MPEG-4やH.264のようなコーデックによって圧縮された映像を直接入力として行動認識を行う論文。背景として、映像には時間方向の冗長性が多く含まれており、その事実はコーデックによって大幅に圧縮できることが挙げられる。圧縮された状態に含まれるmotion vectorとresidualを直接入力とするネットワークCoViARによって、高速かつ高精度な行動認識に成功した。
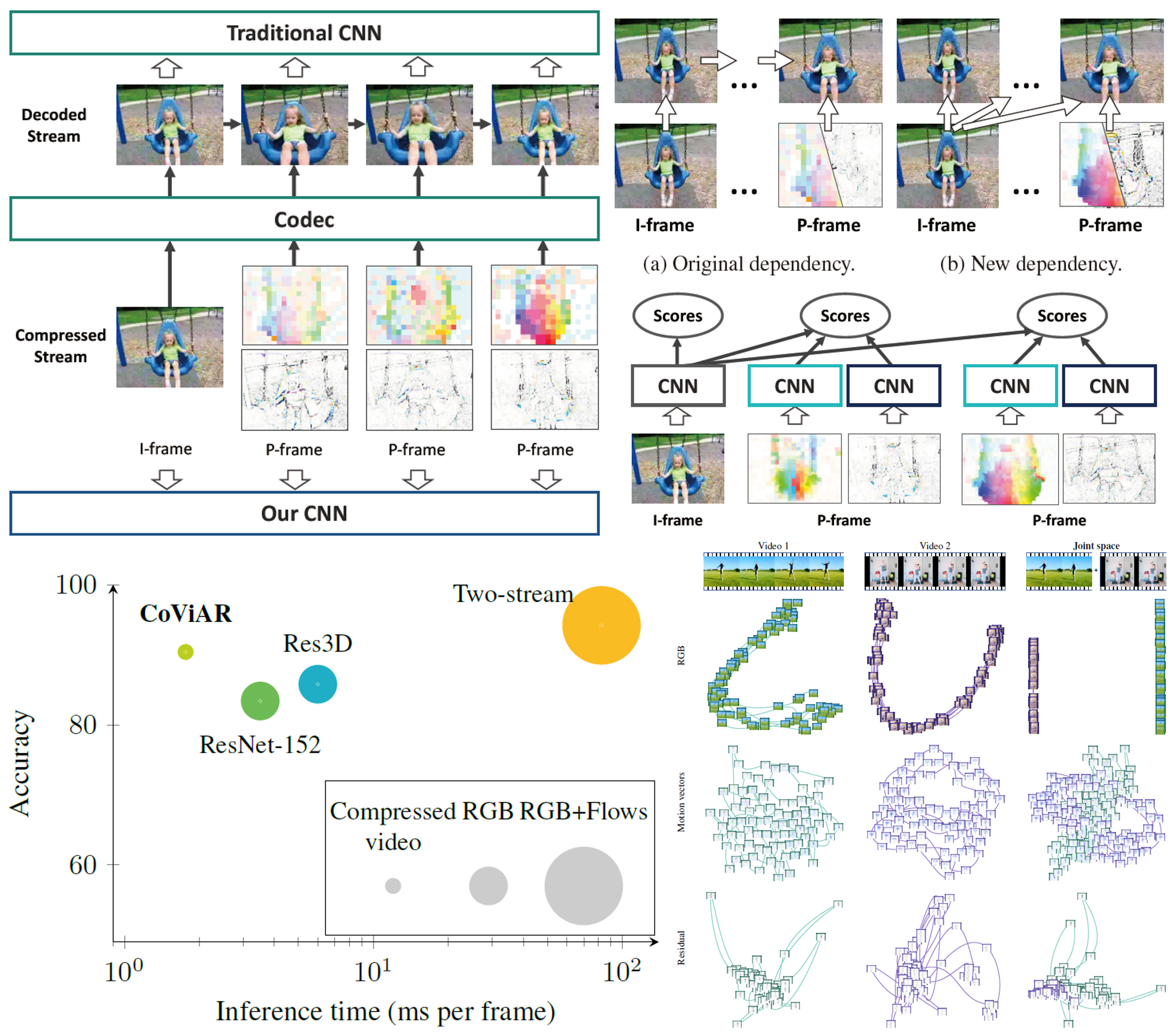
提案手法の入力として、初期フレームにおいてはRGBの情報を持っており、後続するフレームには初期フレームに対するmotion vectorとresidualを持っている。通常のコーデックでは1つ前のフレームに対するmotion vectorとresidualが格納されているので、初期フレームから注目フレームまで累積することで、初期フレームと累積したmotion vectorとresidualを用いることで現在フレームを復元することできる。実際に推定する際には、初期フレームにおけるRGBから得られた特徴量と、各フレームのmotion vectorとresidualから得られた特徴量を統合して、各フレームの行動認識スコアを出力する。異なる動画間の入力ドメインでの分布を見ると、motion vectorとresidualは領域を共有しており、その結果効率的に学習することができる。
2次元画像から3次元形状を復元する論文。DNNを使って3次元形状を推定する手法は、voxelを直接出力するようになっており、GPUのメモリ容量の制限から高解像度な3次元形状を復元することができなかった。本論文では、メモリ効率を良くするため、特定の方向へ延びるtubeが各ピクセルに対応する二次元表現voxel tubeを出力するshape layerを提案した。またネスト構造を持たせたshape layerを適用することで、自己遮蔽領域への対応したネットワークMatryoshka Networkを提案した。
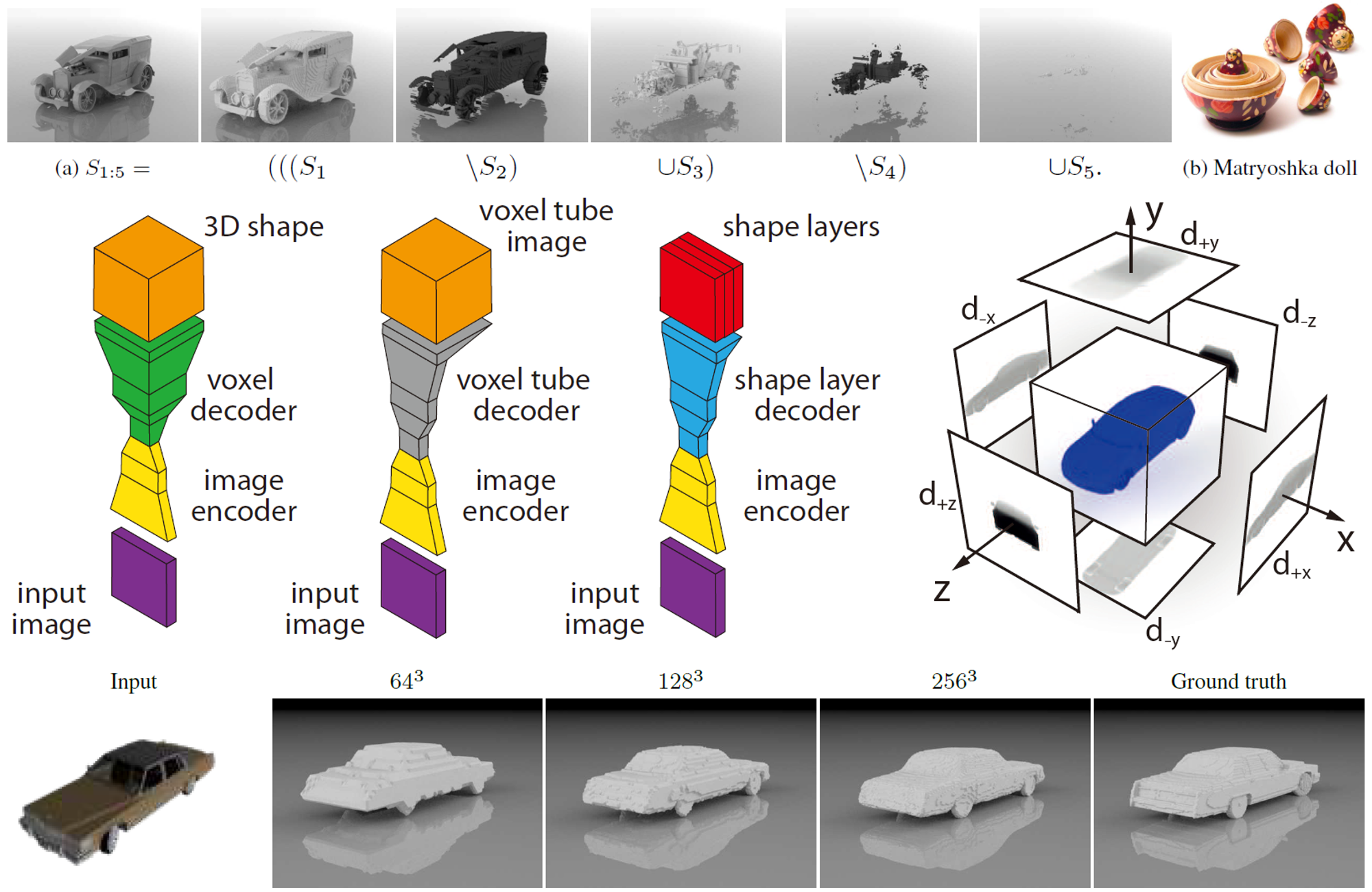
shape layerは6軸方向から見た深度画像を出力し、各軸に対応する2つの深度画像に挟まれた領域の共有部分を出力する。この場合、すべての軸から見ても遮蔽されている領域を復元することができないため、マトリョーシカのようなネスト構造を持つshape layerを出力するMatryoshka Networkを提案し、このネットワークは集合の差と和集合を交互に繰り返すネスト構造を持つ。
3D Hand Pose Estimationのサーベイ的論文。主に以下の2つの点に主眼を置いている。
Hands In the Million Challenge (HIM2017)のトップ10の最新手法に関して、3つのタスク(単一画像からの姿勢推定、3次元トラッキング、物体とインタラクション中の姿勢推定)において調査を行った。
DNNによる手法が混濁する中で、業界を整理するサーベイ的論文が評価されている(?)。最終的に、3D Hand Pose Estimationの現状において以下の7点の洞察を得た。
画像分野では画像理解のために、画像を高次元の特徴ベクトルにして処理を行うことで大きな成功を収めてきた。しかしながら画像のクラスタリングは現在も非常に難しいタスクである。その理由として挙げられることは、クラス内分散がクラス間分散より大きいため、大部分が重複した分布を持っている点である。本論文では、高次元特徴量の場合、ほぼすべてのサンプルがある位置を中心に特定の半径の領域(hyper-shell)に分布することに着目し、新たなクラスタリング手法であるDistribution-Cluteringを提案した。これにより、従来のクラスタリング手法より良いクラスタリングが可能になった。
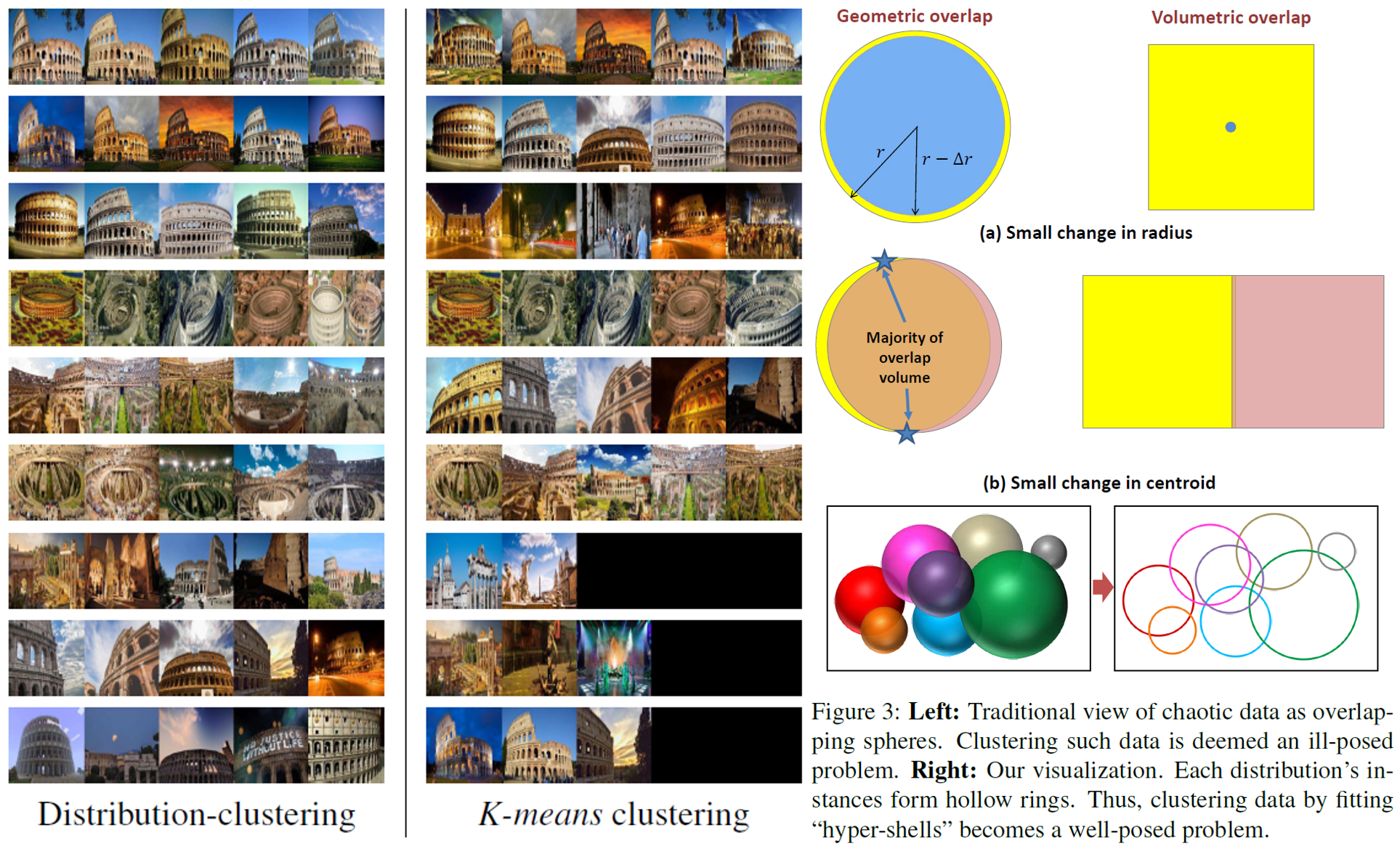
高次元の球の体積がほとんど外側に集中していることはよく知られている事実であるが、それを掘り起こしてきて、クラスタリングに生かし、CVPRに通すところがすごい。具体的な手法の部分は正直なところ理解できなかったが、数学的にも妥当なクラスタリングができているようである。
本論文では、DNNで単一画像から反射成分と透過成分を分離するタスクを解いている。入力画像Iを反射成分Rと透過成分Tに分離する問題は本来ill-posedな問題であり、従来は様々な前提知識を利用してこの問題を解いていた。近年ではDNNが利用され始めているが、最新の手法であるCEILNetでは低レベルなセマンティクスのみを考慮しているため、十分な精度が出ていなかった。そこで提案手法は高レベルなセマンティクスを考慮することで非常に高品質な分離が可能となった。DNNを学習するにあたって、データセットを構築し、またSoTAの精度を実現した。

提案手法におけるネットワークの損失はFeature Loss、Adversarial Loss、Exclusion Lossの3つからなる。Feature Lossは提案ネットワークによって分離した画像と正解画像を深い部分における特徴量の差であり、Adversarial LossはCGANを適用しておいリアルな分離を実現するように学習し、Exclusion Lossは基本的に透過部と反射部は1つのエッジを共有しないという観察を元に勾配空間で透過部と反射部をよりはっきりと分けるように学習する。これらの損失を組み合わせたEnd-to-Endのネットワークを用いることでSoTAを実現した。
Person Re-identificationにattentionを利用したAttention-Aware Compositional Network(AACN)を提案した。体の部位のocculusionや背景の影響を軽減するために、体のどの部分に注目すればいいかを考慮することで精度の向上を計る。 AACNは、Attentionを得るPose-guided Part Attention(PPA)と特徴を得るAttention-aware Feature Composition(AFC)の2つにより構築される。 PPAは、入力画像からnon-rigid part(腕など)、rigid part(頭など)、key pointの3つの観点からattentionを推定する。 AFCは、PPAにより得られたattentionを考慮した対象人物の特徴量を抽出する。
従来の姿勢情報を用いた手法は注目領域に背景などを含んでしまったのに対し、より詳細なattentionを得ることを可能とした。これにより、従来手法と比べあらゆるPerson Re-identificationのデータセットにおいて精度の向上を確認した。
弱教師あり学習に畳み込み層のレスポンスを使ってセグメンテーションを行う手法であるPeak Response Map(PRM)を提案.手法としては,Class Response Mapという各クラスの特徴マップ(Class Activation Mappingのクラス数枚の特徴マップと同意?)からピークを算出し,そのピーク周辺の勾配を各特徴マップから抽出する事でPeak Response Mapを求める. そして,このピーク等を用いる事でセグメンテーションを行う.Pascal VOCとCOCOにおいて高い性能を達成している.
特徴マップにおける特定のピークと勾配情報を用いる事で,セグメンテーションを可能にしている.また,弱教師あり学習(セグメンテーションラベルなし)によりセマンティックとインスタンスセグメンテーションをラベルなしに認識できるため,評価が高い.
Depthマップから手の3次元key pointを検出する手法を提案した。従来手法はdepthマップを2次元画像として扱っているため、2次元への射影時にdistorionが生じる、2次元から3次元への推定は非線形 mappingであるという問題があった。 そこで3次元のボクセルデータから、各ボクセルが3次元のkey pointである確率を推定するV2V-PoseNetを提案した。 2次元のDepthマップをボクセル化することで、V2V-PoseNetによってkey pointを推定する。
直接key pointの座標を求める手法と比べ、ボクセル毎の確立を求めることで精度が向上した。具体的には、正解値との誤差、mAPの2つの尺度において従来手法よりも数値的に向上したことを確認した。
部分的に2Dアノテーションされた複数インスタンスの画像データセットにおいて,3D形状,カメラ姿勢,物体,変形のタイプのクラスタリングを同時に行う. また,不明瞭(indistinctly)に剛体・非剛体カテゴリ分類を行う. これは,クラスタが事前知識であるような既存手法の拡張となる.
物体変形のモデリングを行う.小さい領域の動きを,複雑な変形へと橋渡しできるように, サブスペーススの複数ユニオンに基づく定式化を行う. このモデルのパラメータは拡張ラグランジュマルチプライヤーで学習する. 完全に教師無しで行え,学習データが不要である.
剛体,非剛体カテゴリ,小さい・大きい変形を含む合成データ,実データセットで検証し,3D復元においてSoTA.
弱教師付き動画学習に,ビタビ復号を組み込んでみた話.タスクはアクションセグメンテーション. 用意するのは動画とそのアクションラベルだけ.
動画がネットワークに入力され,その出力された確率分布に対しビタビ復号を実行する.すると,フレームラベルがビタビ復号で生成される.そして,勾配計算時にフレームワイズのクロスエントロピー計算を行い,逆伝播する.
明示的なコンテキスト・長さのモデリングが,これがビデオセグメンテーション・ラベリングタスクの改善に大きく作用することも示す.
アクションセグメンテーションでSoTA.
人物再同定の話.人の領域で丁寧にバウンディングボックスを切ったとしても,やはり背景は映り込んでいて,背景バイアスは免れない. この事実を,以前作成した人領域をピクセルレベルでセグメンテーションして作ったデータセットで検証した.
そして,背景バイアス問題を解決すべく,3つのパーツに分ける人パージングマップに基づき,人領域をガイドとしたプーリングを行うDNNを構成.
また,人画像とランダム背景を合成するという,トレーニングデータのオーギュメンテーション手法も提案.背景画像は監視カメラ映像のフレームから100枚選び,対象の人画像と同じ大きさの背景画像をランダムにオンラインでクロップし,人画像とマージ.
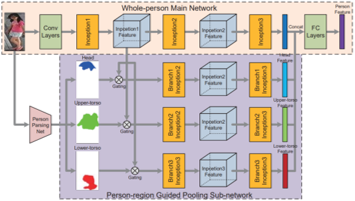
背景バイアスに関する調査と,それを低減できる人物再同定DNNの提案.
人領域を自分たちで色塗りしたデータセットを作る力業ができるSensetime x CUHK.
Action recognition without humanは引用してくれなかった.
顔表情の基本構成であるアクションユニット(AU; Action Unit)を弱教師により敵対的学習する論文である。最初に擬似ラベルによりAUを推定し、敵対的学習の枠組みにより高精度にAUを認識できるようにしていく。敵対的学習はAUの認識を行うRと、AUラベルかどうかを見分けるDから構成される(つまり認識した擬似ラベルが本物のラベルかどうか見間違うように学習を進めていく)。
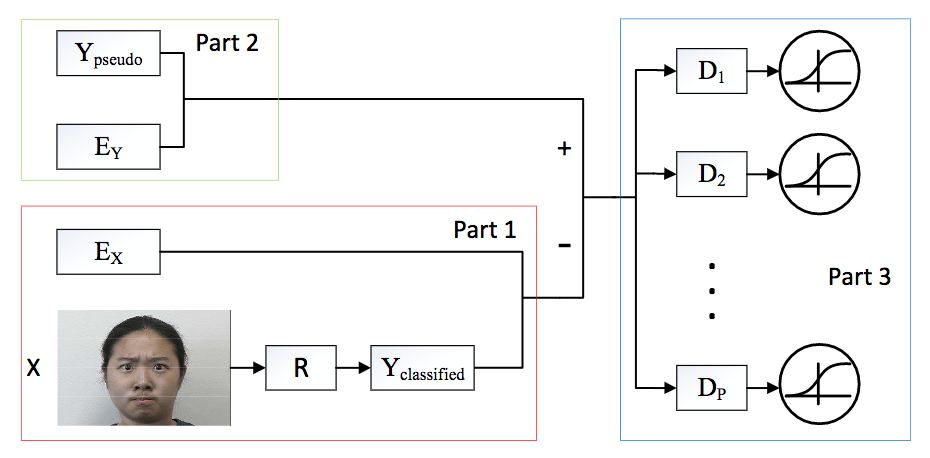
ラベルづけが困難なタスクである顔表情のアクションユニットに対して効果的なアルゴリズムを提案し、弱教師付き学習ができるようにした。GANの枠組みを改良し、擬似ラベルを正解として十分にするよう学習できたことが大きな貢献である。
擬似ラベルでも使用可能なレベルに持っていく学習はSelf-Supervised Learningでも使われているし、最初は粗いラベルでも徐々に意味のある教師になっていく様子が確認できる。アイディアは世界で同時多発的に思いついて実装が行われるので、思いついたらすぐにやらないといけない。
与えられた人物トラッキングやアピアランス情報から人物/物体間のインタラクション認識(ここではVisibility Fluent Reasoningと呼ばれている)を行う。ここで、通常人物や物体のトラッキングは欠損を含むことが多く、途切れ途切れになっている状態からでも認識ができるようにCausal And-Or Graph(C-AOG)を適用して対応関係を学ぶようにする。
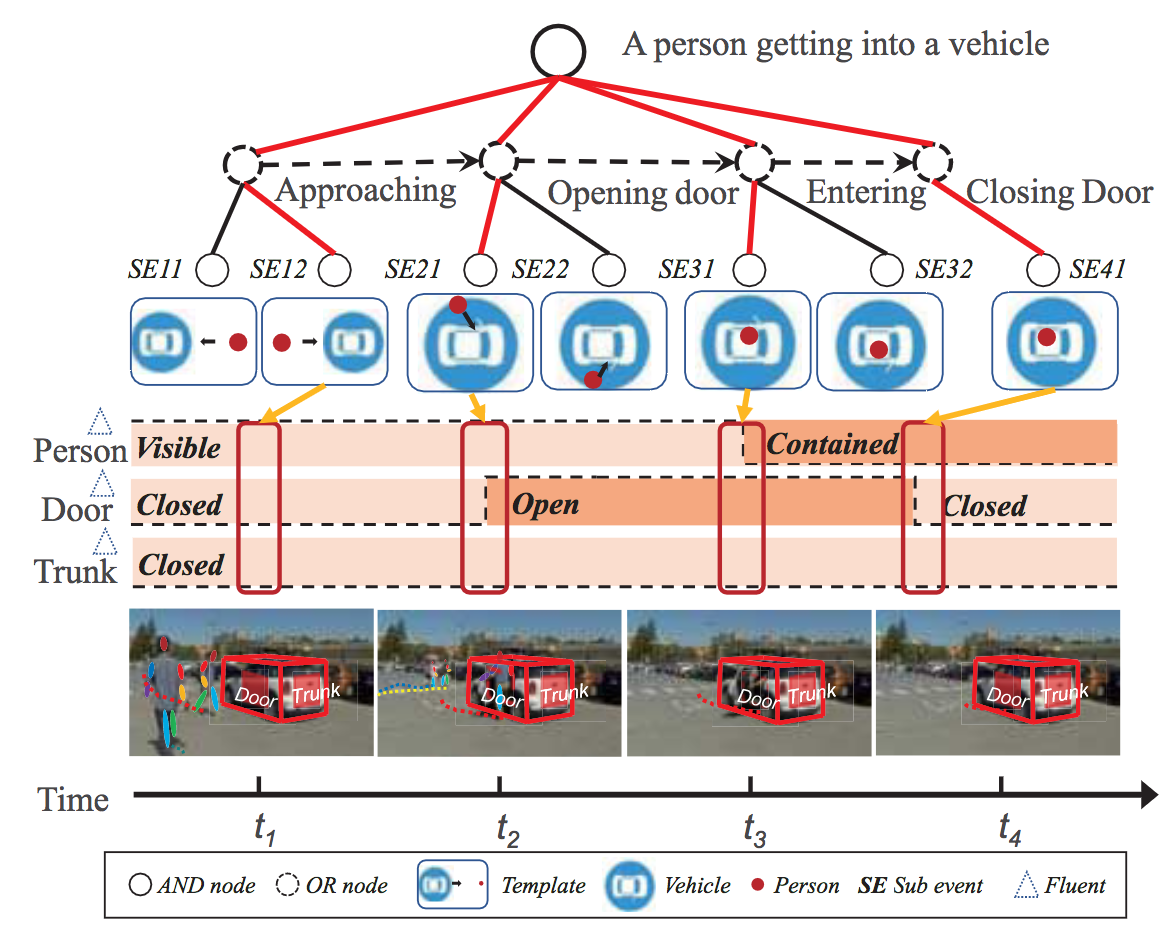
C-AOGを用いて時間軸に伴うイベントの変化を理解することに成功、物体トラッキングと変化の理由づけを同時に行なっている。オクルージョン時の対応(トラッキングが一部できなくなっている)が行われたデータセットも公開し、より複雑かつ情報の欠損を含む環境においてもFluent Reasoningができるようにした。
「ビジョンの認識精度は完璧ではない」という前提でより上位のタスクを完結するデータは今後さらに重要!査読に対する理解(完璧でないなら減点するといったことをなくす)も広がってほしい。
顔表情認識を行うために、De-expression(Happy=>Neutralのように顔表情を打ち消す)を学習することにより特徴表現能力を向上させる。De-expression Residue Learning(DeRL)とよばれる、生成的/識別的な誤差計算を同時に学習可能な枠組みを提案(右図)。DeRLではまずConditional GANによりある表情の顔を無表情の顔に生成するモデルを構築。従来ではピクセルレベル/特徴レベルの違いを見分けていたが、本論文では生成モデルにおける中間層レベルの違いを見分けることにより高精度な表情認識モデルが出来上がる。このうち、Encoder/Decorderの2,3,4,5層、最終識別結果においても誤差を計算。
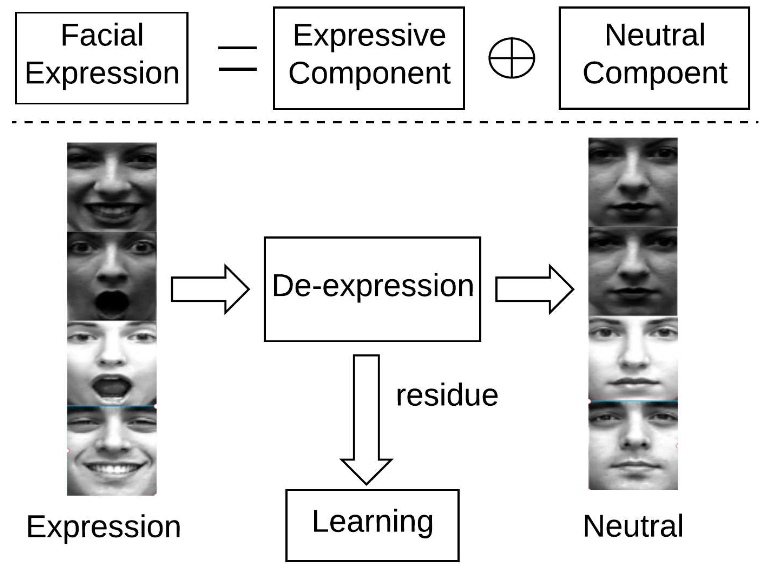
顔表情認識に関して、表情を打ち消すための識別/生成的モデルから誤差を計算するDe-expression Residue Learning(DeRL)により学習を行なった。BU-4DFE/BP4D-spontaneousと2つのデータセットにより事前学習を行い、CK+/Oulu-CASIA/MMI/BU-3DFE/BP4D+にてテストを行なった結果、従来法を超える顔表情認識精度を達成した。
児童心理ケアのシーンにおいて3D次元姿勢推定、行動認識、感情推定を実施した。長期の動画撮影、多様な行動、部分的にしか身体が映っていない、児童の年齢が異なる、などの課題があるが、このような環境にて上記タスクを行なった。詳細行動/感情認識(fine-grained action, emotion recognition)を行うために3,700動画を撮影(各動画は10-15分の長さを保有)、37人の児童から19の頻出行動を分類。
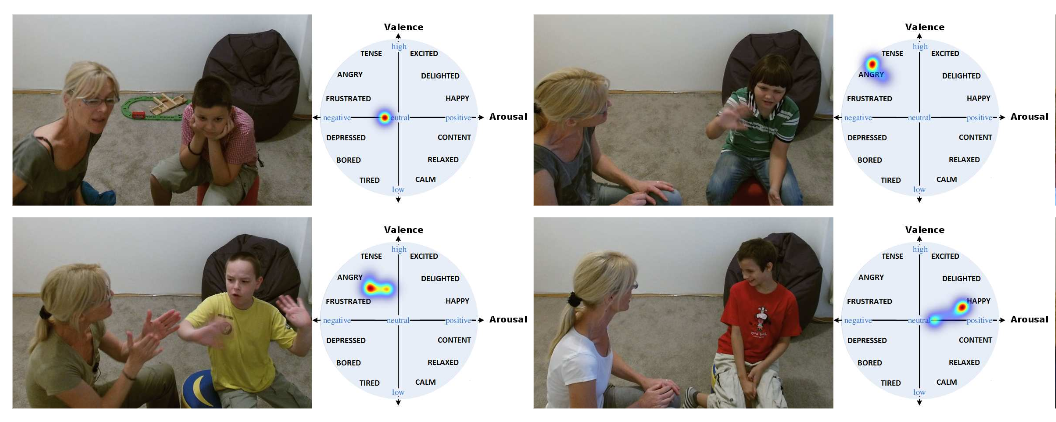
提案手法は姿勢推定においてKinectとcompetitiveな精度を実現するとともに、行動認識や感情推定では良好な精度を実現、Child-Robot Interactionに関する新しいタスクを定義した。
Deep Multi-task Neural Networksにより複数人物の3次元姿勢+形状を推定する。直接的に画像のアピアランスから人物姿勢を推定するのみならず、環境の拘束条件や推定された関節情報からコンセンサスを取るように文脈を把握しながら(2次元や)3次元の姿勢+形状を決定していく。ビデオに拡張することも可能で、さらに自然環境下における高精度な人物姿勢推定も実行した。右図は処理フローを示す。初期段階では単一人物の姿勢推定と推定結果のフィードバックを行い、次に複数人物同時最適化を行い、最終的な複数人物の3次元姿勢とその形状を取得する。
高精度に複数人物の3次元姿勢を推定するとともにその形状も復元可能にした点が貢献点である。さらに、モデルにおいても単一人物/複数人物/環境に関する拘束条件など文脈を把握することにより3次元姿勢や形状を推定した点にも新規性が認められた。
テキストからの画像生成において、テキストから画像への写像を直接学習するのではなく、layout generatorよりtextから中間表現としてsemantic layoutを生成するステップと、image generatorによりそれを画像へ変換するステップに分解して画像を生成する枠組みを提案。
意味のある画像をsemantic layoutに基づき生成する点だけでなく、生成画像のアノテーションも自動で行われている点と生成されたsemantic layoutを修正することによるユーザーがコントロールできる生成も可能にしている点が新しく有用である。StackGANのような鳥や花といった特定対象ではなく、より複雑な一般シーンを想定し、Fine-grained semantic layoutが必要であるという問題設定が良い。
評価の際に、生成された画像のcaptionを生成し、元の文章との類似度を比較しており、納得できる生成モデルの評価をしていた。StackGANでは行われていなかった気がするが、こういった評価は普通?また画像生成等の中間表現としてSemantic layoutを利用する研究が増えてきた。それゆえ物体の形状とインスタンス情報(この研究で言うところのBox generatorとshape generator)をよりスマートに取得または統合できればと感じる。
自然言語に基づいてsegmentationするタスク(referring image segmentation)においてmulti-scaleなsemantic情報を取得するRecurrent Refinement Network(RRN)を提案。これは入力にPyramid特徴からの得られる情報を適応的に組み込み、segmentation maskを洗練する。実験では、ReferIt、UNC、UNC+、G-RefのデータセットでベースラインとSoTAより性能が優れていることを確認。
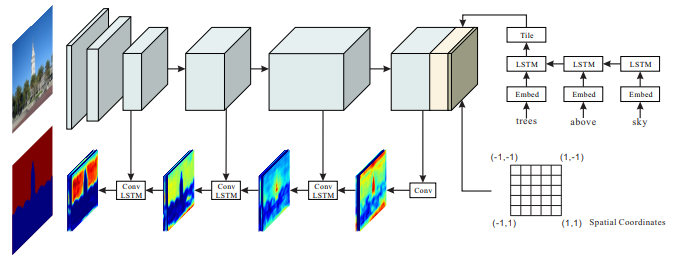
Referring image segementationへmulti-scaleなsemantic情報を含むpyramid特徴を適用し、単純に利用するのではなく、ConvLSTMにより洗練化している点が新しい。そして4つのデータセットでSoTAの性能を達成。包括的な実験により、RRNの有効性を示している。
自動走行のシーンで現れる物体はスケールの変動が大きく、multi-scaleな情報を適切にEncodeする必要がある。multi-scaleなsemantic情報を抽出するために、複数rateのAtrous ConvolutionによるAtrous Spatial Pyramid Pooling(ASPP)が提案されているが、このような自動走行のシーンではまだ十分ではない。そこで、よりスケールの変動に対応するために、Densely connected Atrous Spatial Pyramid Pooling(DenseASPP)を提案。
ASPPのように、Dilation rateを上げると画素のsampling間隔が広がる。これは大きいストライドのconvolutionのようなもので、大きなrateのatrous convolutionは受容野を広げるが、その分情報の欠落が起こる(低密度化)。この問題を解決すべくStackしかつ密な結合をしたDenseASPPにより高密度化し、異なるdilation rateのlayerの多様なアンサンブルを可能とすることで、ASPPよりも多くのスケールを持つ特徴マップを効果的に得ることができる。これが新しい。
この論文ではcityscapeライクなcoarseラベルでの性能を人工データを使って、Semantic Segmentationでのラベルの品質とCNNの性能との関係を調査した研究。これにより、人間の労力を最小化しつつ、coarseラベルを作るべき時間を提案することができる。ラベル品質とあるが、domain adaptation等の手法によるラベル生成の品質検証というわけではなく、人間の労力は前提で、その上でのcoarseラベルの品質と性能を検証している。
結果から、CNNの性能は人間のアノテーションコストに依存することがわかった。これつまり、大きなcoarseアノテーションデータセットは、小さなfineアノテーションデータセットの性能と同等で、coarseラベルでpretrainし、少ないfineアノテーションデータセットでfine-tuneした場合、大きなfineデータセットで学習した性能に匹敵またはそれ以上の性能を得ることができる可能性があることを示している。また様々なネットワーク構造や都市の様々なオブジェクトに対しても有効であることを証明。
ここではcoarseラベルを対象としていたが、ミスラベルの場合は?、汎化との関係は?、stuffクラスは?と異なる対象でさらなる検証がほしいと思わせる研究。これらについて検証した研究がもうすでにあったりする?
360°カメラの動画を用いたビデオ要約を,Memory NetworkをベースとしたPast-Future Memory Networkにより実現した研究.はじめに,入力の360°の動画から81個の領域(normal field of view)を,RankNetベースの手法を用いて切り出す. 候補領域は,MemoryNetのMemoryへと記憶される. PFMNでは,これらの候補領域を過去と将来という形でMemoryに記憶しており,時刻tで最もスコアが高い記憶が過去のMemoryに残される. 印象の強い候補領域を残しつつMemoryをアップデートしていくことで,高性能なビデオ要約が可能となる.
この手法では,対象を360°カメラの動画としており,広大な情報量から効率的に印象的なシーンをMemory Networkを活用することで,高性能な成果を出している.Memory Networkをこのような問題設定に応用した事例はこの手法が初めてであり,この点が高い新規性となっている. また,このタスクを評価する指標として,新たなデータセット360◦ video summarization datasetを提案している.
強化学習を使い,推論時のResNetの不必要な層(ブロック)を取り除いて計算コストを削減するBlockDropを提案.この研究では,ResNetが特定の層を取り除いた際に性能があまり低下しない能力を利用しており,どのブロックを落とせるかをPolicy Networkにより判定させている. 報酬の設計では,画像認識時により少ないブロックで認識が成功できるほど報酬が高くなるように設計されている. BlockDropにより,ImageNetにおいてtop-1の性能を76%を保ちつつ,平均で20%の高速化(一部では36%高速化)を実現している.
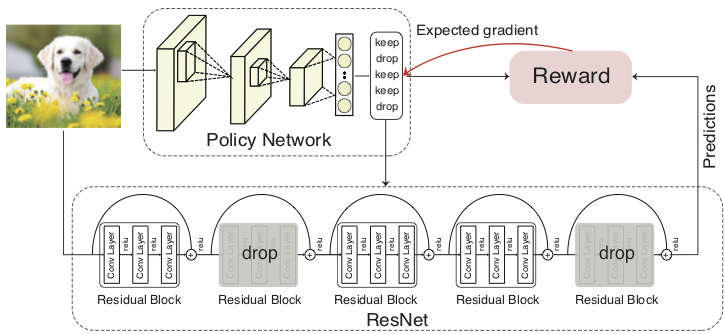
推論時のネットワーク構造を強化学習により最適化させる手法.強化学習によりネットワーク構造を削減する手法はあまり提案されていないため,新規性が高く評価されたと思われる. また,BlockDropでは速度を改善するだけでなく,場合によっては若干性能を向上させる事が可能である事を示している(CIFAR, ImageNetで検証).
DenseNetをベースにコンパクトなネットワークを構築するCondenseNetを提案.このCondenseNetは,学習中は更新回数が増えるに連れて畳み込む特徴マップを減らしていく. そして,推論時は疎になった畳み込み層の特徴マップを入れ替え,Group Convolutionする. これにより,畳み込みに対する処理時間を大幅に削減する事が可能であり,推定時の計算コストを大幅に削減する事ができる.
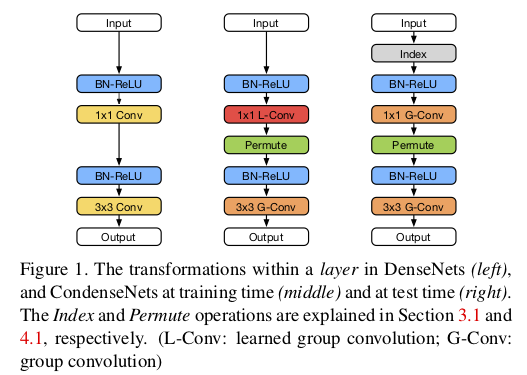
コンパクトなネットワークを構築するために,学習では畳み込みをスパースにする処理を導入し,推論時には特定の特徴マップを畳み込むようにGroup Convolutionを導入している.このような畳み込みの最適化方法は提案されていないため,新規性として高い. また,DenseNetの構造も改良しており,複数種類のプーリングを使用する等の改良も導入している. 同会議で提案されているShuffleNetよりコンパクトにする事ができる.
360°カメラの動画から弱教師あり学習でSailency mapを効率的に求める方法を提案.方法として,360°のシーンを6つのパネルに分割し,チャンネル方向に結合する事で,ネットワークに入力する. ここで,シーンをパネルに分割する際にCube Paddingという方法を提案しており,特定パネルの周囲のパネルの一部を,その特定パネルの両端に結合させる. これにより,パネル間の関連性をネットワークに学習させる事が可能である. また,360°シーンのデータセットを新たに提案している.
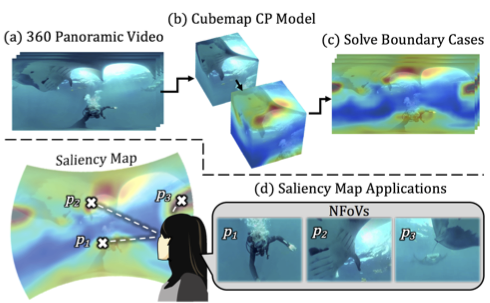
提案しているCube Paddingという広大なシーンに特化した入力方法は,解像度が高い場合においても処理速度の低下を抑制する事が可能である.また,パネルを分割する際にCube Paddingを導入する事で,パネル間の境界に対してロバストにする事ができる. 今回のタスクに対して新しいデータセット”Wide-360° Dataset”を提案している点も,評価が高い.
マルチモーダルに任意の領域を高精度にローカライズする研究.この研究では画像 & テキストを対象としており,右図のように入力されたテキストに適合した領域をヒートマップで推定している. 画像特徴とテキスト特徴を同一空間に落とし込んでネットワークを学習する. そして,認識時にテキストの特徴ベクトルと画像の特徴マップを使ってヒートマップを出力する.

方法としては,画像と単語からResNetとRNNを用いて特徴マップ / 特徴ベクトルを抽出し,同一特徴空間にembeddingさせる.学習では,画像とテキストの特徴からTriplet Ranking Lossを用いて学習させる. ヒートマップは,画像の特徴マップと文章の特徴ベクトルの掛け合わせから求めることができる. このローカライゼーションは,非常に高い性能を達成している.また,Zero-shot Learningにも応用できる.
VQAの質問と画像、答えそれぞれを表現するembeddingを学習する手法を提案。従来のVQAは、任意の文章を答えとして出すものと用意された選択肢の中から選択するものの2種類に分けることができる。 前者は答えが合っているか否かは主観的なものである、後者は選択肢に含まれない答えを出力できない、runningとjoggingのように似ている単語の区別が難しいといった問題がある。 そこで質問と画像のペア、答えそれぞれを表現するベクトルを学習することで答え同士の類似度の定義や未知の答えへの対応を可能にする。 具体的には、それぞれのベクトルを用いた確率モデルを構築し、最尤推定を行う。
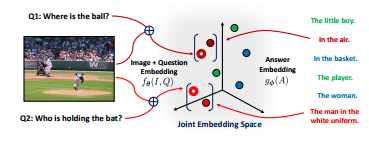
従来手法では学習の際に設定した答えのみしか出力できず、異なるデータセットに適用することが不可能であったが、提案手法により異なるデータセットなどデータセットに含まれていない答えにも適用可能となった。
画像のシーンコンテキストと,物体の関係の2種類のコンテキストを用いて物体検出を行うアルゴリズムを提案.物体検出をグラフ構造の推論問題として扱い,物体をノード,物体間の関係をエッジとしてモデル化する.これを実現するために,Faster R-CNNのような物体検出フレームワークに組み込む構造推論ネットワーク(Structure Inference Network;SIN)を設計した.SINは,特徴マップとしてプールされたRoIをノードとしてFC層にマッピングする.同様に画像全体の特徴をシーンとして抽出し,RoIを連結してエッジとする.グラフは反復的に更新され,最終状態は物体クラス予測の精度向上に貢献する.
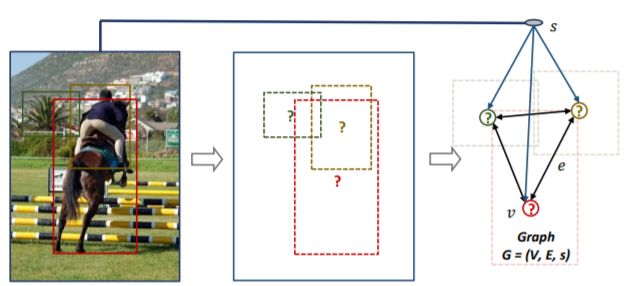
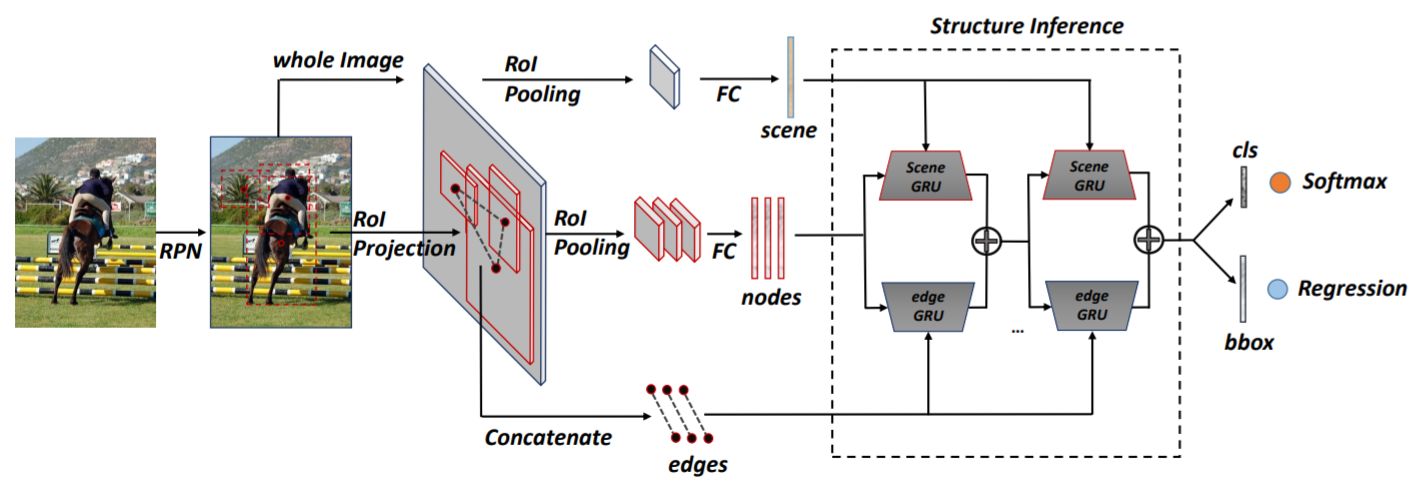
物体検出の精度向上のためにコンテキスト(周辺環境,物体の位置関係など)の理解が重要となる.コンテキストをグラフ構造で表して推論する斬新な手法である.VOCとCOCOで評価を行い,一部のクラスはFaster R-CNNよりも高性能であり,全体では76.0mAP(VOC07),73.1mAP(VOC12)とFaster R-CNN(73.2,70.4)よりも高性能であることを示した.
グラフ構造で物体検出を扱うものはいくつかあるが,エッジの情報と周辺環境のコンテキストも考慮したものは新しい.コンテキストを考慮した物体検出は,未知の物体を検出するためにも重要な要素となり得る?
DCNNを用いてdepth画像を推定するとき,depthを離散化して順序回帰問題として解くdeep ordinal regression network(DORN)を提案.Depthの離散化にはspacing-increasing discretization(SID)を導入した.SIDを用いてログスケールで離散化することで,遠い領域のdepth画像を粗く,手前の領域のdepth画像を細かく離散化してロスの減少に貢献する.ネットワークの構成は高解像度な特徴抽出部,マルチスケール特徴学習器(ASPP),フル画像エンコーダおよび順序回帰optimizerからなる.計算コストを削減するために,skip connectionではなくシンプルな構成を採用した.
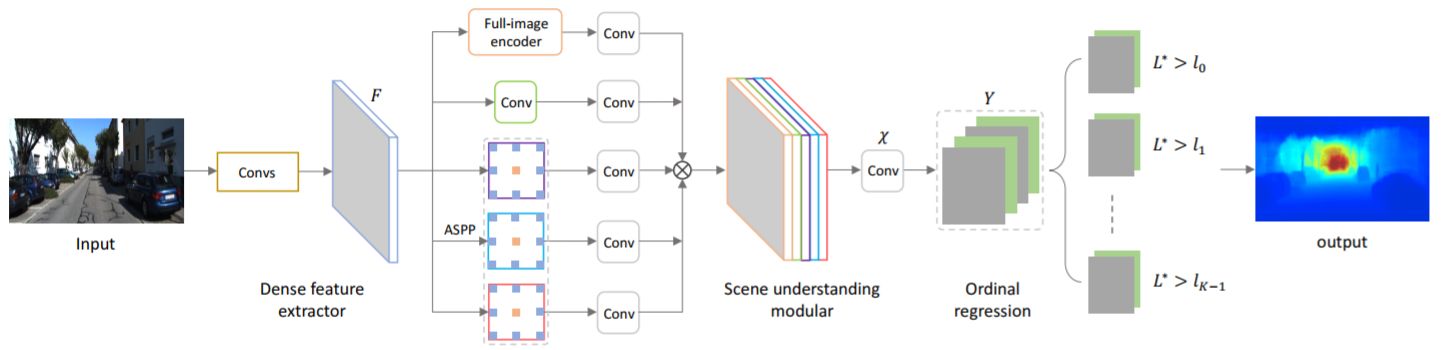
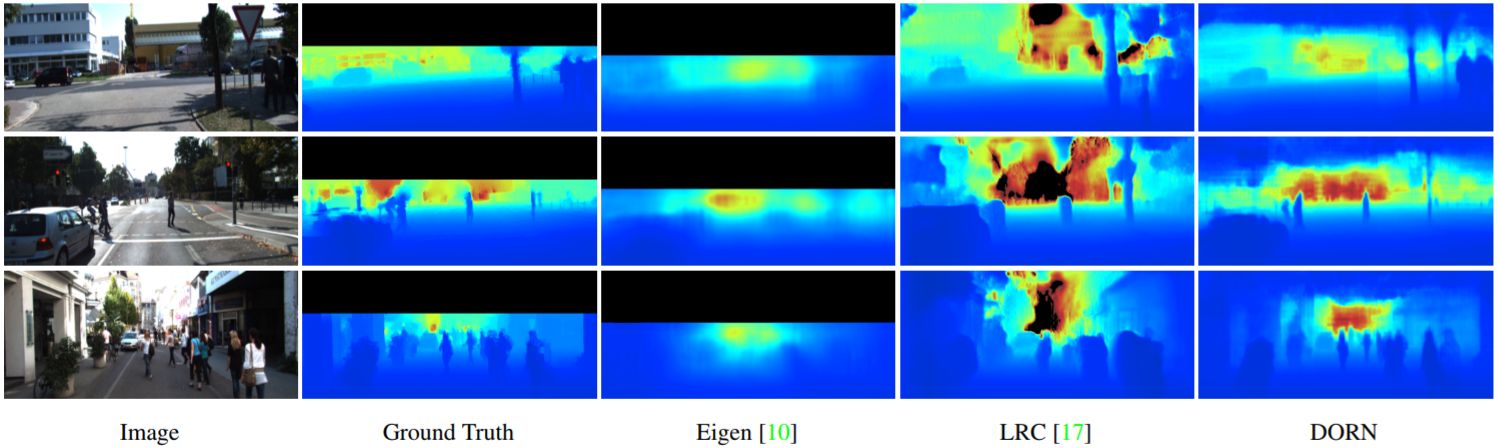
DCNNを用いた高解像度なdepth画像推定は,通常skip connectionや複数のdeconv層が必要だったが,この問題を解決または低減した.KITTI,Make3D,NYU Depth v2などのベンチマークで他の手法を大きく上回りSOTAを達成した.
医療画像処理ではCTやMRIなどの異なった種類のデータが存在する。医療の現場において、CTとMRIはどちらも必要となる場面がある一方で、どちらか一方しかデータが存在しないことも多々発生している。そこで本論文では、CTとMRIという3D画像データ間のドメイン変換を行うタスクに取り組んだ。またCTとMRIのそれぞれからセグメンテーションを行うネットワークも学習させた。
![]()
2D画像におけるImage-to-Image Translationに対応する、医療3D画像におけるVolume-to-Volume Translationに対して以下の点に取り組んだ。
Pruningを最適化問題として定式化し、交互最適化によって解くLC algorithmの提案。定式化としては0をとらないパラメータ数に対して制約を設けて解くConstrain formとそれを罰則項として損失関数に組み込むPenalty formの二つを提案。メジャーなPruning手法であるパラメータのmagnitudeの小さいものをナイーブにzeroingしていくものよりも、良い結果となった。提案する2つのformに関してはConstrain formの方が良かった。
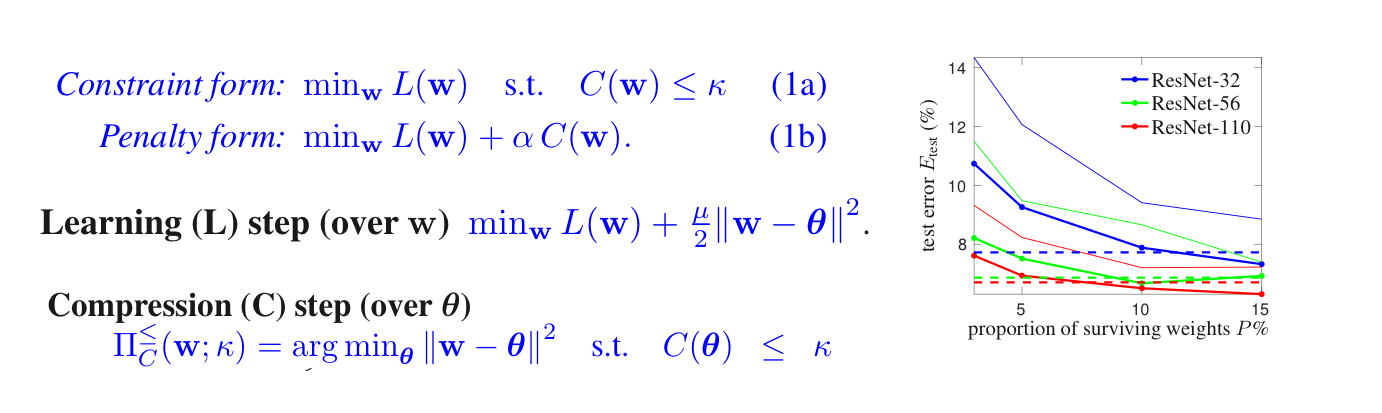
補助パラメータのPruningを行うCompression(C) Stepと本パラメータを補助パラメータに近づけつつ本タスク(識別・回帰など)を学習するLearning Stepからなる。C Stepでは(制約 or 罰則項として) Lp正則をかけながら本パラメータとのMSEを最小化するような補助パラメータを探索する。L Stepでは損失関数における補助パラメータとのMSE項の係数を学習の進行に応じて大きくすることで(μ→∞)、最終的な解がスパースなものに近づく。また、Constrain formでは超パラメータ一つでNN全体において最適化できる。手法の新規性・妥当性が大きく評価されたと考えられる。
magnitudeベースのものは「 magnitude が小さいものは推定への寄与率が低い」という仮定のみでPruningしていくが、この手法ではその仮定をベースにしつつ(C step)、本タスクの性能を担保しながらPruningしていく(L step)点で理にかなっているように思え、面白い。計算効率をモチベーションにされることが多いPruning研究だが、枝刈りの割合によってはLasso回帰のように汎化性能が向上するような地点がないかもきになる。
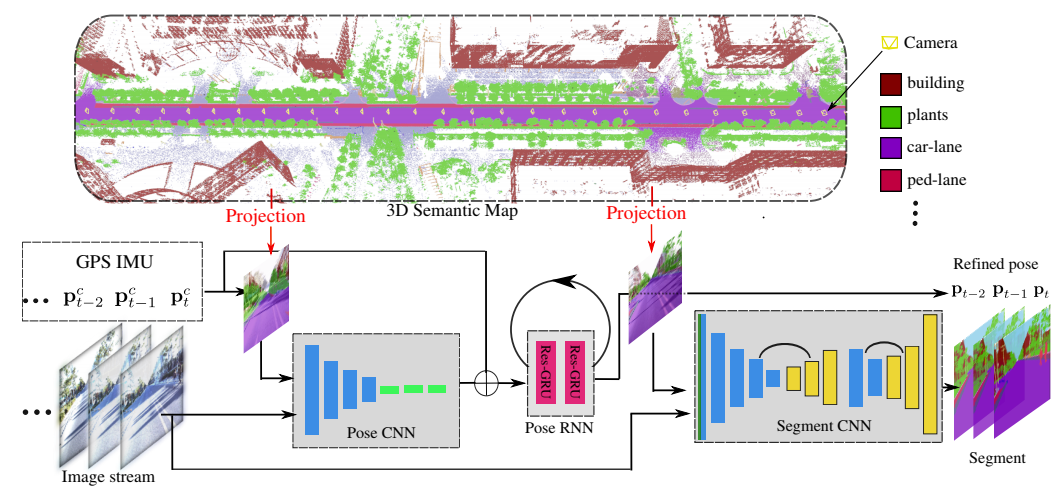
入力に3Dセマンティックマップがあるので,ある意味ではscene parsingに対して提案手法は入力画像を手掛かりにレンダリングされたセマンティックマップをマイナー修正だけ?
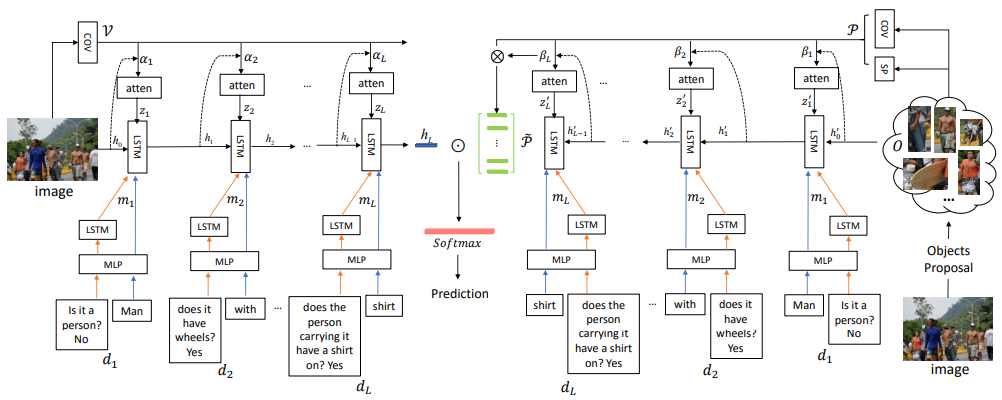
LSTM+attentionもなかなか良さそう
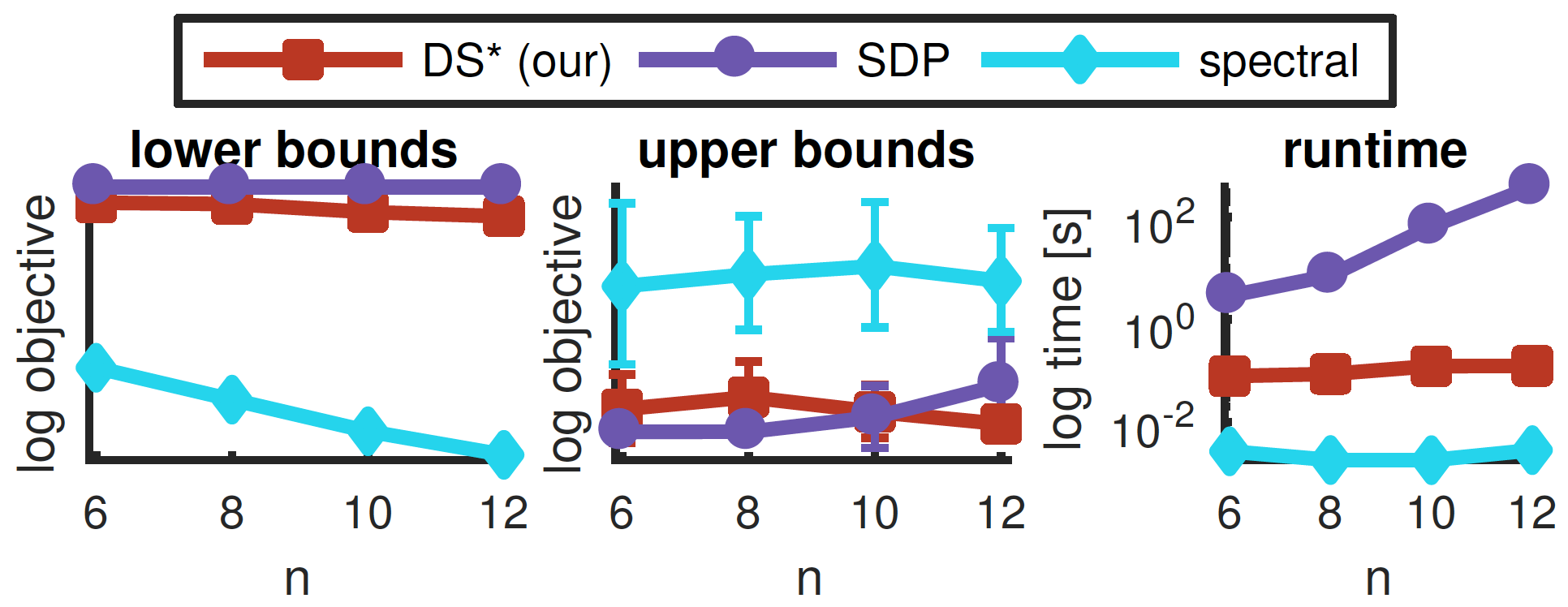
動画像において,土砂降り的なはっきり見えている雨を除去する.高速に動くカメラの動きにも頑健.
スーパーピクセルセグメンテーションをし,デプスを含むユニットに分解.シーンコンテンツの位置合わせをスーパーピクセルレベルで実行する. 雨の線の場所や遮蔽された背景コンテンツに関する情報を抽出し, 雨除去の中間出力を得る. さらに,そこで使った情報を更にCNNの入力特徴として使い, 高周波成分の復元に使う.
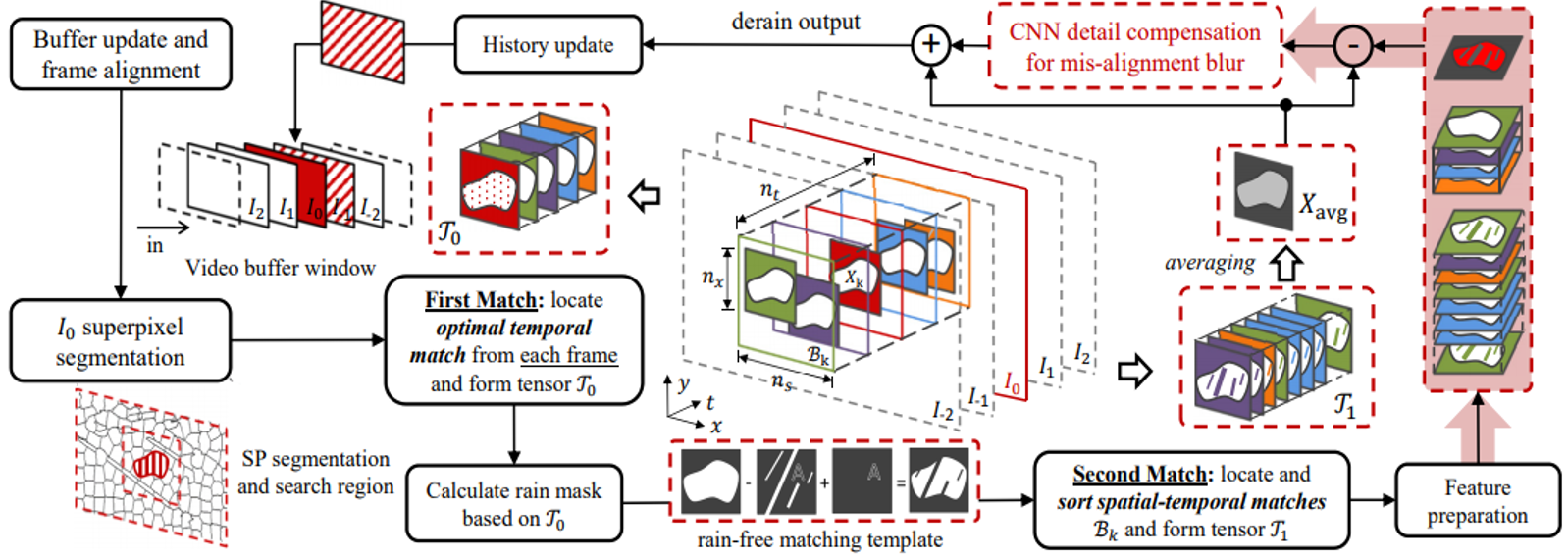
土砂降り雨を合成した車載カメラ画像データに適用し,PSNRが改善,見た目もよくなった.
偏光放射特性のセルフキャリブレーション手法の提案.これまでには,カメラ応答だけ求めるものはあったが, 本研究では,未知のカメラ応答及び未知の偏光角を同時に復元する.
応答が線形とした場合,偏光フィルタを回転すれば偏光強度の変化は正弦波になるはずではる.この事実を使って,統合的に最適化を定式化する.
カメラ応答を偏光情報を使って,放射特性と偏光特性の両方を統合的に最適化するというやり方で,自己キャリブレーションを実現したものは初.
教師なしマイニングの話.ハードポジティブ・ハードネガティブが分別しやすいマニフォールドにおける表現方法を考案. 本手法によれば, 正例たちは一つのマニフォールドに距離が離れて置かれ, 負例たちは複数のマニフォールドに距離が近い形で置かれる. ユークリッド的な近さとマニフォールド的な近さの不一致性によって,両者を分別可能になる.
学習済みネットワークの教師なしファインチューニングや,特定物体検索に適用させてみて,完全・部分教師ありと比較して性能超え.
通常のカメラとは違い,偏光カメラ画像からは,鏡面反射してしまっているようなところでも,物体表面の法線角度が窺い知れたりするので,組み合わせることで良いDense SLAMができるようになると思われる.ところが,偏光情報からの法線角度推定は,特に境界付近でエラーが載りやすい.従来手法では事前にセグメンテーションマスクを生成しており,オフラインアルゴリズムであった.
本研究では,・方位ベースデプス伝播・2視点デプス一貫性チェック・デプス最適化の 反復処理を完全自動化し, 注意深くGPU実装できるように設計, SLAMに組み込んだところでリアルタイムに動くようにした.
通常カメラ+偏光カメラでのSLAMは初.
左右一貫性チェックという,ステレオにおける視差情報を改善する手法がある.従来は,左右でのチェックはそれぞれ独立かつHand-Craftedであった. 本稿では,これを結合的に行えるようなリカレントモデルを提案する.
両眼の視差結果から,オンラインにミスマッチ領域を判別していく.ここで,ソフトアテンション機構を導入する. 学習したエラーマップを使い,次時間の処理において,信用できない領域に選択的に焦点を当てるという方法. これにより,視差結果を反復的に改善していく.
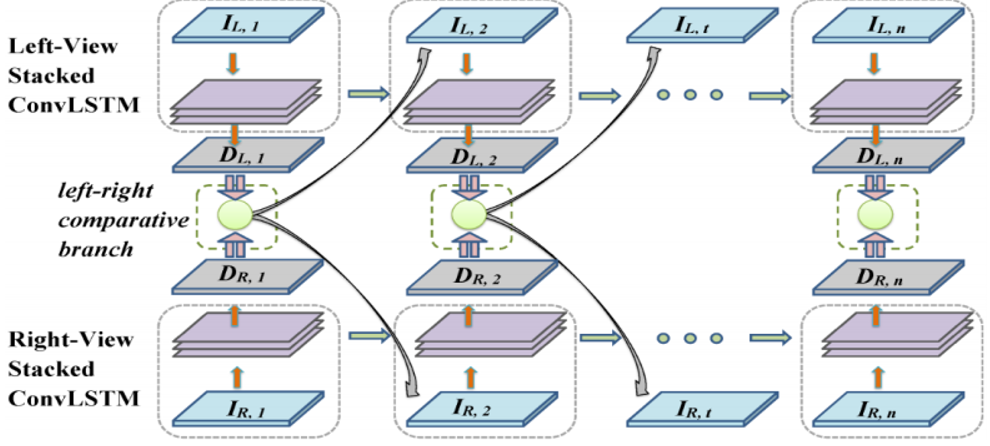
3つのベンチマークでSoTA性能を達成.
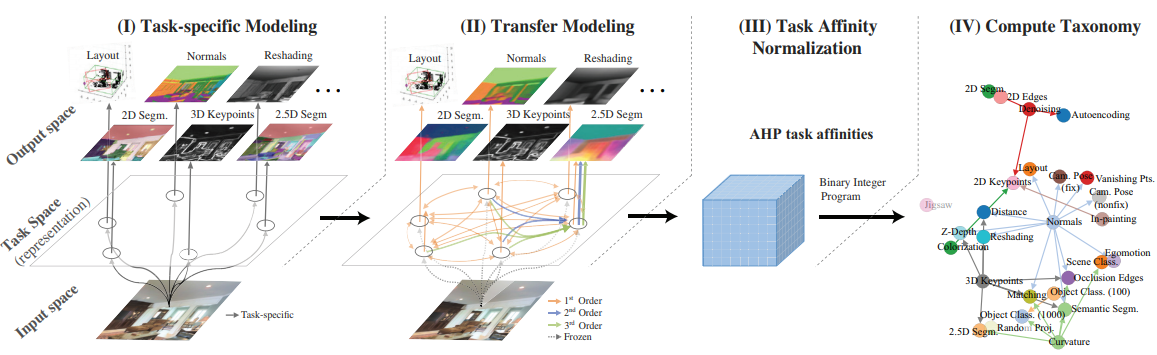
フーリエ周波数領域解析をベースとしたCNNを用いて,単一のRGB画像から距離画像を推定する手法を提案.CNNはResNet-152ベースで,depthbalanced Euclidean lossと呼ばれる損失関数を設計し,広範囲の距離画像を推定できるように学習する.次に,入力画像を複数のアスペクト比で切り取って複数のデプスマップ候補を生成する.アスペクト比の小さい画像は,局所的に信頼できるデプスマップを生成するが,アスペクト比の大きい画像は,大域的なデプスマップを生成する.これらをお互いに補完するために,デプスマップ候補を周波数領域で結合する.
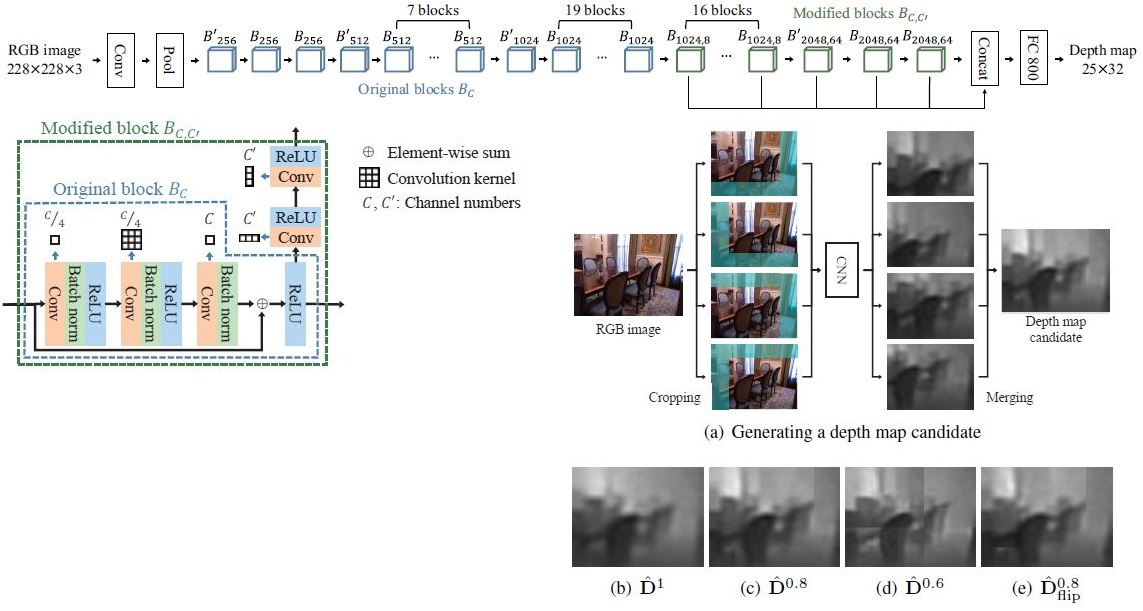
距離画像推定にフーリエ周波数領域解析を使った(作者の知る限りで)初めての論文である.NYUv2 depth datasetの画像280,000枚を学習し,654枚で評価を行った.fully convolutional residual networksを用いた最新の手法と同等またはそれ以上の性能を得ることができた.
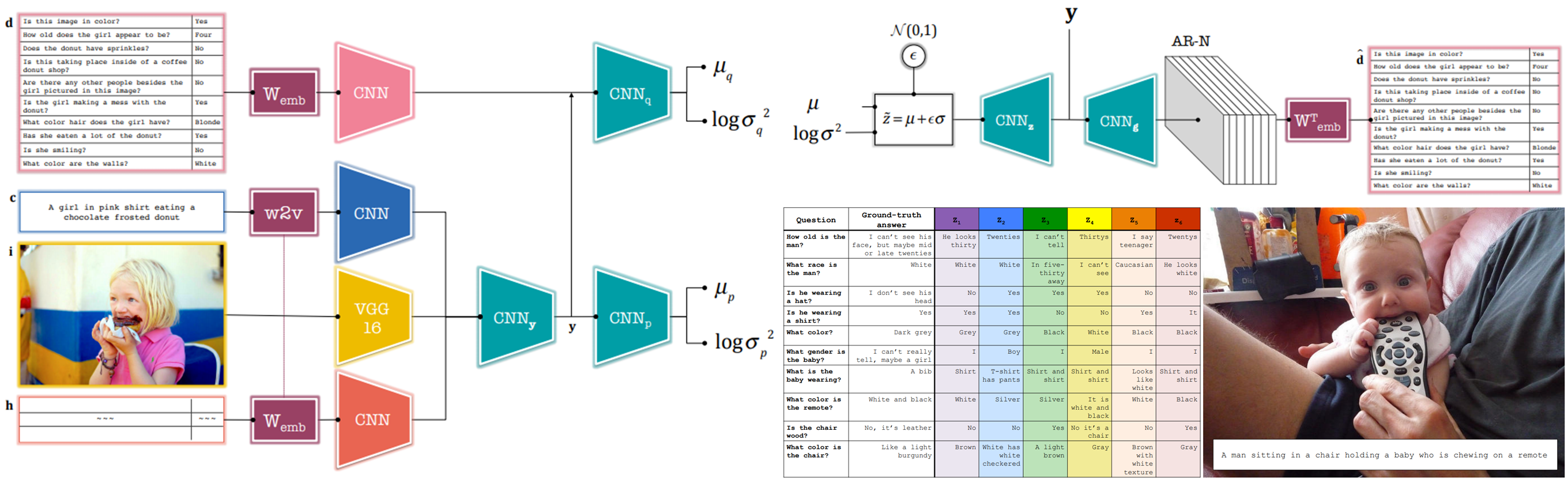
CNNによりfull 会話をエンコードする考えが大胆的
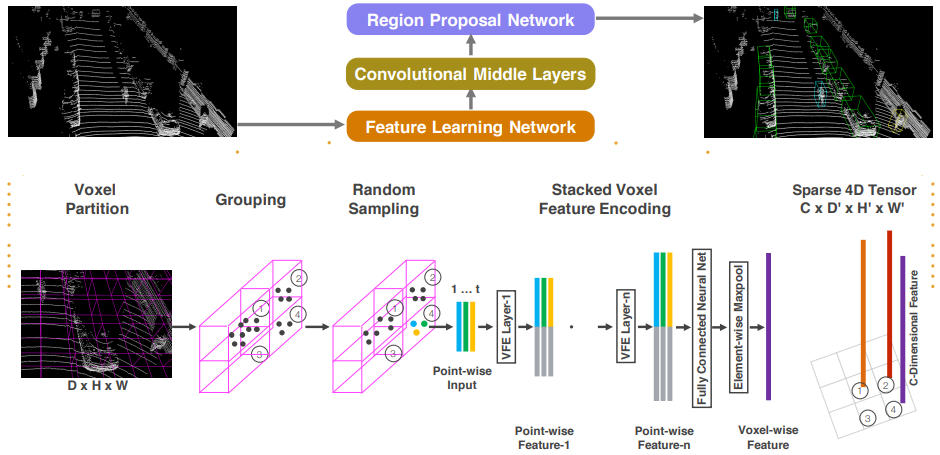
LiDARセンサーから有効的かつ高スピードで識別や検出する研究がまたまた研究の余地があると感じている.
情報検索システムにおける精度は,平均精度(AP)や正規化減価累積利得(NDCG)のような複雑なランクベースロス関数で測られるが,このような関数の微分不可能性・分解不可能性は単純勾配最適化においては許されない.これの回避方法として,一般的には,構造化ヒンジロス上界の最適化をロス関数にする方法や,直接ロス最小化のような漸近的手法が使われる. それでも,loss-augmented inferenceの高い計算複雑性は残る.
本稿では,それを緩和する,新たなクイックソート・フレーバーな分割統治を導入したアルゴリズムを提案する.分解不可能ロス関数に適用可能である.
我々のアルゴリズムにも適用できるロス関数の特徴づけも提供する.これはAP,NDCGの両方を含む. 更に,我々の手法の計算複雑性の上では,漸近的に比較ベースアルゴリズムでは改善できないことを証明する.
あらゆるCVのタスクでの学習モデルでのAP,NDCGの構造化ヒンジロス上界の最適化の文脈において,我々の手法の効果をデモンストレーションする.
![]()
クイックソート的にランクを並べ替え・選択して,というのは面白いやり方に感じる.
グラフマッチングをDeepで扱えるようにしたという,大変汎用的な論文.
グラフマッチングにおける全パラメータのEnd-to-End学習を可能にした.これは深層特徴抽出階層により表現される.
モデルの異なる行列計算レイヤの定式化が肝である模様.勾配の一貫性ある効率的な伝播を行えるようにする, マッチング問題を解くにあたっての組み合わせ最適化レイヤと,特徴抽出階層を通じた, ロス関数からの完全なパイプラインを提案している.
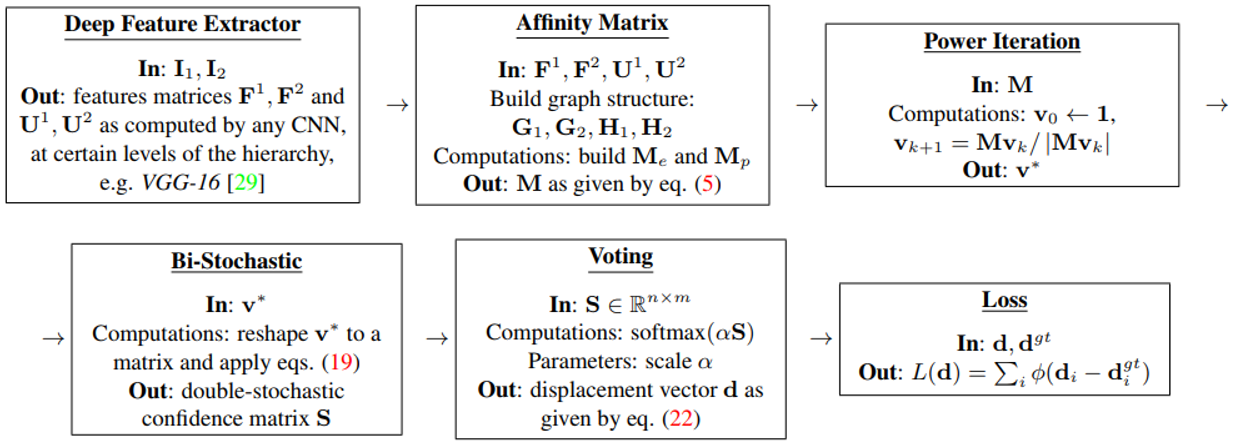
グラフマッチングは,ノードとその間をつなぐエッジで構成されるグラフ(ノードの幾何学的位置は無意味)の等価性を検索するタスクで,コンピュータビジョンや機械学習のあらゆる方面で適用されるものである.これが深層学習で解けるようになれば,それは当然大きな進歩である. グラフマッチングを扱おうとする人の第一リファレンスになりえる論文と思われる.
キーポイント検出において試してみたところ,やはりSoTA性能.
混雑状況認識やカウンティング、密度推定のためのネットワークCongested Scene Recognition Network (CSRNet)を提案し、データドリブンで学習する。畳み込みによる特徴抽出とDilated Convにより広範領域から特徴を評価する(ここにおいてプーリング層を置き換えると記述され、純粋に畳み込みそうのみで構成されている)。図はDilated ConvとPoolingの有無によるヒートマップの比較。
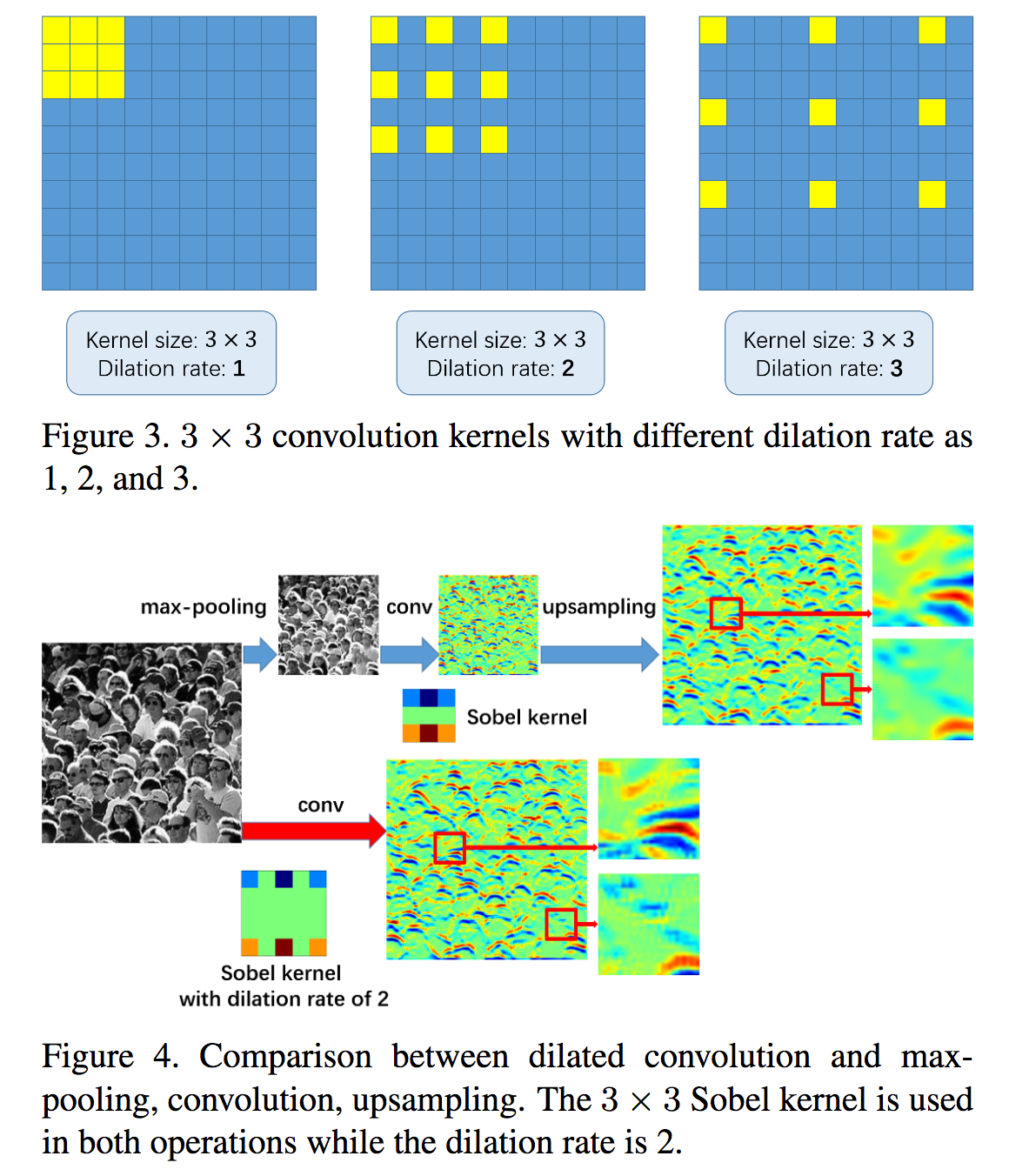
データセットはShanghaiTech, UCF_CC_50, WorldEXPO'10, UCSDを用いて検証した。特にShanghaiTechデータセットではMean Absolute Error (MAE)が47.3%も下がった。
アテンションモデルの改善を行い、VQAに適用する。現在のアテンションに関する弱点は(1)中間層では対応関係といった理由づけに関する情報を除去してしまう(2)StackedAttentionでは局所最適解に陥ってしまうことを挙げた。本論文ではこの問題を解決するため、明示的に中間的な理由づけに関する構造を加えたStacked Latent Attention Modelを提案。マルチモーダルのReasoningに有効であることがわかり、VQAにおいても効果的な手法となった。
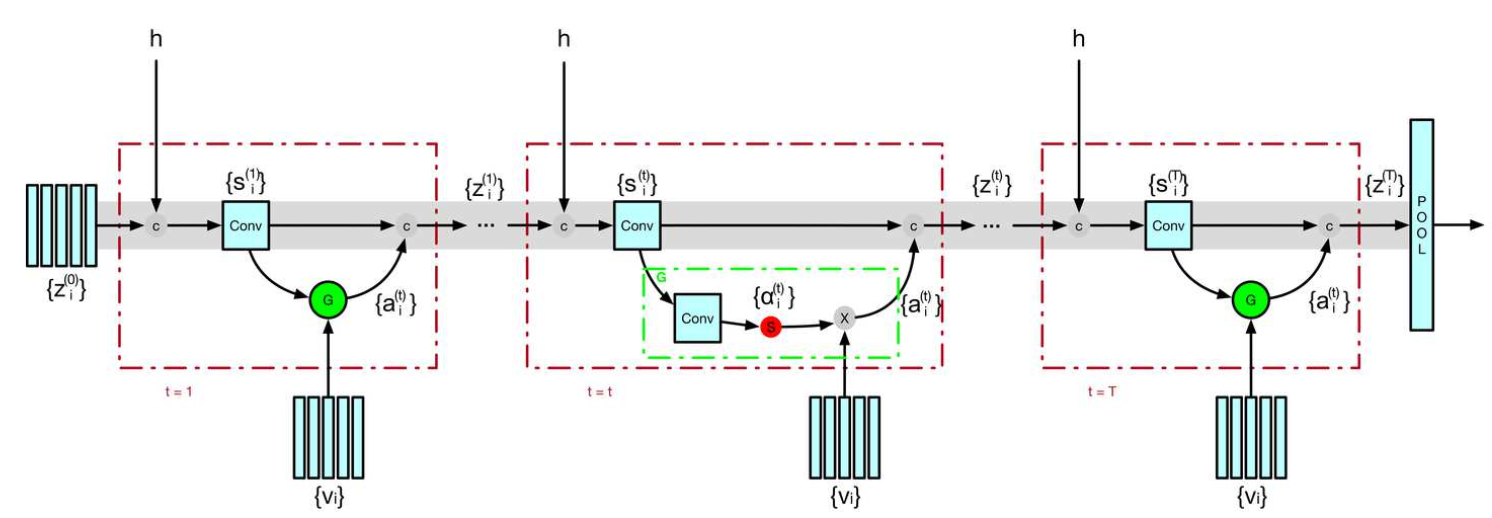
構造をスタックしてより良好なアテンションにしていくモデルを構築した。空間的な理由づけ(Reasoning)を潜在的に行うモデルであり、マルチモーダルであるVQAや画像説明文にも効果的である。
カメラキャリブレーションされていない複数の視点から車の3次元データをパーツ単位で再構成しトラッキングも行うパイプライン「CarFusion」を提案.強いオクルージョンがある場合でも移動車両の検出,localize,再構成を行うことができる.構造化された点(検出された車両のパーツ)と構造化されていない特徴点(Harrisのコーナー検出)を融合して車の正確な再構成と検出を行う.複数視点からの車の再構成にはCar centric RANSAC(cRANSAC)を提案している.通常のRANSACと比較して,左右対称を前提として車の形状を考慮したマッチングを行う.
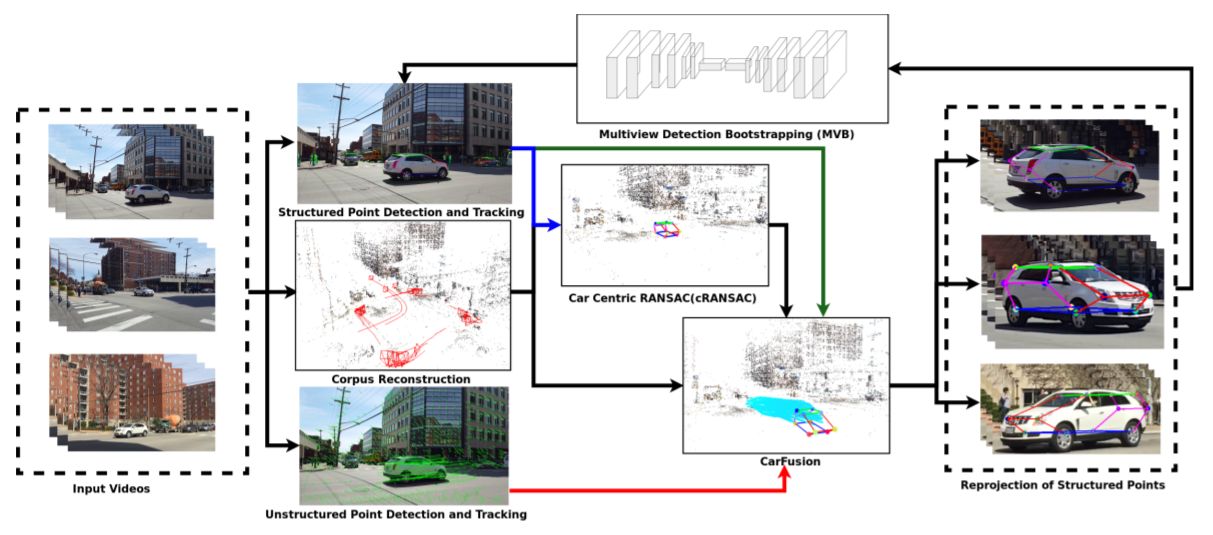

キャリブレーションされていない非同期のカメラからダイナミックに剛体を再構成するという,3D Vision分野で重要だが困難な研究を行った.In the wildでの高精度な検出としても新規性がある.cRANSACのみ用いた場合とCarFusion全体パイプラインを用いた場合で,トラッキングの誤差を4倍削減することができた.再構成時のキーポイント検出も従来手法より優れている.さらに,車の半分程度が隠れてしまう強いオクルージョンがある場合でも3D構成を検出することができた.
人物に関して、主に姿勢に関するパーツベースのセマンティック情報を導入することにより人物再同定(Person Re-identification)の精度を向上させる。提案のSPReIDはInception-v3やResNet-152をベースアーキテクチャにしていて、各種データセットに対して向上が見られた。
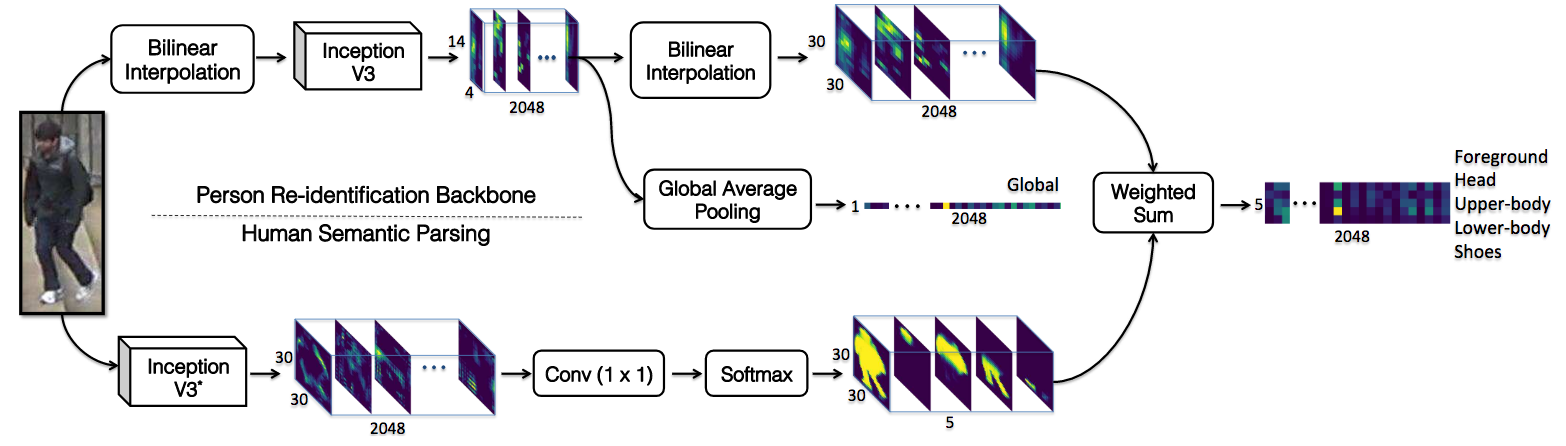
各種データセットにて次の通り向上した。セマンティック情報を人物再同定に使うのは有効であることが判明した。Market-1501 (参考文献48) by ∼17% in mAP、∼6% in rank-1, CUHK03 (参考文献24) by ∼4% in rank-1、DukeMTMC-reID (参考文献50) by∼24% in mAP ∼10% in rank-1。
Web画像により相対的なステレオ視に関するデータセットを作成した。RankingLossを改善した誤差関数によりデータセット内のステレオ視を学習、ペアリングが困難なものについての対応付けを行なった。作成したデータセットに対してState-of-the-artであるのみならず、他のピクセルベースの密な推定(距離推定、セマンティックセグメンテーション)についても有効性を示した。
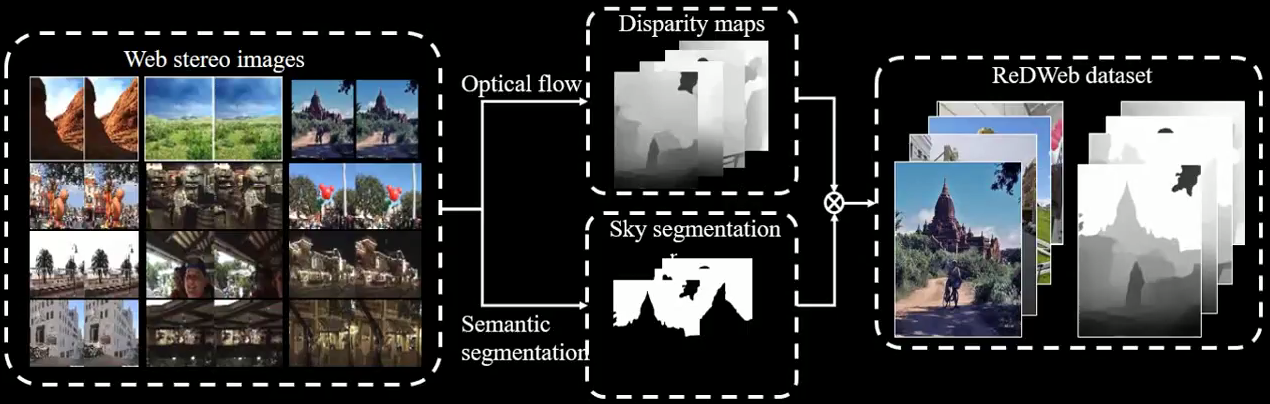
Web画像により密なステレオ視を推定する枠組みを考案、Relative Depth from Web(ReDWeb)の概念を提唱。RankingLossの改善版によりペアリングが困難な対応付についても行った。DIW/NYUDv2データセットにて評価、State-of-the-artな性能を達成した。
イメージング技術において、Time-of-flight(ToF)やTransient Imagingに関する研究である。これらの技術は研究の関心に反して解像度が上がらず、低コスト化も進んでいない。本論文ではセンサの設計を変更し、Arrays of Single Photon Avalanche Diodes (SPADs)を改善することでこの問題に取り組む。DMDを用い、光学系をカスタマイズすることでSPADの解像度を800x400まで向上。時系列ヒストグラムを調整するモデルでは効果的にノイズ除去できることも示した。
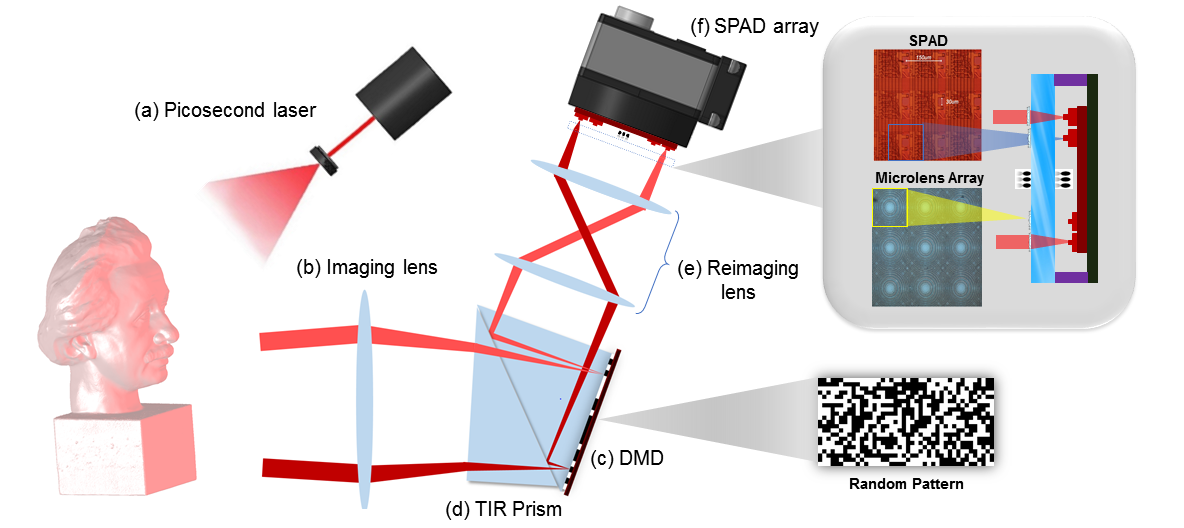
右図は提案のイメージング技術であり、SPADsの高解像度化を実現した。
3次元形状認識のためにGroup-View Convolutional Neural Netowrk (GVCNN)を提案し、形状に関するビュー不変な内的かつ階層的な相関関係を記述する。識別性が高くなるようGroupingModuleによりビューポイントのグルーピングを行い、途中の層でViewPoolingやGroupFusionを行い、3次元形状認識を行う。右図はGVCNNのアーキテクチャである。
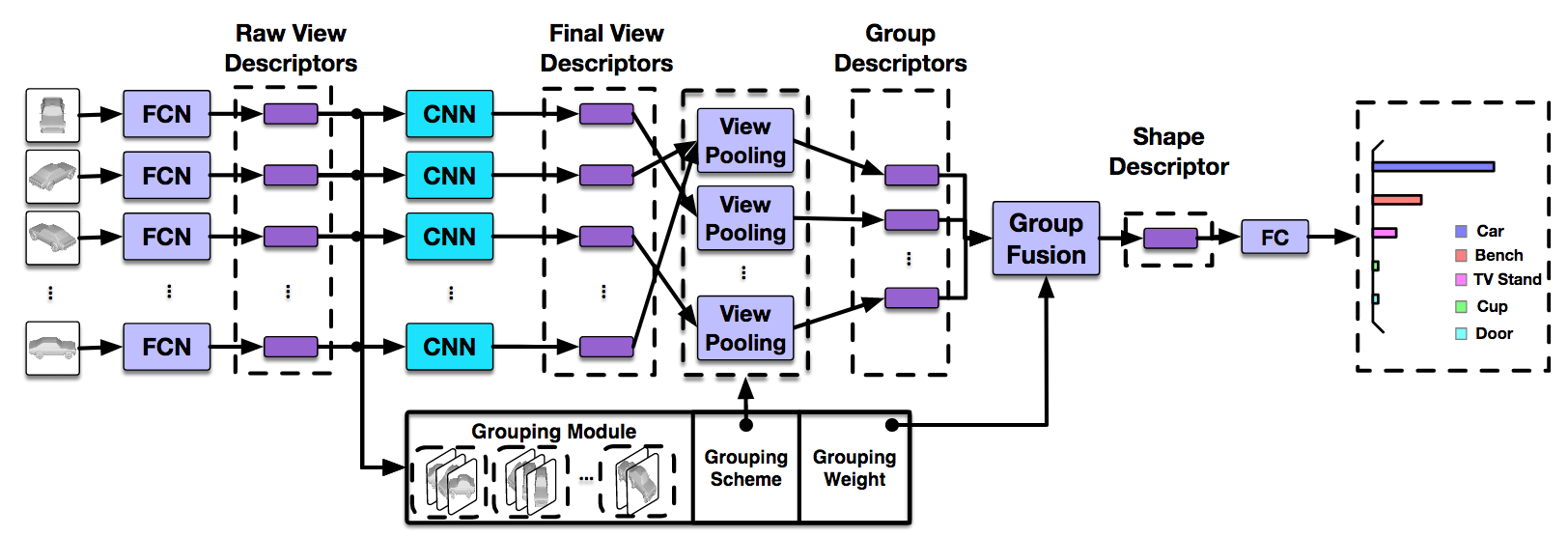
ビューポイントに不変な認識を実施可能なEnd-to-Endな学習フレームワークであるGVCNNを提案した。MVCNNとの比較により有効性を示した。
対象ピクセルを近傍のピクセルと入れ替えるPixel Deflectionを利用した敵対的摂動に対しての防御手法。NNは敵対的摂動ノイズに対しては弱いのに対し、ランダムノイズには強いという経験的な傾向から、敵対的摂動が加わっていないサンプルへの性能をできるだけ保持した状態でノイズを加えるためにPixel Deflection+ Wavelet Denoisingを行う。既存手法よりも良い防御性能を示した。
Pixel Deflectionはある対象ピクセルをその近傍からランダムにサンプルされたピクセル値に置き換える。対象ピクセルを決める際には、正しい識別を行う際に重要となる領域以外からサンプリングする。具体的には敵対的摂動による影響が少ないsaliencyであるRobust CAMを定義し、そのsaliencyが低い領域からサンプル。この背景には敵対的摂動は画像に対して大域的に(物体に関係せず)現れる傾向があるので、できるだけ正しい識別に影響を与えない領域にPixel Deflectionを行いたいという考えがある。
NNのパラメータに関する変更はせずに入力への変更を行うことで敵対的摂動の種類にかかわらず汎用的に防御できるという点が面白い。手法の裏付けとして敵対的摂動とランダムノイズの識別精度への影響比較も行っており、面白かった。
本稿の手法により,60%のピクセルがノイズに侵されている(occluded)テンプレートでもマッチングできる.しかも結果の証明が可能.
N高次元ベクトルの最近傍探索をsqrt(N)次元ベクトルにおける2つのセットの間の最近傍探索 の変換を行う. これで探索効率が二乗でよくなる.
また,コンセンサスセット最大化(cf. RANSAC)による,ハッシング手法も提案.これにより,遮蔽を扱うことができる.
これらのスキームは,高い確率で最適解を得るのに求められるイタレーション数を考慮する,ランダム化仮説&テストアルゴリズムとみなすことができる.

SoTAなロバスト性・高速性・精度を達成.
セマンティックセグメンテーションにおいて,FCNの中に2つの機構を取り入れた.

3つのセマンティックセグメンテーションのデータベースでSoTA.
4D映画を自動で作成するための研究。63本の映画に9286のエフェクトのアノテーションをしたデータセットであるMOVIE4dを提案。エフェクトは、揺れ、天候、風、水しぶきなど。また、人の形のみでなく、視聴覚情報をまとめるニューラルネットワークとしてConditional Random Field modelを提案。

映画のスレッドだけでなく、クリップ内でのキャラクター間のエフェクトの相関関係を利用。
物体の情報に効果的な影響があるセマンティックパーツの検出アプローチを提案。どのパーツを予想するべきかという指標として、オブジェクトの見た目とクラスを用い、その見た目を基に物体の中でのそのパーツに期待される相対的な位置をモデル化。OffsetNetという新しいネットワークモジュールで所定の物体の中の一部の場所を効果的に予測することを達成。
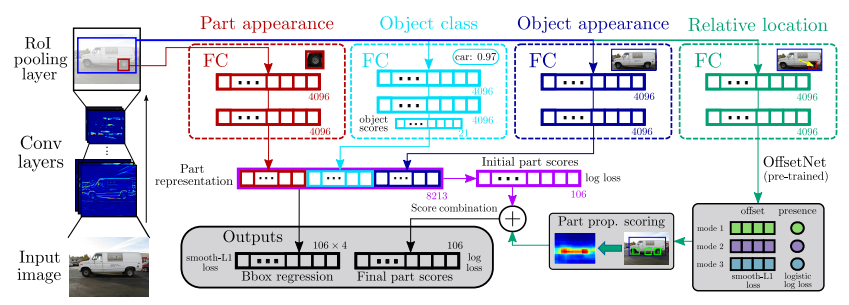
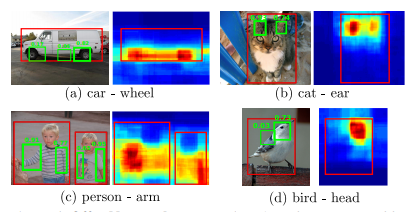
the PASCAL-Part datasetにおいて+5mAPの改善。PASCAL-PartとCUB200-2011において他のパーツ検出手法より優れた成果を達成。
ドローンのような飛行体にユーザーが指定した2つの被写体を含んだ画像を撮影させる手法の提案。ユーザーは希望の2つの被写体を指定し、それぞれどのように配置したいかを指定する。 ここでは、n=2の場合のPnP問題を考えることでドローンの撮影位置を決定する。 カメラの姿勢を求める6自由度の問題として考えるが、P2P問題は解が一意に定まらないので移動距離が最小となる撮影位置を解とする。 ワールド座標系とカメラ座標系間の直接の変換を考えるのではなく、2つの被写体がx軸上に配置される座標系を考えることで、計算を簡略化する。

仮想環境によって実験を実施し、被写体の位置情報にノイズが含まれている場合でも頑健なことを確認した。実環境における実験は、SLAMにより得られた自己位置を使用して行ったが、推定誤差があるような場合においても高い精度で撮影位置を求めることに成功した。 撮影位置の最適化は、1つの物体を先に最適化した後にもう一方の物体の位置を調整するという実験結果が得られた。
RGB画像から6DOF姿勢推定+3Dモデル検索を同時に行えるようにする手法。厳密な中身は画像から6DOF姿勢するパートと、その姿勢とRGB画像情報から最適な3Dモデルを検索して見つけてくるパートに分けられる。三次元姿勢推定については既存手法からInspireされ、認識された物体を内包するProjected 3D Bounding Box(16 Parameters)及び3D Scale(3 Parameters)をResNetやVGGをベースとしたCNNで推定し、PnP問題を解いた。これによりモデル既知でないにもかかわらず、Pascal3D+データセットでState of the artな6DOF姿勢推定精度を実現。3Dモデル検索パートでは、RGB特徴量とDepthImage特徴量の取得を異なるのCNNで定義し、RGB特徴量、対応するDepth特徴量、間違ったDepth特徴量をそれぞれAnchor, Positive, Negativeと扱いTripletLossを計算することで学習。これによりRGB画像とDepth画像という全く異なるドメイン間での特徴量マッチングを実現し、テクスチャレスな3DモデルであったりRGB画像の照明環境不明であっても最適な3Dモデルの検索を行えるようになった。同カテゴリでは似たような形状のモデルが多数存在するにもかかわらず、画像に対する人間のAnnotationに対して約50%の精度での検索結果を実現した。
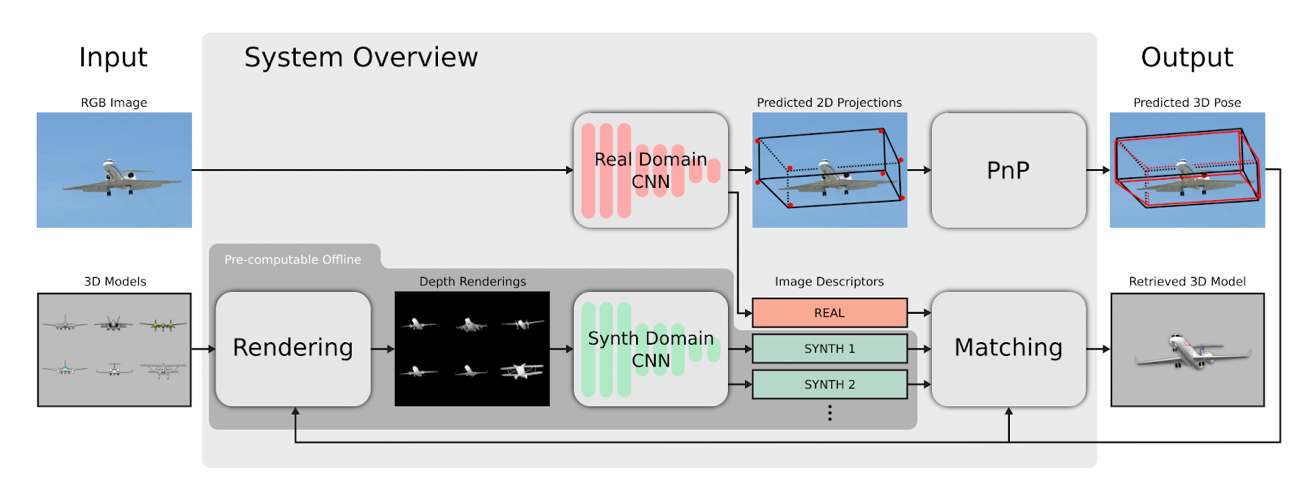
Projected 3D Bounding Box を用いた6DOF 姿勢推定ではモデル既知でしか解けなかったところをモデル既知でState of the art、モデルなしでもCompatibleな結果を出した点。検索パートではハイコストな3D畳み込みや既知DepthImageを要することなくRGBとDepthImage間の共通記述特徴量の学習・その有効性を示した点。結果については姿勢推定においてはState of the art、検索においては人間のAnnotationに対して50%の精度を実現。6DOF姿勢の高精度推定と、RGB・Depth間の共通記述子を学習することにより画像から3Dモデル検索までを行うシステムを実現したことが通った理由と思われる。
手話動画を言語に翻訳する手法を提案。手話の各フレーム及び文章中の各単語を表現する特徴ベクトルを取得し、RNNによりそれぞれのsequenceを取得する。 手話動画から得られるsequenceを文章のsequenceに変換することで翻訳を実現する。 その際、手話動画のフレーム数は文章中の単語数と比べて圧倒的に多いため対応付けが難しい。 そこで、Attentionを導入することで手話動画中の重要なフレームに対して重み付けを行う。
従来のデータセットは機械学習に用いるには数が少ないため、手話動画、手話の単語、対応するドイツ語の文章を含んだRWTH-PHOENIX=Weather 2014Tというデータセットを提案した。従来の手話に関する研究は、Recognitionの問題として考えていたのに対して、Sequence間の変換と考えることにより文章を出力することを可能とした。
180万枚以上の3Dのメッシュを含んだダイナミックで高解像度な3Dの顔のデータベースである4DFABを提案。このデータベースには、5年以上かけて異なる4つの期間で撮られた180のサブジェクトの記録を含んでいる。サブジェクトには、自然な表情とそうでない表情の両方の4Dビデオが含まれており、行動に関するバイオミメティクスだけでなく、顔と表情の認識に使うことができる。また、表情をパラメータ化させるためのパワフルなblendshapeを学習することに使うこともできる。

自然な表情と笑顔,泣き笑い,混乱している表情などの自然でない表情が含まれている.
テスト時に入力できる情報に対して、学習時にはより強い情報が使用できる場合にその+αの情報(特権情報)を学習時にうまく活用する研究。テスト時には特権情報が得られないので、特権情報に対して周辺化したものを出力とする方針をとるが、一般にその値を求めるのは難しい。そこで特権情報をGaussian Dropoutの分散の中に埋め込み学習することでテスト時に特別な計算をせずに周辺化することができる。画像認識・機械翻訳で実験し、学習サンプルが少ない状況下で特に効果を発揮する。
Gaussian Dropout部分での逆伝搬ではVAEなどで用いられるreparameterization trickを利用している。画像認識においては特権情報として物体のbounding boxを与えている。SGDでのNNの最適化が理想的に完了する条件下でデータ効率が上がるという理論的な保証と、実験結果による精度向上が評価されたと考えられる。
マルチタスクでの学習よりもしっかり良い結果となっていて興味ふかい。理論的保証はあるものの、Gaussian noiseが具体的にどのようなサンプルに対してどのように作用しているのかを確認する実験なども欲しかった。
通常、物体のモーションは背景(カメラ)モーションとは異なることを事前知識として動画に対する物体セグメンテーションを実行した。提案モデルであるCascaded Refinement Network(CRN)は最初にオプティカルフローにより荒くセグメントしてから高解像なセグメンテーションをCNNにより実施する(ここらへんがMotion-Guidedと呼ばれる理由)。CRN構造に対してSingle-channel Residual Attention Moduleも提案して学習/推論時間を効率化。
疎密探索の枠組みを採用しており、まずはオプティカルフローを抽出、Active Contourにより荒くセグメント。次にCRNによりセグメンテーションを実施した。動画に対して84.4%@mIOU, 0.73 sec/frame(semi-supervision)を達成した。
Old-fashionな手法を組み合わせて弱教師にする方法を提案。また、DAVISは少量教師や教師なしが当たり前のように出てくる。コンペで教師なしを用いる設定はうまいと思った。
26のアルファベットのうちfewな種類しかデータがない状況で、そのフォントで書かれた他種類のアルファベットを生成する研究。アルファベットの形状をグレースケールで生成するGlyph Netとそれらにカラーで装飾を行うOrnamentation Netの二つからなる。単純にpix2pixのようにsingle-shotな構造で生成するよりも形状生成と装飾を多段に行う方がはるかに実際に近いアルファベットが生成できた。
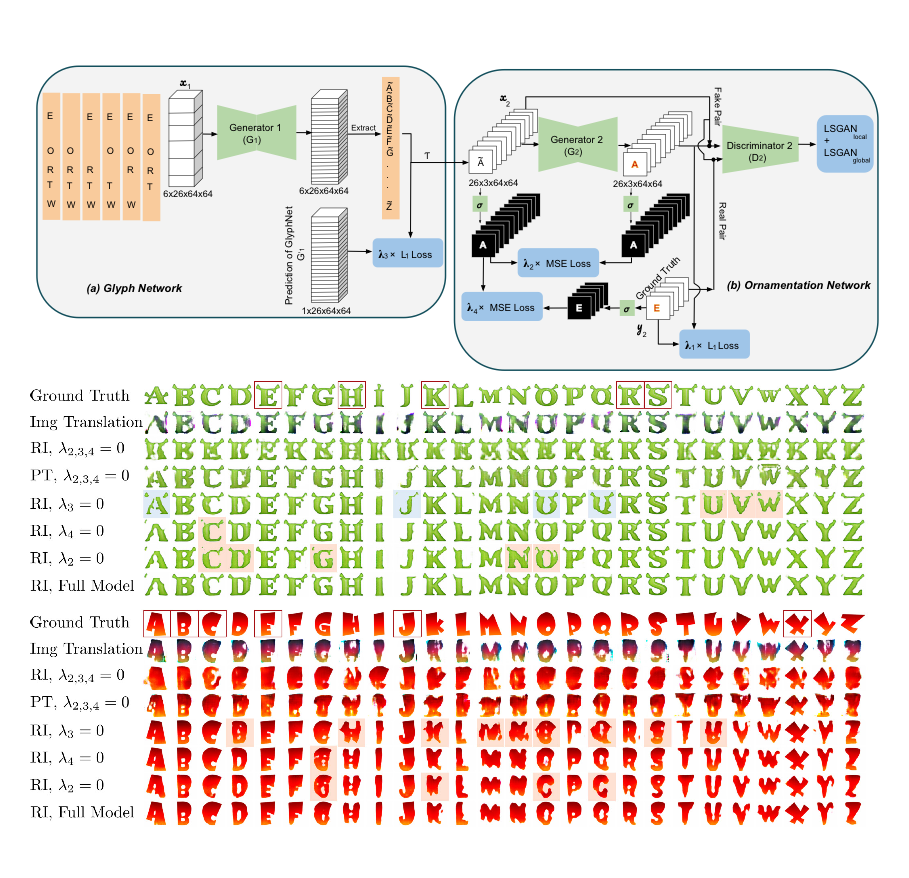
Glyph Netではチャネル方向に配列されたアルファベットを入力する。ないアルファベットは0埋めし、敵対的損失を用いて26×H×Wのグレースケールアルファベットを生成する。 Glyph Netはデータベースのあらゆるフォントサンプルに対して同一のモデルを学習する。 Ornamentation Netは上記のグレースケール画像に対し正解サンプルに近づくよう敵対的損失とMSEによって学習。ここで、正解はfewな種類しかないためそれらにのみ損失を計算。 Ornamentation Netはフォントごとに逐一異なるモデルを学習する。問題設定の面白さ、実際の完成度の高さが評価されたと考えられる。
画像情報の欠損を検出することによる表現獲得手法。encoder-decoder modelの特徴マップ上の領域をランダムに欠損させて、decodeされた画像が欠損されたものがどうかを識別する。
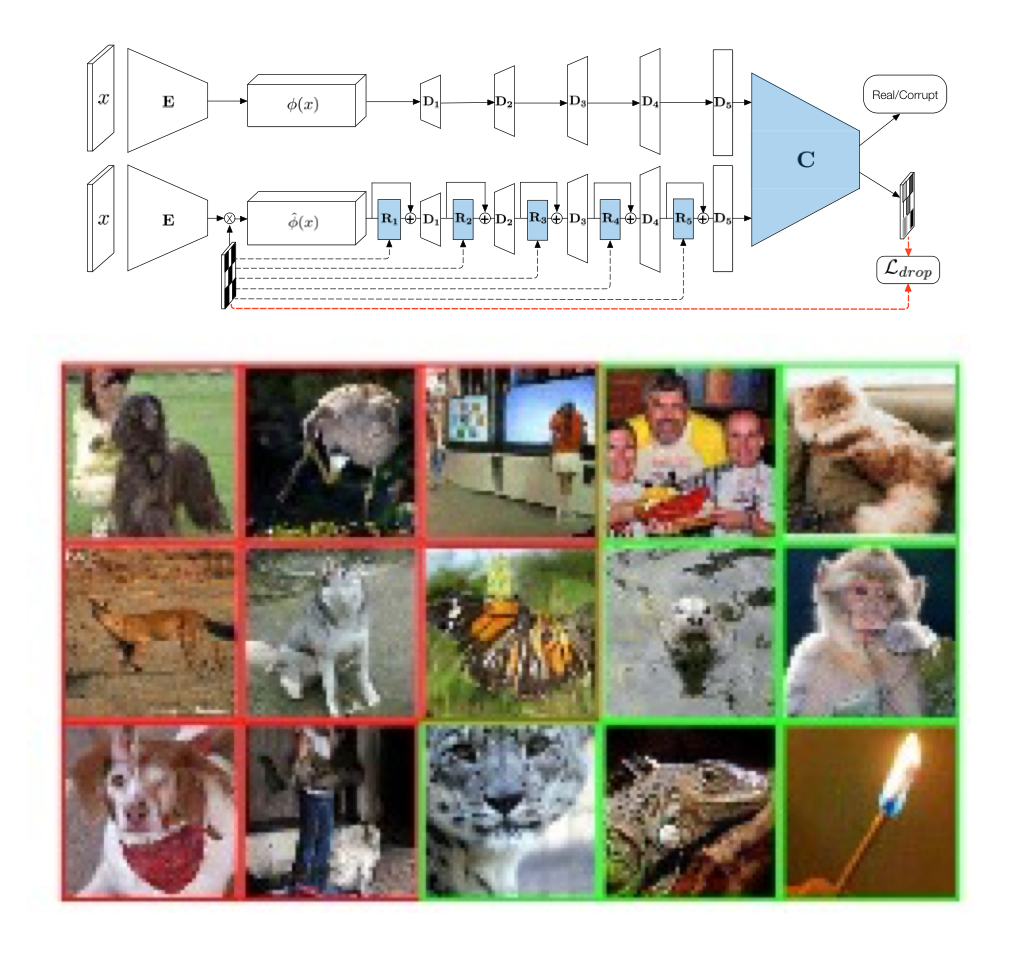
学習はdecoder内の補完レイヤーと識別器間で敵対的に行う。識別器は欠損された部分を示すマスクも出力する。encoder-decoderモデルをreal/fake問わず最初にかませる理由としては、CNNに入力することによるartifactによって識別器が判断しないようにするため、 また高次な特徴マップ上での欠損を行うことで高次な情報が欠損した画像の生成を行うためである。SoTAに近い精度が出ていることが評価されたと考えられる。
弱教師付き学習に対してボトムアップ(物体レベルで似ている特徴量をマイニング)とトップダウン(リファインされた領域をセグメンテーションの教師として学習)のアプローチを組み合わせる手法を考案。右図の(1)RegionNetによる出力/リファイン結果とPixelNetによる出力との比較によりセグメンテーションの誤差を比較、(2)PixelNetによ出力とマイニングした物体マスクと(Class Activation Mappingにより領域抽出された)RegionNetの出力を比較して領域に対する識別の誤差を計算する。
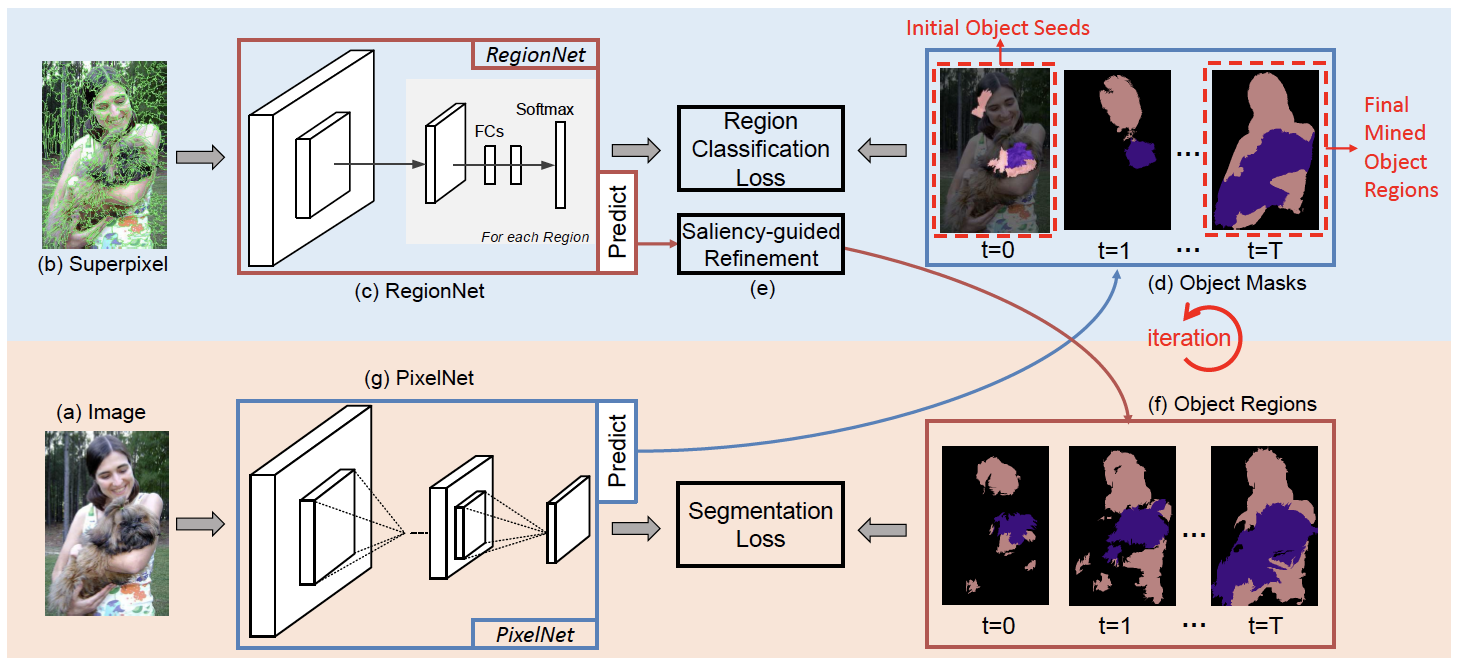
識別ベースによる物体領域抽出とセグメンテーションの誤差を繰り返し最適化することにより弱教師付きセマンティックセグメンテーションを実行する。SuperPixelの導入、類似物体マイニング、領域のリファインなどが徐々にセグメンテーション結果をよくしていく。
言語の入力から画像中の領域を指定するネットワークModular Attention Network (MAttNet)を提案する。本論文では2種類のアテンション(言語ベースのアテンションと視覚ベースのアテンション)を導入した。言語ベースのアテンションではどこに着目して良いかを学習、視覚ベースのアテンションではサブジェクトとその関係性を記述することができる。それぞれのスコアは統合され、最終的には文章を入力すると対応する領域がbboxの形式で出力される。右図はMAttNetの枠組みを示す。文章の入力から言語ベースのアテンションによりワードが厳選され、画像中から探索される。画像ではSubject-/Location-/Relationship-Moduleが働き、最後は統合して総合的に判断、画像中の物体相互関係を考慮した検出が可能になった。
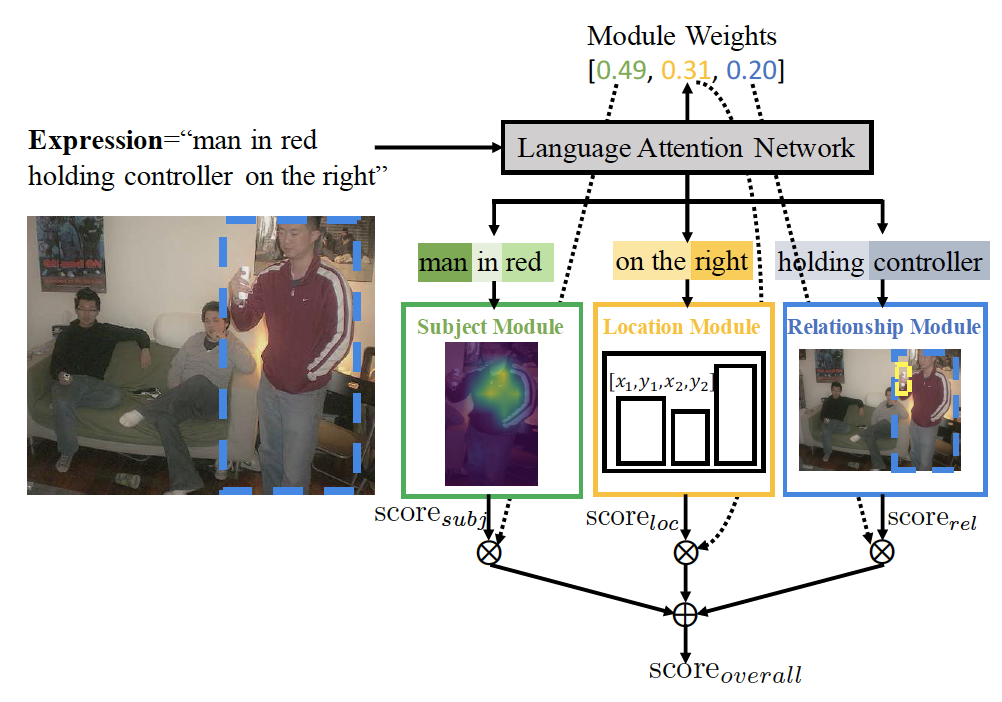
従来の枠組みと比較して、提案手法は(bboxレベルでもpixelレベルでも)高い精度を達成。
Wasserstein GAN (WGAN)の枠組みでハッシング技術を行うHashGANを実装する。主となるアイディアはハッシングのためのデータ拡張を行うためにGANの枠組みを導入。通常は画像生成のみに用いられる仕組み自体を、データバリエーションの拡張のために用いて識別器を強くする。さらに、画像ペアの類似度を計測しながら画像生成を行う枠組みであるPair Conditional WGAN(PC-WGAN)を提案した。図はPC-WGANのアーキテクチャを示し、主に2つの構造から構成される。ひとつは画像生成部Gと識別部Dであり、ランダムノイズuと類似特徴vの連結から画像を生成してリアルな画像を生成。もうひとつはベイジアン学習によりコンパクトなバイナリハッシュを生成するハッシュエンコーダFである。
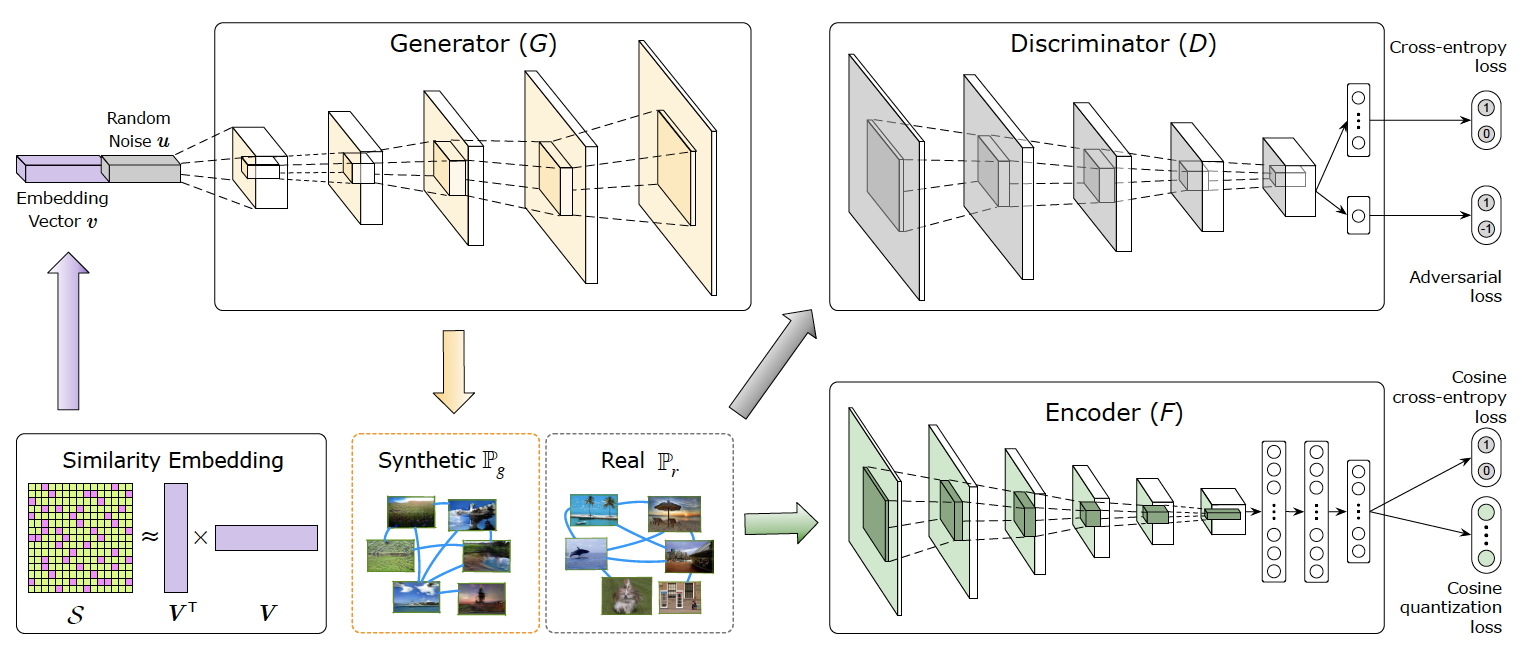
GANの枠組みにより高品質なバイナリコードを生成。生成器Gと識別器DのみならずハッシュエンコーダFを同時に学習する枠組みを考案。NUS-WIDE/CIFAR-10/MS-COCOにおいてSoTA。
肌疾患(Sin Disease)の診断を医師が行いながら、同時にデータ/モデルをIterativeに蓄積・構築する枠組みを考案。従来はComputer Aided Diagnosis(CAD)が肌疾患を判断するために役立ってきたが、2次元画像による判断は(ほぼ)行われていなかった。本論文ではデータの蓄積を行うと同時に、医師の判断材料をベースにした表現方法を学習することで、診断するモデルを構築する。診断の特徴としては、テクスチャの分布(複数箇所に渡り対称性が見られる領域が存在するかどうか)や色の表現(ここでは参考文献39,40のColorNameを適用)、形状を用いる。
医師による診察の目を実装したこと、データを繰り返し実装する枠組みを構築できたことが分野(特に医用画像処理)に貢献した。
効率的かつ効果的なDeep Hash ModelであるDeep Cauchy Hashing(DCH)を提案する。主たるアイディアはCauchy分布によるPairwise Cross-Entropy Lossを提案することであり、類似する画像に対してHamming距離により誤差の重み付けを行う。図はDCHの構造を示しており、畳み込みにより表現を学習、全結合を通り抜けFully-Connected Hash Layer(FCH)によりK-bitのハッシュコードを生成、Cauchy Cross-Entropyにより類似度により誤差を計算して誤差を伝播させる。
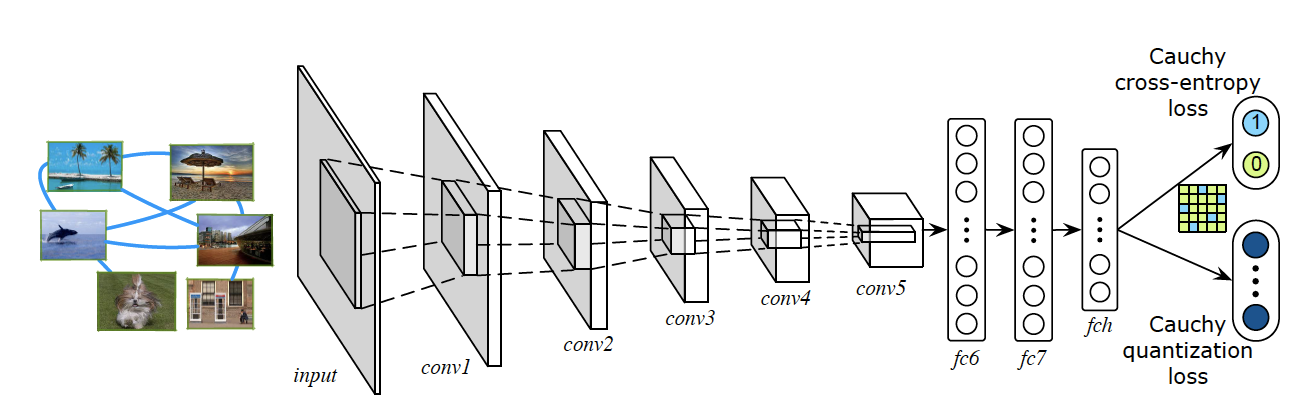
画像検索において3種のデータ(NUS-WIDE/CIFAR-10/MS-COCO)に対してSoTA。
Deep Hashingの研究、データセットをより大きくしてハード面での実装も含めて評価する枠組みが必要?Hashingなので、FCC100Mのように1億枚くらいの画像検索をやってほしい(し、日本でも取り組んでいる人はいる)。
ユーザインタラクティブに動画セマンティックセグメンテーションのための距離学習(Metric Learning)を行い、特徴空間を最適化する。入力画像から任意のモデルに対してセグメンテーションを実施、ユーザが良いと判断したセグメント領域を正解値として特徴空間を設定、一方でテスト(バリデーション?)画像を参照して動画セマンティックセグメンテーションを実行して学習する。
![]()
ユーザインタラクティブというところが良い。セグメンテーションに対するアノテーションはコストがかかる(かかりすぎる)が、これをコンピュータによる推論と、ユーザのクリックのみにして特徴空間を学習していく方がコストが最小化される。精度も出るのでCVPRにアクセプトされている。
セマンティックセグメンテーションに対するアノテーションは一枚あたり$10~12であると言われる。アノテーションコストを下げる方向に研究は進んでいて、特に動画セマンティックセグメンテーションは低コスト/弱教師学習/ドメイン変換等により進められると考えられる。
人物再同定のための特徴表現学習のためにTriplet学習を行う。オリジナルの全体画像(Anchor Image)、マスクされた人物領域(Positive Image)と背景領域(Negative Image)を用いて学習する。ここで、Triplet学習ではAnchor/Positiveをできる限り近く、Anchor/Negativeをできる限り遠くの特徴空間に置くことでよりよく対象となる物体を見ることができ、良好な特徴量を生成することができる。
前景/背景を別々に学習し、背景ではなくできる限り前景に対してアテンションを置いて識別することで、人物再同定において良好な精度での識別を確認した。前景抽出のマスク画像に関するアノテーション(Mars/Market-1501/CUHK03)も公開することで、人物再同定の分野に貢献する。
適切な長さの動画分割(Video Snippet; ビデオスニペット)とCo-Attention機構による人物再同定の研究である。動画からの人物再同定では長いフレーム長をそのまま入力するよりもスニペットに分割して、さらには分割動画間のCo-Attentionに着目することで特徴表現を学習する方が認識に有利であることを実証した。スニペット間で類似度が計算され、ランク付が行われる。
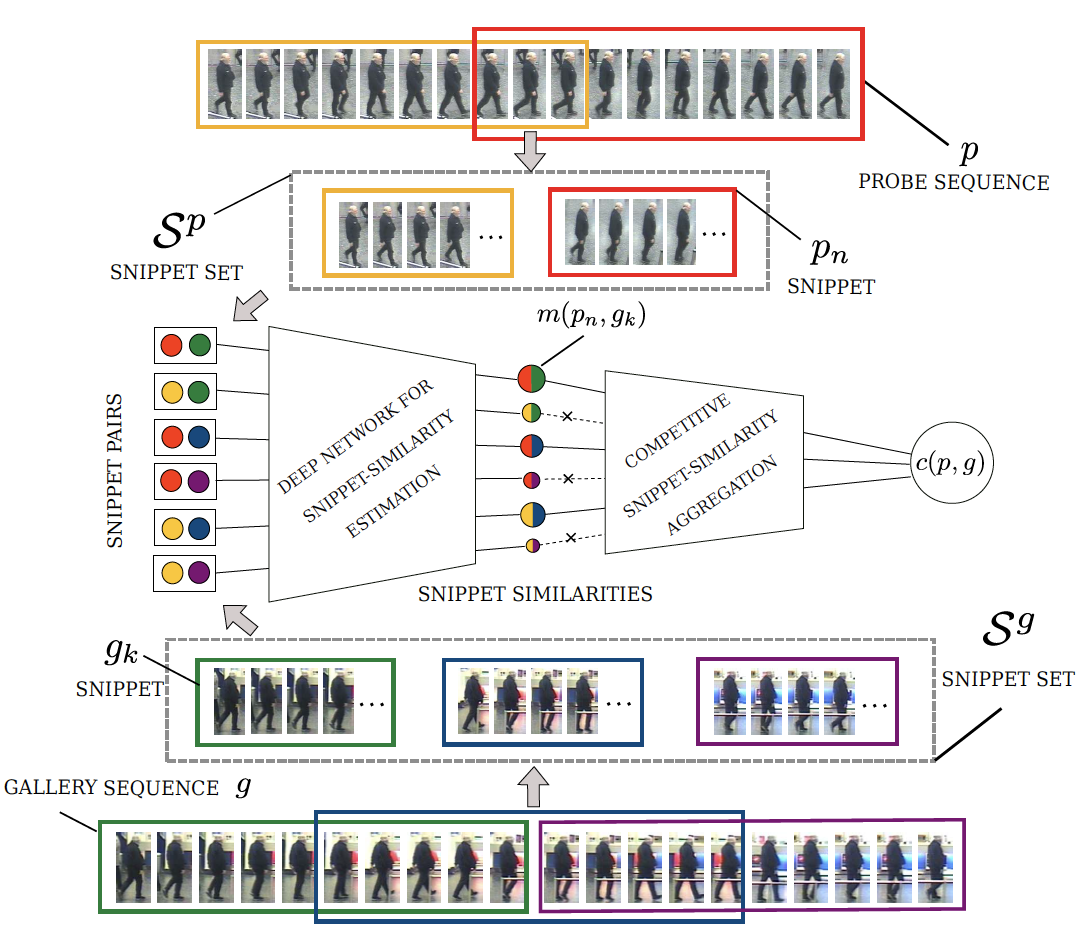
動画スニペットごとに類似度を計算し、それぞれに対してCo-Attentionを求めて特徴量を学習する方法で複数のデータセットにてSoTA。iLIDS-VIDにてTOP1が85.4、TOP5が96.7(上位に正解が含まれているかどうかであり、TOP5は5人中1人が正解であればよい)であり強い手法が構築できた。PRID2011においてもそれぞれ93.0/99.3、Marsにおいても86.3/94.7である。
人物再同定は数年前までTOP5(〜TOP20)が高い精度であれば許される時代だったがTOP5で95+%(驚くべきは99%も出ているデータセットがあるということ)という数値である。中国の事情もあり、その解決のためにSenseTimeがその役を買っているというわけである。今後はさらなるデータ作成と社会実装の推進が進むと思われる。SenseTime/CUHKの連携ラボの枠組みも整った(CUHK-SenseTime Joint Lab.と著者リストにある)ことで、さらに研究が大規模に進められる。
動画に対する姿勢+ヒートマップからの行動認識を解く問題である。通常、動画中の姿勢推定は不安定なものであるが、動画内での平均化や連続する姿勢、ヒートマップから補完的に改善して行動を認識する枠組みを提案。ヒートマップのスパース性を考慮、Spatial Rank Poolingを実装してEvolutionImageを作成しヒートマップや姿勢の変動に対応できるようにした。この枠組みはNTU RGBD/UTD-MHAD/PennActionに対して有効であることを示した。
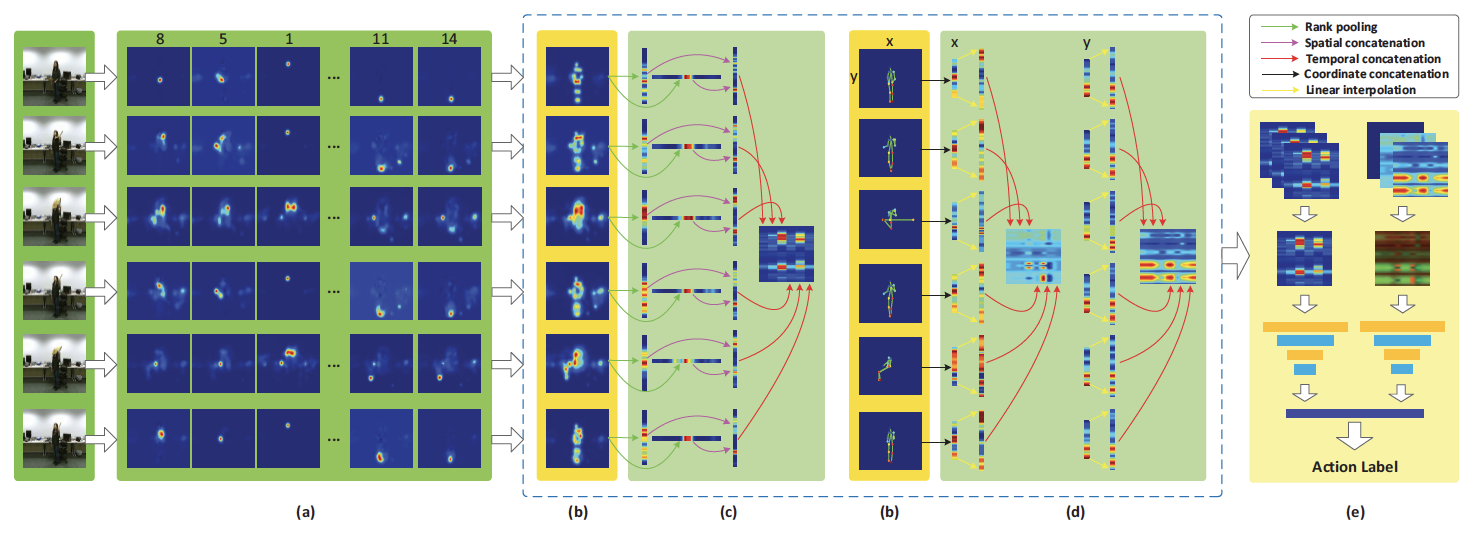
不安定な姿勢変動に対応するためにSpatial Rank Poolingを実装した。位置づけ的にはDynamicImage/VideoDarwinがTwo-Stream ConvNetsに対する改善なのに対して本論文は姿勢に対してこれらの枠組みを試行。この枠組みを用いてNTU RGBD/UTD-MHAD/PennActionに対してSoTA。
行動認識における特徴は独立ではなく、動画を通して共通する部分が多い。これら共通特徴を捉えるためのプーリング(Pooling)手法を確立すると共に特徴表現を学習する。戦略としてはMultiple Instance Learning(MIL)により未知だが識別性に優れた非線形の識別境界(Hyperplane)を求めるようにPooling自体をDNNの中で学習する。右図は従来法のDynamicImages(参考文献2; 図中(iii))と提案手法であるSVM Pooling(図中(iv))の比較である。SVM Poolingは動画像全体の動きを捉える特徴量が抽出しやすくなり、精度向上に寄与した。識別決定境界を学習、動画レベルの識別を最適化することから、SVM Poolingと呼ぶ。

3種類の公開データセット(HMDB51/Charades/NTU-RGBD)にてSoTA。
Pooling/Conv自体のパラメータを固定ではなく、学習可能にしてしまう、というアイディアは多くなってきた。構造自体を学習するNAS(Neural Architecture Search)なんかにも使うことでさらなる精度向上ができないか?
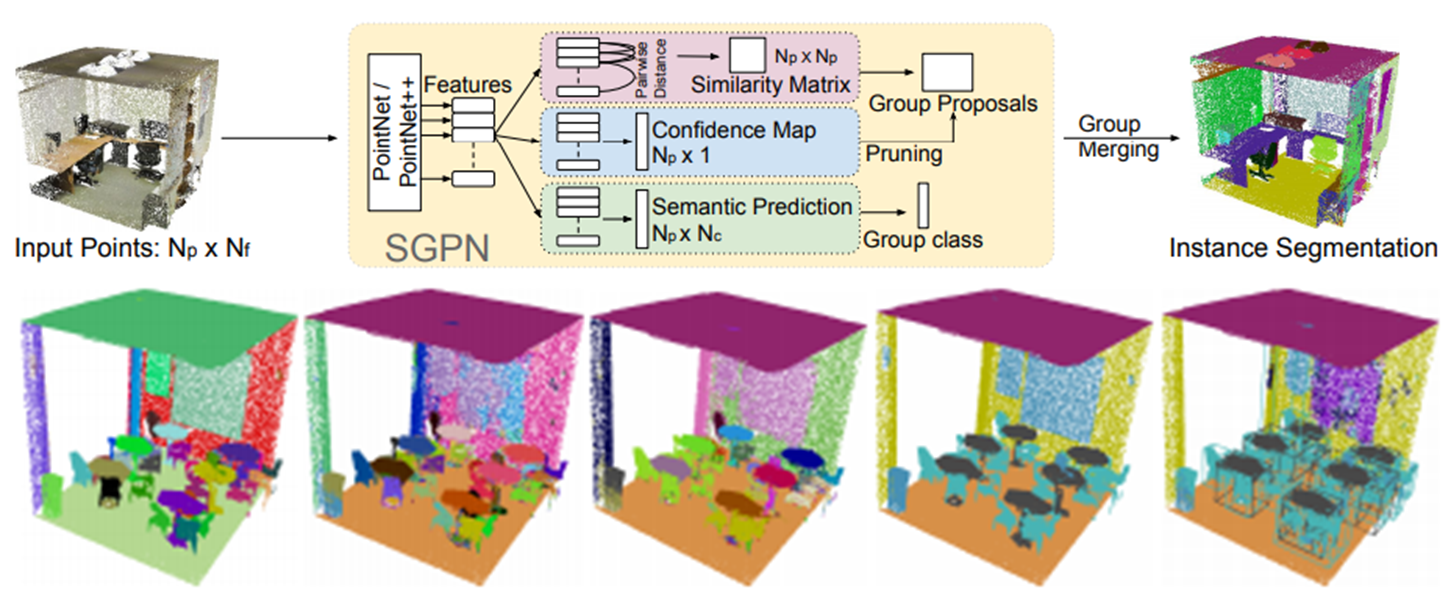
ネットワークの説明が簡潔で,結果も良いのでつかってみたい
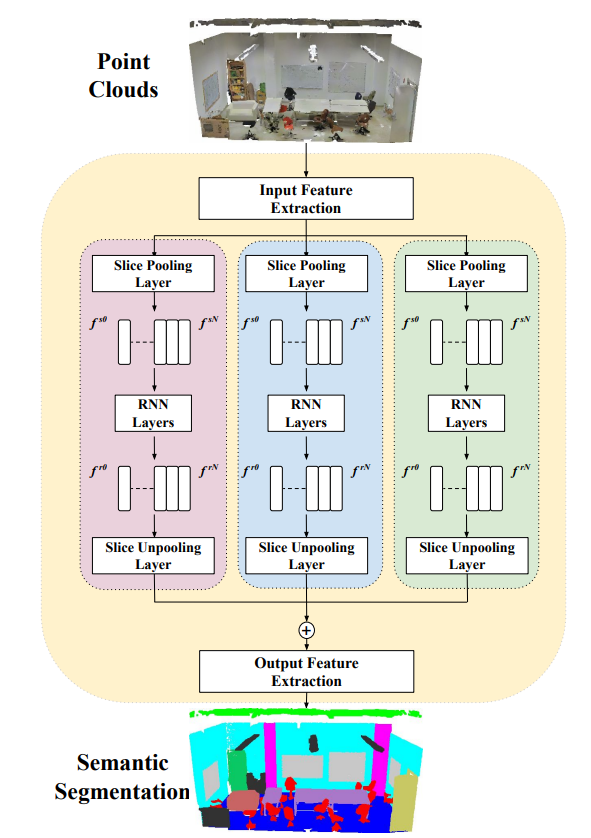

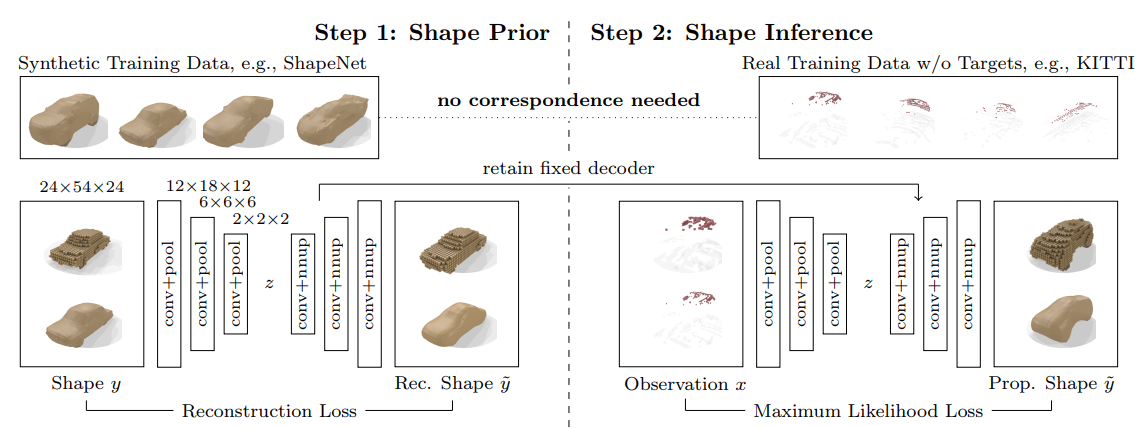
弱監督・無監督がホットスポット.
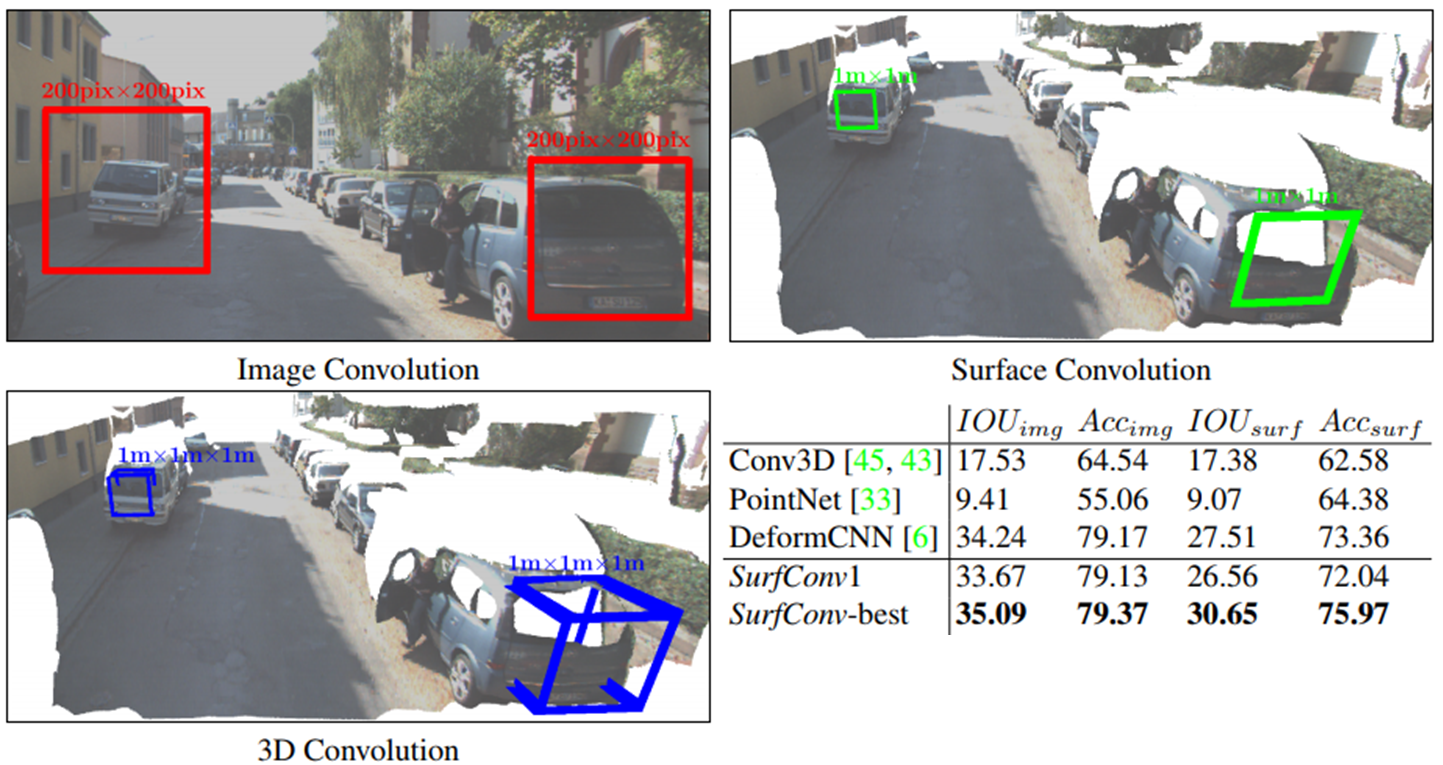
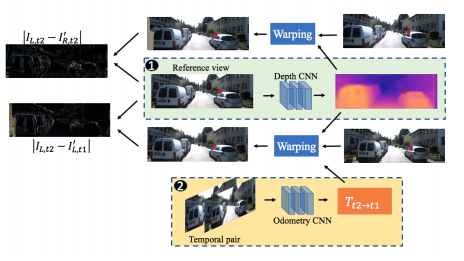
訓練データの複雑さに基づいてモデル容量を反復的に拡張するIG-CNNの提案。CNNは個人の検出だけでなく群衆の特徴を学び群衆密度マップを生成することができる。 しかし、多くのデータセットは群衆が一様ではないため疎の画像を高密度と予測してしまう。 提案したIG-CNNは、データセット全体で訓練されたベースのCNN密度回帰分析から始まり、 訓練データに応じて階層的なCNNツリーを作成していくことで細かく分類していくことである。 提案手法は群衆データセットで高いカウント精度を達成している。
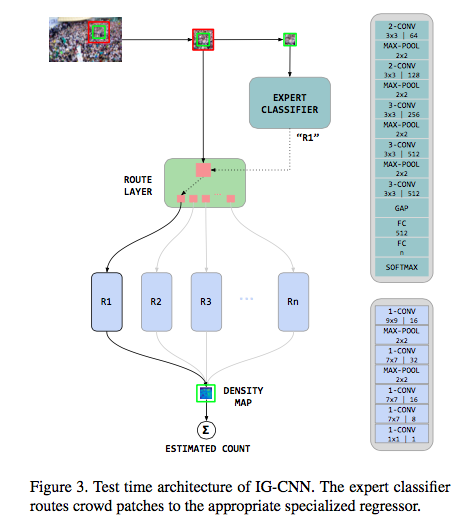
一回のスキャンだけで,かなり複雑な形状の物体を全周囲計測し,復元する3D復元システムの提案.
Light trapと名付けた,Time-of-Flight(ToF)式3Dスキャナの光を反射しまくる鏡部屋を使うのがキーアイデア.Trapの形状を入射光が複数回trapの中で跳ね返るように選択することで, 対象物体に対し,あらゆる位置・あらゆる方向から複数回数光が注ぐことになる. ToFセンサはそれぞれの光の移動距離を入手でき,Trapの形状は既知(予め計測しておく)なので, 全ての完全なパスが再現可能である. そのためのアルゴリズムを提案する.
通常すごく遮蔽する,球格子をかなり複雑な形状物体の例としたときに,シミュレーションによって99.9%の表面に光を当てられることを示す. また,ハードウェアプロトタイプを実装し, 様々な物体の大きさ,反射特性の物体に対し試してみた.


この手のシステムは反射屈折式(Catadioptric)で通っているようだが,問題となるのは一貫性,ラベリング問題(どの受容光が発射光だったのか)を解決しなければならないという困難さがある.
このシステムでは,ToF(パスの長さが分かる)を使っているので,ラベリング問題を解く必要がない.
StyleとContent、それぞれを抽出するEncoderにより得られた特徴を結合することによりStyle Transferを実現するEMDモデルを提案。学習の際、Style Encoderの学習にはStyleが一緒だがContentが違う画像を、Content Encoderの学習にはContentが一緒だがStyleが異なる画像のセットを用いて学習する。
Styleとして漢字のフォント、Contentとして漢字の種類を考え検証を行った。Style及びContentのセットは、枚数が多いほど精度がよくなるが増えていくと飽和して変わらなくなる。 ベースラインと比べるときれいな文字が生成されている。
Style Transferの一般化と書いてある割に、漢字という一部の地域でしか用いられていない文字でしか実験がされておらず他の対象に適用可能であるかが不明。(ロスの設計も漢字を前提とした重み付けがされている)そもそも学習画像のセットにStyleとContentが一緒であるという仮定が必要であり、これらが明らかであるという理由で漢字で実験したとあるように、漢字以外でやる場合StyleとContentとは何かを考えなければならない。
強化学習(Policy Gradient)を応用して大域最適化された物体検出器の学習を行う end-to-end なフレームワークの提案. 既存の物体検出器の学習に RoI 間の相互関係が用いられていないことに着目し, 検出された物体の mAP の総和を最大にする様な学習を行うために強化学習を用いている. 提案手法はネットワークの構造には依存しないので既存の多くの手法に適用が可能. 評価実験では, COCO-style mPA で Faster R-CNN を 2.0%, Faster R-CNN with Feature Pyramid Networks を 1.8% 向上させた.
この研究では,壁や閉塞空間を通した正確な人間の姿勢推定を説明している.これはWiFiの電波が,壁を通り抜け人体に反射する現象を利用している.このとき,人間は無線信号に対してアノテーションを行うことができないため,最先端のビジョンモデルを用いる.具体的には,訓練中に同期された無線信号と視覚情報を用いてビジュアルストリームから姿勢情報を抽出し、それを使用して訓練プロセスを誘導する.いったん訓練されると,このシステムは姿勢推定のために無線信号のみを使用する.人が視認できる状態でテストすると、信号ベースのシステムは、それを訓練するために使用された視覚情報ベースのシステムとほぼ同じ精度であることがわかる.

コンピュータビジョンにおいてはキーポイントから姿勢を推定する際にこれまでのカメラなどのセンサから情報を得るのではなく,高周波信号を用いている.モデリング面においては教師 - 学生ネットワークを用いている.そのため,このネットワークは具体的な信頼できるキーポイントのマップに関するより豊かな知識を伝達する.ワイヤレス面においては,時間の異なる時点で検出された複数の身体部分を費えることによって、壁の後ろの姿勢の不鮮明な説明を作成するRF-Captureと呼ばれるシステムとなっている.
教師あり学習において, test 時に同じ入力から異なる結果を出力可能にする Loss と学習方法 (DiverseNet) を提案. 提案手法はあらゆる教師あり学習の手法に対して適用が可能であり, 提案された Loss は GAN などで報告されている mode-collapse を起こしにくい. 複数のタスクに対して評価実験を行い有効性を確認した.
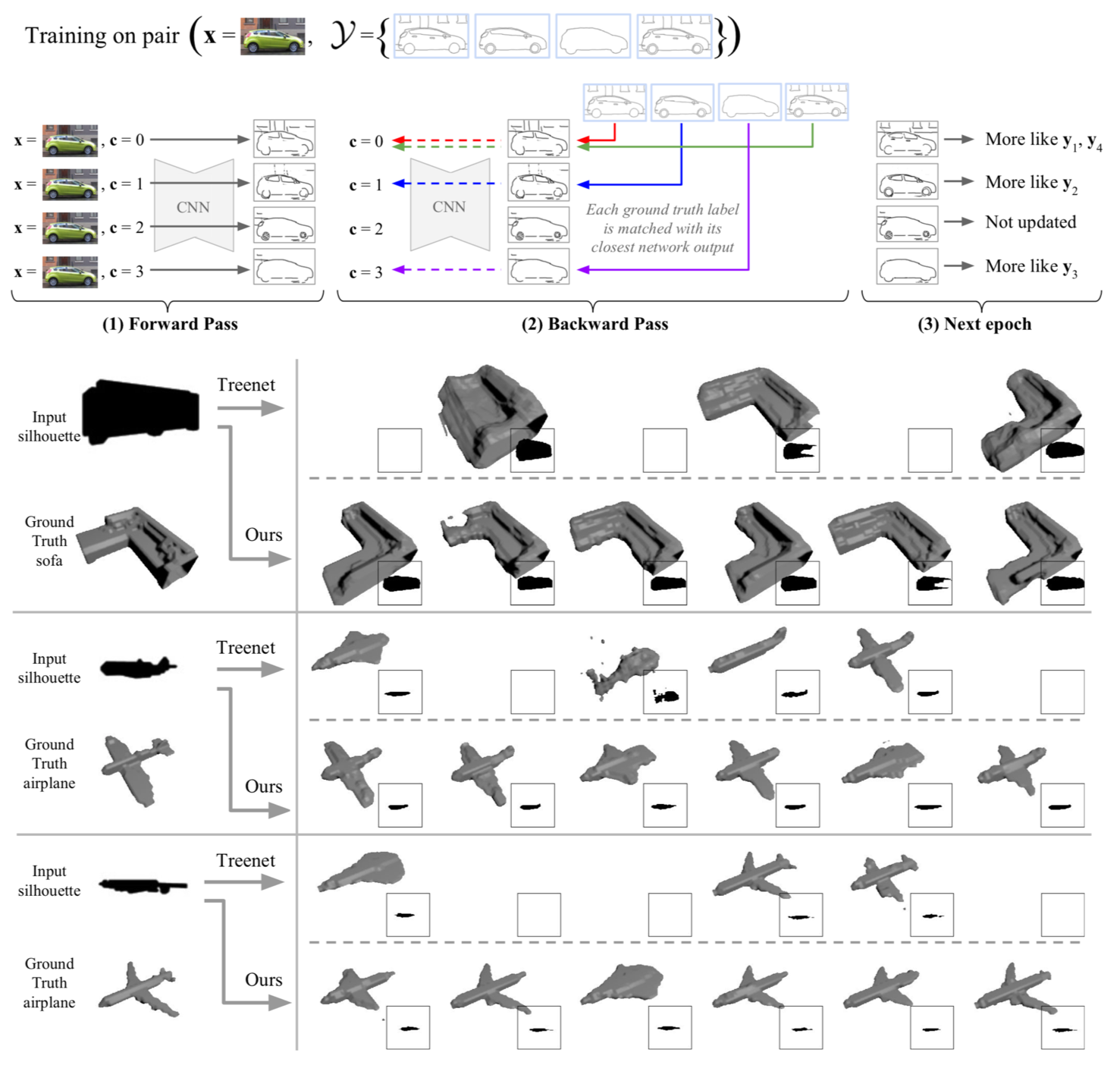
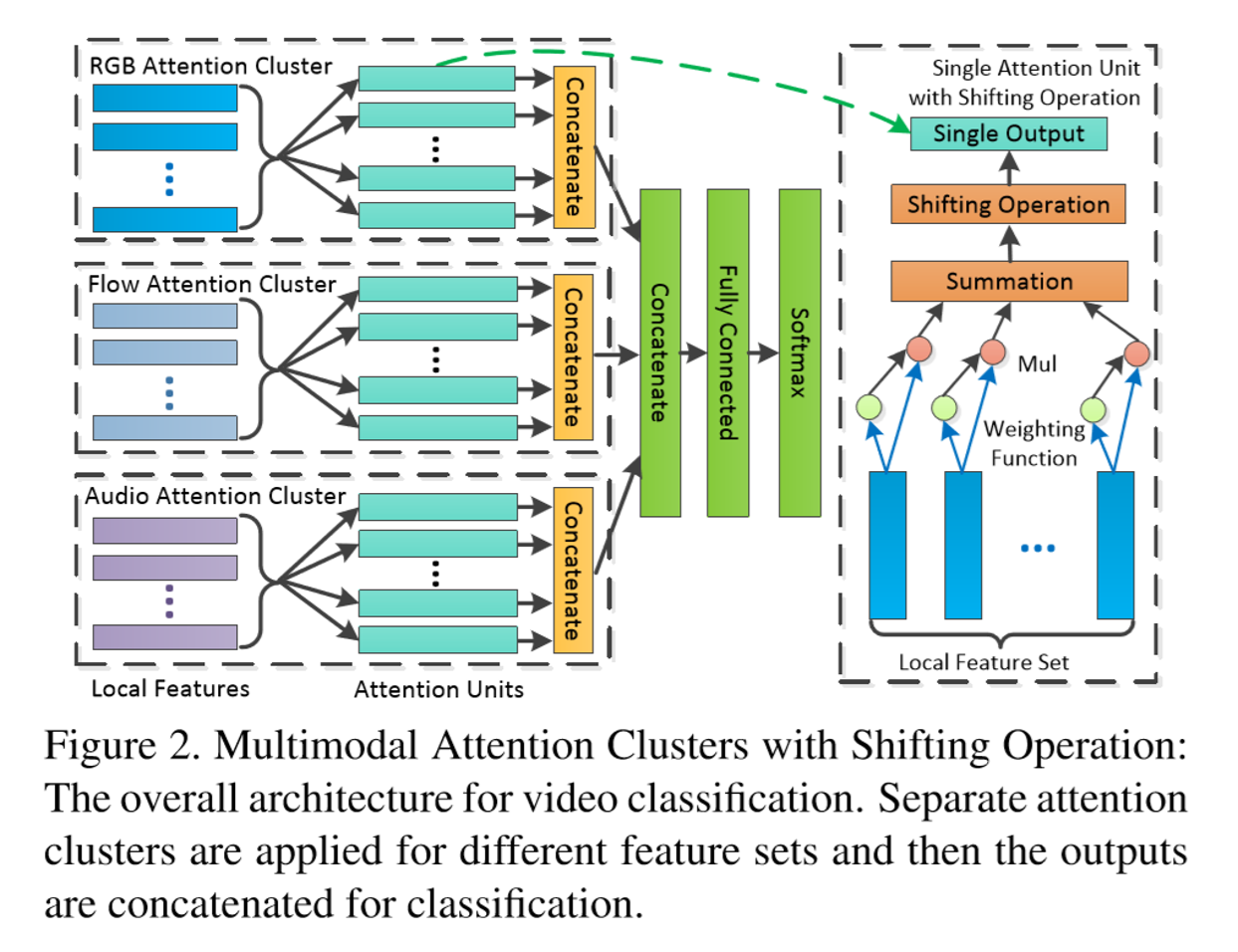
Ground-to-Aerial Geolocalization の研究. CNNを用いて局所特徴量を抽出した後, NetVLAD によって局所特徴量から大域特徴量を生成してマッチングを行う. また, 新しい Loss を提案し学習時間を短縮した. CVUSA dataset 等を用いて行った評価実験では既存手法に大差で優位な結果を達成した.
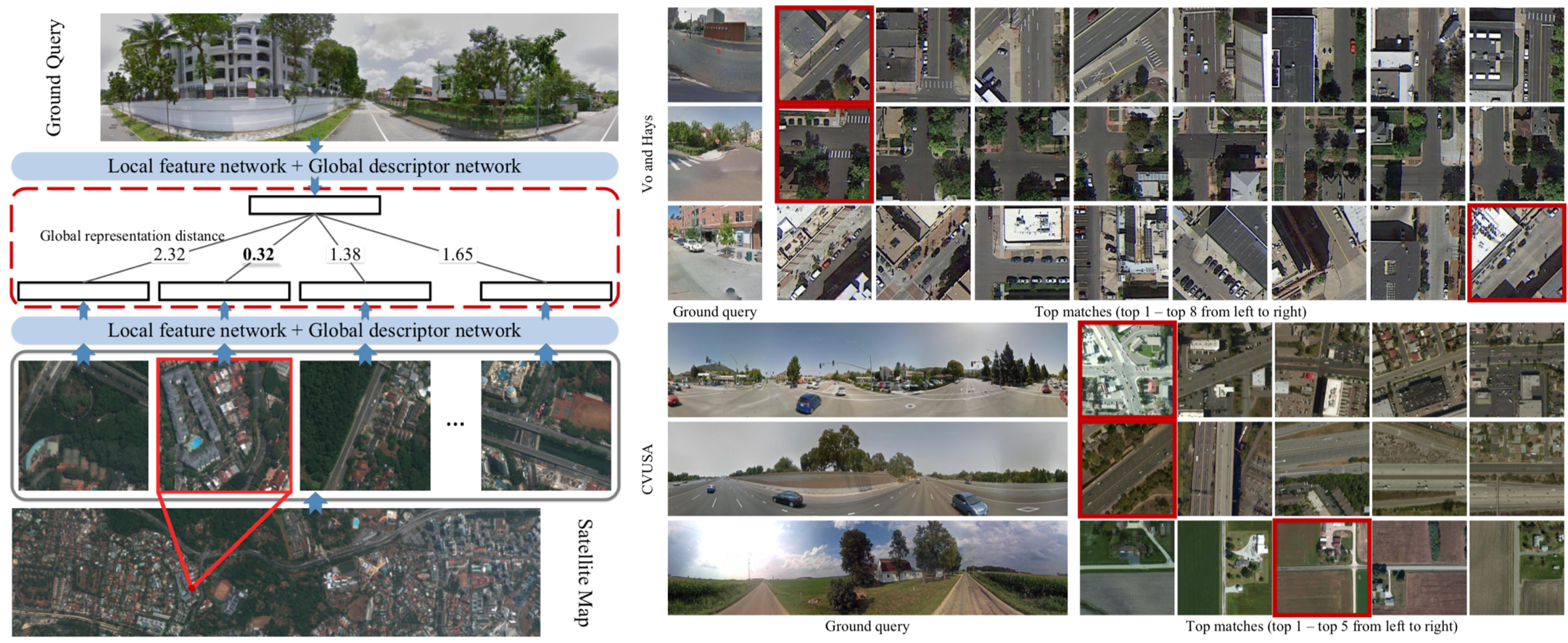
人手によるアノテーションを使用しない本当の意味での自己教師学習を行うために、合成画像の法線マップ、デプス、物体輪郭と実画像とのadversarial trainingを行う手法を提案。実画像に対して汎用的な特徴量が取得できたことを主張している。 輪郭線はキャニーフィルタによるエッジだが、これによって人がつける曖昧なアノテーションを緩和することができる。 デプスを推定することで高次元のセマンティックな情報やオブジェクトの相対的な位置を得ることが可能。 既存研究により法線マップとデプスのそれぞれの推定が良い影響を与えることがわかっているため、法線マップの推定も行う。 GANの学習において、ディスクリミネータの更新は実画像、合成画像に対するGANのロス、ジェネレータの更新は合成画像に対するGANロス、 3つのタスクの推定におけるロスを使用している。ドメインに不変な特徴料を得るために実画像を用いたジェネレータの学習も行ったが、 精度が良くなかった。
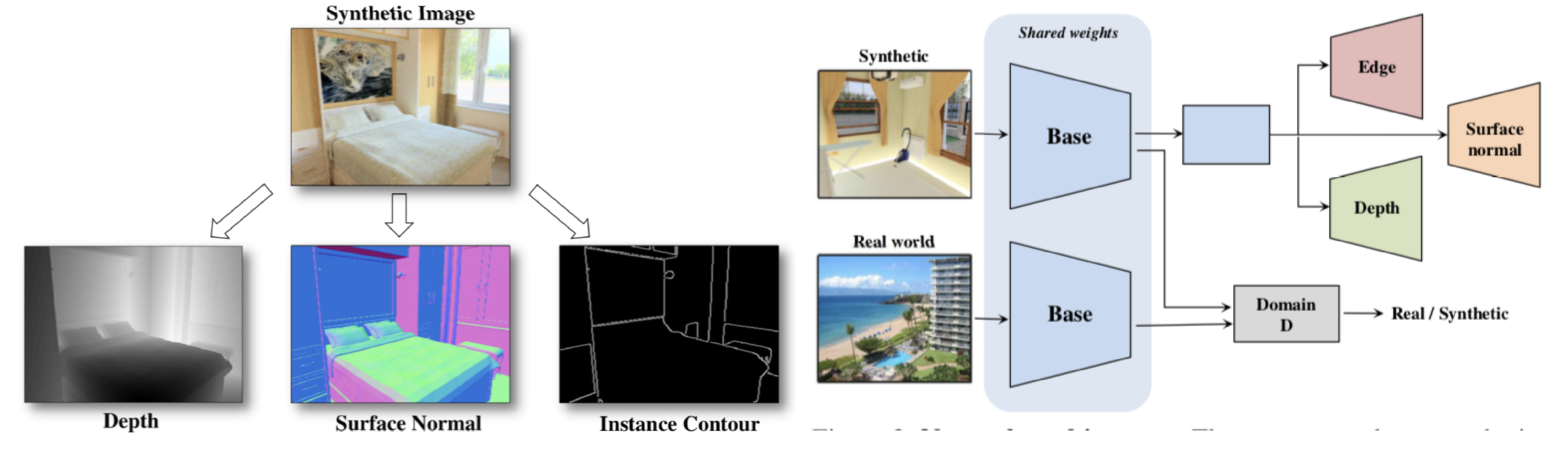
マスクなどから見えている顔領域のみを検出するPartial face recognition(PFR)をFCNで高速かつ高精度に行う手法を提案。トレーニング時には顔全体と顔が見えているパッチのそれぞれに対してパラメタを共有したFCNをで特徴量マップを適用し、 パッチ領域から得られる特徴量マップと同サイズのマップを顔全体からえられた特徴量マップからスライディングウィンドウによって複数個切り出し、 パッチから得られた特徴量マップとの比較を行う。 この比較のことをDynamic Feature Matching(DFM)と読んでいる。 DFMを行う際の工夫として、パッチから得られた特徴量マップを顔全体から得られた特徴量ウィンドウの線形和で表す際の重み、 パッチから得られた特徴量マップと特に類似している特徴量ウィンドウに対する重みの学習を行っている。
顔画像から年齢を推定する際に正確に年齢を推定するのではなく、ガウス分布を用いてある程度幅のある推定を行う手法を提案。大きなコントリビューションはロス関数としてガウス分布の平均値と分散に関するロスをとったことであり、 平均値はGTの年齢との差分をとり、分散は分布がよりシャープになるようにロス関数を設計する。 学習の際には上記2つのロス関数の他に1歳刻みの年齢をそれぞれクラスと見立てソフトマックスロスを取る。 分布を学習する既存手法と異なる点は、提案手法ではGTの平均値、分散を使用しない点である。
MRIのスキャンデータに対するセグメンテーションを、MRIのソース画像とセグメント画像のペアを使用せずに行う手法を提案。はじめにセグメント画像のみを用いてVAEを学習。 次に教師無しでセグメンテーションを行うためにdecoderの重みを固定してソース画像に対するセグメンテーションの推定を行う。
単視点動画に映っている物体を静的物体と動的物体に分離することで教師なしでデプス、オプティカルフロー、カメラ向きを推定する手法を提案。フレームワークは二段階で構成されており、 まずはじめにデプスとカメラ向きをそれぞれ独立に推定することで道路や街路樹などの静的物体のモーション情報を得る。 続いて静的物体との差分情報を使用することで歩行者などの動的物体のモーション情報を得る。教師無しの推定を行うため、 参照フレームから推定されたモーション情報の逆変換をターゲットフレームに適用し参照フレームを推定することで consistency lossをとることで精度が向上。
Shape Parsing の研究. 2次元画像, 3次元ボクセルから同じ形状を生成するプログラムを推定する. 学習のための2次元や3次元のLogoやCADモデルなどを含む synthetic dataset を作成・公開した. また, 教師データが無い場合でも強化学習を用いた学習が可能.
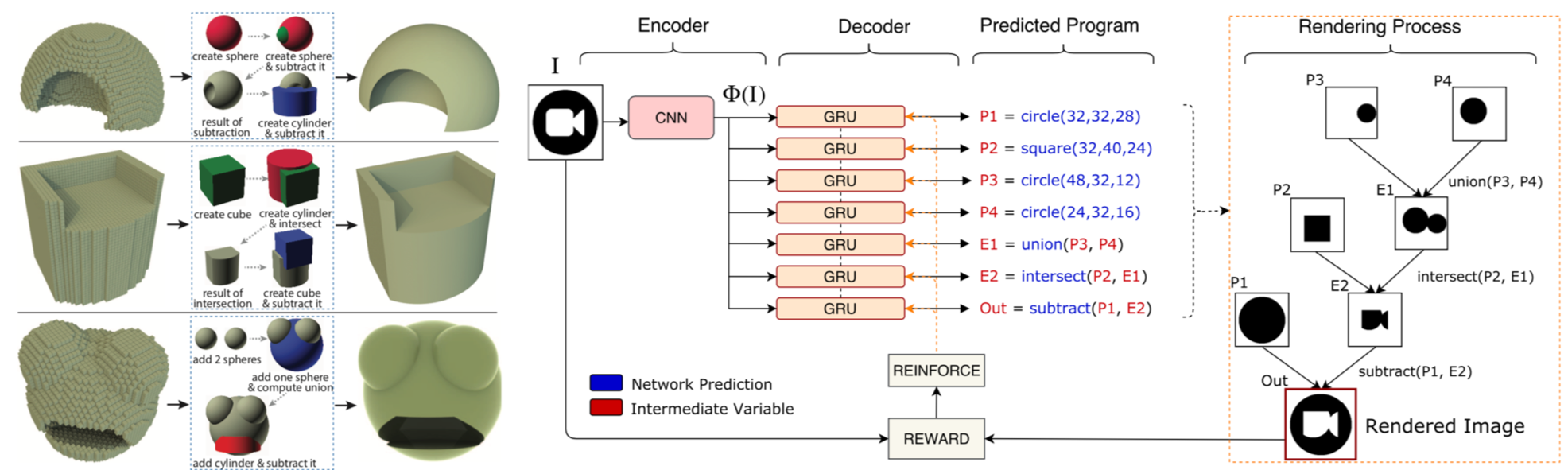
ラベル付けする人の評価尺度やcontextを考慮して画像の類似度を求めるContext Embedding Networksを提案した。クラウドワーカーによるアノテーションは、個人独自の評価尺度やコンテキストに影響される。 例えば、人物顔画像をクラスタリングする際にはある人は性別によってクラスタリングするが、別の人は表情によってクラスタリングしてしまうと考えられる。 そこで、workerと見せた画像(context)それぞれから、画像のどのような点に注目するかを表すattributeをAttribute Encoderにより求める。 画像の類似度は、2枚の画像それぞれに対してImage Encoderから得られる画像特徴を、attributeによる重みつきの類似度によって求める。
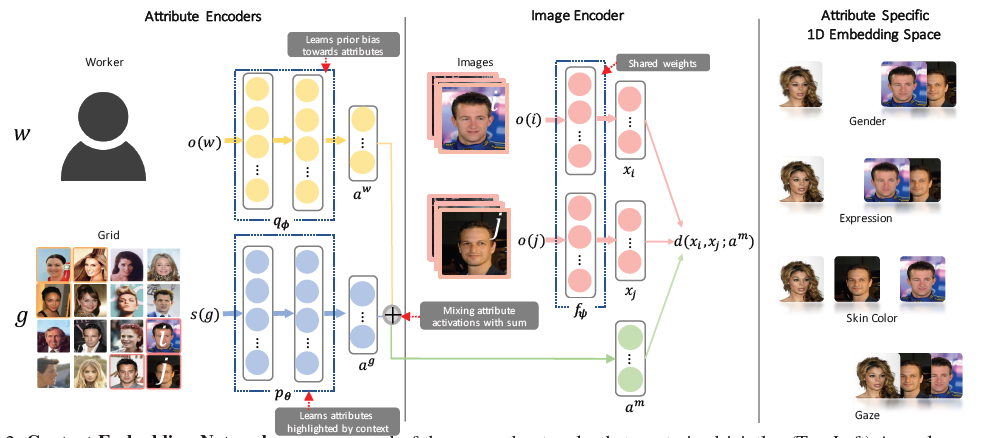
クラウドワーカーに応じた類似度の算出が可能になった。各クラウドワーカーがどのattributeに基づいて画像クラスタリングをしているかを予測することに成功した。
画像中のどの箇所がクラス分類に寄与するかを可視化する手法を提案。多くの手法は、クラス分類のタスクを学習することで重要な特徴を調べている。 しかし、識別への寄与が強い特徴が存在する場合ネットワークは強い特徴のみに注目してしまい、他の特徴は無視されてしまう。 医療画像からの病気の診断では、病気のステージを見極める、複数の要因が絡む病気を発見するなど無視されてしまう特徴を探すことは極めて重要である。 本研究では、Wasserstein GANを用いてある病気を発見する上で重要な領域を示したマップMを生成する。 病気のラベルがついた入力画像xに対して、x+Mが病気でないと判定されるMを生成するGeneratorを学習する。 その際、患者の個人性による画像の違いを考慮するためにL1正則化項をロスに加える。
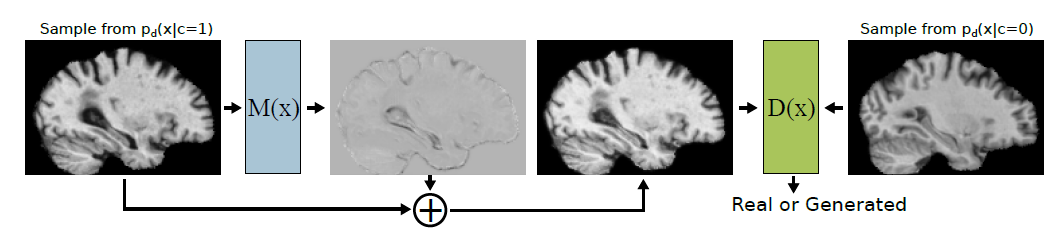
合成画像と実際の医療画像の2種類により評価した。従来の特徴を可視化する手法は、病気の際に見られる特徴のうち一部しか取れない、エッジなどの高周波情報が取れないという結果に対して、提案手法はこれら2つを改善した。 Normalized Cross Correlation(NCC)による数値評価では、ベースラインと比べ提案手法が最も良い数値を記録した。
1枚のRGB画像から人間の全身の3次元モデルを推定するEnd-to-Endのネットワークを提案した。DNNを用いた3次元モデルの推定は、膨大なアノテーションが必要となり現実的ではない。 そこで、画像からの2次元特徴の抽出と2次元特徴から3次元モデルの推定の2段階に分けることによりDNNベースの手法を実現する。 始めに、Human2DというRGB画像から2次元の特徴点及び人物のシルエットを推定する。 2次元特徴点及びシルエットから3次元モデルの推定には、SMPLという統計モデルを用いて作成した学習データにより学習を行う。 加えて、得られた三次元モデルから2次元特徴点とシルエットを取得し、画像から得られた情報と一致するかをロスに加える。
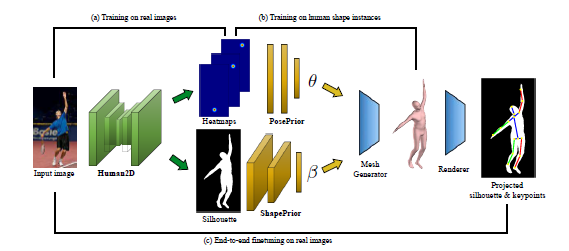
推定した3次元モデルの誤差を評価したところ、提案手法が最もground truthに近づいたことを確認した。1枚の画像に対して50msという従来研究と比べ大幅に高速化することができた。
ゼロショット学習のオープンな問題に取り組む上で,カーネルを利用したゼロショット学習の手法を提案する.
提案する手法は,回転とスケーリングが組み込まれているため,制約のないモデルでは,より自由度が高いために過学習を防止することができる.1枚目の画像はゼロショットカーネルの配置. 2枚目の画像は一般化ゼロショット学習プロトコルと新たに提案されたデータ集合についての評価. (tr)はtrain + testクラス,(ts)はテストクラスの平均トップ1精度,(H)はハーモナイズされたスコア,(Better than SOA)は提案手法が他の最先端の方法(表の上部)よりも優れているデータセットの数を示す.
tracking-by-detectionベースの手法は、(1)各フレームにおけるpositive sampleが空間的に重なった領域を取りやすいため、十分な見た目のばらつきを学習できない点と(2)positive sampleとnegative sampleの不均等さ(class imbalance)が顕著に出てしまうという点が問題である。本論文では、positive sampleのデータ拡張を行うため、GANを用いて長い時間のスパンで頑健な特徴を学習可能なVITALアルゴリズムを提案した。またclass imbalanceを解決するため、識別が容易なnegative sampleを取り除くためのhigh-order cost sensitive lossを提案した。
![]()
提案手法はCNNで抽出した特徴量に適用するマスクを複数(論文では9個)用意し、マスクを通じて重み付けられた特徴量に対して識別器Dが対象物体か背景かの二値分類を行う。学習時には識別器Dに最も悪い識別性能を出させたマスクを学習させる。テスト時には生成器Gは取り除いておく。また識別が簡単すぎる大量のnegative sampleのロスが合計されて大きくなってしまう現象であるclass imbalanceを、あまり学習に寄与しないようにする。
物体追跡タスクでは追跡対象の画像を1フレーム目においてのみ与えられるため、トレーニングデータの多様性が不足していることがDNNを適用する際の障壁となっている。そこで変形や遮蔽といった困難な環境下における正解サンプルを生成する手法(SINT++)を提案した。提案手法は他の物体追跡手法に取り入れることが可能である点も非常に重要である。
![]()
VAEを用いて追跡対象の多様体を生成し、その多様体局面上を移動させることで正解サンプルを増やすネットワーク(PSGN)と識別器の認識性能にクリティカルな領域を探すように遮蔽領域を決定する強化学習ネットワーク(HPTN)を用いて、正解サンプルの多様性を増幅させる。追跡器はSINTを用いているため、与えられた追跡対象の画像に対するオフライン学習も、追跡中のオンライン学習も行わない。
オプティカルフローのアノテーションが困難であることから、教師なし学習ベースのオプティカルフロー推定手法が提案されているが、十分な精度が出ていない。そこで問題とされている遮蔽と大きな動きに対応したネットワークを提案。教師なし学習ベースの手法では最も良い精度を出し、教師あり学習ベースの手法とのギャップを埋めた。
2枚の画像に対して、1枚目から2枚目へのオプティカルフローと、2枚目から1枚目のオプティカルフローを推定する。2枚目の画像と前者のオプティカルフローを用いて、1枚目の画像を復元する。復元した1枚目の画像のうち遮蔽が発生していない部分に対して、本物の1枚目の画像との差を損失として用いる。
物体追跡のためのオフライン学習ベースの手法は精度とスピードにおいて高いポテンシャルがあるが、追跡対象に適応させることは困難である。一方で、オンライン学習ベースの手法は計算コストとオーバーフィッティングが問題になっている。本論文では、Siamese NetworkにおけるCross CorrelationをAttentionで重み付けしたRASNet(Residual Attentional Siamese Network)を提案し、リアルタイムを超える速度(83fps)とSOTAを実現した。
![]()
Siamese NetworkにAttention Mechanismを導入した。Attention MechanismにはResidual AttentionとGeneral Attentionを含むDual Attentionと、Channel Attentionを導入した。Resiual Attentionは追跡対象に特化させるようにオンライン学習をし、Channel Attentionはチャンネルごとの特徴量の質を示している。
人間が一枚の静止画から動き情報を推定可能であることを受け、一枚の静止画から動き情報(フロー)の事前知識を得る手法を提案。具体的には動き情報の表現方法とU-Netの構造を変形させたエンコーダ・デコーダネットワークを提案。提案手法で得たフロー情報を利用することで、行動認識の精度が向上した。
動き情報を動きの大きさと角度(角度はコサインとサインに分解)の計3チャンネルで表現する。角度は周期的な構造であるが、三角関数を用いることでこれを避けることができる。損失関数は(1)フロー自体の損失と(2)動き情報のコンテンツの損失の和で構成される。動き情報のコンテンツは、ResNetをUCF-101データセット上で行動認識にfine-tuningさせたものから取得し、推定したフローと正解のフローから得られたコンテンツの差から損失を得る。
物体追跡タスクにおいて、Multi-Kernel Correlation Filter (MKCF)はKernelized Correlation Filter (KCF)のカーネルを複数にすることで識別性能を向上させているが、計算量がボトルネックとなっていた。そこで目的関数の上界を目的関数として再設定し、上から押さえるように最適化問題を解くことで、MKCFより高速(150fps)かつ高識別性能な物体追跡手法 (MKCFup)を提案した。
![]()
MKCFupは従来のMKCFの最適化問題における目的関数の上界を最適化する。上界を最適化する問題に再定式化することで高速かつ高精度な追跡を実現しており、DNNを使っていない数少ない論文の1つ。Correlation FilterがDNNベースの物体追跡に利用されているように、今後DNNベースの物体追跡手法が使用する可能性がある。
オフラインで学習させたDNNで得た特徴量を使用した物体追跡手法は、ターゲットの動画に特有の情報を使用していないことから、相関フィルタベースの手法より良い精度が出ていなかった。提案手法は大規模な画像ペアデータを用いて学習し、同じ特徴量抽出器を2つの入力に適応させて得た特徴量の類似度を比較するSiamese NetworkとFaster R-CNNで提案されているRegion Proposal Network(RPN)を組み合わせた上で、物体追跡をlocal one-shot detectionとして定式化することで、高速かつ高精度な追跡を実現した。
![]()
従来のSiamese Networkを利用した手法とは異なり、RPNを用いることで物体の変形に合わせた矩形領域を提示することによって高い精度を出すことが可能である。また物体追跡をlocal one-shot detectionとして定式化する。
深層学習の成功に反して映像解析では未だに手作りのオプティカルフローが使用されている。通常のオプティカルフローは、それを利用したCNNと独立してしまっている点と時間的・空間的計算コストが非常に大きい点が問題である。本論文では、オプティカルフローに代わる特徴をEnd-to-Endに学習可能なネットワーク(TVNet)を提案した。End-to-Endに学習可能になることで、特定のタスクに特化した動き特徴量を学習できる。
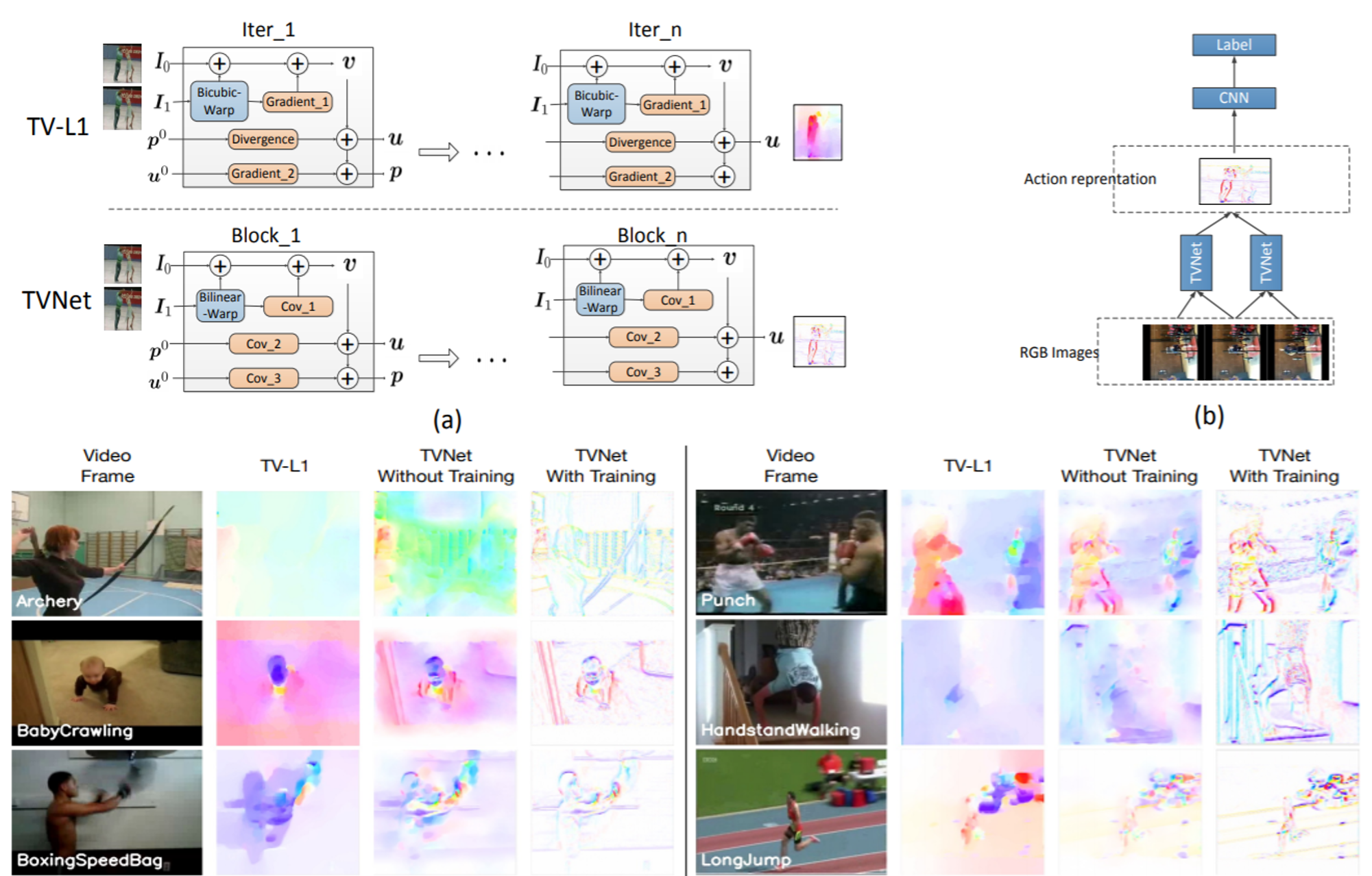
オプティカルフロー抽出手法の1つであるTV-L1をDNNにカスタマイズさせた。End-to-Endのネットワークにすることで、フロー抽出後のタスクから得られた誤差を伝搬することができるため、特定のタスクに特化した動き情報の抽出が可能となっている。
従来のCorrelation Filterベースの物体追跡手法は現在のフレームの見た目しか考慮できておらず、フレーム間の情報や動きの情報を考慮していなかった。本論文ではフロー情報を直接的に考慮することで時間変化に関する情報を考慮することが可能な物体追跡手法を提案した。
![]()
通常のネットワークに対してフロー情報を追加しただけではなく、Spatial AttentionとTemporal Attentionも提案した。これにより空間情報と時間情報を効率的に考慮することが可能となった。
tracking-by-detectionベースの物体追跡手法は識別器の不完全性からオンライン自己学習するため、自己学習のループでドリフト問題が発生する。そこで学習する識別器に対する教師が必要であるという発想から、相補的に教師になるアンサンブル学習ベースの手法が提案されている。しかし、アンサンブル学習ベースの手法は、各識別器が互いに重複した領域を対象にする冗長性が発生する。本論文ではその冗長性を軽減することが可能なリアルタイム物体追跡手法(DEDT: Diversified Ensemble Discriminative Tracker)を提案する。
![]()
DEDTは高い適応性と多様性を持つ識別器群であるCommitteeモデルと長期記憶を持つAuxiliaryモデルからなり、Committeeモデルが不明確な回答を出した入力に対しては、Auxiliaryモデルが代わりに回答する。Committeeモデルは自身が不明確な回答をしたデータを用いて学習する。またこれまでのデータから不明確な回答になるようなデータを人工的に生成し、そのデータにおけるエラー率が、推定時に冗長な結果が得られたデータのエラー率より小さくなるまで繰り返し、更新することで、冗長性を回避する。一方でAuxiliaryモデルはCommitteeモデルより更新頻度が低くすることで長記憶性を持つ。
Correlation Filterベースの物体追跡手法は識別性と信頼性を学習するべきであるが、従来手法は識別性に着目したものが多く、Bounding Box内の予期されない顕著な領域に影響を受ける可能性がある。本論文では信頼性の高い領域に特に着目して物体追跡を行う手法(DRT)を提案した。
![]()
提案手法は識別性を保持するbase filterと信頼性を保持するreliability termのアダマール積を取ることで、より信頼性の高い領域に着目する。目的関数には学習サンプルの分類誤差に関する項と、局所応答に一貫性を持たせる制約項、L2ノルム正則化項からなる。
コンテキストを考慮したCorrelation Filterによる物体追跡手法を提案した。カテゴリごとに事前学習したオートエンコーダーのエキスパートを複数用意し、その中からコンテキストネットワークが1つ選択する。
![]()
リアルタイム性が重要である物体追跡タスクでは、リアルタイムにDNNを学習することは困難である。本論文では事前に各物体のカテゴリ別に学習したオートエンコーダーを用意し、その中から1つを選択することで、ある程度既に特定の物体に特化したネットワークを使用できるため、再学習の必要性を軽減することができる。
物体追跡手法の1つであるSiamFCは効率的なオフライン学習を行うことで、非常に高い識別性能を持つが、追跡対象の見た目の変化に弱かった。そこで、見た目特徴量とセマンティックな情報を別々に抽出する2つのSiamese Networkを利用することで、追跡対象の見た目変化にも強い物体追跡手法を提案した。セマンティックな情報を抽出するネットワークは画像分類タスクで学習させることで、見た目の変化に頑健な特徴量を抽出することが可能となる。
![]()
推論フェーズでは、それぞれのネットワークで別々に追跡対象画像と探索画像の類似度を計算し、それを統合する。セマンティックな情報を抽出するネットワークは、見た目変化には頑健ではあるが、識別性能は不十分であるため、与えれた追跡対象に反応するチャンネルの重要度を増やすChennel Attentionを追加する。これによって追跡対象に適応する最低限の機能を追加している。
画像グループ内での関連性や相関関係などを考慮し、キャプションを出力するGroupCapの提案。まず、個々の画像でvisual tree parser(VP-Tree)を構成し、文字ベースで意味の相関を構築。次にツリーの関係から、画像間での関連性と多様性をモデル化。この制約関係をもとにLSTMでキャプション生成。これらをトリプレットロスとしてend-to-endで学習する。
従来のイメージキャプショニングでは、単一画像に対して説明文を生成している場合がほとんど。これらはオフラインで学習し、画像間での視覚的構造関係を無視して推定している。本手法のグループベースの手法によって、グループ画像内での構造的関連性や多様性を協調して学習することでキャプションの正確性を向上させる。
動画中の物体にセグメンテーションを行うタスクにおいて、フレーム間処理をモーションキューによって改善するMoNetの提案。オプティカルフローを利用し、その近傍の表現を統合することにより、ターゲットフレームでの表現を強化する。これにより、時間変化におけるコンテキスト情報を活用することができ、外観変動やモーションブラー、物体の変形に頑健となる。また、動作の一致性を考慮することで、ノイズの大きいモーションキューを前景または背景に変換し、精度を向上させている。
セグメンテーションの改良と、フレームごとの学習を行うという観点からモーションキュー(オプティカルフロー)を利用している。これによって、前景と背景の分離する制度を向上。 また、distance transform layerを提案し、動作が一致しないインスタンスと領域をフィルタリングすることができる。
Learning-based Multi-View Stereo の研究. 任意の枚数の画像から, 視差 Map の推定を行う(推定結果は入力の順番に依存しない). また, ネットワークの学習のため, 新しい synthetic datasets (MVS-SYNTH dataset) を作成・公開した. ETH3D を用いた評価実験では DeMoN を上回り, COLMAP と同等の結果を達成した.
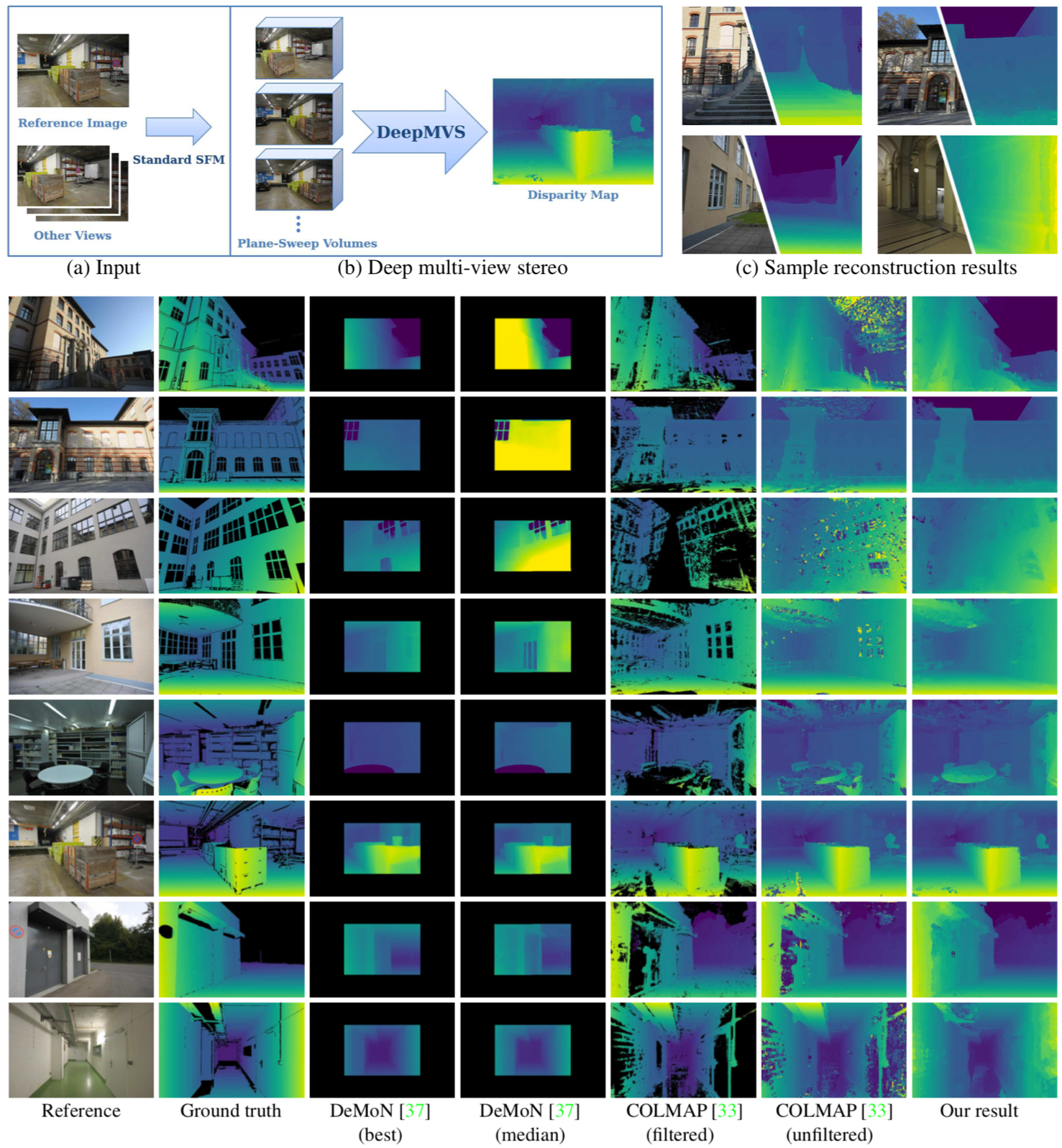
RNNは強力なシーケンスモデリングツールであるが,高次元の入力を扱う場合,RNNのトレーニングはモデルパラメータが大きくなるため計算に時間がかかるという問題がある.これは,RNNがビデオや画像キャプションのアクションレコグニションなど,多くの重要なコンピュータビジョンのタスクを行うことを妨げる.この問題を解決するためにRNNのパラメータを大幅削減し,トレーニング効率を向上させるコンパクトで柔軟な構造「Block-Termテンソル分解(BTD)」を提案し,これをBlock-Term RNN (BT-RNN)と名付ける.テンポトレインRNN (TT-RNN)のような他の低ランク近似とBT-RNNを比較すると,同じランクを使用する場合,より簡潔でより良い近似が可能であり,より少ないパラメータで元のRNNに戻すことが可能である.ビデオ,画像キャプション,画像生成のアクションレコグニションを含む3つの困難なタスクに対し,BT-RNNは予測精度と収束速度の両方でTT-RNNや標準のRNNより優れていると言える.この研究において,BT-LSTMはUCF11データセットのアクションレコグニションのタスクで15.6%以上の精度向上を達成するために,標準LSTMより17,388回少ないパラメータを使用した.
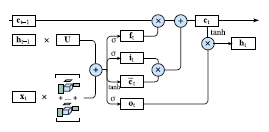
BTDは最適なTT-rankの設定を見つけることを困難にする代わりに次のような利点がある.・Tucker分解は異なる次元間の相関関係を表し,より良い重み分担を達成するためにコアテンソルを導入している。 ・コアテンソルのランクを等しくすることができ,異なる次元での不均衡な重みの共有を避けることができ,かつ入力データの異なる順列に対して頑強なモデルを導くことができる. ・BTDは,複数のTuckerモデルの合計を使用して高次テンソルを近似し,大きなTucker分解をいくつかのより小さいモデルに分割し,ネットワークを広げ,表現能力を高めることができる. 一方で複数のTuckerモデルは、,ノイズの多い入力データに対してより堅牢なRNNモデルを導く. 結果として,BTDを使用してRNNの入力非表示重み行列の接続をプルーニングすることにより,パラメータの数が少なく,フィーチャディメンション間の相関モデリングが強化された新しいRNNモデルが提供され,モデルトレーニングが容易になり,パフォーマンスが向上した.ビデオ行動認識データセットの実験結果は,BT-RNNアーキテクチャが数オーダのパラメータを消費するだけでなく,標準的な従来のLSTMおよびTT-LSTMよりもモデル性能を向上させることを示していると言える.
動画内のいつ行動が行われたかのTemporal Action Proposals(TAP)とどのような行動が行われたかのキャプションを行うタスクにおいて,self-attentionを用いて既存手法を改善する.
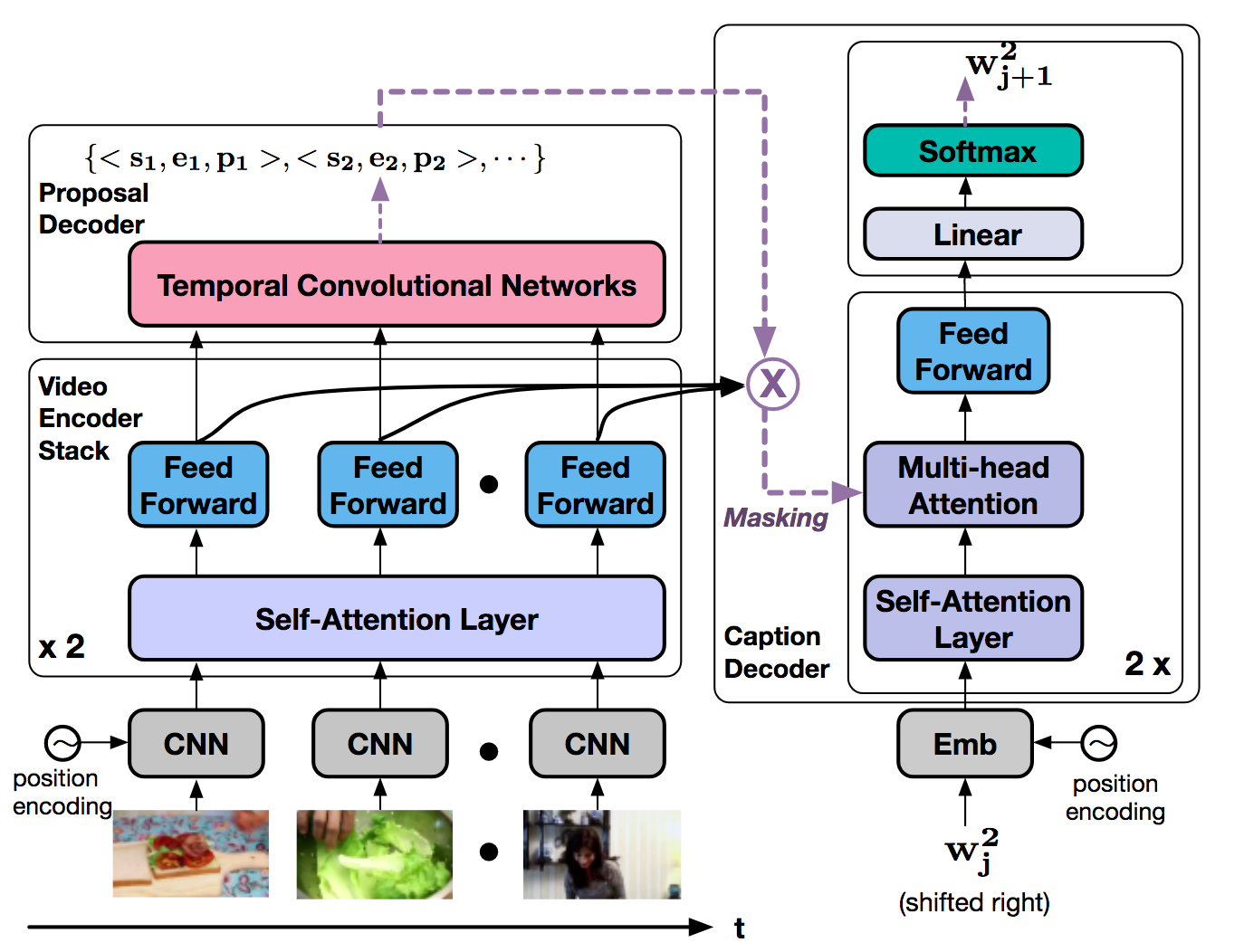
ActivityNet CaptionsとYouCookIIでキャプションの評価を行い,METEORスコアが10.12と6.58であった.
SoTAではないが,時間的なイベントの検出とイベントのキャプショニングをEnd-to-Endに行う手法であること.また,このようなタスクで初めてのRNN-basedでは無い手法を提案したこというところが新規性.
・CNNは画像処理の様々なタスクをこなすうえでとても有効だが,ネットワークのストレージにかなりのコストを要求するため,展開が制限される.2値化フィルタを用いたCNNの移植性向上のための新しい変調畳み込みネットワーク(MCNs)を提案する.MCNでは,end-to-endフレームワークにおけるフィルタ損失,中心損失,ソフトマックス損失を考慮した新しい損失関数であるM-フィルタを提案する.
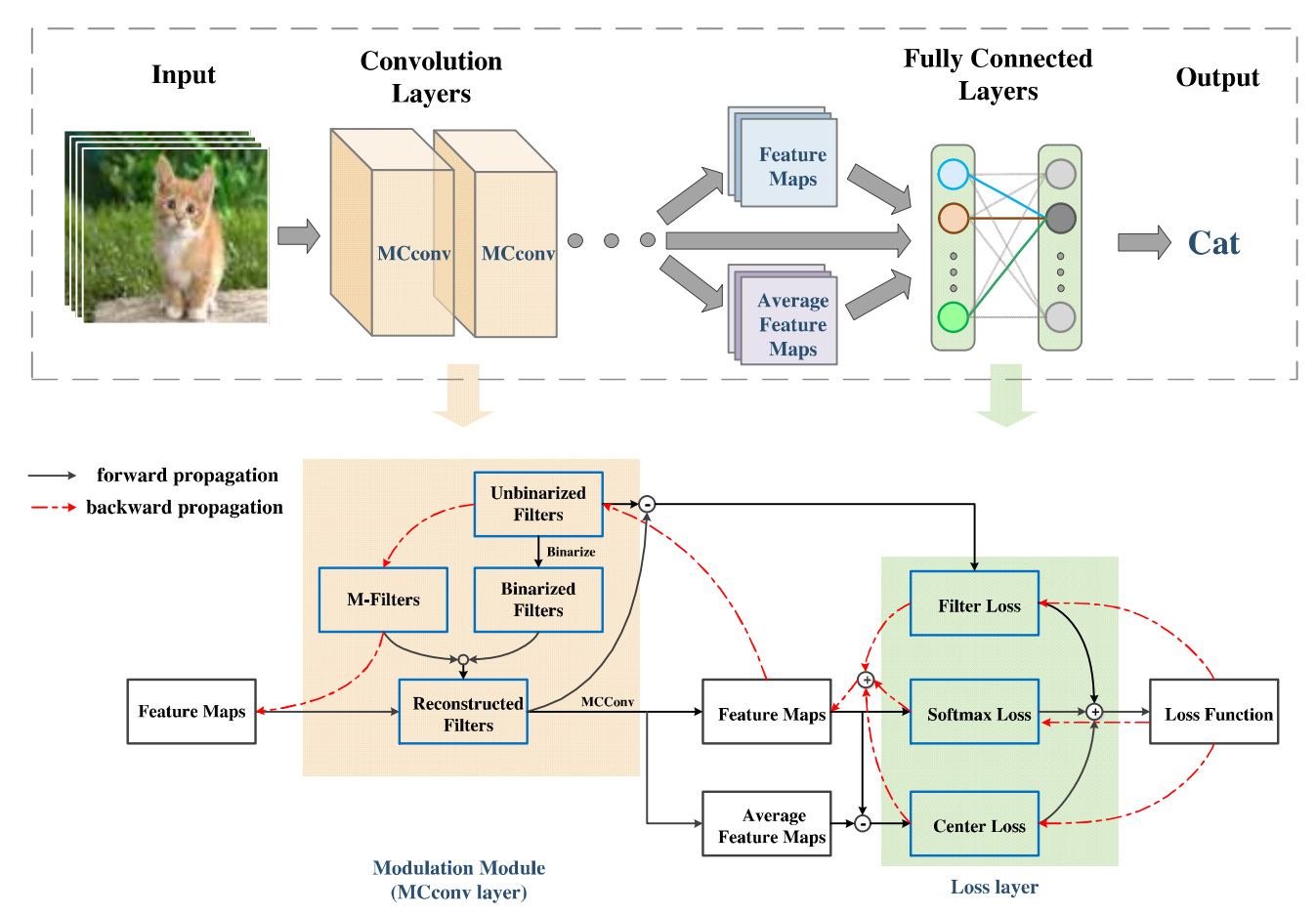
・非二項フィルタを復元するために,M-フィルタを導入しネットワークモデルを計算するための新しいアーキテクチャを導出する.MCNは完全精度モデルとは対照的に,畳み込みフィルタの必要な記憶スペースのサイズを32倍に縮小することができ,最先端の2値化モデルよりもはるかに優れた性能を達成した.また,MCNは完全精度のResentsおよびWideResentsと同等のパフォーマンスを達成した.
3D ground truthの存在しないデータに対し人間の関節の奥行きデータの監視信号を使用することを提案。人体関節の奥行きを用いて3Dの姿勢推定をConvNetsで学習すると正確な関節座標で学習結果を得ることができる。 通常の深さ注釈をもつ2Dポーズデータセット(LSPとMPII)はConvNetsの学習に容易に組み込むことができるため、 ポーズデータセットを拡張させることにより3Dの姿勢に対する序数の深さ正確なものにし、 標準のベンチマークでstate-of-the-artを達成した。
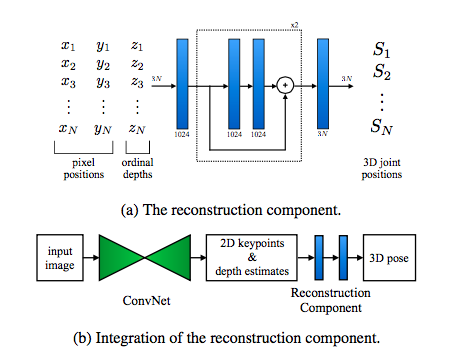
なめらかに早送りするという,ビデオ要約の新たな形を提案.
新しい適応的なフレーム選択手法を提案.重み付き最小値再構築問題として定式化. そこに,スムーズなフレーム遷移の手法を組み合わせる. 通しで見るとなめらかに見えるようにフレームを落とす.
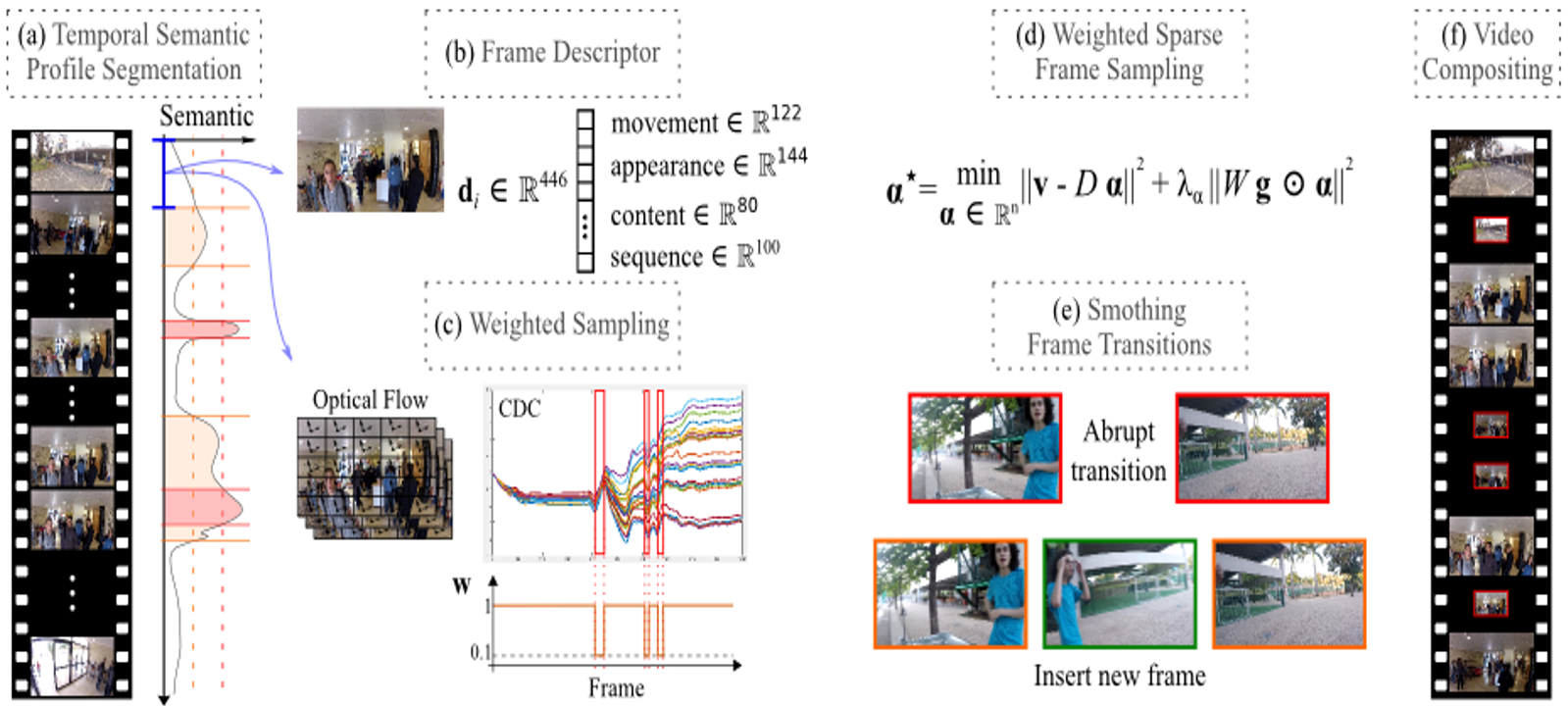
問題設定が面白い.流行りのビデオ要約の流れを汲みつつ,意識的に新しい枠組みを提案している. しかも十分実行可能と思われる問題である.想定される成果の見栄えもよい. 解き方もちゃんとしている.
画像で感情分析を行う研究.従来法は全体的な画像特徴からセンチメント表現を学習していたが, 本研究では局所特徴もとらえるようにした.
弱教師付き二つ組CNNによる.(1)感情に特定的にソフトマップを検出するFCNN. 画像レベルのラベルだけ必要にしたので,画素レベルアノテーションのようなアノテーション負荷が低くて済む. (2)ロバストなクラス分類のために,深層特徴を使い,感情マップを2つ組することによって,全体・局所情報の両方を活用. そして,これら2つを統合してEnd-to-Endで最適化できるようにする.
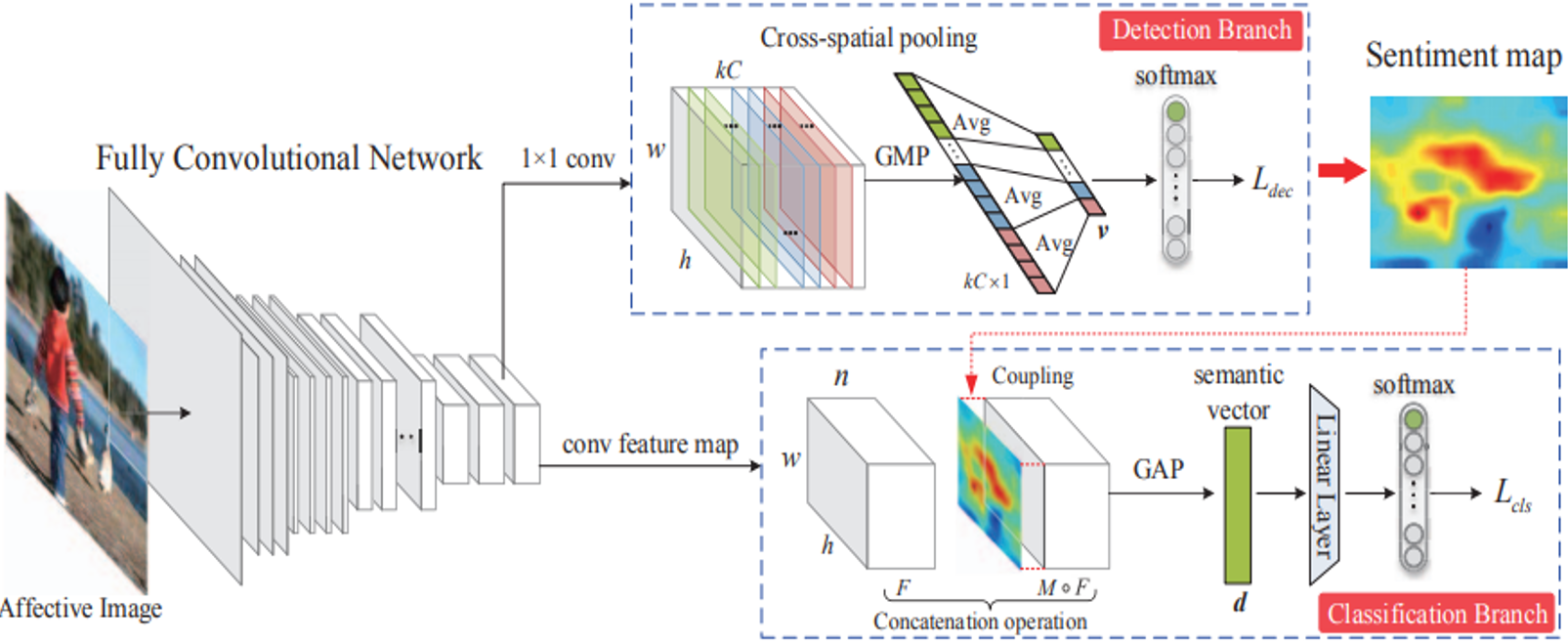
より詳細に画像を見るように設計した.その結果,6つのベンチマークで評価を行い,SOTA性能を達成.
著者らIBMが開発した100万個のノードが伝達しあうニューラルネットワークを模倣したプロセッサ「TrueNorth」を使った, 新しいカメラ「Dynamic Vision Sensor」を使ってステレオしてみた論文.
Dynamic Vision Sensorは,通常カメラのフレーム撮影方式ではなく,イベントベースに,各画素が非同期で撮影するという新たな撮影方式のセンサである. これにTrueNorthを組み合わせれば,完全にグラフベースで,配列などのあらゆるデータ構造無しに フォン・ノイマン型計算モデルの計算が可能である.
これにより,2000fpsの視差マップ生成を達成.通常のカメラではとらえられない急激な変化をとらえることが可能. しかも200倍省エネ.

上記参照.
ビデオキャプショニングの話題.Long-Termのマルチモーダルな依存性のモデリングと 文脈的ミスアラインメントがあるのに対し, (1)メモリモデリングするのは Long-Term系列的問題に対して 潜在的な利点がある (なにそれ), (2)視覚的アテンションにおいてワーキングメモリは主要素, という二点の事実を考慮した, Multimodal Memory Modelling(M3)を提案. LSTMの外部に視覚-テキスト間共有メモリを持ち,Long-Termな視覚-テキスト間依存性をモデル化する.
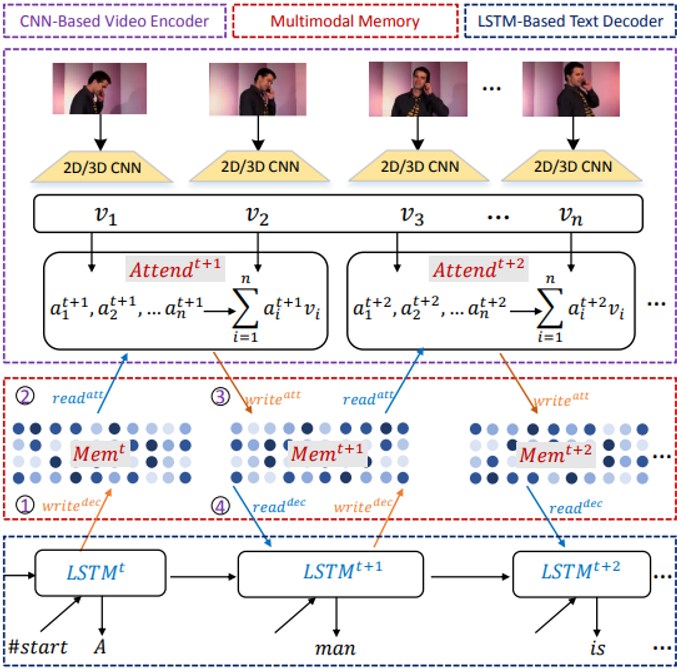
MSVD,MSR-VTTで評価し,BLEU,METEORにおいてSOTA性能.
画像における静的なSaliency Modelを,動的なビデオのSaliencyの予測に使う手法.この著者らは,前回に写真内に写っている人の注視(Attention)をCNNのAttentionと組み合わせるというShared Attentionに関する論文を出していたが, 今度は写真を撮る人・シーンに映っている人のShared Attentionについて取り組んだ.
マルチストリームCNN-LSTM構造を提案.これはSoTAなSaliencyをDynamic Attentional Pushに拡張する.
4つのステージからなる.Saliencyステージと,3つのAttentional Pushステージ.この複数ステージ構造は,Augmenting ConvNetに従っている. ConvLSTMの補足(complementary)と時間変化出力組み合わせで学習. 拡張したSaliencyと,ビデオにおける「見ている人」修正パターンの間のRelative Entropyの最小化を行う.

動画データセットHOLLYWOOD2,UCF-Sport,DIEMにおいて,SoTAな時空間Saliency推定性能を達成.
Dense Video Captioningの話.イベントの発生時間のプロポーザルと,それぞれのイベントにおける文章生成の両者を結合的にEnd-to-Endで学習する, Descriptiveness Regressionを提案. シングルショット検出に組み込む.これは文章生成を経由したプロポーザル時間ごとの説明的複雑性を推論する. これが時間定位の調節につながるらしい. キャプショニングと検出の結合・汎用最適化をするところが他手法と異なるらしい.
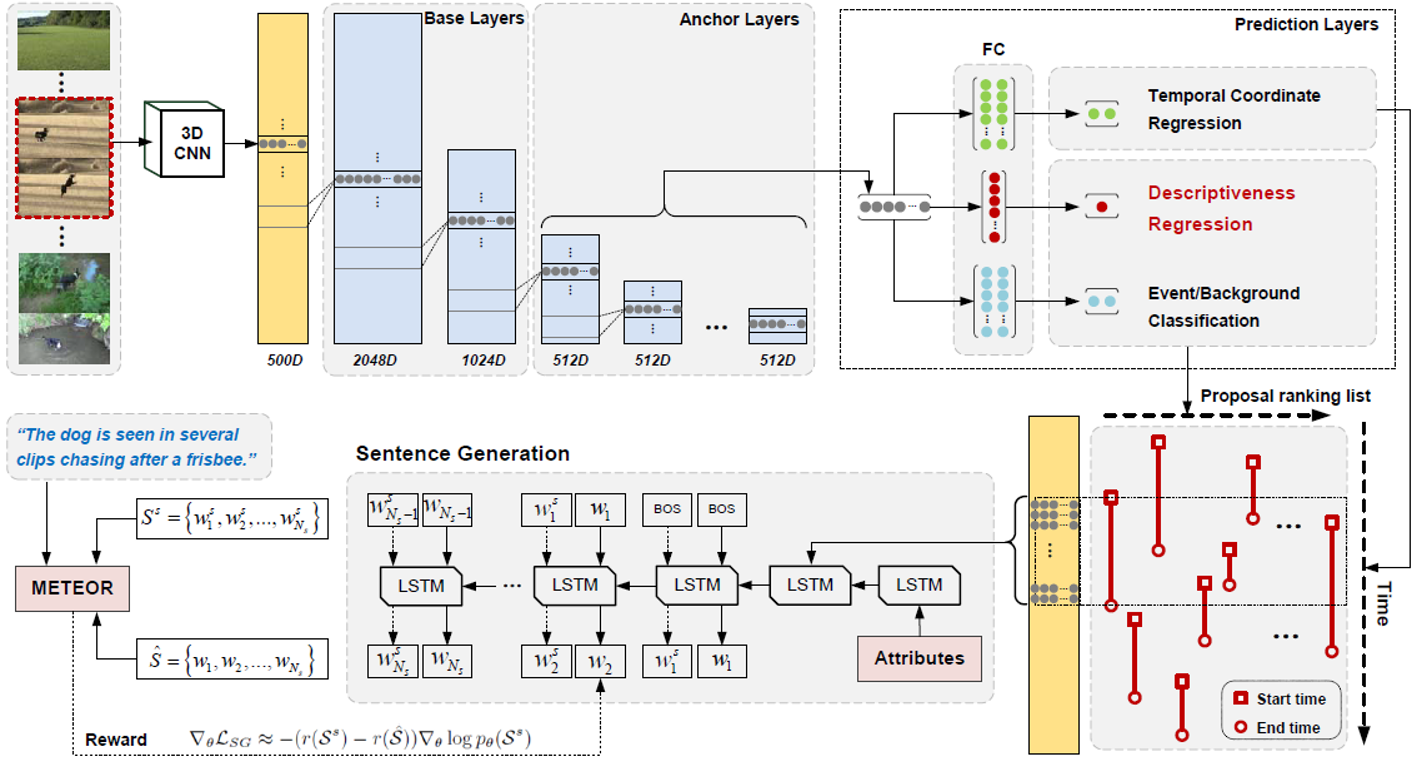
動画データセットActivityNetにおいてSoTAを達成.著者らはMETEORで12.96%出たのがすごいと言っている.
「音から手の動きは生成可能か?」バイオリンやピアノ演奏の音声を入力すると,アバターが演奏しているかのようにアニメーションするようなスケルトンの推定を行う手法を提案. 結論:できる.
実際ちゃんとやるにはいくつかアドホックな工夫が必要なようで,詳細はおのおの論文を確認してもらいたい.学習時に使うスケルトンデータはYouTubeのリサイタル動画からOpenPoseやMaskRCNNを駆使して生成する. 入力音声からこの手法で 13次元ベクトルに変換し,さらにその時間差分や音量エネルギーを足した28次元ベクトルにする. これから上半身のスケルトンの時系列を生成するLSTMを作り, スケルトンにアバターを着せてアニメーションを作成する.
アプリケーション枠らしく,見た目の良さがあり,また実装上の困難と解決についてちゃんと書いているのが評価されたものと思われる. アプリケーションとして利用するに当たって,どれだけうまくいけるのかが窺い知れる資料として 貴重に思われる.
Facebookでの研究.ユーザのこれまでのハッシュタグから,一意に同定できない意味の単語のハッシュタグでもユーザが意図した画像検索ができるようにした. 画像のDeCAFを取り,ユーザの履歴特徴,ハッシュタグ特徴を埋め込んだ3次テンソルを構成,多クラスロジスティック関数などで評価する.
MLPによる手法よりこちらの方が良い性能を示した.Top1で43.7%,Top10で72.12%のAccuracy.
3D部屋レイアウトとその2D画像との合成の話題.
Spatial And-Or Graph (S-AOG) ※ で屋内シーンを表現する.終端ノードは物体エンティティ(部屋とか家具とかその他).
終端ノードに対し,マルコフランダム場(MRF)を用い, 人間の文脈で関係性をエンコードする. 屋内シーンデータセットから分布を学習し, モンテカルロマルコフ連鎖(MCMC)を使って新しいレイアウトをサンプルする.

3つの視点で有効性を確認.
ドローンのようなサイズ,重さ,力が制約されたプラットフォームでも,3D自己位置同定を高速に行えるフレームワークを提案. 点群データの混合ガウス分布(GMM)表現による圧縮をキーアイデアとしている.
デプスセンサのデータと,オンボード姿勢参照システムからピッチとロールを得る.データをGMMで表現した尤度を使って,複数仮説パーティクルフィルタにより定位.
CVPRでは,高速性・省メモリに関するトピックに興味があるかもしれない.SLAM系はICRAでは大変多く議論されている話題だが,逆にCVPRだとアプリケーション枠で 通る可能性があるかもしれない.
3Dメッシュの変形に関して,Variational AutoeEcoder(VAE)を使ってみたという研究.可能な変形の確率的潜在空間の探索を行う. 学習は簡単で,学習データも少なくて済む(どれくらい?) 事前分布を代替することで,異なる潜在変数の顕著性(Significance)を柔軟に調節可能な拡張モデルも提案.
形状生成,形状補完,形状空間埋め込み,形状探索においてSoTA越え.
DID-MDN (density-aware multi-stream densely connected convolutional neural network-based algorithm) と呼ばれる、画像内の雨量密度推定と雨除去を行うアルゴリズムを提案。雨のストロークをより良く特徴づけるため、multi-stream densely connected de-raining networkでは異なるスケールの特徴量を効率的に活用する。また、雨密度ラベル付き画像を含むデータセットを新たに作成した。このデータセットを学習に使うことにより、state-of-the-artな手法を超えることができた。

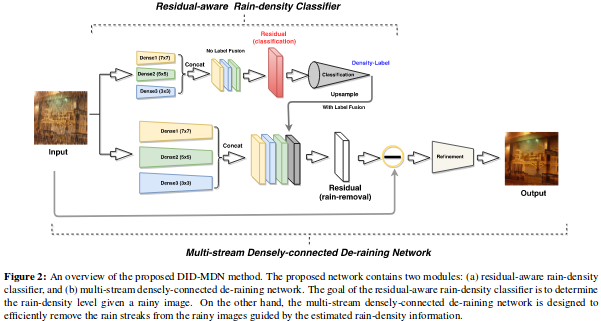

PSNRとSSIMにより雨除去の性能を評価した。比較に使用した手法、および、結果は右図の通り。 右図におけるTest1とTest2は、使用したテストセットが異なることを表している。
オクルードされている物体の全体像を推定するため、SeGANを提案。SeGANは物体の見えていない領域のセグメントを生成することができる。また、occluderとoccludeeの関係も推定することができる。さらにSeNetはcategory-agnosticでありカテゴリー情報を必要としない。データセットにはDYCEを使用。
右図に示すように、他のセグメントベースラインと比べ、SeGANが見える領域、見えない領域、それらの組み合わせの全てにおいて最も良い結果を出した。ここで、SUは見える領域のセグメント、SIは見えない領域のセグメント、SFは全体像のセグメントを表している。
群衆の画像データにおいて、ネットワークの訓練を改善するためのself-supervisedタスクを提案。タスクは集計情報とランキング情報の両方を組み合わせたマルチタスクフレームワークであり、群衆カウントのためにend-to-endで訓練できる。 群衆画像をだんだん小さくするように切り取って人数をランク付けおり、提案されたself-supervisedタスクはラベル付けのされていない群衆画像のCNNに大きく貢献した。 提案手法は群衆計測の困難なデータセットShanghaiTechとUCF CC 50においてstate-of-the-artを得ている。
![]()
image-to-image translationタスクで用いられるモデルは、ターゲットドメインの翻訳結果をコントールする機構がなく、出力結果が多様性に乏しい。この研究では、1. conditional image-to-image translationをいう問題を新たに設定し、2. この問題を解くためにconditional dual-GAN (cd-GAN) を提案する。 1では、複数の画像を組み合わせたtarget domainが入力されたsorce domainを変換する問題を扱う。複数の画像をどのようにして組み合わせるかで多様性に富んだ変換結果が得られる。

入力は64x64とする。eA, eBは3つの畳み込み層で構成されており、各畳込み層の活性化関数にLReLUを用いる。デコレーターネットワークであるgAとgBは4つのデコンボリューション層から構成されており、はじめの3層はReLUで活性化し、4層目にはtanhで活性化する。ディスクリミネーターであるdAとdBは4つの畳み込み層と2層の全結合層から構成されており各層の活性化関数にLReLUを用いる、最後の層(2つ目の全結合層)のみsigmoidで活性化する。オプティマイザーはAdamを用い、学習率は0.0002とする。以上の設定で実験した結果を右図に示す。
DNN 画像クラス分類器の入力空間における位相的・幾何学的性質を実験的に分析した研究. DNN が学習している各クラスの領域は接続されたものであり, その境界は少数の大きな曲率をもつ方向と, 平坦な大多数の方向があることが確認された. また, 大きな曲率をもつ方向はデータ間で共有されており, これらの方向とネットワークの摂動に対する感度に関係性があることを確認した.
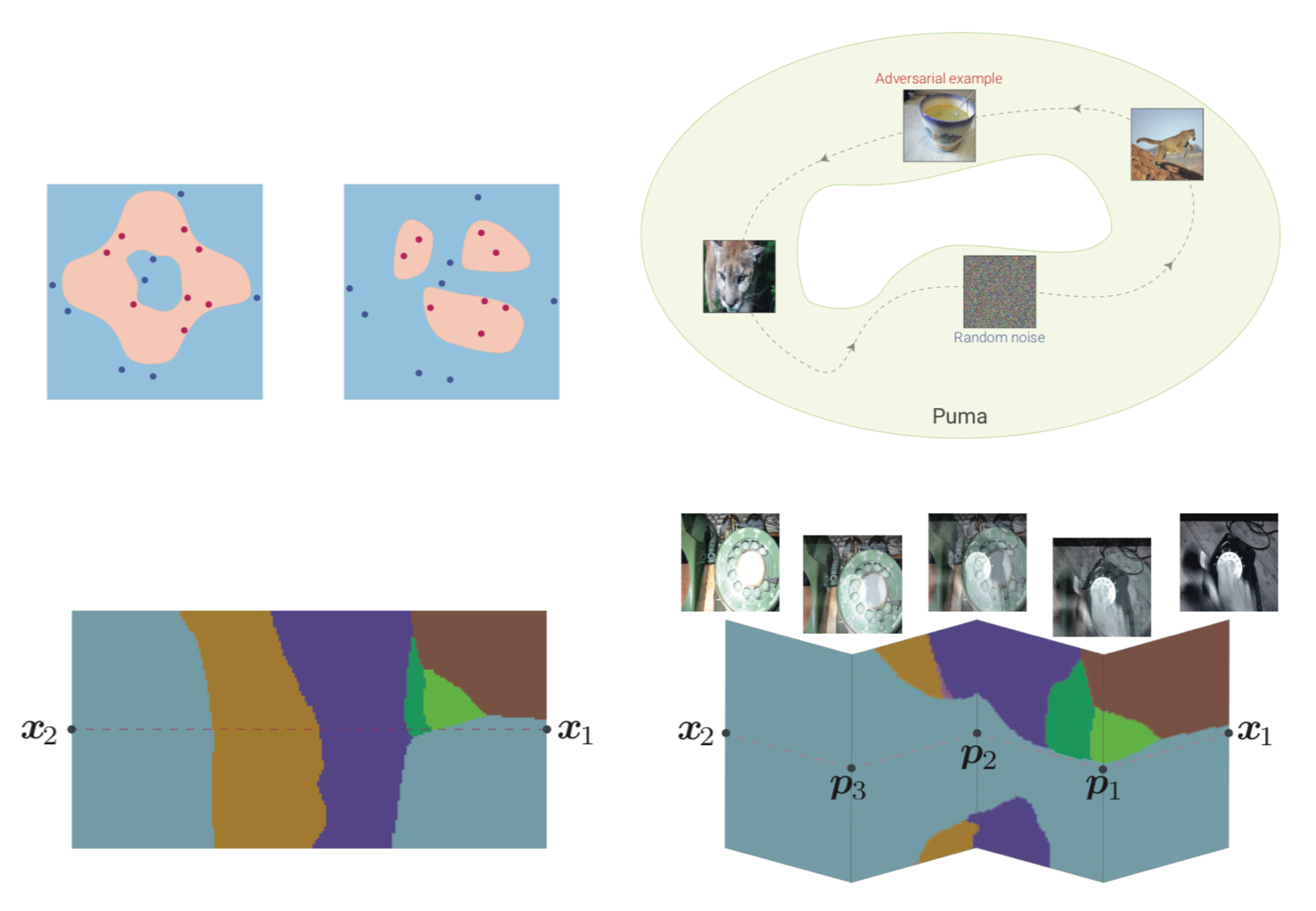
2枚の画像間の対応点探索を学習ベースで行う方法を提案。従来のhandcrafted特徴(SIFTなど)による手法は、特徴量により候補を決めた上でRANSACなどのアルゴリズムで対応点かそうでないかを決定する。 本研究では同様に、候補となる対応点の中から実際に対応しているペアをMulti Layer Perceptrons(MLPs)により決定する。 対応点の数は画像によって異なるので、ネットワークには対応点のペア(4変数)毎に実際に対応しているかの判定を行う。 一方で、中間層出力を全ペアの平均と分散により正規化することでglobal contextを考慮する。(Context Normalization) 学習は、ペアの判定が正しいか、判定結果を用いてessential matrixが正しく求められるかによって行う。 その際、学習データに対して対応点のアノテーションを手動で与えるのは非常に時間がかかってしまう。 そこでepipolar distanceを用いた閾値処理により対応点を取得する。
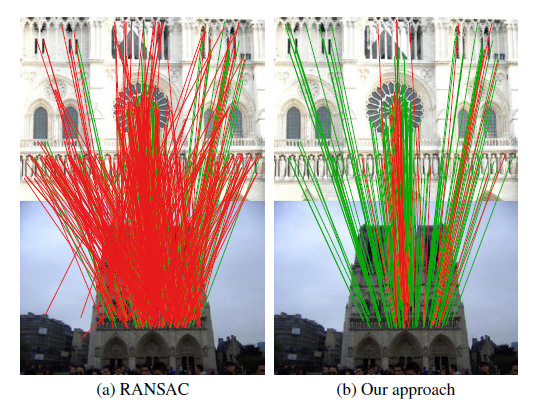
ベースラインと比較して、学習したシーン、学習していないシーンどちらにおいても高い精度ないし同等の精度を出すことに成功。59枚の学習データのみで学習した場合であっても、ベースラインと比べ高い精度を出すことに成功。 RANSACのみで対応点を決定する場合より、提案手法により候補を絞った上でRANSACにより更に候補を削るほうが17倍計算時間が早い。
顔のattributeを編集するEnd-to-Endのネットワークを提案した。ドメイン間の変換を考えるのではなく、Encoderにより得られた特徴のドメイン間の差分を考えることにより特徴の付与を実現する。 ドメイン毎の特徴は、全ての学習データの平均ではなく入力画像の最近傍K枚の平均を考える。 Encoderにより入力画像から得られた特徴から、Facelet Bankというネットワークによりドメイン間の差分を求める。
従来手法と比較して、artifactが少なく高解像度の画像を出力することが可能になった。女性に髭を付与するなど学習データには存在しないようなものの場合、従来法では男女の違いが付与されて髭以外の変化が加わってしまう。 しかし、編集に重要な領域(髭→口周り)のみに変化を施すため従来手法よりも自然な変化が実現可能である。
1枚の顔画像から、指定した表情に変化する動画を生成する手法を提案。たとえ同じ笑顔であっても、作り笑いとそうでない場合など目の動きなど顔の変化は異なる。 そこで、指定された表情に対して複数の動画を生成する手法を提案した。 入力画像とラベルから、指定されたラベルに対して適した顔特徴点の変化を複数のネットワークによって予測する。 その際、各ネットワークの予測がお互いに類似しないように最適化することで動画を複数用意することなく予測することを可能とする。 予測した顔特徴点から各フレームの顔画像を復元することにより、動画の生成を実現する。
従来の動画生成に関する研究と比べ、artifactが少なく与えられた画像の人物の個人性を保った合成を実現した。ユーザースタディの結果、比較対象とした研究よりも提案手法により生成された動画のほうが圧倒的に好まれるということが分かった。 Action Unit(AU)の変化を調べたところ、提案手法により生成された動画は実際の動画に近い変化をすることが分かった。
Capsule Wardrobesという、良い組み合わせが多数存在するファッションアイテムのセットを自動で作る手法を提案。ファッションアイテムのセットに対して、それで実現可能なファッションの親和性と多様性を最大化することによりセットを決定する。 注目レイヤー以外を固定して最適化することを繰り返すことでファッションアイテムの選択を行う。 ファッションの親和性を決定するために、トピックモデルをベースとした教師なし学習による全身画像からのファッションの評価方法を構築した。

ファッションサイトに掲載されているCapsule Wardobesと作成したものに含まれるファッションアイテムの類似度を測った結果、ベースラインと比べ提案手法により選ばれたものの方が類似度が高いという結果が得られた。提案手法である繰り返しの最適化と貪欲法による最適化結果をユーザースタディで比べたところ、提案手法のほうが好ましいと答えた人が59%いた。 また、個人の好みに応じたCapsule Wardrobesの作成が可能である。
交通事故予測のため, 1. loss関数としてAdaptive Loss for Earlay Anticipation (AdaLEA)と2. 予測のためのNear-miss Incident DataBase (NIDB) の提案を行った. AdaLEAにより, モデルが学習過程において, 徐々に早く危険を予測できるように学習される. モデルが交通事故を予測する速さでペナルティを与えることにより, これを実現する. NIDBは, 多くの交通ニアミス動画を含んでおり, 危険と危険要素予測の評価用アノテーションが付けられている.
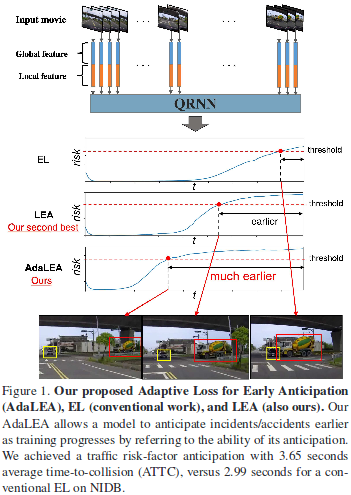
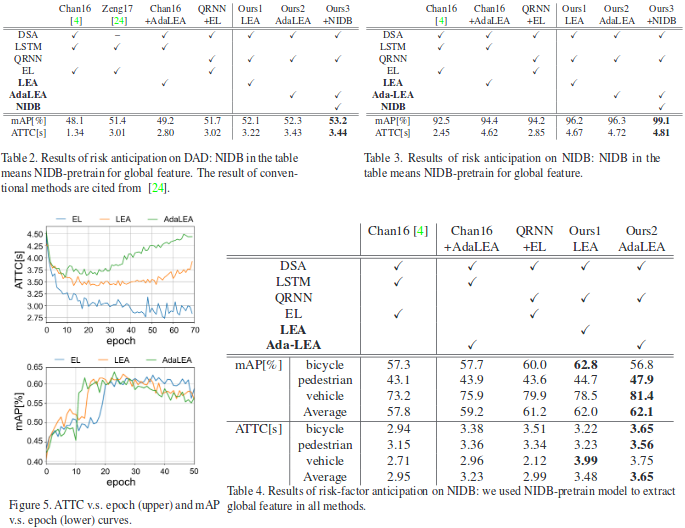
ベールモデルとしてDSA, LSTM, QRNN, loss関数としてEL, LEA, AdaLEAを用いて実験した.その結果, 危険予測では, mAPが6.6%上昇, ATTCが2.36sec速くなった. また, 危険要素予測では, mAPが4.3%上昇, ATTCが0.70sec速くなった.
実際の古い写真,ノイズの多い画像,生物学的データ,取得プロセスが不明または非理想的な画像のSuper-Resolution(SR)を実行を行うことができるZero-Shot SR(ZSSR)を提案.過去の画像例や事前訓練に依存することなく,Low-Resolution(LR)とその縮小版から複雑な画像特有のHR-LR関係を推論するCNNを訓練を行うことにより, 実際のLRの画像において,State-of-the-artなCNNベースのSRおよび教師なしSRよりも優れている.
SR-CNNは大規模な外部データベースの画像を事前に訓練しているのに対し,ZSSRは小さな画像から粗い解像度のテストデータを訓練.
ZSSRは同じ教師なしのSelfExSRにと比べ全てのDataSetにおいて優れている.教師あり学習でも通常のLRはあまり変わらない精度を出しており,未知LR画像で確認をするとかなり優れた精度を出している.
強化学習(Deep Q-learning)を用いた画像復元の研究. 単一の大きなネットワークを用いる手法とは対照的に, 特定の distortion に対する復元に特化した小さなネットワークを複数集めて toolbox とし, agent が各ステップにおいて最適な tool を選択することで段階的な復元を行う. 評価実験では従来の大きな単一のCNNを用いた手法と同程度の精度を20%程度の計算量で実現した.
動画による教示と言語による説明を組み合わせて Reward の学習を行う研究. 言語情報によって与えられた目標の達成の可否を, 画像情報から判断する Instractable Perceptual Rewards を提案し, 学習用のデータセットを作成した. また, 評価実験では教師ありで静止画像のみから学習した場合と比較して, 優位な結果を達成した.
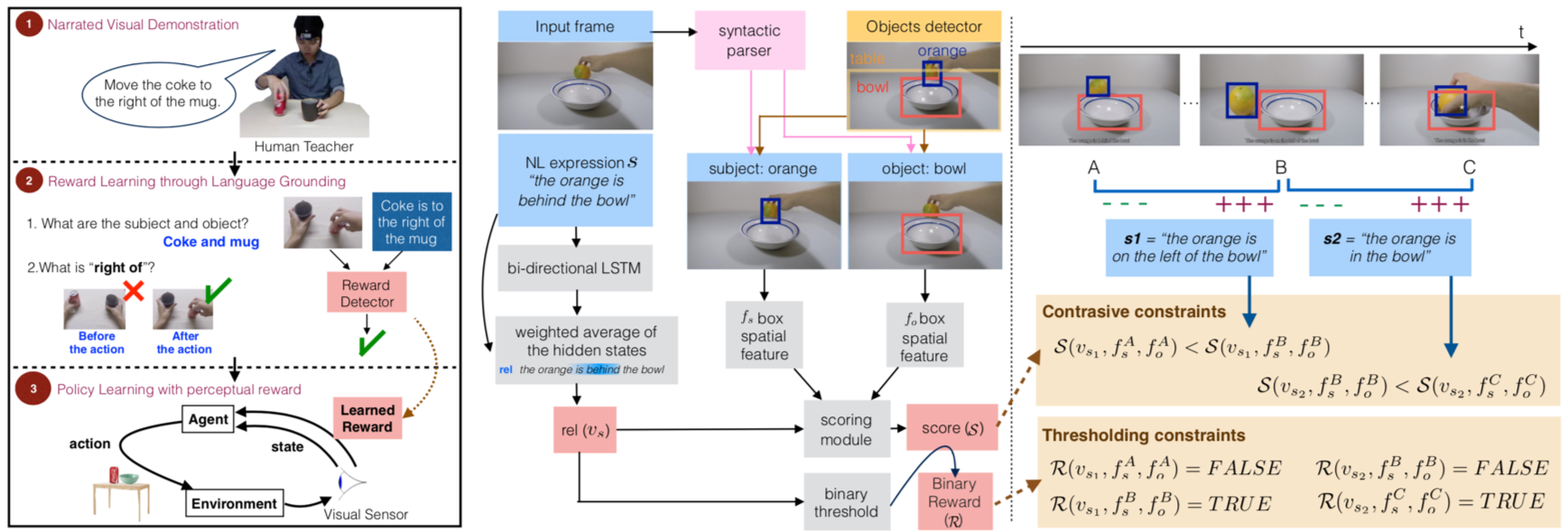
LightFieldカメラからの距離画像推定の問題を提案。オクルージョンに伴う物体境界の精度や質向上に対して操作を行なったことが貢献である。従来法とは異なり、PatchMatchをベースラインとして距離画像とオクルージョン領域を同時推定を直接的に行う。同時推定を行うことで、データを全て同時に学習に用いることができ、さらに前処理のステップが不要になる。結果的には、オクルージョン領域の推定を行い物体境界をケアしただけでなく滑らかな表面再構成に成功した。公開されているLightFieldデータセットにて評価した結果、12のうち9の指標においてState-of-the-artな数値を出した。

ライトフィールドカメラを用いた距離画像推定においてオクルージョン対策を講じた。距離画像とオクルージョン領域を同時推定する手法では既存のライトフィールドカメラにおける評価指標においてState-of-the-art。さらに、平面推定においても高度な推定を実現した。
モバイルで動作する新規アーキテクチャMobileNetV2の提案論文、データセットを用いた複数タスクにてState-of-the-artな精度を達成した。物体検出のモデルであるSSDLiteやセマンティックセグメンテーションのモデルであるMobile DeepLabv3を考案した。これらはInverted Residual Structureと呼ばれる、ショートカットコネクションが小さなボトルネックレイヤに挟まれた構造を最小ユニットとして構成される。中間の拡張レイヤは非線形関数として軽量化されたdepthwiseの畳み込みとして実装される。右図に本論文の重要技術であるInverted Residual Blockについて示す。従来のResidual Block(左)は前後のdepthが広いが、提案のInverted Residual Blockは中ふたつがdepthが広く、前後は狭い。
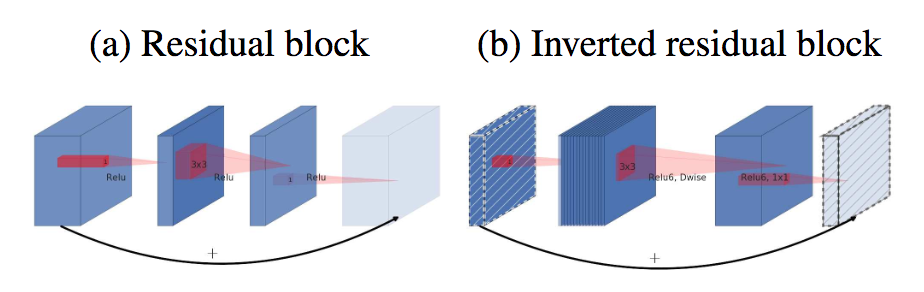
Inverted Residual Blockの提案等によりモバイルサイズのモデルにおいても良好な認識精度のモデルを提案することに成功。認識精度とパラメータ数のトレードオフについても良好で、さらにはCPUにおいても高速に動作することを示しCVPRに採択された。
動画から人間の行動を理解するためのPoseFlowの提案。PoseFlowはオプティカルフローに代わる新しい動き表現であり、背景の動きによるノイズやオクルージョンに頑健。人間の骨格位置とマッチングの2つの問題を同時に解決するようなネットワークであるPoseFlow Net(PFN)を提案し、学習する。これにより、人体の部分のみに動きベクトルが付与された出力を得ることができる。
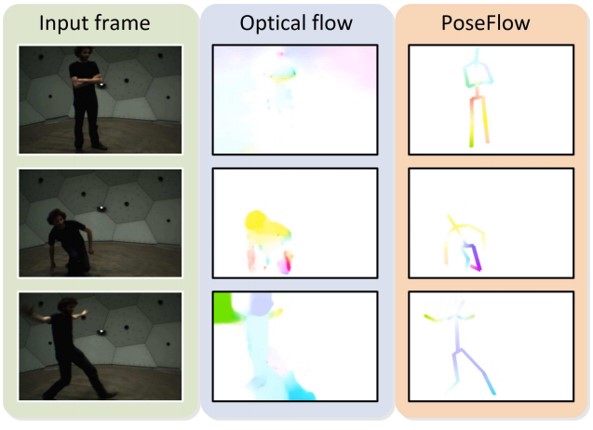
従来手法では、オプティカルフローを使ってモーションキューを探索している場合が多いが、背景の動きなども取ってしまうので“ノイズが多い動きの表現”であり、姿勢推定や行動認識のタスクにおいて支障をきたす。実験では、従来手法と比較して、姿勢推定や行動認識タスクにおいて高精度となっている。
3D映画やAR / VRの需要に先駆けた、Stereoscopic Neural Style Transferの提案。スタイルトランスファーによって、左右視点での整合性を保持するために、style loss functionにdisparity lossを追加し、左右視点での視差制約を設けている。また、リアルタイム性を考慮したソリューションの開発に取り組み、stylization sub-networkとdisparity sub-networkの2つを共同してトレーニングできるモデルを提案。

ステレオカメラを使ったスタイルトランスファー手法。通常、図(a)のような左右視点の画像とスタイル画像を入力すると1行目のように,左視点(b)と右視点(c)のように左右の視点で差が生じる(d)。このような不一致性は、(e)のアナグリフ画像のようになり、視聴者へ左右視点での三次元的視覚疲労が生じさせる。提案手法ではこのような不一致性を抑制し、2行目のように整合性のとれたスタイルトランスファーを可能にする。
局所構造と視覚的豊かさの両方を保持できる、より汎用的なtexture transfer問題を解決するための提案。元画像と元画像のセマンティックマップ(aのようなセグメンテーション画像)と、変換後となるセマンティックマップの3つを入力とする。変換顔のセマンティックマップを元にスタイルトランスファーを実行する(ゴッホを痩せさせるなど)。contour key points match(CPD)やTPSアルゴリズムをベースとしたstructure propogation手法を提案している。
タスクの多様性と、ユーザガイダンスの簡潔さをテーマに取り組んでいる。図のように、(a)簡単な絵をアートワークに変更、(b)装飾パターンの編集、(c)テキストに特殊効果を付与、(d)テキスト画像における効果を制御、(e)テクスチャの交換、などユーザのガイダンスによってさまざまなテクスチャの変換を実現できる。
弱教師付き学習で物体検出を行うmin-entropy latent model (MELM)の提案。MELMは、object discoveryとobject localizationの2つのサブモデルで構成され、end-to-endで学習可能。 object discoveryで、 global min-entropyと画像分類lossを最適化。local min-entropyとソフトマックスを最適化。グローバルとローカルそれぞれで物体を検出し、エントロピーを最小化し、グローバルからローカルへ物体確率を伝播。
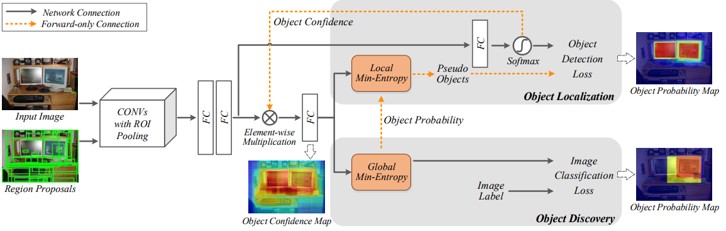
弱教師付き学習による物体検出は、物体位置と検出を同時に学習するのが困難。弱教師と学習目標間に不一致が生じると物体位置にランダム性が生じ、検出器をうまく学習できない。min-entropyによって、学習中の物体位置のランダム性を計測し、物体位置を学習することができ、検出器のあいまいさを回避できる。
既存手法のZero-shot style transferでは画像生成と効率のトレードオフによって,高品質な画像の生成とリアルタイムでの画像生成(style transfer)が困難.本稿ではこの問題を解決し,効率的かつ効果的な画像生成が可能なAvatar-Netを提案.提案手法では,高品質なstyle transferを可能にし,有効性および効率についても実証.さらに複数のスタイルの統合や動画のデザインを用いたアプリケーションも実装.
![]()
![]()
![]()
動画中に存在する繰り返しの動作を推定する問題について考慮.既存の研究(フーリエベース)では静的および定常周期性という仮定のもとでは良好な精度であるが,現実的なシーンにおいては測定が困難.そこでウェーブレット変換を適用し,非静的かつ非定常な動画においても適切に処理できる手法を提案.また,非静的かつ非定常な動画で構成されるQUVA Repetition datasetを提案.動画内の繰り返し動作のカウント実験では深層学習による手法に比べ,良好な精度を実現.

実世界の風景画(写真)を漫画スタイルの画像へ変換する手法の提案.漫画スタイル変換のためのGAN,CartoonGANを提案.ペアの画像を使用しない学習方法を採用し,そのための新規の損失関数を提案.実験では,写真のエッジや滑らかな陰影を保持したまま,アーティストのスタイルを表現することが可能であることを確認.
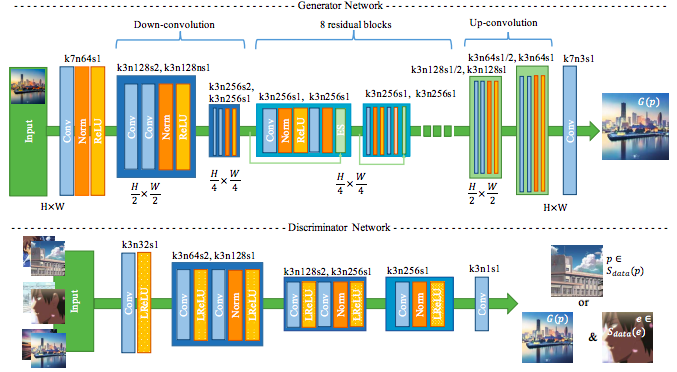
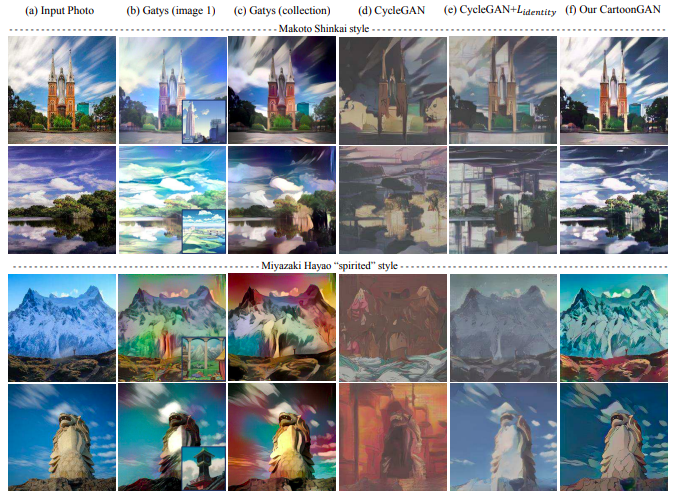
画風変換には以下のような問題が存在,これにより既存の損失関数においては表現が困難
本稿ではメタネットワークを用いた1つのフィードフォワードパスによる,(style transferのための)ニューラルネットワークパラメータを自動生成する手法を提案.最新のGPU 1つで19 ms以内に任意の新しいスタイルを表現することが可能.また,生成された画像変換ネットワークの容量はわずか449 KBでありモバイルデバイス上でリアルタイムでの実行が可能.
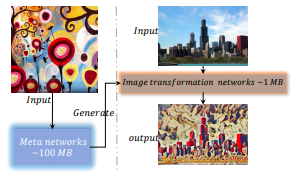

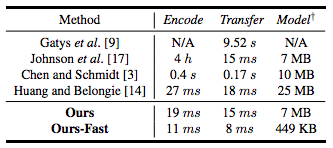
既存のstyle transferに関する研究の問題点
以上の問題に対応するための策として
さらに
この論文は,隣接する建物の境界線を幾何学的特性を利用して正確に描画するDeep Structured Active Contours (DSAC)の提案である.DSACは制約条件であるActive Contour Models(ACM)と従来のポリゴンモデルを使用している. 今回はCNNを用いてインスタンスごとのACMのパラメータを学習し, 構造化された出力モデルに全てのコンポーネントを組み込む方法を示し,DSACをend-to-endで学習可能にした. この論文は3つの困難なデータセット"building","instance","segmentation"をDSACで評価し, state-of-the-artと比較して優れた結果を残している.
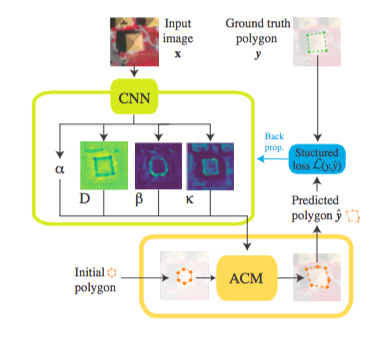
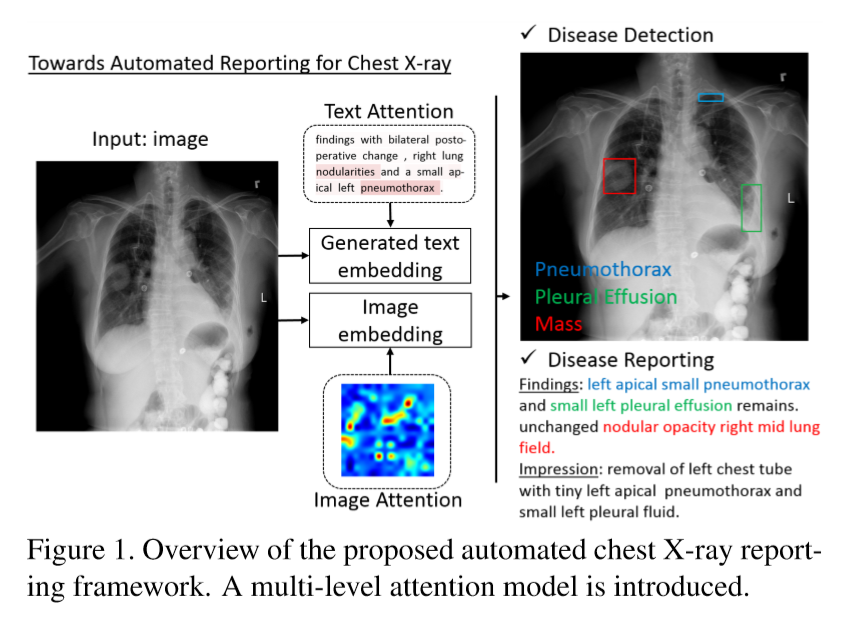
深層ネットワークでは大量のデータが必要で,ラベル付けされたデータはネットワークのデザイン同様深層ネットワークにとって重要である.しかし手作業の収集はお金と時間がかかる.そこでMicrosoftのDirectXレンダリングAPIを用いてゲームをやりながらリアルタイムでセグメンテーションやオプティカルフローなどのための正解ラベルを作成する手法を提案する.集めたデータセットは他の合成データセットより視覚的に現実世界と近いものになっている.

このシステムはリアルタイムにすべてのラベルを計算するため直接ゲームのレンダリングパイプラインにコードを組み込んでいる.また人によるアノテーションが必要ない.さらに,様々なデザインの複数のゲームにおいてこの手法を用いることができる.
動画データセット上の比較的浅いものから非常に深いものまでの様々な3DCNNの構造を調べた.
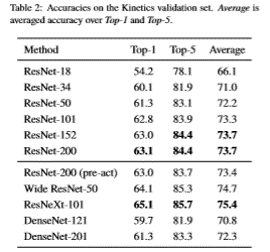
ロボットなどのエージェントに知覚を身につけさせるためのGibsonという仮想環境を提案した。Gibsonは572の建物、1447のフロアから構築されている。 RGB-Dデータから、任意のカメラ位置でレンダリングする場合欠損が生じてしまう。 そこで、複数のカメラ位置でレンダリングした画像を組み合わせた上で、Neural Netにより欠損箇所を保管する。 得られた画像はリアルではないため、レンダリング画像とリアル画像間のドメイン変換手法Gogglesを提案した。 また、物理エンジンを組み込むことにより、実世界で起こる衝突などの判定を可能にした。

目的地へ向かう、階段を上るといったエージェントのタスクに加え、depth推定、シーン認識によって有効性を検証した。実世界で撮影した画像によるテストでは、他のデータセットと比べ1番精度が良かった。
従来の動画認識に関する研究は、映像情報のみを用いているものが多く字幕のようなテキストや音などの情報は利用されていない。動画認識のタスクに、映像情報に加えテキスト情報を利用するための手法を提案した。 考慮すべきこととして、映像とテキストの情報が時系列的にどのように対応しているか、同じラベルに対してテキストでは複数の表現方法が存在している、という2つの点が挙げられる。 そこで、時系列的な対応付けを行うFuzzy Sets MIL(FSMIL)とテキストがどのラベルに対応しているかを推定するProbabilistic Labels MIL(PLMIL)の2つの学習方法を提案した。
動画認識タスクとして、顔認識及びアクション認識の2つによりテストを行いベースラインと比べ精度が向上したことを確認した。
濁った水や霧の中で撮影したような,散乱光により劣化したような画像に対して適用可能な3D復元手法の提案.
形状依存の前方散乱(forward scatter)を扱うモデルを考え,ルックアップテーブル使用で解析的に求める, それを空間的変化カーネルとして表現する. また,前方散乱の除去を可能にする,大規模密行列を疎行列に近似する手法を提案.
厳密に形状依存の表面-カメラ間前方散乱をモデル化し,その解析的解法を提案したものは初めて.
実,合成データに対して改善的性能を示した.
かなりスパースな輪郭線(元画像の4%程度のデータ量)から大変きれいな画像の復元ができ,更に輪郭線を調節すると大変きれいにパーツ位置を変えられる. 参照画像も変更できるので,髪を生やせるし,(効果は薄いが)人の鼻を犬っぽくできる.
まず,入力の輪郭線を工夫する.この手法でスパースな輪郭線を取り, 輪郭線の左右の画素の色(RGB)を色値(RGB×左右=計6値)とする. また,画像の各色における勾配を取り,輪郭線の位置におけるRGB×XY成分=計6値を勾配値とする. ここからN次元特徴マップを(GANを回している最中に)学習する. 構造はDeeplabを参考にしたDilated Conv.による簡素なネットワーク構造による.
この輪郭線特徴を入力として,2段階の復元用U-Netを生成器に,Dilated-Patch Discriminatorを判別器にしたGANを回す.
アプリケーションとしてかなり使い出かあるように見える.
文書から二値化,陰影除去をするのに使えるDocument Enhancementの話.文書平面を三次元化し,文書面から凸凹を除去するという形で可視領域(Visibility)の検出をし, それをベースに鮮鋭化するというやり方. 本手法を前処理として,二値化手法や陰影除去を適用するとSOTA性能を上回る.

基本方針としては,識別性を高める高次元空間への変換のやり方を考えました,という非ディープなパタレコにおけるノリ.
論文の質としては他論文と比較して若干劣るように感じられるが,「平面だけど三次元点群にするとうまくいくとは,驚きだ!」と言っていて,それがウケたのだろうか. おそらく当初の発想も文書の凸凹を消すという発想だったと思われる.
混合分布内のラベルなしデータと少量のラベルありデータから正しく分布の重み(Weights of components)を推定し、画像分類を行う問題を提供。この問題自体をMixture Proportion Estimation(MPE)という。
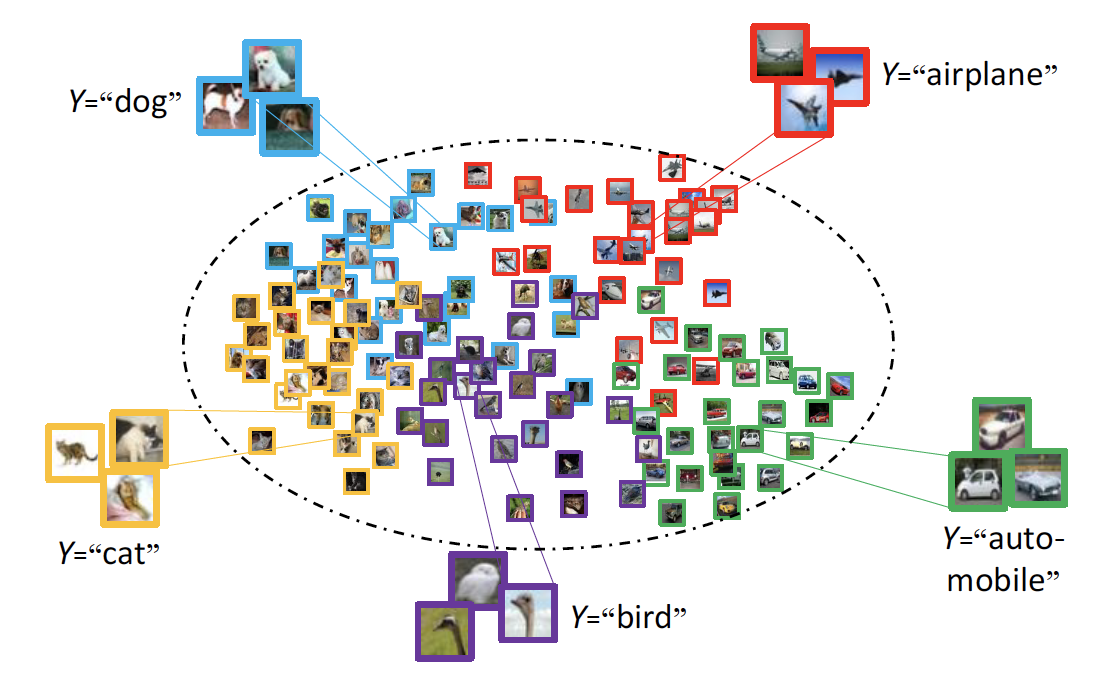
データに多数のノイズを含んでいても、少量のラベル付きデータから混合分布の割合を把握して正しく画像分類を行うことができるアルゴリズムを提案。Web画像に見られるラベルノイズが発生している学習/Semi-supervised学習、合成データ/実世界データの両者においてState-of-the-artな精度を達成した。
勾配の最適化手法であるStochastic Gradient Descent(SGD)やRMSPropアルゴリズムをRiemannian Optimizationの設定にて一般化する手法を提案する。SGDはDNNでは一般的に用いられるが、勾配の最適化に大きな分散があり、一方でRMSPropやADAMがこの問題を解決するために提案されてきたが決定だとは言えなかった。本論文ではRiemannian Centroidsの計算や深層距離学習(Deep Metric Learning)を考慮して勾配最適化の不安定性に取り組む。詳細画像識別問題に取り組むことで提案手法の有効性を示した。右図は最適化のイメージ図であり、Riemannian多様体空間で勾配計算と誤差最適化を測ることで安定感のある最適化を実現。
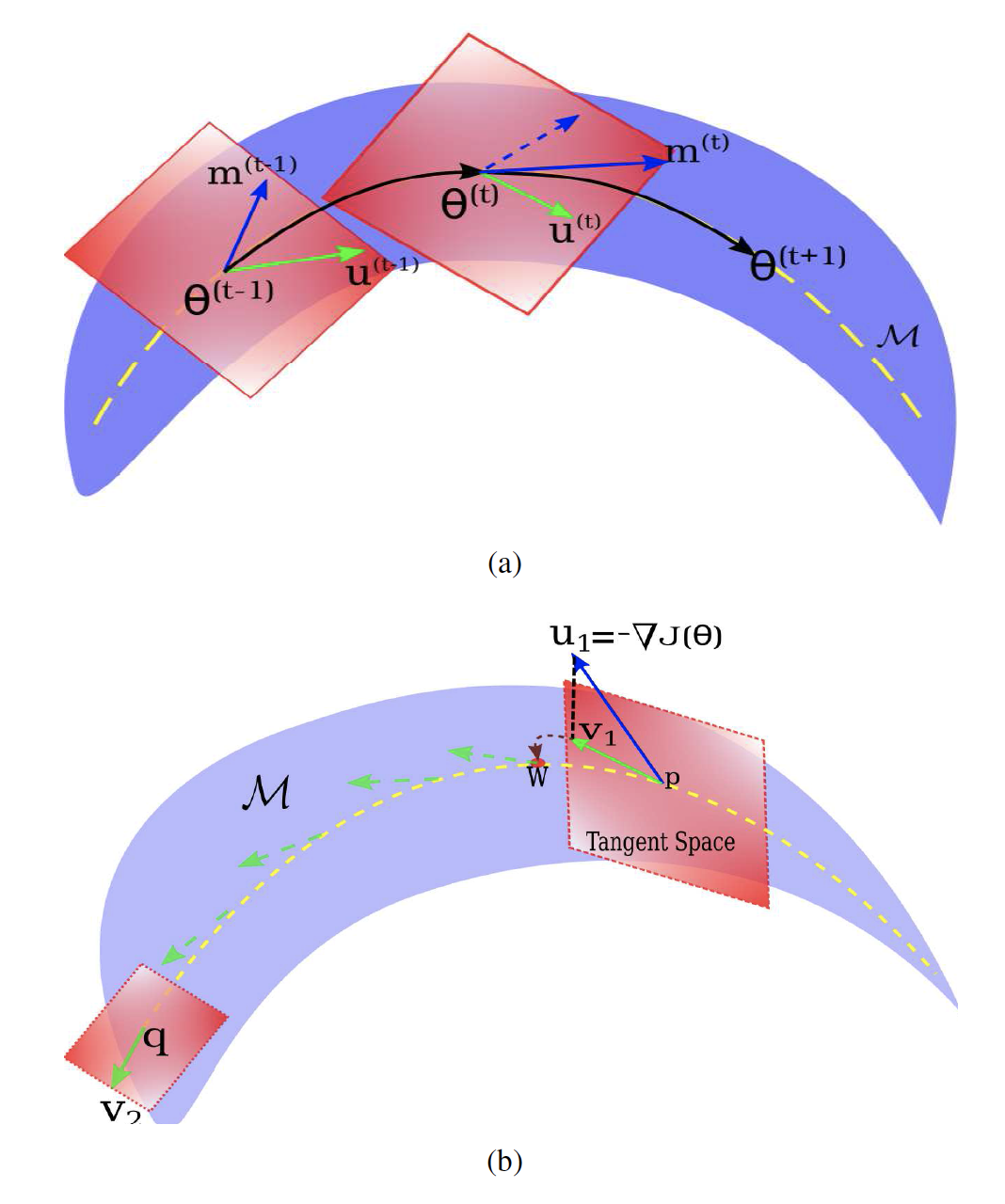
多様体空間で最適化を実現するcSGD-M/cRMSPropを提案、問題設定に対して拘束を強めてダイレクトに最適化ができる手法とした。機械学習の文脈において、PCA/DMLの拡張と位置付けられる手法を提案。同枠組みを詳細画像識別問題に適用したところ、Competitiveな結果を達成した。
ある視点の人物画像からターゲットとなる視点(Novel View)の人物画像を復元するタスクを提案。従来法であるVSAP(参考文献40)では正確な視点変化に関するフローを推定することができなかったが、提案法ではまず距離画像を推定してからフロー推定することで精度を劇的に改善した。
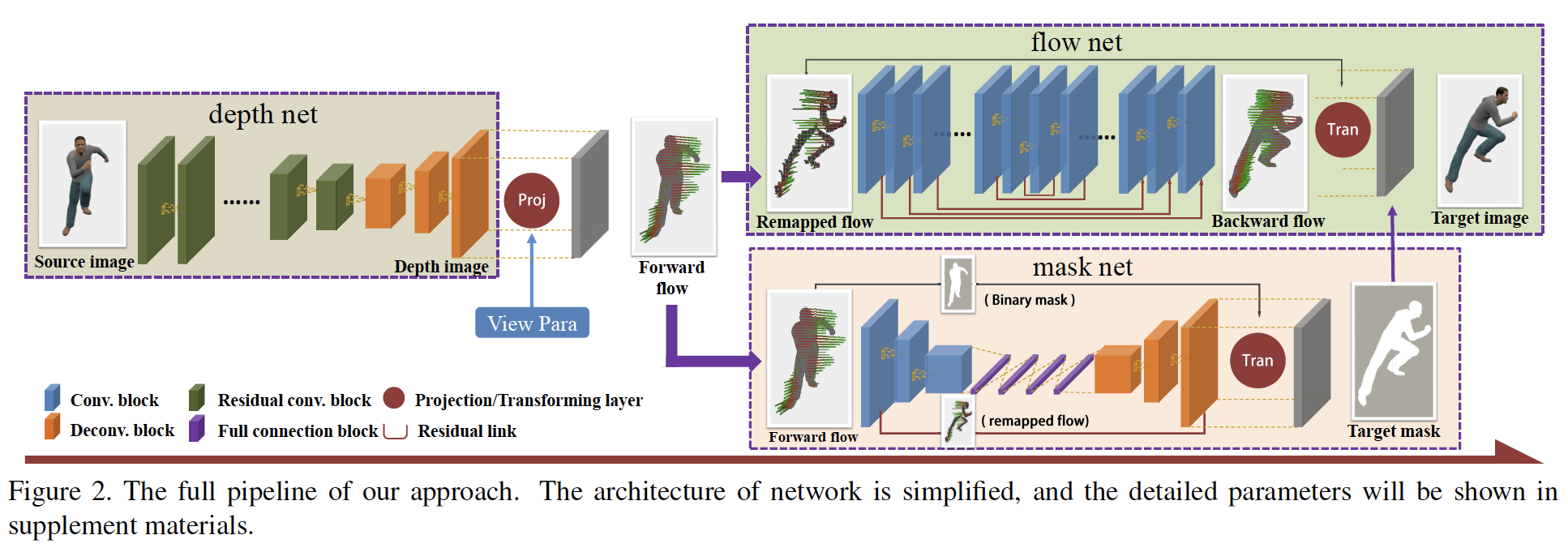
距離画像の復元(予め形状を復元することに相当)することにより、ビューポイント変化に関するフローの推定精度を劇的に向上させ、さらにバックフローも組み合わせることでターゲット視点の人物画像復元を改善。距離画像の復元からオプティカルフローの推定を行うこのような枠組みをShape-from-Appearanceという?3次元的な情報があることで姿勢に関するバリエーションがあったとしてもロバストなビューポイント変化の人物画像推定が可能。合成データによる人物画像データセットも作成、2,000の姿勢に対して22のアピアランス変化を含む。
以前は経由する情報をいかに少なくしてダイレクトに復元を行うか、が重要であったが、DNN時代になってから効果的な情報復元(この場合は距離画像による形状復元)を経由することにより推定精度が向上。
幾何学的な変換に頑健なDNNを考案。従来のDNNでは例えば右図のようなアフィン変換(ここでは主に回転)に対して脆弱であり、上図では馬の種類を答えていたものが、多少の回転を与えるだけで犬の種類を答えてしまう。本論文ではManiFoolというシンプルだがスケーラブル、多様体(Manifold)ベースのアルゴリズムManiFoolを提案、幾何学的な変化に対する不変性や複雑ネットワークに対する評価を行う。さらに、Adversarial Trainingにより幾何学的な変動に頑健なモデルとなるような学習法を実装した。

最小の幾何学的変換により認識を誤ってしまう問題に対して不変性を計測するManiFoolを提案したことがもっとも大きな貢献である。ImageNet等の大規模データに対して幾何学的変換とそのロバスト性を評価した最初の論文である。ManiFoolアルゴリズムをAdversarial Trainingに応用して幾何学的変換に対してロバストな学習法を提案。
自動的に冗長なレイヤを除外してくれるε-ResNetを提案し、よりコンパクトなサイズで最大限の認識パフォーマンスを実現する。ε-ResNetでは閾値εを設けて、これよりも小さい値を出力するレイヤに対して誤差を計算しないという方策を取る。提案法であるε-ResNetを実現するために、少量のReLUを加えることで実現した。CIFAR-10,-100,SVHN,ImageNetに対して単一のトレーニングプロセスで学習が成功し、なおかつ約80%ものパラメータ削減を実行した。右図は752層のε-ResNetを実装して最適化した例である。図中の赤ラインは除去されたレイヤ、青ラインは認識に対して必要と判断されたレイヤである。図の例では、CIFAR-100に対するオリジナル(ResNet-752)のエラー率が24.8%、提案法(ε-ResNet-752)のエラー率が23.8%であった。
ResNetを対象として、レイヤを増加させることによる冗長性を自動的に除去してくれるε-ResNetを提案した。ε-ResNetは従来の枠組みに対して4つのReLUを組み合わせ、閾値カット処理だけで実装可能である。より深い層のモデルに対して有効であり、大体80%くらいの冗長生をカットする。パラメータ数を減らしつつも超ディープなモデルにおいて多少の精度向上が見込める。
実装が非常に簡単そうであり、すでにDNNフレームワークにおいて実装されていれば、広く使ってもらえそう。また、各タスク(e.g. 物体検出、セグメンテーション、動画認識)において気軽に使用することができれば、広がりがありそう。
敵対的サンプル(Adversarial Examples)を生成的に作りだすモデルを考案し、自然画像に対して摂動ノイズを与えて学習済みモデルを効果的にだます手法(GAP; Generative Adversarial Perturbations)を提案する。提案のGAPは画像に依存する/しない摂動ノイズ、いずれも生成することが可能であり、画像識別やセマンティックセグメンテーションに対して有効。また、ImageNet/Cityscapesを用いたより高解像な画像においても効果的に識別器をだますことに成功した。さらに、従来の同様の枠組みよりもより速く推論を行うことができる。
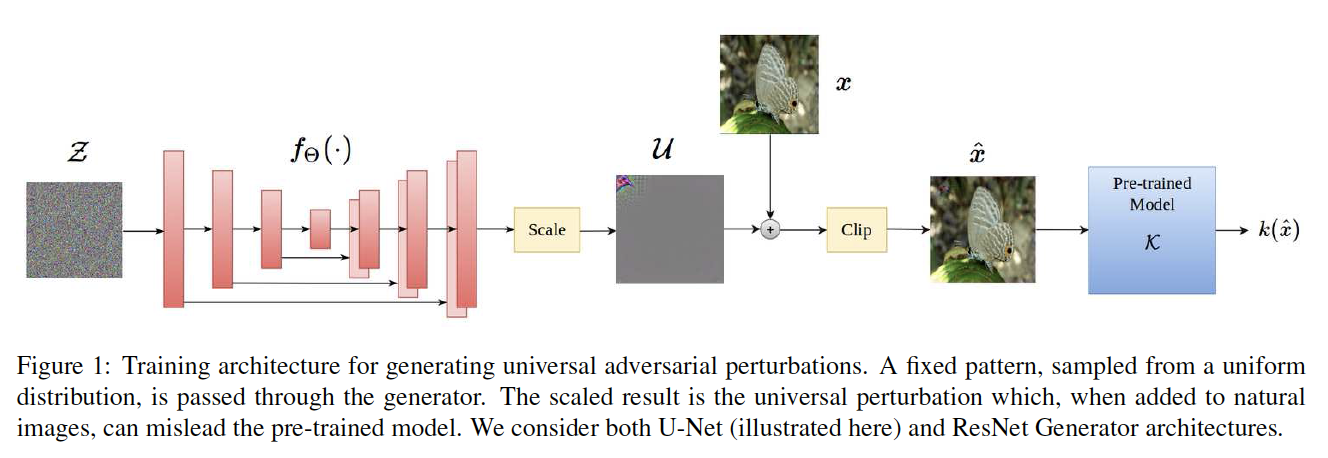
より汎用的かつ画像依存性のあり/なしに関わらない摂動ノイズを、画像識別/セマンティックセグメンテーションに対して行うことができる。それでいてUniversal Perturbationsの枠組みを生成モデルにより実装、より効果的にだますことに成功。
この論文は引用されそう?だが、ホントの意味で騙せているのかは不明である。(Adversarial Examplesの論文は、会議の前に攻略法がarXivに載せられるなどまだまだ研究が必要である)
セマンティックセグメンテーションにおいて、ピクセルごとの最適化ではなく領域(Intersection-over-Union)ごとの最適化を行うことで小領域を含む領域ベースのセグメンテーションを改良する。この問題に対して、サブモデュラ凸最適化手法Lovasz(参考文献26をベースとした)を用いることで誤差計算を行う。このLovász-Softmax Lossは従来のCross-Entropy Lossよりも領域評価jに対して頑健であることを示した(右図)。位置付け的にはLovász Hinge Lossのマルチカテゴリに対する一般化である。

セマンティックセグメンテーションにおいて特に小領域であったとしても適切に評価して誤差を計算できるLovasz-Softmax Lossを提案した。PascalVOCやCityscapesにおいてCross-Entropy Lossを用いた誤差計算よりも良好な性能を示すことが明らかとなった。
顔認識において、本人認識率が向上するようにアフィン変換や形状変化(Diffeomorphic)を行うように変換を実装するネットワークDeep Diffeomorphic Transformer Networksを提案。直感的にはズームインだが、さらに形状変化を行うことが効果的であると判断してネットワークを構築した。

顔認識においてアフィン変換によるズームインのみならず、認証率が向上するような形状変化方法であるDiffeomorphic Transferを提案した。同処理はCNN内に実装され、Deep Diffeomorphic Transformer Networksと呼ばれ、LFW/CelebA等でState-of-the-artであった。
幾何学的な表現を用いたEnd-to-endのシーンテキスト認識アプローチ.シーンテキストインスタンスの幾何学的構成をエンコーディングするため,幾何学的な表現を学習するInstance Transformation Network (ITN)を提案する.右図上部の(a)のように,いくつか並んだサンプルグリッド(橙色)をテキストにフィッティング(青色)する.また,(b)のように入力画像(の特徴マップ)からフィッティングのためのモデルを学習する.ネットワーク構成は,特徴抽出部,インスタンスレベルのアフィン変換を予測する部分,幾何学的表現部からなる.変換の回帰,座標の回帰,分類はマルチタスク学習となる.
幾何学的表現で強いアフィン変換がかかっていても頑健なテキスト検出が可能である.データセットにはICDAR2015およびMSRA-TD500を用いて評価を行う.ベースネットワークにResNet50を用いた場合,MSRA-TD500のPrecisionは90.3,F値は80.3と非常に高精度な結果となった.ICDAR2015ではVGG16ベースの方が良い結果となり,Precisionは85.7,F値は79.5である.
教科書(テキストデータ+画像)に含まれている情報に関する質問に答える、Textbook Question Answering(TQA)に関する研究。質問の答えはテキストの局所的な部分に含まれていることが多く、テキストの要約によって答えを得ることが難しい場合が多い。 本研究では、テキストや画像から得られる因果関係や構造を表したContradiction Entity-Relationship Graph(CERG)を構築し、矛盾を探すための手がかり(Guidance)とすることで局所的な情報を使用して質問に答えることを可能とする。 CERGの構築には画像特徴とテキスト特徴を使用し、質問の答えには画像特徴とテキスト特徴に加えCERGから得られたGuidanceを用いることで出力を得る。
Contextが多く要約することが難しい場合、得られる情報をグラフにして記憶することが効率的であるということを示した。ベースラインやランダムに選択する場合と比べて、あらゆる質問のタイプ(truth or falseやmultiple choise)において正解率が向上していることを確認した。
一応画像情報を使用しているが、全体的にはNLP色が強いと感じた。手法としての完成度は非常に高く、評価は問題自体が新しいこともあり数値評価(従来法との比較、モデル設計の評価)及びqualitativeな比較であった。
マルチレベルの物体認識,検出,セマンティックセグメンテーションのための弱教師カリキュラム付き学習のパイプラインを提案。このパイプラインは物体位置の中間点と訓練画像のピクセルのラベルの結果をを入手し、結果を用いて教師付きのやり方で特定のタスクの深層学習で訓練する。その全体のプロセスは4つのステージを含む、訓練画像の物体位置を含み、物体のインスタンスのフィルタリングと結合し、訓練画像のピクセルラベリングをし、特定のタスクのネットワークでトレーニングをする。訓練画像からキレイな物体のインスタンスを入手することで、物体のインスタンスのフィルタリング、結合、クラスファイリングのための新しいアルゴリズムを複数の解決策から集める。このアルゴリズムは、検出された物体のインスタンスをフィルタリングするため、metric learningと密度ベースのクラスタリングの両方を組み込んでいる。
マルチレベルの画像の分類においてstate-of-the-artを達成.

単画像におけるカメラパラメータのキャリブレーションの話.事前知識なしに非コントロール環境でもちゃんと動くように, DCNNによるキャリブレーションパラメータの直接推測手法を提案する.
ImageNet学習済みDenseNetの最終層を3つの分離したヘッドに置き換え,それぞれ水平角度推定,水平線の中心からの距離,縦方向の場を表すように改造する. これを,大規模パノラマ画像データセットから自動生成したサンプルにより学習する.
評価については,実際人がおかしさを感じるかどうかによるので,AMTで聞いてみた結果から導いた人の誤差モデルをもとに語ってみる.

結果はそれなりにできている.が,それなりっぽく見えてしまうので,人間の感じ方もちゃんと調べて載せた! というのが評価されているように思う.
ネットワーク構造の簡単な調整で達成できたところが,DNNの手に掛かれば様々な問題が如何様にも解ける感じを醸し出していておもしろい.
アプリケーション枠狙いにするためか,アプリケーション例をいくつか掲載している.論文自体,他のアプリケーション系論文と比べて,読んでいて飽きない感じがする. 合わせ技一本,という感じがする.
速読したからかもしれないが,不思議な構成の論文だった.論点が2つあるからだろうか.違和感は感じるが,なんとかうまく収めている感じもする.
NVidiaにGPUを寄付してもらったらしい.
グラフなどの不規則な構造をした幾何学的入力のためのディープニューラルネットワークの変形であるスプラインベースの畳み込みニューラルネットワーク(SplineCNN).スペクトル領域内でフィルタリングするのではなく,純粋に空間領域で特徴集計をする.SplineCNNを使用することで,手作業による特徴記述子の代わりに入力として幾何学的構造を使用することで,深いアーキテクチャの完全なend-to-endの学習が可能になる.
DNN を用いて動画中の時間の流れている方向(Arrow of Time)を学習する研究. 人工的な信号を含むキューは Arrow of Time の学習に悪影響を及ぼすことを示し, それらの影響を取り除いた大規模 dataset を作成した. 評価実験では映画中の逆再生部分を検出するというタスクにおいて人間とほぼ同程度の精度を達成した.
![]()
テンソルがスライス方向に欠けてしまった場合の復元についての論文.このケースでは,よく行われる核ノルム利用やその他正則化手法ではムリ. 遅れ/シフトに不変な構造を捉えることが重要になることから, 「高次元空間への低ランクモデルの埋め込み」を行うことで解決する. 時系列の遅延埋め込みを,テンソルにおける「複数方向遅延埋め込み変換」 を行い,不完全なテンソルを高次不完全ハンケルテンソルへと変換する. その後,この高次テンソルをタッカー展開の枠組みで低ランク化することで 復元が行われる.
![]()
伝統的に行われてきた行列・テンソル解析系の論文.情報学部出身の読者になるべく分かりやすいように丁寧に書いているように見受けられる. 画像で言えば,伝送エラーなどで行の一部分や下半分が吹き飛んでしまった時などに使える復元手法.
きちんと読み手への導入は行われているものの,読み下すには,テンソル分解程度の数学の知識が必要.ついでに,カオスのような時系列システムも知っているとわかりやすい(図中の説明での事例がそれ). まとめ人にとっては数学の復習になったので,ぜひ論文を読んでみていただきたい.
ロボットアームを用いたビジュアルサーボについての研究. DNN を用いた視点に依存しないビジュアルサーボの能力を学習する Recurrent Convolutional Neural Network Controller を提案. 様々な視点, 光源環境, 物体の種類や位置に置けるタスクをシミュレーション上で学習することで, 未知の視点において自動でキャリブレーションを行うことが可能.
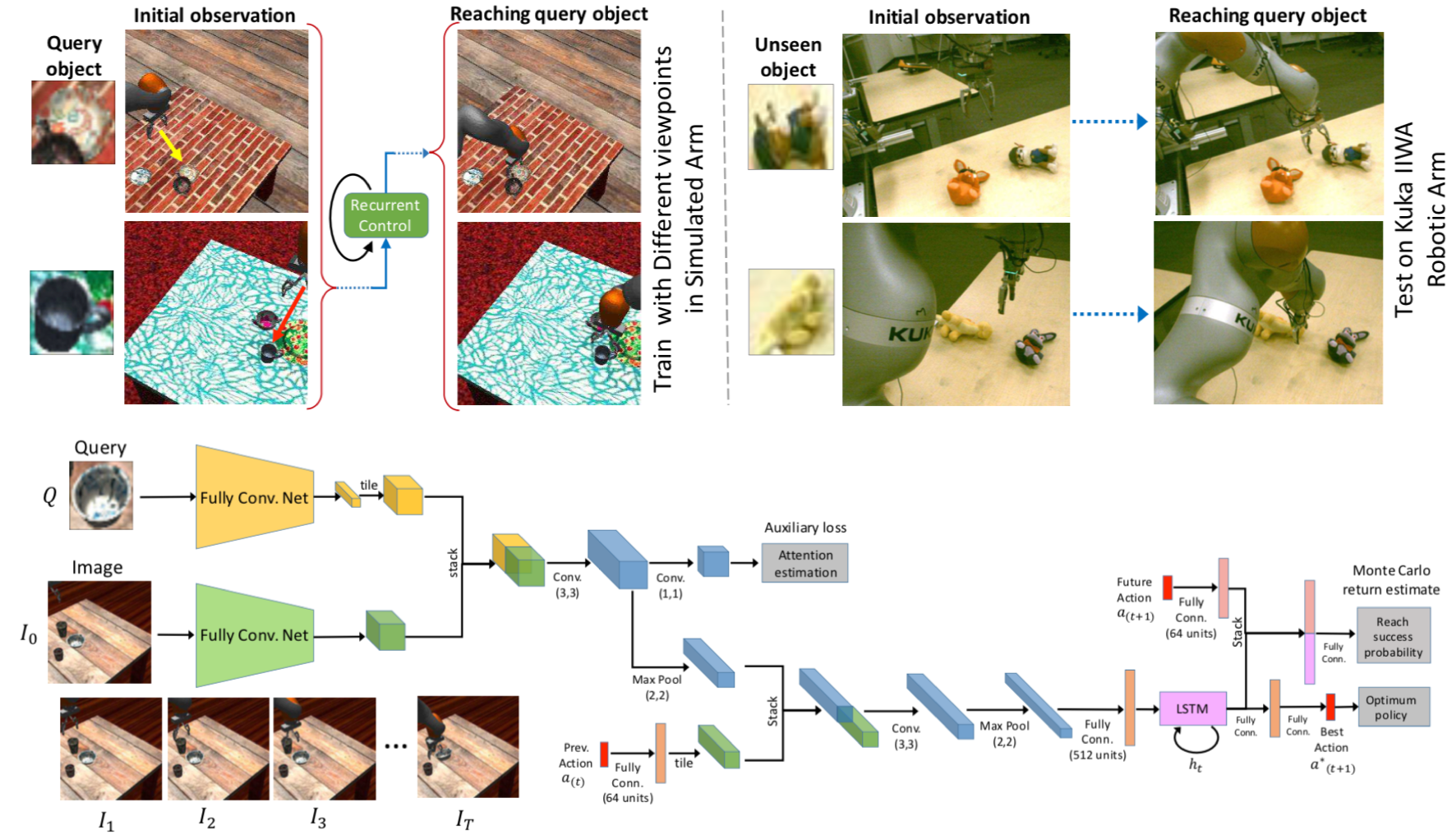
コーナー検出とセグメンテーションを用いた高速かつ高精度なテキスト検出手法.テキスト検出時,ボックスのコーナー点を局所化し,テキスト領域を相対位置でセグメンテーションする.画像を入力すると,DSSDベースのNWで特徴抽出をし,コーナー点検出とコーナー位置に基づくセグメンテーションを出力する.コーナー点はサンプリングおよびグループ化され複数の候補ボックスとなる.セグメンテーション結果とあわせてスコア付けしてNMSする.長いテキストを自然に検出でき,複雑な後処理をする必要もない.
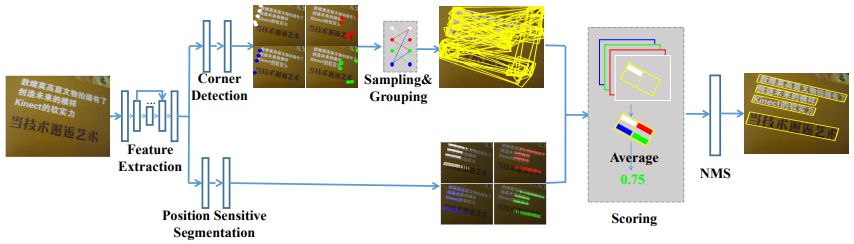
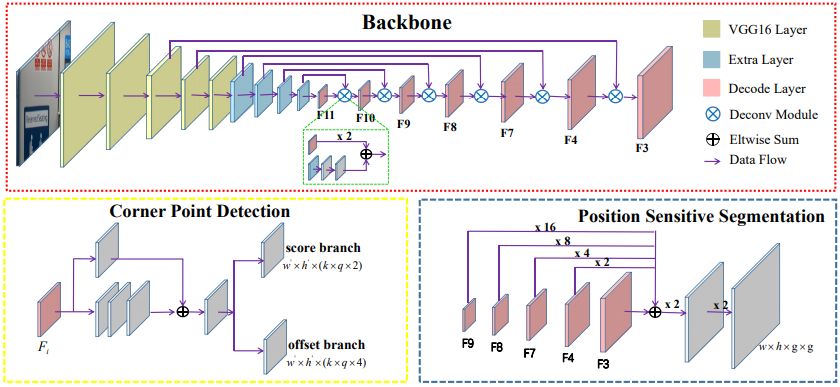
Deepベースのテキスト検出は,テキストを物体の一種として扱いb-boxの回帰を行うか,テキスト部分を直接抽出する手法である.前者はアスペクト比によっては検出できず,後者は複雑な後処理を必要とする.本手法はその2つを組み合わせて,両者の欠点を補う.SynthText,ICDAR2015,2013,MSRA-TD500,MLTおよびCOCO-Textのデータセットで評価して,ほとんどがSOTAを達成した.とくに,ICDAR2015では84.3%(F-measure),MSRA-TD500では81.5%を達成した.10.4FPSで動作する.
動画によるセマンティックセグメンテーションにおいて、精度を向上させつつ、処理速度を上げる手法の提案。2つのコンポーネントを組み込んだフレームワークで構成している。1つ目は、時間変化に伴って空間的な畳み込み処理を変化させ、特徴を適応させる特徴伝播モジュール。2つ目は、精度予測に基づいて、計算を動的に割り当てるスケジューラ。
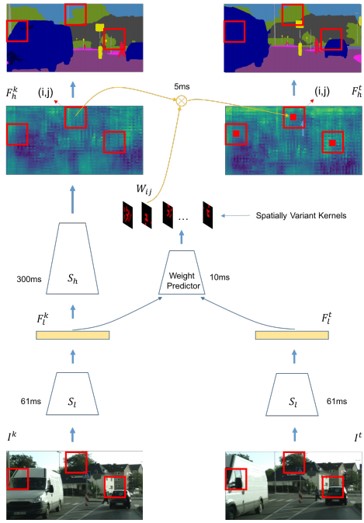
動画のセマンティックセグメンテーションには、高スループットやコスト、低遅延などの問題があり、 自律運転などにおいて重要となる。時間的変化に適応させた処理によって精度向上、処理速度向上を図る。
家の中の環境をシミミュレーションするための仮想環境 VirtualHome を作成した. また, 家の中で典型的に起こる様々な行動を自然言語とプログラムの形式で表現し, それらを仮想環境上でシミミュレーションした動画を組みにした VirtualHome Activity Dataset を公開した. 加えて, LSTM を用いて動画やテキストからプログラム形式の表現を生成する手法を提案した.

画像に関する質問に答えるVisual Question Answering(VQA)と与えられた答えになる質問を作るVisual Question Generation(VQG)を同時に扱うInvertible Question Answering Network(iQAN)を提案した。質問が与えられている場合は答えを、答えが与えられている場合は質問を推定することで学習をする。 その際、2つのタスクを独立した問題ではなく逆問題であると考え、質問と答え及びそれぞれを表現する特徴量間の変換に使用する重みを共有する。
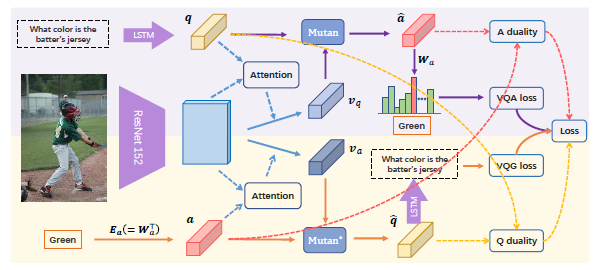
VQAに関しては、従来手法と比べて精度を向上することが可能となった。また、VQGによって生成した質問と答えのペアをVQAの学習に使用すると精度が向上することが分かり、VQGによってデータ数を増やすことが可能であると結論付けた。
画像に写っているもののカテゴリをコンピュータが人間に教えるためのシステムEXPLAINを提案。カテゴリを分類する上でどこに注目すればいいのか(例:蝶の種類を見分けるにはどこに注目すれば良いか)を提示することで人間がカテゴリを学習することを支援する。
従来の手法ではカテゴリを表すラベルを提示するのみであったが、重要領域を提示することでより効率的に人間が学習することを可能とした。ユーザースタディにより人に学習してもらった内容に関するテストをしたところ、EXPLAINの方が短い時間で高い正答率を出すという結果を得られた。
人間の年齢変化顔を合成するIdentity-Preserved Conditional Generative Adversarial Networks (IPCGANs)を提案。合成画像が満たすべき特徴を、(1)目的の年齢に近づいている(2)変化前の人物と同一人物か(3)リアルな画像かの3つとした。 (1)(2)については、Generatorによって生成した画像を年齢推定及び同一人物性を評価するネットワークによって評価する。 (3)はDiscriminatorにリアルかどうかを判定させることで最適化を行う。
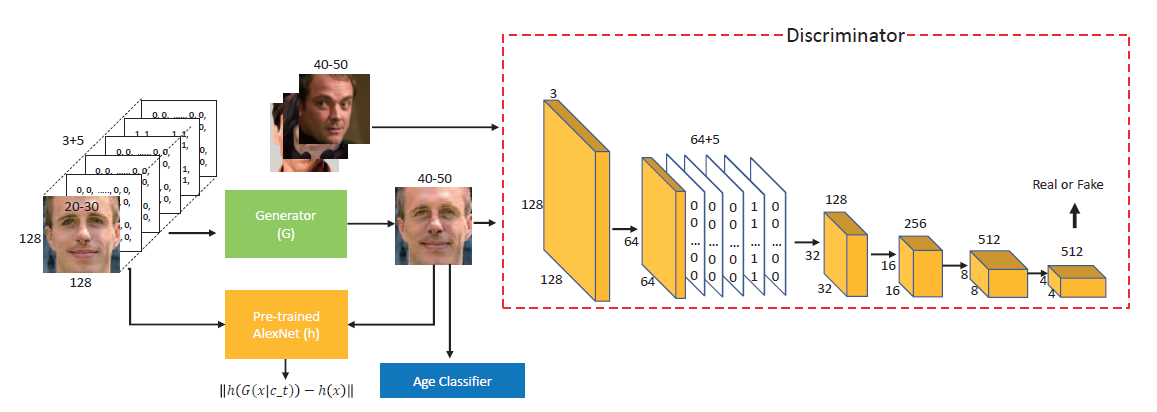
ユーザースタディにより、Image Quality, Age Classification, Face Verificationの3つの観点を評価し、DNNベースの手法と比較してFace VerificationとImage Qualityの2つの観点で高い評価を得た。VGG-faceによりinception scoreを求め、比較対象の手法より高いスコアを得た。 また、計算時間についても劇的に良化した。
画像に潜んでいる感情と注目を集める領域の関連を調査した。アイトラッキングのデータと、画像中に写っている感情に関連する物体(笑顔など)をアノテーションしたEMOtional attention dataset(EMOd)を構築した。 また、画像中の注目領域を抽出するDNNモデルであるCASNetを提案した。

EMOdを用いて分析した結果、感情に関連する物体の方が人々の視線を集めることが判明した。その中でも、人間が関連する(笑顔など)場合がより視線を集めることが分かった。 従来のSaliencyを求める手法よりもCASNetの方が多くの指標で高いスコアを獲得した。 また、感情に関連する物体の方がより注目を集めるという結果を出力したことからEMOdの分析結果を反映していることを確認した。
Vision and Languageのタスクに、Cognition分野で提唱されているbasic levelという概念を基にしたBasic Concept(BaC)を導入した。basic levelとは人間が幼少期に行う抽象化であり、本研究では物体のクラスを類似したもの同士を1つにまとめる。 始めに、MSCOCOのキャプションとImageNetのクラスをマッチングすることで、Salient Concept(SaC)というBaCに候補を決定する。 続いて、物体のクラス分類におけるConfusion Matrixを求め、混同されるクラス同士を1つにまとめることでBaCを決定する。

Vision and Languageのタスクとして、Image CaptioningとVQAによって検証を行った。Image Captioningについては、ベースラインと比較してほとんどの指標において精度が向上し、向上しなかった指標についてもベースラインと大差ない数値を記録した。 VQAについては、ObjectとLocationについて精度の向上を確認した。
一枚のRGB画像から3次元物体認識を行う研究. region-based な2次元の物体検出器を3次元に拡張する一般的なフレームワークを提案し, end-to-end のネットワークで2次元と3次元の物体位置と物体のクラスを同時に推定することが可能. KITTI dataset を用いた評価実験では state-of-the-art の結果を達成した.
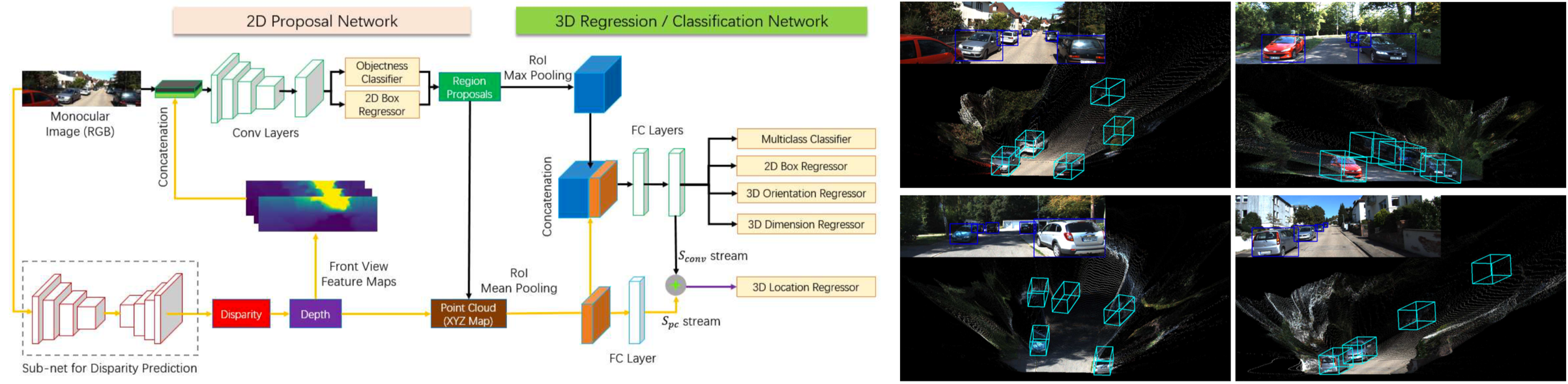
ローカリゼーションやリンク付けなどの画像中の参照表現に焦点を当てた研究.既存手法が複数のインスタンス学習によるペアワイズの領域をモデル化し単純化しているのに対して,今回の提案手法では対象とコンテキストの相関関係を用いる変分的コンテキストである変分ベイズ法を提案している,教師あり,教師なし双方のモデルに対して実験したところSoTAであった.
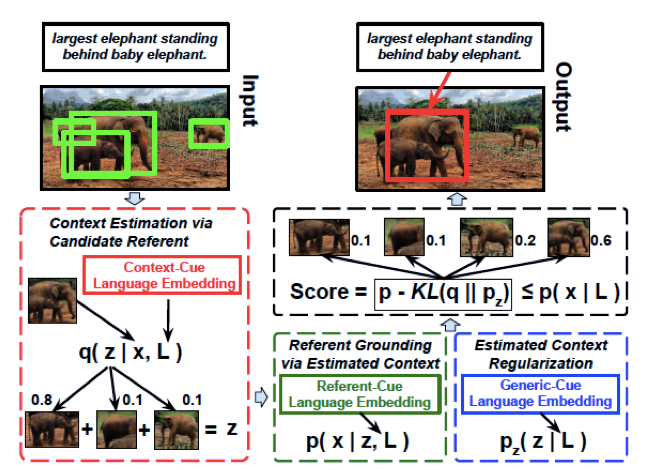
画像復元の問題は復元エラー(distortion)とエントロピー(rate)とのトレードオフであるが、本論文ではこのトレードオフをできる限り解消し、画像圧縮を行うAutoEncoderを提案する。著者らはコンテキストモデルから直接的に潜在表現のエントロピーを復元するモデルを考案して同問題に取り組んだ。AutoEncoderには条件付き確率モデルを学習した3D-CNNを適用。実験ではSSIMを用いて従来の畳み込みによるAutoEncoderモデルよりも良好な精度を実現した。
3D-CNNにより条件付き学率モデルを学習したAutoEncoderモデルを考案したことが新規性であり、JPEG(2000)などよりも良い圧縮法であることを示し、Rippel&Bourdevらのモデルと同等レベルの精度を達成した。
Recurrent/Convolutional Neural Networks(RNN/CNN)を用いた非可逆画像圧縮の手法を提案し、BPG(4:2:0), WebP, JPEG2000, JPEGよりも性能のよいものを提案した。3つの改善、(1)ニューラルネットにより空間的分散を効果的に捉えて情報量の劣化を防ぐ、(2)エントロピーコーディングの上に空間適応的ビット配置アルゴリズムを適用して効率的な画像圧縮とする、(3)SSIMによりピクセルごとの損失を計算して最適化することで圧縮数値を改善する、を加えて圧縮方法を提案。KodakやTecnickのカメラを用いてコーデックの評価を行った。
従来の圧縮方法であるBPG(4:2:0), WebP, JPEG2000, JPEGなどよりも効率の良い圧縮方法を提案した。また、手法的にもCNN/RNNを応用し、さらに後処理として画質を改善するSpatially Adaptive Bit Rate (SABR)を提案したことが評価された。
unconstrainedな顔に対してクラスタリングを行うDeep Density Clustering(DDC)を提案。顔画像をDNNによって単位超級面空間に射影する。続いて、各サンプル2点の類似度を測定する際に、 その2点の近傍に位置するサンプルを考慮することでクラスタの密度を推定することが可能となるため、これに基づいてクラスタリングを行う。
入力顔画像に対して任意の画像を生成するネットワークを提案。顔向きのコンディションとしてランドマークのヒートマップを与え、U-Netによって画像を生成し、2つのdiscriminatorを用いることで画像を生成。 1つ目のdiscriminatorは入力画像をコンディションとして生成画像or正解画像を識別し、 2つ目のdiscriminatorはランドマークのヒートマップをコンディションとして生成画像or正解画像を識別する。 また人物IDを保存するためにLight CNNによる特徴量によるロスをとる。
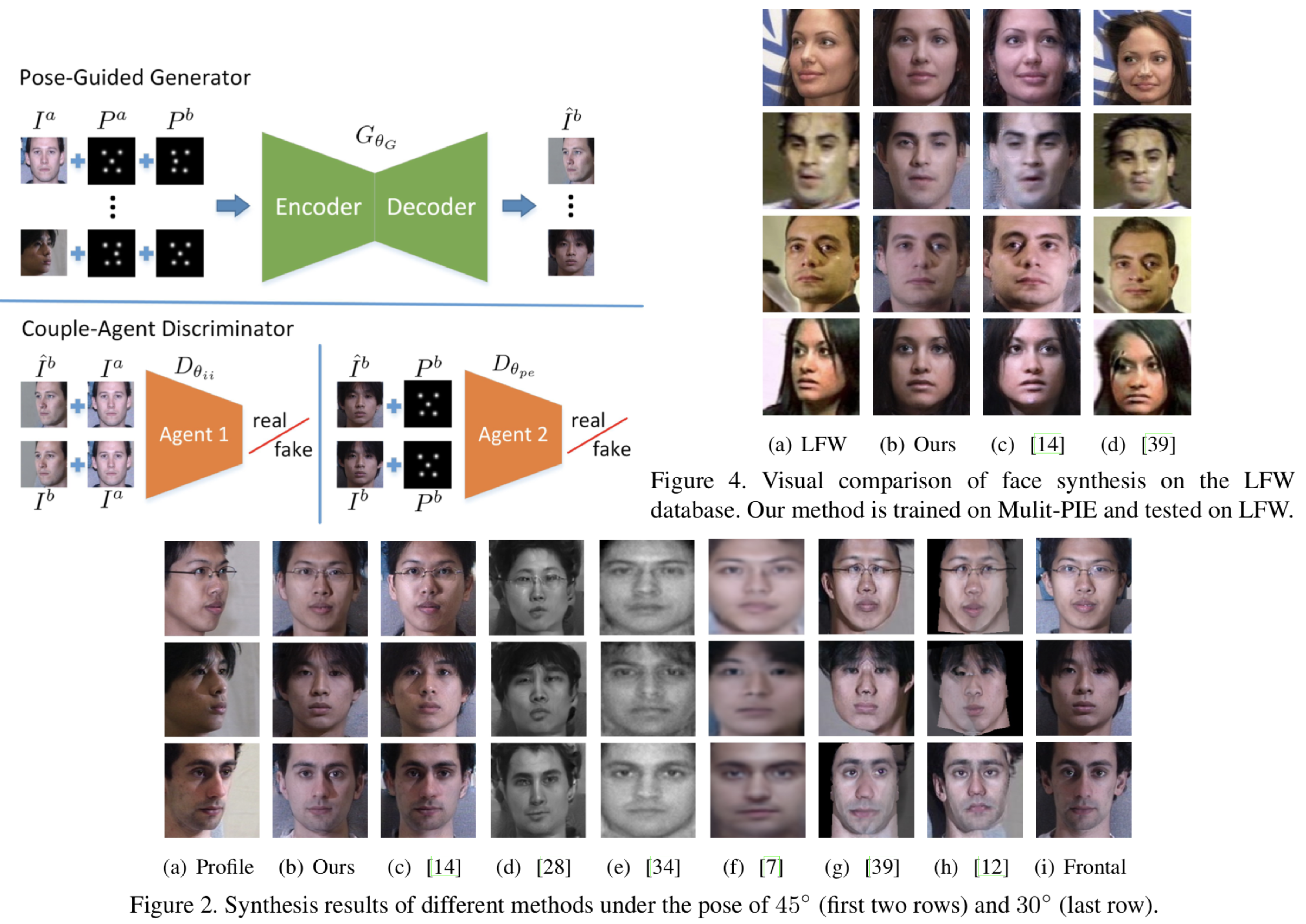
それぞれ単独の実画像データセットと3D Morphable Model(3DMM)データセットを使用し、画像から3DMMを生成する手法を提案。トレーニングには実画像データセットVGG-Face、3DMMデータセットBasel Face 3DMMを使用。 IDが保たれることを念頭にネットワークを構築。Batch Distribution Lossでは、 Basel Face 3DMMのパラメタ分布が平均0、標準偏差1のガウス分布であるため、 実画像によって生成される3DMMのシェイプ、テクスチャパラメタがどちらも平均0、標準偏差1となるようにロスをとる。 Loopback Lossは画像/生成された3DMMのdecoderによる特徴量の差分を取り、よりリアルな3DMMかつ、 より現実的な3DMMパラメタを得ることを目的としている。
ソースドメイン(SD)とターゲットドメイン(TD)のそれぞれのreproducing kernel Hilbert space(RKHS)における共分散を最適化することでdomain adaptation(DA)を行う手法。 既存のカーネルベースのDAはSDとTDのRKHS上の統計的分布の類似度に大きく依存することに着目。 共分散を最適化する方法としてkernel whitening-coloring map(KWC)とkernel optimal transport map(KOT)があり、これをRKHS上で計算で可能なように式変形を行うことでDAを行う。
VQAのデータセットにおけるバイアスを調査した上で、VQAにおけるdomain adaptation(DA)を提案。提案手法では選択肢の中から解答を選択するVQAを扱う。VQAデータセットは画像、質問、解答選択肢=正解+誤答の要素からなる。 それぞれの要素を組み合わせた入力を用いて、その入力がどのデータセットに所属しているのかを調査した結果、 画像はほぼ無相関であることがわかり、質問と解答によってデータセット間にバイアスが生じていることを確認。 この結果に基づき、以下のようにDAを提案。ターゲットドメイン(TD)に質問/解答選択肢のみがある場合、 ソースドメイン(SD)の質問/正解(誤答は任意性があるため使用しない)の特徴量が持つ分布とTDの質問のDNNによる 特徴量が持つ分布のJensen-shannon Divergence(JSD)が小さくなるように学習。TDが質問と正解(+誤答)を持つ場合、 SDが持つ質問・正解の特徴量分布とTDの質問・正解のDNNによる特徴料が持つJSDが小さくなるように学習。 さらにSDで事前学習を行った質問-正解識別をTDでfine-tuningを行う。

教師なし学習で単眼の動画から Depth と Ego-Motion の推定を行う研究. 連続するフレーム間における 3D Geometry の一貫性を教師信号の代わりに利用して学習を行う.
Point Cloud データのクラス分類についての研究. 順序不定の 3D Point Cloud データを 2D Depth 画像に変換し, ResNet でクラス分類を行う. 評価実験では PointNet より優位な結果となった.
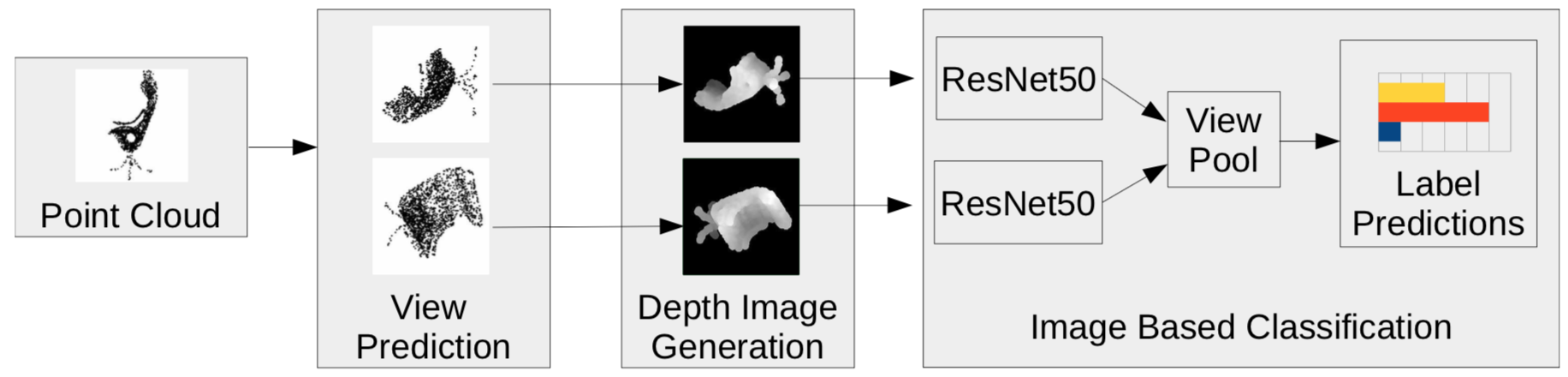
Deep binary descriptor においてバイナリを生成する際に0と1の境界に位置する曖昧なビット (ambiguous bit) の問題に取り組んだ研究. 強化学習によって学習したビット間の implicit な関係性を付加することで曖昧性を緩和する GraphBit を提案.
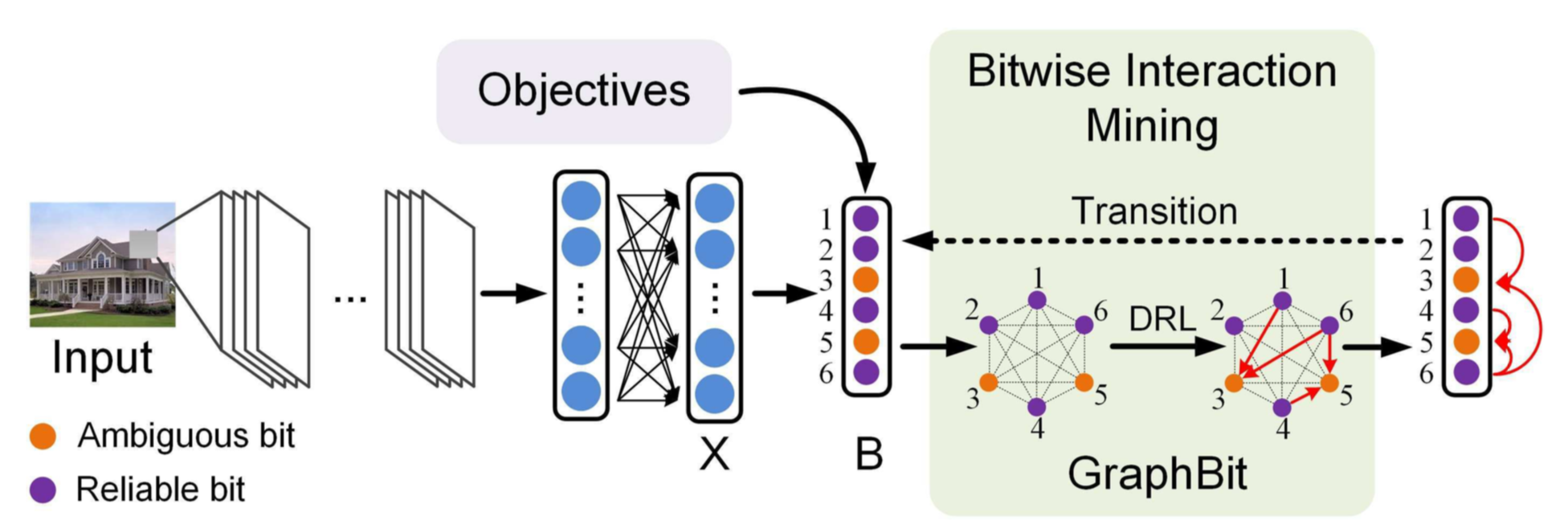
Skeleton-based action recognition の研究. 強化学習によって与えられた動画から最適な keyframe の組を選択する frame distillation network (FDNet) と graph-based convolution によって keyframe の skeleton 情報から行動認識を行う Graph-based CNN (GCNN) を提案.
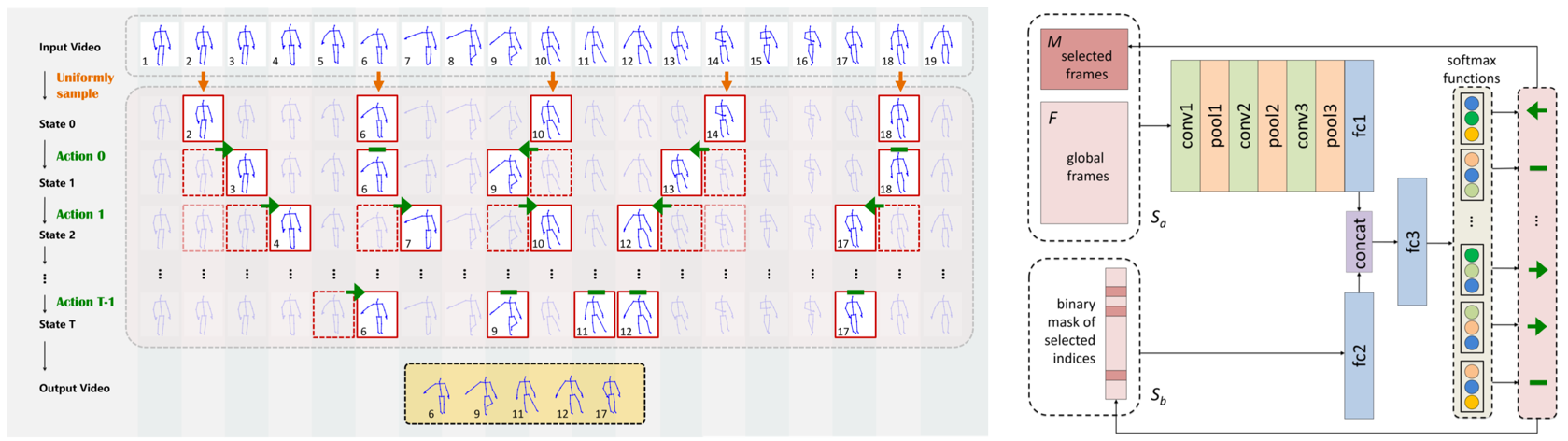
superpixel segmentationのためにピクセルの類似性(pixel affinities)を学習するdeep learningベースの手法を提案。pixel affinitiesが同一物体に属する2つの隣接画素の尤度を測る。これまで、groundtruthがないこと、superpixelsのインデックスが交換可能であること、superpixelsの手法は微分不可であることからdeep learningベースのsuperpixelアルゴリズムは試みられていなかった。論文では、segmentation誤差から類似性を学習するsegmentation-aware loss(SEAL)と、pixel affinitiesを出力するPixel Affinity Net(PAN)を提案し、superpixelsとdeep learningを統合する。既存の手法より物体境界を保持したままsuperpixelsを計算することが可能になった。
![]()
superpixels + deep learningが新しい。実験では単純なpretrained modelによる特徴量や、edge検出によるsuperpixelsとの統合はうまくいかないことを示している。手法に関しては、superpixelsを直接出力するのではなく、pixel affinitiesを計算、graph-basedのアルゴリズム(ERS)を経由し出力、そしてSEALを計算する。これにより、pixel affinitiesを出力するPANへ誤差を逆伝播することができる。
人間の三次元輪郭形状から,見えない体の内側を解析してしまおうという話.本論文では,X線画像を生成する. さらに,X線画像はパラメタライズしておくことで,体のキーポイントの調節によるマニピュレーションも可能.
構造的には,2つのネットワークからなる.(1)部分画像といくつかのパラメータから,画像全体を生成するように学習, (2)全体画像が得られるような(1)のパラメータの推定. これら2つのネットワークを,一貫性が出てくるように反復的に学習させる.
生成した画像を使ってみて,画像補間に使ってみた.
体表面を計測しておくなどして,体表面形状のデータがあれば,X線画像をある程度任意に生成できる.逆に,体表面形状をいじることでそれに対応したX線画像も作れる. 学習データとして活用することができる可能性がある.
構造はGAN風だが,いい感じに変形している感じがウケているかもしれない.
スタイル特徴量を用いて画像の見た目を変換するネットワークとドメイン間で不変な特徴量を得るネットワークを用いて、domain adaptationを行うことで教師無しでセマンティックセグメンテーションを行うFully Convolutional Adaptation Networks (FCAN)を提案。画像の見た目を変換するAppearance Adaptation Networks (AAN)では ホワイトノイズから画像を生成し、ソースドメインの特徴量マップ、ターゲットドメインのもつスタイル特徴量が小さくなるように学習を行うことで、画像をもう一方のドメインの見た目になるように変換する。 ドメイン間で不変な特徴量を得るRepresentation Adaptation Networks (RAN)ではsemantic classificationと、 それぞれのドメインにから得られた特徴量マップに対するadversarial lossと、 ASPPによって得られた特徴量マップに対してピクセルごとにadversarial lossを適用。 ドメインとして実画像とゲーム画像で検証している。
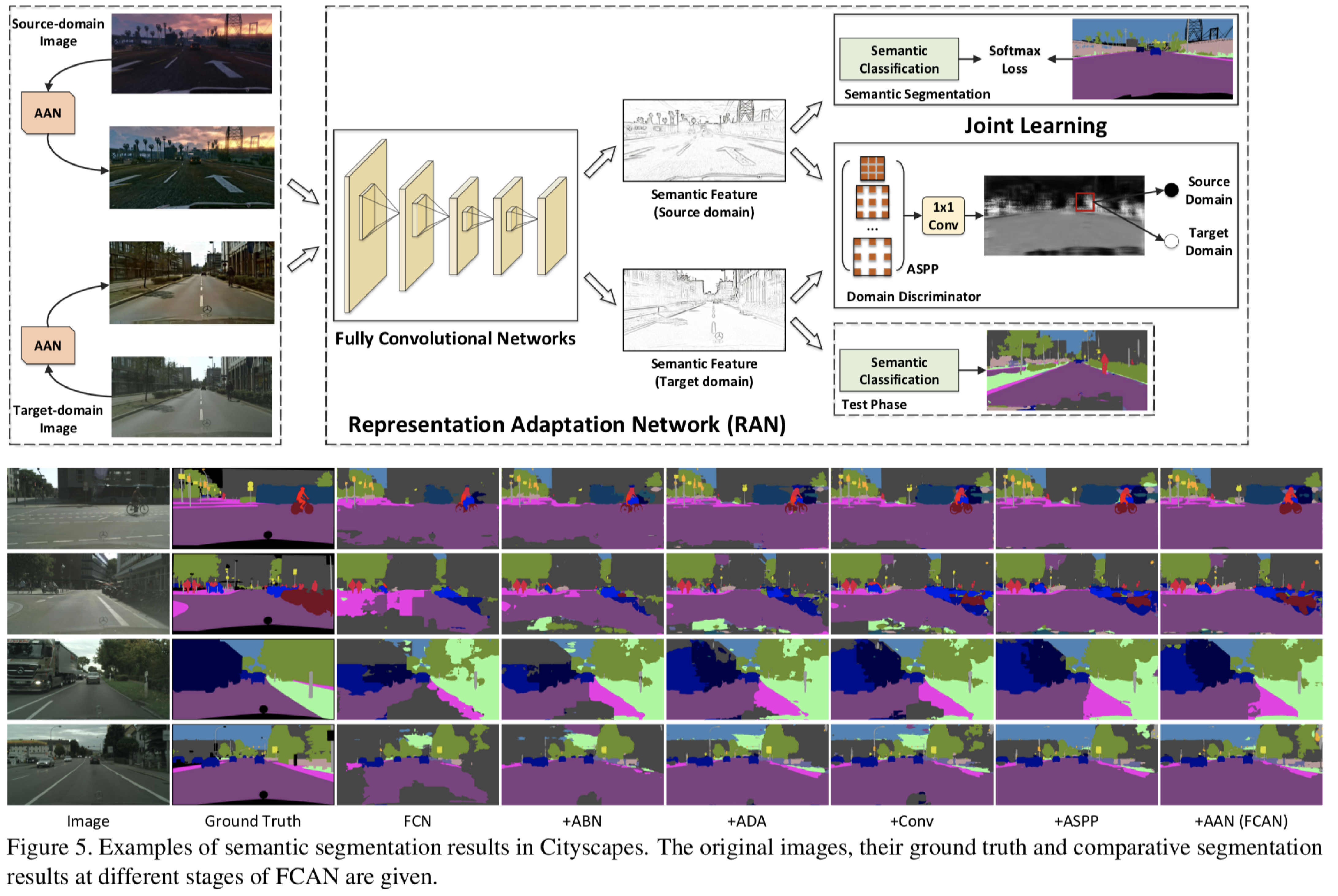
Unsupervised Domain Adaptationを行うため、ドメイン間の特徴量分布を一致させるoptimal transportベースのEM distanceを導入し、ターゲットドメイン(T)のラベル分布をソースドメイン(S)のラベル分布に対してラベルごとに重み付けした分布で表現する手法を提案。 domain discriminatorをOTベースのEM distanceをロス関数とすることでドメイン間の特徴量分布を近づける。 一方でベイズの定理より、ドメイン間のラベルの事前分布と特徴量の事後分布は比例関係にありラベルは低次元かつ離散的であるので ドメイン間で類似度が高いと仮定し、Tにおけるラベルの事前分布をSのラベルの事前分布の重みを変更したもので表す。
教師無しで画像をバイナリに符号化するハッシュ関数であるHashGANを提案。ハッシュ関数が満たすべき条件は画像が変換されて同じハッシュ値を返すこと、異なる画像には異なるハッシュ値を与えることである。 既存の教師無しハッシュ関数は過学習のために精度がよくなかった。提案手法であるHashGANはgenerator、discriminator、 encoderからなる。学習はGAN loss、encoderによって生成されるハッシュ値のエントロピーが小さくなるように、 出現するハッシュ値が同じになるように、画像の変換によるハッシュ値が不変となるように、画像ごとのハッシュ値が固有となるように、 合成画像をエンコードした際のハッシュ値のL2ロス、実画像と合成画像を入力とした際のdiscriminatorの最後の層に対して feature matchingを行う。またdiscriminatorはデータ固有の情報を識別し、encoderはデータ固有の情報を抽出しようとするため、 両者の目的が一致しているのでパラメタを共有して学習を行う。
ランドマークのGT有り顔画像とラベルなし顔動画を用いて、現在フレームに対して直接推定されたランドマークと、トラッキングによって前フレームから推定されたランドマークの位置の誤差を学習することで顔画像に対してランドマークを推定する手法を提案。 人間によるランドマークのアノテーションは正確でないため、この誤差が学習や推定精度に影響を与えてしまう。 これに対して本論文ではランドマークの推定器に最適化によって計算されるオプティカルフローを教師情報として与える Supervision by Registration(SBR)を提案。ランドマーク位置を推定するCNNに対して、 Lukas-Kanade法によるトラッキング結果とランドマークの推定位置が同じになるように学習を行う。
微分不可能な multi-stage pipline において joint optimization を可能にする environment upgrade reinforcement learning (EU-RL) を提案. 2段階の Instance segmentation と pose estimation のタスクで評価実験を行い, どちらも優位な結果を示した.
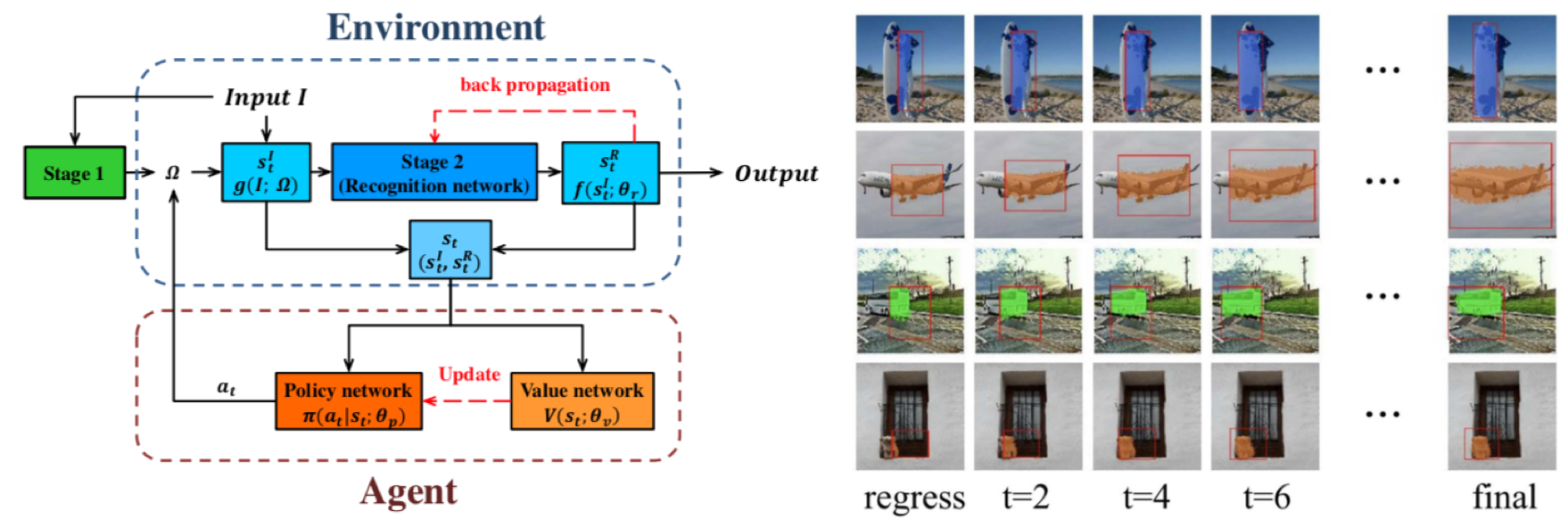
Region proposal network(RPN)と深層強化学習(DRL)を組み合わせたdrl-RPNを提案する.通常のRPNがRoIを貪欲に選択するのに対し,DRLで学習されたsequential attention mechanismを用いて選択することで,最終検出タスクに最適化される.また,時間経過とともにクラス固有の特徴を蓄積し,分類スコアに良い影響を与えて検出精度が高めることを示す.また,学習をいつ停止するか自動的に判断する.
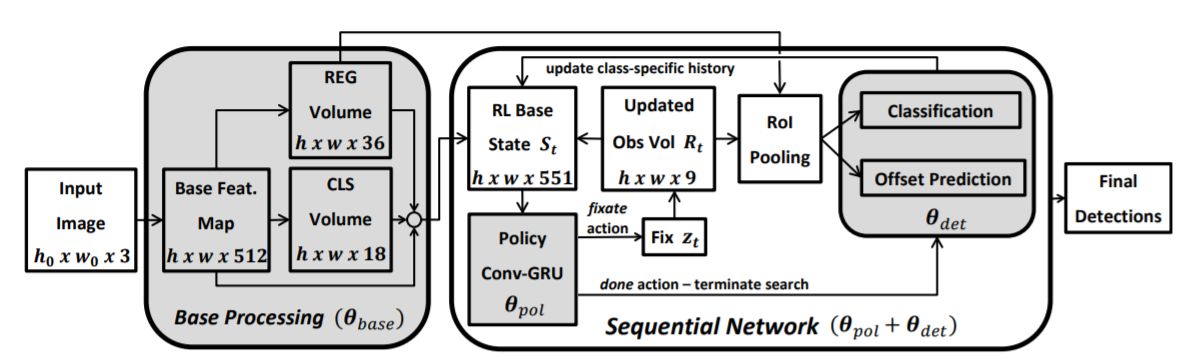
RPNにDRLを導入して,attentionに即したRoIを選択できるようにした.VOC2007を用いた評価では,通常のRPNがmAP74.2%なのに対し,drl-RPNは76.4%を達成した.MSCOCOでも各指標・各セットで数%の精度向上が見られた.
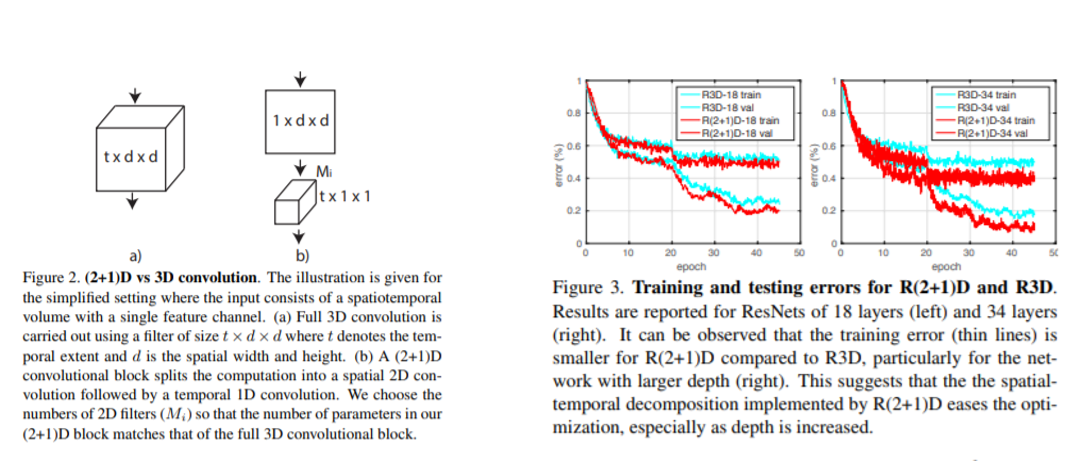
単眼の画像から深さ(depth)と表面の法線マップ(surface normal maps)を同時に予測する幾何ニューラルネットワーク(GeoNet)を提案.NYU v2 dataset、ではGeoNetが幾何学的に一貫した深度マップと法線マップを予測できることを確認.surface normal maps推定でSOTA、また既存のdepth推定方法と同等の精度を達成.
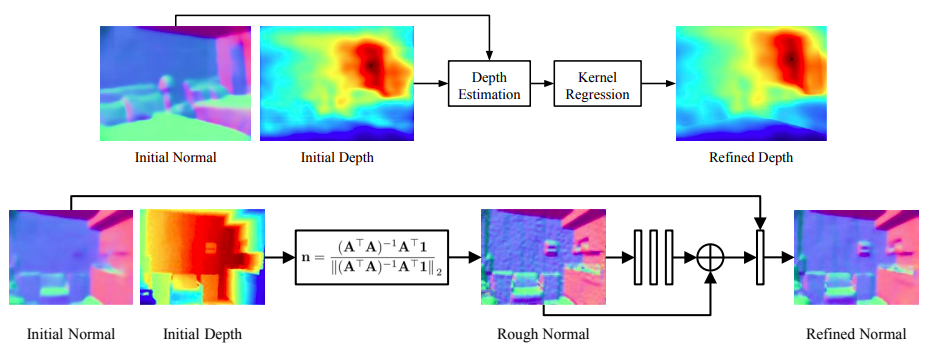
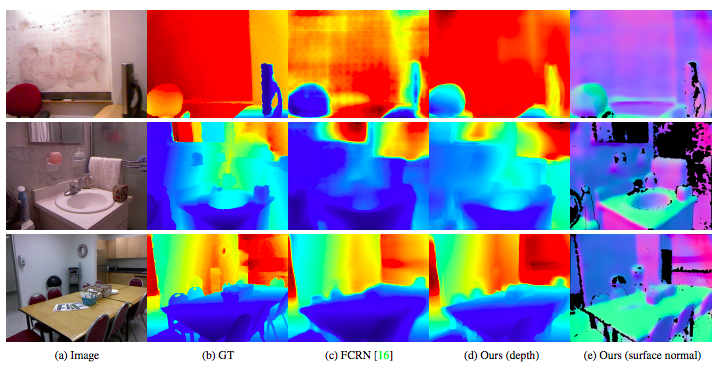
2D CNNと3D CNNの畳み込みモジュールを統合した行動認識のためのネットワークMixed Convolutional Tube(MiCT)を提案.3つの有名なベンチマークデータセット(UCF101,Sport1M,HMDB-51)においてMiCT-Netが元の3D CNNのみの手法より著しく優れていることを確認.UCF101とHMDB51での行動認識でSOTAの手法と比較し、MiCT-Netは最高の性能を発揮.
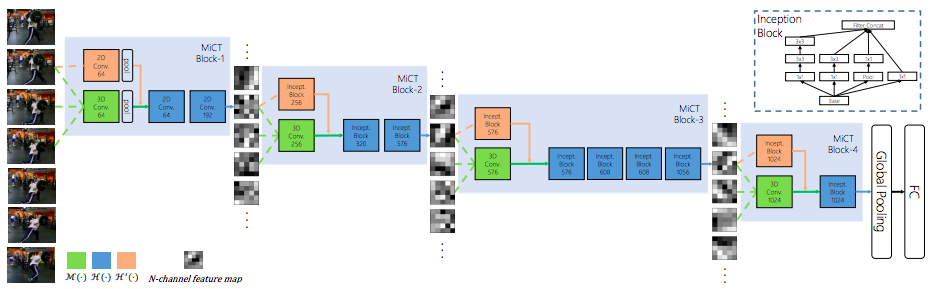

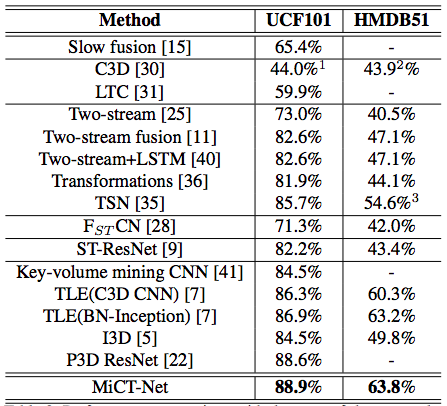
高速で大きな動きに対して加速度法の出力を頑健にするための、ジャーク(振動,ぶれ)の新規利用方法について言及.微小な変化は時間的スケールでの高速な大きな動きよりも滑らかであるという観点・観測に基づき、高速で大きな動きの下でのみ微妙な変化を通過させるジャークフィルタを設計.
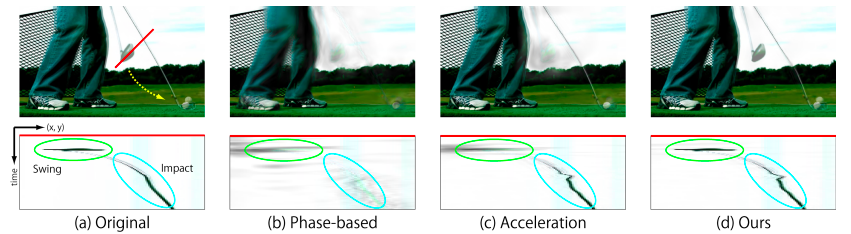
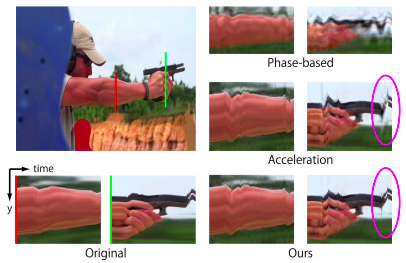
ジャークフィルタを加速度法に適用することで、最先端のものより優れた結果を確認.
Instance segmentationのような画素単位のグループ分け問題を行うEnd-to-Endで学習可能な枠組みを提案。同じグループの画素はcosine similarityが高くなるように、異なるグループはmargin以下の値になるように超球面上に回帰(Spherical Embedding Module)し、そこでRNNによるMean-shift clusteringを実行すること(Recurrent Grouping Module)で実現。
![]()
既存のregion proposalやbboxによる組み合わせたinstance segmentationの手法とは大きく異なり新しい。またこれをRNNでMean-shift clusteringを表現することで実現し、End-to-Endな学習を可能としている。加えてhyperparameterの設定に関する理論的分析も提供。instance segmentationやsemantic segmentationだけでなく、様々なpixel-levelのドメインタスクへ応用可能。
手法もシンプルでかつ効果的で応用先も広い。Fig.11の結果からsemantic segmentationにおいてもinstanceの情報が効果的に利用できそうで試してみたい。
Semantic Segmentationにおけるintra-class inconsistencyとinter-class indistinctionの問題を、Discriminative Feature Network(DFN)によって対処。intra-class inconsistencyは図の牛の一部を馬と誤認識するような現象。inter-class indistinctionは、図のコンピュータのように外見が似ている対象の区別することが難しい現象。前者の問題をmulti-scaleかつglobal contextな情報を抽出するChannel Attention Block(CAB)を持つSmooth Networkにより、後者の問題をbottom-upなBorder Networkにより緩和する。
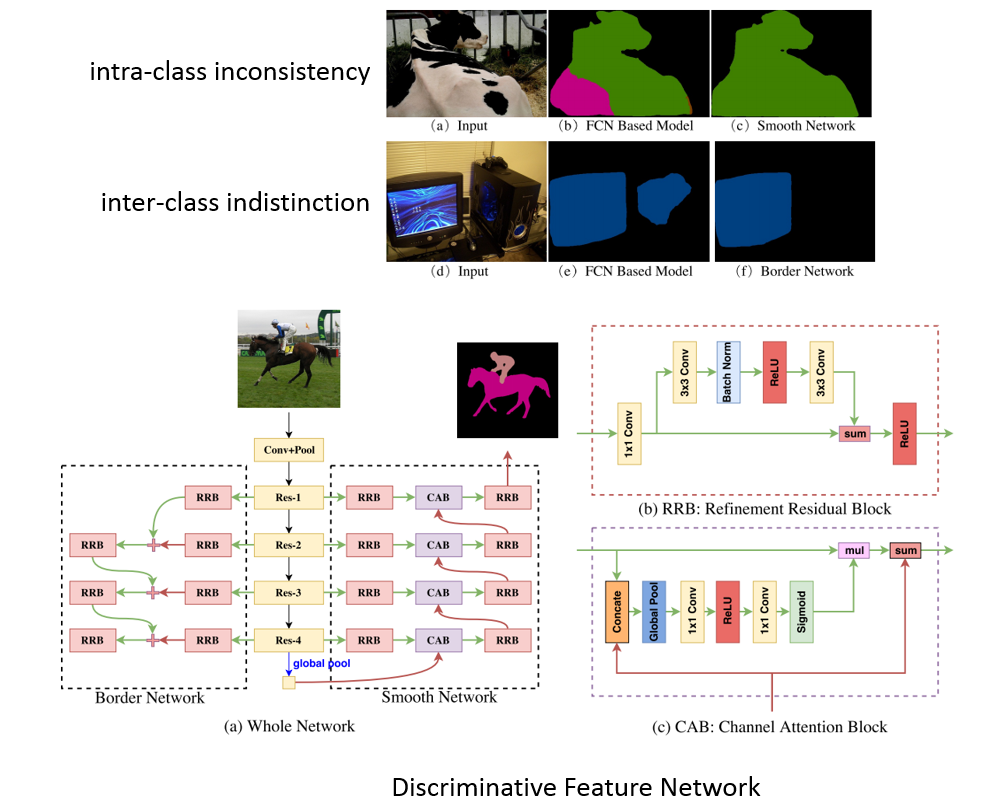
Semantic Segmentationをpixel単位のラベル付けだけではなく、物体の1つのカテゴリに対して一貫したセマンティックラベル付けをするタスクとして考えた。それゆえのBorder Networkと考える。上記の2つの問題は、必要な情報が異なるゆえ、対処の仕方をCABとU-Net構造に似たSmooth NetworkとBottom-upなBorder Networkとうまく分解している。PASCAL VOC 2012でmean IoU 86.2%、Cityscapesで80.3%を達成。
実験で各モジュールの効果を検証していたが何が効いているのかよくわからない。直感的にはBorder NetworkとSmooth Networkの分離は良いアイデアと感じたが、この分離による効果は1%未満。
書面上のコミニュケーションをする上で文書のスタイルは魅力と明快さに影響する.同一の画像からスタイルの異なるキャプションを生成するという研究.様々なスタイルの単語の選択肢とは異なる構文をもつ文章をデコードするための統一された言語モデルを開発した.
Video Object Segmentation (VOS) を強化学習によって行う研究. Object Segmentation では主に物体の領域とそれらの(周辺との)関係性が重要であるという推量に基づいて, VOS をマルコフ過程として定式化し, Deep Q-Learning を適用した. 評価実験では, state-of-the-art とほぼ同等の結果を達成した.
インタラクティブセグメンテーションに強化学習を適用した研究. 入力画像と初期 seed から自動で新しい seed を順次生成する SeedNet を提案. 評価実験では state-of-the-art の結果を達成すると共に, 教師あり手法と比較しても優位な結果を達成した.
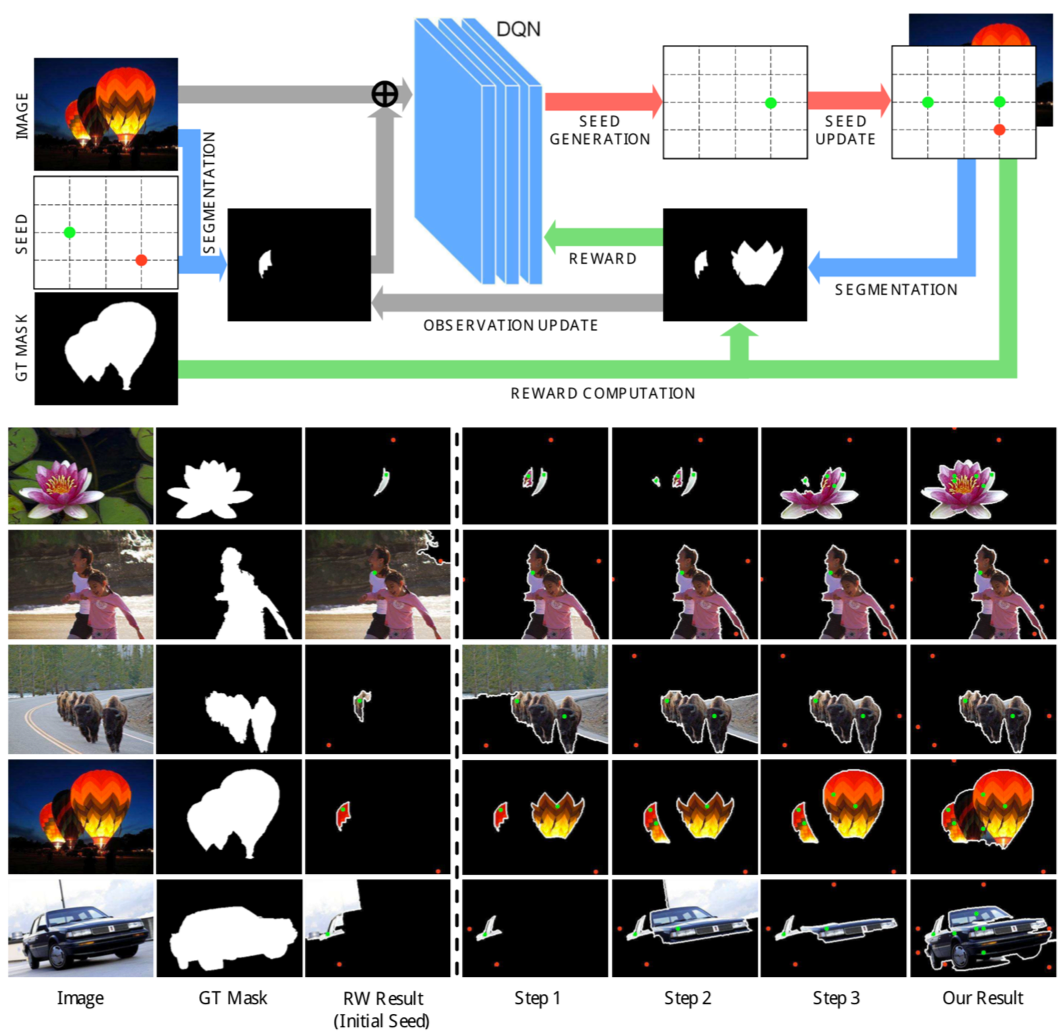
弱教師ありの Object Localization の研究. 2つの Classifier を並列に配置し, 片方の classifier で注目された領域を他方の入力から取り除いておくことで, それぞれが異なる領域に反応するような構造となっている. 評価実験では ILSVRC dataset の localization のタスクで 45.15% (new state-of-the-art) の誤差率を達成した.
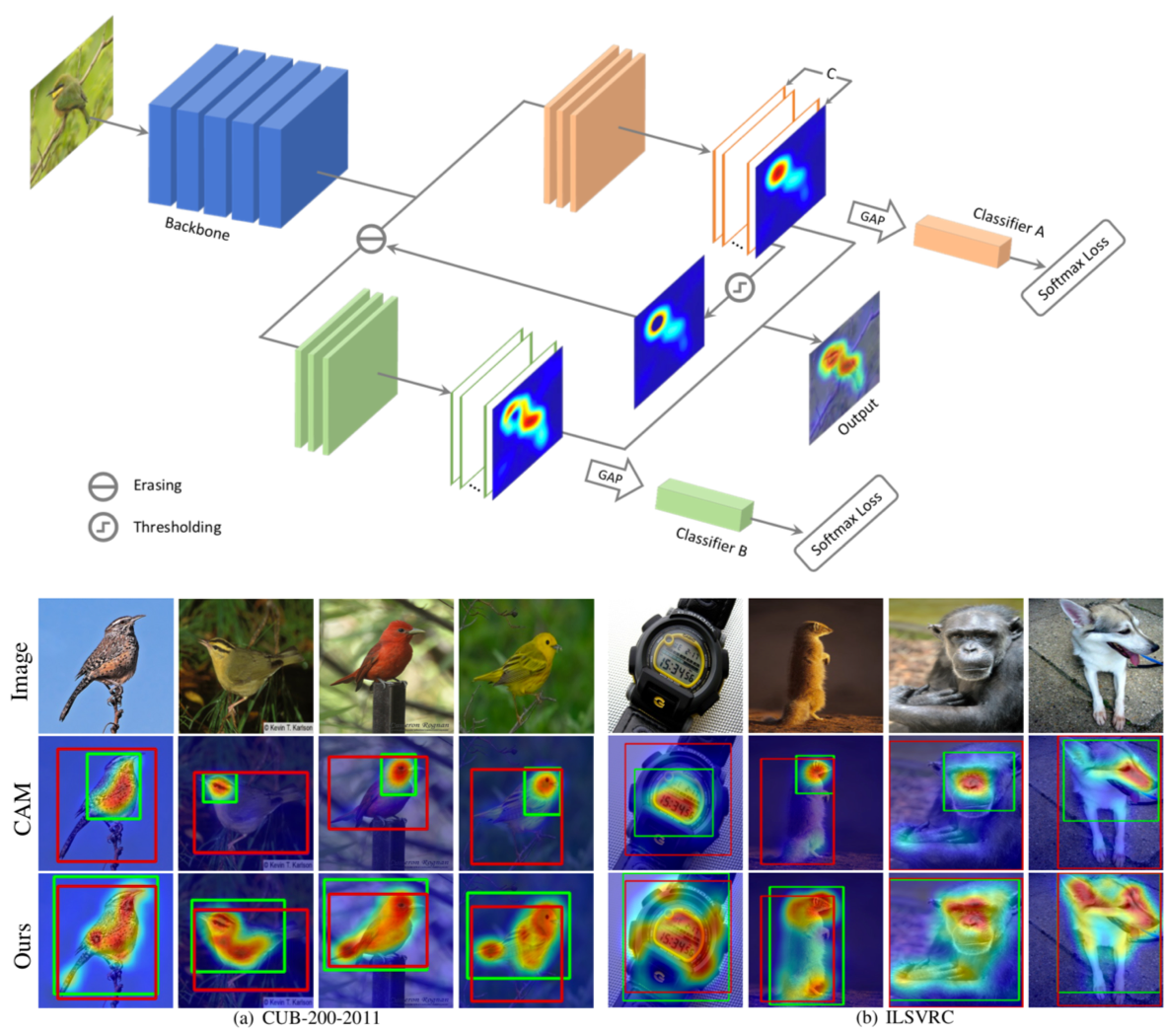
物体検出時に用いるRegion-of-Interest(RoI)を,sub-regionとアスペクト比の差を用いて再構成するFeature selective netsを提案.画像全体に対してsub-regionのattention bank(すべてのattention mapを記憶するbank)とアスペクト比のattention bankを生成する.Attention mapはbankから選択的にpoolされ,RoIの改善に使用される.処理の手順は(1)CNNから得られた特徴マップをRPNに入力しRoIを得て,(2)特徴マップのチャンネル数を削減してRoIプーリングを行い,圧縮されたRoI特徴を得る.(3)削減される前のRoIをregion-wise attention生成モジュールに入力する.特徴マップを用いてアスペクト比attention bankとsub-region attention bankを得る.(4)各bankにselective RoIプーリングを行う.そして,(2)と(4)で得られたRoI特徴と各attention mapを結合して検出サブネットワークに入力する.
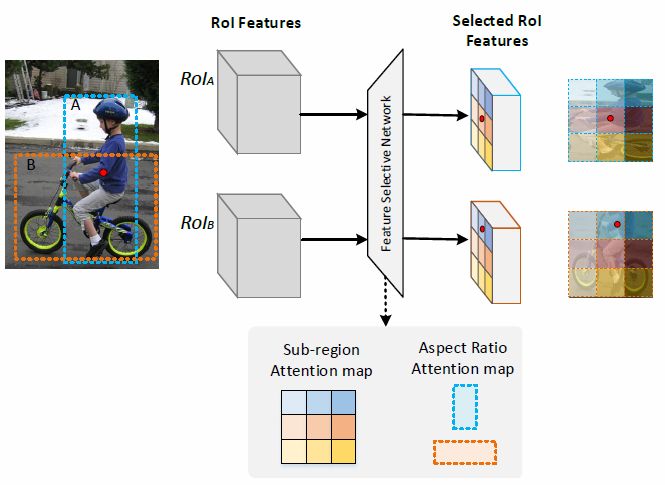
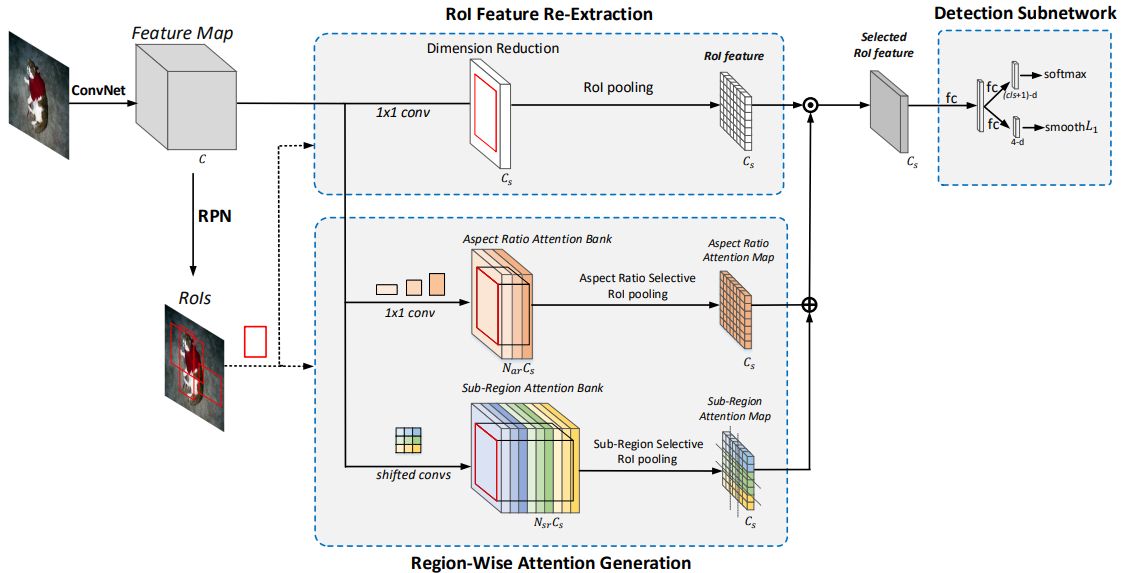
RoIをattentinを用いて補正する.VGGだけではなくGoogLeNetやResNetにも適用可能である.VOC2007を用いた評価では,mAP: 82.9%, 76.8%, 74.3% (Res101, GoogLe, VGG-16)を達成し,Faster R-CNNの78.8%, 74.8%, 73.2%(上記と同順)よりも高精度である.さらに,検出サブネットワークをシンプルにしているため,Faster R-CNNよりも高速な検出が可能である.
Bounding boxでの物体検出でグラフカットを用いて擬似的なマスク(セグメンテーション)のrefinementを行う.インスタンスセグメンテーションの学習を行うことで擬似的な物体マスクを推定できるようにネットワークパラメータを最適化する.フレームワークは検出ネットワークと擬似的なマスクのrefinementを行うグラフカットベースのモジュールからなる.RoIを入力として,ベースネットワークの特徴マップからインスタンスセグメンテーションを行い,それをグラフカットモジュールに入力して擬似的なマスクを得る.インスタンスセグメンテーションの結果はbounding boxの修正にも用いられる.
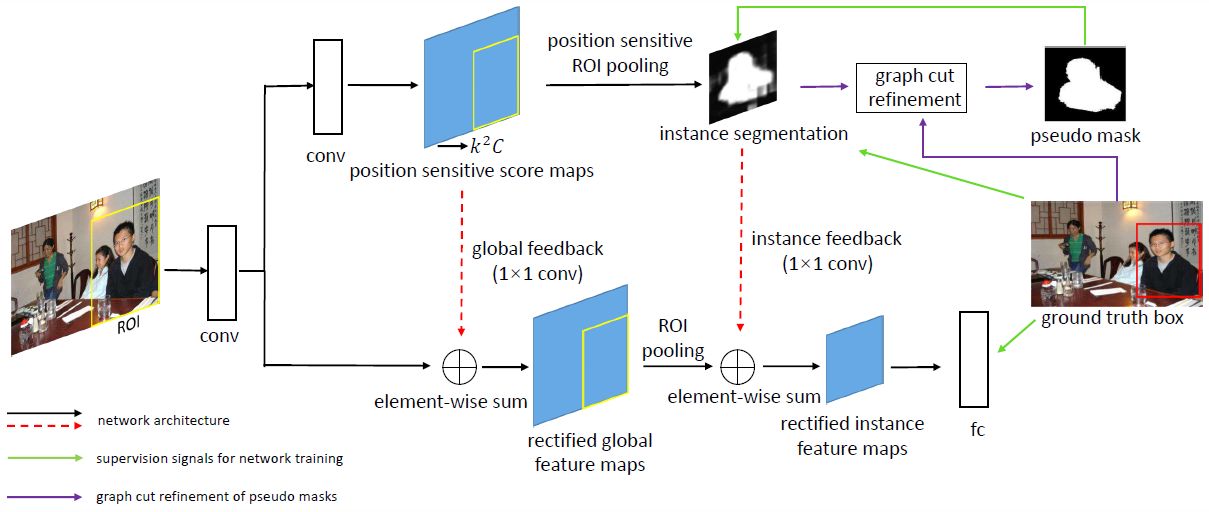

流行りの物体検出+セグメンテーションの手法.マスクを単に特徴マップから得て終わりではなく,グラフカットでrefineする部分は新しいところ.グラフカットを数iter行うことで,よりきれいなマスクを得ることができる.VOC2007/2012を用いた物体検出の精度はmAP74.4%(VGG-16)で,Faster R-CNN(70.4%)やHyperNet(71.4)よりも良い.VOC2012SDSを用いたセグメンテーションの精度は58.5/67.6(マスクレベルスコア/物体検出スコア)%であり,iterを繰り返すことで精度が向上することが確認されている.
複数画像を使用した非剛体のSfM (Non-Rigid Structure-from-Motion)に関する研究である。右図は非剛体の表面形状復元結果の一例であり、顔のように時系列的に変化する形状を、多様体の概念をSfMに導入することにより問題解決を図っている。非剛体の形状変化を、空間的・時間的な部分空間としてすいていすることでSfMを実行する。

非剛体物体の表面形状復元に関するSfM問題を、グラスマン多様体(Grassman Manifold)の問題と捉えて解決している点が新規性として挙げられる。柔軟に表面形状復元ができている様子は動画にて確認可能である。
2次元画像、もしくは3次元点群からメッシュや分解構造を生成し、テクスチャありのメッシュや3次元プリント物体を出力する。この枠組みはAtlasNetと呼ばれ、同タスクのPrecision向上と一般化の面で性能改善を行い、3次元形状を集めたデータベースであるShapeNet上で形状をAuto-Encoding、単眼画像からの形状復元を行った。その他、AtlasNetを用いてモーフィング、パラメトライゼーション、超解像、形状マッチング、共セグメンテーションを実施した。

3D表面形状生成器であるAtlasNetを構築したことが最も大きな新規性である。形状に関するパラメータを学習可能にした。さらに、AtlasNetをGitHub上で公開して使用できる形式にしている。復元したメッシュ形状も、提案手法がもっともノイズが少なく、良好な復元結果となった。
歩行者検出におけるオクルージョンやハードネガティブを改善するための提案。本提案手法は、シングルステージ物体検出手法に適応可能。オクルージョン処理のために、ベースモデルの出力テンソルを更新してパートスコアを推定し、オクルージョン認識スコアを算出する。ハードネガティブの混同を軽減するために、 average grid classifiersをpost-refinement classifiersとして導入。
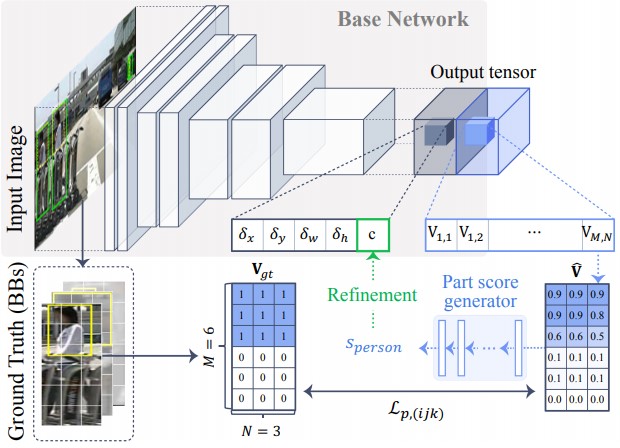
SqueezeDetやYOLOv2、SSD、DSSDを含むシングルステージ物体検出手法に適応でき、オクルージョンやハードネガティブを改善する。本論文では歩行者検出におけるオクルージョンにフォーカスを当てているが、一般物体検出にも適応できる可能性がある。
ノイズのあるラベルを含んだデータセットを使い、CNN学習を高精度に行うための新しい反復学習フレームワークの提案。反復的なノイズラベル検出、特徴学習、および再重み付けの3段階のフレームワークでノイズの多いラベルを検出しつつ、識別器を反復的に学習。再重みづけでは、クリーンなラベルの学習を重視し、ノイズの場合には低減させる。
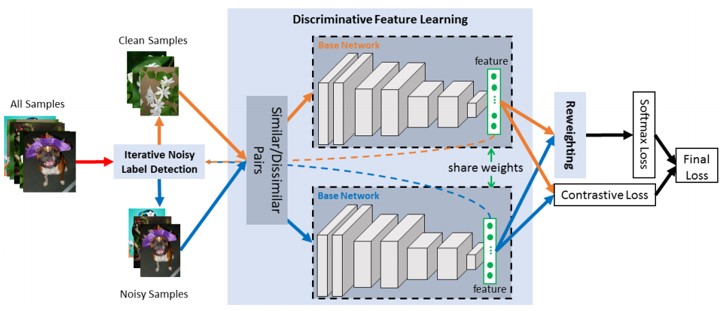
綺麗なラベルアノテーション付き大規模データセットによる学習は非常に重要だが、人の手間がかなりかかる他、ヒューマンエラーを含む可能性が否めない。本研究では、あえてノイジーなデータセットに挑戦することで、これらの問題を解決する。
正規化されたポイントクラウドを入力として、複雑な手構造を捕捉し、手の姿勢の低次元表現を正確に回帰させることができるHand PointNetの提案。Oriented Bboxでポイントクラウドを正規化し、ネットワーク入力をよりロバストにする。その後、階層的なPointNetに入力し特徴抽出。PointNetを細分化することにより、指先に対する推定精度を向上させる。
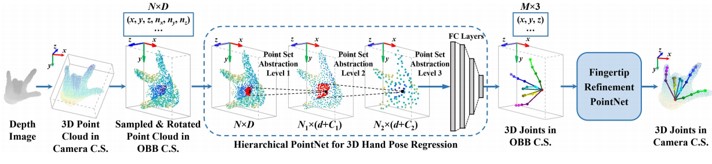
CNNを用いた従来の奥行き画像における3次元手姿勢推定手法とは異なり、本研究では三次元点群に着目している。データは、奥行き画像をポイントクラウドデータに変換してから使用している。
自動車の運転シーン理解のためのデータセットであるHonda Research Institute Driving Dataset(HDD)の提案。本データセットはサンフランシスコ・ベイエリアにて、様々なセンサーを備えた自動車を人間が運転したデータが104時間分含まれる。センサはグラスホッパーカメラ、LiDAR、ダイナミックモーションアナライザ、Vehicle Controller Area Network (CAN)の4つ。これらのデータから運転者の行動を基にアノテーションを付加している。
様々なセンサを用いて、大規模データを収集しただけでなく、ヒューマンファクタや認知科学に基づいてアノテーションを行っている。アノテーションは、Goal-oriented action, Stimulus-driven action, Cause, Attentionの4つ。
スマートフォンで撮影したノイズの多い画像で構成したデータセットSmartphone Image Denoising Dataset (SIDD)の提案。 5つの代表的なスマホカメラを使用し、様々な照明条件下で約30,000枚のノイズの多い画像を収集。ノイズの多い画像だけでなく、ノイズを除去した画像をground truthとして提案。

過去10年間で、撮影される画像は一眼レフやコンデジから、スマートフォンに切り替わったことに着目。しかし、口径やセンサ―サイズが小さいため、スマホの写真はノイズを多く含んでいる。このような、ノイズを多く含んだスマホ画像を集めることで新たなデータセットを提案する。
やはりノイズを含むスマホ画像でのトレーニングよりも、高品質な画像でトレーニングした方が、CNNで高い精度を得た。現在のタスクにおいて「スマホの画像だから精度が出ない」というのはあまり考えにくいが、日常的なアプリケーションには有用なデータセットではないか。
3Dセンサで得られた点群から3D物体検出や追跡を行う新しいDNN「Fast and Furious(FaF)」を提案.検出と追跡,さらに短期の経路予測を同時に推論でき,Sparse dataやオクルージョンに頑健な検出ができる.3D点群と時間の4Dテンソルを入力として,空間と時間に対して3D畳み込みを行う.4DテンソルはEarly FusionまたはLate Fusion(図中ではLater)で時間情報を結合している.これらは精度と効率のトレードオフ関係にある.
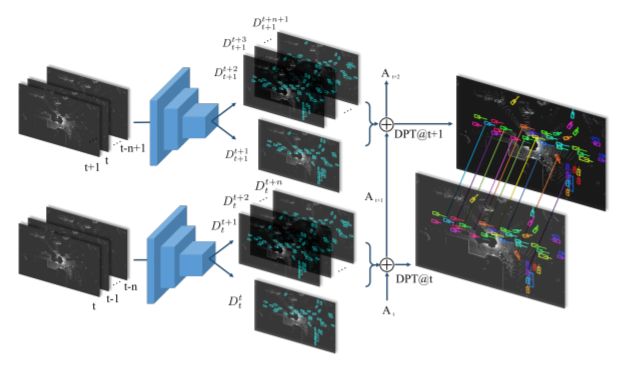
物体検出から追跡,さらに経路予測までend-to-endで行えるモデル.全体の検出時間はわずか30ms以下である.約55万フレームからなるLiDARのデータセットを作成し,車両に3D bboxとトラッキング用IDをラベリングして学習および評価に用いる.物体検出の結果はSSDのIoU 77.92mAPを上回る83.10mAPである(Late Fusionを用いることで1.4mAP向上している).追跡もHungarianと同等以上の性能で,経路予測もL2距離0.33メートル未満で10フレーム予測可能である.
人間の想像力に着目することで、メタ学習におけるLow-Shot Learningを可能にするアーキテクチャの提案。コンピュータビジョンに幻覚(想像)を抱かせることで、少ないデータから新しい視覚的概念を学習させる。アプローチとしては、メタ学習を取り入れており、 meta-learnertとhallucinator(幻覚者)を組み合わせて共同で最適化。hallucinatorは、通常のトレインセットとノイズベクトルから幻覚トレーニングセットを出力する。通常のトレーニングセットに加えて、幻覚トレーニングセットを学習することで精度向上を図る。

人間は新しい視覚的情報を素早く学習できる。これは、「物体がさまざまな視点から見たときにどのように見えるかを想像できるから」と仮定。そのうえで、人間の想像力をモデルとし、システムに組み込むことでLow-Shot Learningを可能にしている。
3次元物体認識を実行するMulti-view Harmonized Bilinear Network (MHBN)を提案する。異なるビューの特徴量を学習するために基本的にはパッチベースでマッチングを行う。Polynomial Kernel/Bilinear Poolingの関係性を記述するために、畳み込みによる3次元物体表現とBilinear Poolingを実行する。MHBNの枠組みはEnd-to-Endでの学習が可能である。構造は右図のように示され、畳み込みにより特徴マップ(3次元物体表現)を生成、最後にBilinear Poolingを通り抜けて識別を実行。
3次元物体認識の場面においてSoTA。ModelNet40, ModelNet10ではそれぞれ94.7 (Instance)/93.1 (Class), 95.0 (Instance)/95.0 (Class)である。
アピアランス/ビューポイント/背景など、分解された(Disentangled)人物画像の生成を行うための研究である。この目的のため、2ステージの生成手法を考案した(右図を参照)。1ステージ目はリアルの埋め込み特徴(Embedding Features)を獲得する学習を行い、前景/背景や姿勢などを表現。次に2ステージ目は敵対的学習により生成的特徴学習を行いガウシアンノイズから中間表現にマッピング、特徴変換を行う。
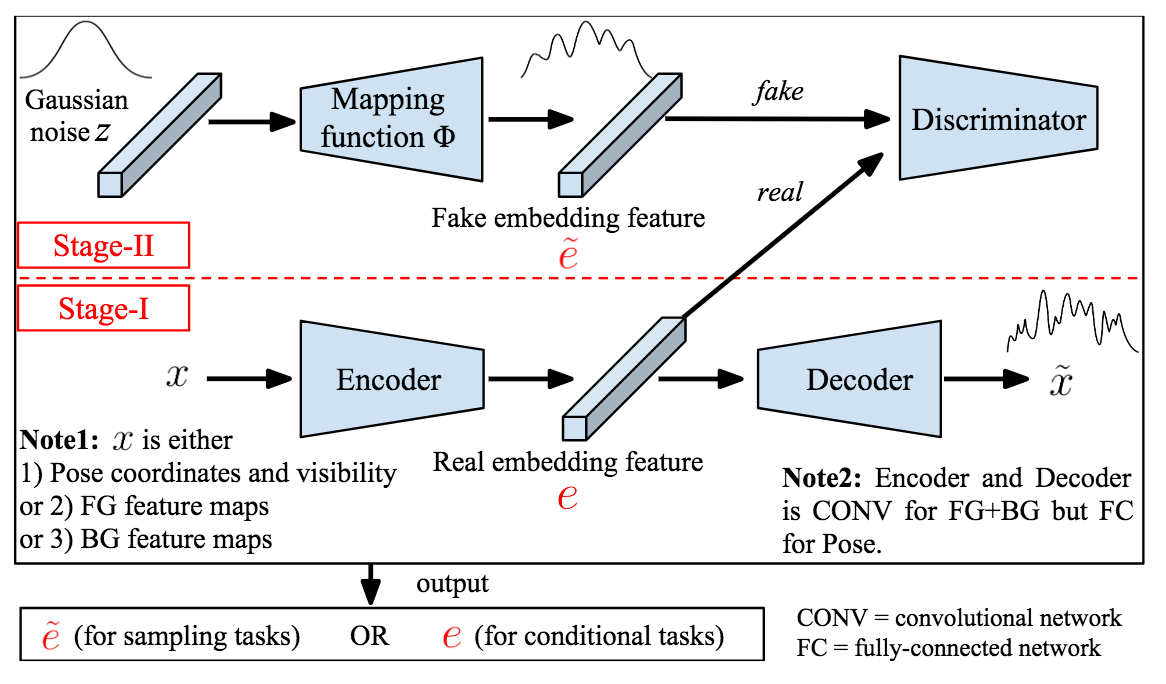
姿勢ベースの人物画像を生成し、人物再同定(Person Re-Identification; ReID)の学習に適用。人物画像生成自体も誤差が少なく、ReIDのためのにおいても良好な精度を実現した。
異なるビューポイントの距離画像入力から、低次元の潜在表現を利用して手部領域追跡の学習を実行する研究である。ビューポイント推定の誤差をフィードバックして、教師なしでも手部の姿勢推定に必要な潜在表現を獲得する。これにより、必要なのは対象となるビューポイントではなく、第二のビューポイントのみであり、ラベルあり/ラベルなしの場合においても効果的に学習することができる(Semi-supervised Learningの枠組みで学習可能)。
あるビューポイントの距離画像が手に入れば、異なるビューポイントに関する手部領域の姿勢推定が可能になるSemi-supervised Learningを提案。異なるビューポイントの低次元潜在表現を学習し、3Dの関節位置を推定することができる。NYU-CS dataset/MV-hands datasetにてState-of-the-artな精度を達成。
Fine-grainedなスポーツ動画キャプショニング
RGBのみの動画入力からリアルタイムに3次元手部関節位置推定を実行する手法を提案。YouTubeのようなコントロールされていない場面においても3次元手部関節位置推定を行うことができる。本論文では3次元のハンドモデルとCNNを組み合わせることによりトラッキングを実行しており、GANによる生成ベース(手の3次元合成データをリアルに変換していることに相当)の手法によりオクルージョンやビューポイントの違いに頑健である。GANはAdversarial LossとCycle-consistency Loss、さらには幾何学的な整合性を保つためにGeometric Consistency Lossを最適化するよう学習。
GANをベースとして合成データからリアル画像を生成、同データで学習したモデルは、RGB-onlyな3次元ハンドトラッキングにおいてState-of-the-artである。敵対的学習を用いたデータ生成手法、YouTube等のあまり校正されていないデータにおいても良好な精度を実現していることが採択された理由であると考える。
キャリブレーション済みの2カメラにおける相対姿勢の推定問題を解くための全体最適化法(Globally Optimal Solution)を提案する。局所最適解ではなく、グローバルな最適化が計算できることが新規性である。本論文では、凸最適化の問題においてあらかじめ定義された問題(Shor's Convex Relaxation)としてQuadratically Constrained Quadratic Program (QCQP)を扱うことを実施する。ここに対して、理論的かつ実験的な解答法を提示したことが本論文の貢献である。
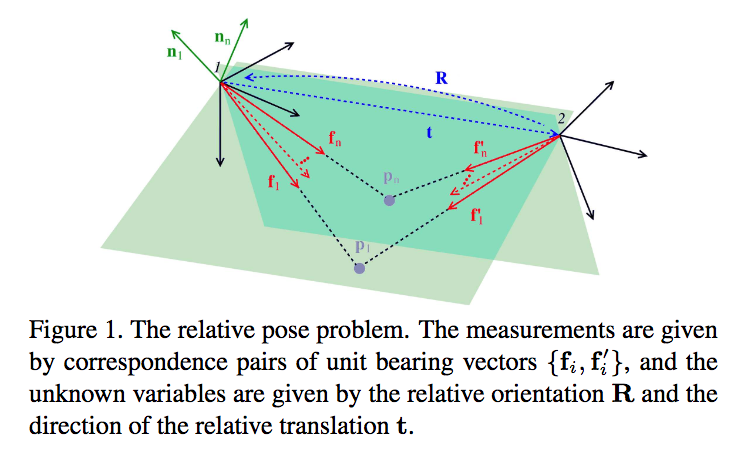
2カメラの相対姿勢問題の解決のために従来の凸最適化手法を適用して、理論的かつ実験的に解決できることを示したことが新規性であり、CVPRに採択された理由である。
LiDERで取得したポイントクラウド、車載カメラ映像、および一般ドライバーの運転動作からなるLiDAR-Videoデータセットの提案。運転動作は、ハンドルの傾きと自動車の走行速度情報によるもの。また、これらのデータを使い、自律走行における運転手段を決定するためのPolicy Learningを提案。 これは、DNN+LSTMで構成されるアーキテクチャである。3種類のデータの対応時間を登録することでどのように運転するかをベンチマークする。
自律走行において、これまではカメラとレーザースキャナー、運転動作を組み合わせたデータやアプローチがなかった。本論文ではデータベースを構築したうえで、自律走行に対するアプローチを提案している。
CNNの浅い層ではドメイン固有の特徴量を、深い層ではドメインに不変な特徴量を取得することでdomain adaptationを行うCollaborative and Adversarial Network(CAN)を提案。 従来のDomain Adversarial Training of Neural Network(DANN)ではドメインに不変な特徴量を学習することができるものの、ターゲットドメイン固有の特徴量を得ることが難しいという問題があった。 提案手法では、CNNの浅い層では低次の特徴量を、深い層では高次の特徴量を取得することができることに着目し、 CNNのそれぞれのブロックに対するdomain discriminatorに対して、浅いブロックではソースドメインとターゲットドメインを識別可能となるように、 深いそうでは識別が不可能となるように学習を行う。ソースドメインに対してはクラスの識別も行う。 またテストデータに対してpseudo labelingを行うIncremental CAN(iCAN)も提案。 ターゲットドメインのサンプルのうち、高いconfidenceでソースドメインであると判定され、 かついずれかのラベルに対するconfidenceが高いものに対してpseudo labelingを行うことで、データセットを拡張しdomain shiftを解消する。
顔の境界線を事前分布として使用することで、顔のランドマークを推定する手法を提案。既存手法でジゼ情報として使用されている顔のパーツは情報が離散的であり、 顔に対するセマンティックセグメンテーションであるface parsingは鼻に対する精度が良くない。 一方で顔の境界線は定義がはっきりしており、かつ顔の形状から推定することが可能。 提案手法では顔の境界線をstacked hourglassをベースとして、オクルージョンに対して頑健になるようにmessage passing layer、 推定精度の向上のためにadversarial netを導入している。推定された顔の境界線を元に、顔のランドマークを推定する。
ソースクラスのBBoxアノテーションを使って、弱教師付きのトレーニング画像からターゲットの物体検出器を学習する知識転移手法の提案。まず、ソーストレインセットでproposal generatorをトレーニングし、それをターゲットトレインセットに適用。次に、画像のクラスラベル(Bboxなし)を使用し、知識転移でMultiple Instance Learning(MIL)を実行。 MILによって、物体検出器をトレーニングするために使用する、ターゲットクラス用のBBoxを生成。最後に、ターゲットの物体検出器をターゲットテストセットに適用。
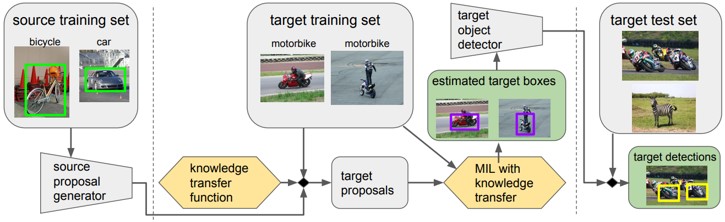
物体候補とクラスを段階的に知識伝達していくフレームワーク。これにより、固有のクラスやジェネリックなクラスに渡る、広い知識伝達を可能にすることができる。
距離空間/距離画像の超解像を行う(Super-Resolution)を行う技術を提案。従来はShape-from-shadingにより行って来たが、形状の複雑性(誤りを含む)が存在していたため、これを改善する手法を提案した。
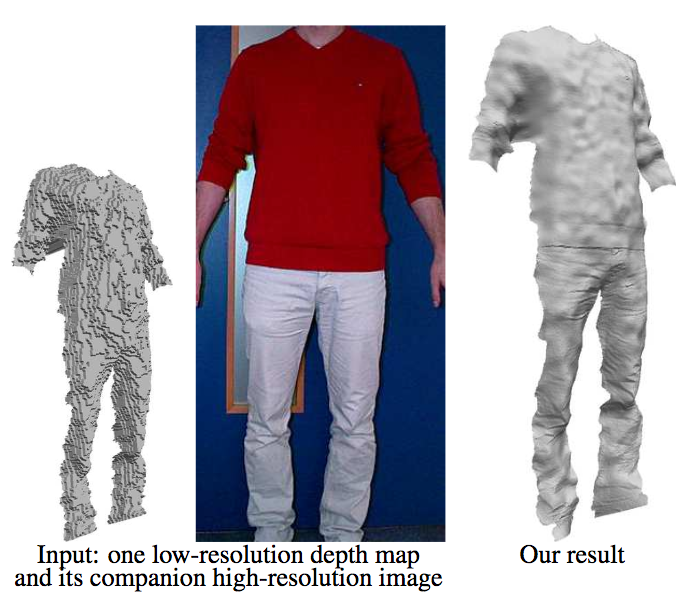
距離画像における超解像を行うための最適化手法を提案した。結果は図に示すとおりである。
人物の姿勢を事前情報として、ある視点の人物画像の入力からビューポイントを変更した人物画像を合成する手法を提案する。右図では3ステージのフレームワークについて示しており、最初のステージでは角度情報を挿入した姿勢変換、次のステージでは角度変化した人物にアピアランスを挿入、最後に背景を自然に挿入するステージ、という感じで変換が進んで行く。どう枠組みを実行するため、特にステージ2ではAdversarial Lossが、ステージ3ではForeground/Global Adversarial Lossを適用して誤差を計算する。
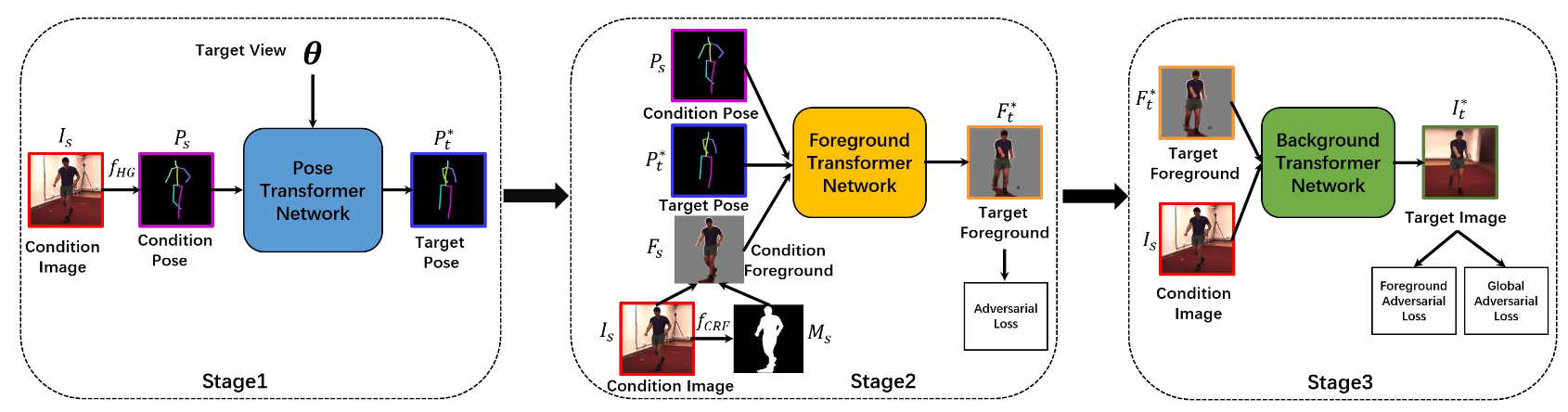
評価は生成した画像のPSNR(シグナル・ノイズ比)、正解値との誤差SSIMを計算して、提案手法がもっとも優れた数値を出していることを明らかにした(SSIM: 0.72, PSNR: 20.62)。
2次元画像と3次元手部モデルを同様の空間で扱うことができるCross-modal latent spaceを提案して、手部姿勢推定を実行する。別々にクラスタリングするのではなく、同一の空間で扱う(2DRGB-3D空間関係なく、同じ姿勢は同じような空間位置に投影される)方がマッチングの際にも便利。この特徴空間を学習するためにVariational Auto-Encoder(VAE)の枠組みで、Cross-modalのKL-divergenceを学習する。
2D-3Dの共通空間を学習することで、2D画像からダイレクトに手部の3D関節点推定に成功した。距離画像との単一空間も学習可能とした。同一空間上で扱えるようにして、かつ従来法よりも精度向上が見られたため、CVPRに採択された。
マルチレベルのコンテクスト情報を選択的に統合する、顕著性のためのProgressive Attention Guided Recurrent Networkの提案。Attention Moduleを複数組み込み、その出力をステップ形式で統合していく。高レベルのfeatureを使って、低レベルのfeatureをガイドするイメージ。また、ネットワーク全体を最適化するためのmulti-path recurrent feedbackを提案。これにより、上部の畳み込み層からのセマンティック情報を、浅い層に転送することができる。
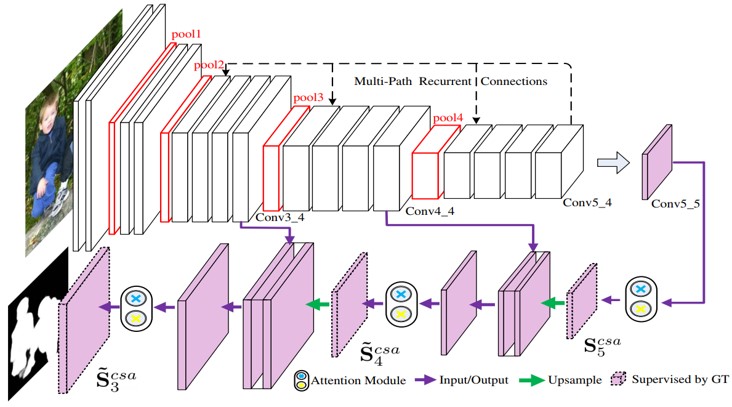
顕著性推定のための学習方法の提案。 従来のFCNベースの方法では、情報を区別せずに多レベルの畳み込み特徴を直接適用してしまうため、精度が上がらないと指摘。複数の層、複数のAttention Module出力を使い、コンテキスト情報を統合するので強力な特徴を抽出できる。
マルチスケールに対応した物体検出器であるScale-Transferrable Object Detection(STDN)の提案。STDNは DenseNet-169をベースとし、複数の物体スケールに対応するためのsuper-resolution layersを搭載。このsuper-resolution layersによってアップサンプリングすることで高解像度のfeature mapを得られるので小さな物体に対応し、大きな物体にはpooling層で対応する。
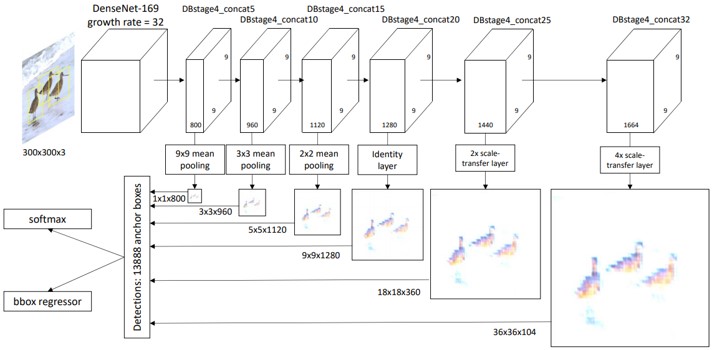
従来の物体検出手法では、様々なサイズのfeature mapを組み合わせるなどして、スケールに対応していたが、やはり小さな物体は苦手。本手法では、super-resolution layersという新たな手法によって改善を図る。
人物姿勢推定において「似たような姿勢はほぼ同じセグメント結果を保有する」という前提で弱教師付き/半教師あり学習を実行する。ある対象画像が入力された際にはほぼ同じ姿勢のデータをDBから検索して知識を転用(Pose-guided Knowledge Transfer)学習を実行する。その際に姿勢による拘束条件(Morphological Constraints)を入れ込むことでピクセルベースの姿勢のセグメンテーションを実行。モデルは全層畳み込みネット(Fully Convolutional Networks; FCN)を適用。
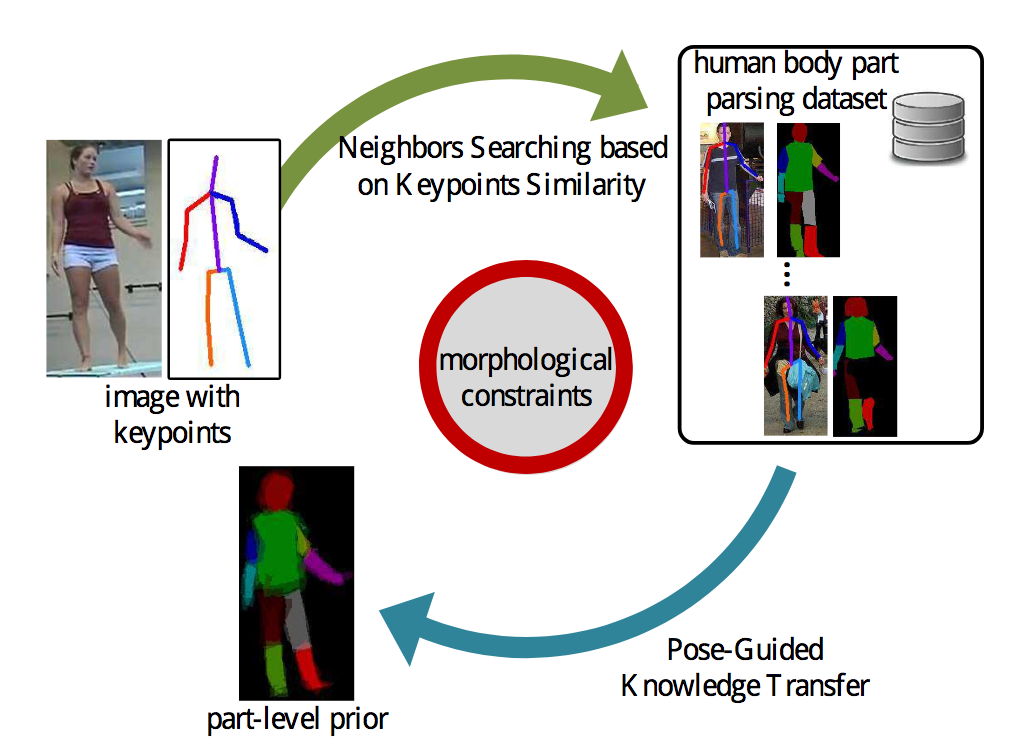
弱教師付き学習(類似の姿勢を検索して対応づける)/半教師付き学習(少量のデータがあれば学習を実行)、いずれの手法でも姿勢学習を実行することができる。その上でデータ量を確保することに成功し、PASCAL-Part datasetにてmAPが3ポイント向上した。
オクルージョンに頑健な、Faster R-CNNベースの歩行者検出手法の提案。歩行者検出について解析することで、CNN特徴の各チャンネルがそれぞれ異なる身体部分を活性化していることに着目。(実際にチャンネルごとにアテンションを取ることで確認)各チャンネルが異なる身体部位を表現しているならば、オクルージョン発生時に身体部位の特定の組み合わせを定式化することができる。

歩行者検出器におけるCNN特徴について解析することで、歩行者に特化した物体検出を可能にしている。Faster R-CNNにAttention Networkを追加したアーキテクチャを提案。これにより、上位featureの重みパラメータを調節。
IDを保った任意の顔向き画像をGANで生成するために、実画像ドメインと合成画像ドメインのそれぞれのIDを識別するclassifierを導入したFaceID-GANを提案。従来のGANではgeneratorとdiscriminatorが競い合うだけでclassifierは補助的な機能を果たしていたが、 提案手法におけるclassifierは実画像に対しては実画像ドメインのID番号を、 合成画像に対しては合成画像ドメインのID番号を識別させる、というようにデータセットに含まれるN個のラベルに対して、 2Nのラベル識別を行う。 他にも実画像のIDを表す特徴量と合成画像のIDを表す特徴量のコサイン類似度をロス関数として使用することで、 異なるドメインに属する特徴量の類似度を高める。generatorには顔の形状特徴量、顔向き特徴量、ランダムノイズを入力とする。
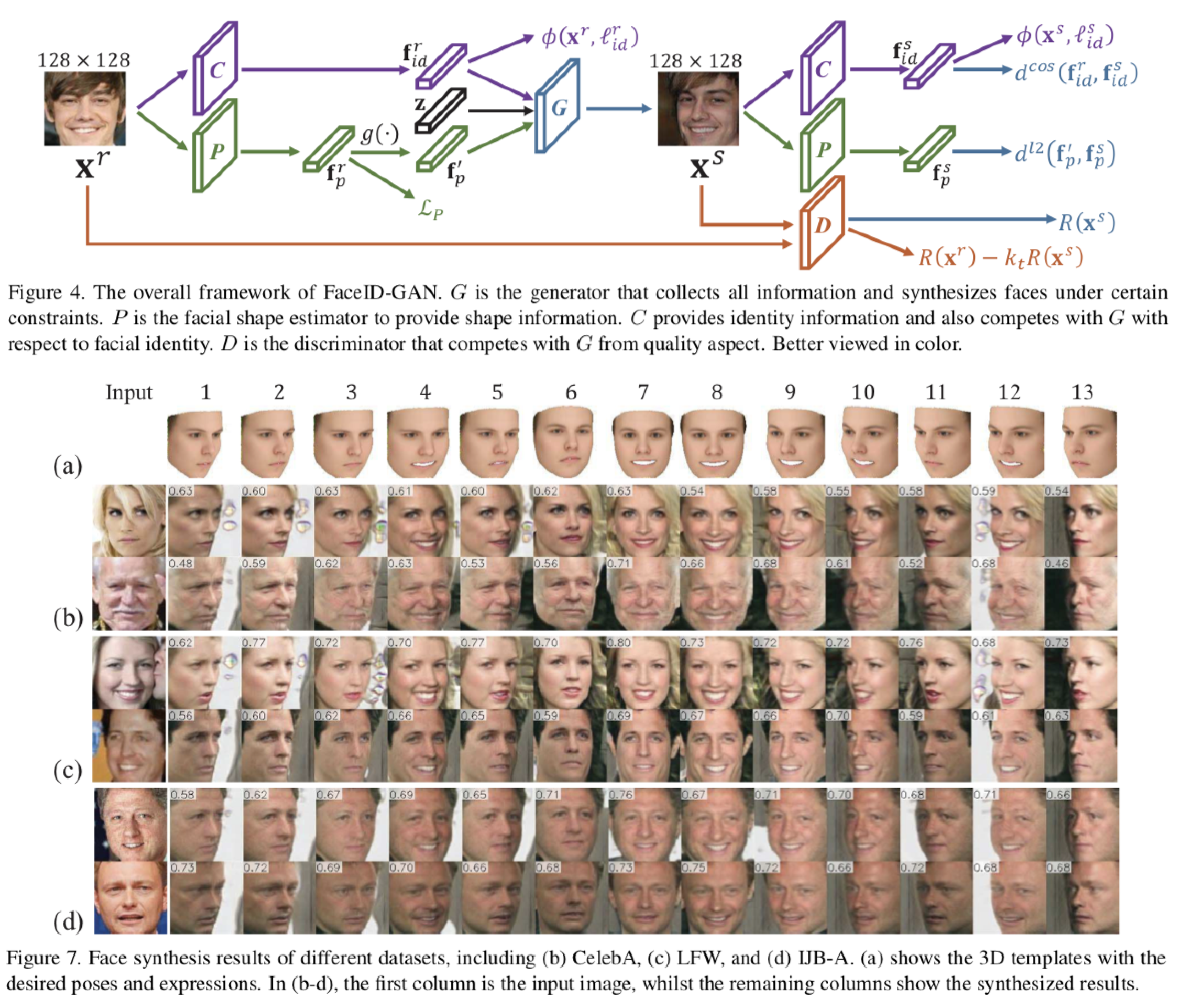
高解像度かつ短いスペクトルバンド幅で撮影された画像であるhyper resolution hyperspectral image(HR HSI)を、HR HSIの正解データなしで、広いスペクトルバンド幅で撮影された高解像度画像(HR MSI)と、短いスペクトルバンド幅で撮影された低解像度画像(LR HSI)を用いて生成する手法を提案。 高解像度かつ短いスペクトルバンド幅で写真を撮影することはハードウェア的に困難であり、データセットの構築も難しい。 提案手法ではHR MSIとLR HSIをトレーニングデータとして2つのencoder-decoderを用いる。 HR MSIとLR HSIにはそれぞれ独立のエンコーダーが適用されるが、LR HSIから得られるスペクトル情報を共有するため、 デコーダーは共有する。またスペクトル係数の総和は1という物理的な制約を実現するために潜在変数がディリクレ分布に従うようにする。 また推定されたスペクトルに対し得てスペクトル空間上の角度の差が小さくなるように学習を行う。
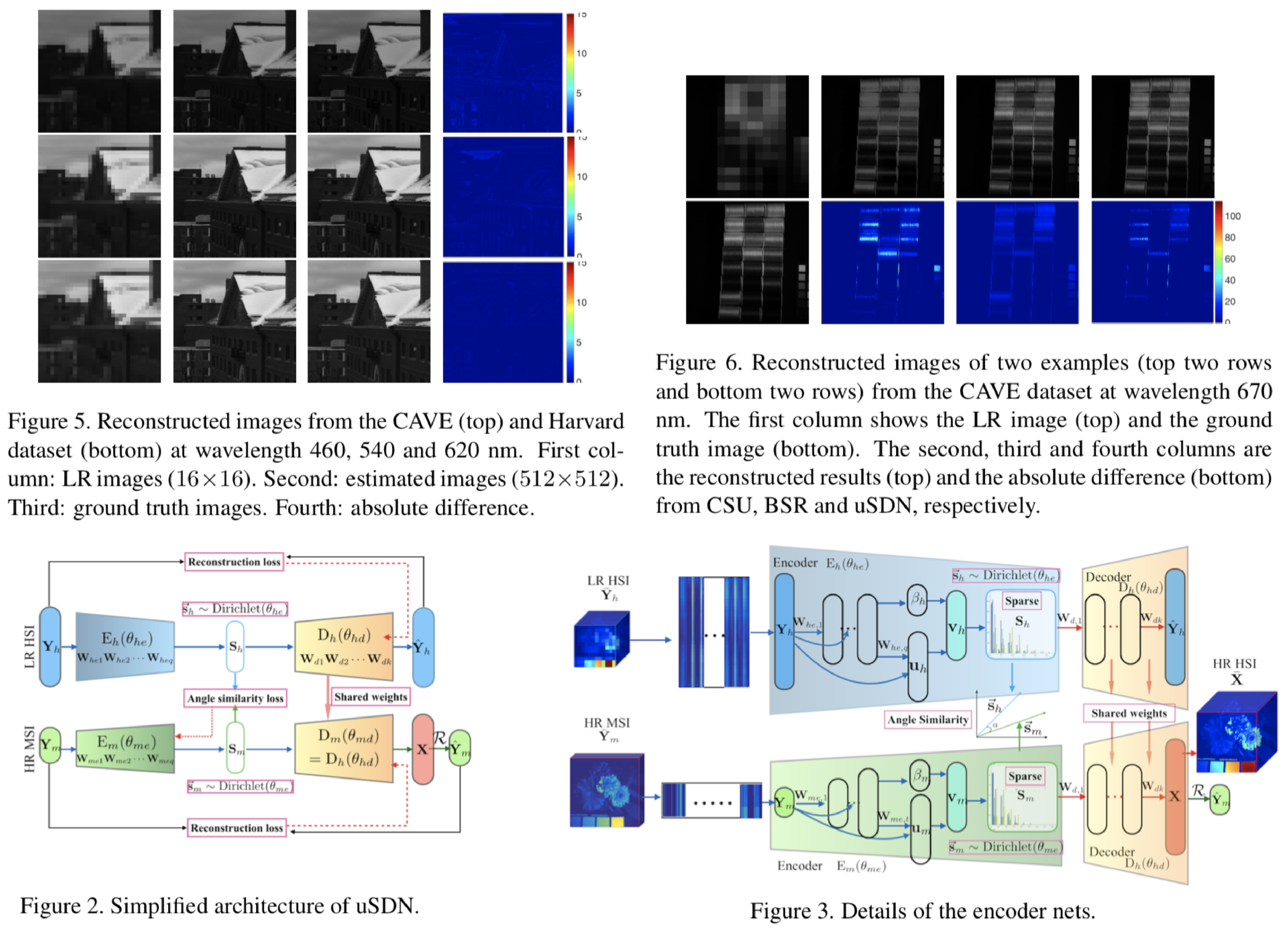

画像からの3次元形状構造復元がvolume復元と比べパラメータ数が圧倒的少ないので,問題自体の難しさも低い.しかし実応用を考えると,構造復元がかなり応用場面が多いと思う.問題設定がとても良いと思う
逆に今までどうしてやる人がなかったのが分からない
今後”analysis by synthesis”,”inverse graphics”などの概念の引用が増やしそう
かなり様々なところで工夫をしている.
動画中の物体検出において精度とコストの柔軟な trade-off が可能となる Scale-Time Lattice を提案. Propagation and Refinement Unit を用いて時間とスケールについての upsampling を階層的に行う. ImageNet VID dataset を用いた評価実験では先行研究と同等の精度の結果を Realtime で得られた.
強化学習(DQN)を用いて automatic color enhancement を行う研究. 編集後の画像のみを利用して学習を行う方法(distort-and-recover scheme)を提案し, この学習方法の場合は従来の教師あり学習の手法よりも, 強化学習を用いる方が適していることを検証した. また, 評価実験では先行研究と同等か優位な結果を達成した.
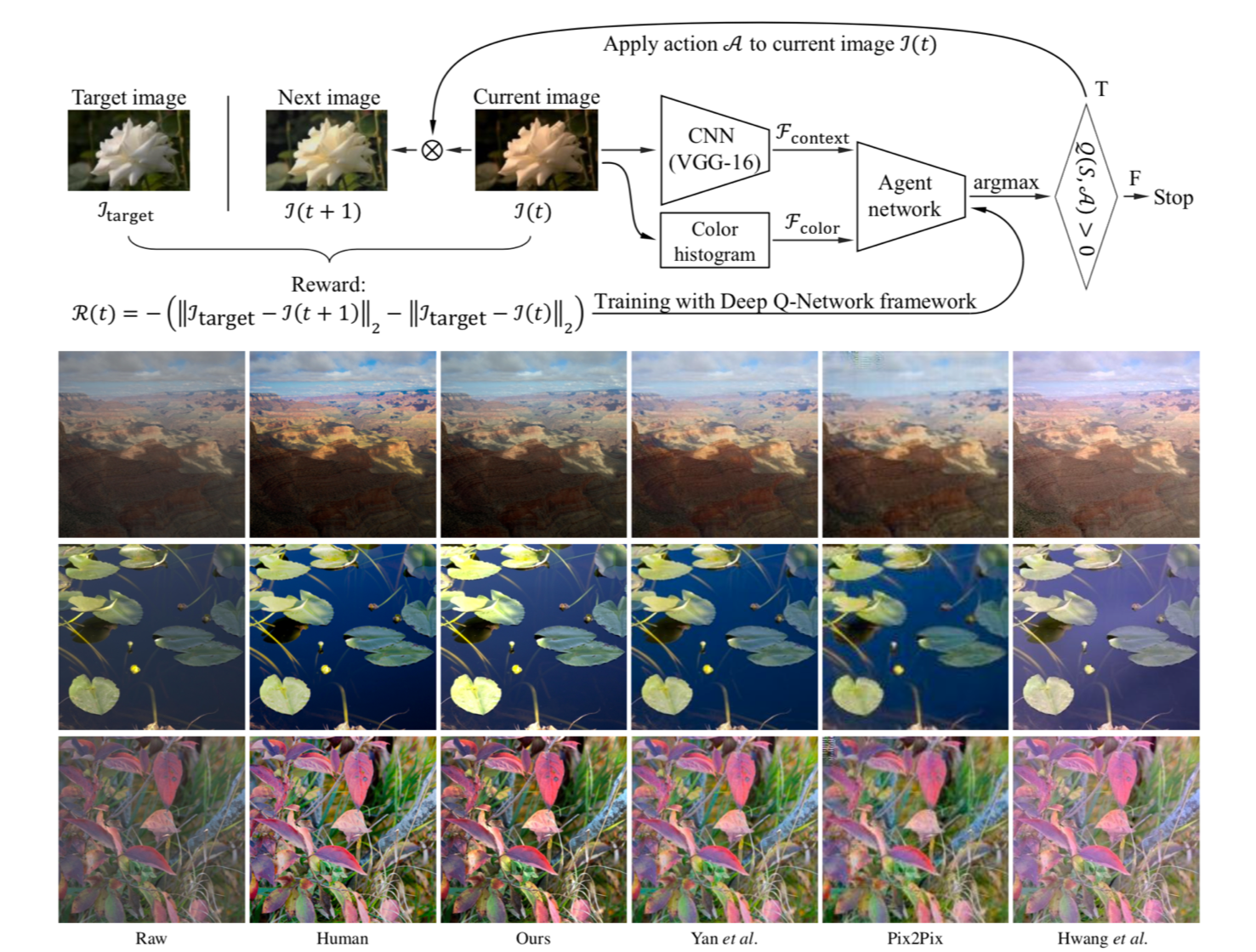
弱教師ありの物体認識の学習を使用して, 教師あり物体認識を学習を行う研究. 弱教師ありの物体認識は物体中の最も特徴的な領域や, 複数の領域を抽出してしまう傾向があるが, それらの結果から教師データとして最もらしい Pseudo ground-truth を生成する方法を提案. PASCAL VOC 2007 と 2012 を用いた評価実験では先行研究よりも優位な結果となった.
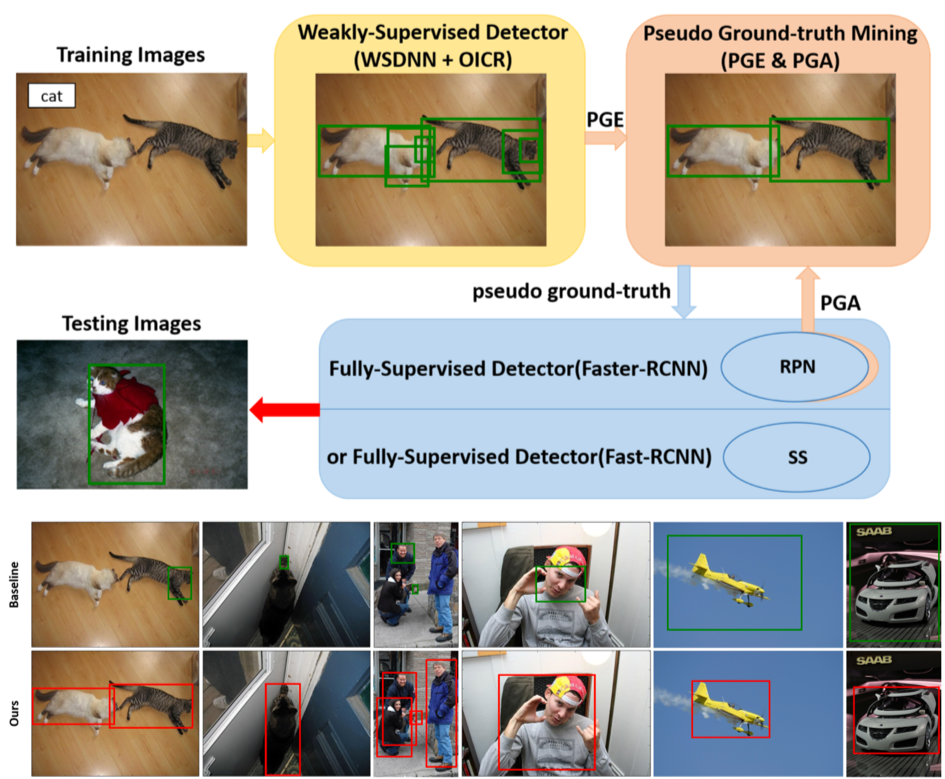
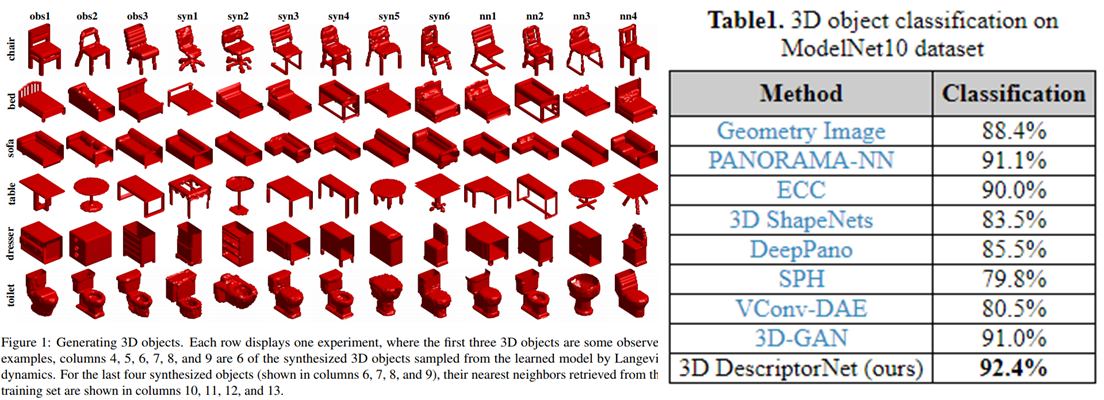
コードで実際のネットワーク構造を確認したい.
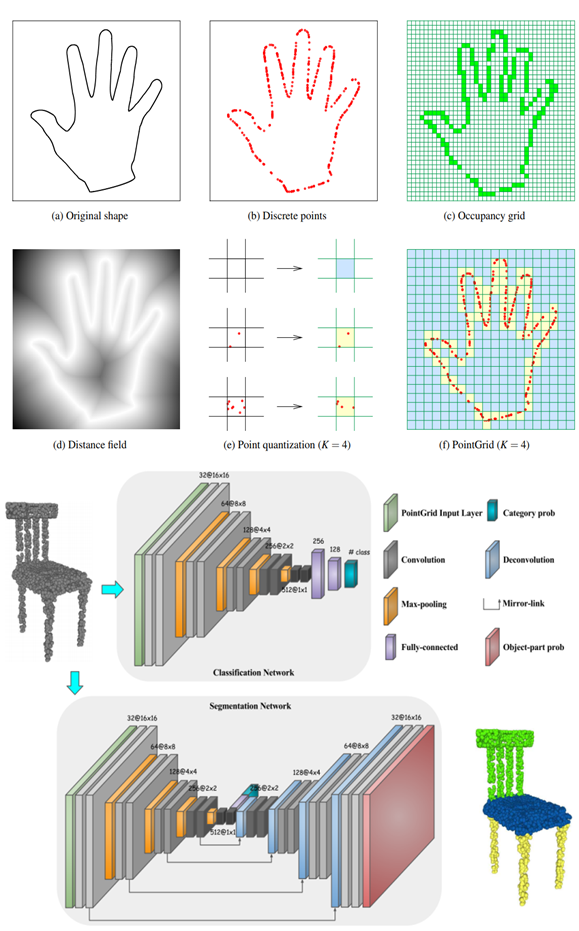
キャリブレーション済みのピンホールカメラにおいてカメラ姿勢推定問題を解く。例としてStructure-from-Motion (SfM)の2D-3Dマッチングを2D-2Dマッチングのように行う問題である。従来は構造ありの2D-3Dマッチングを解く絶対的なカメラ姿勢推定(absolute pose approaches)か、構造なしのテスクチャベースで2D-2Dマッチング(relative pose approaches)を行なっていたが、両者のいいとこ取りをする。本稿では新規にRANSACベースの手法を提案することで繰り返し最適化を行い、同問題の解決に取り組んだ。提案手法は、2D-3D/2D-2Dマッチングを同時にRANSACの要領で繰り返し最適化することができる(図を参照)。
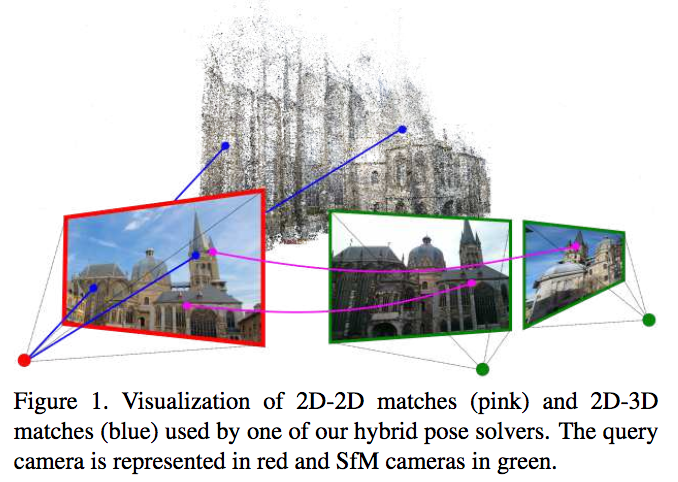
Structure-based/Structure-lessなマッチング(それぞれ2D-3D/2D-2Dに対応)を同時に解決する手法であるHybrid-RANSACを提案して、SfMの問題に対して適用した。両者のマッチングを単一の枠組みで実装しただけでなく、両者のいいとこ取りができる手法として完成させた。CVPRオーラルとして採択された。
16~256のような大きなバッチサイズでも学習することができる、物体検出手法MegDetの提案。ミニバッチ数を上げられることから、GPUを効率的に使用することができ、学習速度を向上。複数のGPUからうまくバッチ正規化を行う、Cross-GPU Batch Normalizationを提案。これにより、33時間の学習を4時間に短縮、かつ高精度にうまいこと学習できる。
2018年現在の著名な物体検出アルゴリズム(Faster R-CNNやMask R-CNNなど)は、全体のフレームワークやロスの設計に力を入れている。本研究では、手薄と思われるバッチサイズに着目し,新しいアプローチで精度向上を図っている。
本稿では非凸問題の一種であるRotation Averagingに対してLagrangian Dualityを用いる。3次元再構成問題において、その画像群が「どこで、どのカメラ角度で、いつ撮影されたか?」に依存して再構成されるモデルが局所最適解に陥るという問題がRotation Averagingである(Rotation averaging)。図のようにカメラの移動軌跡やそのカメラアングルが変化した状態だと3次元再構成の局所解は大きく異なる(3次元再構成が表面のみ捉えていることに依存する)。


Structure-from-Motion (SfM)の重要タスクであるRotation Averagingの問題解決についてLagrangian Dualityを用いた全体最適化(局所最適解をできる限りの場面で脱することができた)を行ったことがもっとも大きな新規性である。シンプル/スケーラブルなアルゴリズムであり、大規模空間に対するSfMにも応用可能である。結果は下の図の通りであり、局所最適解を脱してより詳細な形状復元を行うことに成功した。
脳の平均3D形状である脳アトラスの各ボクセルが患者の脳3次元データのどの位置に対応するか、という画像位置合わせ(image registration)をUnetを用いて正解データ無しの教師無し学習で行う手法を提案。 既存手法は最適化ベースだったが、学習ベースの画像位置合わせを初めて提案。トレーニング、検証で使用されているのは脳のMRIデータだが、 他のデータに対する画像位置合わせにも適用することが可能。
固定解像度で処理する画像認識システムでは、遠近感を持つシーンの画像において物体が任意のスケールを持つことが問題となる。(距離によって物体のスケールが変わる。カメラから遠いほど物体は小さく、近いほど大きい。)これ解決するために、物体のスケール(Depthに反比例)によってPoolingサイズを可変にするdepth-aware pooling moduleを提案。遠くの物体の細部は保持され、近くの物体は大きな受容野を持つことができる。 Depth画像は与えられるか直接RGB画像から推定され、Depth情報と意味的予測を利用するRecurrent Refinement Moduleにより、Semantic Segmentationを反復的に精錬する。
受容野のサイズを変化させるためにDepth情報を利用しこれを自然にCNNに組み込んだこと(geometricな情報を利用する先行研究はあり)。またこのDepth予測をSemantic Segmentationと互いに補い合う用にRecurrent Refinement Moduleを組み込んだこと。NYU-depth-v2の単眼深度推定においてstate-of-the-artな性能とSemantic Segmentationの性能改善を確認。
Recurrent refinement moduleのLoopにより物体の事前情報を捉えることができるが、Loopによる精度変化が小さい。Curriculum Learningと組み合わせるとおもしろそう。ResNetから得られる特徴はすでにスケールを考慮した特徴が抽出できているようにも思え、depth-aware pooling moduleが活かされているかというと疑問。
モバイルや組み込み機器上で低消費電力かつリアルタイムに動作する物体検出のオンラインモデル.Single-Shotベースの物体検出モデルとLSTMを組み合わせたモデルである.また,通常のLSTMよりも計算コストを大幅に削減できるBottleneck-LSTMを提案する.Bottleneck-LSTMは,NチャンネルのBottleneck特徴マップ(Bt)を計算してすべてのゲートの入力をBtに置き換える.これによるゲート内の計算が減る.LSTM自体をDeepな構成にしても標準LSTMより効率的な計算が可能である.
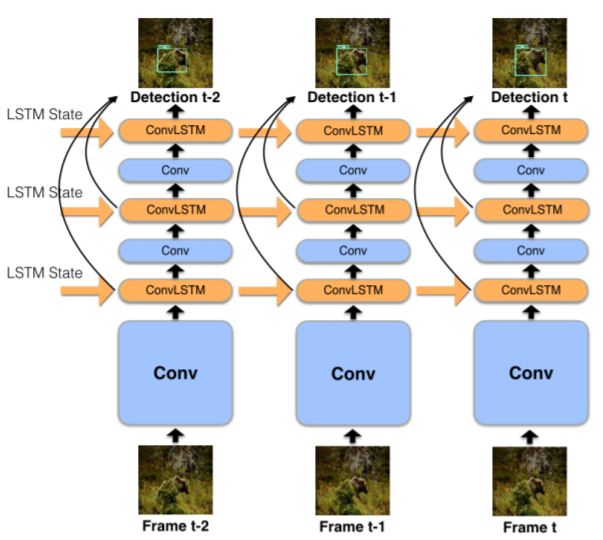
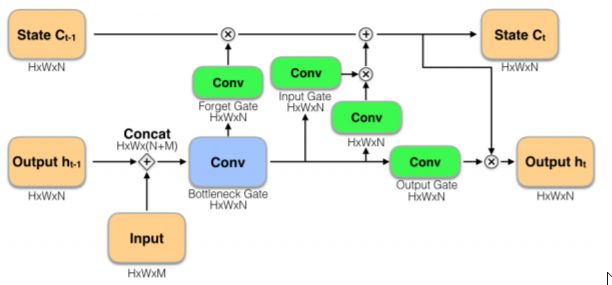
従来のVideo object detectionはフレームごとの検出に依存しているため,時間的情報を利用することができなかったが,本研究では検出器の速度を犠牲にせず時間的な情報を組み込んだ.ImageNet VID データセットでmobilenet-SSDよりも高精度(54.4mAP)に検出可能でありながら,モバイルCPU(Qualcomm Snapdragon 835, Xperia XZ Premiumなどに搭載)で15FPSの速さで検出できる.
Googleでのインターン成果とのこと.リアルタイム検出は時系列情報があれば精度がよくなるが,それを入れることで速度の低下が起きてしまうのでこの2点のトレードオフになっている?
ResNeXtを用いたEncoder-Decoder(エンコーダ-デコーダ)構造、かつシングルパスのセマンティックセグメンテーション手法を提案する。エンコーダとデコーダは折り返したような構造になっており、エンコーダの特徴は図のように対称となる/同じサイズのデコーダ位置に統合される(enc1-dec1が対応)。今回は特にデコーダ側に改善があり、(1)コンテキスト情報を抽出、(2)セマンティック情報を生成、(3)異なる解像度の出力を適宜統合という新規性がある。これを実現するため、DenseNetを参考にしたDense Decoder Shortcut Connectionsを提案し、デコーダにおいてコンテキスト特徴を全て後段に渡すようにした。
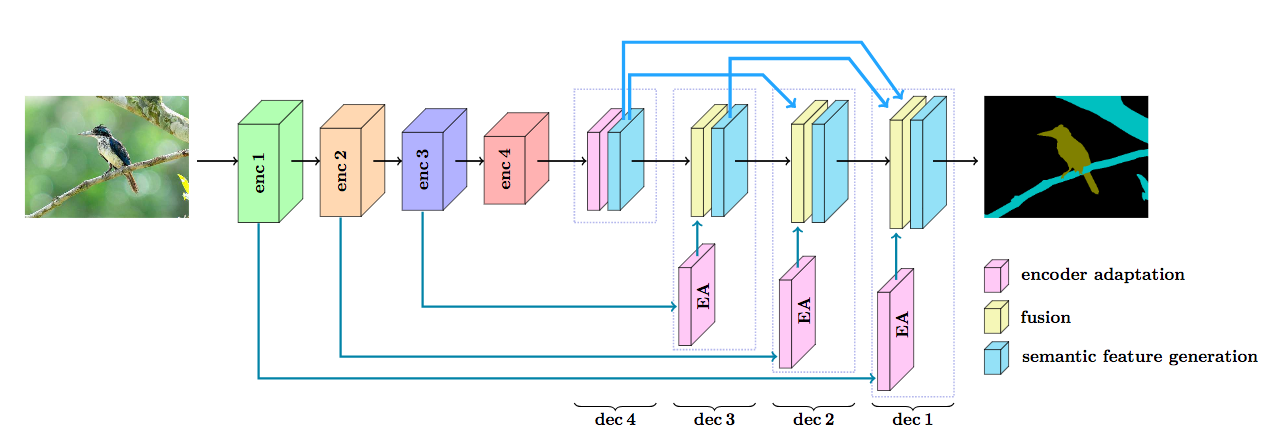
デコーダにおいてDenseNetを参考にしたDense Decoder Shortcut Connectionsを提案、コンテキスト情報を後段に渡して精度を向上させた。ResNeXtの構造適用と合わせて各データセットにてState-of-the-artな精度を達成。NYUD datasetにて48.1(mean IoU)、CamVid datasetにて70.9(mean IoU)となった。PascalVOC2012においても81.2であった(SoTAはPSPNetの82.6)。
セマンティックセグメンテーションの覇権争いが激化。ここら辺まで精度が向上すると確率的にSoTAになったりならなかったりする(回す回数が多いと一回くらい精度が高いモデルが学習される)?逆に、学習しやすい(誰が、どんなパラメータで回しても同じくらいの精度が出る)アーキテクチャというのが提案されてもよいかも。
人物行動認識のための表現に対して、モーションとアピアランスの共起表現(Disentangling Components of Dynamics)を提案する。従来の人物行動認識に限らず動画認識ではRGBを入力とするアピアランス、オプティカルフローを画像に投影したフロー画像が用いられていたが、本論文ではそれらの共起表現を新たに提案した。フロー画像とは異なり、特に「アピアランスの変化」をカラー付きで表現できる。さらに、3Dプーリングを提案し、上記3つのチャンネルからの特徴を蓄積する手法についても考案した。
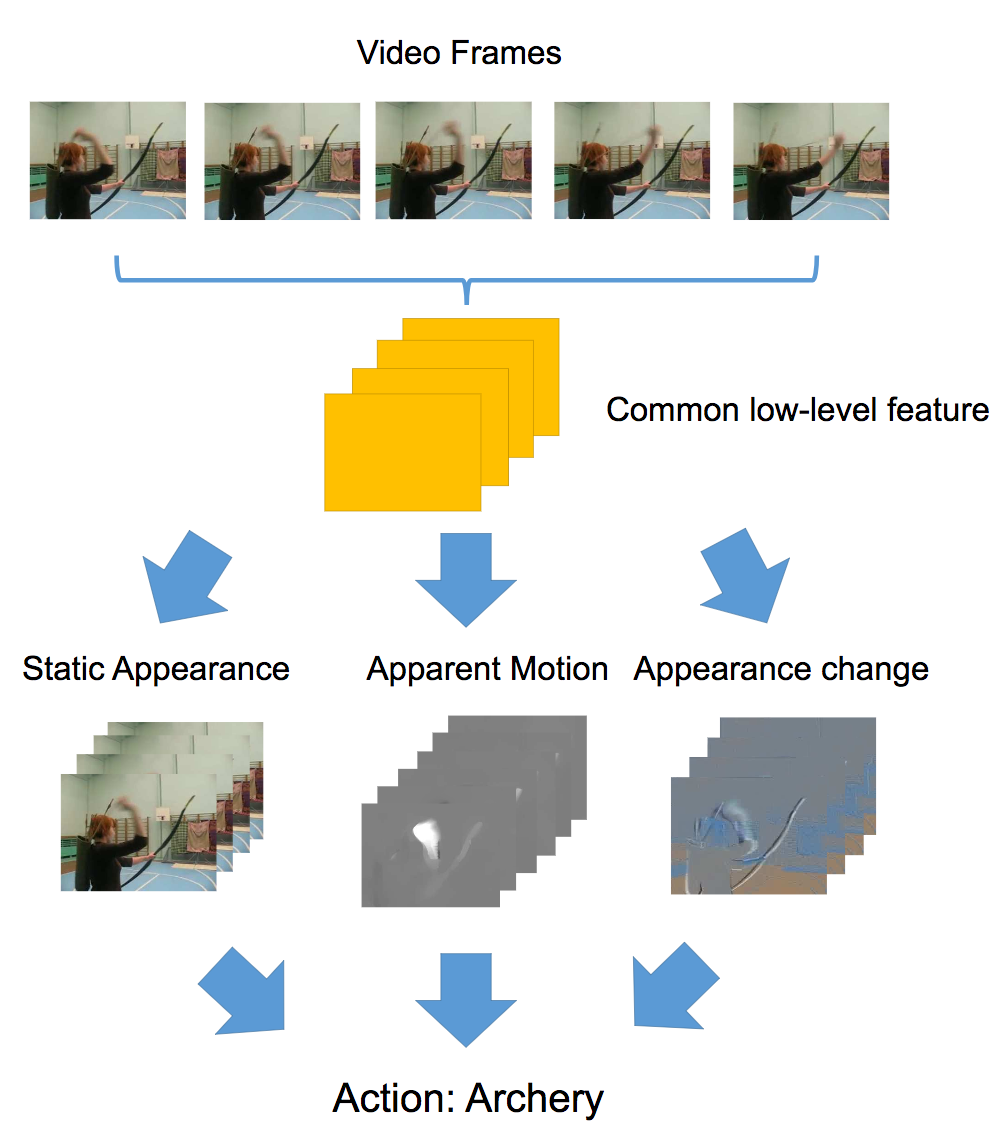
人物行動認識の文脈において、新規の特徴表現方法であるDisentangling Components of Dynamicsを提案した。同手法はフローとは異なり、RGB値の変化を効果的に捉える方法である。さらに、3Dプーリングも提案し、RGB/Flowも合わせた3チャンネルの特徴を適切にプーリングすることができる。フルモデルを用い、さらにKineticsにて事前学習を行った実験では、95.9%@UCF101を達成、従来の行動認識の大部分よりも高い精度を実現。
SSDをベースにした2つのモジュールから構成されるSingle-shotベースの物体検出アルゴリズム「RefineDet」を提案.Anchor Refine Module (ARM) とObject Detection Module (ODM) と呼ばれるモジュールと,2つを繋いで特徴マップを転送するTransfer Connection Block (TCB) からなる.ARMは物体が存在しない領域を示すNegative Anchor(※)の削減や,Anchorの粗い調整を行う.ODMはTCBを通じて特徴マップを受け取って座標の回帰およびクラス推定を行う.
※物体候補領域を示すBounding-boxをAnchorと呼ぶ.SSDでDefault boxと呼ばれているものと同じ.
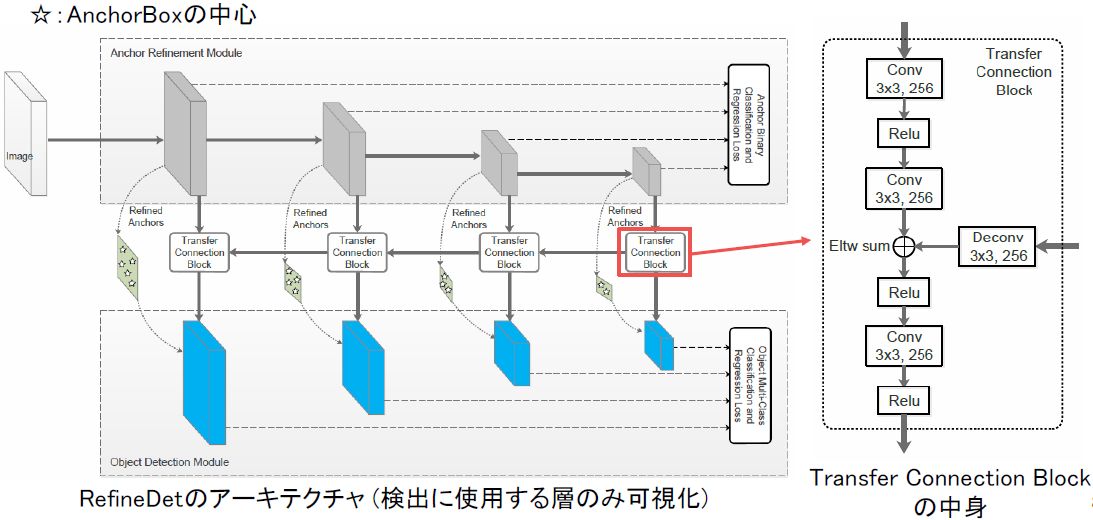
SSDで細かい物体をより精度よく検出するために,一度畳み込んだ特徴マップをDeconvしたりUp samplignしたりする手法がいくつかあるが,この手法はTCBで特徴マップを転送するときに1つ前 (=出力側) の特徴マップをDeconvして足している.Single-shotでありながら2つの役割分割されたモジュールがうまく連携している.推論速度は入力320x320で24.8ms (40.3FPS),512x512で41.5ms (24.1FPS) @TITAN Xと非常に高速である.精度もDSSDより高性能 (VOC2007: 83.8mAP, MSCOCO: 41.8AP)である.
異なるキャラクタに対するモーションのリターゲティングをRNN、Cycle consisteny lossを用いることで教師なしで学習する手法を提案。RNNのencoder-decoderを用いて入力された関節位置、局所座標の原点の4次元モーションから、 各関節のクォータニオンと局所座標の4次元モーションを出力しそれをForwad Kinematicsによってターゲットキャラクターに転写する。 これを教師なしで行うためにCycle consistency loss、GAN lossを導入する。 これによって同じモーションを持った異なるキャラクタのデータが無い場合にも、モーションのリターゲティングを行うことが可能となる。
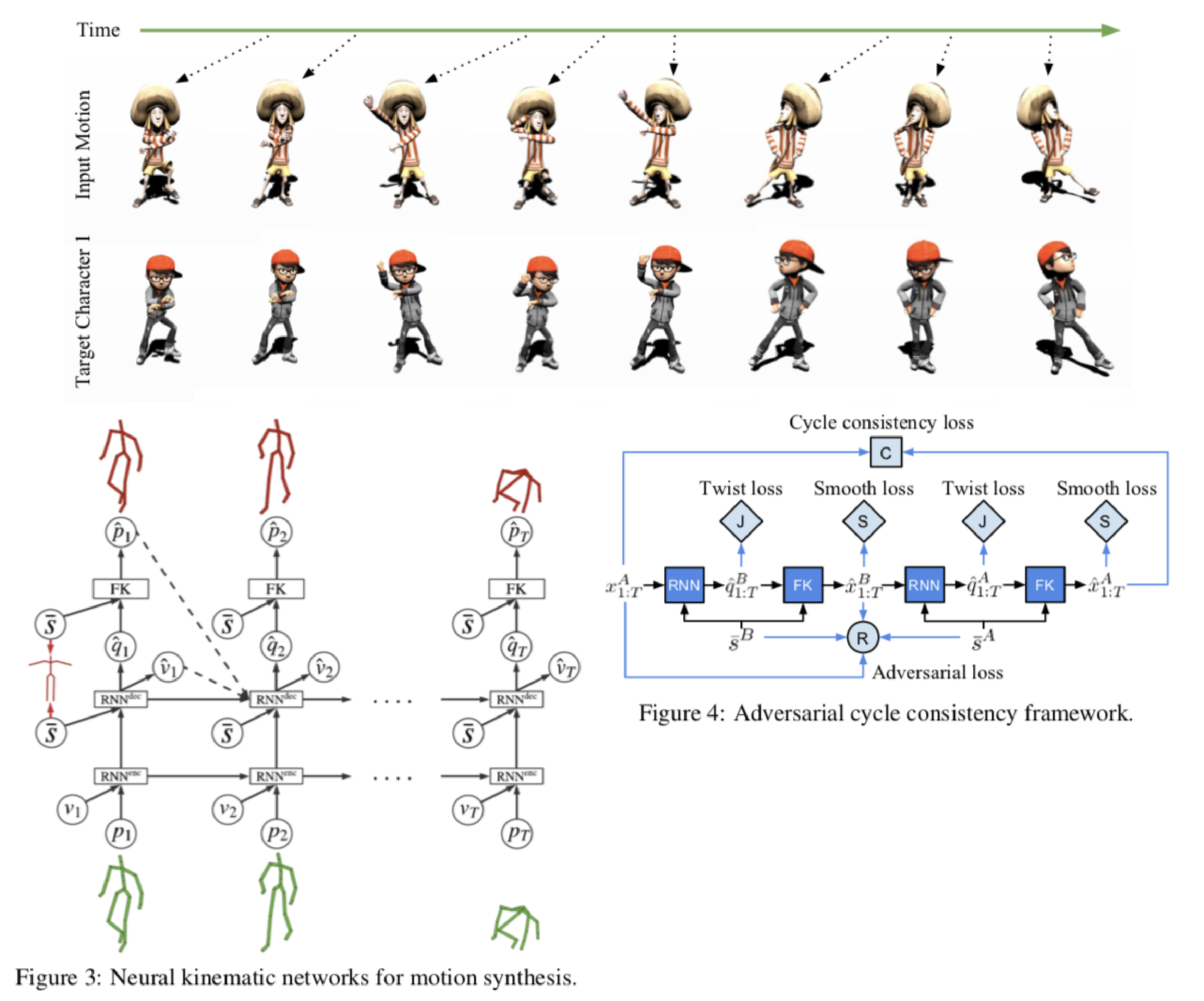
インスタンスレベルのアノテーションを持つソースドメイン(S)とイメージレベルのアノテーションを持つターゲットドメイン(T)を用いてdomain adaptationを行い、Tに対する物体検出を行う手法を提案。Sを用いて物体検出器のプリトレーニングを行い、 Cycle GANによってSをTに変換した画像を用いて物体検出器のfine-tuningを行う。 続いてSとそのイメージレベルのアノテーションを用いて半教師学習を行いSに対する物体検出を行う。 半教師学習を行う際にインスタンスレベルのアノテーションが施されたデータセットが必要なため、 クリップアート、水彩画、漫画のデータセットの構築も行っている。
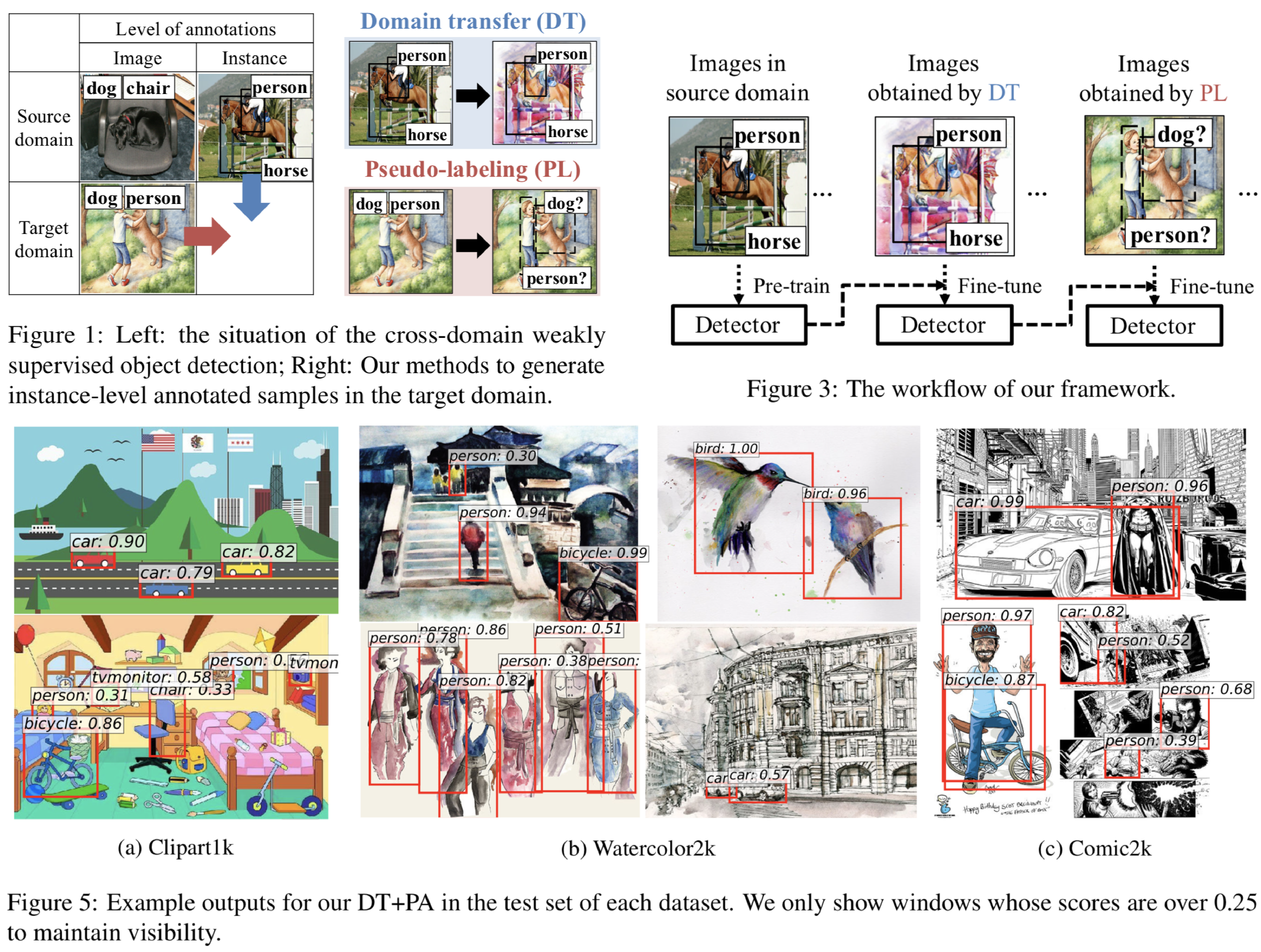
合成画像とそのデプス画像、そして実世界画像を用いてunsupervised domain adaptationを行うことで、実世界画像に対するデプス画像を生成する手法を提案。 実世界画像に対するデプスのアノテーションは困難であり、かつ枚数も多くない。 一方合成画像に対するデプスのアノテーションは完璧だが、 実世界画像に対する推定を行うときにドメインシフトが起きてしまう。 提案手法ではUnetによって合成画像からデプスを推定し、Cycle GANによって実世界画像を合成画像に変換することでデプスを推定する手法を提案。 GPUを用いることで44FPSで実行することが可能。
![]()
ソースドメイン(S)の各カテゴリの重心ベクトルと、S・ターゲットドメイン(T)から得られたadversarial featuresの行列積を用いることでdomain adaptation(DA)を行う手法を提案。 従来のDAではSとTのそれぞれから得られる特徴量をGANによってdomai-confusionを行い、 Sで学習したラベル識別器をTに適用するという手法だった。提案手法ではadversarial-confusionに加えて、 Sの各カテゴリにおける重心ベクトルとgeneratorから得られる特徴量の類似度を高くするように学習しDAを行う手法を提案。
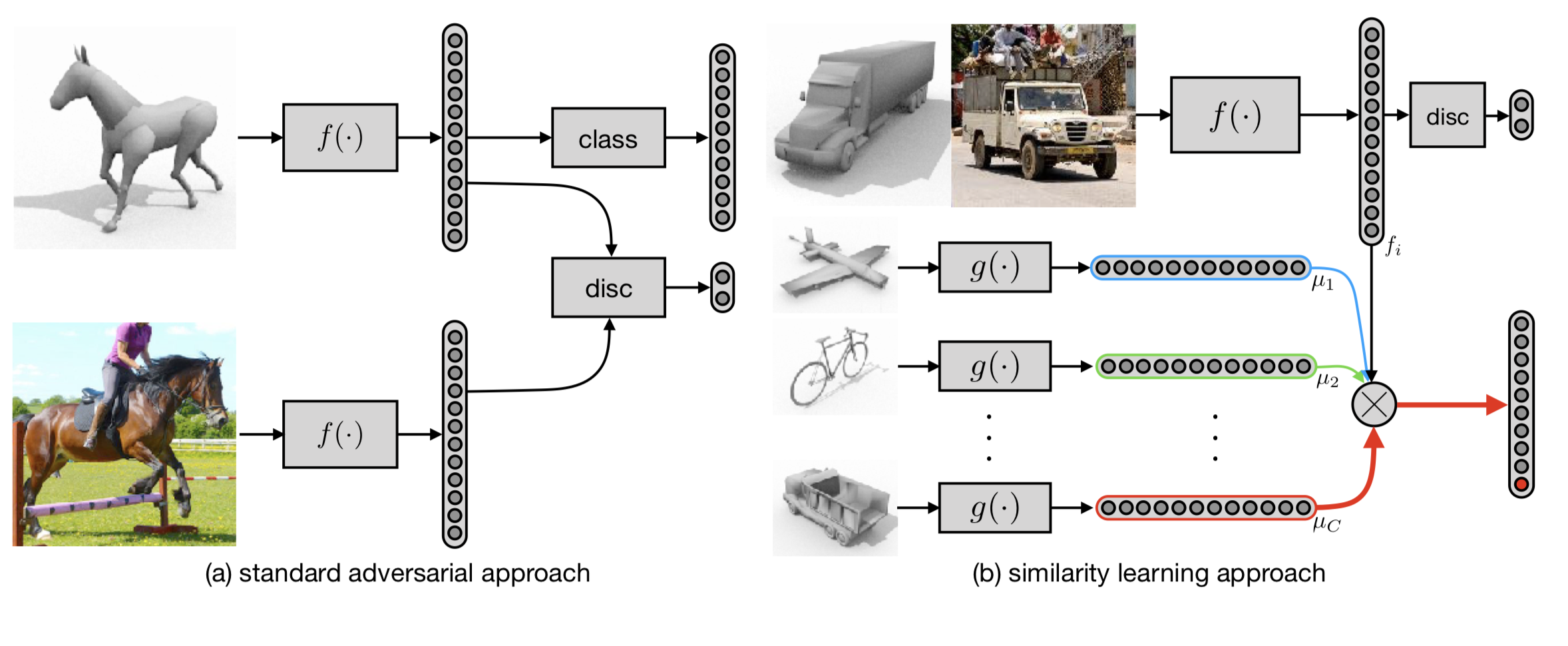
人物認証(person re-ID)の精度が落ちないようにソースドメインの人物画像をターゲットドメインの画像に変換するSimilarity Preserving GAN(SPGAN)を提案。ドメイン間の変換をCycleGANで行う。 またそれぞれのperson re-IDのデータセットには基本的に同じ人物は写っていないということを利用して、 ソースドメインとターゲットドメインで異なるデータセットを使用し、 ターゲットドメインへと変換された画像はIDが保たれ、かつターゲットドメインのどの人物のIDとも一致しないように学習を行った。
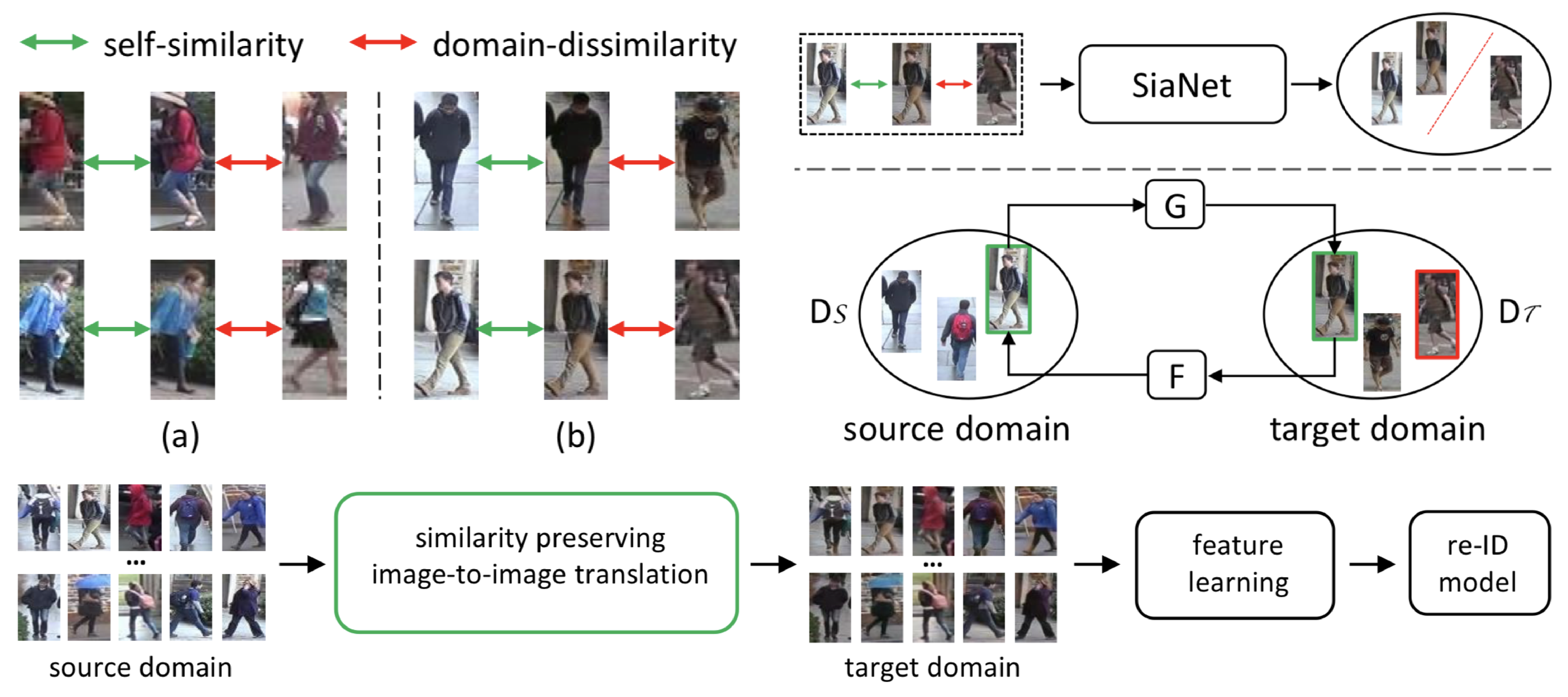
domain adaptaion(DA)に対して、ソースデータは潜在的に複数のドメインで構成されていると仮定し、ソースサンプルがどのドメインに所属しているかを精度よく識別するためにMulti-domain DA layer(mDA-layer)を導入することで、 ターゲットのラベルの識別精度を向上させる手法を提案。 実験ではmulti-soure domain adaptationを行うことでその有効性を検証している。 ソースデータないのドメインを識別するCNNの特徴量を用いることで、ターゲットドメインのラベル識別の精度が向上している。
鳥の種族などより細かいラベルを推定するdomain-specific fine-grained visual categorization(FGVC) taskにおいて、効果的なトレーニングデータセットの構築方法を提案。 事前実験からターゲットドメインの画像の見た目に近い画像を含むソースドメインでトレーニングするほど、 識別精度が高くなるということを発見している。 ターゲットドメインに含まれる画像の見た目に近い画像を多く持つソースドメインのクラスをいくつか選択することで トレーニングデータセットを構築する。画像の見た目はEarth Mover’s Distanceで測定され、 7つのfine-grainedデータセットにおいて提案手法が効果的であることを示した。
![]()
ソースドメインを学習したネットワークのパラメタを残差ブロックで変換することでターゲットドメインへdomain adaptaionを行う手法を提案。 既存手法ではドメインに普遍な特徴量を学習していたためにネットワークのパラメタが多すぎてしまう。 提案手法は学習時には残差ブロックとソースドメインを学習するネットワークのファインチューニングを行い、 ソースドメインに対するラベルの識別と2つのドメインに対してadversarial domain adaptationを行う。
![]()
ターゲットドメインがソースドメインが所持するクラスの一部しか持たずかつラベルがない場合であるpartial domain adaptationをadversarial netベースで行う手法を提案。 adversarila netの手前いにドメインを識別するclassifierを用意し、 このclassifierが精度良く判別可能なソースサンプルはターゲットドメインには含まれていないクラスに所属している可能性が高いので重みを小さくし、 逆にconfidenceが低いソースサンプルはターゲットにも存在するクラスに所属している可能性が高いので重みを大きくする。 この重みとソースサンプルを掛け合わせたものとターゲットサンプルをadversarial netで学習させる。
Adversarial Autoencoder(AAE)に対してMaximum Mean Discrepancy(MMD)を導入することでトレーニングデータを過学習することなくdomain generalizationを行う手法を提案。 domain generalizationとは、複数ドメインのラベル付きデータセットを学習し、 テスト時にはデータセットに含まれていないドメインのデータセットにおける識別や生成タスクを行うことを指す。 複数のソースドメインで不変な特徴量を取得するmulti-task learningに対して、提案手法ではMMDベースでドメイン間の差分をとることと、 AAEによって特徴量空間に対して事前分布が押し込むことでソースドメインに対する過学習が防ぐ。
特徴量空間におけるデータオーギュメンテーションとソースドメインとターゲットドメインに不変な特徴量を取得することでunsupervised data adaptationを行う手法を提案。 右図にあるようにstep1で、ソースドメインとノイズをデコードして生成されたベクトルをGANにかけ、 特徴量空間においてソースドメインに対するオーギュメンテーションを行う。 続いてstep2において、ソースドメインとターゲットドメインを同一のエンコーダーに入力することでドメインに不変な特徴量を取得する。 ベースラインであるAdversarial discriminative domain adaptationではドメインごとにエンコーダーを使用していたが、提案手法ではエンコーダーは一つ。
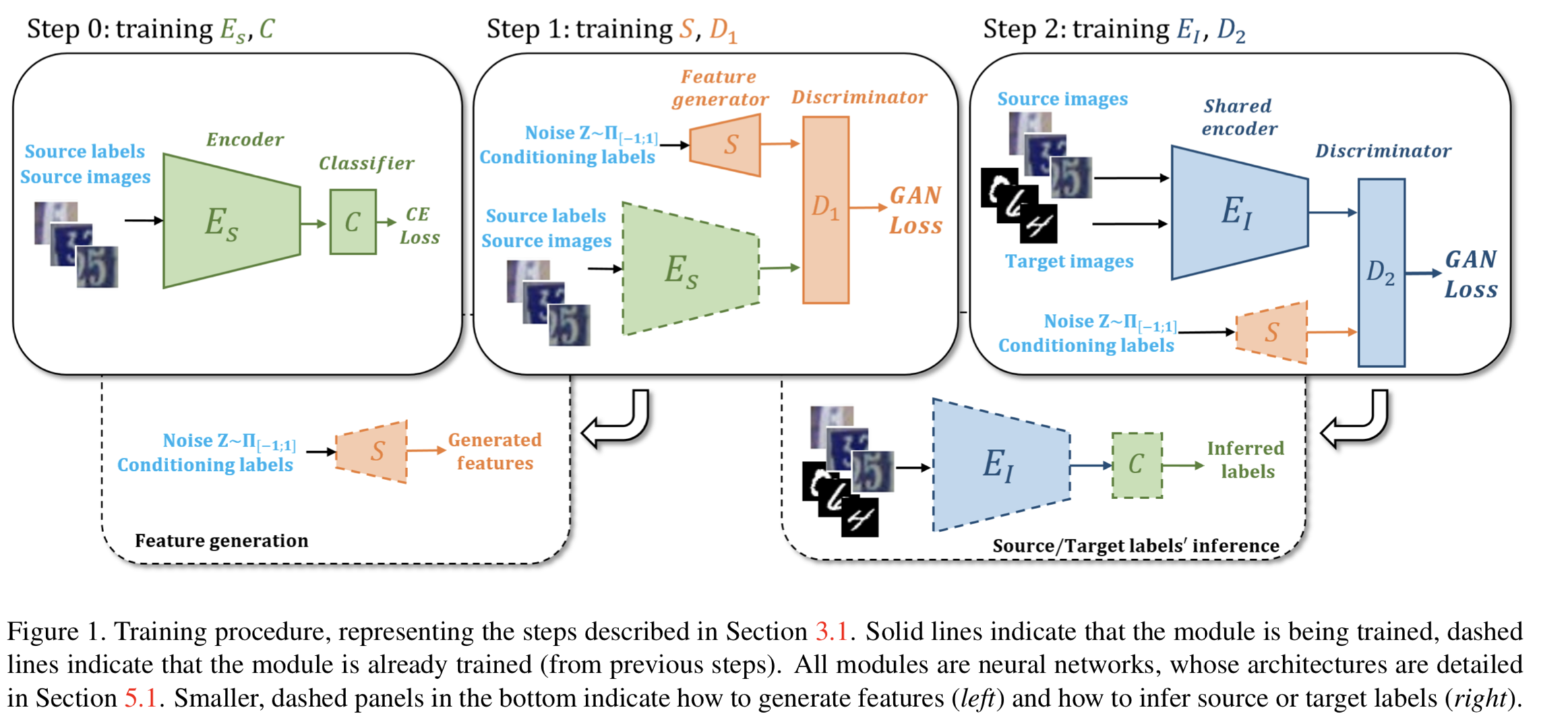
動画像セグメンテーションの問題に対してネットワーク選択(Decision Network)を行い適応的にCNNモデルを処理するDynamic Video Segmentation Network (DVSNet)を提案する。同手法では性質の異なるふたつのネットワーク(深くて精度が高いが低速/浅くて精度は低いが高速)を組み合わせて交通シーンにおけるシーン解析にて高速な処理を実現する。
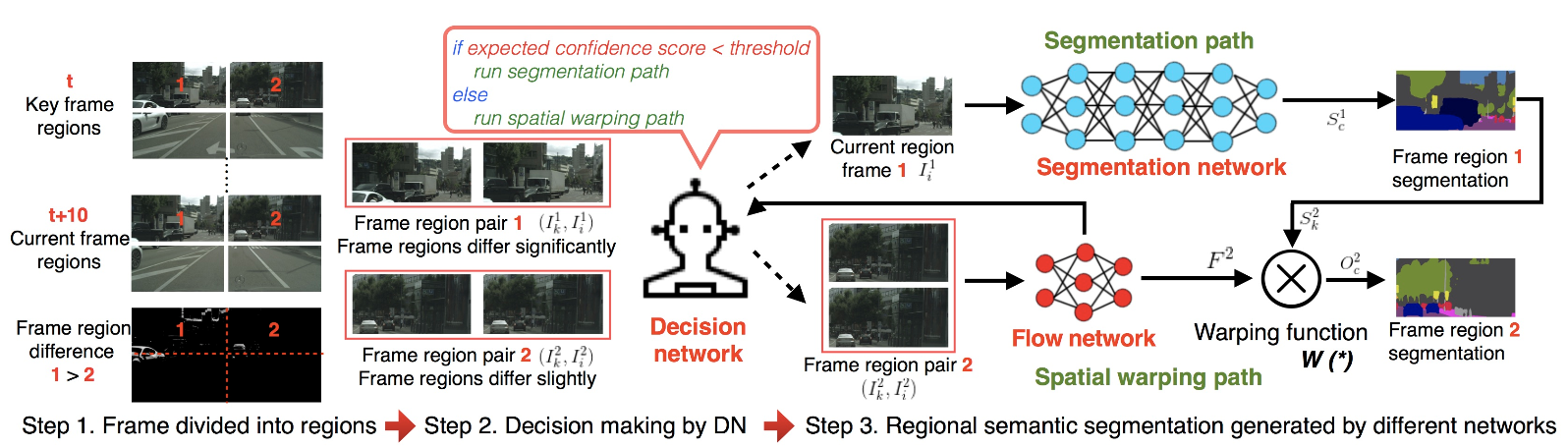
DVSNetは低速なもので70.1%/20fps、高速なものだと65.2%/34.4fps(いずれもCityScapes datasetにて処理した結果)を達成する。両者を、トレードオフを考慮してあらゆる場面に適応することができるという意味で新規性がある。
画像とテキストなどの異なるメディアタイプ間で検索する、クロスメディア検索手法のcross-media knowledge transfer(DCKT)の提案。大規模なクロスメディアデータセットの知識を、小規模なデータセットのモデルに転移学習する。メディアレベルと相関性レベルでのドメインの違いを最小化するために、2レベルでドメイン変換することで精度向上。また、ドメインの違いを徐々に減らすようにトレーニングサンプルを選択することで、モデルがより頑健になる。
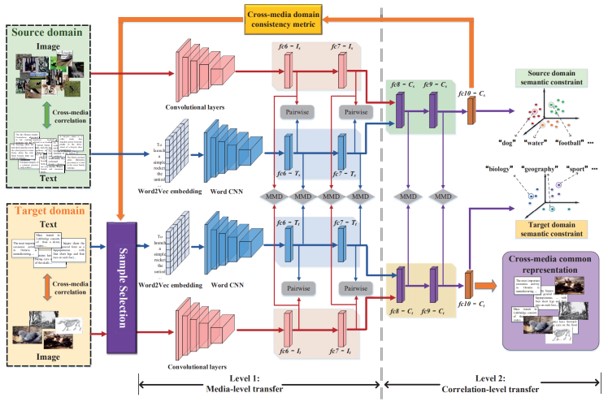
マルチメディア分野における検索。既存の手法では、ラベル付きデータを学習する方法が多いが、大規模なデータの収集とラベル付けは手間取るため問題とされる。そこで、既存のデータを転移して解決する。
視覚情報とテキストの情報が抽象的に統合された図であるダイアグラムを解析するためのunified diagram parsing network(UDPnet)の提案。入力は様々なイラストやテキスト、レイアウトを持つ図のみ。物体検出器によって、図内のグラフ構造を推論し、新手法であるdynamic graph generation network(DGGN)によってグラフを生成。生成されたグラフからテキストで関係性を出力する。
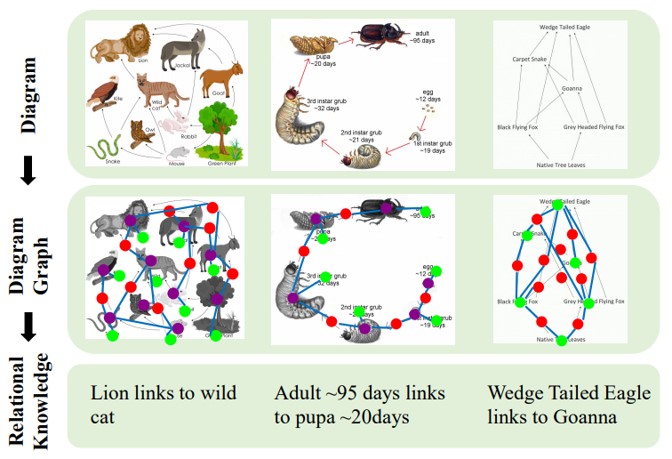
ダイアグラムのような図には、豊富な知識が含まれているが、固有の特性やレイアウトの問題から、コンピュータに自動的に理解させる方法はあまり提案されていない。本手法では、物体検出器やRNNを統合し、ダイアグラムから知識をテキストとして生成する。
物体インスタンス特有の特徴(同じ物体領域に属しているか?)を捉えることでビデオに対する教師なしの物体セグメンテーションを実施する。ここでは静止画で捉えた特徴を、ビデオに表れる物体候補/オプティカルフローと組み合わせて物体のインスタンスセグメンテーションを実施。本論文ではさらに、ビデオに対するfine-tuningなしに高精度なセグメンテーション手法を構築したと主張している。
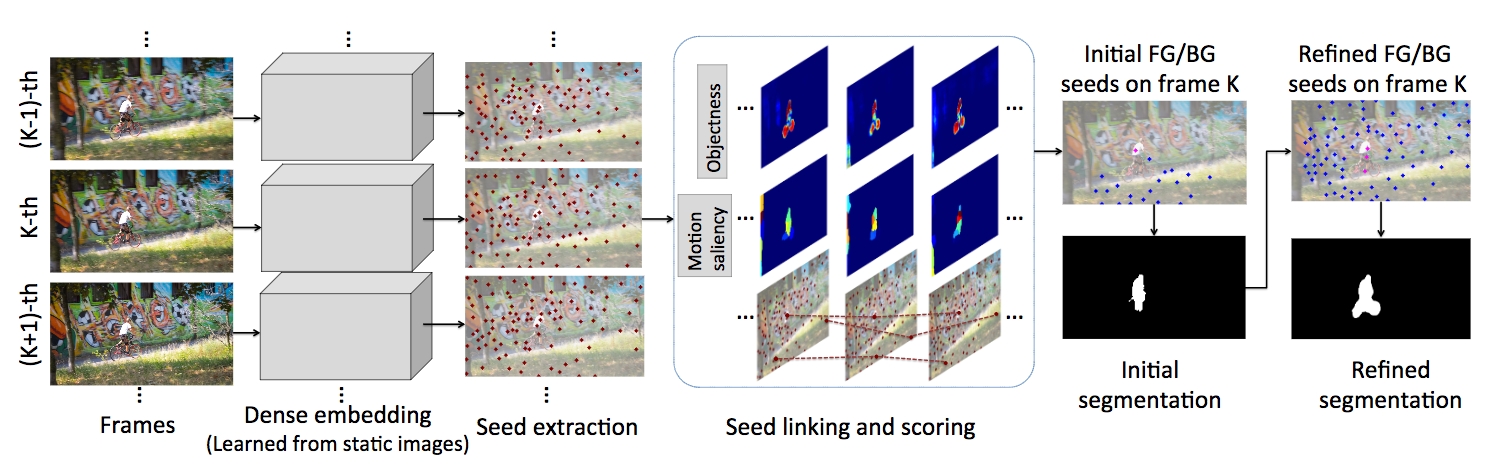
静止画の学習パラメータを動画に適用していく、その際に物体候補/オプティカルフローと統合していくことで動画的な表現を教師なしで獲得していく。DAVIS datasetを用いた評価で78.5%、FBMS datasetにて71.9%(いずれもmean Intersection-over-Union (mIoU)の評価にて)を達成し、それぞれのデータセットでState-of-the-art。
"Without finetuning"というのもアピールになるということを勉強した(ただしそれでstate-of-the-artである必要がある?)。
ステレオビデオ(Stereo Video)に対するリターゲティング(Retargeting)を扱う。ステレオ(かつビデオ)に対するリターゲティングは従来のリターゲティングと比較すると、動画中の顕著性が高い物体の把握やダイナミクスを含むためまだ新しくチャレンジングな課題である。ここに対して、Depth-aware Fidelity Constraint(距離画像から推定される信頼性のようなもの)を適用することで物体の顕著性を把握しつつ3次元空間を再構成することができる(リターゲティングと3次元再構成の同時推定問題)。最適化にはTotalCost関数を適用して物体の顕著性を把握しつつ形状、時間情報、距離画像のディストーションを推定。
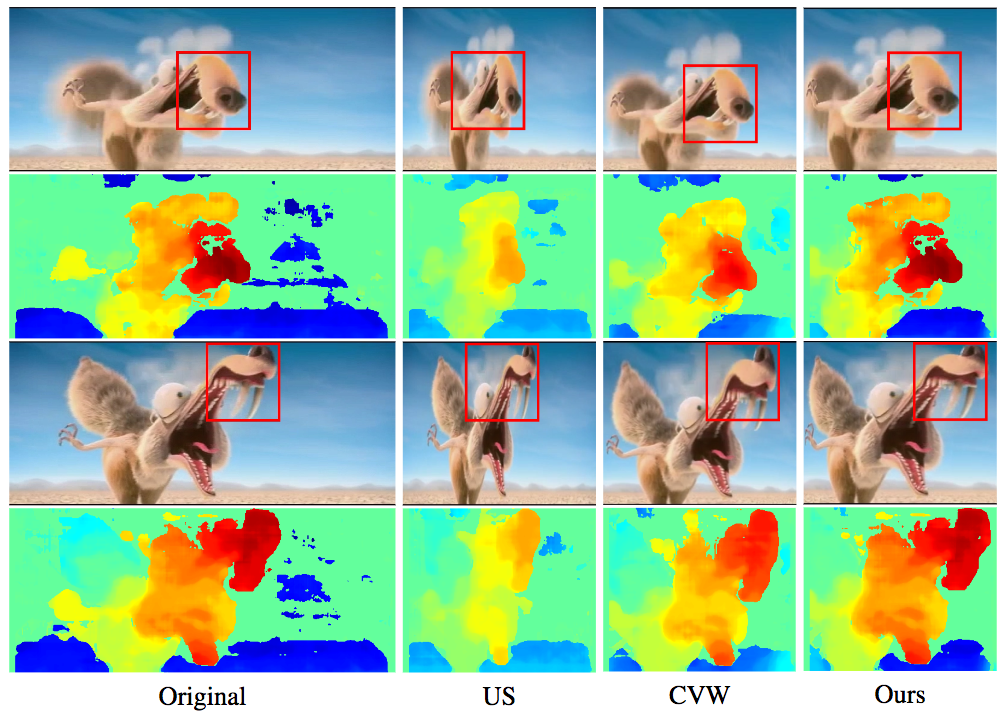
ステレオビデオの入力から、顕著性の把握、形状推定、時間情報、距離画像のディストーションを同時推定し、従来法であるCVWよりも綺麗なリターゲティング画像を生成することに成功した。
屋内および屋外シーンにおける3D物体検出手法のfrustum PointNetsの提案。まず、RGBデータからCNNで2Dの物体候補領域を推定する。次に、点群の深度情報を用いて、各物体領域の視錐台(viewing frustum)を推定する。最後に、frustum PointNetsによって3Dバウンディングボックスを推定。
従来の手法では、画像や3Dボクセルに処理を加えて、3Dデータの自然なパターンや不変性を曖昧にしている。本手法では、RGB-Dスキャンによって生の点群データを直接操作する。
高解像度画像に出現する様々なサイズの物体を、精度の維持と処理コストの低減を実現しながら検出するフレームワークの提案。最初はダウンサンプリングされた粗い画像から、次に高解像度の細かい画像から検出する。強化学習を用いた2つのネットワークで構成。R-net:低解像度の画像を入力し、その検出結果を用いて高解像度領域を解析する。これにより、どの順番にズームインすべき判断できる。Q-net:ズームの履歴を使用し、拡大領域を順次選択。
しっかり検出する範囲を絞ることで処理量を低減、効率化を図ることができる。基本的な検出の構造はいじっていない。処理する画素数を約70%、処理時間を50%以上短縮し、なおかつ高い検出性能を維持できる。
セグメンテーションを実行する際に任意のアノテーション済み物体を事前情報(Spatial Prior)として高精度化を図るための技術を提供する。本論文では、最初の一フレームに対してセグメンテーションを行うだけで、動画中の物体に対してセグメンテーションを行うモデルを提案する。アノテーションから抽出した事前情報はニューラルネットの中間層にて情報を挿入して抽象化を行う。図は提案のフレームワークを示しており、VisualModulator(初期フレームのアノテーションから視覚的なガイドを行う)、SegmentationNet(VisualModulator/SpatialModulatorの補助を受けつつ、RGB画像の入力からセグメンテーションを実行)、SpatialModulator(空間的にどこらへんに対象物体があるかをサポート)の3つのコンポーネントから構成される。
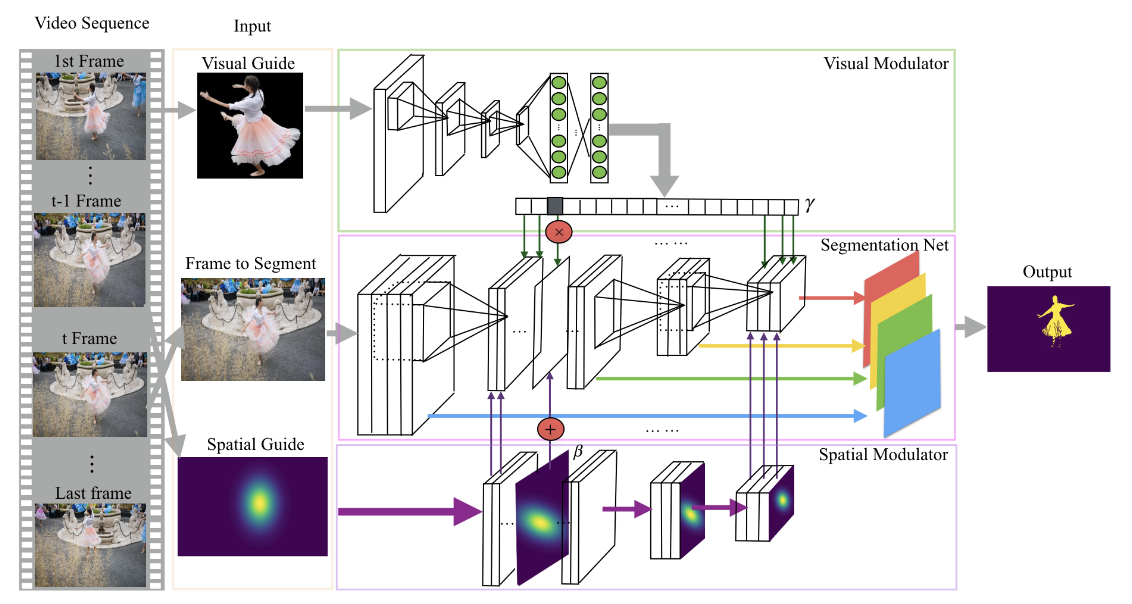
最初のフレームのアノテーションのみから動画セグメンテーションを実行するという問題を提供した、さらに視覚的な特徴量/位置的な事前知識をセグメンテーションのネットワークに導入し、動画セグメンテーションを高精度化した点が評価された。動画セグメンテーションタスクであるDAVIS2016にて74.0、YoutubeOjbsにて69.0(処理速度は0.14second/image)であった。State-of-the-artには劣る(それぞれ79.8, 74.1)が、処理速度では優っている(提案 0.14 vs. 従来 10.0)。
監視カメラの文脈において異常検出を実行する研究である。ここで、異常検出においてビデオに対して時間のアノテーションを付与するのは非常にコストのかかる作業であるが、ここに対して弱教師付き学習の一種であるMultiple Instance Learning (MIL)を適用して正常/異常ラベルが付いたビデオから異常検出を行うモデルDeep Anomaly Ranking Modelを提案する。さらに、13種類の異常シーン(e.g. road accident, robbery)を収集したデータセットを提供することで同問題の解決を実践した。
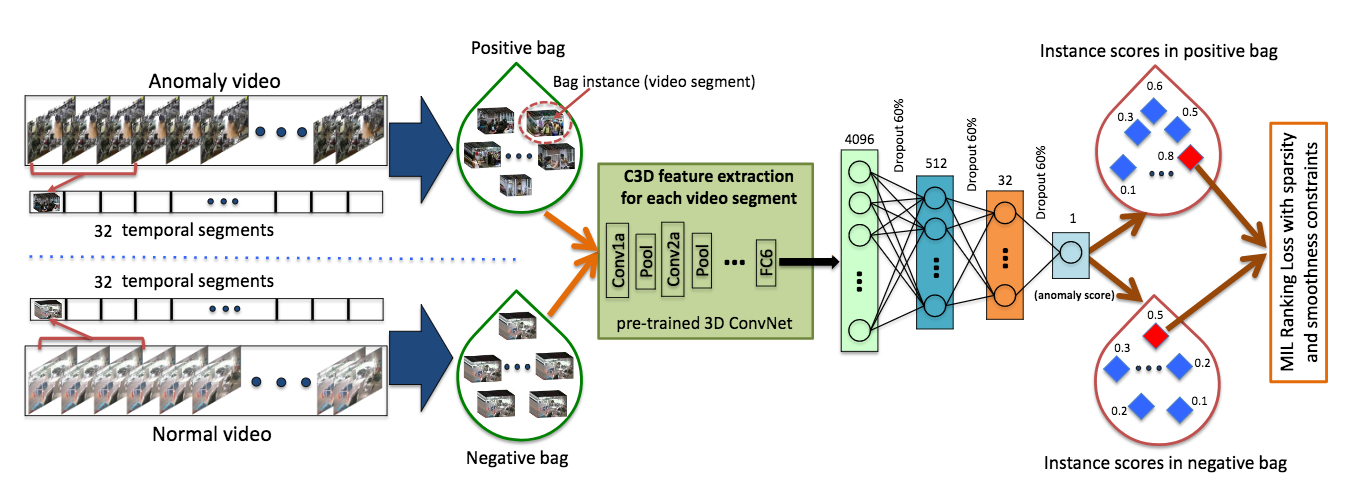
弱教師付き学習であるMILをベースとして異常検出を行なった、おそらく初めての例であり、その精度は従来法による精度を上回りState-of-the-artとなった(AUCにて75.41を達成)。また、1900の動画に対して13種類の異常を収集したデータセットを構築し、公開した。同データセットは合計で128時間にも及ぶ。
Weakly-supervisedなセマンティックセグメンテーション手法があって,その方針はインタラクティブに部分的に正解(シードとか)を与えるというものである.そこで,よく用いられるロス関数(クロスエントロピー等)で評価しようとすると,教示の塗りミスが致命的になったりする.そもそも設計的にエラーが考慮されていないからである.
本論文では,非Deepな手法で行われていた評価指標に基づく新たなロス関数Normalized Cut Lossを提案.
従来法と違うところは,提案するロス関数におけるクロスエントロピーの部分は,ラベルが既知のシードの部分での評価だけやっているという点.Normalized Cutはゆるく全ピクセルに対する一貫性の評価を行う.

Fully-supervisedな手法と同レベルの性能を実現できた.
従来法の知見を活かした橋渡し的手法.
携帯含む最近のカメラは連写機能が付いているので,手ブレのあるようなハンドヘルドカメラの連写で撮ったノイズ入り画像をデノイズしようという話.連続撮影における手ブレに頑健なデノイズCNNを提案する.
写実的ノイズ定式化に基づく,インターネットから拾ってきた加工済み画像からカメラで撮ったような写実的画像を生成する合成データ生成手法で学習データを作成.学習中に空間的に変化するカーネルを使い,位置調整とデノイズを実現. 不慮の局所解落ち回避のための,焼きなましロス関数をガイドとした最適化.
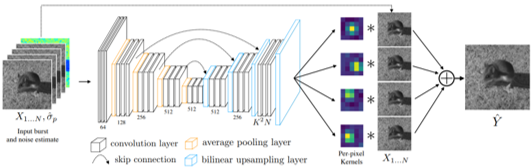
流行に乗った手法(合成データによる学習,適応的パラメータ調整)を使って実現.問題設定も地に足がついている感じがする.
物体のBounding-box detection, Semantic segmentationとDirection predictionを同時に行うモデル「MaskLab」を提案する.Faster R-CNN・ResNet-101をベースに,Bounding-box内の前景と背景をわけることでSegmentationを行う.Mask R-CNNと違い,Segmentationを行うときは単純に前景背景分割をするだけでなくクラス分類も行い,また,各ピクセルのDirectionを予測して同じクラスの重なっている物体のInstance segmentationも可能である.また,検出されたBox内でさらに切り出しを行い,小さな物体の検出をしやすくする仕組みも入れている.
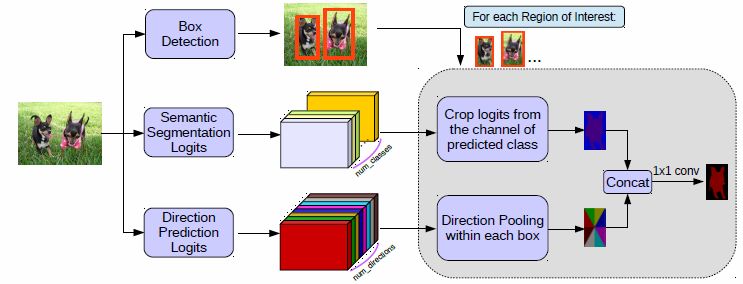
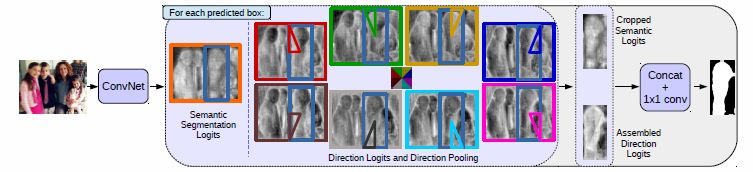
Object detectionとSemantic segmentationを同時にEnd-to-endで解くモデルの提案.それだけでなく,Semantic segmentationではDirectionを考慮して高精度な認識が可能である.MSCOCOで性能評価を行い,FCIS+++(mAP,Seg:33.6),Mask R-CNN(Seg:35.7,Det:38.2)よりも高い性能(学習時にScale augmentationを行いSeg:38.1,Det:43.0)を達成した.Res-NeXtを用いたMask R-CNN(Seg:37.1,Det:39.8)よりも高性能である.
最近,Detection + Segmentationがいくつか出てきているので今後に注目.検出速度に関する記述は見当たらなかったが,Faster R-CNNベースなのでそれ相応の速度だと思われる.ワンショット系の検出器に適応してこの精度を保ちつつ高速な検出ができればウケそう?
RNNの改良であり、畳み込み層や全結合層の役割を前処理として構造に入れ込むPreRNNを提案した。従来のRNNとPreRNNの違いは図に示すとおりである(従来型TraditionalなRNNは構造内にfc/conv+avepoolを要するが、PreRNNではそれらを内包している)。このPreRNNを用いて、より有効だと思われるタスクーSequential Face Alighnment, Dynamic Hand Gesture Recognition, Action Recognitionにて適用した。
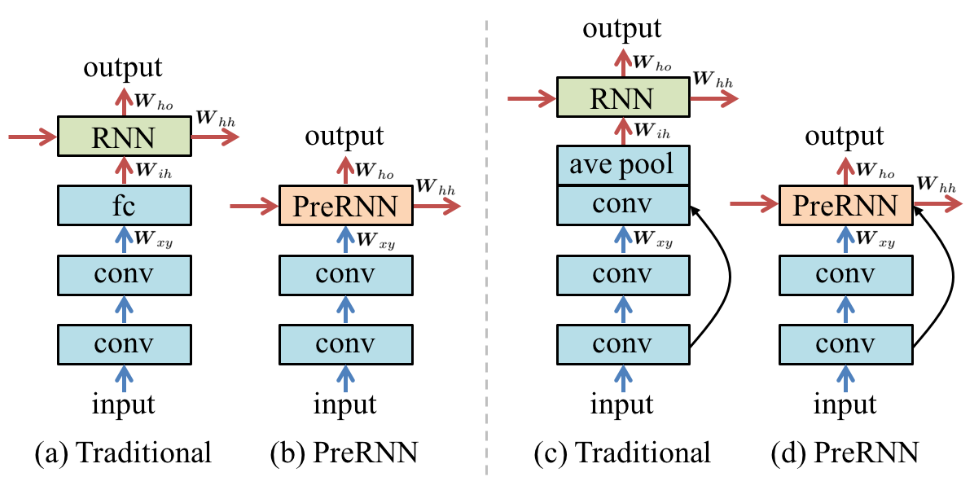
従来型のRNNを改善して、fc-layer/conv+avepool-layerをその構造の中に取り込んだPreRNNを提案し、複数タスク(顔アライメント推定、ジェスチャ認識、人物行動認識)にて従来法よりも高い精度を達成した。
複数人いる人物が同時に同領域に注意を向けることをCo-attention/Shared-attentionといい、本論文では三人称視点の入力からこの推定に取り組む。ここに対してConvLSTM(Convolutional Long-Short Term Memory)を用いたモデルを適用、さらにはVideoCoAttと呼ばれるTV番組をメインとしたビデオからデータ収集を行なった。モデルは視線推定(YOLOv2による顔検出も含む)、領域推定(Region Proposal Map)、空間推定(Convolution)と時系列最適化(LSTM)から構成される。データは380ビデオ/492,000フレームから構成される。
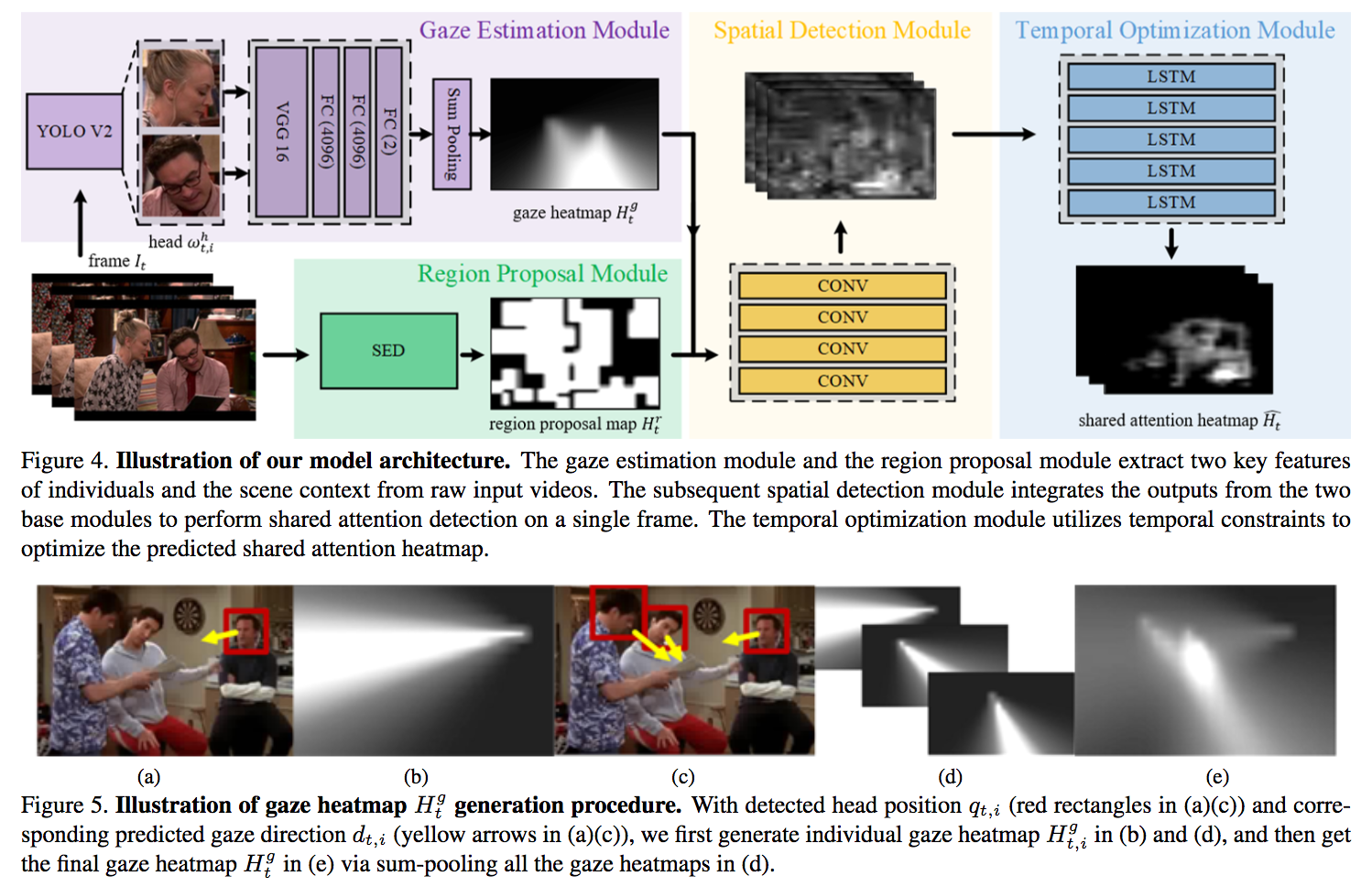
新しい問題である、三人称視点からの共注視を設定し、データとモデルを公開したことが採択された理由である。また、実験により従来法を抑えて、提案法が71.4%の精度かつ誤差がもっとも小さい手法であることを明らかにした。
Aperture Supervision(カメラのフォーカスによる教示)により単眼画像からデプスマップを推定する研究である。これを推定するために、Focus/Defocusを処理して、領域ごとの反応を確認することでデプスの教示に相当する。CNNベースの距離画像推定では、確率的距離マップ、Shallow Depth-of-field(各距離における重み付けされたマップ)を適用する。図は本論文における単眼カメラによる距離画像推定のパイプラインである。
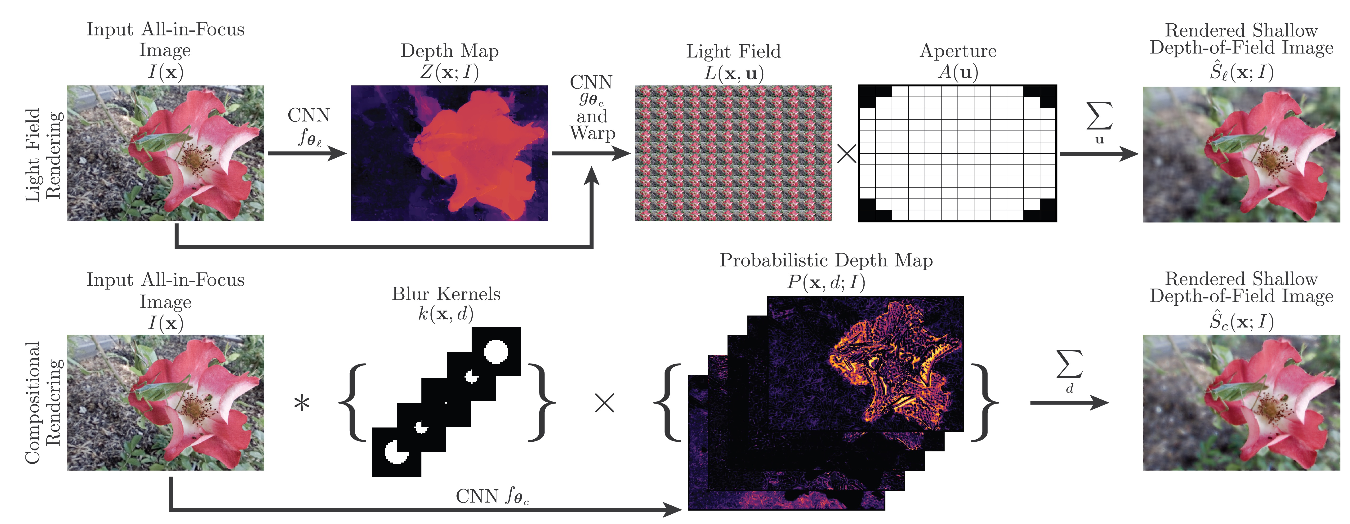
RGB-Depthを変換する、いわゆるダイレクトな距離画像推定では計算コストも高く、かつ解像度も低かったが、本論文ではフォーカスに関係する教示によりこの問題を解決し、単眼による距離画像推定を実現した。
End-to-EndでセンサデータからToFセンサの出力を行うToFNet (Time-of-Flight Network)を提案する。従来のシステムであh、センサーデータの入力からデノイジング、Phase Unwrapping (PU)やMultipath Correction (MP)を行っていたが、ToFNetでは一括処理が可能となるだけでなく、ノイズがない鮮明な画像を出力可能、リアルタイムで動作可能である。ToFNetはPatchGANという枠組みにより最適化が行われる。PatchGANはEncoder-Decoderの構造をした生成器と非常にシンプルな構造の識別器により構成される。誤差はL1+DepthGradient+Adversarialと、その重み付き和により計算される。
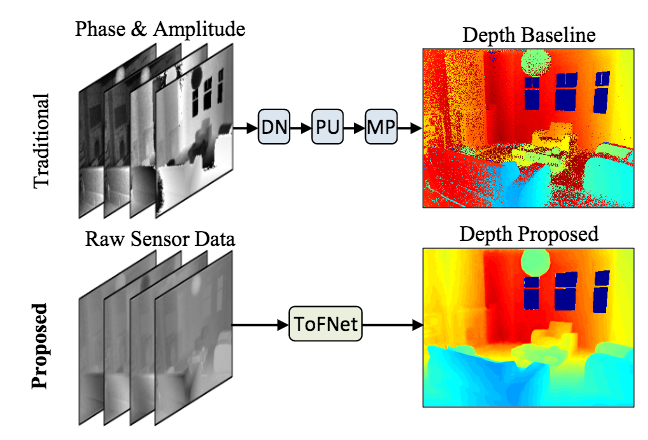
従来のカスケード型処理(デノイジング、PU、MP)ではノイズが蓄積してしまいがちだが、提案のToFNetは一括での処理を行い、(1)ノイズを鮮明に除去できるのみならず(2)リアルタイムでの処理が可能である。主にこの2点が採択された理由であると考える。
VQAの学習は学習データの答えの分布に依存してしまう。そこで、答えの分布が異なる学習データを用いて学習した場合でもGrounded Visual Question Answering(GVQA)を提案した。 GVQAでは質問に答える上で、(1)必要な情報を認識する(例:物体の色を聞かれている場合対象となる物体を認識する)(2)必要な答えを推測する(例:物体の色を聞かれている場合色を答える)の2つが重要であると仮定する。 そこで、画像から質問に答えるために必要な情報を抽出する部分と答えを推定する部分の2つに分けたモデルを構築した。 その際、質問から質問のタイプ(yes/noで答えられるか)を推定することで、質問の答えを異なるネットワークによって出力させる。
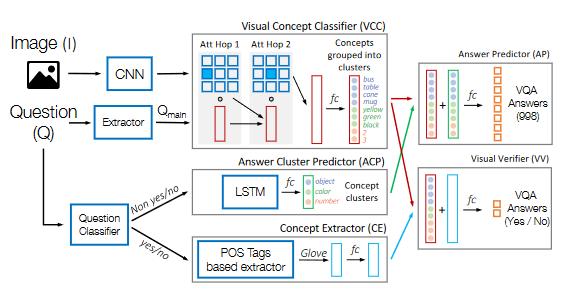
質問の答えの分布を学習データとテストデータで異なる分布にしたVQA-CPデータセットを提案した。同データセットを用いて従来手法及びGVQAの精度を調べたところ、従来のデータセットと比べた際の従来手法の精度低下及びGVQAの方が高い精度を記録したことを示した。 また、GVQAによって答えの根拠を説明することが可能となった。
Adversarial attackが、VisionとLanguageの融合問題のようにより複雑な問題に対しても有効であるかを調査した。対象とするタスクは、画像キャプショニング及びVQAとして画像のAdversarial exampleによる出力の変化を調べた。 また、これらの手法におけるlocalizationがAdversarial Attackに影響されるかを確認した。

Dense Captionについては、97%の確率で騙すことに成功した。同じ画像の同じ領域に対しても目標とするキャプションが異なると異なるキャプションを出力させることが可能なことを確認した。 VQAについてもごく一部を除いて騙すことができることを確認した。 Attention Mapを確認すると、Adversarial exampleを入力した場合異なる領域に注目していることが明らかになった。
VQAの答えだけでなく判断根拠も出力する手法を提案。質問をtree構造に分解し、各nodeに関する情報(例:plane)が画像中のどこに存在するかを示すattention mapを求める。 既に得られているattentionマップ及びhidden stateを更新していくことで、質問の答えとたどり着いていく。 最終的な質問の答えはhidden stateを用いて求める。
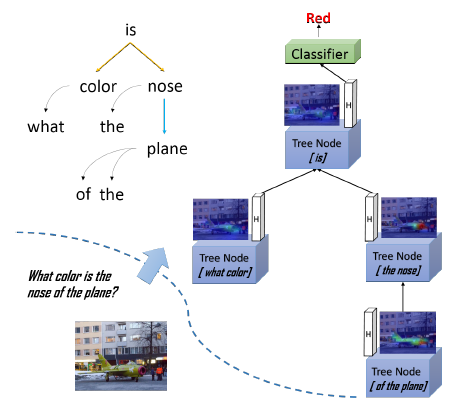
質問への回答の精度は従来手法と比べて大きく向上されているわけではない。従来の判断根拠を求める研究はルールを人間が設計するもしくはground truthが必要であるのに対してこれらを必要とせずに回答根拠を得ることに成功。
画像の品質を評価するためのBlind Predicting Similar Quality Map for IQA(BPSQM)を提案した。CNNを用いた画像の品質評価手法は数多く提案されているが、その大半はブラックボックスとなっている。 本研究は、ピクセル単位の画像の損失度合いを示すquality mapを始めに推定することで、画像圧縮などに伴いどのように画像の品質が低下してるかの可視化を可能とした。 また、qualityマップから画像の損失度合いを表すスコアの算出を行う。
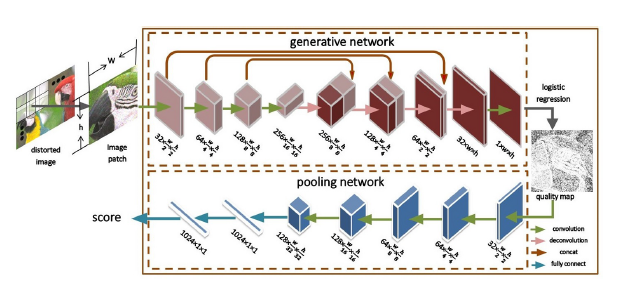
従来のquality mapを求める手法は、損失前の画像(reference)が必要なものが大半であり、reference不要なCNNベースの手法はパッチ単位で推定するのみであった。それに対して本研究は、referenceなしでピクセル単位のquality mapを推定することを可能とした。 損失度合いの推定に関しても、referenceなしの手法と比べて精度の向上を実現した。
画像中の記憶に残りやすい領域(Memorability)を可視化するネットワークであるAMNet(Attention and Memorability Network?)の提案。ResNet50による特徴表現、LSTMにより実装されたAttention構造の仕組みによりMemorabilityスコアを算出する。アノテーションは従来研究であるLaMem(下記リンク参照)に使用したデータセットであるSUN Memorability(同じく下記参照)を用いて学習を行った。
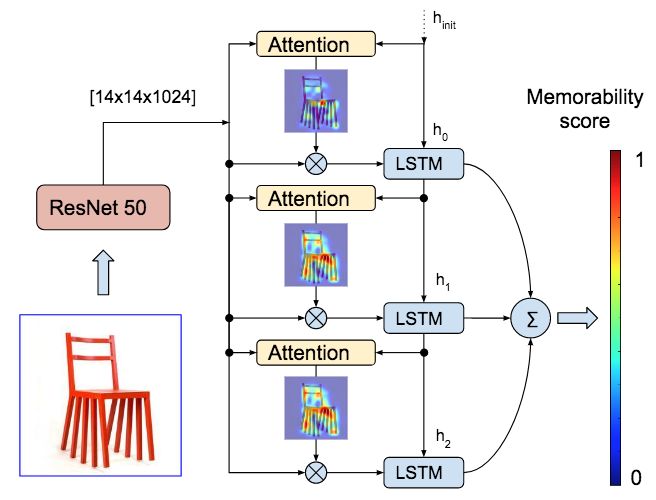
従来法よりも精度が良かった(より人間の記憶の構造に近かった?)ことを示した。これはアテンション構造を用いていることが、より人間の記憶の仕組みにおいて再現性が良かったことを示しているといえる。
記憶の仕組みも人間の直感が必要な高次機能の再現である。このように高次なラベリングが今後は増えてくると思うし、人間のタスクをカバーする意味でも重要になるか?
手荷物検査や医療用として用いられるComputed Tomography (CT)画像の復元を、限られた角度のSinogramの入力から行う技術(CTNet)を提案する。CTNetは1D/2D畳み込みで構成され、SinogramからFull-viewのCT画像を復元することができる。図はCTNetの学習とテストを示したものである。学習時にはGAN-likeな手法により構成され、入力から1DCNNにより特徴量を生成、GeneratorがCT画像を復元、DiscriminatorがReal/Fakeを判断することでGeneratorを鍛える。テスト時にはさらにFBP (Filtered Back Projection)/WLS (Weighted Least Squares)なども用いて最終的な結果を得る。
角度が限定されたx線画像から、360度のCT画像を生成するというチャレンジングな試みを行ったことが評価された。同課題に対してGAN-likeな手法を提案し、手法的な新規性も打ち出せたことが採択された基準であると考える。PSNRやセグメンテーションベースの方法で評価を行い、従来法よりも優れた手法であることを示した。
1枚のブラー画像から時系列フレームを推定して動画像を生成するアプローチを提案。モーションブラーは通常、カメラなどセンサによる露光により発生するが、その分解は非常に困難な問題として扱われていた。本論文では平均化を除去してフレームを時系列方向に並べ、次にDeconvolutionを復元して同問題に取り組む(この問題は通常、Blind Deconvolutionと言われる)。提案法では、深層学習の手法としてこの両者を実現する構造を構築。

Blind Deconvolutionの課題を取り扱っているが、さらにここでは単一のブラー画像から動画像を生成するアルゴリズムや深層学習アーキテクチャを提案した。特に、ブラー画像から時系列画像を順次復元するための誤差関数を提案したことが最も大きな新規性である。
テクスチャに対して有効かつスケーラブル、さらに学習可能な局所特徴量を提案する。さらに提案手法は既存のランキングロスやFully-Convolutional Networks (FCN; 全層畳み込みネットワーク)と統合可能である。著者らは、新規の学習誤差関数であるPeakednessという指標を畳み込みマップに対して導入した。画像はテスト画像に対して提案手法を施した結果であり、Repeatableな特徴量(画像の中に再帰的に登場するテクスチャ特徴)が検出されている。

(i)FCN構造によりフルサイズの再帰的なテクスチャパターンを評価することに成功した、(ii)Peakednessという指標を導入し、これを最大化することでテクスチャを評価するための畳み込みマップを洗練化することに成功、という点がもっとも重要な新規性である。実験ではcarpet/asphalt/wood/tile/granite/concrete/coarseといったテクスチャパターンに対して有効であることを示した。
元画像の輪郭情報から画像を再構成する手法を提案.GANをベースとして,入力情報が与えられない領域のテクスチャと細部を合成する.実験では,顔認証システムや人間を対象にして元画像と再構成された画像と区別されないという結果となった.

入力情報がない輪郭と輪郭の間の画像部分の再構成にも力を入れてる
オブジェクト性検出と分類を分離した物体検出器であるR-FCN-3000を提案した.RoIのための検出スコアを得るために,オブジェクト性検出と分類スコアをかける. R-FCNで提案されたposition-sensitive filterはfine-grained classificationには必要ないというのが基本アイディア. また本論文では,R-FCN-3000はオブジェクト数が増えると性能が向上することが示されている.

ImageNet detection datasetで一秒あたり30枚の画像を処理したところ,mAPが34.9%であった(YOLO9000は18%).
暗い環境において,同じシーンを短時間露光で撮影した暗い画像と長時間露光で撮影した明るい画像のrawデータを集めたデータセットを提案した.このデータセットは,5094個の暗い画像のrawデータと424個の明るい画像のrawデータが1対多で対応付けられている. インドアとアウトドアの両方で撮影を行った.

このデータセットを用いてFCNをトレーニングし,テストしたところ図に示すような結果が得られた.このネットワークはrawデータを直接扱うため,図に示すように,従来の画像処理パイプラインの多くの代わりになる.
General Advesarial Networks(GAN)は現在,コンピュータビジョン分野で広く使われている手法である.しかしながら,複雑な学習をするには時間がかかり,人の手が必要となる.そこでSGANというトレーニングプロセスを検討する.SGANではいくつかの敵対的でローカルなネットワークの組み合わせを独立させて学習させることでグローバルな一対のネットワークの組み合わせを学習することができる.SGANの学習はローカルディスクリミネータとジェネレータによってグローバルディスクリミネータとジェネレータが学習される.
adversarial pairs (G1,D1),...,(GN,DN)を学習し, G0はD1,...,DNによって学習, D0はG1,...,GNによって学習させることでグローバルな一対のネットワークを学習する。
日に日に増えるウェブデータから学習することはポピュラーになりつつあるが,従来の学習とウェブデータを使用した学習では,ラベルが時々間違っているなどの大きなギャップが存在する.これを解決する従来手法では,さらに情報を追加してウェブデータから学習する傾向があったが,この論文では,より活発なカテゴリレベルの監視をすることによりラベルノイズを減らすWSCI(Webly Supervised learning with Category-level Information)を提案. 分類を行うネットワークをVAE(Variational AutoEncoder)の隠れ層に接続し,分類ネットワークとVAEがカテゴリレベルのHybrid Semantic Informationを共有する. 提案手法の有効性はAwA2, CUB, SUNの3つデータセットで評価している.

いずれのデータセットにおいても,提案手法は従来手法に比べ2~5%ほど精度が向上しており,AwA2のデータセットにおいては90%を超える評価を出している.
DNNを使用したデータ駆動型による学習を可能するカメラ位置推定手法, MapNetを提案.MapNetではイメージ間の絶対的な位置姿勢と相対的な位置姿勢のロスを最小限に抑えることができる. さらに画像だけでなく,Visual odometry(VO)やGPSなどのユビキタスセンサ,Inertial Measurement Unit(IMU)などをカメラ位置推定に加え, ラベルなしのビデオを利用した,自己教師あり学習によるMapNet+の提案もした. Pose Graph Optimization(PGO)によって入力データをrefineしてAccurancyの改善を行う. データセットには小規模な位置推定のトレーニングに7-Senes,大規模なものにはOxford RobotCarsを用いている.
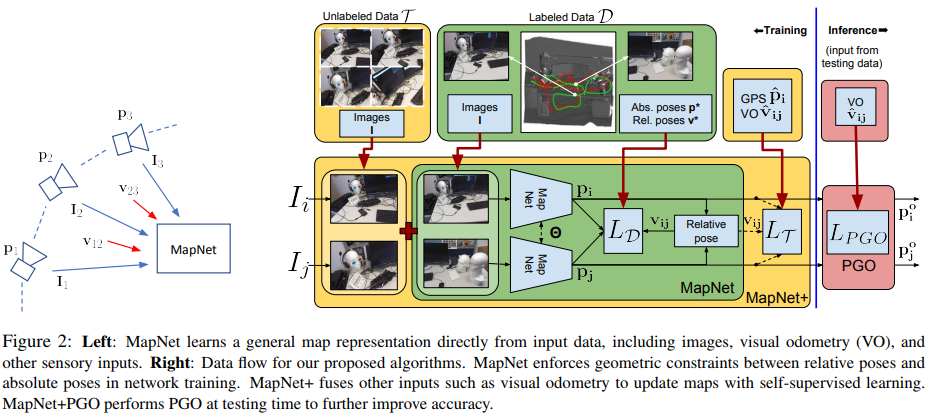
MapNet+は自己教師あり学習とマルチセンサによってパフォーマンスを向上させており,特に大規模な位置推定ではStereo VOやPoseNetなどの従来手法と比較し精度が劇的に向上している.
コンピュータによって学習用のアノテーションを生成し,実画像のような合成画像として用いることが流行.しかし,ドメインの不一致という問題が起きる.それを解決するために,GANをFCNフレームワークに統合することでSemanticSegmentationのためのドメイン適用のための手法を提案.
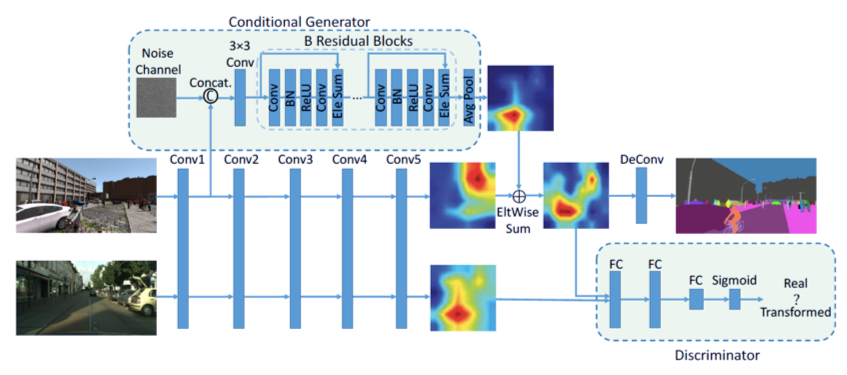
画像からスケッチのストロークを取得する手法の提案。人間が画像からスケッチをすると、同じ画像に対しても様々なバリエーションが生じてしまう。 そこで、教師有学習と教師無学習を組み合わせることによって画像からスケッチの取得を実現する。 教師有学習は、画像からスケッチもしくはスケッチから画像という変換を学習する。 教師無学習は、オートエンコーダのように画像もしくはスケッチを符号化し、元に戻すという処理を学習する。 その際、CycleGANのようにドメイン変換を繰り返すのではなく、符号化したものをそのまま復号化する(Shortcut Cycle)。
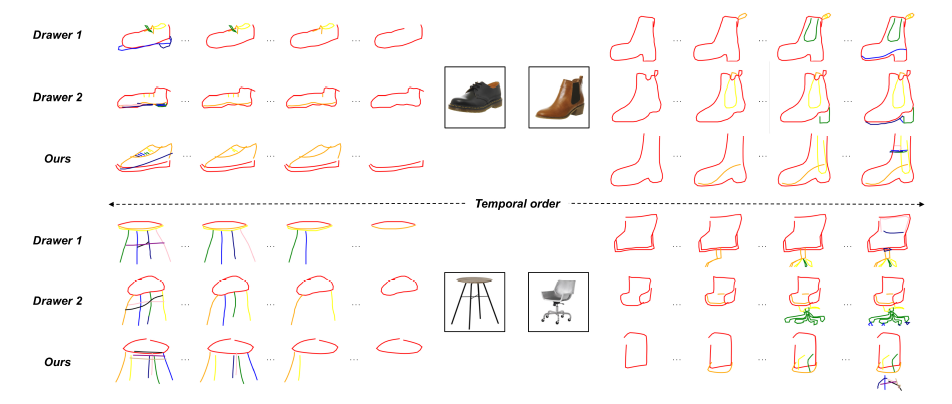
Pix2pixやCycleGANなどの手法と比較を行い、いずれの手法と比較してもスケッチとして抽象化されつつもセマンティックな特徴を捉えていることを確認した。また、数値評価としてスケッチの認識及び検索タスクを行って評価した。 どちらのタスクにおいても、従来手法と比較して高い精度でスケッチへの変換ができていることを示した。
複数の文で構成されたテキストの内容を表す画像シークエンスを検索する手法を提案。文章から抽出される特徴と画像から抽出された特徴を対応付けることにより、各文に対して1枚の画像を選択する。 その際、文章特徴はGRUによって前後の文章との関係を含めて抽出する。 また、heやitなどの代名詞が何を指しているかを明らかにするために、テキスト全体としての一貫性を測るcoherence vectorを導入した。
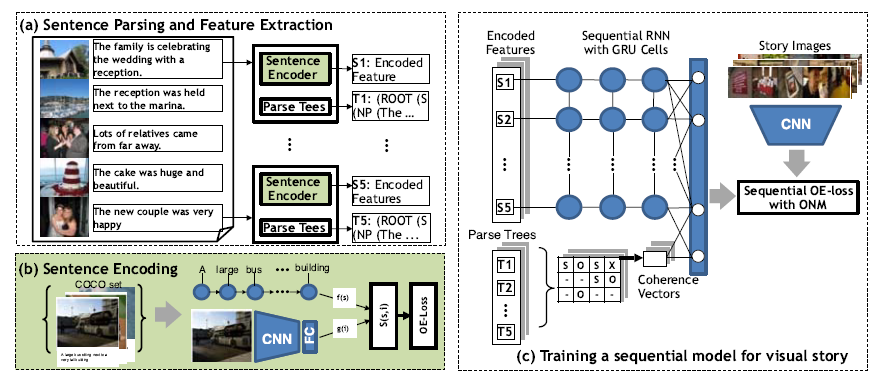
ベースラインとなる手法では、文単位で画像の検索を行っているために画像シークエンスとしての一貫性が損なわれてしまう。そこで、GRU及びcoherence vectorによって前後の文で登場した単語などを考慮することが可能となり、テキスト全体を表す画像シークエンスの検索が可能となった。 ユーザースタディにより、ベースライン、coherence vector無し、coherence vector有りの比較を行い、coherence vector有りが最も好まれる結果を得た。 また、画像シークエンスがテキストに合っているかは主観的な評価であるため、saliencyベースの新たな評価指標を提案した。
順序構造に対して不変な3次元 Point Cloud のための deep learning アーキテクチャー SO-Net を提案. Self-Organizing Map (SOM) を作ることで点群の空間分布をモデル化し, SOMのノードを用いて階層的な特徴量の抽出を行う. Point Cloud のクラス分類やセグメンテーションなどのタスクを用いた評価実験では, 先行研究と同等以上の結果をより短い学習時間で達成した.
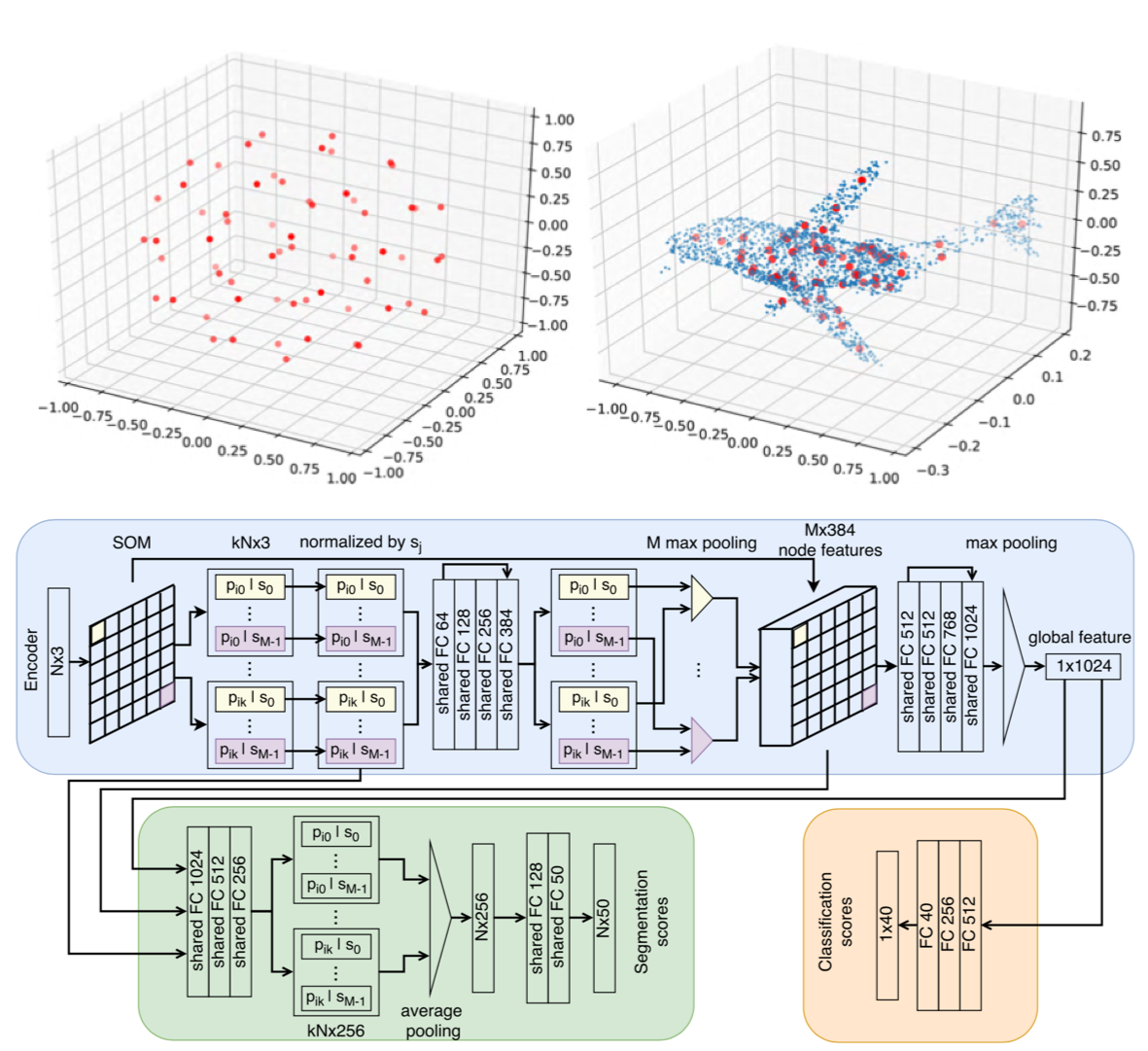
大規模(数百万規模)な point clouds データに対して効率的に Semantic Segmentation を行う研究. まず, point clouds 全体を形状が単純で, 意味的に同じ点が属する部分集合(superpoint)に分類し, superpoint が作るグラフ (SPG)に graph convorution を適用することで segmentation を行う. Semantic3D と S3DIS dataset を用いた評価実験では先行研究よりも良い結果を達成した.
3次元点群処理のための autoencoder を提案. Folding という新しい decoding 演算を導入することで, 2次元グリッド上の点から3次元点群の表面上への射影を教師なしで学習した.
Video Fast-forwarding のタスクを MDP(Markov Decision Process) として定式化し, 強化学習を用いて解く方法を提案. 評価実験では精度と効率の両方に置いて先行研究よりも優れた結果を示した.
ウェアラブルデバイスのような使用可能な電力が限られる状況において, 電力消費と精度を強化学習を用いてバランスするフレームワークを提案. 複数のセンサー情報を用いた行動認識のタスクにおいて, 高精度・高電力消費な predictor と低精度・低電力消費な predictor を強化学習の結果に基づいて適宜切り替えることで少ない消費電力で先行研究と同等の精度を達成した. また, 一人称視点動画行動認識のための新しいデータセットを作成した.
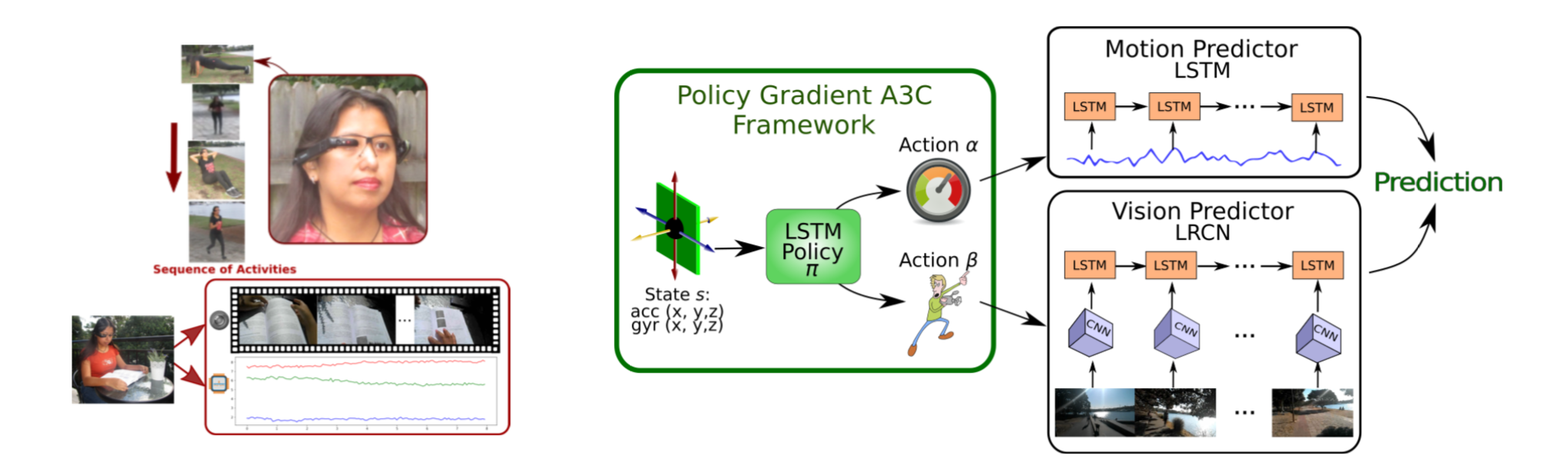
強化学習 (A3C) を用いて Image cropping を行う手法を提案. 従来の sliding winodow に基づく手法のように膨大な数の cropping 候補を評価する必要がないため, 先行研究よりも短時間で結果の計算が可能. また, 評価実験では精度についても先行研究よりも優位な結果を達成した.
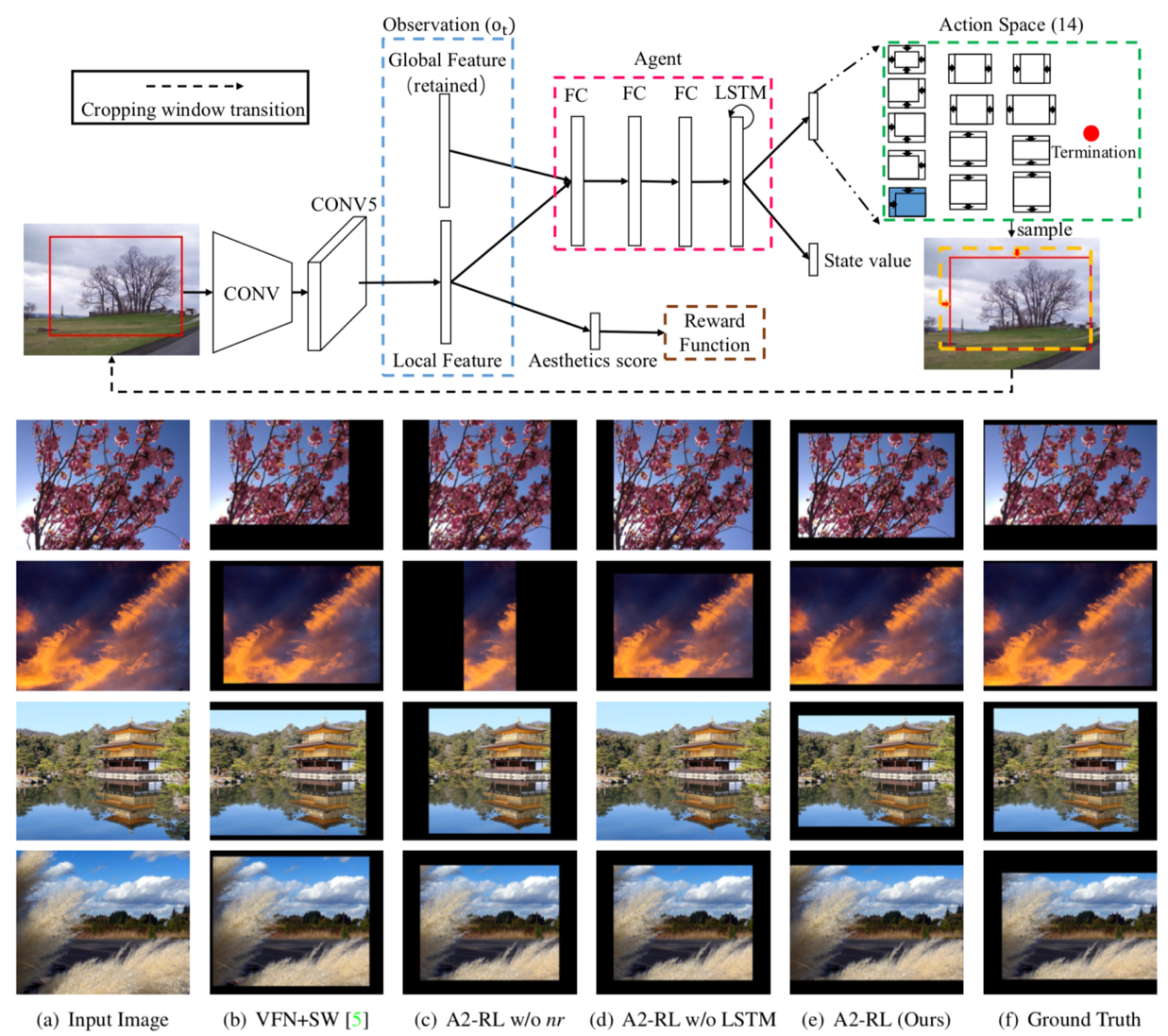
画像の構図の良し悪しを評価するComparative Photo Compositionデータセットを構築。10800枚の画像から24の構図の画像を作成し、クラウドソーシングによって2つの構図のどちらがいいかをアノテーションした。 また、入力画像をどのようにクロッピングすると良い構図になるかを提示するシステムを構築した。 その際、IOUを評価尺度にすると構図的に評価が低いものも高いスコアになるため、画像を評価するネットワークから得られるスコアを指標とした。

従来のデータセットでは画像に対してスコアがついていたのに対して、構図の異なる2枚の画像どちらがいいかを100万ペアアノテーションを行った。構図推薦システムは、ユーザースタディの結果従来手法よりも良いと感じる人が多いことを確認した。 また、計算速度も従来手法と比べはるかに向上した(75FPS+).
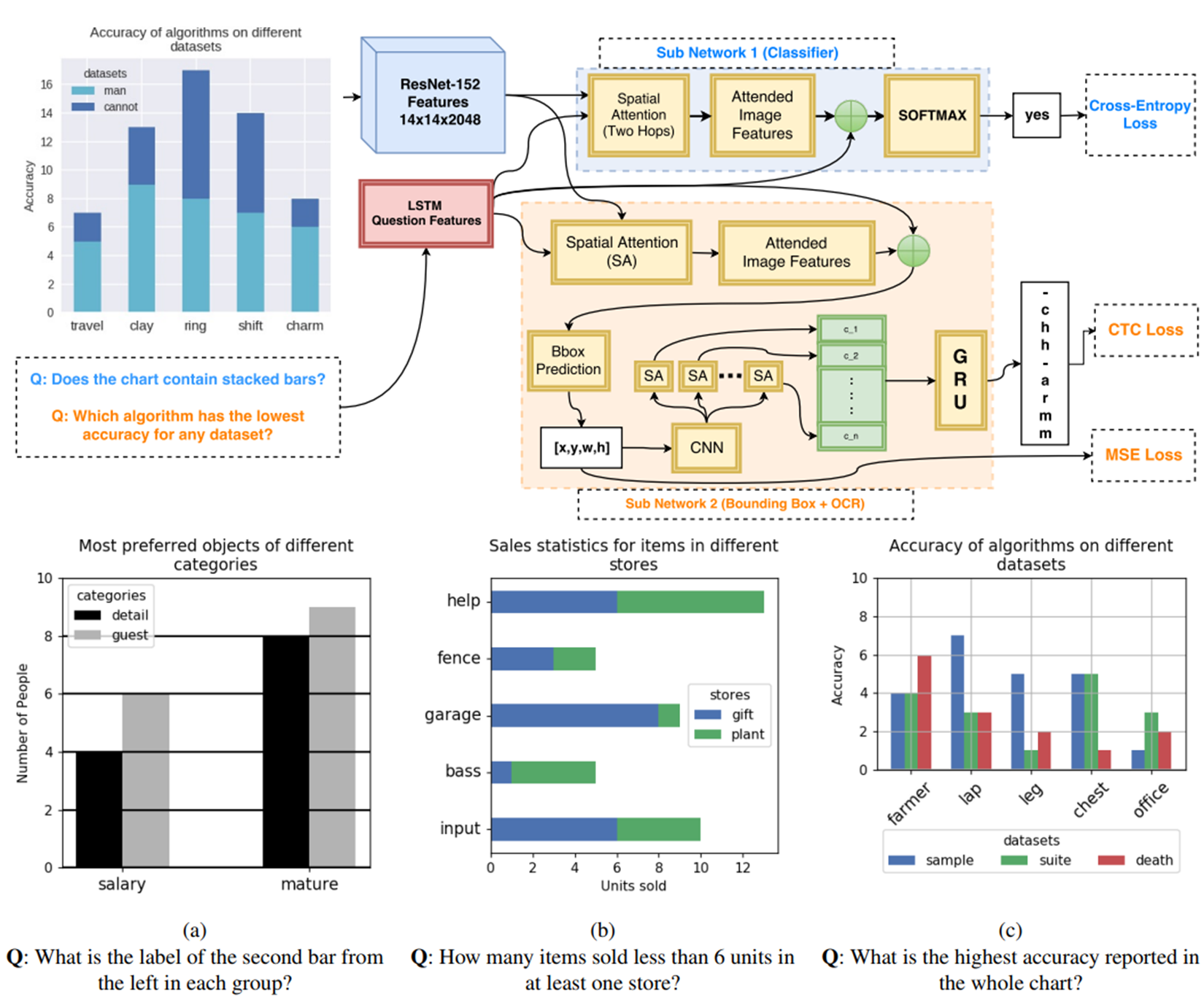
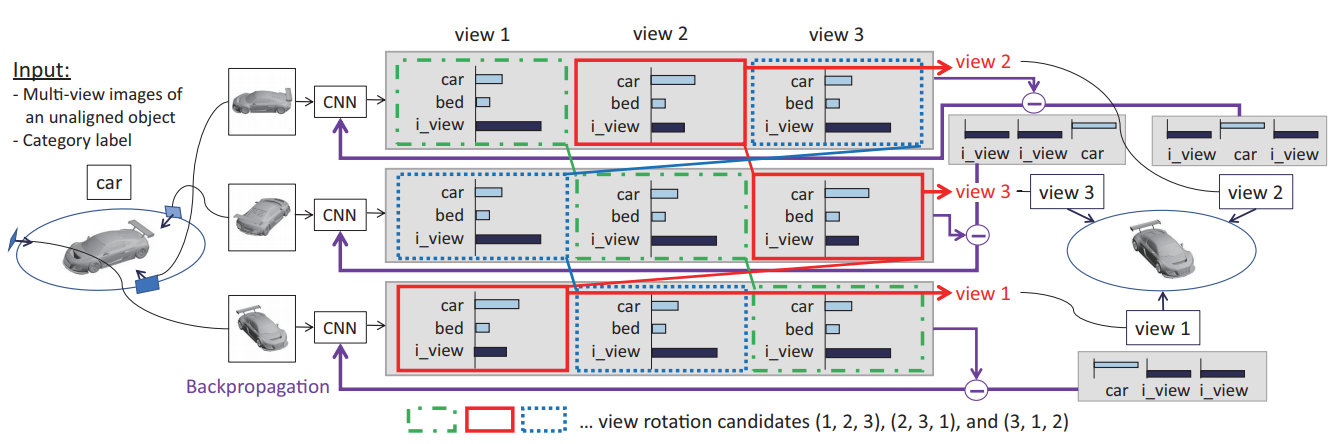
地理情報に関する分析の研究に用いられるデータセット
国のバリエーションが豊かなデータセットなので,国ごと上空シーン特徴の比較などにも用いられる
ソースドメインのラベル付きデータセットが複数ある場合のunsupervised domain adaptation(UDA)であるmultiple domain adaptation(MDA)によってターゲットドメインのクラシフィケーションを行う Deep Cocktail Network(DCTN)を提案。MDAではUDAで問題視されるドメインシフトに加えて、 ソースドメインのデータセット間で全てのカテゴリが共有されていないカテゴリシフトが存在する。 DCTNでは、k番目のソースドメインのデータセットとターゲットドメインのデータセットを入力として discriminatorによってperplexity scoreを算出することでどのソースドメインのデータセットの分布に近いかを算出し、 これを全てのソースドメインのデータセットに対して行い、perplexity scoreを重み付けるすることで最終的な識別結果を出力する。
2つのドメインを結合する手法であるCanonical Correlation Analysis(CCA、正準相関分析)を教師なし学習に対して行うUnsupervised Correlation Analysis(UCA)を提案。 既存のCCAは教師あり学習かつ2つのドメインが何らかの対応関係を持っていることを前提としていたが、 UCAは教師なし学習かつ2つのドメインに対応関係がない場合を想定している。 教師あり学習とは異なり、トレーニング時に2つのドメインにおける相関係数を計算することができないため、入力する2つのドメインと、 ネットワークによって射影された潜在変数空間の3つのドメイン間の射影、逆射影がうまくいくように様々なロスをとることで学習を行う。 ロスに対するablationも行なっている。
ラベルなしデータセットにおいてperson re-identification(re-id)を教師なしで行うために、ラベルありデータセットからdomain adaptationを行うTransferable Joint Attribute-Identity Deep Learning(TJ-AIDL)を提案。person re-idとは、街中の監視カメラのような異なる視点、 重複のない領域を撮影された映像内の同一人物を探すことである。 TJ-AIDLにはアイデンティティーを推定するIdentity branch、アトリビュートを推定するAttribute branch、 アトリビュートからアイデンティティーを推定するモジュールであるIdentity Inferred Attirbute(IIA)からなる。 domain adaptationの際には、Attribute branch、IIAの更新のみを行う。
![]()
同一カテゴリのdomain間におけるadaptation, transferをラベル識別と2つのdiscriminatorを用いるネットワークDupGANを提案。target domainにはラベルがない状況である教師なし学習を対象としている。 DupGANはencoderでそれぞれのドメインの潜在変数をエンコードし、generatorでデコードを行い、 2つのdiscriminatorでそれぞれのドメインに対してfake/realとラベルの認識を行う。 結果はdomain transferされた数字画像のラベル認識・生成結果、物体認識の精度において比較を行う。
比較をしていない設計(Oct-tree based representationなど)もあるので,そういった構造に対して比較実験を行うのも面白い.
3次元あたりの徹底的比較を行って,何らかの結論を出すような研究がまだ少ないので,研究テーマを沢山作れるかも?
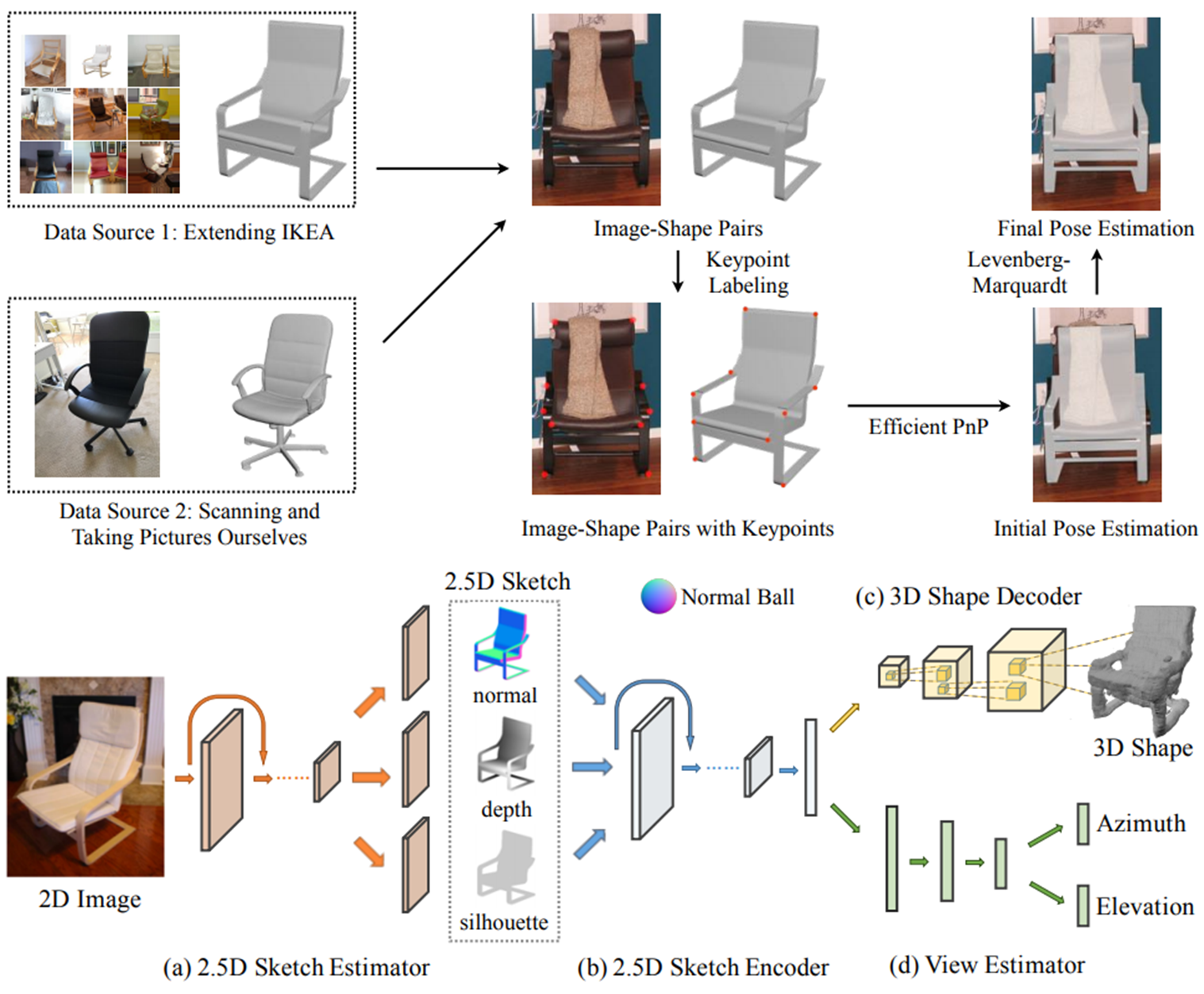
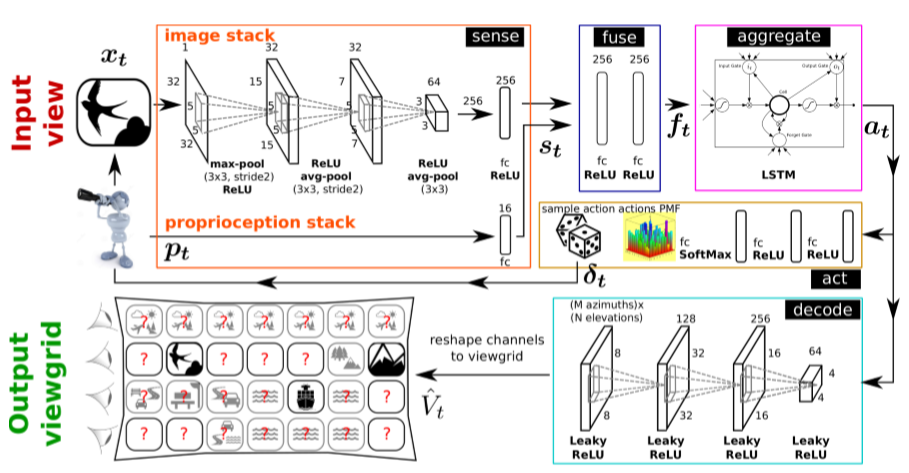
Interactive 環境でのVQAタスク(Embodied Question Answeringなど)は環境から“情報量が豊かな画像”を集めるのが重要の一環なので,提案フレームワークを用いられそう.
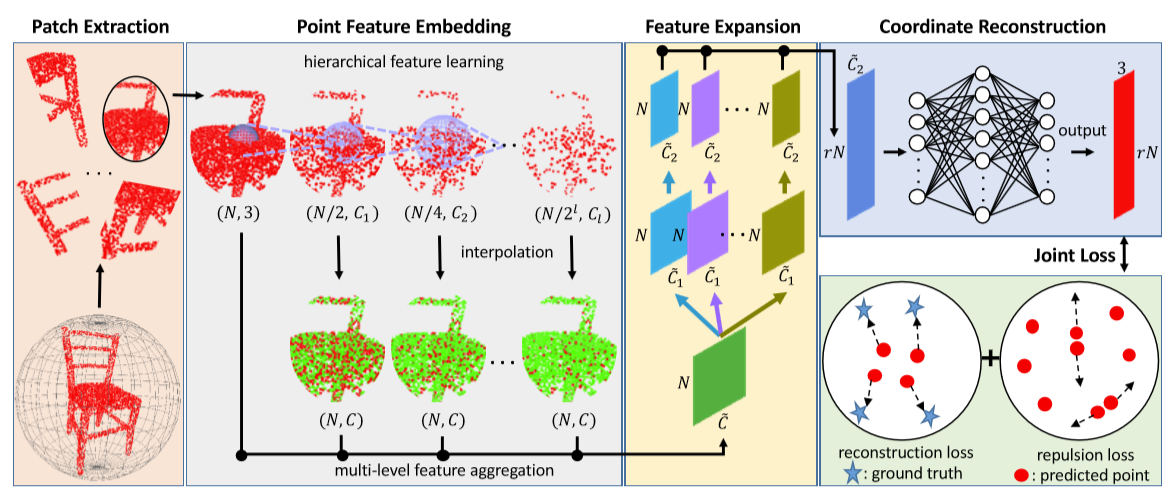
提案手法を更に発展し物体モデルの補完およびアップサンプリング同時にできることを期待される
Pointnet++を基本構造として使っていることがすごそう
深層学習を用いた教師あり学習による顕著性の検出方法は教師データに依存する.そこで,“汎化能力を改善しつつ教師データなしで顕著性マップを学習することは可能か?”という問いに対して,弱いものやのノイズのある教師なし顕著性検出手法によって生成される多数のノイズラベルを学習することによって教師なしで顕著性の検出を行った.
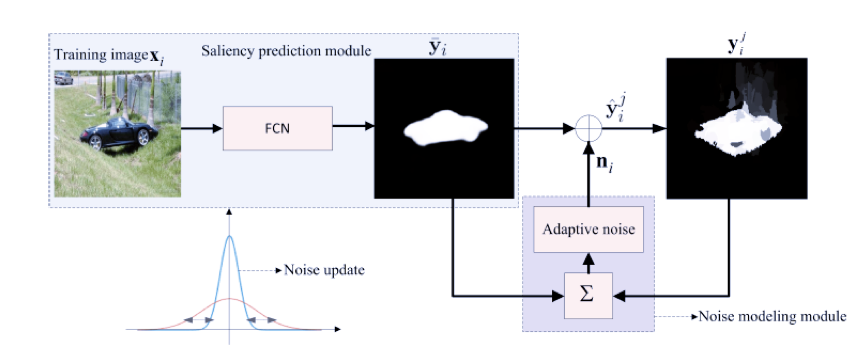
対応する航空写真とストリートビュー写真間の変換を行うcGANを提案.pix2pixによる変換に比べて,オブジェクトの正しいセマンティックスを捉え維持する変換が可能となっている.提案したcGANモデルは2つあり,X-Fork とX-Seq と呼んでいる.出力が変換画像とセグメンテーションマップであることが特徴.Inception Scoreの比較実験をすると,航空写真からストリートビュー方向の変換ではがX-Forkが優れ,逆方向の変換ではX-Seqの生成結果が優れていることがわかった.

256x256の解像度で生成可能.gがストリートビューで,aが航空写真に当たる.
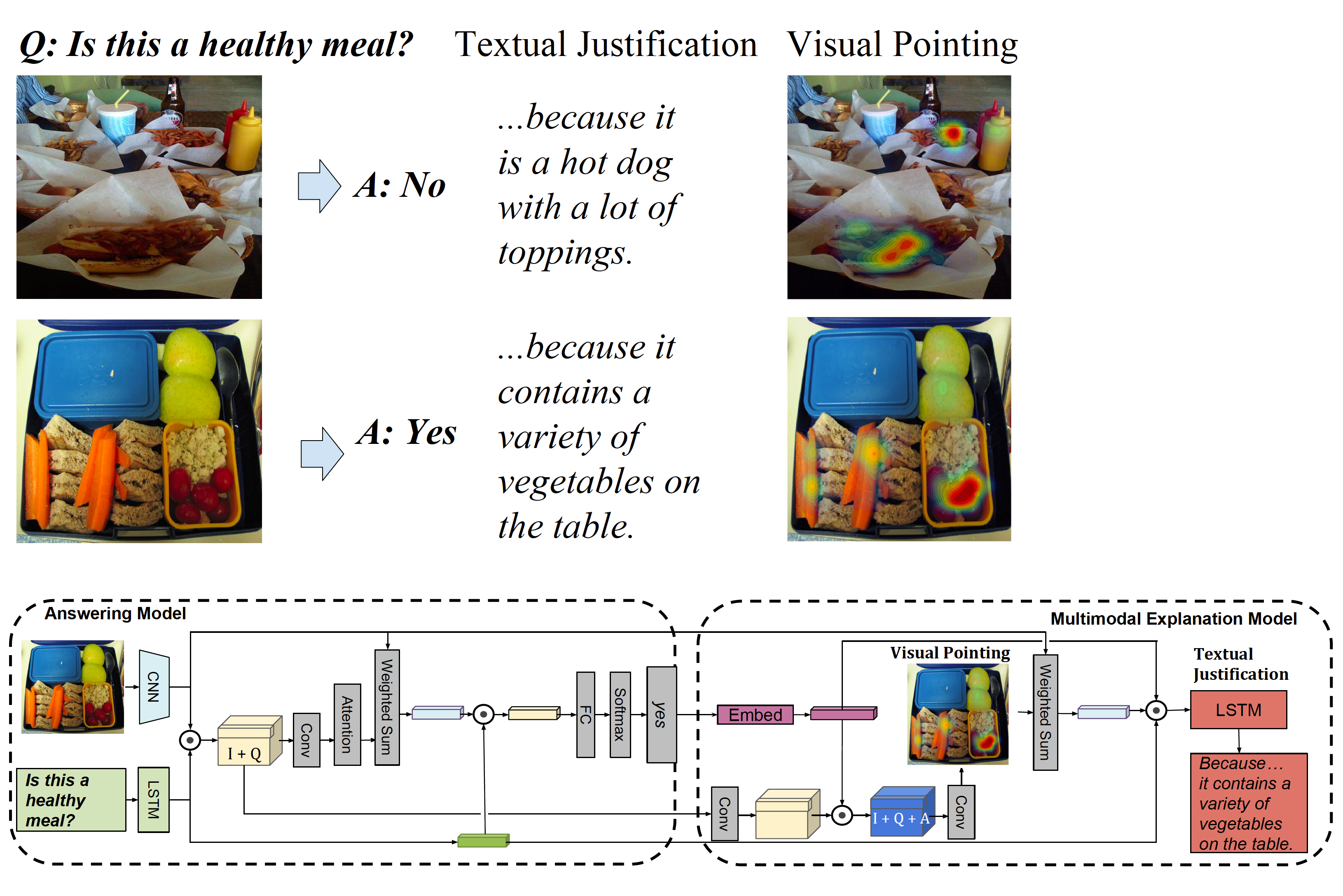
画像を構成する成分はshape(ジオメトリ、ポーズなど)とappearanceであるという考えのもと、VAEによってappearanceを推定し、 U-Netにshapeを学習させることで入力画像のappearanceとshapeの 片方を保ったままもう一方を変更することが可能なVariational U-Netを提案。 通常のVAEではshape、appearanceの分布を分離することが不可能なため、 VAEに画像とshapeを入力することでappearanceの特徴量を抽出し、U-Netによってshape情報を保つように学習を行う。 shapeとして体のポーズや線画が入力される。トレーニングデータには同一物体に対する様々なバリエーションの画像は必要としない。
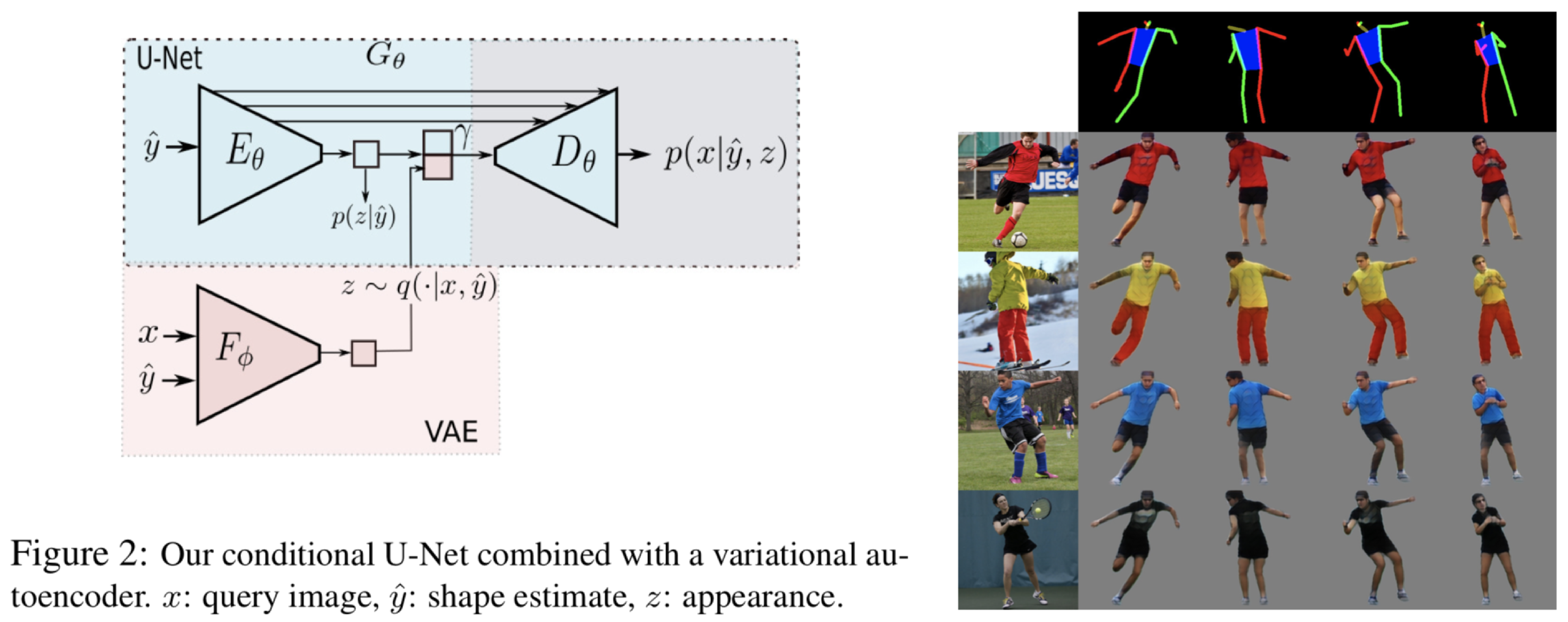
表情、体全体の動き、手のジェスチャといった様々なスケールの動きをマーカー無しでキャプチャするdeformation modelである”Frankenstein”と”Adam"を提案。 3Dキャプチャシステムに置いて、画像の解像度と3Dキャプチャシステムの視野はトレードオフであるため、 体の局所的な動きと全体的な動きを同時に捉えことは難しかった。提案手法では顔、両手、両足、 手の指における3Dキーポイントと3D Point Cloudを用いて表情などの 局所的モーションと体全体のモーションをキャプチャすることができるFrankensteinを構築。 また70人のトラッキングデータを用いてFrankensteinモデルを最適化することで、 髪と服を表現することが可能なAdamモデルを提案。結果は既存手法とのトラッキングの精度によって比較している。
![]()
ラベル付き合成顔画像とin-the-wildなラベルなし実顔画像のどちらもトレーニングデータとして使用することで、実顔画像からシェイプ、リフレクタンス、イルミネーションを推定してリコンストラクションをend-to-endに行うSfSNetを提案。 実顔画像に十分なラベルがついているデータセットが存在しない、という問題を解決。Shape from Shading(SfS)のアイディアに基づき、 低周波成分を合成顔画像から、高周波成分を実顔画像から推定する。リコンストラクションされた画像のL1ロスを取ることで、 トレーニングにおける合成顔画像と実画像の橋渡しが行われる。リコンストラクションにはランバーシアンレンダリングモデルを使用する。
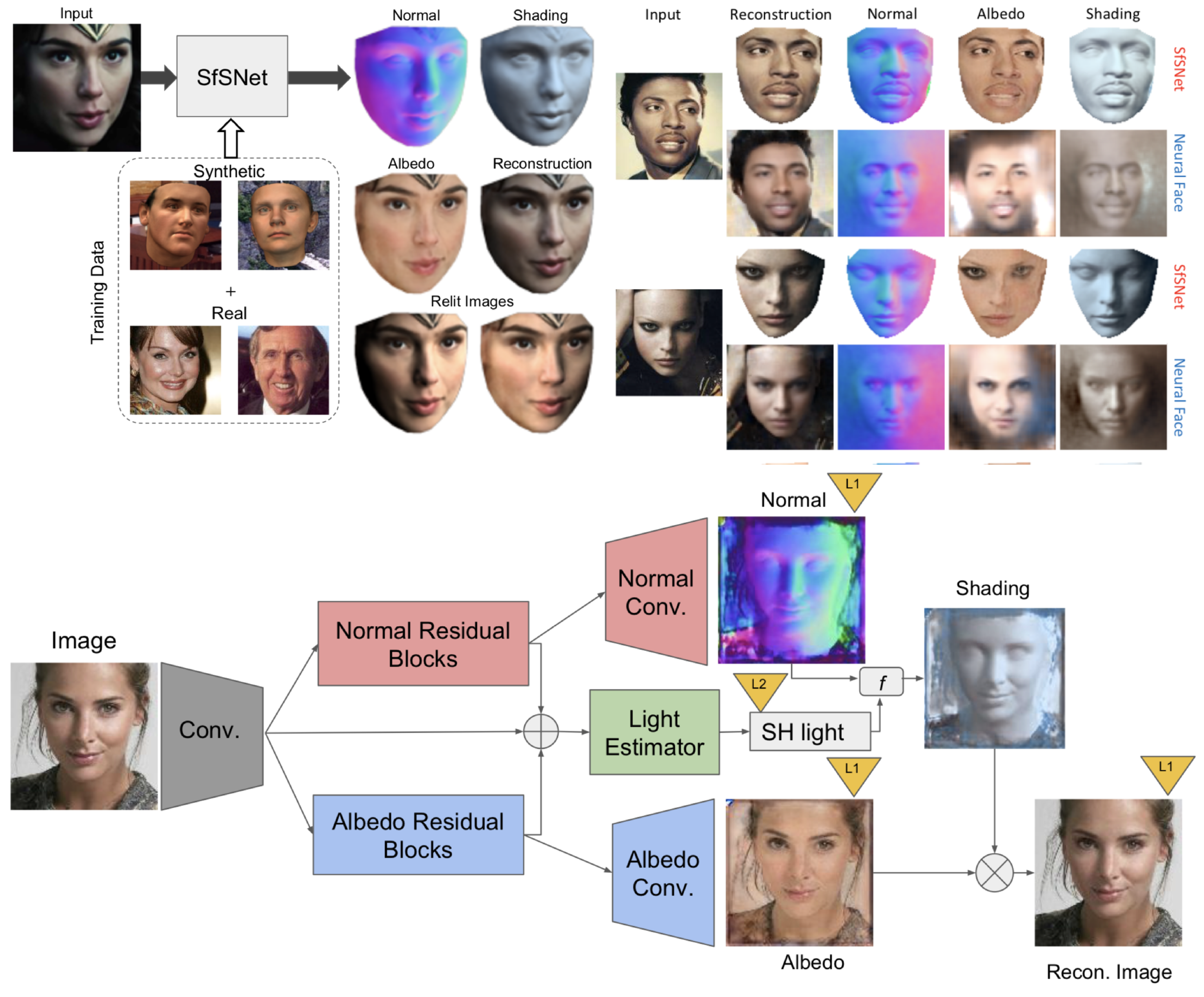
2つの動画から、手術や絵を描くなどの技能がどちらが上かを予測する手法の提案。入力動画をTemporal Segment Networks(リンク参照)によりいくつかのセグメントに分割し,技能評価に用いるフレームを3枚選択する。 技能評価の学習は、2つの動画のどちらが技能が上か、2つの動画の技能が同じであるとき同じであると判定できるかの2つの尺度をロスとして行う。 技能を表すスコアは、Two Stream CNN(リンク参照)によって空間と時間それぞれについてスコアを取得する。
手術、ピザ生地をこねる、絵を描く、箸を使うの4つの技能を撮影したデータセットにより実験を行った。そのうち絵を描く、箸を使うは新たにデータセットを構築した。 全てのタスクで70%以上の精度を達成し、箸を使う以外のタスクではベースラインと比べ精度が向上した。
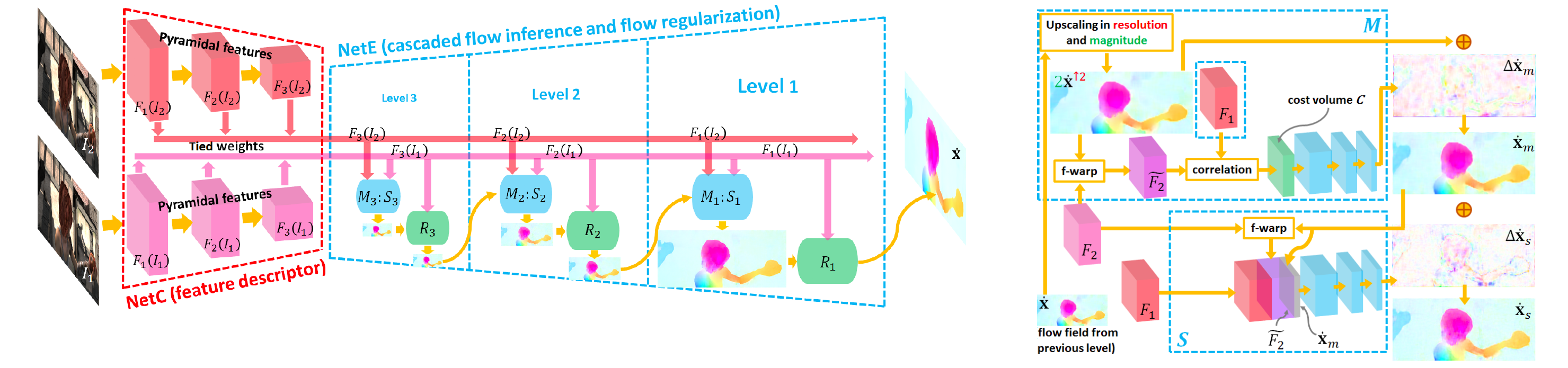
Person Re-identification (ReID)のパフォーマンスは大きく向上したが,複雑なシーンや照明の変化、視点や姿勢の変化といった問題の調査は未だなされていない.本稿ではこれらの問題に関する調査を行った.このためにMulti-Scene MultiTime person ReID dataset (MSMT17)を構築した.またドメインギャップがデータ間に存在するため,このドメインギャップを埋めるためのPerson Transfer Generative Adversarial Network (PTGAN)を提案した.実験ではPTGANによってドメインギャップを実質的に狭められることを示した.



大規模スケッチベース画像検索において,既存の手法では学習中にカテゴリの存在しないスケッチクエリがある場合失敗するという問題がある.本稿ではそのような問題を解決するZero-shot Sketch-image Hashing(ZSIH)モデルを提案した.2つのバイナリエンコーダとデータ間の関係を強化する計3つのネットワークで構成される.重要な点として,Zero-shot検索での意味的な表現を再構成する際に生成的ハッシングスキームを定式化する点である.Zero-shotハッシュ処理を行う初のモデルであり,関連する研究と比較しても著しく精度が向上した.
3Dスキャンは人間をキャプチャするために設計されており,自然環境での使用や野生動物のスキャンおよびモデリングには不向きという問題がある.この問題を解決する方法として,画像から3Dの形状を取得する方法を提案した.SMALモデルを画像内の動物にフィット,形状が一致するようにモデルの形状を変形(SMALR),さらに複数の画像においても整合性がとれるよう姿勢を変形させ、詳細な形状を復元する.本手法は,従来の手法に比べ大幅に3D形状を詳細に抽出することを可能にするだけでなく,正確なテクスチャマップを抽出し,絶滅した動物といった新しい種についてもモデル化できることを可能にした.

俯瞰画像から物体検出するためのデータセットを提案.従来のデータセットのものよりも小さい物体が多いデータセットである.各画像は4000×4000ピクセルであり,さまざまな大きさ,向き,形状を示す物体を含む.データセットは15カテゴリに分類されており,188282のインスタンスを含み,それぞれは任意の四角形でラベリングされている.人工衛星での物体検出の基礎構築のために,DOTA上の最先端の物体検出アルゴリズムを評価した.
俯瞰画像データセット内のインスタンスは小さいものの割合が高く,細かいものも検出可能人工衛星による物体検出に応用が利く可能性を示唆.
フラッシュを当てた状態の写真とそうでない写真の2種類を利用して,画像を光源の違いに基づく構成画像へと自動的に分離するアルゴリズムの提案.2つの写真の色情報の違いに基づき,光源に対応するスペクトルや陰影との関係を見出す.従来手法と比較して,光の色合いや陰影を忠実に反映した低ノイズでの分離が可能であることを示した(従来手法(Hsu et.al.)でのSNR:10.13dB 提案手法でのSNR 20.43dB).また,提案手法が画像のライティングの編集,カラー測光ステレオに有用であることを示した.

この論文は,各々の入力インスタンスに対して,複数の見えないクラスラベルを予測できるmulti-label learning及びmulti-label zero-shot learning(ML-ZSL)の新しい深層学習の提案した研究. 提案手法は複数のラベル間で人間が関心を持つsemantic knowledgeをグラフの中に組み込むことにより, 情報伝播メカニズムを学習し見えているクラスと見えないクラスの間の相互依存関係をモデル化することに適用できる. 本手法はstate-of-the-artと比較して,同等または改善されたパフォーマンスとして達成をすることができる.
・見た目だけでなく,経験を通して学んだ知識を使って物体を認識・WordNetから観察された知識グラフをend-to-endの学習フレームワークに組み込み,意味空間に電番されるラベル表現と情報を学習 ・NUS-81およびMS-COCOの結果をWSABIE,WARP,Fast0Tag,Logisticsと比べたところ精度について一番高い結果を残した. ・ML-ZSLについてもFast0Tagと比べて高い精度を残している.
generatorとdiscriminatorを一つのモデルで表現するIntrospective Neural Network(INN)に対してwasserstein distanceを導入することで、INNと同等の生成能力・識別能力を保ちつつclassifierにおけるCNNの数を20分の1にしたWasserstein INN(WINN)を提案。 生成された画像の比較はDCGAN、INN for generative(INNg)、INNgのclassifierにおけるCNNを一つにしたINNg-singleと行った。 またadversarial exampleに対して頑健な識別精度を達成した。
3Dスキャンデータを使用せずにin-the-wildな顔画像のみを用いてencoder-decoderによって3D Morphable Model(3DMM)を生成する手法を提案。生成された3DMMを nolinear 3DMMと呼んでいる。 従来のlinear 3DMMは学習のために3Dスキャンデータが必要であり、かつPCAによって次元削減を行うため表現力に乏しいという問題点があった。 提案手法ではencoderによってプロジェクション、シェイプ、テクスチャのパラメタを取得し、decoderによってシェイプ、テクスチャを推定する。 また初期の学習では既存手法によって得られる3DMMのプロジェクションパラメタ、 シェイプパラメタとUV空間から得られるテクスチャを擬似的なGTとすることで弱教師学習を行う。
in-the-wildな入力顔画像から得られるUVマップの補完をU-Netで行う手法を提案。入力画像に対して3D Morphalbe Modelを適用し不完全なUVマップを取得し、U-Netで補完を行うように学習を行う。 discriminatorにはUVマップ全体と顔領域の判定をさせる。 またUVマップの個人性が失われないように、アイデンティティーに関するロスを取る。 1892人のUVマップをもつWildUVデータセットの構築も行った。
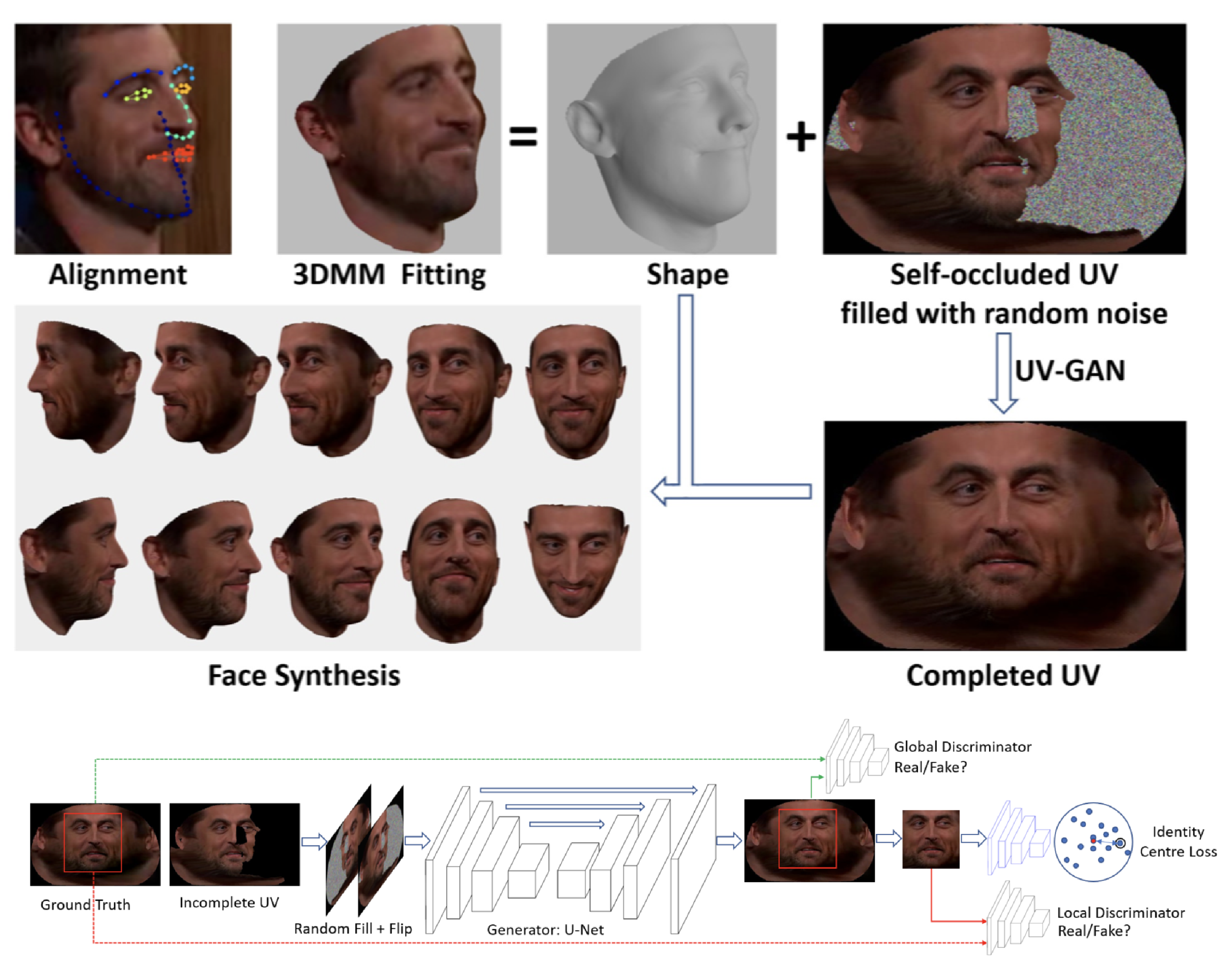
単RGB画像で,リアルタイムに材質反射特性を推定する手法を提案し,デモシステムを作った.
構造は,主に複数のU-Netからなり,それぞれ前景セグメンテーション,スペキュラー推定,鏡面反射推定を行う.ロス関数も定義.
さらに,形状情報も使えるのなら,低・高周波光源情報の推定も可能.連続撮影時の光源情報の連続性を考慮した時系列統合の枠組みも提案.
低解像度+高解像ガイダンスマップを与えると,高解像度画像を効率的(省計算時間,省メモリ)に出力できるGuided Filtering Layerなるものを提案.
GuidedFilterは, 空間的に変化する線形変換行列のグループとして表現でき, CNNに統合可能.つまり,end-to-endで最適化可能な 深層ガイデッドフィルタネットワークを構成できる.
CNNにより学習したタスクの出力結果に対して、人間がヒント(例:画像中に空は見えない)を与えていくことで精度向上を図る研究。CNNモデルをheadとtailの2つのパートに分割し、headから得られた特徴マップをヒントによって修正していくことで精度の向上を実現する。 その際、ネットワークの重みを更新するのではなく修正に用いるパラメータを言語情報から推測することで行う。 ネットワークの予測結果とground truthの差分を取り、正しく予測できていない物体の種類や位置を推定することで学習に用いる文章は自動で生成する。
セマンティックセグメンテーションにより実験を実施したところ、クラス間違い、物体の一部が欠けている、物体の一部のみが見えるといったケースにおいて精度が向上することを確認した。ヒントを繰り返し与えていくことはノイズとなってしまうためあまり精度が向上しなかった。 従来のディープラーニングは一度学習をしてしまうと得られる出力が固定されてしまうのに対して、人間が介入することで結果を変えるという新しい応用方法を提案している。
顔検出におけるターゲットドメインからソースドメインへのadaptationを、negative transferとcatastrophic forgettingの両方を引き起こさずに行う手法を提案。negative transferとはターゲットドメインに対する検出精度がadaptation後よりも前の方が良い場合を指しし、catastorophic forgettingとはadaption後におけるソースドメインの検出精度が著しく下がることを指す。提案手法では、ソースドメインとターゲットドメインの違いを、ロス関数とDNNの重みの差分で表現し、この差分がなくなるように学習を行う手法を提案。またターゲットドメインにface or notのラベルがないという状況も考えて教師あり学習だけでなく教師なし学習、半教師あり学習の結果についても議論を行った。
![]()
入力顔画像からバンプマップや視点を推定することで、入力画像からは見えていない側面や、強いオクルージョンがある顔画像からも精度の高い三次元形状を取得する手法を提案。 入力画像から帯域的な情報として三次元の大まかな形と、 局所的な情報としてしわなどのディティールを表現するバンプマップを別々のDNNモデルを使って取得する。 続いてオクルージョンがある場合には、バンプマップが不自然な起伏を持つため深層学習による修正を行う。 最後に顔の対称性を利用して、入力画像からは見えていない側面などをルールベースで復元する。
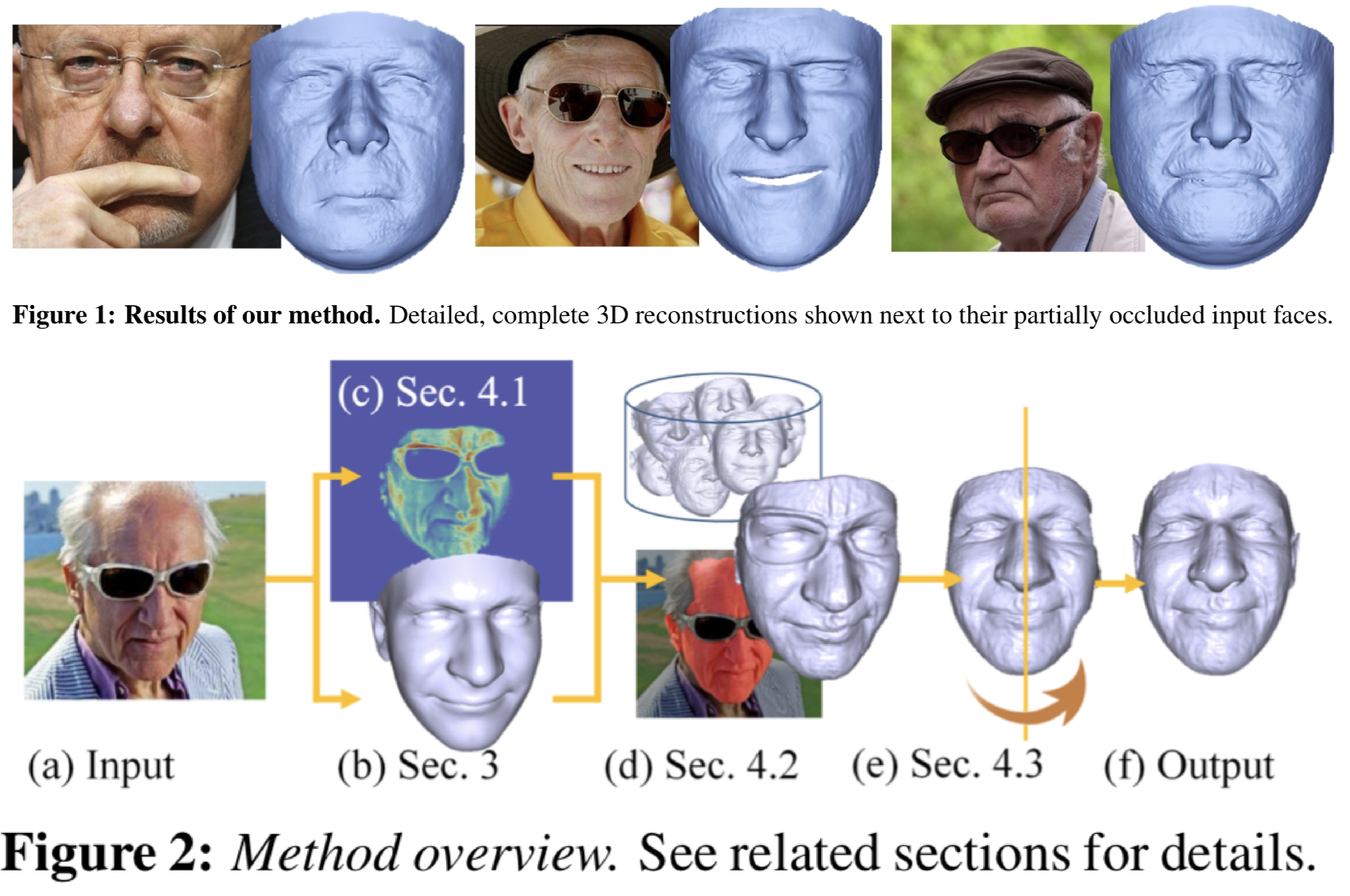
実世界の3D顔モデルを使用せず合成された3DモデルのみでCNNをトレーニングすることで、実世界の顔画像から顔向き、形、表情、リフレクタンス、イルミネーションの3D復元を行う手法を提案。 CNNをトレーニング際の問題点として、実世界の3D顔モデルに対するアノテーションが足りないという問題があった。 これに対して、実世界の顔画像から推定されるパラメタと合成顔から推定されるパラメタに対してself-supervised bootstrappingを行うことで、 トレーニングに使用する合成顔3Dモデルのパラメタの分布を実世界のパラメタの分布に近づくようにトレーニングデータを逐次的に更新を行うことで、 CNNの学習を行った。

様々な照明環境、表情をした横向き顔画像を入力として、正面顔画像を生成することで高い個人認証率を達成するGANベースのPose Invariant Model(PIM)というネットワークを提案。 学習で使用できるトレーニングデータが少ないため、効率的かつ過学習を防ぐために以下のようにPIMを構築。
DNNによって得られた特徴量を超球面上に配置するように正規化を行うロス関数であるRing lossを提案。特に教師あり識別問題においてはDNNによる特徴量を正規化することでより精度の高いモデルを構築することができる、 というアイディアもとにRing lossを提案。 SoftMaxといった基本的なロス関数と組み合わせることでより高い精度を達成。 実験には様々な識別タスクを行うことができる顔データセットを用いることで、精度の向上を確認した。

3Dモデルから実画像へのドメイン変換をGANによって行うことで、単一顔画像から照明パラメタを推定するLabel Denoising Adversarial Network(LDAN)を提案。 人の顔画像に対して照明パラメタ(論文で使用されているのは37次元の球面調和関数)がアノテーションされたデータセットがないため、 3Dモデルを使用してFeature Netと呼ばれるネットワークで中間特徴量を取得し、 中間特徴量からLightning Netを用いて照明パラメタの推定を学習。 続いて人の顔画像に対して、既存手法を用いてノイズが乗った照明パラメタを取得し、 人の顔画像に対してもFeature Netを新しく学習し、 3D モデルから得られた中間特徴量と共にGANに入力することでドメインの変換を行うことでノイズが除去された照明パラメタを取得。
顔向きをコンディションとして与え木構造で表された顔のランドマークを学習させることで、顔のランドマーク推定を行うPose Conditioned Dendritic CNN(PCD-CNN)を提案。 顔のコンディションはPoseNetにより出力された値を使用する。 顔のランドマークを木構造として与えることで、ランドマークの位置関係を利用してCNNを学習させた。 また提案ネットワークはPCD-CNNと通常のCNNの二段階になっており、 後段のCNNをファインチューニングすることでランドマークのポイント数が違うデータセットや顔向き推定などの他のタスクにも適用可能。
ノイズを考慮しつつ、数千もの画像セット全てにおいて一致する(信頼できる)特徴を見出すことで、画像間の対応を図るマッチング手法。マッチングはセマンティック性を考慮することができる(目と目、耳先と耳先など)これにより、一貫性がある画像セット内で信頼できる特徴の関係を確立。何千もの画像を処理する場合にスケーラブルな手法。つまりは数に頑健。

従来手法では、全てのペアで対応する関係を最適化していたが、本手法では、特徴の選択とラベリングに着目し、信頼度の高い特徴のみを用いた疎なセットのみで識別、マッチングする。
Intrinsic Image Decompositionのために,時間経過とともに照明が変化するビデオを使ったCNNの学習方法を提案.正解の Intrinsic Imageが不要な点が強みである.学習が完了したモデルは単一画像に対して適用できるよう汎化しており,いくつかのベンチマークに対して良い結果となった.
Contribution:
・データセット(BigTime)の公開.室内,室外両方での照明変化のあるビデオと画像シーケンスのデータセット.
・このGround Truthを含まないデータを使った手法の提案.
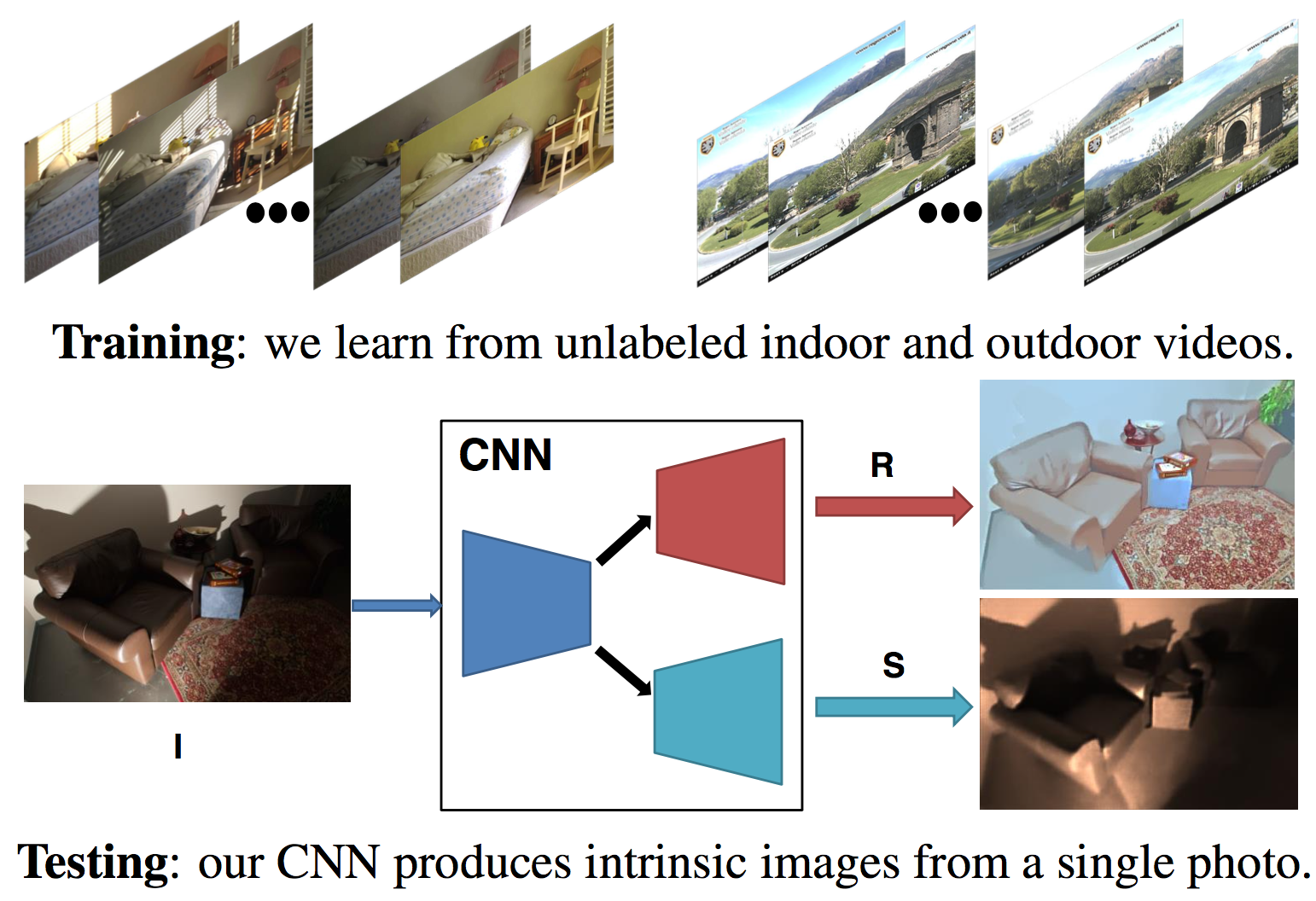
学習時:ラベル無しで,視点が固定され照明が変化するビデオを学習に利用する.
テスト時:単一画像からintrinsic image decompositionを行う.
最適化ベースのIntrinsic Decomposition手法と,機械学習手法の間に位置する手法と言える.
・U-netに似た構造のCNN.
・Lossの工夫:画像ペア全てを考慮するall-pairs weighted least squares lossとシーケンス全体のピクセル全てを考慮するdense, spatio-temporal smoothness loss.最適化ベースのlossをフィードフォワードネットワークのlossとして利用する.
Intrinsic image decompositionとは,入力された1枚の画像をreflectance画像とshading画像の積に分解する問題のこと.
intrinsic imagesのGround Truthを大規模に揃えることは困難.
階層的入れ子構造の識別器を使用し,テキストから高解像画像を生成するGANを提案.end-to-endの学習で高解像画像の統計量を直接モデルリングすることが可能な手法.これは,step-by-stepで高解像画像を生成するStackGANとは異なる点である.複数のスケールの中間層に対して階層的入れ子構造の識別器を使用することで中間サイズレベルでの表現に制約を加え,生成器が真の学習データの分布を獲得しやすくする.
新しい構造と,lossの工夫でtext-to-imageのタスクで高解像画像の生成を可能とした.
・hierarchical-nested Discriminatorを使用.
・lossには,pair lossとlocal adversarial lossを使用する.pair lossでは入力テキストと生成画像が一致しているかを評価.local adversarial lossでは生成画像の細部の質を評価する.
プライバシー保護のために画像に含まれる個人的な情報を自動的に改変する手法の提案.プライバシーを守りつつ画像の有用性を保つためのトレードオフが問題となる.有用性を保つためには改変する領域サイズが最小限である必要があり,これをセグメンテーションの問題として取り組む.
Contribution:
![]()
指紋,日時,人,顔,ナンバープレートを黒く塗りつぶせている.
他にも,住所やメールアドレスのようなテキスト情報や顔や車椅子などの視覚情報,あるいはテキストと視覚情報を合わせたものなど,多様な個人情報に対応するデータセットとモデルを提案.
どのような対象(Textual, Visual, Multimodal)を扱うかで使用するモデルは異なる.
Textualな対象では,Sequence Labelingを使用する.
VisualとMultimodalな対象では,Fully convolutional instance-aware semantic segmentationを使用する.
Nearest Neighborなどのベースライン手法と比較を行なっている.
画像全体を黒く塗ればプライバシーは保護されるが,画像の価値がなくなるので,トレードオフが存在する.
データセットを作った貢献がメイン.プライバシー保護のためのアノテーションを行ったことで,それなりの正解率で個人情報の改変を行えるようになった.
ノンパラメトリックのInapinting手法を提案.
視覚的な構造とスタイルをdeep embeddingすることで,パッチの検索と選択の際に視覚的なスタイルを考慮することが可能で,さらに,パッチのコンテンツを補完画像のスタイルに合わせるためのneural stylizationが可能となる.この手法は,patch-basedの手法とgenerativeベースの手法の架け橋的な補完手法である.
技術的貢献:
・style-aware optimization
・adaptive stylization
以下の手順で画像補完を行う.
1.スタイルを考慮して穴に埋める候補を検索する
2.補完画像と構造とスタイルが合うパッチをMRFで複数集め,選択する
3.選択されたパッチを補完画像のスタイルに変換する
motion deblurringのためのGAN(DeblurGAN)を提案.structural similarity measureとアピアランスでSoTA.ブラーを除去した画像で物体検出の精度を出すことで,ブラー除去モデルの質を評価するという方法を提案.提案手法は,質だけでなく実行速度も優れており,従来手法の5倍の速さがある.モーションブラーのかかった画像を合成するための方法を紹介し,そのデータセットもコード,モデルとともに公開.

ブレを除去してからYOLOで検出すると精度が良くなることを示している.これをDeblurモデルの指標にすることができると主張.
ボケ(blur)が望ましいのか否かと,そのボケが写真のクオリティーにどのような影響を与えているのかを,自動的に理解するアルゴリズムは少ない.この論文では,blur mapの推定とこのボケの望ましさの分類を同時に行うフレームワークを提案する.
貢献:

ボケ具合をピクセルごとに3段階で示し,ボケの望ましさも出力する.
ABC-FuseNetでは,低レベルのボケの推定と高レベルの画像内で重要コンテンツの理解の二つを行う.
A: attention map,FCNである.
B: blur map,Dilated Convolutionとpyramid pooling, Boundary Refinement用の層を使ってblurの推定を行う.
C: content feature map,ResNet-50を使ってコンテンツの特徴を抽出.
ボケの推定はBによって行い,ボケの望ましさの分類はA, B, Cから得られた特徴を用いて行う.ネットワーク全体をEnd-to-endで学習することができる.
指定された形状のタグに強く関係する領域を検出する手法の提案.明示的に領域ごとのラベリングはなく,さらにあらかじめセグメンテーションされていない状況で,形状のタグを与えた時に領域を発見するという問題設定.難しい点は,オブジェクトのタグという弱い教師情報からポイントごとのラベルを細かく出力する必要があること.このために分類とセグメンテーションを同時に行うネットワークを使う.形状ごとのタグからポイントごとの予測を得るためのネットワーク構造(WU-net)を提案したことがメインの貢献.
学習が完了すれば,タグが不明な形状に対しても手法を適用することができる.また,元々Weakly-supervised用に提案しているが,strongly-supervised用としても利用できる手法となった.
U-net風のWU-netを提案.U-netから修正した点は,
・浅いU型の構造を3回くりかし,skip-connectionで密に繋がっている.深いU型1回の場合との結果の違いを図示している.
・セグメンテーションの用の隠れ層にタグ分類用の層を追加.(元々のは,strongly-supervised セグメンテーション用に設計されているので.)
ニューラルネットワークに組み込むことができる3Dメッシュのレンダラーである Neural Renderer を提案。レンダリングの『逆伝播』と呼ばれる処理をニューラルネットワークに適した形に定義し直した.そしてこのレンダラーを
・一枚の画像からの3Dメッシュの再構成(ボクセルベースの再構成との比較あり)
・画像から3Dへのスタイル転移と3D版ディープドリーム
に応用できることを示した.

2D-to-3Dスタイルトランスファーの例
従来のままでレンダリングの操作が処理の途中にあると逆伝播が行えない状態であるので,レンダリングのための勾配を定義することでニューラルネットワークの中にレンダリング操作を加えても学習を行えるようにした.
商品などのデモンストレーションの映像の特徴を通してその商品などのアフォーダンスを推論する研究.映像から埋め込みベクトルを抜き出すことで,ヒートマップと行動のラベルとして特定のもののアフォーダンスを予測するDemo2Vecモデルを提案.また,YouTubeの製品レビュー動画を集め,ラベリングすることでOnline Product Review detaset for Affordande(OPRA)を構築.

アフォーダンスのヒートマップと行動のラベルの予測に関し,RNNの基準よりよいパフォーマンスを達成
YouTubeで公開されている動画では,Demo2Vecを用いてある物体のデモ動画からSawyer robotのEnd Effectorを予測したヒートマップの地点に移動するように制御させている様子を見ることができる.
葉に隠れていても3次元の枝構造を多視点画像から推測できるようにした。多視点からの植物画像を入力として枝構造の2次元確率マップをdropoutを取り入れたPix2Pixで推測して、それらから3次元の確率構造を作成した。最後にpartical flowシュミレーションによって明確な3次元の枝構造を生成した。
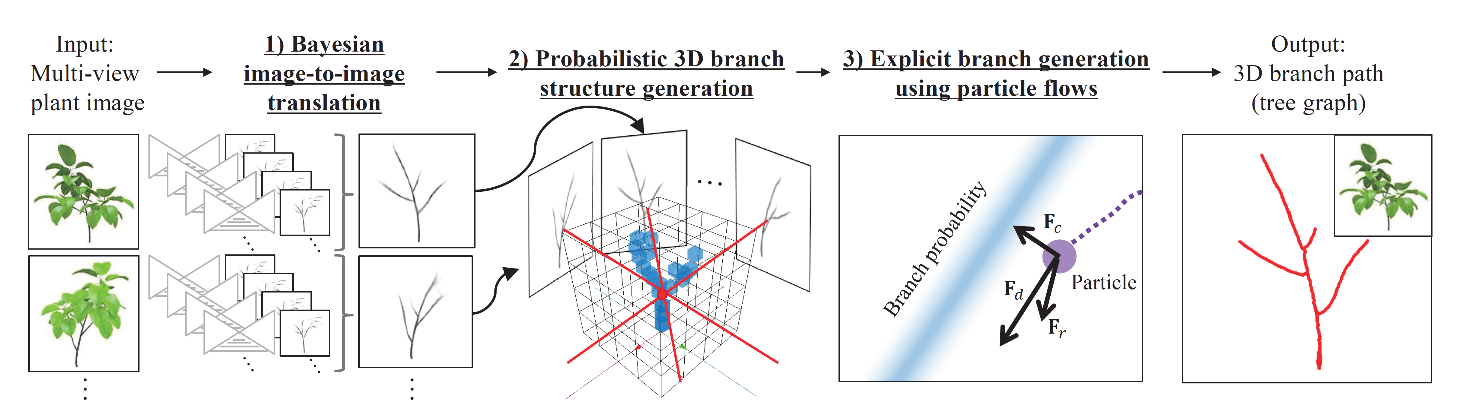
葉や他の枝によって隠れてしまっていても枝構造を生成できるようにした。ベイジアンPix2Pixを利用することで植物の3次元構造をより正確に表せるようにした。
synthetic-to-realな変換を行う際に、1)モデルがsyntheticにoverfitするstyleの側面と、2)syntheticとrealの分布の違いの側面から発生する2つの問題があることに著者らは着目している。解決するために、前者はtarget guided distillation、後者はspatial-aware adaptationという手法を提案し、それを組み合わせた Reality Oriented ADaptation Network(ROAD-Net)を考案。GTAV/SYNTHIA - Cityscapesの適合タスクで評価し、sotaのsemantic segmentationモデルの汎化性能を向上したことを確認。
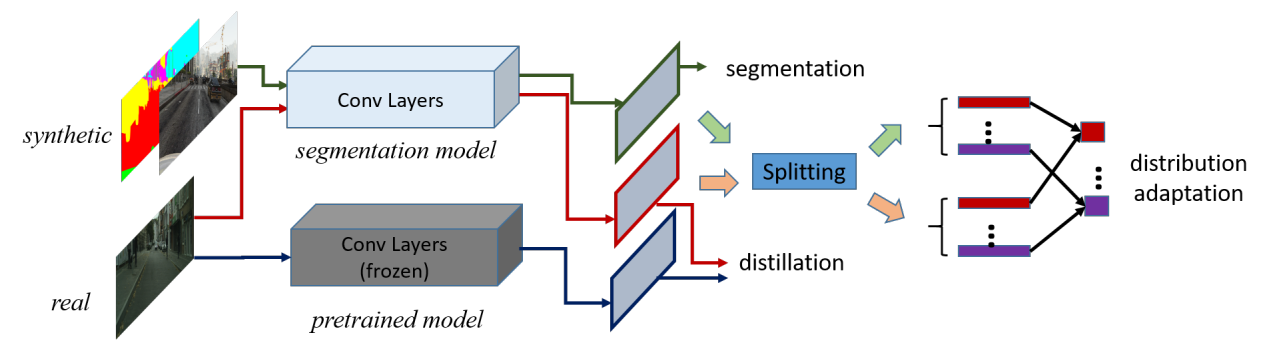
霧がかかった画像(hazy input)から更に3つの入力,White balanced input,Contrast enhanced input,Gamma corrected inputを計算して導出し,これらの異なる入力間の外観差に基づきピクセル単位のConfidence Mapを計算する.これらを学習することで鮮明な画像を生成するMulti-scale Gated Fusion Network(GFN)を開発した.

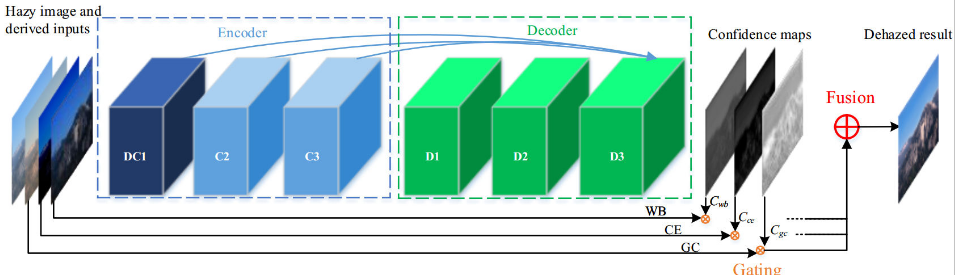
従来手法と比較し,実装や再現が容易であり,また出力結果もPSNR,SSIMともに従来手法より高い評価となっている.
教師あり深層学習による手法は単眼カメラ画像における深さ推定に対して良い結果を出している.しかし.grand truthを得るためにはノイズに影響され,コストもかかる.合成データセットを用いた場合の深度推定では固有のドメインにしか対応していなく,自然なシーンに対して対応するのが難しいと言われる.この問題に対応するため,Adversalな学習と対応したターゲットの明確な一貫性をかすこと事によりAdaDepthを提案.
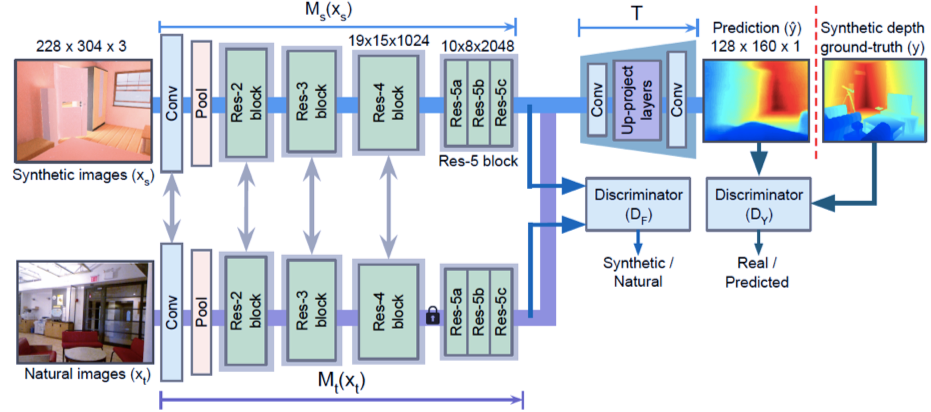
End-to-Endで3次元空間における特徴点の抽出とマッチングを行う手法を提案した。2つの距離画像を入力とし、VGG-16 を利用したFaster R-CNNを基本構造としている。 2つの距離画像からそれぞれVGG−16を利用して特徴マップを作成し、RPNにより領域候補を推定して、ROIプーリング層、全結合層を経て特徴量ベクトルを作り出す。最終的にcontrastive lossを利用して得られた特徴量間の対応関係を求めた。
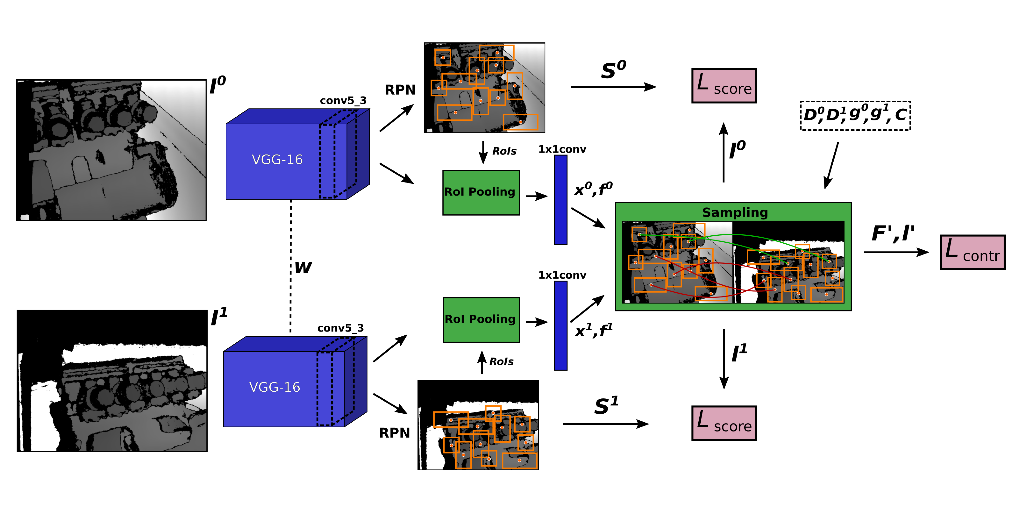
初めてEnd-to-Endで3次元マッチングを行えるようにした。ノイズ環境下においてキーポイントマッチングで従来手法のHarris3D +FPFHなどよりも10%以上高い精度を出した。
アテンションドリブン,複数ステージでのRefineによって,テキストから詳細な画像を生成するGANを提案.CUBデータセットとCOCOデータセットでinception scoreがstate of the artを超えた.生成画像の特定の位置をワードレベルで条件付けしていることを示した.
貢献:
・Attentional Generative Adversarial NetworkとDeep Attentional Multimodal Similarity Model(DAMSM)の提案.
・実験でstate-of-the-art GAN modelsを超えたことを示す.
・ワードレベルで自動的に生成画像の一部をアテンションするのは初である.

・Attentional Generative Networkはセンテンスの特徴から始めて段階的に画像を高精細にしていくネットワークで,途中にアテンションレイヤーからのワード特徴を入力して条件付けする.
・各解像度に対してそれぞれDiscriminatorがある.
・最終的な解像度になったあと,Image Encoderにて局所的な画像特徴量とし,ワード特徴量とDAMSMにて比較することで,生成画像の細部がどれくらい単語に忠実であるか評価する.
SBADA-GANの提案.(Symmetric Bi-Directional ADAptive Generative Adversarial Network)
unsupervised cross domain classificationにフォーカス.
ラベルが与えられるSourceのサンプルを利用して,最終的にはTargetの分類問題を解く.SourceのサンプルをTargetのドメインに(Image-to-Imageの)マッピングをし,同時に逆方向も行う.分類器の学習に利用するのは,Sourceサンプル,TargetをSource風にしたもの,SourceをTarget風にしてさらにSource風に戻した3種類を使う.それぞれにラベルもしくは擬似ラベルを付与して学習する.テスト時はTargetサンプルのクラスを予測したいので,Target用の分類器と,TargetサンプルをSource風にしてから入力するSource用の分類器の2つを使用する.
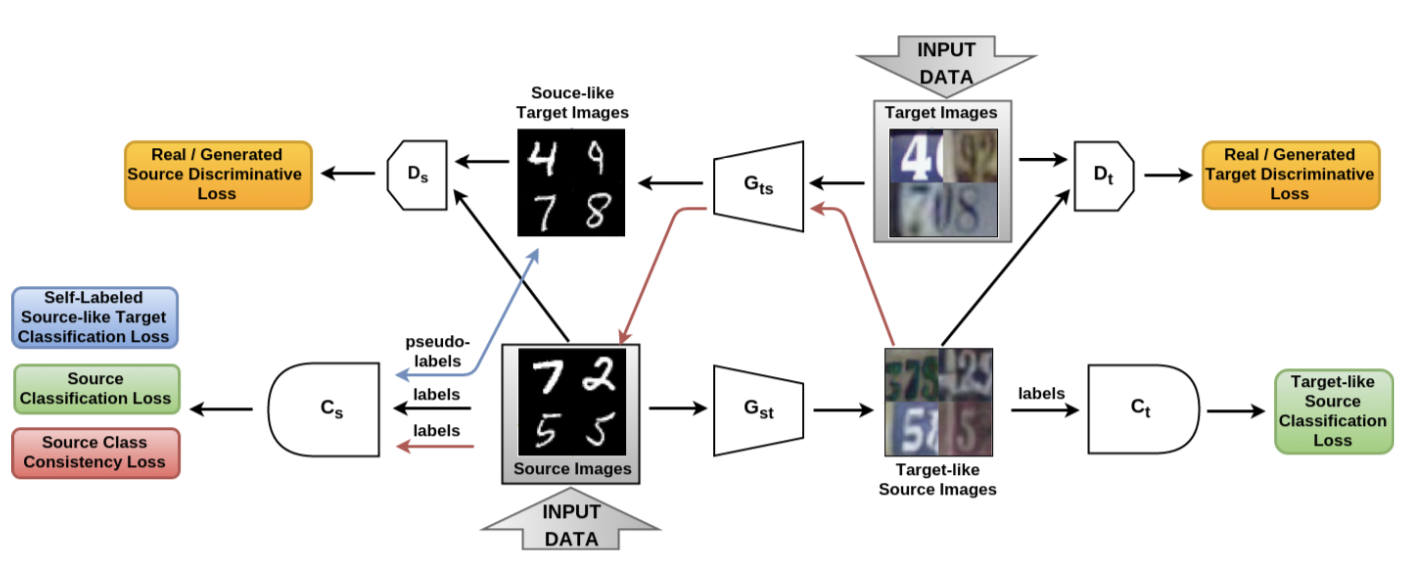
学習ベースで画像のエンハンスメントを行う手法の提案.入力として「良い」写真のセットを使う.このセットに含まれる特色を持つように変換することが「エンハンスメント」に繋がると定義する.エンハンスメント問題をimage-to-imageの問題として扱い,提案手法は「良い」写真のセットの中で共通の特色を発見することを狙っている.普通の写真のドメインを「良い」写真のドメインに変換すれば良いとし,(CycleGANのような)2方向GANを以下の3つの工夫とともに利用する.

Wikipediaのようにノイズの多いテキストからzero-shot learningを行うためのGAN用いる方法を提案.GANを使ってテキストが表現するオブジェクトのビジュアル的な特徴を生成する.オブジェクトのクラスごとに特徴を近い位置にembeddingできれば良い.これができれば後は教師あり手法で分類を行えることになる.
コントリビューション:
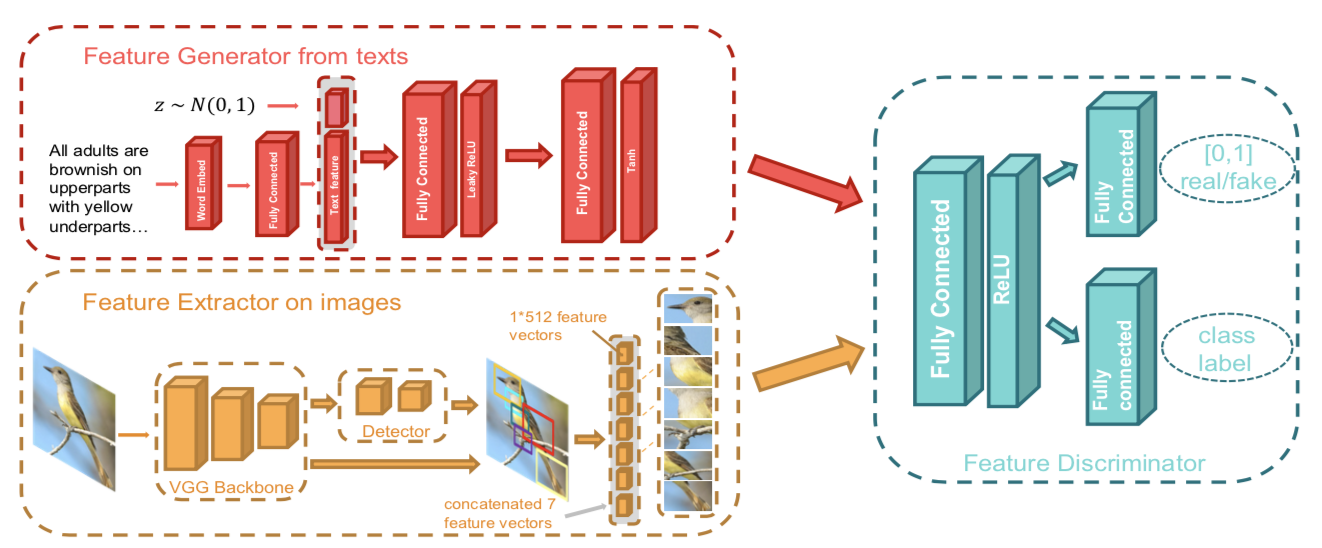
左上段がFakeデータを作るストリーム.左下段がRealデータを作るストリーム.
Unseenクラスについてのノイズを含むテキスト記述を入力とし,このクラスのvisual featureを生成するGANを提案.テキストから生成されるvisual featureをFakeデータとし,真の画像から得られるvisual featureをRealデータとしてGANを学習.
教師不要でコンテンツとモーションという要素に分解し,ビデオを生成するGANを提案.コンテンツを固定しモーションのみ変化させることや,逆も可能.広範囲の実験を行い,量と質ともにSoTAであることを確認.人の服装とモーションの分離や,顔のアイデンティティーと表情の分離が可能であることを示している.
Contribution:・ノイズからビデオを生成する,条件なしでのビデオ生成GANの提案. ・従来手法では不可能である,コンテンツとモーションのコントロールが可能なこと ・従来のSoTA手法との比較

言語的な文脈の中で指示語からそれが何であるかを特定する問題(Visual Grounding; 「それを取ってください」の「それ」を動画中から探索するなど)を扱う論文である。この問題に対してMIL(Multiple Instance Learning)を参考にした弱教師付き学習であるReference-aware MIL(RA-MIL)を用いて解決する。
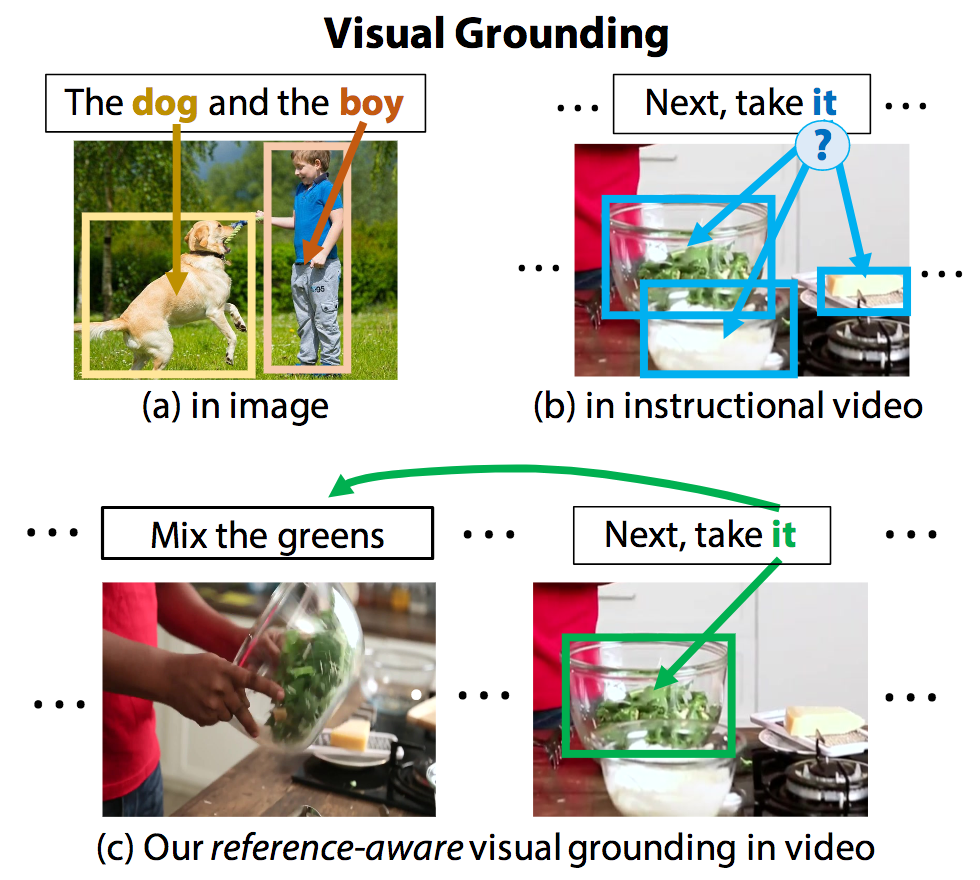
画像に対するVisual Groundingが空間的な関係性を捉えるのに対して、Visual Groundingは時間的な関係性を捉える課題である。YouCookII/RoboWatch datasetにて処理を行った結果、弱教師付き学習であるRA-MILを適用するとVisual Groundingに対して精度向上することを明らかにした。
Language and Visionの課題はすでに動画にまで及んでいる。Visual Groundingのみならず、新規問題設定を試みた論文として精読してもよいかも?それと視覚と言語のサーベイ論文は読んでみたい
ブロック単位でのアーキテクチャ生成手法であるBlockQNNを提案。Q学習(Q-Learning)を参考にして高精度なニューラルネットを探索的(ここではEpsilon-Greedy Exploration Strategyと呼称)に生成する。基本的には生成したブロックを積み上げることによりアーキテクチャを生成するが、早期棄却の枠組みも設けることで探索を効率化している。
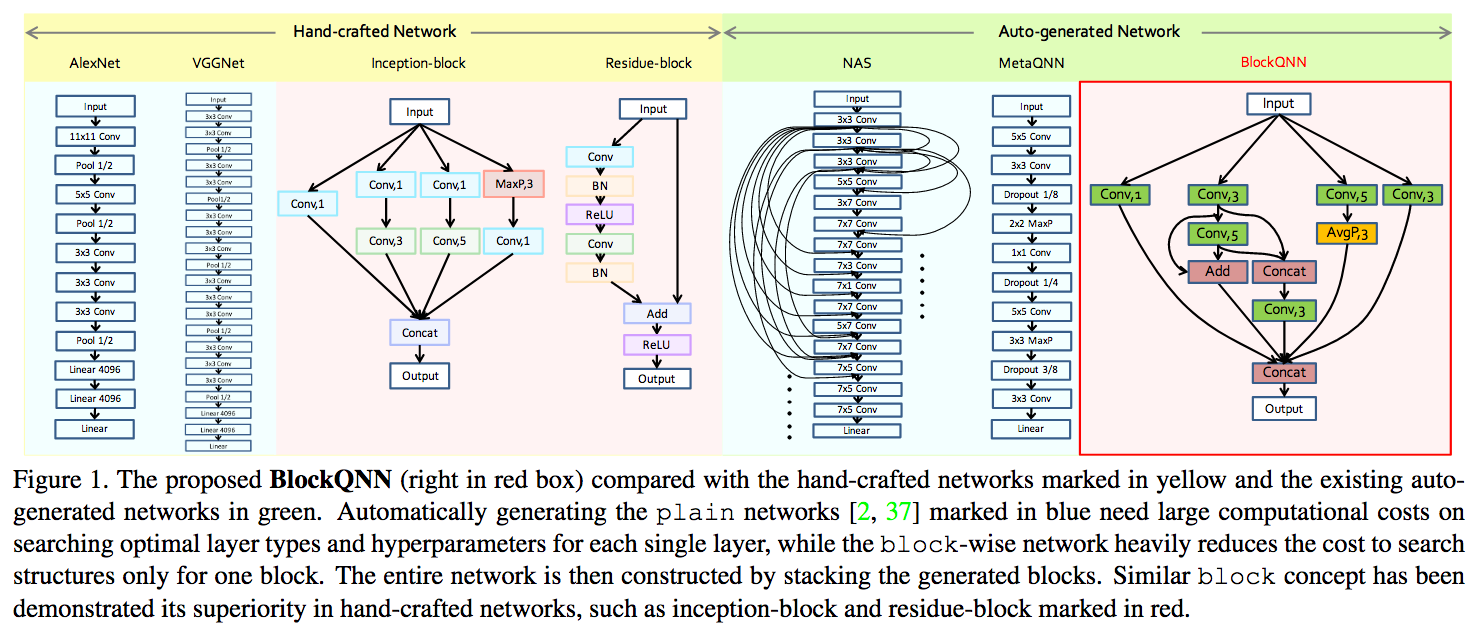
ブロック単位でニューラルネットのアーキテクチャを探索するBlockQNNを提案した。同枠組みはHand-craftedなアーキテクチャに近い精度を出しており(CIFAR-10のtop-1エラー率で3.54)、探索空間を削減(32GPUを3日間使用するのみ!)、さらに生成した構造はCIFARのみならずImageNetでも同様に高精度を出すことを明らかにした。ネットワーク構造の探索問題においてブロックに着目し、性能を向上させると同時に同様の枠組みを複数のデータセットにて成功させる枠組みを提案したことが、CVPRに採択された基準である。
低解像画像から高解像画像(SR; super-resolution image)を復元するための研究で、DenseNet(論文中の参考文献7)を参考にしたResidual Dense Networks (RDN)を提案して同課題にとりくんだ。異なる劣化特徴をとらえたモデルであること、連続的メモリ構造(Contiguous Memory Mechanism)やコネクションを効果的にするResidual Dense Blockを提案したこと、Global Feature Fusionにより各階層から総合的な特徴表現、を行い高解像画像を復元した。DenseNetで提案されているDense Blockと比較すると、提案のResidual Dense Blockは入力チャネルからもスキップコネクションが導入されているため、よりSRの問題設定に沿ったモデルになったと言える。
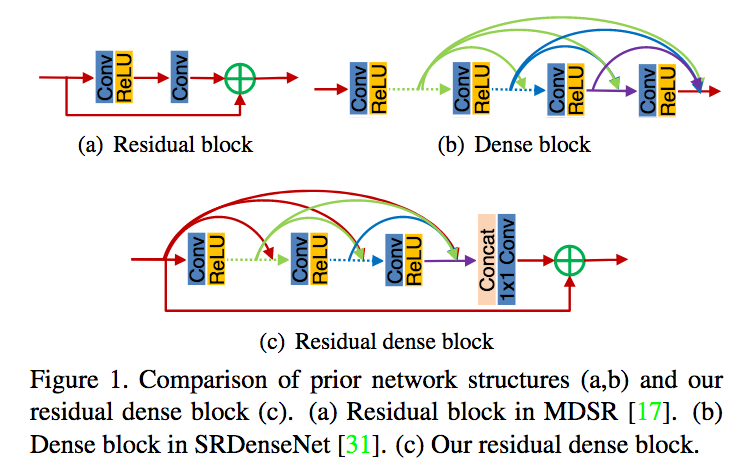
高解像画像を復元するための改善として、DenseNetを改良したRDNを提案した。Dense Blockを置き換え、より問題に特化したResidual Dense Blockを適用。実験で使用した全てのデータセット(Set5, Set14, B100, Urban100, Manga109)の全てのスケール(x2, x3, x4)にて従来手法よりも良好なAverage PSNR/SSIMを記録した。結果画像はGitHubのページなどを参照されたい。
現在でもチャレンジングな課題として位置付けられる人物に対する3次元姿勢推定に関する研究で、Adversarial Learning (AL)を用いて学習を実施。問題設定としては「多量の」2次元姿勢アノテーション+「少量の」3次元姿勢アノテーションを使用することで、新規環境にて3次元姿勢推定を実行することである。本論文で提案するALではG(生成器)として、2D/3Dのデータセットからそれぞれ2D/3Dの姿勢を推定、実際のデータセットからアノテーションを参照(リアル)して、生成されたものか、データセットのアノテーションなのかを判断(D; 識別器)させることで学習する。G側の姿勢推定ではHourglassによるConv-Deconvモデルを採用、D側には3つの対象ドメイン(オリジナルDB、関節間の相対的位置、2D姿勢位置と距離情報)を入れ込んだMulti-Source Discriminatorを適用する。
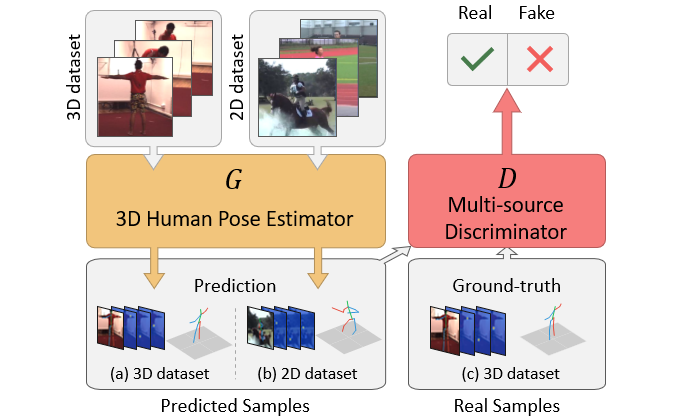
GANに端を発する敵対的学習を用いて、3次元姿勢に関するアノテーションが少ない場合でもドメイン依存をすることなく3次元姿勢推定を可能にする技術を提案した。また、もう一つの新規性としてドメインに関する事前知識を識別器に入れ込んでおくmulti-source discriminatorについても提案した。
手部領域に着目してチャネルを追加することにより、ジェスチャ認識自体の精度を高めていくという取り組み。従来型のマルチチャネル(rgb, depth, flow)のネットワークでは限定的な領域を評価して特徴評価を行なっていたが、提案のFOANetでは注目領域(global, right hand, left hand)に対して分割されたチャネルの特徴を用いて特徴評価を行い識別を実施する。図に示すアーキテクチャがFOANetである。FOANetでは12のチャネルを別々に処理・統合し、統合を行うネットワークを通り抜けて識別を実施する。
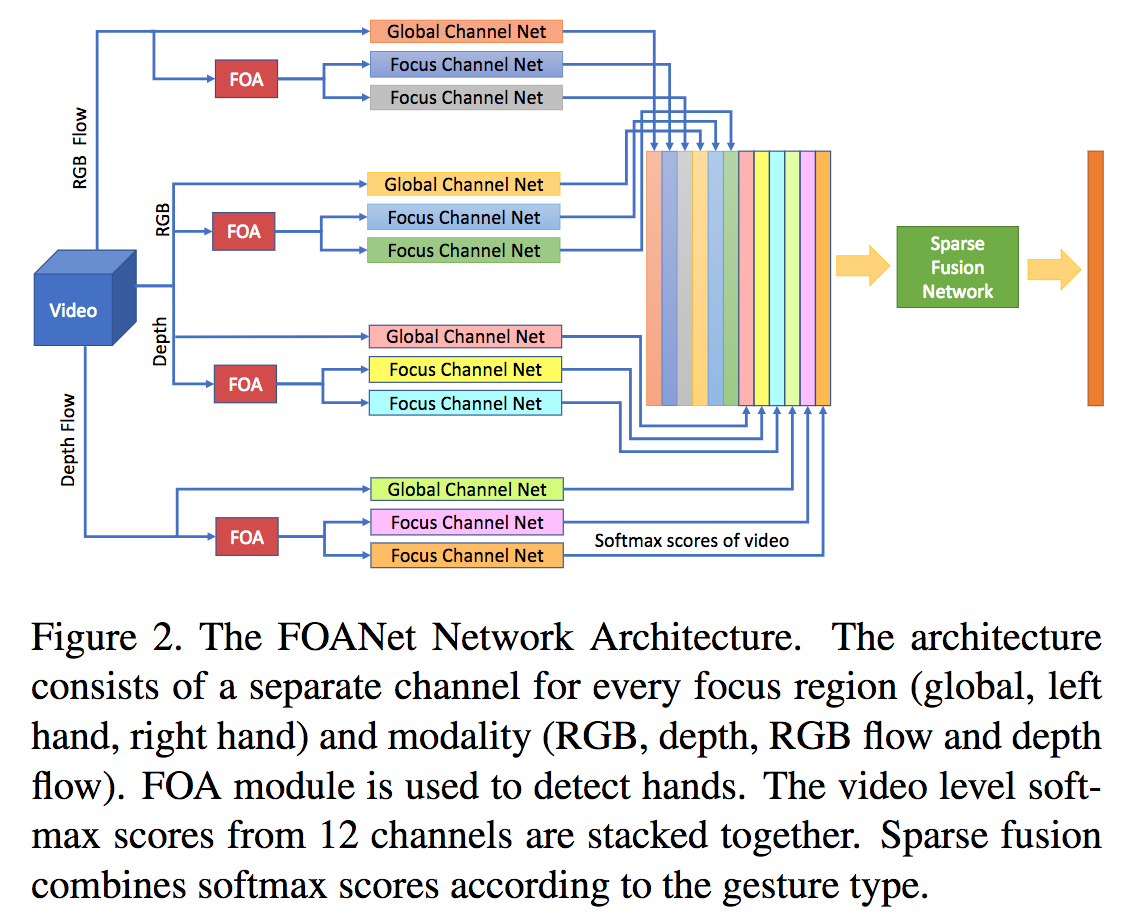
手部領域に着目し、よりよい特徴量として追加できないか検討した、とういアイディア自体が面白い。また、ChaLearn IsoGD datasetの精度を従来の67.71%から82.07まで引き上げたのと、同じようにNVIDIA datasetに対しても83.8%から91.28%に引き上げた。
あまりメジャーに使用されているDBではないが、重要課題を見つけてアプローチする研究は今後さらに必要になってくる?一番最初に問題を解いた人ではないが、二番目に研究をして実利用まで一気に近づけられる人も重宝される。
顔のアライメントにおいて,Direct shape regression networkを提案.いくつかの新しい構造を組み合わせている.(1)二重Conv, (2)フーリエ特徴プーリング, (3)線形低ランク学習. 顔画像-顔形状間の高い非線形関係性(初期化への強い依存性,ランドマーク相関導出の失敗)の問題を解決する.
coarse-to-filneに単画像デブラーリングする,Scale-recurrent Network (SRN-DeblurNet)を提案.
構造的には,(1)入出力がピラミッド画像, (2)中間はUnet, (3)最終層の出力を第1層に注入(Recurrent)し,ピラミッド画像の枚数分実行.
従来のCNNの構造では基本的に決められた方向へのみのforwardを行うのに対して、すべてのレイヤー間で結合を持つClique blockで構成されるClique Netの提案。CIFAR-10でSoTA、その他ImangeNetやSVHNでも少ないパラメータでSoTAに匹敵する精度を記録。
Clique blockでは以下のような処理が行われる。
DenseNetの拡張に近い構造のため妥当性があり、実際に精度が出ている点が強い。
合成画像のペア間のフローと教師ラベルのない実画像のペア間のデプスを推定することによってシーン認識、行動認識のための表現学習を行う研究。フロー推定を行ったのち、デプス推定にfine-tuningし、さらに目的となるタスクにfine-tuningする。 直感的には、低レベルな特徴が獲得されそうだが、行動認識などの高次な問題設定でも効果を発揮した。
多段にfine-tuningするため、初期の問題設定によって獲得した特徴が失われてしまう可能性があるので、2段目のfine-tuning時にはfine-tuning前の出力結果への蒸留を同時に行う。ImageNetのpretrainingとも行動認識において補間的な関係がある。表現学習自体での使用データが少ないのに関わらず高い精度向上が実験的に示されたことが大きなcontributionだと考えられる。
特徴のforgetを防ぐ手法は、複数のタスクで学習済みモデルを作成する際に、その順番が重要となるような状況で有用だと思われる。既存手法との比較においては今回は+αのデータを利用している点はフェアではないと感じた。 また、目的のタスクへのfine-tuningの際のフレームペアの選び方などの詳細な設定が記されていなかった。主に精度評価のみで、高次なタスクでうまくいく考察が少なく、疑問もあった。
メタ学習を用いたFew-shot learningの新しい枠組み,Relation Networkの提案.一度学習されれば,ネットワークのアップデートの必要なしに新しいクラスの画像分類ができるようになる.
1エピソードにおける少数の画像の比較によって距離メトリックを学習するメタラーニングを行う.少数の新クラスの代表画像群とクエリ画像の関連性スコアの比較により,追加学習なしに新クラス画像分類が行える.
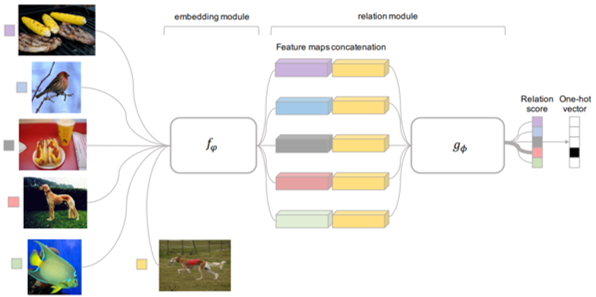
画像における深度予測はCV分野において基本的なタスクである.既存の手法は学習データによる制約が伴う.今回提案する手法では,インターネットの画像をデータセットとするMVSの手法を改良し,既存の3D reconstructionとsemantic ラベルを組みわせて大規模な深度予測モデルであるMegaDepthを提案.
リアルタイムで顔の回転に頑健な顔検出を行うProgressive Calibration Network(PCN)を提案。PCNは3つのステージで構成されており、それぞれのステージでは検出された領域を0° or 180°回転させる、 0° or 90° or -90°回転させる、頭が上にくるように顔を回転させる、という処理をそれぞれ行う。 また各ステージ共通で検出された領域が顔であるか顔でないかという識別を行う。第1,2ステージで粗く回転を行うことで第3ステージにおける回転量と、 各ステージにおける顔識別の学習が容易になったことで、高精度かつリアルタイムに顔検出を行うことが可能となった。

顔のアトリビュート推定に有効なネットワークであるPS-MCNN/-LCを提案。従来手法のMCNNでは、類似度の高いアトリビュートの識別率を高めるために、 類似度の高いアトリビュートのごとにグループを形成し、MCNNの高い層では各グループごとにCNNを形成して学習を行なっていた。 そのため低い層で得られていた特徴量が消失するという問題が起きていた。 これを解決するために、MCNNに対して各レベルで得られた特徴量を教諭するShared Netを導入したPS-MCNNを提案。 また同一人物において推定されたアトリビュート同士のロスをとるPS-MCNN-LCも提案した。 ネットワークの構築に関する議論も行なっている。
顔に対してセマンティックセグメンテーション(face sparsing)を利用することで、モーションブラーが加えられた正面顔画像に対するCNNベースのデブラーリング手法を提案。 face sparsingによって顔のパーツの位置関係や形といった情報を利用することができると主張。 また学習の際には様々なカーネルサイズによるブラー画像を同時に与えるのではなく、 小さなカーネルサイズのブラー画像から順々に学習させるincremental trainingことでデブラーリング精度を向上させた。
Semantic Segmentationに関するDomain Adaptationの研究。Semantic Segmentationをsource domainとtarget domain間の空間的な類似性を持つ構造的な出力として考え、出力空間(prediction map)でのDomain Adaptationを行う敵対的学習手法を提案。低次特徴は利用せず、高次特徴のみを複数のDiscriminatorにより異なる空間解像度ごとに適応させる(Multi-level Adversarial Learning)。実験ではsynthetic-to-realとcross-cityでの比較を行っている。
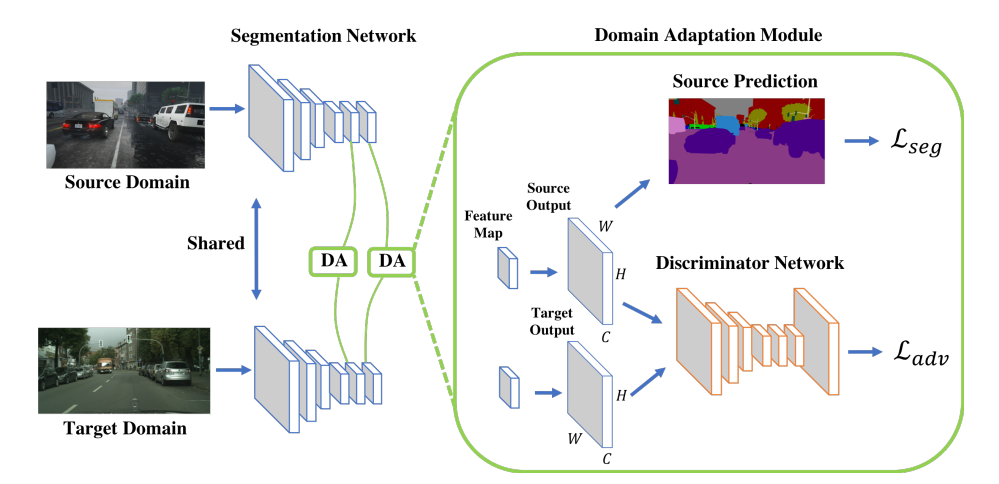
画像分類タスクを中心に発展していたDomain Adaptationを画素単位の構造予測が必要なSemantic Segmentationに適用した点。
Semantic Segmentationに限らず構造予測をするタスクへも容易に拡張ができる。
画像分類と比較して、アノテーションの労力がかかるため実用性・将来性がある。
学習時のタスクごとの重みによって精度がかなり変化する。そこでNNのマルチタスクモデルにおいて各出力を分布表現にし、その同時確率を最尤推定するように学習することで結果的にタスクごとの不確実性を考慮した重み付けを損失関数に課す。実験ではSemantic Segmentation, Instance Segmentation, Depth estimationのマルチタスク学習を行い、等しい重みや手動での重み設計時よりも良い結果となった。
モデルから各タスクに対して不確実性を表す値を同時に出力させる。回帰タスクの場合はこれが分散を表し、最終的には回帰出力値を平均とするガウス分布として表現する。識別タスクについては不確実性が分布の温度パラメータとして扱われる。これらの同時確率を最尤推定すると、通常の損失に対してタスクごとに適応的に重み付けされた損失を最適化していることになる。理論的にも妥当であり、精度向上は大きくチューニングの手間が省けるという点でかなり便利である。
簡単な実装でハイパーパラメータが減るという点でかなり有用に感じた。様々なマルチタスクで行った訳ではないのでこの手法の汎用性がきになる。結局、識別の場合は通常でも不確実性は考慮しているので、本質的に新しいのは回帰の場合である。
2つの画像間で最も顕著な違いは表せられるがその他の細かい違いは示されないことが多い.それに対して,より多くの違いによって画像を比較できるようなモデルの構築をした.また,そのモデルを使って,UT-Zap50K shoesとthe LFW10のデータセットを用いて評価したところSoTAであった.構築したモデルを画像記述と画像検索に導入し,拡張を図った.
画像修正検出.修正箇所をちゃんと注目すべきで,リッチな特徴の学習が必要.修正後画像から修正領域を検出するtwo-stream Faster R-CNNを提案. RGB stream:コントラスト差,不自然境界とかを捉える.Noise stream:ノイズの非一貫性を捉える.Steganalysis Rich Modelでとれたノイズ特徴に基づく. そして,両者のバイリニアプーリングで共起性を捉える.
1枚のRGB画像から物体の6次元姿勢を推定する研究. CNN を用いた単一のネットワーク (YOLO v2 ベース) で RGB 画像から物体の 3D bounding box を直接推定する. post-process 無しで高精度な姿勢推定が可能なため, 実時間(従来手法の約5倍速)で従来手法と同程度の推定精度を達成した.
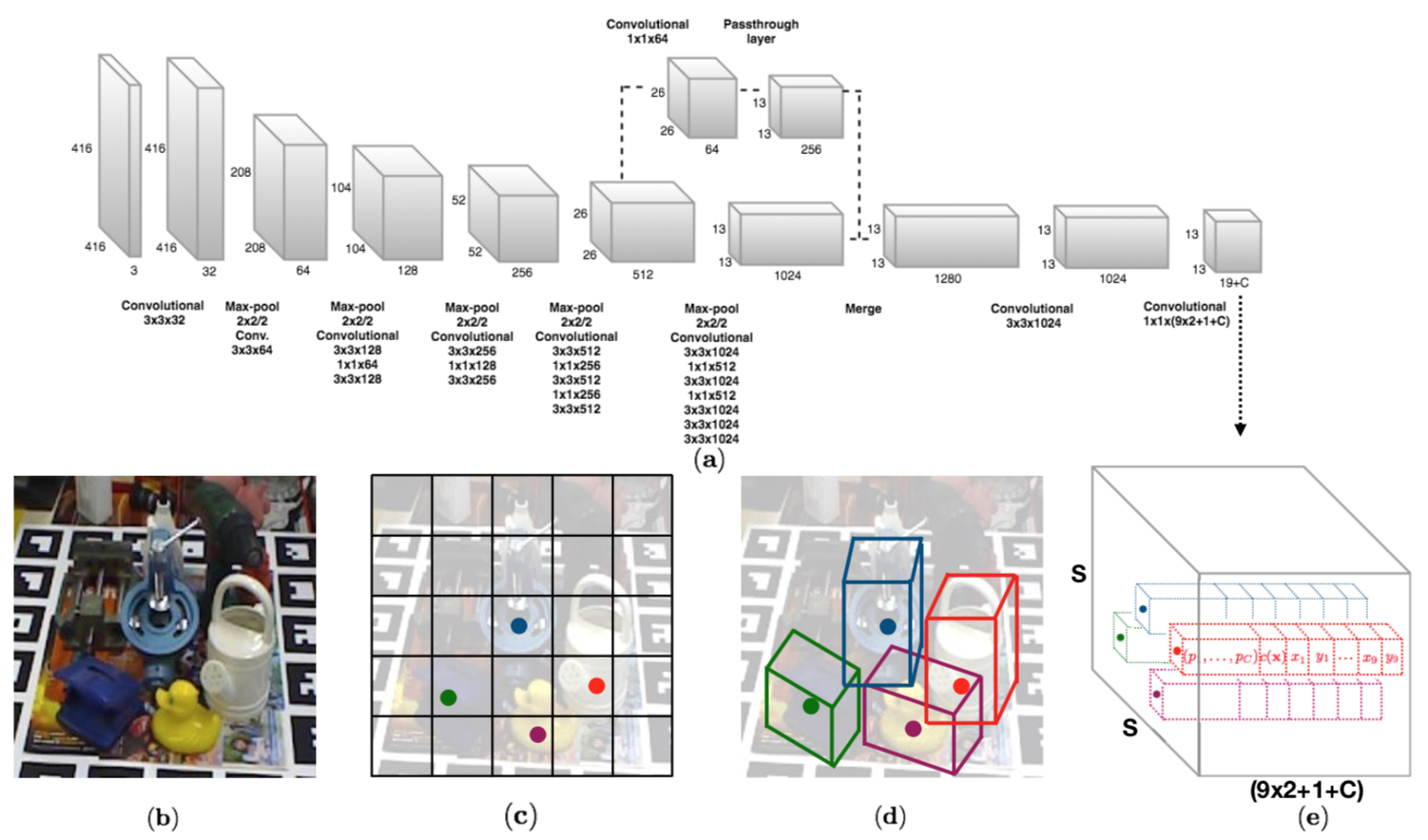
Video captioning のための階層型強化学習フレームワークを提案. Caption を複数のセグメントに分割し, High-level の Manager Module が各セグメントのコンテキストをデザインし, Low-level の Worker Modeule が単語を生成することで順次セグメントを作成する. 提案手法は MSR-VTT データセット を用いた評価実験で既存手法よりも複数の評価尺度で良い結果となった. また, video captioning のための新しい大規模データセットを公開.
1枚のRGB画像から物体の形状とカメラ姿勢の両方を推定する研究. 異なる視点から見たときの一貫性(具体的には物体の輪郭または深度情報の一貫性)を教師情報として用いるため, 従来手法と異なり学習時に物体の3次元形状と姿勢のいずれについても直接の教師データも必要としない.
CNNに対して中間的に法線方向推定と輪郭推定も加えることで最終的にdepth推定とscene parsingの精度を向上させる。法線方向と輪郭についてはdepthとscene parsingのラベルから計算可能であるので追加にアノテーションする必要はない。 NYUD-v2とCityscapesにおいてSoTA。
中間的に推定した結果を元に最終的な目的タスクを出力するが、その中間出力として3つのパターンを考えた(タスクをに分けずconcat, タスクごとにconcat, attention機構を取り入れたconcat)。 attention機構を取り入れたconcatが最も良い結果となった。シンプルな手法だが、実験結果が良いので評価されたと考えられる。
「distillation」という言葉を用いているが、生徒モデルと教師モデルがあるようなdistillation手法は使われておらず、単に複数の中間タスクからのMulti-modalな情報の統合に対してその言葉が使用されている。 単に通常のマルチタスク推定に中間タスクを導入したのみでかなりシンプルな印象。
時空間的な特徴を捉えて、長期のモーション予測を行う研究である(ここではいかに最初の限られた情報量のみでシーケンスを推定できるかどうかについて検証を行なっている)。この課題に対し、Convolutional Long-term Encoderを用いてより長期的な隠れ変数をデコーダにより推定する。このエンコーダ-デコーダ構造にて短期〜より長期的な変数の予測を可能にする。本手法では主にRNNベースのSequence-to-SequenceなモデルにConvolutionalな要素を加えたことが技術的発展であると主張。
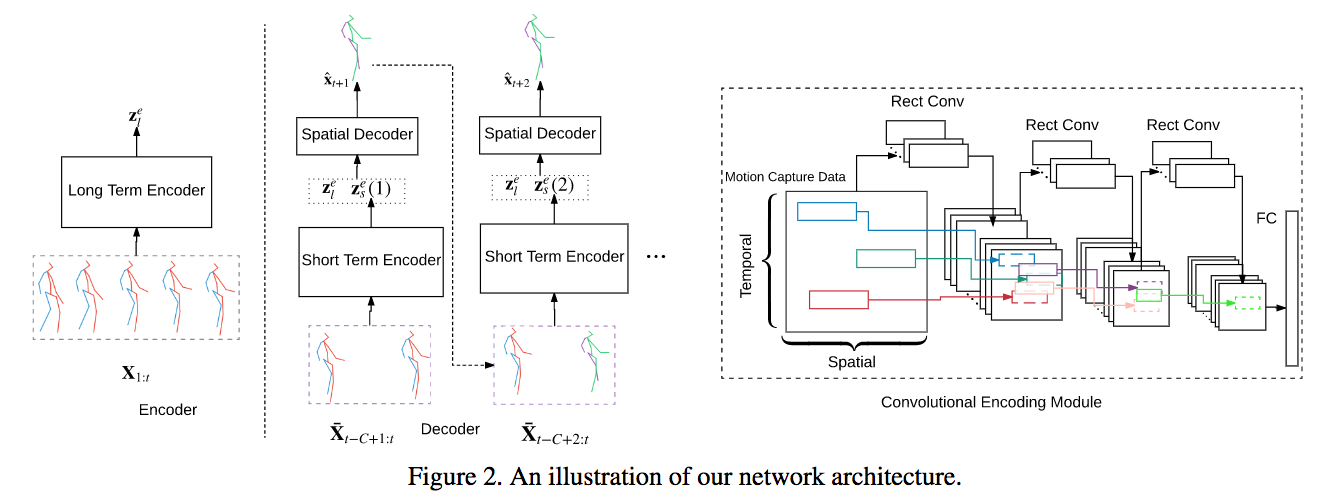
より長期の(といっても数秒間のシーケンス?)人物モーション予測(ここでは人物姿勢位置を予測)を実現したことが課題設定として大きい。手法としてはConvolutional Long-term Encoderやその抽象化された特徴をデコーダにより長期隠れ変数を推定。Human3.6MやCMU Motion Capture datasetにて高い精度を実現した。
Convolutional Pose Machine (CPM)のCNN部分を再帰的ネットであるLSTM (Long-short term memory)により置き換えた人物姿勢推定手法。時系列的に連続するフレーム(e.g. t, t+1, t+2)の入力に対して処理を実行し姿勢を推定する。CPMとは基本となるアーキテクチャの考え方(multi-stage algorithm)は同様であるが、それぞれのステージ間でパラメータを共有している点で異なる。
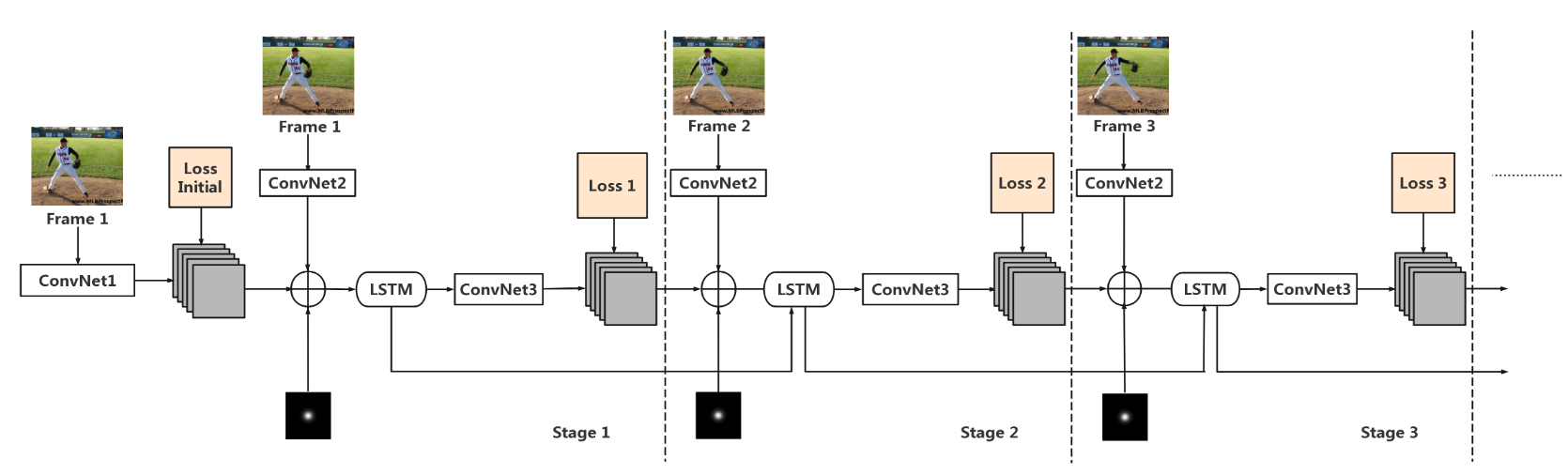
CPMと同じmulti-stageの姿勢推定学習を、LSTMの構造にて実現したことが技術的なポイントである。さらに、CPMとは異なりステージ間でパラメータを共有することで精度向上が見られたと説明。Penn Action datasetやJHMDB datasetにて最高精度を叩き出した。JHMDBにて93.6@PCK(=0.2)、Penn Actionにて97.7@PCK(=0.2)を記録。さらに、各フレーム時のメモリチャンネルの挙動も可視化し、どのような際に成功するか/失敗するかを明らかにした。複雑姿勢(複雑背景?)の際にはエッジに着目していて、姿勢推定が成功する際にはピンポイントで関節位置を回帰する傾向にある。処理速度の面においても本論文の技術では25.6msで動作した(CPMは48.4ms)。
混雑時の人数カウントにおける問題点を解決するため、End-to-Endで学習可能なDecideNet(DEteCtIon and Density Estimation Network)を提案する。混雑時の人数カウントでは、従来(1)人物検出では認識ミスによる過不足によりカウントを誤ってしまう、(2)回帰ベースの手法では人物が存在しない領域が蓄積されると実際のカウントよりも多く集計されてしまう、という問題が存在した。DecideNetでは検出ベース/回帰ベースを別々に行い、それらの結果を総合してカウントを行うという点で従来法を解決していると言える。実験では本論文で提案のDecideNetが混雑時の人数カウントにおいてもっとも優れた精度を達成したと主張。検出/回帰の手法としてはFaster R-CNN/RegNetを適用している。
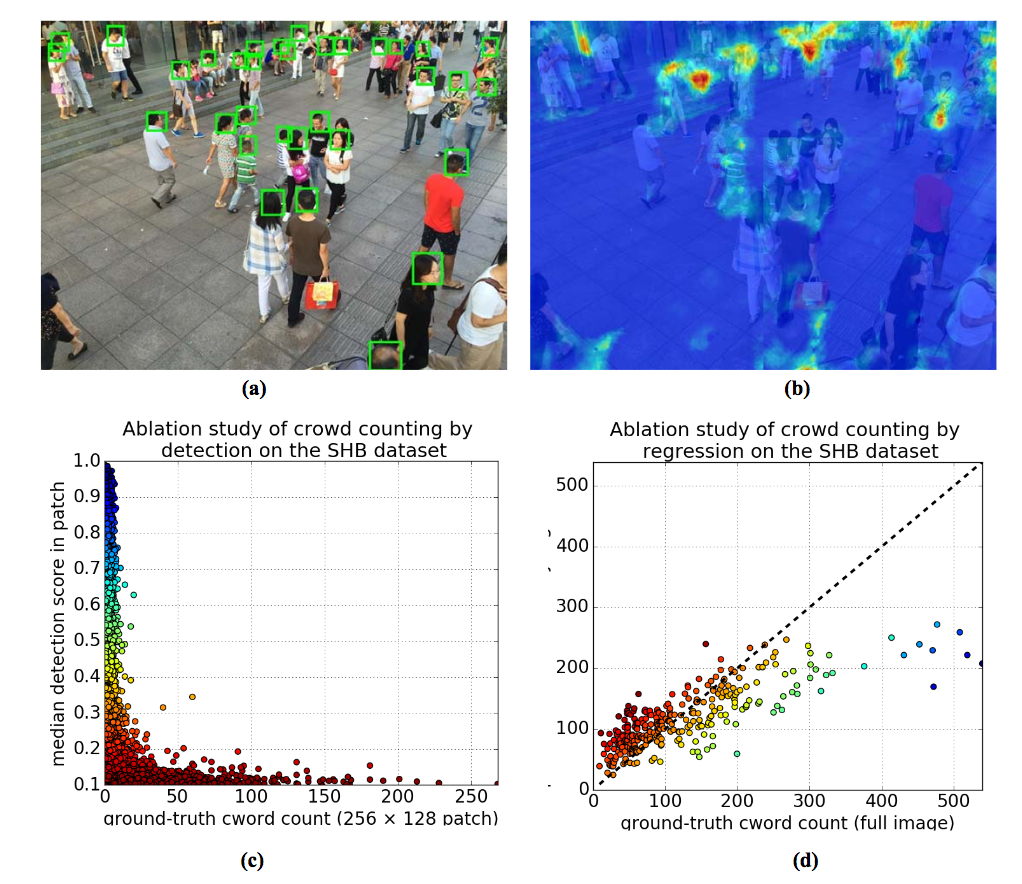
3つのベンチマーク(Mall, ShanghaiTech PartB, WorldExpo10 dataset)においてState-of-the-artな精度を達成すると同時に、混雑時の人数カウントの問題と異なるアプローチを同時実行して相補的なアプローチDecideNetを提案したことが採択された大きな理由である。
複数人ポーズ推定には,キーポイントの半/全遮蔽や,複雑な背景といった要素(hard keypoints)が問題になる.Cascaded Pyramid Networkを提案. hard keypointに対応するためのもの.2つの構造からなる.
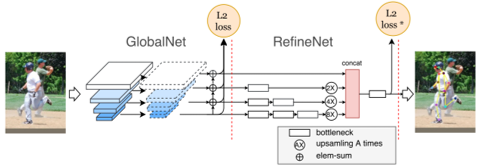
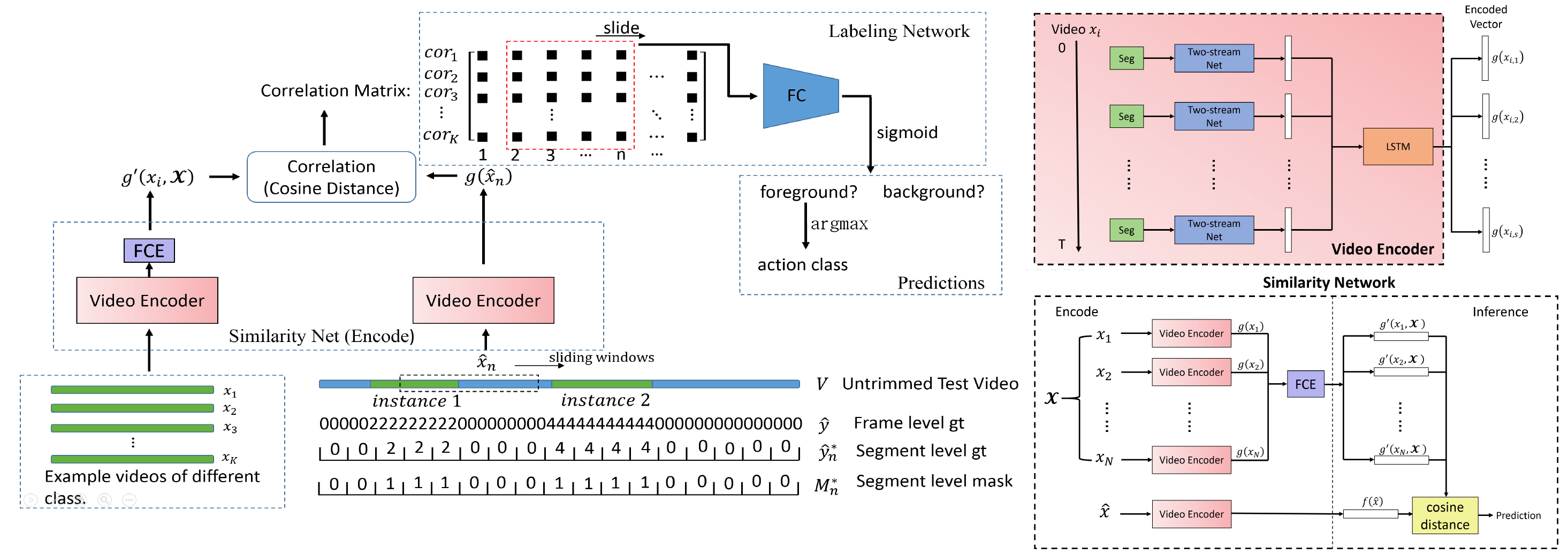
ワンショット学習(One-shot Learning)により動画像における人物再同定(person re-identification)を実行する論文。ラベルなしのtracklets(人物から抽出した動線)が容易かつ事前に手に入ることから、このtrackletsを徐々に改善しつつ人物同定率を高めるようにCNNを学習していく手法を提案する。本論文での学習では、最初にひとつのラベルを用いて初期化したあと、(1)信頼度の高い少量のサンプル(簡単なサンプル)に対して擬似ラベルを付与、(2)擬似ラベルを含めたラベルを元にカテゴリを更新してより難しいサンプルも取り込む、を繰り返して学習を行う。実験的に擬似ラベルを選択する方法についても議論している。
正解ラベルが付与されたある画像一枚を準備するだけで擬似ラベルを推定して徐々に学習を進めていくワンショット学習を提案した。人物再同定の問題においては有効な解決策であることを示したことがCVPRに採択された基準である。ワンショット学習によりrank-1の精度が21.46@MARS dataset、16.53@DukeMTMC-VideoReID datasetであり、コードも公開されている。
動画シーケンスにおいて2D姿勢推定のベンチマークを提供する。本論文で提案するベンチマークでは特に、人物の重なりを含む混雑シーン、密なアノテーションを提供する。さらに右の画像で示すようにドメイン依存していない多様な(diverse)シーンを捉えつつ姿勢アノテーション数でも有数、1画像に対する複数人物/ビデオに対するラベルづけにも対応している。トータルでは23,000画像に対して153,615人の姿勢アノテーションを行なった。チャレンジとしては単一フレームに対する姿勢推定(single-frame pose estimation)、ビデオに対する姿勢推定(pose estimation in videos)、姿勢トラッキング(pose tracking)を提供し、評価用サーバも提供する。同DBに対するベンチマーキングではOpenPoseにも導入されているPAFを改良したML-LAB(引用52)がトップ(70.3@mAP)、Mask R-CNNをベースにしたProTracker(引用11)は64.1@mAPであった。
大規模かつ静止画ではなく動画に対する人物姿勢データセットを構築し、さらには評価サーバを提供、さらに最先端手法に関するベンチマーキングを行なっていることが新規性およびCVPRに通った理由であると考える。
Person Re-ID(人物再同定)は異なるカメラ間で同一人物を対応づける問題設定であり、画像の質や形式が異なるため非常に困難である。本論文ではカメラ間のスタイル変換を行うことでカメラに依存せず安定して認識できる特徴抽出(camera-invariant descriptor subspace)を行い、人物再同定の問題を高度に解決することを目的とする。この問題に対してCycleGANを適用することでカメラ間の特徴変換を捉えた上で、データ拡張を行う。存在するノイズへの対策として有効と思われる正則化:Label Smooth Regularization (LSR)を適用する。LSRを使用する場合では学習データに対するオーバーフィッティングが見られず、有効な手法であることが判明した。
CycleGANによるカメラ間のスタイル変換を実現してデータ拡張、LSRによりノイズへの対応を行いオーバーフィッティングを回避していることが新規性である。また、人物再同定においてその高い精度(Market-1501のrank-1にて89.49%、DukeMTMC-reIDのrank-1にて78.32%)を実現している。さらに、LSRを用いることでベースラインからの精度向上が見られる。
単眼距離画像から簡易的かつ効果的に3次元手部姿勢推定を実施する技術について提案する。従来の3D手部姿勢回帰の手法と比較して、本論文ではピクセルごとの(pixel-wise)解析を可能とする。手法としては2D/3Dの関節点を返却するカスケード型の多タスクネットワーク(multi-task network cascades)を提案し、End-to-Endでの学習を行う。その後MeanShiftによりピクセルごとの姿勢位置を推定する。
従来のほとんどの手法では関節レベルの手部姿勢推定であったのに対して、本論文で提供する技術はピクセルベースの3D手部姿勢推定であることが新規性である。ピクセルごとの回帰はノンパラメトリックな手法を構築した。MSRA/NYU hand datasetにてすべての従来手法よりも高い精度で手部姿勢推定を実行した。また、ICVL hand datasetでは(頭打ちになっていると思われる)論文5には及ばなかったが、接近した精度を叩き出すことに成功した。
顔画像からshapeの三次元復元を行う際に、画像から個人性(顔の形など)を反映した3Dモデルと、個人性以外(表情など)を反映した3Dモデルをencoderで別々に生成しdecoderで三次元復元を行う手法を提案。 生成された顔のshapeは三次元復元におけるstate-of-the-artよりも高い精度を達成し、 また生成されたshapeによる顔認証においても多くの既存手法より高い精度を達成した。
アンカーベースで画像中の小さな顔に対する検出精度を向上させる手法を提案。アンカーベースの手法では画像中に等間隔で並べられた点(アンカー)を中心とした矩形によって物体を検出する。 アンカーによる検出精度を評価する数値としてExpected Max Overlapping(EMO) scoreを提案し、 EMOを深層学習に学習させることで、小さな顔(16X16)に対する検出精度を向上した。
顔に関するタスクに汎用的な特徴量を得ることができるDistilling and Dispelling Autoencoder(D2AE)を提案。Encoderによって顔から個人性を表現する特徴量(性別など)と個人性を排除した特徴量(表情など)を抽出する。 取得された特徴量により、個人識別、アトリビュートの識別、顔のアトリビュート編集、顔の生成を行うことができる。
FCNの中にKernel convolutionを暗黙的に入れ込み,大域的特徴情報を残すというアイデアを提案.Conv層で局所特徴を取り,KernelConvでそれをブラーにかけ,DilatedConv層で大局的特徴をリファインするという構造.
特に解像度に独立・きっちりROIがとれない・要複数検出対応・要遮蔽対応な顔ランドマーク検出タスクに有効.KernelConvによって勾配平滑化と過学習抑制が働き収束しやすくなる. アウトライア弾きのために,事前処理ステップにおいて,ネットワーク出力をシンプルなPCAベース2D形状モデルにフィットしておく.
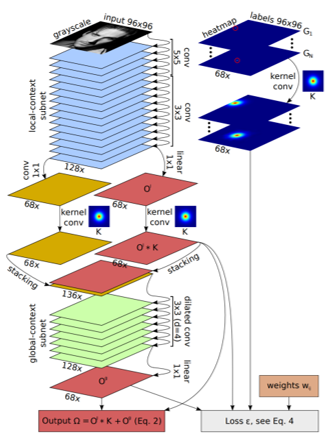
影の周りには様々な背景があり,セマンティクスを理解しなければならないため,影の検出は基本的のようで困難である.それに対して,方向認識の方法で画像のコンテキストを解析することで影検出手法を提案する.空間のRNN内のコンテキスト特徴が密集している箇所にアテンションを導入することで方向認識の手法を定式化する.97%の検出精度と38%のバランスエラー率の低減を実現.
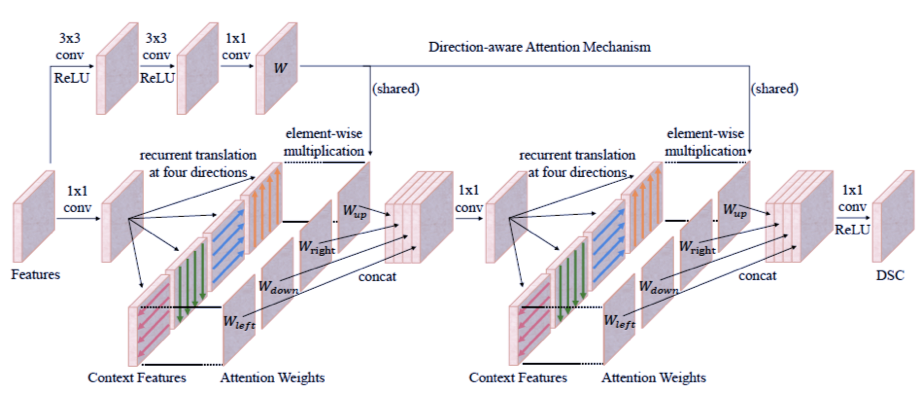
現実の多様な場面での環境の物体に対するアフォーダンスの推定する研究。ADE20kを基にしたADE-Affordanceというデータセットの提案。このデータセットはリビングなどの屋内から、道路や動物園などの屋外まで幅広いタイプの画像とそのannotationで構成。また、画像中の物体に対してアフォーダンスの推理を行うための,画像からcontextual informationを伝えるGraph Neural Networksの提案。
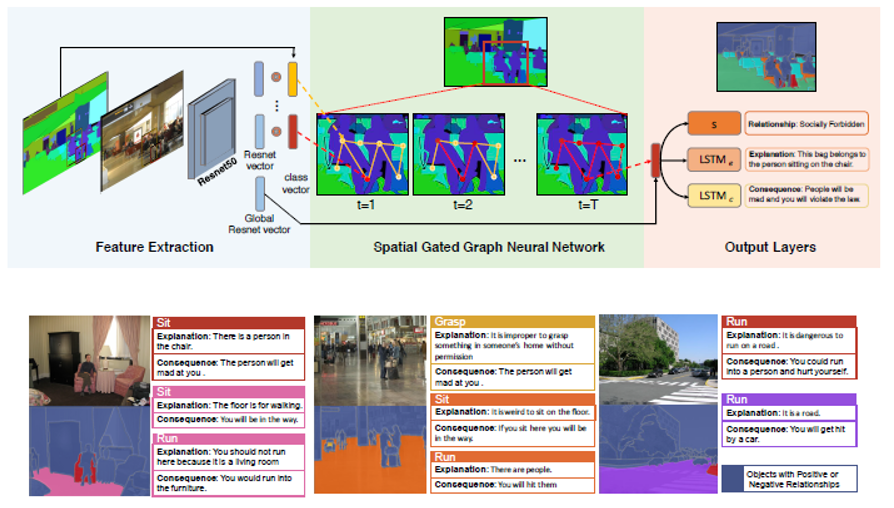
・ある場面の状況下での適切でない行動の理由について身体的や社会的な観点から説明・画像上のある物体に対してだけでなくその場面を全体としてとらえてアフォーダンスの推論を行っている. ・物体間の依存関係をモデル化することでアフォーダンスとその説明を生成
現在のキャプショニング方法は,2つの異なる画像であるにも関わらず,同じキャプションを生成してしまうなどの弁別性にかけている.それに対して,学習の際に画像とキャプションの一致度を直接関連付けるLossを組み込むことによって他のキャプションよりも弁別性のあるキャプションを生成している.

機械翻訳の評価指標であるBLEU,METEOR,ROUGE,CIDErやSPICEにおいても既存のキャプショニング手法よりも高いスコアを示している.
入力された会話文に対して、その返答と適切な顔のジェスチャーを生成する手法。映画データセットを元にトレーニングデータセットを構築。 RNNに対してディスクリミネータの出力を報酬とした強化学習を行った。

顔認識のための新たなロス関数としてソフトマックス関数をベースとしたLarge Margin Cosine Loss(LMCL)を提案した研究。LMCLはソフトマックス関数の指数部分を重みベクトルWと特徴量ベクトルxの内積においてWとxのノルムを1とし、定数mを引いた関数。 認識タスクでは異なるクラスタ間の距離を遠く、同じクラスタ間の距離を近くする、という基本的な考えがある。 LMCLはこの考えを元に上記のようにL2正則化を施すことで、Wとxのノルムに左右されることなくWとxの角度空間においてクラスタの分離を行う。
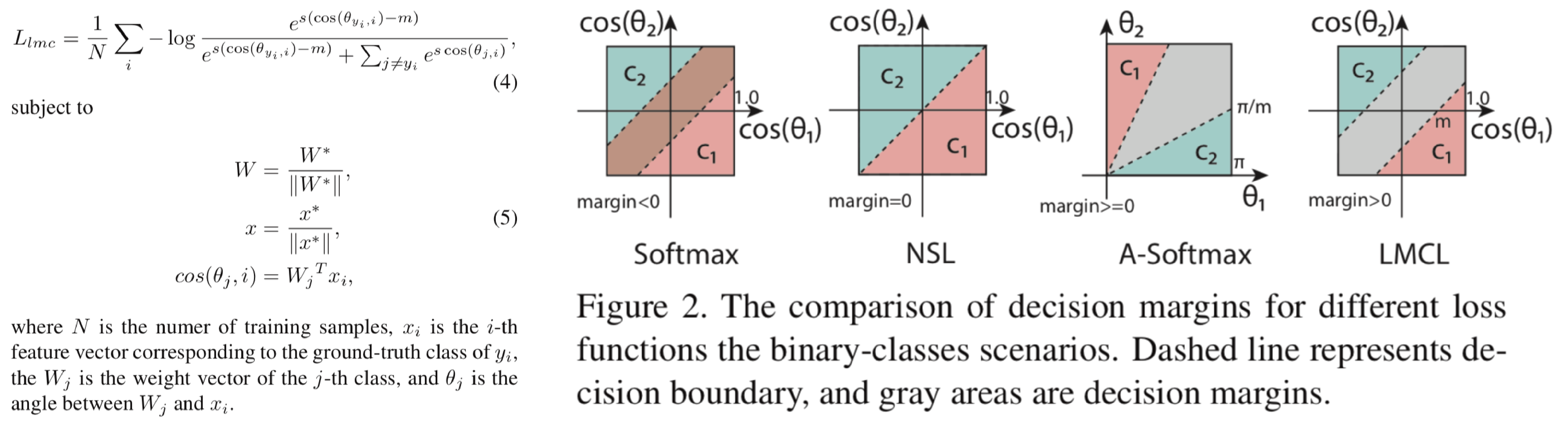
異なる位置の点光源1個によって照らされた5枚の正面顔画像から高品質な3次元顔形状を最適化によって復元する研究。被写体の正面に5つのLED点光源が配置されいている照明環境で撮影を行う。 入力画像に対して3D morphable modelを適用することで簡易的な3次元顔形状を生成し、法線マップ組み合わせることで点光源の位置をピクセル単位で推定する。 またセマンティックセグメンテーションを行うことで体毛が生えいてる領域とそうでない領域に分割し、体毛が生えている領域にはフィルタ処理を行うことでノイズを除去する。

顔の超解像度化を学習させる際にランドマーク、パーツの位置推定を同時に行うネットワーク(FSR Net)を提案した研究。同ネットワークをベースにFSR GANも提案。 また生成された高解像度画像に対する評価尺度として生成画像とGTにおけるランドマークのNRMSE、顔パーツに対するセマンティックセグメンテーション画像(parsing)に対するPSNR、SSIM、MSEを提案。 GANベースの手法では高精細な画像が生成されるがPSNR、SSIMが低くなり、MSEをロスとしたネットワークではPSNR、SSIMは高いがボケた画像になってしまう、というジレンマから上記の評価尺度を導入。
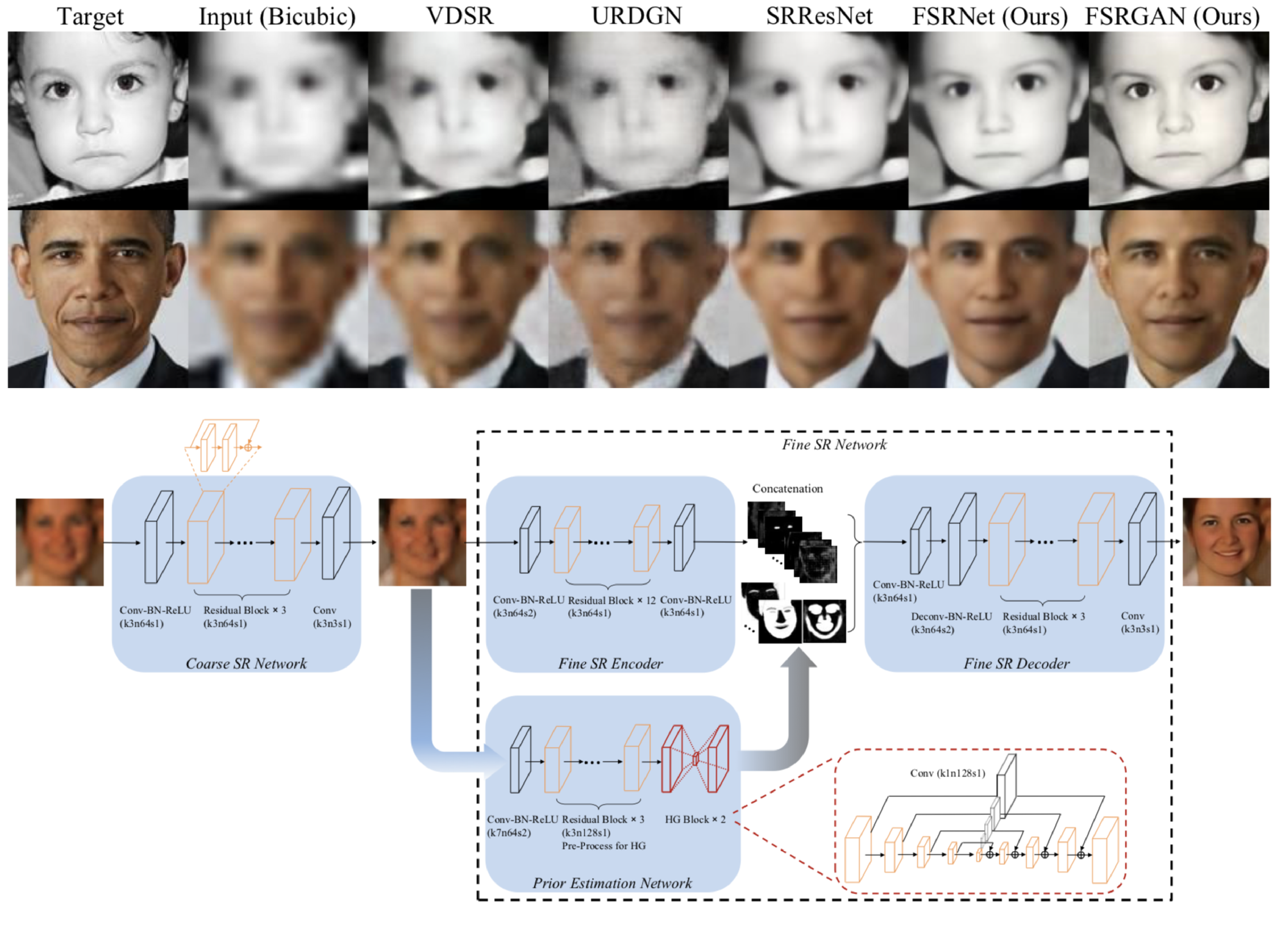
相互に関連性がある2D/3D姿勢推定+人物行動認識を多タスク学習(Multi-task Learning)により最適化した論文である。それぞれで学習を行ったときよりも高い精度を実現することを明らかにし、複数のデータセットにてState-of-the-artな性能を叩き出した。2Dと3Dの姿勢推定、人物行動の特徴量が相補的に補完し合い特徴学習をより高度にしている?
姿勢推定(しかも3D姿勢推定も含めて)や人物行動認識を単一の枠組みで解決、さらには多タスク学習により別々に学習したときよりも高い精度でふたつの問題を解決した。さらに複数のベンチマーク(姿勢推定:Human3.6M, MPII/行動認識:PennAction, NTU)にて最高精度も叩き出したことが採択の理由である。
目的のタスクに特化した2つの分離境界を利用したドメイン適応手法。従来の埋め込み空間においてドメイン間の分布を単に近づける方法に対して、あるタスクと解くための分離境界を考慮して適応を行う。この枠組みでの適応はtargetでの損失の上界を下げる埋め込み空間への写像を求める作業と類似している。さまざまなドメイン適応のベンチマークにおいてSoTA。
Source(S)で学習を行った二つの識別境界を作成する。その識別器がTarget(T)で異なる判断を行ったサンプル(discrepancy)はSの分布とは乖離している領域であると考えられる。以下のような敵対的な適応を行う。(1) TにおけるDiscrepancyが増加するよう識別境界を学習。(2) Discrepancyが減少するように埋め込み空間を学習。(3)Sでの識別は常にうまくいくよう学習。 識別境界を考慮した適応という新規性、理論的な背景、論文の明快さ、精度としての結果が揃っている。
アイデアの面白さと同時に論文が非常にわかりやすかった。識別境界はあくまで埋め込み関数を適化するために得たものなので、この枠組みで得られる最終的なもの以外(得られた埋め込み空間上で新たに学習したもの)でもうまくいくのではないかと感じた。
非剛体的な変形を伴う3Dオブジェクトの形状補完.部分的な形状補完のための学習ベースの手法としてgraph-convolutionを含むVAEを提案した.推論時には,既知の部分的な入力データに合う形状を生成できる変数を潜在空間で探すように最適化する.結果として人体と顔の合成データ,リアルなスキャンデータに対する補完が可能であることを示した.
eye-Inpaintingを行う手法.顔のようなそれぞれ固有の特徴を持つ画像においてのInpaintingで,従来のDNNによる手法は新しい顔を生成するなどidentityを保たなかった.exemplar informationを利用するconditional GAN(ExGANs)を提案.参照画像やperceptual codeというidentifying information(exemplar information)をGANの複数の箇所で利用することで,perceptualに優れ,identityを反映した結果を生成することができた.identifying informationをGANの複数の箇所で利用することが新しい.さらに,将来の比較のためにEye-Inpaintingのタスクの新しいベンチマークとデータセットを用意した.

cGANの一種.参照画像のIdentityを符号化するネットワークと,Generator,Discriminatorから成る.identifying informationを生成に利用するだけでなく,DiscriminatorやPerceptual lossの算出にも利用している.参照画像をベースにした場合と符号をベースにした場合にアプローチを分けている.
特徴ベクトルのクラスタリングでGANの入力ベクトルを作成する学習方法で,ロゴの生成と操作が可能とした.ロゴのデータは高マルチモーダルのデータであり,従来のSoTAではmode collapseを起こしてしまうが,提案する学習方法では多様なロゴを生成する.iWGANをCIFER-10で学習するとき,提案する学習方法によって,Inception scoreでSoTA達成.Contribution:
![]()
上段はデータセットから.下段が生成結果.
Clustered GAN Trainingと読んでいる.GANのネットワークは,DCGANとimproved Wasserstein GAN with gradi- ent penalty (iWGAN)を利用.オートエンコーダーの中間特徴ベクトルもしくは,Resnetの特徴ベクトルをクラスタリングして,Generatorの入力ベクトルとする.このクラスタリングでセマンティックに意味のあるクラスタを形成し,GANの学習を向上させることが可能.
多様で意味のあるサンプルを生成可能な,複数のGeneratorと1つのDiscriminatorから成るGAN(MAD-GAN)を提案.一つのGeneratorが一つの構成要素を担当する混合モデルとしてはたらく.いくつかの従来のGAN手法と比較実験を行い,MAD-GANは多様なモードを獲得できることを確認.さらに,理論的な分析も行っている.
 それぞれの行が異なるGeneratorによって生成した結果.行はそのGeneratorにランダムなノイズzを入力して生成した結果.マルチビューなデータセットから異なるモードを異なるGeneratorが学習していることを確認できる.
それぞれの行が異なるGeneratorによって生成した結果.行はそのGeneratorにランダムなノイズzを入力して生成した結果.マルチビューなデータセットから異なるモードを異なるGeneratorが学習していることを確認できる.
スケッチから写真を生成する手法の提案.50のカテゴリの写真を生成することができる.スケッチに対して,自動でデータ拡張をする方法を示し,その拡張方法がタスクに有効であることを示す.さらに追加の目的関数と新しいネットワーク構造も提案.マルチスケールの入力画像を入れることで情報の流れを向上させている.結果はまだphotorealisticとは言えないが,従来手法よりリアルでinception scoreの高い結果を得た.

大規模3D顔データセットを構築し、そのデータによってトレーニングされたCNNが高い3D顔認識精度を持つことを示した論文。従来の3D顔データセットはデータ数が少なく、最も多いND-2006でも888アイデンティティー・13540種類のみであったが、本論文で構築されたトレーニング用データセットはおよそ10万アイデンティティー・310万種類。 このトレーニングデータを用いてCNNを学習させることで、認識精度は98.74%となりstate-of-the-artよりも優っていることを確認した。 また既存の3D顔データセットをマージすることで、1853アイデンティティー・31K種類のテスト用3D顔データセットを構築した。
高解像(128x128)のリアルタイムなタイムラプス動画の生成をするGANを提案.最初のフレームを与えると,近未来のフレームを生成する.新規性としては,
corse-to-fineの2ステージアプローチのGAN.ステージを分けた狙いとしては,1ステージ目でコンテンツの生成を行い,2ステージ目でモーションのモデリングを行うこと.1ステージ目のU-net風のネットワークでは3D convolutions と deconvolutions を含んでいる.
2ステージ目のDiscriminatorとして,モーションパターンをモデル化するためにGram matrix使って,adversarial ranking lossを算出する.1ステージの出力ビデオ,2ステージ目の出力ビデオ,真のビデオからランキングをとる.
タイムラプス用のGANが初めて提案されたことが評価されたのかなという印象.定量的な評価はメインがPreference Opinion Scoreで, 他はMSE, PSNR and SSIM.
Object Tracking 手法において用いられる複数の Hyperparameter を強化学習によって各シークエンス毎に最適化する手法を提案. Hyperparameter の選択を Action, Tracking の精度の良さを Reward として, Normalized Advantage Functions (NAF) を用いた強化学習を行なっている. また, Heuristic を導入することで, 学習の遅さの問題を緩和した.
![]()
3次元データを扱う新しい convolutional の方法 "Tangent Convolution" を提案. 全ての点の近傍点を仮想的な接平面上に射影し, 接平面上で畳み込みを行う. 接平面は法線ベクトルが計算できれば構成する事ができるため, 複数のデータ形式に対して同様に適用が可能. また, 事前計算を行う事によって大規模なデータベースに対しても効率的に計算を行う事が可能となった.
・部分的に観測されたシーン(RGB-D)から,full sceneの構造及びセマンティックラベルを推定する新規な問題設定”semantic-structure view extrapolation”及びフレームワークを提案した.
・従来のview extrapolationは画像のboundryの色情報しか行わず,シーンのセマンティック構造に対してextrapolationを行う研究がない.そこで,この論文で,著者達がsemantic-structure view extrapolationを提案し,50%以下のシーンの観測データから構造及びセマンティックをextrapolation予測する.
・提案フレームワークは:①一枚のマルチチャンネルpanorama画像でシーンの情報(RGB,構造,セマンティック)を表示する;②3次元構造をデプスのような詳細な三次元情報を用いずに,3次元平面方程式で表示する.③マルチロス関数(ピクセルレベル,グローバルコンテキスト)を用いる.
・提案フレームワークの考え方は入力と出力を一枚のマルチチャンネルpanorama画像として表示し,encoder-decoderにより,欠損した入力からfullなpanorama画像を出力する.
・CG データセットSUNCG及びリアルシーンデータセットMatterport3Dを用いて従来手法よりシーンの構造及びセマンティックの予測が優位.
・一枚のマルチチャンネルpanorama画像でシーンの情報を表示し,シーンの情報を固定なサイズにできるので,2次元畳み込みを用いられる.
「CNNは理論上任意の関数を近似できるが、その構造自体に汎化性能をあげるようなPriorが含まれている」という考えのもと、ランダム初期化されたCNNを用いて高いレベルの画像復元、ノイズ除去などを行った。また、CNNのPrior をさらに裏付けるものとして、自然画像を復元するより、ノイズ画像を復元する学習の方がiteration数がかかることも示された。

ノイズ画像zをencoder-decoderモデルに入力して、生成された画像を欠損画像にMSEで近づけるように学習するだけである。注意点として、完全に学習仕切ってしまうと欠損画像と同じものが出るだけなので、学習をある程度のiterationで止めると、復元されたような画像が得られる。また、CNNのPrior をさらに裏付けるものとして、自然画像を復元するより、ノイズ画像を復元する学習の方がiteration数がかかることも示された。着眼点や面白い実験方法に加え結果も伴っている研究
畳み込み処理×SGDの異常なまでの汎化性能を実験的に裏付けていると思われ非常に面白い。逆にCNNのPriorの苦手なところとして、Adversarial exampleやGANのチェッカーボード現象も関係してそう。畳み込み処理の派生(Deformable convなど)でのpriorの検証も気になる。
OCRのstate-of-the-artな手法として,encoder-decoderで文字カテゴリごとのAttentionを取ってからテキスト認識をするvisual attentionベーステキスト認識があるが, ある文字がよく見えなかったり1文字でも複数ピークが出てしまったりする問題はある. GTとの差を取るとして,エンコード後の文字列で比較する編集距離を取ることが考えらえるが, 本稿ではVAで出る尤度分布で比較する,編集確率(Edit Probablity)を提案する. これにより,字抜けや余分な字を拾ってしまうような誤認識に強い文字認識を実現可能.
正統進化を,他のラボが,1年未満に行ってしまっているあたり,CV分野の流れの早さがうかがえる.
・VQA問題の逆問題iVQA設定及びモデルを提案し (画像及び回答文から,質問文を生成する),更に iVQAもVQAと同じく“視覚-言語”の理解のベンチマック問題設定になれると指摘した.
・iVQAタスクに用いられるmulti-modal dynamic inferenceなフレームワークを提案した.提案フレームワークは回答文を生成する段階で,“回答文”,“生成した部分的な質問文”によって導かれ動的に画像attentionを調整できる.
・更に,回答文の従来の自然言語的評価に, ランキングベースなiVQAタスクの回答文を評価できる指標を提案した.その指標により,などの面を評価できる.
・近年,従来のVQAの成功がデータセットバイアス及び質問文からの情報理解,画像の内容に対する理解がまだVQAにおいて深く利用されていないことが指摘された.そこで,画像と回答文から質問文を予測する問題設定iVQAを提案した, iVQAタスクにおいてはVQAと比べ,①画像内容の理解の要求が高い,②また回答文が常に短いので,質問文と比べよりスパースな情報抽出しかできないため,回答文に頼りすぎることにならない.③モデルの推定及びreasoning能力が更に必要である.
・提案フレームワークの各パーツ(dynamic attention, multi-modal inferenceなど)の有効性に関してAblation studyを詳しく行った. 説得力がある.
・Dynamic attention mapsの可視化分析により問題文を生成する段階で,動的に関連する画像領域にattentionすることを指摘した.
・実験を通して,iVQAをVQAとヒュージョンしたら, VQAの精度を挙げられることを証明した.
・VQAの問題点を深く理解した上での新規問題設定.
・Dynamic attention mapsの可視化分析により問題文を生成する段階で,動的に関連する画像領域にattentionすることを指摘した.
・新奇な考え方・詳しい分析実験・論文の理解しやすさなどが非常に良い
手書き画像から,書いたものの判別をする画像分類器を出力するメタ学習の提案.学習していない手書きカテゴリでも,そのカテゴリの画像分類器が出力される.3つの枠組みが作れる. (1)スケッチ画像カテゴリ分類モデルを入力 (2)スケッチ画像を入力 (3)コースなリアル画像分類モデル+スケッチ画像を入力
枠組みとしては,Model Regression Networkによる.論文では,SVMパラメータの学習を行っている.
画像合成の際に,背景に対して位置やサイズ感などが正しくなるように幾何的変換を求め,修正を加えてくれるGANを提案.たとえば,家具が適切な場所に置かれたり,メガネが適切に掛けられたりする.
構造的には複数のSpatial Transformer Networkをジェネレータとして組み込んでいることが特徴.複数のSTNにおける,反復画像ワーピング(画像変形方法の一つ)と逐次学習を導入している.

・Visual Dialogタスクに用いられる質問の回答文と質問文を両方予測できるネットワークを提案した.
・提案フレームワークは100個の回答文(質問文)から正解を予測する(discriminative). 提案フレームワークは質問文,画像,キャプション,QA履歴,選択などの情報をsimilarity+Fusionネットにより100次元のベクトルを生成し,正解ラベルとのcross-entropy誤差を求める.
・また,従来Visual Dialogの質問文を評価する指標がない,著者達が質問文を評価できる“VisDial-Q evaluation protocol”を提案した.提案protocolは質問文を100個に固定し,予測した質問文がどれくらい通常の人により提出される可能性が高いかにより評価を行っている.
・同じネットワークで質問文と回答文を両方予測できる.
・質問文を評価できる指標の提案.
・Discriminative VQAタスクにおいて, VisDial評価指標は従来手法(HRE, MN, HCIAE-D-NP-ATT)より良い性能を達成した.
・VQGタスクにおいて,提案した評価指標“VisDial-Q evaluation protocol”により55.17% recall@5 と 9.32 mean rankを達成した.
人や自律移動プラットフォームが,移動している人を避けるにはいくつかの経路が考えられる.本手法は,人間の経路予測にシーケンス予測とGANを組み合わせたツールを用いて,複数の経路予測を行う.Recurrent sequence-to-sequence modelは,複数の人の間で情報を集約するための新しいプーリング手法を用いて,観測者の行動を予測する.そして,GANを用いてもっともらしい行動をいくつか予測する.予測された経路はDiscriminatorへ入力され,Fake/Real判別をしGANを訓練していく.
Generatorでは,複数の人が同時にどう動くか予測するために,Encoderの各LSTMの出力をまとめるプーリングモジュールを導入した.Discriminatorは,経路そのものがFake(人として社会的にあり得ない行動)またはReal(あり得る行動)を判断する.ETHやHOTELなどのデータセットを用いて評価実験を行った.12ステップ後のAverage Displacement Error(全ての時間での真値と予測値の誤差)は0.58(Social LSTM: 0.72),Final Displacement Error(最終目的とでの真値と予測値の誤差)1.18(Social LSTM: 1.54)となった.

与えられたポーズ情報を条件として人物画像を生成するタスクを扱う.任意ポーズへの変形タスクで発生する,(服などの)変換前のピクセルと変換後のピクセルの対応が不整列である問題に対応するために,deformable skip connectionを対案する. 従来手法と比べ,条件画像の服の色・テクスチャを保存して別ポーズの画像を生成できている. 人物画像の生成に限らず,キーポイントを与えることのできる不整列のオブジェクトであれば,この手法が適用できると著者らは考えている.
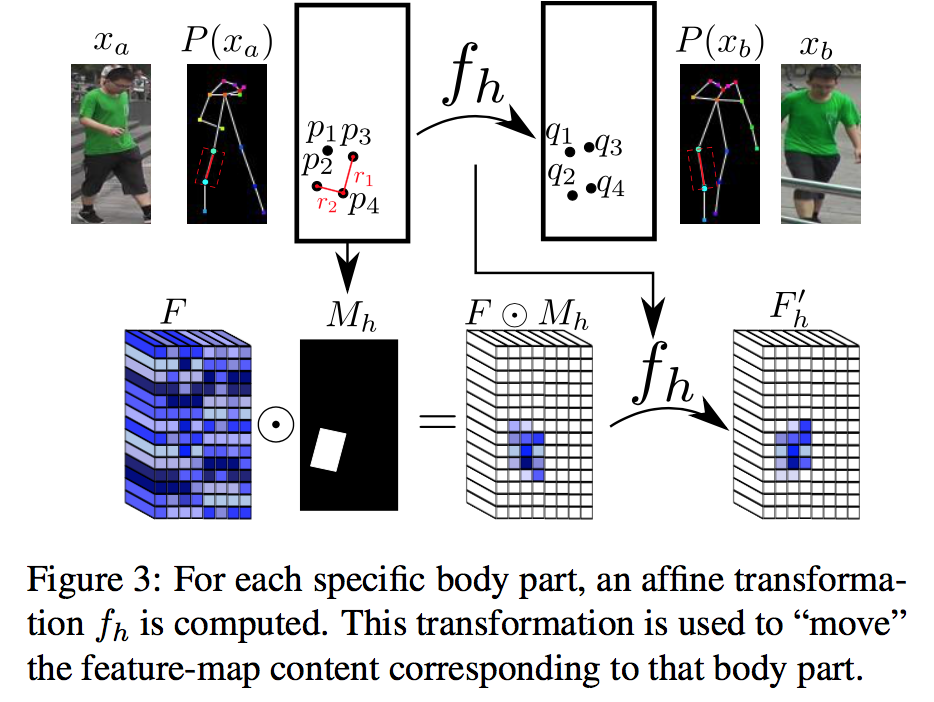
U-net likeのEncoder-Decoder, GANdeformable skip connectionについて. 変換前後の両方のポーズ情報が既知なので,キーポイント周辺のピクセルが変換前から変換後にどこへ移動するか知ることができる.したがって,キーポイントの座標からアフィン変換を求め,畳み込みから得た特徴マップをアフィン変換することで,服の色やテクスチャを変換前から変換後の画像に移して生成できる. Encoderの特徴量をアフィン変換し,Decoderの特徴量にskipするのがdeformable skip connectionである.
・盲人に集められたVQAタスクのデータセットVizWiz(画像と音声質問文)を提案した.VizWizが31,000枚の盲人が携帯により撮影し,画像ごとに画像を撮影した盲人が提出した音声質問文一つ付き.質問文ごとに,10個の回答文がアノテーションされている.
・従来のVQAデータセットほぼ人工設定により作成された方が多く,また現実環境の盲人ユーザを対象に“goal oriented”なVQAデータセット未だにない.そこで,盲人がカメラにより周囲環境を撮影し,環境を理解することを目的にして,盲人ユーザにより集められた画像及び質問文のデータセットを構築した.
・ 盲人ユーザにより撮影されたのでVizWizは画像の質が良くなく,又質問文が音声情報なので,はっきり発音が取れない場合などの問題点がある.提案データセットで現状のVQAモデルで検証した結果,性能が従来のデータセットで検証した性能より劣るので, VizWizが将来的の盲人のためのVQA応用に新たな挑戦を提出した.

・初めての盲人により撮影及び質問したVQAデータセット.
・従来のVQAデータセットと比べ,もっと画像の周りの環境に関する質問文が多い.
・従来のVQAデータセットとの質問文の詳細的な特徴比べも行っている.
GANの枠組みにてセマンティックラベルからの高精細画像(HD-Image)生成に関する研究。意味ラベルからリアルな画像を生成するのみならず、インタラクティブな操作で画像生成をコントロールすることも可能。Residual blocksにより構成されるエンコーダ/デコーダ構造を(入力をスケールが異なる画像として)入れ子構造にしデコーダ直前の中間層で統合して画像生成を実行する。さらに、ラベルのみならずインスタンスレベルの特徴量を用いることで写実性が向上したと主張(論文中図4では物体境界面あたりに出ているボケが綺麗になっている)。

従来法より、見た目の画像生成が明らかに良くなり、高画質の画像を対象にしても画像生成ができるようになった。従来手法(pix2pix(論文中文献21), CRN(論文中文献5))さらに、インタラクティブな操作により生成画像を所望の結果に近づけることができる。動画像を見れば従来手法よりも鮮明になっていることは明らかであり、アーキテクチャや生成に関する知見も得ている。CVPRでoralになるための準備やプレゼンが論文中にも書かれていると感じた。やはりNVIDIAはずるいと言われるくらいの計算機環境が揃っているのではないか。
2つの未キャリブレーションカメラにおいて,5点のみで基礎行列を推定する手法を提案.
回転不変な特徴点(SIFT等)を使う.3点は平面にあれば,他2点はどこでも可能.グラフカットRANSACのようなロバスト対応点推定と組み合わせれば,state-of-the-artな性能が出る.
通常,7点や8点取るアルゴリズムが用いられるが,リーズナブルな制約で,少ない情報のみでキャリブレーションできるのはうれしい.例えば図のようにキャリブレーションボードを小さくできたりする. 大変有用な研究成果.
画像分類におけるadrversarial attackの防御手法として, high-level representation guided denoiser (HGD) を提案.target model (メインの処理を担うネットワーク) への前処理段階で用いる. HGDは, マルチスケールインフォメーションを得るためU-netの構造を使い, トレーニングするための損失関数として, 元画像とノイズの乗った画像をそれぞれ入力したときの出力差を用いる. 右図に提案手法の詳細を示す.
pixel-levelの損失関数を課した従来のdenoiserと比べ, より良い結果が得られた.
state-of-the-artな防御手法であるensemble adversarial trainingと比べ, 3つのメリットがある.
・新規の“Customized画像説明文生成”タスクを提案した.また,インタラクティブにユーザに自動的に画像に関する質問をし,回答文を収集できるような仕組みを提案した.・従来の画像説明文生成タスクにおいて,異なるユーザの性質や画像の注目領域などにより,多様な説明文を生成できることが検討されていない.このような性質に応じて,多様な質問文を生成できる仕組み及びユーザとインターアクションしユーザの個性的な回答文を収集しユーザの特徴を学習することにより,Customizedで画像説明文を生成できる仕組みを提案した. ・提案仕組みは具体的に:①画像から self Q&A modelにより,画像中のマルチリジョンを注目し(attention構造を利用した)質問文を生成し, VQAモデルにより回答する(マルチ回答がある質問文だけを保留);② ①により生成できた質問文をユーザに提示し,回答させる;③画像リジョン・質問文・回答文の統合した画像説明文を生成する. ・画像リジョン・質問文・ユーザ特有な回答文からchoice vectorを抽出し,このベクトルを利用してほかの画像が入力された場合,ユーザの個性的な画像説明文を生成できる.
・新規な問題設定“Customized画像説明文生成”・提案手法により,画像からより多様でユーザの個性を含んだ説明文を生成できる. ・ Automatic Image Narrative Generationにおいて,従来のデータセットCOCO, SIND, DenseCapなどと比べ”diversity”,”interesting”,”naturalness”,”expressivity”などの指標に対しパフォーマンスが良い ・ Interactive Image Narrative Generationにおいて,ヒューマンテストで良い評価を達成した.
・画像と点群情報を利用した3D物体検出のフレームワークPointFusionを提案した.・従来のマルチセンサーの情報を利用した3D物体検出は前処理が必要、マルチセンサーを異なるパイプラインで処理し,他のセンサーのコンテキストをうまく利用できないなどの問題点がある.PointFusionは①異なるネットワーク構造を用いて画像(CNN)と点群情報(PointNet)を直接処理し,②デンスフュージョンネットワーク構造を提案し,画像と点群の抽出情報を統合しより精密な3D物体検出を行う. ・2種類のデンスフュージョンネットワークを提案した.①画像情報及びPointNetにより抽出したグローバル情報を統合し, 3Dボックスのコーナー位置を推定する.②画像情報及びPointNetにより抽出したグローバル情報、ポイントフィーチャーを統合し, 3Dボックスのオフセット及びconfidence scoresを予測する.最後の2つの結果を統合し,最終的な結果を予測する
・点群データの前処理が必要無し.・対応できるデータの形式が広い,室外環境と室内環境両方対応できる. ・多様な三次元センサーのデータを対応できる.(RGB-D, LiDar, Radar,…) ・KITTI, SUN-RGBDデータセットにおいてstate-of-the-artな結果
Feature Pyramid Network(FPN)ベースのMask R-CNNに,下位層の特徴マップを上位層に伝播させるPath Aggregation Networkを提案.インスタンスセグメンテーションの傾向として,上位層では物体全体に強く反応するが,下位層では物体の局所的な領域に強く反応する. そのため,Path Aggregation Networkでは,上位層と下位層の特徴マップを用いることで,インスタンスセグメンテーションの精度を向上させている. Path Aggregation Networkは,COCOのベンチマークで2位の性能を達成しており,CityscapeとMVDでも高い性能を達成している.
Path Aggregation Networkの構造は右図のようなシンプルな構造になっている.(a)の部分はFPNと同様の構造となっており,FPNの特徴マップから(b)で新しい特徴マップを作成する. ここで,(a)と(b)では,緑線と赤線のように短距離と長距離のショートカットを導入する. これにより,下位層の特徴を上位層に伝播することが可能である.
1つのネットワークでマルチドメイン対応の画像変換が可能なStarGANを提案.pix2pixやCycleGANの場合,左上図のように特定の1つのドメイン変換しかできないため,複数のドメイン変換をする時には各ドメインを変換するネットワークをそれぞれ構築しなければいけない. StarGANでは,入力する条件とロス設計を適切に設計することで,シンプルなネットワークで多ドメインな画像変換を実現している. 実験では,顔属性のCelebAと表情のRaFD Datasetを使用し,2つのデータセットでGANを学習して下図のような多様な顔画像変換を可能にしている.
StarGANの構造は,右上図のようになっている.ここで,入力はそれぞれのドメインの画像がランダムに入力される. まず,real imageとfake imageでDiscriminatorを学習する. そして,次にGeneratorを学習する. Generatorは,生成したい顔画像の条件とreal imageを入力して,画像変換する. ここで,変換した画像はDiscriminatorに入力される. 変換した顔画像はCycleGANのようにreal imageを再変換する. 定義するロスは,一般的なAdversarial Loss,ドメインを認識するロス,real imageと再変換したimageのL1 Lossである. また,複数のデータセットを学習するために,各データセットのラベルとデータセットの情報が格納されたMask vectorを導入している. これにより,多ドメインかつ複数データセットに対応したGANを構築できている.
意味ラベル(Semantic Layout)から写真のようにリアルな画像をSemi-parametricな手法にて生成する。Semi-parametricはNon-parametricとParametricの強みを相補的に適用する手法である。セマンティックセグメンテーションのアノテーションとその対応する画像をペアとした外的なメモリにより対応関係を学習、Canvasとしてその順番や境界面を初期ステップとして出力する。次にCanvasと意味ラベルを入力としてConv-Deconv構造のネットワークにより写真のようにリアルな画像を出力とする。

Cityscapes, NYU, ADE20Kデータセットとセマンティックセグメンテーションに関するラベルが付与されていれば学習/テストが可能であり、同データセットにて従来法よりもさらにリアルな画像を生成するに至った。図には従来法(Chen and Koltun, ICCV 2017)との比較があり、従来法ではエッジ付近にボケが生じているが、提案法ではボケを相殺してさらに光の度合いまでもリアルに復元できている。
・最も近いスーパークラスを予測することにより階層的新規(novelty)物体識別及び検出のフレームワークを提案した.・従来,新規なunseen物体識別は”known”と"unknown"に回帰する問題として対応されている.この論文で,物体のクラスを階層的に取り扱い,unseen物体の最も近いスーパークラスを求める.提案フレームワークによりgeneralized zero-shot learningタスクに用いられる階層的エンベディングを得られる. ・2種類の階層的な新規(novelty)物体検出構造を提案した.①top-down構造ではconfidence-calibrated classifierにより物体を分布の一致性が高いスーパークラスに分類する.②flatten構造では階層的分類構造の全体を用いずに error aggregationを避ける単一的なclassifierを用いる.また,①と②を組み合わせすることにより,階層的検出精度を向上できることを示した.
・従来のクローズデータセットを用いた物体検出と比べ,提案手法はオープンデータセットを対応できる.・generalized zero-shot learningタスクで提案フレームワークを用いられる ・ ImageNet, AwA2, CUBなどのデータセットで階層的新規(novelty)物体識別においてベースラインより高い精度を達成した.
・マルチsalientオブジェクトおよびそれぞれのsalientランキングを同時に検出するネットワークを提案した.・従来のsalientオブジェクトタスクに,salientランキングは観測者によって異なる結果が出る性質があるため,オブジェクトのsalientランキングについてまだ検討されていない.この文章でsalientランキングを有効的に得られるネットワークを提案した.またsalientランキング手法の評価方法も提案した. ・具体的なネットワーク構造はまずencoderネットワークにより粗末な相対salientスタックを生成し,そしてStacked Convolutional Module (SCM)により粗末なsaliency mapを生成する.またrank-awareでstage-wiseなネットワークによりsalientスタックをリファインする.ヒュージョンレイヤーにより各stageのsaliency mapを統合する.
・saliency ランキングの提案・AUC, max F-measure, median F-measure, average F-measure,MAE, and SORなどの 評価方法により,state-of-the-artなsalientオブジェクト検出性能を達成した.
コンパクトかつ効果的なオプティカルフロー推定を実現するPWC-Netを提案する。ピラミッド構造かつ学習可能な階層的処理、射影(Warping)、コストボリュームにより設計され、軽量化しながら高精度なフロー推定を実現している。図は従来法(左図)と提案法(右図)のアーキテクチャの概略を示している。従来は画像のピラミッド構造により全てのサイズを階層的にオプティカルフローの射影や最適化を行い、最後に後処理をしていたが、提案法のPWCNetではあるひとつの階層内で後処理を行い、コンテキストを考慮したネットワーク(ContextNetwork; Dilated Convによる、各階層のオプティカルフローを入力するとそれらを総合的に解釈して最良のオプティカルフローを出力する)を通り抜けることで出力する。間には{Warping, Cont Volume, Optical flow}を行う層により構成される。
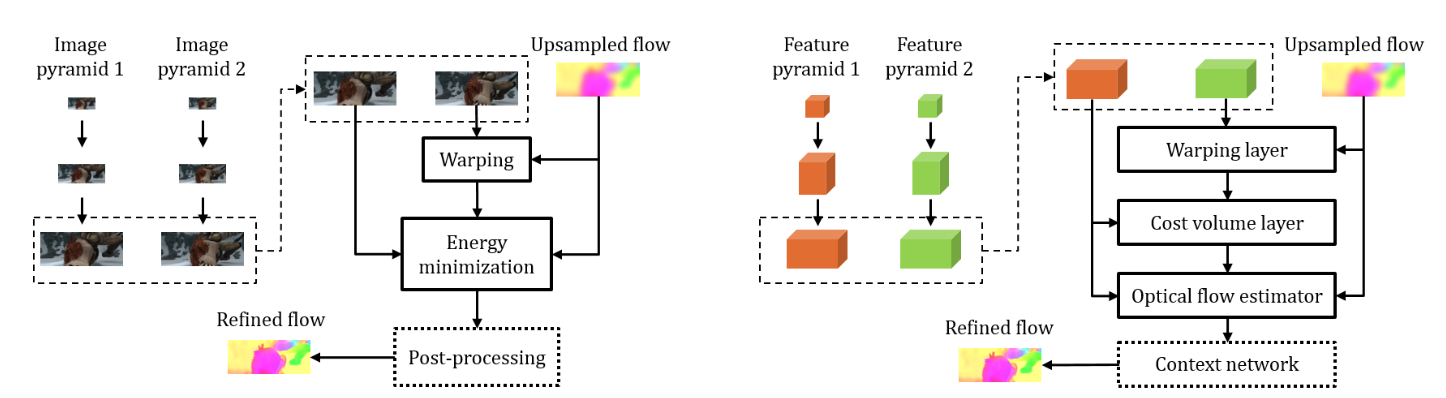
従来法であるFlowNet2よりも17分の1の軽量化モデルでありながら、MPI Sintel final pass/KITTI 2015 BenchmarkにてState-of-the-art、Sintel 1024x436の解像度にて35fpsで動作する。
・無監督インスタンスレベルのattentionを用いたImage Translationフレームワークを提案した.・従来の無監督Image Translationではセットレベルで実現され,物体パーツレベルの対応ができないため,従来手法より生成した物体画像が幾何や意味的な情報のリアル性が低い場合がある.それと比べ,提案フレームワークは①物体をはattentionを用いた高構造化latent空間に変換し,このlatent空間によりインスタンスレベルなImage Translationを可能にした.②さらに,source samplesとtranslated samplesをセマンティック的に対応させるconsistency lossを提案した.
・初めてattentionをGANに導入したと宣言・MNIST , CUB-200-2011, SVHN , FaceScrub and AnimePlanet 1などのデータセットを用いて実験を行い,ドメンadaption,テキスト-画像合成,ポーズモーフィング,顔‐アニメーション化などのタスクにおいて,state-of-the-artな精度を達成した.
様々なシーンに頑健かつ、大きな動きにも対処しながらビデオフレームの補間を行うPhaseNetの提案。中間のフレームにおける位相と階層構造を推定するnnのデコーダを搭載。これにより、既存の位相ベースの手法よりも広範囲に渡る動きに対応。
既存のビデオフレーム補間アプローチは、フレーム間において密な対応付けが必要であり、照明変化や被写体ブレに頑健でない。カーネルに依存した深層学習ベースの手法でもある程度緩和することはできるが不十分。ピクセル単位の位相ベースの手法ならば上手くいくことが実装されている。位相ベースでnnを用いた手法を提案。
物体検出時に特徴量の高次の統計量(high-order statistics)を獲得するためのMulti-scale Location-aware Kernel Representation(MLKP)を提案する.MLKPはSSDで用いるような,複数解像度の特徴マップを結合したマルチスケール特徴マップを用いて効果的に計算できる.マルチスケール特徴マップをMLKPに入力すると,畳み込みと要素ごとの積算を行いr次の表現Z^rを得る.このとき,location-weight networkは各位置の寄与度を学習する.その後,各次の表現を重みつき結合し,RoI Poolingへ入力する.
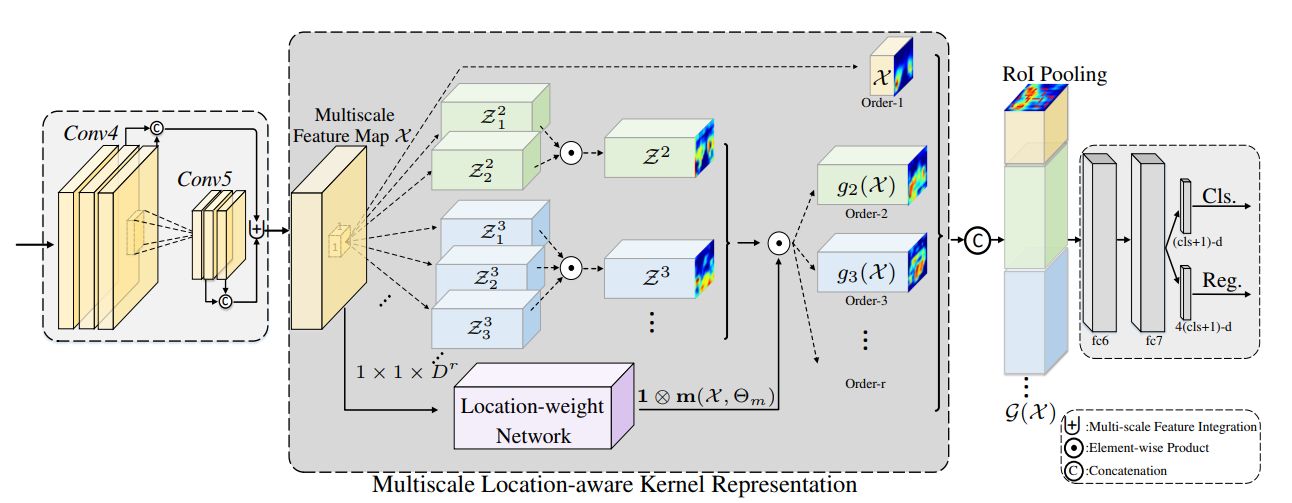
最近の分類メソッドでよく用いられる高次統計量を物体検出器の高精度化に用いる手法である.Faster R-CNNにMLKPを統合することで,Faster R-CNNよりも精度が4.9%(mAP, VOC2007),4.7%(mAP, VOC2012),5.0%(MSCOCO)向上した.DSSDやR-FCNと比較しても同等もしくはそれ以上の性能である.
幾何学変換を利用したGeometrically Stable な特徴表現の獲得手法。オリジナル画像とそれに幾何学変換を施した画像を同じCNNに学習し、中間特徴マップ上で対応するpixelでの特徴量の類似度が高くなるように学習する。キーポイントマッチングなどの問題設定で教師あり学習以上の効果を発揮。Pixelによってはマッチングが困難ば場合も存在するため、不確実性を考慮した学習を提案。
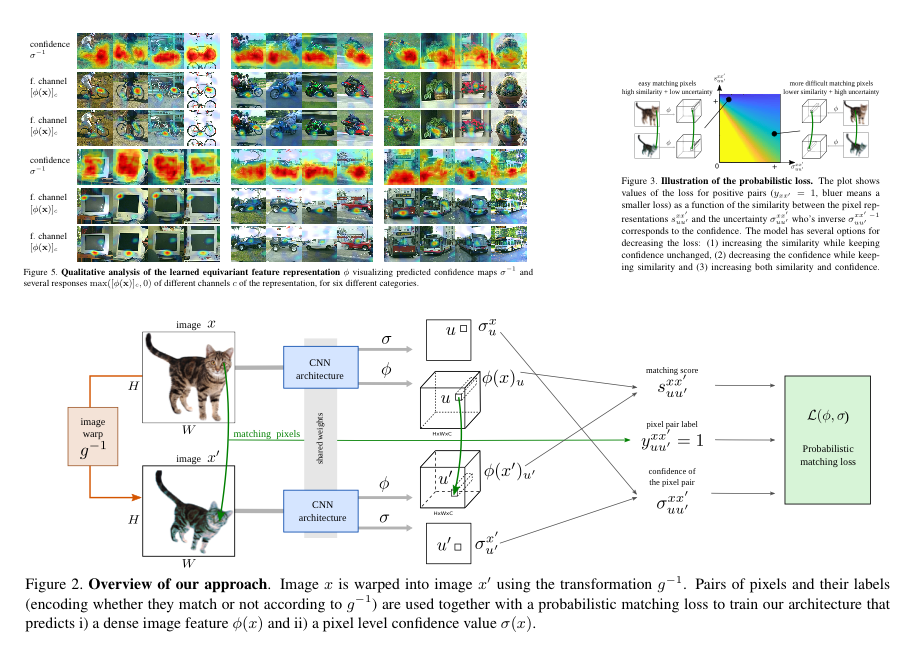
ペアとなる画像を同じNNに入力し、各pixel ペアの類似度と、不確実性を表す値を算出。不確実性を考慮した損失関数を定義することで、結果的にNNはマッチング可能かつ対応するpixelに関しては高い類似度と低い不確実性を、マッチングが困難なものに関しては高い不確実性を算出するように学習される。
定義された距離尺度において対象に直接近づける枠組みが多い通常の類似度学習と異なり、連続値である類似度を確率変数とすることで、不確実性を考慮するのは興味深い。しかし、定式化としては論文内のものよりも、不確実性利用してモデルが類似度の分布を算出しているという定式化にした方がわかりやすいのではないかと思った。
Residualモジュール, Inceptionモジュールに対してAttention機構を導入したネットワーク.Squeeze-and-Excitation Networks(SENet)では,生成される特徴マップのチャンネルに対してAttentionを導入している. SENetは,ImageNetでstate-of-the-artな性能を達成している.(現在1位) また,Place Datasetでも高い性能を達成している.
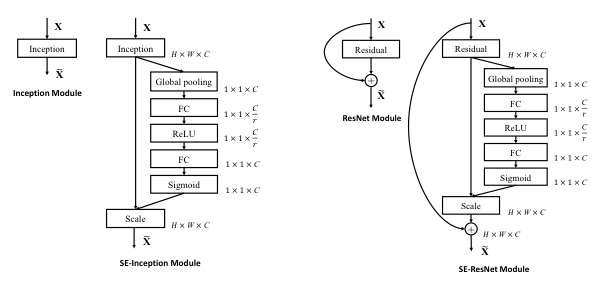
SENetには,右図のように2つのモジュールが提案されている.SE Inception moduleは,VGGやAlexNet等の順伝播ネットワークで使われるSEモジュール. SE Residual moduleは,ResNet系のネットワークに使われるSEモジュールである. 基本的には,Global Average Poolingを施した後に,全結合層を何層か通してチャンネル毎のAttentionを生成する. この構造は,ResNet等の様々なネットワークモデルにも適応できる.
1平方キロメートル以上の広範囲の領域を撮影できるWide Area Motion Imagery(WAMI)の映像から、車などの小さい物体を検出する手法の提案。まず、ClusterNetでビデオフレームから、CNNを使って動きと外観情報を結合し、regions of objects of interest(ROOBI)を出力。次に、FoceaNetによって、ヒートマップ推定を介して、ROOBI内の物体の重心位置を推定する。
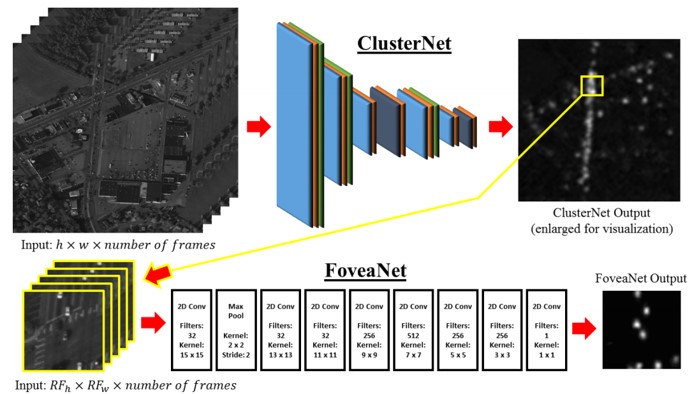
WAMIを使った従来の物体検出は、アピアランスベースの分類器であまり精度が出ず、背景差分やフレーム間差分などの動き情報に依存しがち。Fast R-CNNなどにおけるこれらの問題を検証し、効率的かつ効果的な新たな2ステージCNNを提案。
極端なスケール変化に頑健な物体検出手法であるSNIPの提案。物体検出において、大きな物体と小さな物体をそれぞれ検出することは困難。そこで、学習時に異なるサイズの物体における勾配を、選択して逆伝播する。物体の幅広いスペクトルに対処し、ドメインシフトを低減する。ピラミッド型のネットワークとなっており、end-to-end学習可能。
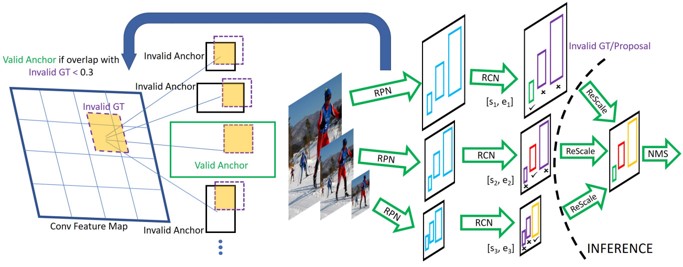
まず、現代の物体検出手法の欠点として、スケール変化について解析している。小さい物体を検出するために“アップサンプリング画像が必要か”などを、ImageNetを使ってパフォーマンスを評価。これらの解析に基づいてSNIPを開発。
自然界にける、“写真に写り易さ”を考慮した画像分類・検出タスク用データセットの提案。5000種類以上の植物や動物からの85万9000の画像で構成。世界各地の多種多様な種やシチュエーションで撮影され、様々なカメラタイプで収集することで画質の変化し、クラスの均衡が大きい。
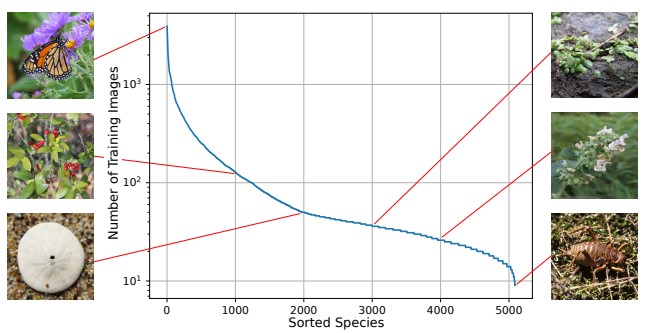
従来の画像分類・検出用データセットでは、カテゴリごとに画像数が統一されている傾向にある。しかし,写真に収め易い種と、そうでない種があるため、自然界はとても不均衡。この差に着目し、現実世界の状況に近い状況で分類・検出に挑戦するデータセットを提案した。
Between-Class learning(BC learn)という画像分類タスクにおける新学習方法の提案。まず、異なるクラスの2枚の画像をランダムな比率で混合したbetween-class imageを作成。そして、画像を波形として扱うためにミキシングを行う。混合画像をモデルに入力し、学習することで混合した比率を出力する。これにより、特徴分布の形状に制約をかけることができるため、汎化性能が向上する。
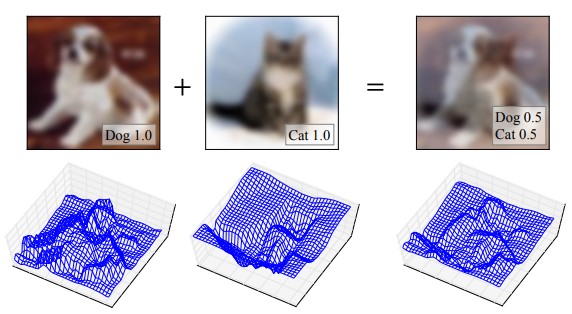
もともとは、混合できるデジタル音声のために開発された手法。CNNは“画像を波形として扱っている”という説から、本手法を提案。2つの画像を混合する意味に疑問はあるが、実際にパフォーマンスが向上している。
ラベルノイズを使って、画像分類モデルを学習するCleanNetの提案。人間による“ラベルノイズの低減”という作業を低減する。事前知識として人の手で分類されたクラスの一部の情報だけを使い、ラベルノイズを他のクラスに移すことができる。また、CleanNetとCNNによるクラス分類ネットワークを1つのフレームワークとして統合。ラベルノイズ検出タスクと、統合した画像分類タスクの両方で、ノイジーなデータセットを使って精度検証。
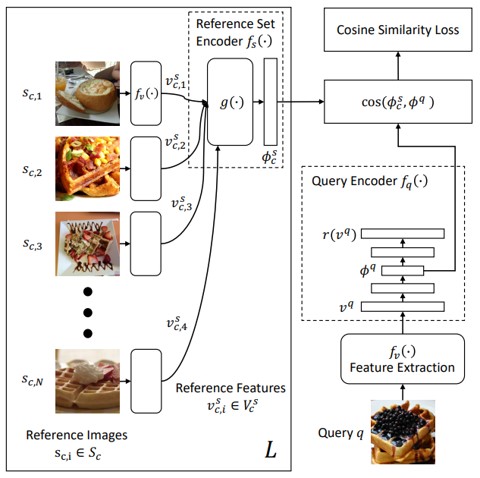
人間がラベルのアノテーションをすると時間がかかり、学習はスケーラブルじゃない。逆に人間に頼らない手法はスケーラブルだが、有効性が低い。少し人間に頼って、あとは自動的にノイズ除去をするというハイブリットな手法。
顔画像のアトリビュートを使用することでGTとなる高解像度画像(HR)を使用せずに低解像度画像(LR)を超解像度化する研究。LRとともに顔のアトリビュートも入力として使用することで超解像化における曖昧さを解決。 ネットワークの大枠はGANを採用。 ジェネレータにおいてLRをauto encoderに噛ませる際にエンコードされた特徴量にアトリビュートを付け足してでコードを行う。 ディスクリミネータはGTのHR画像なら1を、ジェネレータによる画像or画像にアトリビュートが含まれていないと判断した際には0を返す。
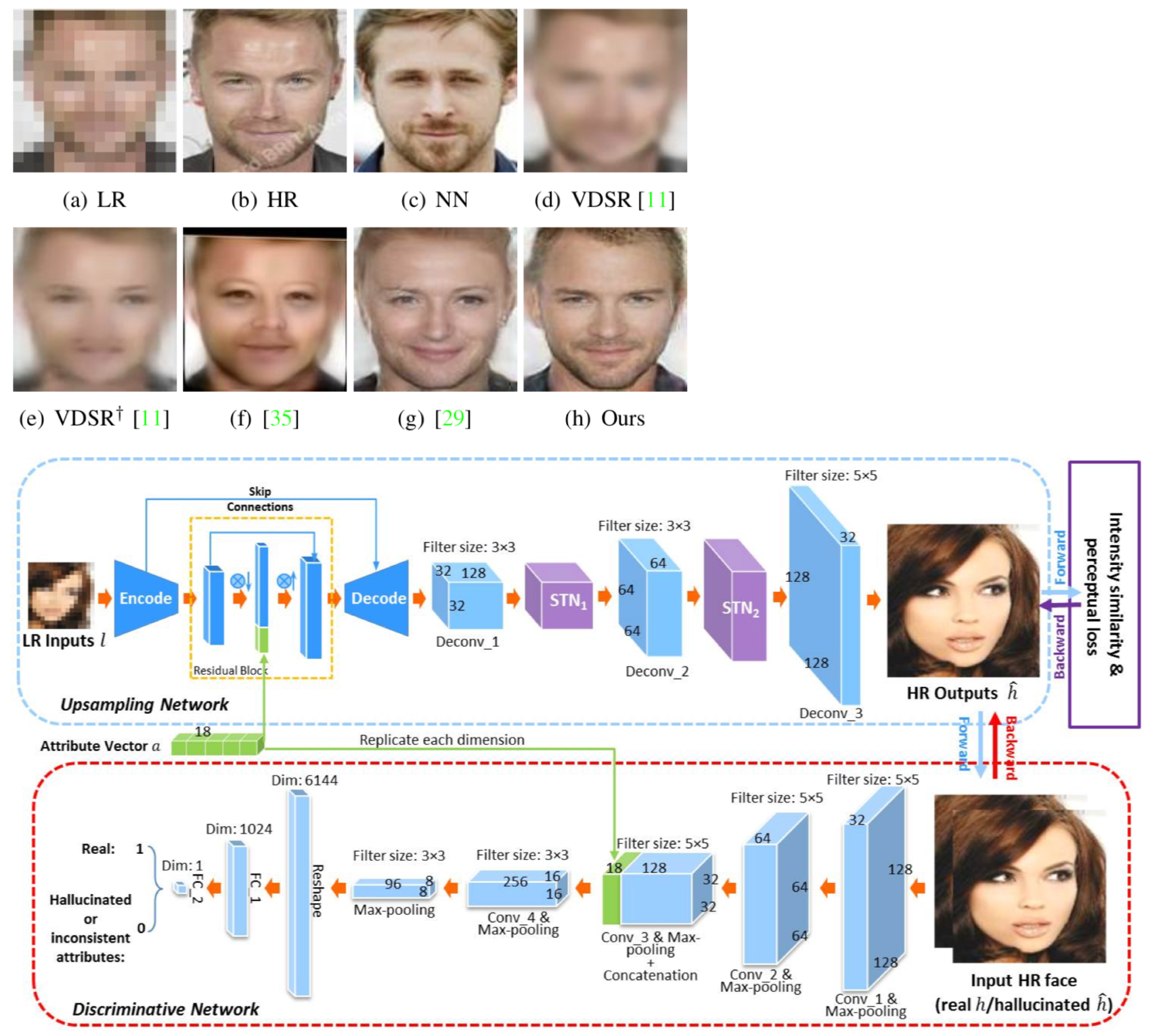
Detection with Enriched Semantics (DES)というシングルショットオブジェクト検出器を提案.セマンティックセグメンテーションブランチとオブジェクト検出ブランチで構成. セマンティックセグメンテーションブランチとグローバルアクティベーションモジュールによってオブジェクト検出の特徴であるセマンティクスを向上. 既存のSSDなどのシングルショット検出器よりも速度と精度が向上.
光の反射やシェーディングなどを再計算することで自然画像の分解と再構成(Image Decomposition)を行う問題設定である。従来型の事前情報を陽に与えるフィルタリング手法とは異なり、深層学習による提案手法では(十分なラベル付きデータが存在すれば)画像の内的な情報を効果的に捉えて画像の再構成をより自然に行うことができると主張。この問題を解決するために、2種類のカテゴリに関する問い ー(1)詳細なラベル付きデータ(2)弱教師付き学習により比較的多様なラベル付きデータを学習ー を解決することができる。これにより学習データには詳細なラベル付けを行わず弱い事前知識(Loose Prior Knowledge)のみで大量のサンプルを準備することができる。手法面において、最初は荒く光の反射(Albedo)やシェーディングを推定し、次いでエッジやテクスチャ等を推定できるようにフィルタリングを学習する。
主要な画像再構成のベンチマークにおいて全てState-of-the-artの(最先端の)結果を達成した。さらに、従来まではデータセットに対してアドホックである(と思われる)が、本論文にて提供するデータや手法はよりオープンかつリアルな問題に対して汎用的に使用できる。弱い事前知識のみでリアルデータを学習できるようにしたことも新規性として挙げられる。CVPRの査読を突破できた理由として、State-of-the-artな精度を全てのデータにて達成したことや、その学習法/アーキテクチャの提案にあると考える。
光の反射(Albedo)や陰影(shading)を同時に推定できる技術はよりリアルな画像の生成には重要技術なのでどんどん進んで欲しい。
単眼顔画像からリフレクタンス、ジオメトリー、照明情報を推定する研究。トレーニングデータには上記の情報のアノテーションを必要とせず、3D Morpahlbe Modelを使用することで高品質な3Dパラメトリックモデルを生成。 3D Morpahlbe Modelを使用することで高品質な3Dパラメトリックモデルを生成。 テスト時には250Hz以上で実行することができる。
ユーザが色,スケッチ,テクスチャから深層画像合成を行うTextureGANを提案.既存手法では,カラーやスケッチによる制御を行っているが今回の手法ではユーザがテクスチャパチをスケッチ上に配置することによってテクスチャによる制御を実現.
TextureGANをローカルテクスチャで制約することにより,テクスチャとスケッチベースの画像合成の効果を実証.
別のテクスチャデータベースから抽出されたテクスチャから生成されたスケッチを用いて実験を行い、提案アルゴリズムがユーザコントロールに忠実な妥当な画像を生成されることを確認.
入力された動画が生身の人間によるものか、あるいはそれ以外のspoofing(撮影された動画や顔のプリントなど)を判定する研究。空間的な情報として顔のデプスマップ、時間的な情報としてrPPG(信号のパルス信号)。 CNN-RNNモデルを使用しCNNでデプスマップと顔の特徴量マップを、RNNは各時刻でCNNによって推定された顔の特徴量マップを入力としてrPPGを推定する。 既存研究では様々なパターンのspoofingがあるにも関わらずCNNによるバイナリの識別問題として捉えていたため、CNNの広すぎる空間を学習してしまい結果的に過学習をしてしまっていた。 提案手法では補助的な情報としてデプスマップ、rPPGを使用することで識別精度を向上した。 更に165の被写体に対して様々な照明環境、ポーズ、表情、顔むきごとの動画を収集し、anti-spoofingのためのSiWデータベースを構築した。
1クラス分類の際のノベリティ検出のために2段階のネットワークを構築.1つのネットワークはノベリティの検出をし,もう1つでは,inlierを強化しoutlierを歪ませる. 画像と動画で検証.
画像空間上ではなく、特徴空間上でデータ拡張(Data Augmentation)を行う研究である。この課題に対して著者らは特徴空間上で物体姿勢/見え方のバリエーションを多様体として考慮するFeature Transfer Network (FATTEN)を提案。従来の特徴空間上でのデータ拡張とは異なり、提案法であるFATTENはEnd-to-Endでの学習が可能であり、より効果的にデータ拡張を実行可能である。同ネットワークは姿勢やカテゴリの多タスク学習により学習を行う。図は直感的な特徴空間上での挙動を示したもので、Pose/Appearanceにおける特徴空間の動線を把握した上でデータ拡張を行うことができる。One-/Few-shot学習でも効果を発揮し、特にOne-shotでは他を大きく離して優れていることを示した。
新規性としては複数の属性(ここでは姿勢・アピアランス)を同時に考慮しながら特徴空間上でデータ拡張を行える点が新規性としてあげられ、さらに関連研究と異なるのはEnd-to-Endで学習できる点も優れている。直感的にはビューポイントの違いとそれに対応するアピアランスを拡張する形で特徴学習ができていると言える。FATTENを適用しModelNet/SUN-RGBDのデータセットにてデータ拡張を行った結果、はっきりとした精度向上を確認した。
RotationNetとの比較や統合(RotationNet+FATTEN)が気になる。もともとこの論文で扱っている問題に対して精度が高いRotationNetに本論文のデータ拡張手法を使用するとさらに大きく精度向上するのでは?
Extreme pointを用いた物体セマンティックセグメンテーション法.このExtreme pointは,セグメンテーションの上端,下端,右端,左端を使用している. 4つのExtreme pointは,物体の大まかな形状の情報を取り込みながらCNNを学習することができる. Pascal VOC, COCO, DAVIS2016, DAVIS2017, Grabcutで評価し,どのベンチマークにおいても高い性能を示している. また,セマンティックセグメンテーションのアノテーションツールとして応用できることも示している.
使用するネットワークは,ResNet101をBackboneにしたDeepLab-v2である.提案手法のDeep Extreme Cutでは,Extreme pointを有効的に学習するために,点にガウシガウシアンを施してヒートマップを作成し,そのヒートマップを入力画像のチャンネルに追加している. この学習方法は,様々なタスクのセグメンテーションに有効であり,セマンティックセグメンテーション,動画のセグメンテーション,インスタンスセグメンテーション,インタラクションセグメンテーションに応用することができる. また,セグメンテーションのアノテーションツールにも応用でき,従来のアノテーションコストを10分の1まで削減できていることを示している.
徐々にダウンサイジングしながらも詳細な情報は保持するという問題設定を解決するDNN、特に微分可能なプーリング手法であるDetail-Preserving Pooling(DPP)を提案する。同ネットワークでは隠れ層にて徐々にダウンスケールを行う。図にはフローチャートが示されている。このように線形ダウンスケーリングを施した画像に対して、出力が情報量をできる限り失わないように学習できるプーリングを提案することで任意の畳み込みネットに対して性能向上を見込める手法とした。
データセットにより最良なプーリングの手法が異なるという欠点を解決するべくDPPを提案した。また、グラフィクスの分野にて提案されているDPID(文献31)を参考にして微分可能(学習可能)なプーリング手法を提案した。このようにして作成されたプーリングはあらゆるネットワークに対し有効にフィットし、(max/average poolingなどより)精度向上を保証すると主張した。例として単純にResNet-101のアーキテクチャのプーリングを置き換えてもCIFAR10にてエラー率が下がっている。このように学習可能であり、汎用的に使用できて高精度が期待できるプーリング手法を提案したことが採択された理由であると考える。
従来の単一画像の超解像手法では,低解像度の画像は,高解像度の画像からのバイキュービック的にダウンサンプリングされたものであるという仮定を置いている.そのため,この仮定に従わない場合,性能が低下する.さらに,複数の劣化に対処するスケーラビリティーも欠けている.本論文ではこれらの問題に対処するため,畳み込み超解像ネットーワークに低解像度画像とdegradation map(ブラーカーネルとノイズレベルから作成)を入力する方法を提案している.

畳み込み超解像ネットワークにブラーカーネルやノイズレベルも入力しようとすると,低解像度画像とのサイズの違いによりネットワークの設計が困難になる.本論文では,dimensionality stretcing strategyを導入することによりこの問題を解決した点が新しい.
劣化されたSet5などのデータセットに対して,従来法や提案手法を適用し,PSNRとSSIMにより評価した結果,提案手法が最も良い結果を示した.
任意の向きの低解像度顔画像に対して超解像度化する研究。生成された超解像度画像に対してランドマーク推定を同時に行うことで画像の精度が良くなることを主張。顔画像の高解像度化の際にランドマークを特定することは有用であることはすでに示されていたが、低解像度かつ任意の顔向きの際にはランドマークを使用して高解像度化することが難しかった。提案手法ではGANによって低解像度顔画像から超解像度化された顔画像を生成し、生成された顔画像に対してランドマークのヒートマップを推定を推定することでネットワークの学習を行う。

入力されたLDR画像に対する露光量の調節をend-to-endに行う研究。2つのU-Netを使用し、LDR画像からHDR画像の推定と、推定されたHDR画像からLDRドメインへの変換、という2つ学習によって実現する。LDR画像に内包されている問題として、露光量が少ない箇所ではピクセルが黒く塗りつぶされてしまい、実際のシーンにおける色の推定が難しいという問題がある。そこで、LDR画像から一度HDR画像を生成することで、塗りつぶされた領域を修復する。
![]()
学習サンプルに少ないような質問に対しても回答ができるような手法を提案.ベースはMemory-Augmented Network (One-shot learningを導入したMemory Network)であり,記憶ブロックとAttentionの機能により,稀に発生する質問に対しても正確に回答をすることができる. VQA benchmark datasetとCOCOのVQAタスクで評価し,高い性能を示している.
この手法の大まかな構造はMemory-Augmented Networkになっており,特徴抽出部分が質問文と画像特徴である.画像特徴はVGGやResNetの特徴マップを使用しており,質問文はLSTMの特徴ベクトルを使用している. この2つの特徴ベクトルは結合され,質問と画像特徴の2つのAttentionがそれぞれ与えられてAugmented memoryに格納される. そして,Augmented memoryを用いて最終的な回答が出力される. 提案手法では,右下図のように,稀に存在する困難な質問に対しても正確な回答を得ることができる.
Deep Neural Networkにおける,層間の結合に関して様々な検討を行った論文.従来のネットワーク(ResNet, DenseNet, FCN, U-Net等)のスキップ結合は,”浅い”結合しか適用されていなかった. この論文では,より”深い” 結合をネットワークに取り入れ,少パラメータかつ高精度なネットワークモデルを構築している. 画像分類をはじめ,様々な認識タスクで実験を行い,高精度化を実現している.
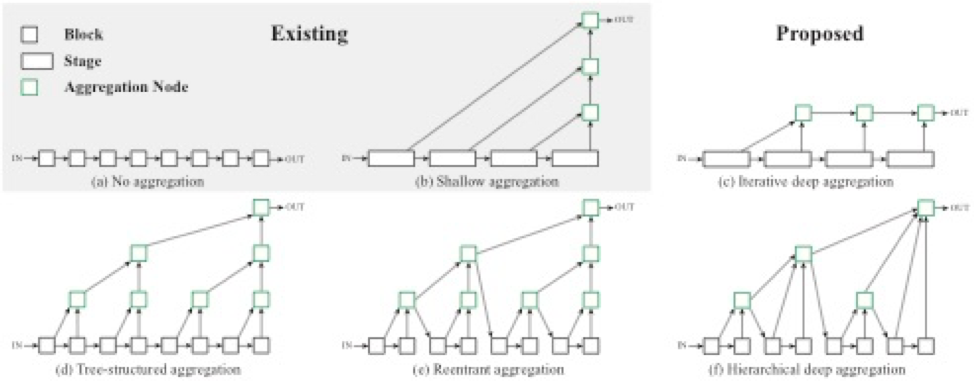
この論文では,右図のような4つのモデルを検討している(c~f).(c)のようにシンプルに特定の層を集約して連鎖的に入力していくモデルから,(d~f)のように様々な層を集約して連鎖的に集約していくモデルを検討しており,上位層と下位層の層を効率的に伝播することで,認識精度を向上させている. また,(c)と(f)のモデルを組み合わせることで,より性能を向上させることも可能である. 画像分類,Fine-grained Recognition,物体検出,セマンティックセグメンテーションで実験を行っており,全ての認識タスクにおいて高い性能を示している.
ラベル付きとラベルなしデータを用いることで画像認識の精度を向上させるData Distillationを提案.この手法では,self-trainingとHinton先生のKnowledge distributionをベースに提案されている. この手法は,インターネット上のラベルなしデータを大量に学習できる. この論文では,Mask R-CNNによる人のKeypoint検出と,FPNをbackboneにしたFaster R-CNNによる物体検出で高精度化を実現している. (COCOをラベル付き,Sports-1M statistic framesとCOCO2017unlabel imagesをラベルなしデータとして使用.)
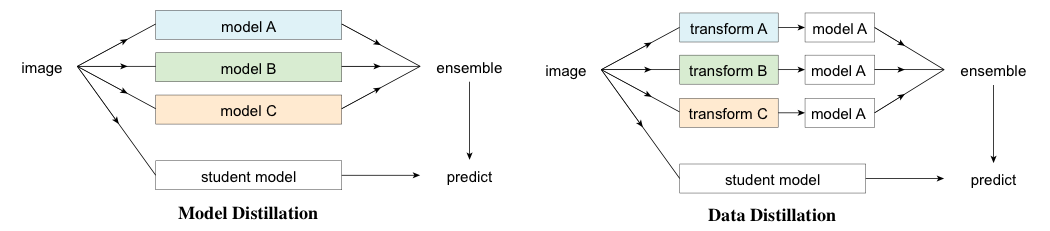
一般的なラベルなしデータを扱うModel Distillationとは異なり,Data Distillationは1つのteacher modelとstudent modelを用いる.構造としては,1つの画像を複数の単純な変形を加え,それぞれの認識結果を得る. そして,それぞれの認識結果を統合し,統合した認識結果をラベルとしてstudent modelを学習する. ここで,学習に使用するラベルは”soft”なラベルではなく,”hard”なラベル.COCOをベースに実験をしており,ラベルなしデータを併用することで人のKeypoint検出と物体検出で高精度化を実現している.
一人称(First Person View; 頭部にカメラを装着して撮影)かつ三人称(Third Person View; 環境に設置したカメラから撮影)の視点から人物行動や操作している物体を撮影したデータセットCharades-Egoを提供する。一人称/三人称視点は互いに対応付けされており、実に157の行動カテゴリ、112人の実演、4,000の動画ペア、全8,000動画を保有するデータベースの構築に成功した。手法の側面ではTripletによる弱教師付き学習(Weakly-supervised Learning)により一人称/三人称から抽出した複数の特徴量を評価する枠組みActorObserverNetを提案する。さらには、三人称から一人称視点への知識転換(Transferring Knowledge)をZero-shot行動認識の枠組みで実行する。
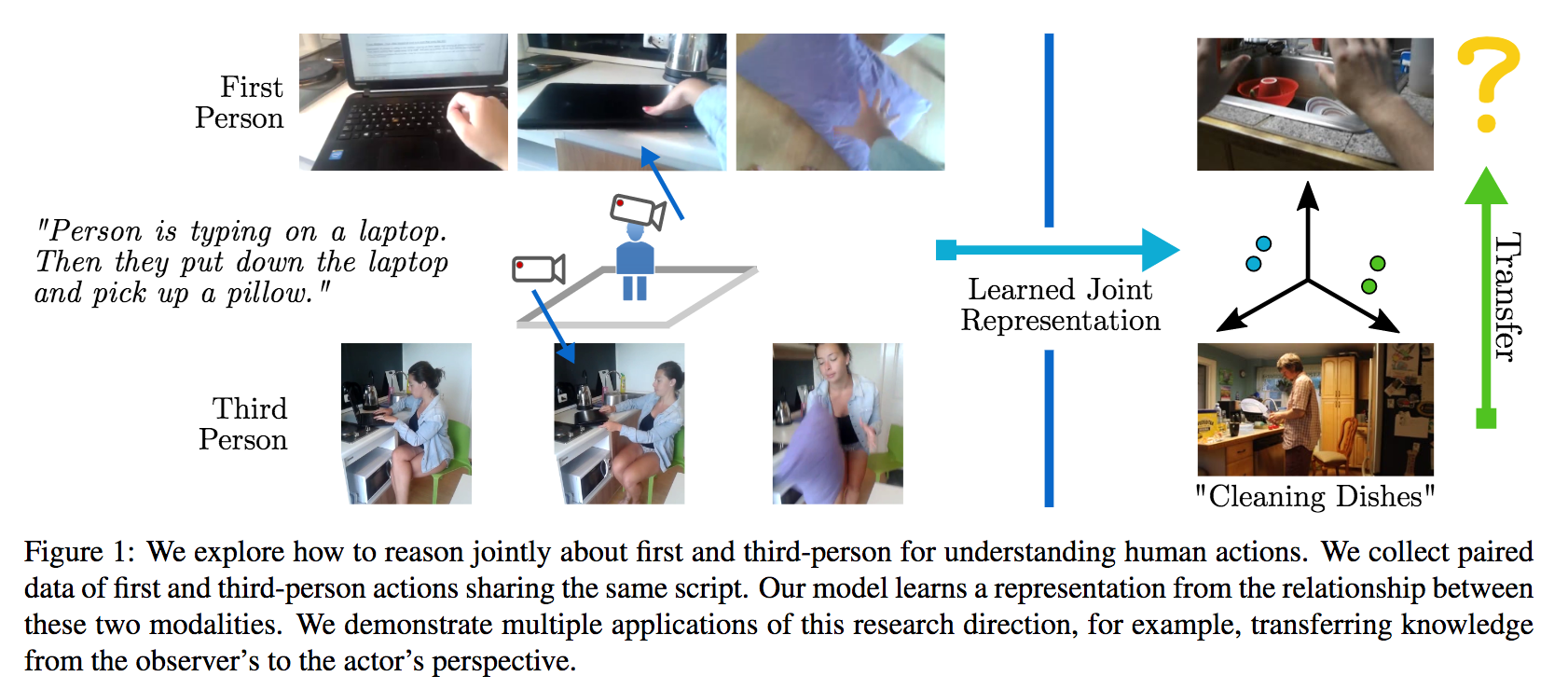
一人称/三人称は従来独立に撮影されて、それぞれのデータベースを構築して来たが、ここでは同時解析することにより行動に関するより詳細な考察(e.g. 間接的に行動を観察した方が良い vs. 操作している物体で行動を認識する方が良い)を行えるようにした。また、弱教師付き学習により特徴学習できるActorObserverNetを提案した。CVPRに通った理由はなんといってもデータベース(とそのベンチマーキング)、弱教師付き学習によるものである。
Hollywood in HomesのようにAMT(クラウドソーシング)にてユーザがフリーで使用を許可した動画を収集するのはアリにしている。公開してフリーにしても良い人だけの動画を効率良く集める仕組みが今後流行ってくるか?(ただ日本だと難しいかも?)データベースに対するベンチマーキングは若干少ない印象を受けるが、データベースの意義自体が優れているため査読を突破したと思われる。
モーションセグメンテーションの問題を扱う。従来のモーションセグメンテーションは幾何的制約を設けることで効果的に動作をセグメントして来たが、高次なセグメントに失敗していた。一方でCNNについては従来方とは逆の特性があった。この両者の特性を活かして、両者にとって良いところどり(The Best of Both Worlds)することでモーションセグメンテーションの性能を向上させた。手法は図に示すようにオプティカルフローを用いた剛体の動き推定(Perspective Projection Constraints)、変形可能でより複雑な物体形状を推定できるようCNNによるセマンティックセグメンテーションを実行。物体のモーションモデルを形成するために、SharpMask(論文中文献35)による物体候補も導入し物体に関する知識を導入した。
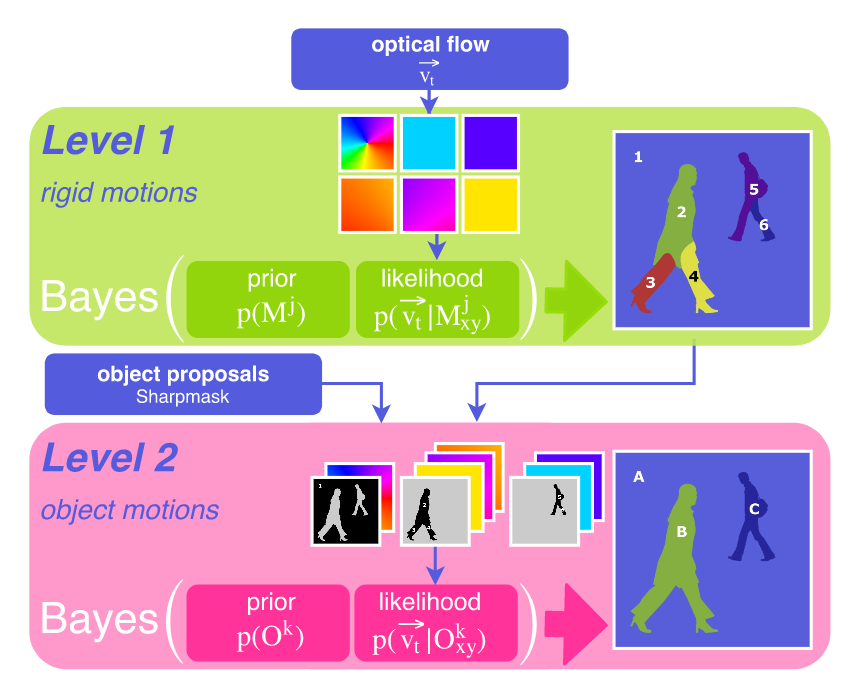
クラシカルなフローによる剛体モーション推定とCNNによる物体セグメンテーションを統合、両者の良い部分を引き出しているところが評価に値した。アブストラクト/図1が非常にわかりやすくこの2つで問題設定を把握できるところもグッド。
encorder/decorderモデルにhiden stateと過去のhiden stateを再構成することによって隣接するhiden stateの接続を強化するためのARNetを導入.

群衆に頑健な歩行者検出法を提案.Faster R-CNNで群衆を検出したとき,歩行者同士の間にBounding Boxが出現しやすい. これは,Bounding Box回帰の誤差を算出する時に誤差を最小にしようとして歩行者同士の間にBounding Boxが発生してしまう. この現象を解決するために,新たにRepulsion Lossを導入し,群衆に対しても高精度な歩行者検出を実現している.

Repulsion Lossの中身は, L1 smooth lossをベースにしたL_RepGTとL_RepBoxから構成されている.L_RepGTは,targetの歩行者付近から最も近いGTとの誤差を示しており,targetと最も近いGTにBounding Boxが検出されると誤差が大きくなるように誤差が設計されている. L_RepBoxは,複数のBounding Boxが特定の箇所に集中するように誤差を設定している. L_RepBoxの目的は,NMSの割合の影響を減らすためである. 歩行者検出のCaltech, CityPerson(Cityscape)でstate-of-the-artな性能を出しており,Pascal VOCにおいても有効であることを示している.
歩行者検出のベンチマークにおいて非常に高い性能を示しており,ResNetベースのFaster R-CNNに対してDilated Conv.を導入する等のちょっとしたテクニックも色々導入されている.
複数のデータセットを1つのネットワークで学習する場合,通常は過去に学習したデータセットは段々と精度が低下していく.これは,全てのパラメータに対して更新するため,過去に学習したデータセットの特徴を抽出できなくなっていくのが原因である. この論文で着目していることは,大規模なネットワークは特定のパラメータは学習をサボる傾向があるところであり,このサボっているパラメータを使って効率よく学習させて複数のデータセットを学習させている.
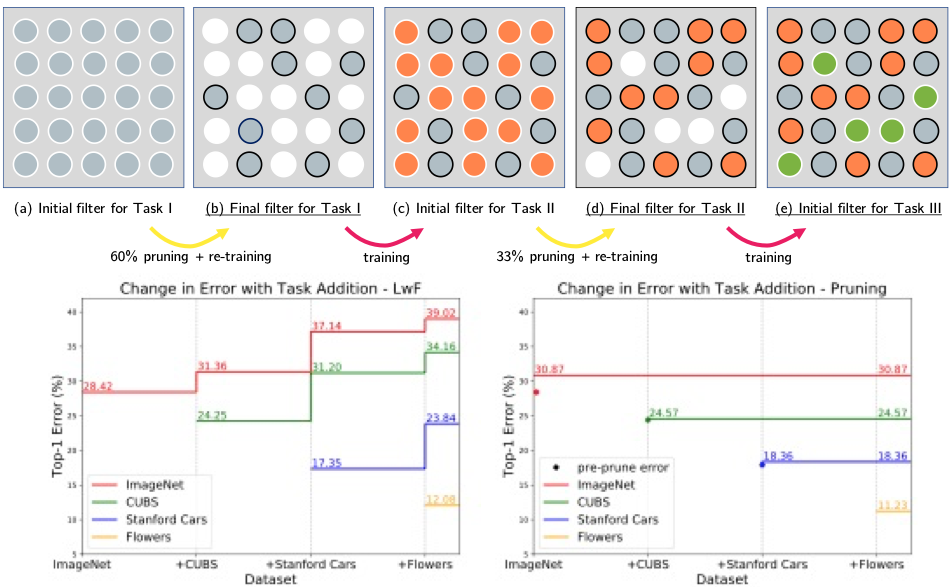
手法自体は非常にシンプルであり,特定のパラメータをプルーリング(右上図の白領域)して再学習する.そして,プルーリングしたパラメータのプルーリングを解放してパラメータをアップデートする. 特定のタスク(データセット)を学習した後は同じ要領でまたプルーリングと再学習を行う. 特定のパラメータを特定のタスクに割り当てるような学習をすることで,複数タスクに対応している. 結果としては,右図のようにタスクが追加されても性能がほとんど低下していない.
弱教師あり学習で得られる物体のローカライゼーションを高精度にする研究.方法としては2つ提案しており,

1)の方法では,2streamなCNNをベースにしており,入力はそれぞれ通常の画像と,GAPのローカライゼーションから物体領域を排除した画像を入力する.この処理により,物体と背景を明示的に学習できる. そして,セマンティックセグメンテーションでは, 1)のネットワークに加えて,セマンティックセグメンテーションのラベルと出力したAttention mapとの誤差を算出させることで,Attention mapを最適化させる. Pascal VOCのweakly-supervisedによるセマンティックセグメンテーションのタスクで評価し,高い性能を示している. また,発生するAttention mapの領域に対してオリジナルのデータセットを作成して評価している.
一般的な顔(物体)検出法(Faster R-CNN, FPN, SSD, YOLO等)は,Backboneな部分がFCNベースで構築されているため,各ピクセルを密に畳み込んで検出結果を出力する.しかし,顔検出では背景領域を大量に含んでおり,検出に必要な領域はごく僅かである. 本論文では,顔検出を効率化するために,2つのAttentionを適応して高速化を試みており,左上図のように高い性能を維持しつつ,4倍以上の高速化を実現している.
本手法で適応しているAttentionは,右上図のようなspatial attentionとscale attentionである.spatial attentionは2次元上における顔の位置を示しており,scale attentionは出力されたスケールピラミッドから最適な特徴マップをAttentionで表現している. spatial attentionは2次元の位置のattentionから探索する領域を制限するために使用し,scale attentionは探索するスケールピラミッドを制限するために使用する. ネットワークは下図のようになっており,2つのAttentionにより背景と判定された領域は,マスクされた状態で後段のMask FCNに入力される. AFW, FDDB, MALFでstate-of-the-artな性能かつ,高速な検出が可能(最速で14.2ms).
Attentionを計算コスト削減に適応した物体検出法.顔検出や車載系の物体検出等の背景領域を多く含む問題設定では非常に効果的に使えそうな手法. (COCO, VOCではあまりコストに対しては言及していない)
既存の学習ベースの3D面推定方法は,End-to-Endでの学習ができないが,本研究では,end-to-endでの学習を可能にした.3D面推定手法の一つのマーチングキューブは微分不可.そこで,代替の微分可能定式化を行い,これを3DNNの最終層として追加する. また,疎な点群で学習が行えるようにロス関数群を提案. サブボクセル精度での3D形状を推定可能であることを確認した. 本モデルは形状エンコーダ・推論と組み合わせられる柔軟さがある.
End-to-endで行われたものはない.適用範囲が広そう.
近年,条件付き画像生成や機械翻訳において畳み込みニューラルネットの功績は大きい,これを画像キャプションに応用してみた.ベースラインであるLSTMモデルと同等の精度を示し,パラメータ数ごとの学習時間の短縮をすることができた.
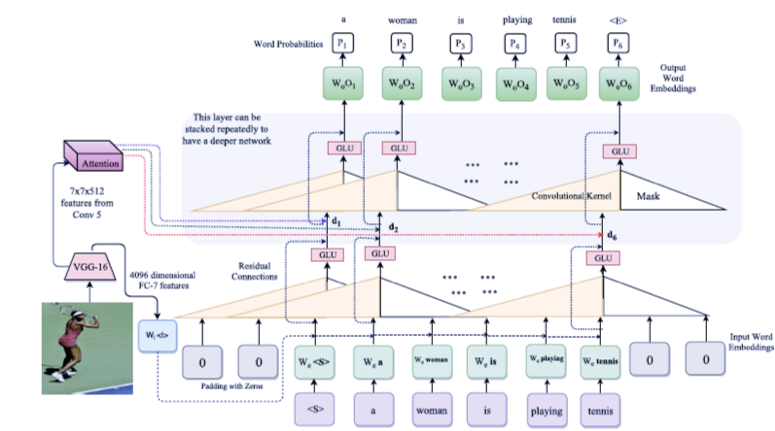
・強化学習とGANを用いたVisual Dialog回答文を自動生成する手法の提案.・従来のVisual Dialogシステムは画像とDialog履歴に基づきMLEにより回答文の予測を行う.こういった手法では回答文が短い,バリエーションが少ないなどの問題点がある.そこで, co-attentionを利用したジョイントで画像, Dialog履歴をreasonできる回答文生成器を提案した.提案モデルはsequential co-attention生成器と回答文が“human”からか“生成された”かを弁別できる弁別で構成される.
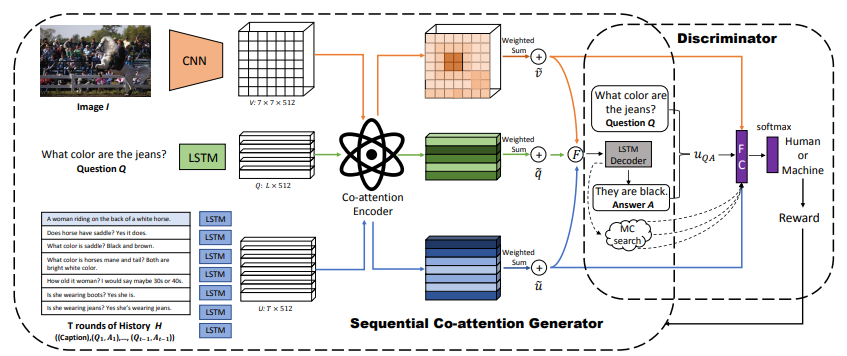
・GANを用いた提案手法はVisual Dialogタスク従来の学習データの不足,簡潔な回答しか生成できないなどの問題点を改善した.・attentionをGANと組み合わせ, 生成回答文のinterpretabilityを向上した ・ VisDial データセットにおいて,従来の手法より高い精度を達成した.
・ 三次元センサーにより取得したPoint Set の密度の変動を対応できるPoint Set Registrationの手法を提案した.・従来の三次元センサー(例Lidar)により取得できるPoint Setの密度が均一ではない,一方,従来の確率的Point Set Registrationの手法は高密度の部分を対応させ,低密度の箇所の対応が重視されない問題点がある.提案手法はシーン構造の確率分布をモデリングすることにより,密度の変化にロバストに対応できる. ・提案手法は3次元シーンの構造及びフレーム間のカメラ移動量を同時にモデリングし, EMベースなフレームワークに基づきKL divergenceを最小化によりパラメータの最適化を行う.

・Lidarを用いたregistrationシステムのPoint Setの密度変化をロバストで対応できた.・ DAR-ideal、 VPS and TLS ETH datasetsなどのLidarデータセットで従来の確率的マルチビューRegistration手法より良い性能を達成した.
カメラ姿勢推定,3次元復元に使われるバンドル調整では,適した初期値を与える必要があるが,初期値を与える必要を無くす提案をする.
アフィンバンドル調整問題においては,任意の初期化から到達可能な使いやすいminimaがあることが知られているが,その主な要因は,収束のワイドな領域を持つことで知られているVariable Projection(VarPro)法の導入によるものである.本研究ではPseudo Object Space Error(pOSE)を提案する.これは,アフィンと射影のモデルのハイブリッドで表現される複数カメラにおける目的関数である. この定式化で,VarPro法に適したバイリニア問題構造となり,真の射影復元と近い3D復元結果を得られる. 実験では,ランダムな初期化から高い成功率で正しい3D復元を得られることを確認した.

ランダム初期値でもメトリックの正しい3D復元が行える.
GANを用いて画像中の顔を検出する研究。検出が難しい顔として小さくかつボケている顔が挙げられるが、これらの顔をGANによって高解像度かつはっきりとした顔にすることで検出精度を向上させる手法を提案。 generatorは高解像度にするsuper resolution network(SRN)と顔の詳細な情報を復元するrefinment network(RN)を結合したネットワークである。 discriminatorはVGG19であり、ロスとしてデータセットの顔/generatorによる顔、顔/顔ではないモノを同時に行うロスを導入。 またよりはっきりとした顔を生成するために、generatorのロスとして物体識別のロスを導入。

・コンテキスト情報の抽出を利用したセマンティックセグメンテーションの効率を上げられるContext Encoding Moduleを提案した.・従来の階層式シーンの高レベルから低レベル特徴の抽出を行うネットワーク(eg. PSPNet)にはシーンのコンテキスト情報の抽出がexplicitではない問題点があり,従来のグローバル特徴抽出ネットワークの知識から,シーンのコンテキスト情報を抽出することにより,セマンティックセグメンテーションの効率を上げられるモジュールを提案した. ・具体的には:Encodingによりシーンのコンテキスト情報をキャプチャーし,クラス依存の特徴マップを選択的に強調表示できるContext Encoding Moduleを提案した; Semantic Encoding Loss (SE-loss)を提案した; Context Encoding Moduleを利用したセマンティックセグメンテーションネットワークEncNetを提案した
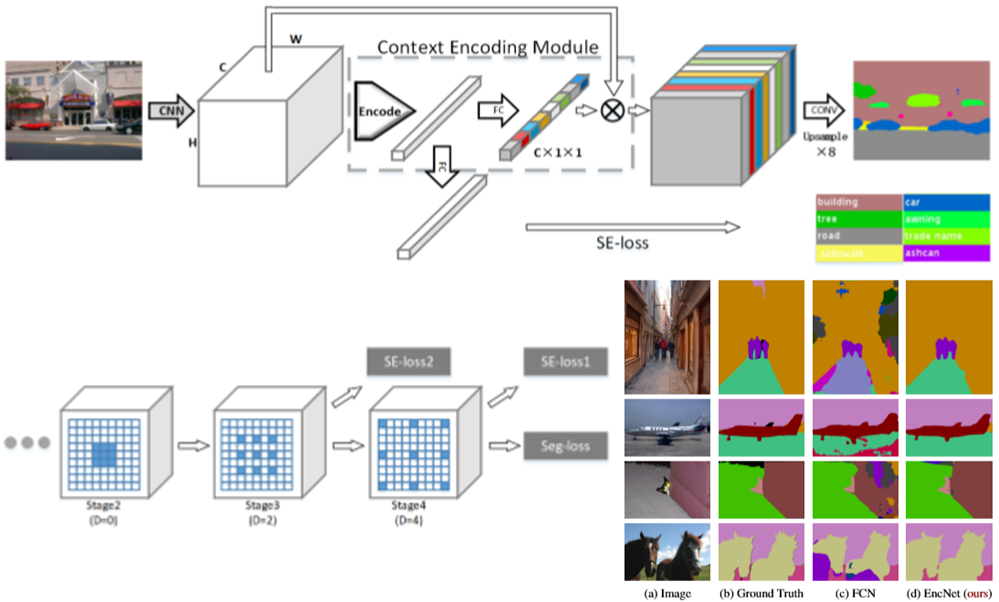
・ PASCAL VOC 2012において85.9% mIoUを達成した・提案ネットワークをCIFAR-10 datasetに応用し,14層だけのネットワークで100層超えのネットワークと同じレベルの精度を実現した
人間が動いている単眼のRGB映像から、正確な3次元物体モデルと任意の人物テクスチャを得る研究。仮想現実や拡張現実、監視やゲームなどの人間の追跡にはアニメーション可能な人間行動の3Dモデルが必要である。この研究では、動的な人間のシルエットに対応するシルエット形状を見つけ出し、テクスチャや骨格を推定して、アニメーション可能なデジタルダブルを作成することができる。
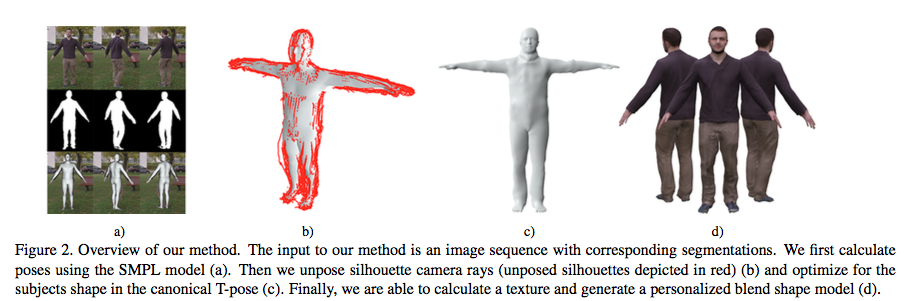

(a). SMPLモデルを用いてポーズを計算(b). シルエットの赤で描かれていないシルエットを取り除く (c). 正規のTポーズで被写体の形状を最適化 (d). ティクスチャを計算しパーソナライズされた好みの形状を生成 ・単眼のRGBビデオから髪や衣服を含む現実的なアバターを抽出 ・被服を含む4.5mmの精度で人体形状を再構成
・マルチオブジェクトのアピアランス特徴及び幾何情報間の関係を取り扱える,様々なタスク(物体検出,VQAなど)に用いられるObject Relation Moduleを提案した.・最近attentionに関する研究が発展し,著者たちがattentionモジュールがelement間の依頼性を学習できる面から,物体検出に応用できるアテンションモジュールを提案した. ・提案モジュールを物体検出の2つの段階に応用できる:インスタンス認識段階で提案モジュールによりオブジェクト間の関係を習得でき,精度を上げられる;duplicate removal段階で提案モジュールにより有効的に物体領域を抽出できる.
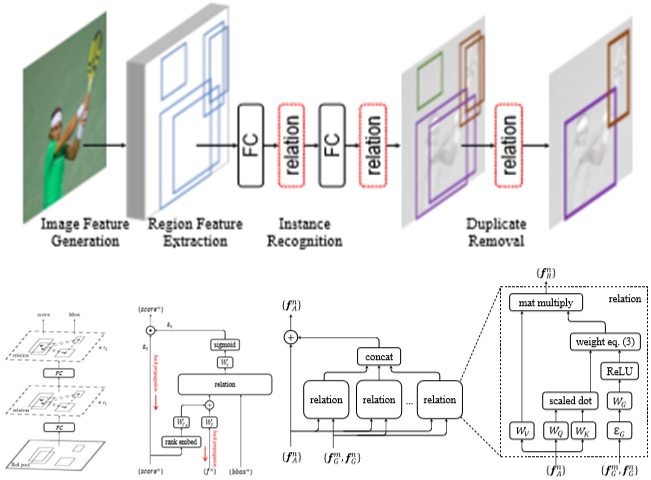
・従来の物体検出手法は物体ごとに推定を行い,物体間の関係を利用しない.提案手法はObject Relation Moduleを提案し,物体間の関係を学習することで,物体検出の精度を更に向上した.
点群データから直接3Dの局所特徴量を抽出するネットワークを提案.N-Tuple loss(Triplet lossの拡張)によって, 対応点間の特徴量が近く,それ以外の特徴量間の距離が遠くなるような変換を学習する. PPFNetの入力は局所パッチ内の点の座標,法線,Point Pair Featureをまとめたデータ. ネットワークの内部ではPointNetを利用する. 大域的な情報を得るために,各パッチから取得した局所特徴量を Max poolingによって大域特徴量化し,局所特徴と結合する工夫も入れている.
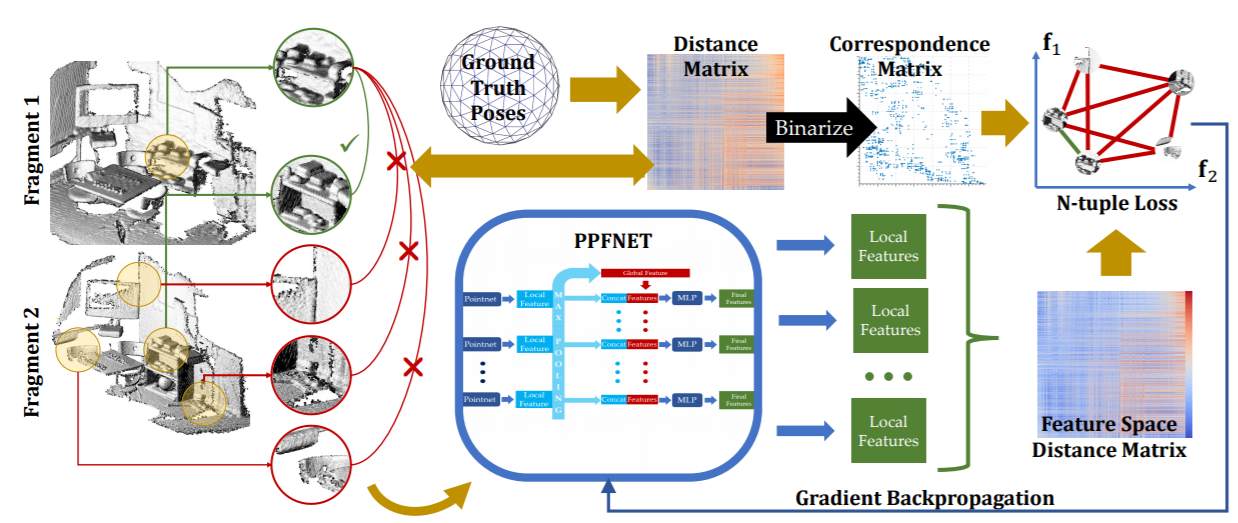
局所特徴量を生成するネットワークを構築した点,N-Tuple lossによる学習法を提案した点が新しい. キーポイントマッチングのベンチマークでRecall rateが向上. オーバーラップが少ないシーンでのレジストレーションも可能になっている.
既存のGANでは考慮されていなかった形状や位置といった幾何学的情報をGANの生成プロセスに組み込んだGeometry-Aware Generative Adversarial Networks (GAGAN) を提案.具体的にGAGANでは,ジェネレータで統計的情報な形状モデルの確率空間から潜在関数をサンプリングする.次にジェネレータの出力値を微分可能な幾何学変換を介して標準座標系にマッピングすることで,物体の形状や位置といった情報を強制し,生成を行う.

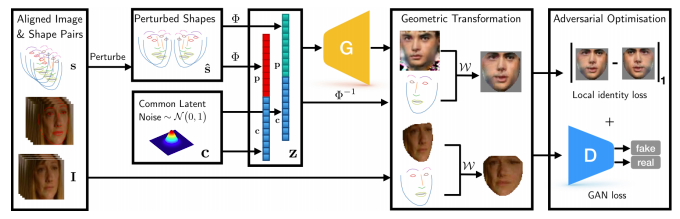
今後は,(i)より大きな画像の生成,(ii)アフィン変換によって起こりうる変形を緩和するより複雑な幾何学的変換の探索およびそれによるGAGANの拡張,(iii)顔のランドマーク検出のための従来CNNアーキテクチャの拡張に取り組む予定
・新たな問題設定ー動的環境とインターアクトしながら視覚質問に答える(IQA)を提案した.・具体的には, IQAには4つの設定がある:環境でナビゲートする能力;環境中のオブジェクト,アクション及びアフォーダンスの理解;環境中のオブジェクトとインターアクトする能力;質問文に応じで環境での行動を計画する能力. ・提案の問題設定を解決するために,階層的マルチレベルで行動計画及びコントロールするネットワークHIMN及び空間的かつセマンティックなメモリを実現できる新たなrecurrent layer形式Egocentric Spatial GRUを提案した. ・更に,75000質問及びCGシーンを含んだデータセットIQUAD V1を提案した.
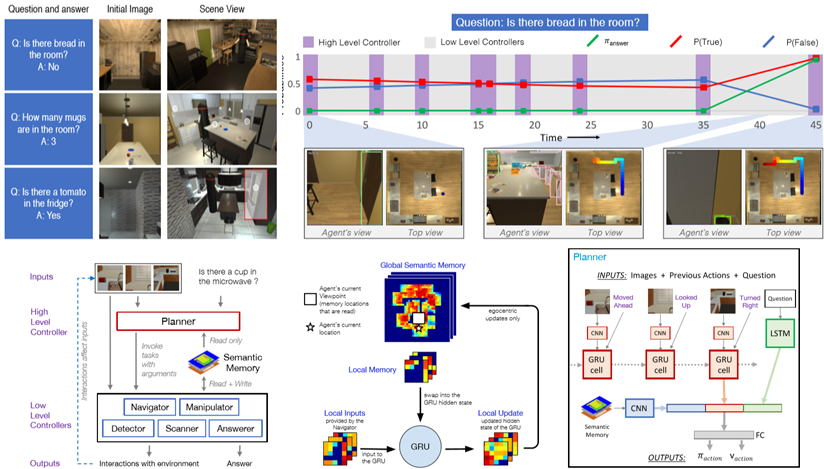
・従来のVQAタスクをCGシーンでの自己ナビゲーションと組み合わせた新たな問題設定を提案した.・IQUAD V1で従来の手法よりstate-of-the-artな精度
・従来のVQAタスクに更に環境での探索および環境中オブジェクトとのインターアクトを取り入れ,従来の問題設定より一層現実に近づいている.・質問文の自動生成にも応用できそう ・特に色々なタスクを取り扱えているので,技術の面では向上する空間がありそう
adversarial attackに対するロバスト性の評価を, semantic segmentationにおいてstate-of-the-artな性能を持つネットワークを用いて実験した.Pascal VOCとCityscapesのデータセットに対して, FGSM, Interative FGSM, FGSM II, Interative FGSM IIで攻撃したときのIoU Ratioによりロバスト性を評価した.
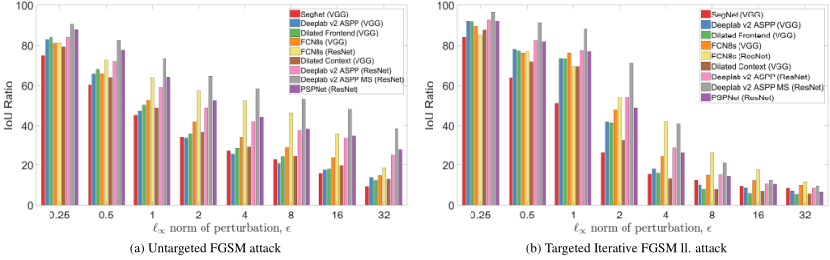
・RGB画像の強度データと少数のパラメータを条件に,ほぼリアルタイムで行えるデンスなシーン幾何を推定手法を提案した.・提案手法UNet構造により強度画像の特徴抽出を行い,更に抽出特徴をauto-encoder構造を用いたデプス情報推定ネットワークに入力することで階層的にデプス情報推定を行う.また,カメラ移動中得られるマルチフレームに対し,フレームごとのデプス推定及びフレーム間のカメラモーションをジョイントで最適化を行う.
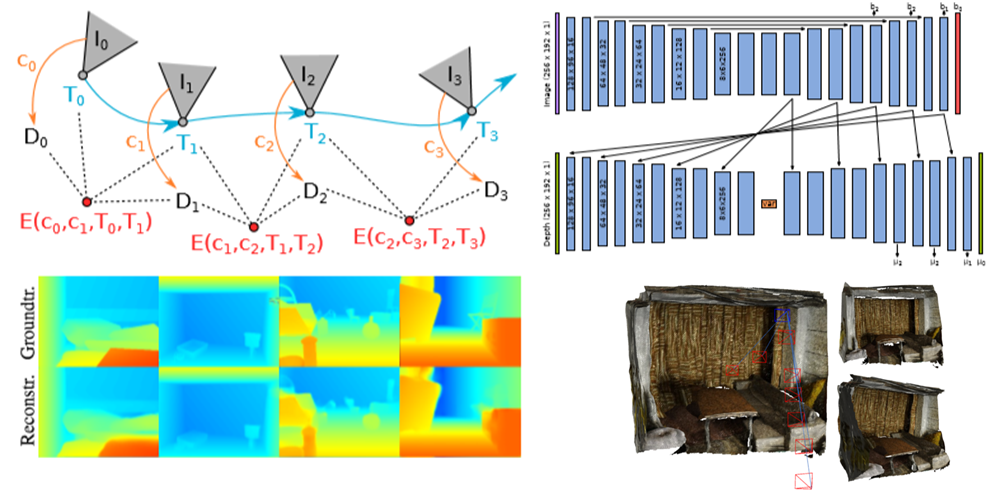
・デンスなデプス情報推定を行うことでSLAMシステムの更なる精度向上できると宣言した.・初めてのほぼリアルタイムで行えるカメラモーションとシーンのデンス幾何をジョイントで推定する研究である.
・VQAタスクに用いられる新たなインターアクティブ学習フレームワークを提案した.・提案フレームワークは入力画像から,question proposal moduleにより問題集を生成し,画像との相関性を基準に問題集をフィルタリングし,残った問題をVQAにより解く.予測した答え,自己の知識及び過去の知識から質問を1つ選び,oracleにより答える. ・提案フレームワークにより,効率高い学習サンプルを得られる.また,従来のVQAネットワークで用いられるstate-of-the-artな問題集を生成できる.
・従来のあらゆるフレームワークは学習データから学習を行う.この論文で,質問文の自動生成できる及び質問を選択する構造を導入し,自動的でインターアクティブで環境から情報を獲得することを可能にした.・実験を通し,提案手法により質問を選択する規制がsampleの効率を高められる.(従来と同じ精度の場合,学習データ量を40%減らせる)
Spatially Regularized Discriminative Correlation Filters (SRDCF)に空間正則化を導入した一般物体追跡手法Spatial-Temporal Regularized Correlation Filters (STRCF)を提案. SRDCFは複数学習画像を利用するため, 計算量が大きくなってしまうことに着目し, 単一学習画像に対するSRDCFにonline Passive-Aggresive learningの考えに基づいて時間正則化を導入. STRCFはADMMで直接解くことができるため, DCFの高速性を保持したまま高い精度で追跡が可能となっている.
![]()
一般物体追跡手法の二大手法であるカーネルリッジ回帰(相関フィルタを含む)とCNNのハイブリッドな手法を提案した.カーネルリッジ回帰は全体的な情報に,CNNは局所的な情報に注目するように設計している.それぞれの導入がどの精度向上に結びついているかも検討している.
![]()
VQAタスクに用いられるattentionメカニズム“Dense Co-attention Network”(DCN)を提案した.DCNはfully対称的で,階層的にスタックできるため,マルチステップで視覚及び言語特徴のインターアクションを可能にする.具体的には,まず言語から画像の注目マップ及び画像から言語の注目マップを生成し,そして連結によりマルチモデルの特徴を融合する(dense co-attention layer).そして階層的にdense co-attention layerをスタックにより,さらにマルチモデル特徴を深く探る.
・従来のattention for VQAタスクより,有効的でデンスな視覚と言語モデルの特徴の融合メカニズムDCN(構造的にも簡潔で拡張しやすい)を提案し,将来の様々なVQAタスクに用いられる.・VQA, VQA2.0データセットで2017 VQA優勝したモデルより良い精度を達成した. ・定性的な実験により,提案モデルが有効的にattentionを抽出できることを証明した
画像中から物体のパーツ(車のタイヤなど)を検出するための新しい手法を提案.投票ベースの手法でオクルージョンへの頑健性を持つ. Visual ConceptというMid-levelな特徴をベースにして, 個々のMid-level特徴から推定されるパーツの位置推定結果を積み重ねていくことでパーツを検出する. Visual Conceptの検出とそれに基づく投票処理はConvolutionによって実装されており, End-to-Endでの学習が可能になっているところがポイント. Faster-RCNNといった物体検出アプローチよりもオクルージョンに頑健なことが実験的に確認できている.
合成データを利用した、6D pose estimationとdepth based 3D hand pose estimationの研究。
埋め込み空間内で、合成データから実データへのマッピング関数を学習する。その関数の学習のためには実データに対応する(grand truthが同じ)合成データが必要であるので、教師あり実データがある程度あることが前提としてある。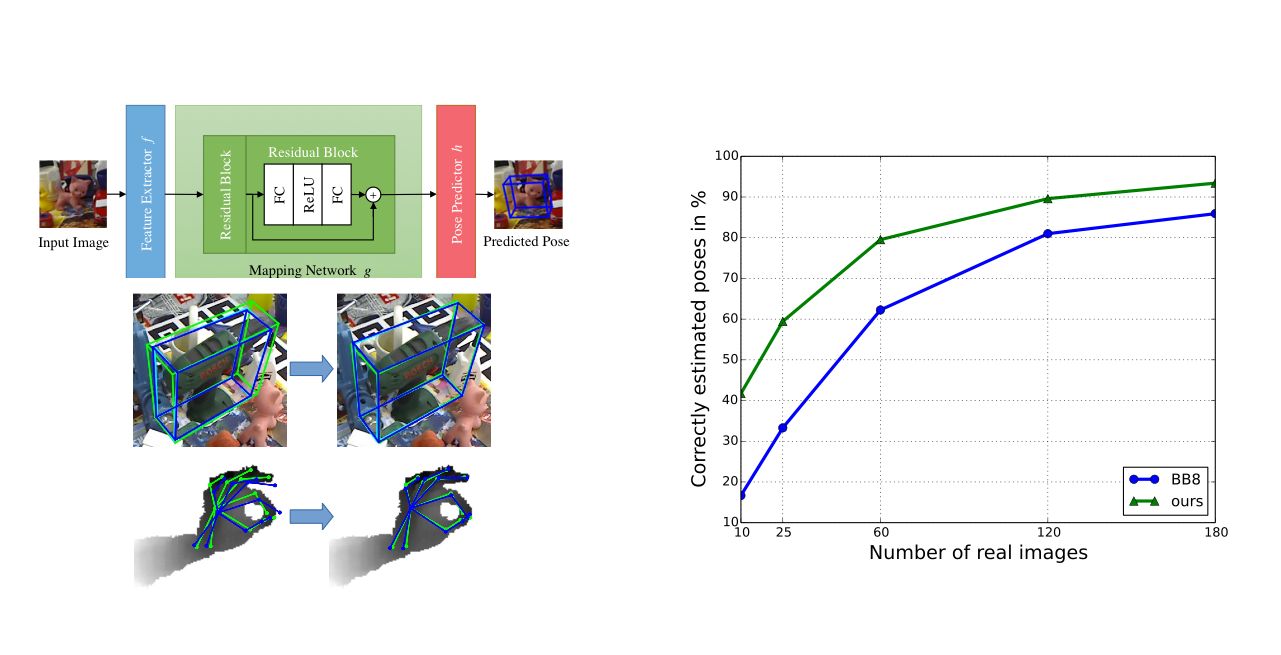
残差構造を持つmapping netを対応するペアを用いて学習する。従来のドメイン適応手法と比較しても提案手法の精度が良く、適応の有無による性能の差も非常に大きい。
3次元空間において、エージェントに質問の答え(例:車の色は?)を探させる研究。初期位置における視覚情報だけでは答えに行きつかないためにエージェントは移動しながら答えを探していく。 エージェントの移動には、どの方向(forward, rightなど)に進むかを決定するplannerとどこまで進むかを決定するcontrolerによって行う。 目的地(正解が分かる場所)にたどり着いた時点で、最後の5フレームを用いて172の選択肢から正解を出力する。
LSTMを使った場合の方が目的地により近付けるという結果が得られた。強化学習なしのものは目的地により近づいている一方、ファインチューニング+強化学習の方が正解率は高いという結果となった。 また、最短経路を与えてVQAによって答えさせる場合でも精度が悪く、答えを導くにあたってどの方向から目的地に近づくかも重要であるということが分かった。
GANによる画像生成の枠組みを中間的に取り入れることでSemantic segmentationにおけるドメイン適応を行う研究。
従来の特徴ベクトルに対する敵対的学習によって埋め込み空間におけるdomain gapを縮める手法に対して、この研究では特徴ベクトルから画像を復元し、その画像が識別器によってどのドメインからの復元か識別できないように埋め込み関数を学習させる。 合成データからのドメイン適応で最も良い精度を達成。
Source(S)は教師ありデータ、Target(T)は教師なしデータ。学習のフローは以下である: (1)識別器(D)は入力画像に対してpixel-wiseにsource real(SR), source fake(SF), target real(TR), target fake(TF)の4値分類を学習。(2)生成器(G)は入力特徴ベクトルからDによってSからの特徴はSRに、 Sからの特徴はTRに分類されるよう学習。 (+入力との担保を取るL2Loss)(3)埋め込み関数(F)はSからの入力はTRに、Tからの入力はSRに分類されるように学習。さらにSからのサンプルに対してはFからの特徴マップを入力としてsegmentation taskを解くCNNを学習。
論文内にこの手法がうまくいく理由の裏付け的実験や考察が詳細にはなかったが、特徴量から画像再生成を行うことによる入力情報の保存とS/T間の敵対的学習による分布の混合が一つのフローで行えていることが効いているように思えた。実際特徴量に対するS/T間の敵対的学習のみの場合よりも大きく精度が向上している。
SNSなどで共有された画像には、プライバシー保護の問題が生じる。プライバシー保護のために顔領域にぼかしや黒塗りなどの処理がされることが多いが、画像としては不自然さが残ってしまう。 そこで、塗りつぶされた領域に顔を挿入することで自然な画像ではあるが別人のためプライバシーを保護できる画像を生成する。 提案手法は、特徴点検出(生成)と顔の挿入の2つのステップに分かれる。 特徴点検出(生成)では、オリジナルの顔画像が存在する場合は既存の特徴点検出によって特徴点を検出する。 対称の画像が既に黒塗りされているなどで特徴点検出ができない場合は、GANによって特徴点を生成する。 次のステップでは、黒塗りされている顔画像と特徴点を入力し、黒塗りされた領域に顔の挿入を行う。
特徴点生成器は、GANによって生成することで正解値とのノルム最小化よりも高い精度で生成することを可能にした。画像に対する処理としてぼかしと黒塗りを比較したところ、ぼかしは顔の情報が一部残るため高い精度での生成が可能である一方、元の人物の情報は黒塗りよりも多く残ることが分かった。 また、顔の形状にも個人性が含まれるためオリジナル画像から検出した特徴点よりもGANによって生成した特徴点を使用した方が個人性は損なわれることが分かった。
SfMにおいて,一つの撮影にしか映らないような移動物体を考慮することで,そのシーンの絶対スケールが推定可能になるし,人混みだと見えにくい地平面の復元も成しうる.個々の撮影画像において検出された人を3次元空間に投影し,さらに物体の意味情報(本稿では背の高さの分布)から絶対スケールを推定する. また,人検出結果を用いて地平面推定も行う. ランダムなインターネット画像で手法をデモンストレーションし,量的評価を行う.
人検出はトルソモデルのフィッティングに基づく.画像における肩,腰の位置が推定でき,おおよその立ち位置も分かるということ.

若干SIGGRAPH的な気風のある,面白い視点を提供する論文.過去の知見に基づく高品質な人検出などを用いて成し得た,正統なアプリケーションに感じる. 動画のインパクトも大きいので,一度視聴を勧める.
従来の単眼奥行き推定法では, 推論の際に幾何的な制約を明示的に課していないことや多くのground truth labeled dataが必要といった問題があった.この研究では単眼奥行き推定問題をview synthesis問題とstereo matching問題に分けて考えることにより, 従来法の問題を解決する. view synthesis問題では, 入力を左画像として捉え, view synthesis networkにより右画像を生成する. stereo matching問題では, 左画像を右画像を用いstereo matching networkにより奥行きを推定する.
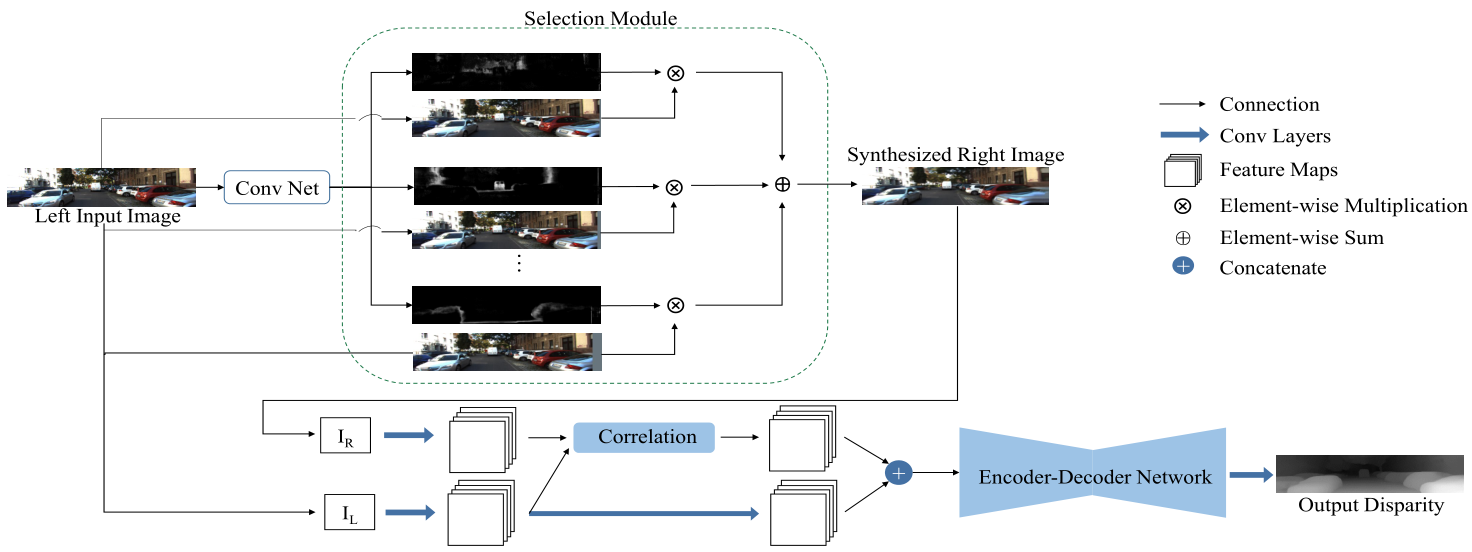
入力画像中の人物の老化顔をGANによって生成する手法の提案。Discriminatorには生成した画像が合成画像であるか及び目標年代の特徴を保持しているかを判定させ、それに加え元の画像とのL2ノルム及び元の顔画像と同一人物であるかをロスに加えることで、同一人物性を保持している。 その際、Discriminatorの中間層の各出力を途中で取り出すことにより(ピラミッド型ネットワーク),様々な解像度からの年齢特徴の抽出を行う。
年齢推定及び個人認証タスクによって有効性を確認した。従来手法では髪や額領域は変化できなかったが、提案手法によってこれらの要素を変化させることを可能とした。 Discriminatorをピラミッド型にすることにより、従来手法に比べてより詳細な老化特徴を取り出すことに成功。
物体同士の関係を表すScene Graphsから画像を生成する手法の提案。従来のテキストから画像を生成する手法よりも物体の数が多く複雑なシーンの画像を生成することができる。 初めに、Scene Graphsを処理するネットワークによってScene Graphsを表現するベクトルを取得し、そこから画像のレイアウトを作成する。 次にレイアウトからCRN(参考文献)を用いて画像を作成する。 作成された画像は、画像全体のリアルさと各物体のリアルさを評価するDiscriminatorによってリアルな画像であるかを評価する。
ユーザースタディの結果、StackGANと比較して合成結果が良いと答えた人が68%、認識可能な物体を生成できてると答えた人が59%という結果が得られた。
Image captioningとVQAタスクに用いられるBottom-upとtop-down attentionをコンバインするメカニズムを提案した.従来のオブジェクトレベルの領域の抽出のほか,salient 領域の抽出も行う.Faster R-CNNを利用したbottom-up的にsalient 領域を特徴ベクトルを抽出し, top-downにより特徴のウェットを決めることをベースに, Image captioningとVQAのアーキテクチャを提案し(右図),両方ともstate-of-artな性能を得られた.
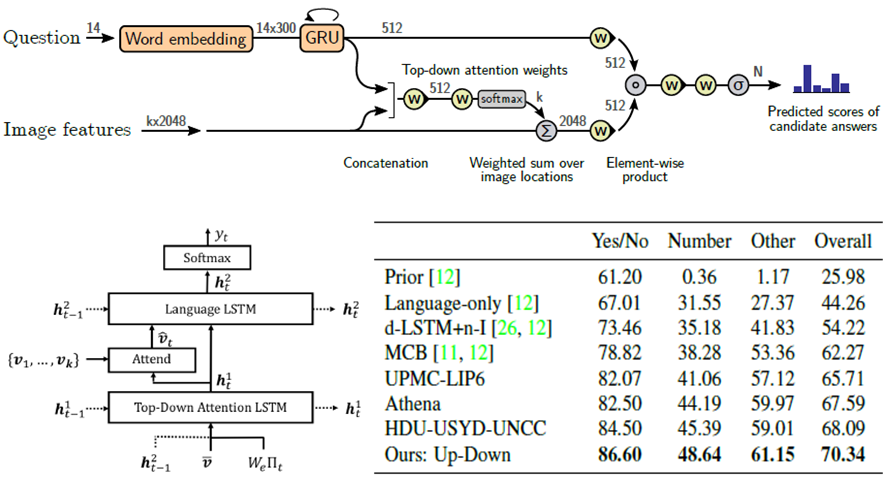
・従来のVQAとImage captioningは主にタスクスペシフィックなtop-downタイプのattentionを用いる.この論文で,人の視覚attentionメカニズムから,タスクスペシフィックなtop-downタイプのattentionを及びsalient 領域に注目するBottom-upのattentionを用いることと主張した.・2017 VQA Challengeにおいて優勝した.VQA v2.0 test-standardにおいて70.3%の精度を達成した.また, Image captioning タスクに対しMSCOCO Karpathy testで従来の手法より良い性能を達成した.
2017 VQA Challengeに優勝したモデルのモデル詳細を紹介し,さらにいかにVQAモデルの精度を上げられるかのコツとテクニックを紹介した.モデルのコアなところは視覚と質問文の意味特徴をジョイントでエンベディングし,さらにマルチ-ラベル予測を行う.

論文により,VQAの性能上げるために,以下のテクニックがある:1.sigmoid outputsを用いて,マルチアンサーをできるようにする.2.Soft scoresを用いて,分類ではなく回帰を行う.3.Bottom-up attentionから注目領域の画像特徴を用いる.4.Gated tanhを活性化関数に用いる.5.Pre-trainedウェットで初期化する.6.ミニバッチサイズを大きく設定し,training-dataにシャッフリングを用いる
「3DCNNが実は動き特徴を捉えられていないのではないか」という考えのもと、3DCNNにおける動き特徴の影響の上界を実験的に求める。提案する工夫により、この影響のかなり低い上界を得ることができ、動き特徴を捉えているのではない(例えば実は複数フレーム入力から「重要なフレーム選択」を行っているなど)ことを示唆した。
通常の16frames入力で学習したC3Dにおいてtest時にsub-samplingした(動き情報を無くした)設定下でできるだけ精度を上げることで結果的に動き特徴の上界を得る。Naïveにsub-samplingを行うと入力のデータ分布の明らかな違いから動き以外の精度低下への影響をもたらすと考えられるため、 sub-samplingされたclipから元clipを生成するgeneratorを構築。学習はC3Dの中間層の値をMSEで近づける。 またsampling方法によっても精度は変わるという考えから、識別confidenceが最大となるframesをsamplingする。注意として、この際動きに関しては全く考慮せずにsamplingしてきている。
結果として、かなりきつい上界を求められ、論文内では3DCNNが2Dよりも精度が良いのは動き特徴ではなく、複数フレーム入力の中で最も識別しやすいフレームを選択可能になるからではと述べられている。
フレーム選択をしているという仮説は面白いし、select frameによって精度が上昇したり、動きが大きい動画はフレーム単位での推定結果の分散が大きいなどから十分ありえそう。これが本当なら、optical flowを3dCNNに導入して大きく精度が向上することともつじつまが合いそう。
3D triangleメッシュから有用的な三次元幾何情報を抽出するネットワークSurface Networkを提案した.従来のLaplace operatorがintrinsic三次元幾何情報しか抽出できない.しかし,様々な応用場面でextrinsic情報が必要となる.この文章で主要なcurvature方向を抽出できるDirac operator を提案し,従来のLaplace operatorより幅広い場面で応用できる.
・定性的および定性的な結果によりspatial-temporal predictionsタスクにおいて,従来手法より良い結果を得られている.・variationalエンコーダーを用いたメッシュ合成手法を提案し,有効的に3次元メッシュを生成できる.
点群情報を直接処理できるSPLATNet(右図)を提案した.SPLATNetは直接点群から階層的な空間情報を抽出可能.また,2D情報と3D情報のマッピングも行えるので,点群とマルチ画像の両方をSPLATNetで処理可能.従来の直接点群情報を処理するネットワークはより局所的な空間情報を損失してしまう問題点がある.提案手法はこの問題を解決するために,BCLs層を用いた. BCLs層は点群をスパースなlatticeにマッピングし,さらにそのスパースなlatticeを畳み込みできる.それにより, unordered点群情報を処理できる上に点群のより局所的な情報も抽出可能にした.
Façade segmentationタスクにおいて,点群とマルチ画像のラベリングに良い処理スピードと従来手法手法より優れた精度を得られた.ShapeNet part segmentationにおいて従来手法より優れた精度(クラスmIoU:83.7%)を得られた.

ある音声と2人分の顔画像から,どちらの人物の声かを推定する課題と,ある顔画像と2人分の音声から,どちらの音声がその人物の声かを推定する課題の2つを解くという問題設定の研究. 異なるモダリティ間でのマッチングという課題ということ. ある入力に対応するのがどちらの人物かという2クラス識別の問題設定として定式化. この問題を解くために,3入力を扱う3-streamのネットワーク構造を持つモデルを提案. 音声もスペクトログラムの形式で画像のように扱い,顔画像,音声ともにConvolutionしていくモデル. 実験では80%程度の識別率を達成し,人と同等の結果が出ている. 二人分の選択肢の性別,国籍,年齢などが同じという設定にすると,60%程度の正答率になるが,こちらでは人 (57%) を上回る結果となっている.
センテンスの入力から、行動者と行動(Actor and Action)を同時に特定する研究である。複数の同様の物体から特定の人物など、詳細な分類が必要になる。ここではFully-Convolutional(構造の全てが畳み込みで構成される)モデルを適用してセグメンテーションベースで出力を行うモデルを提案。図は提案モデルを示す。I3Dにより動画像のエンコーディング、自然言語側はWord2Vecの特徴をさらにCNNによりエンコーディング。その後、動画像・言語特徴を統合してDeconvを繰り返しセグメントを獲得していく。
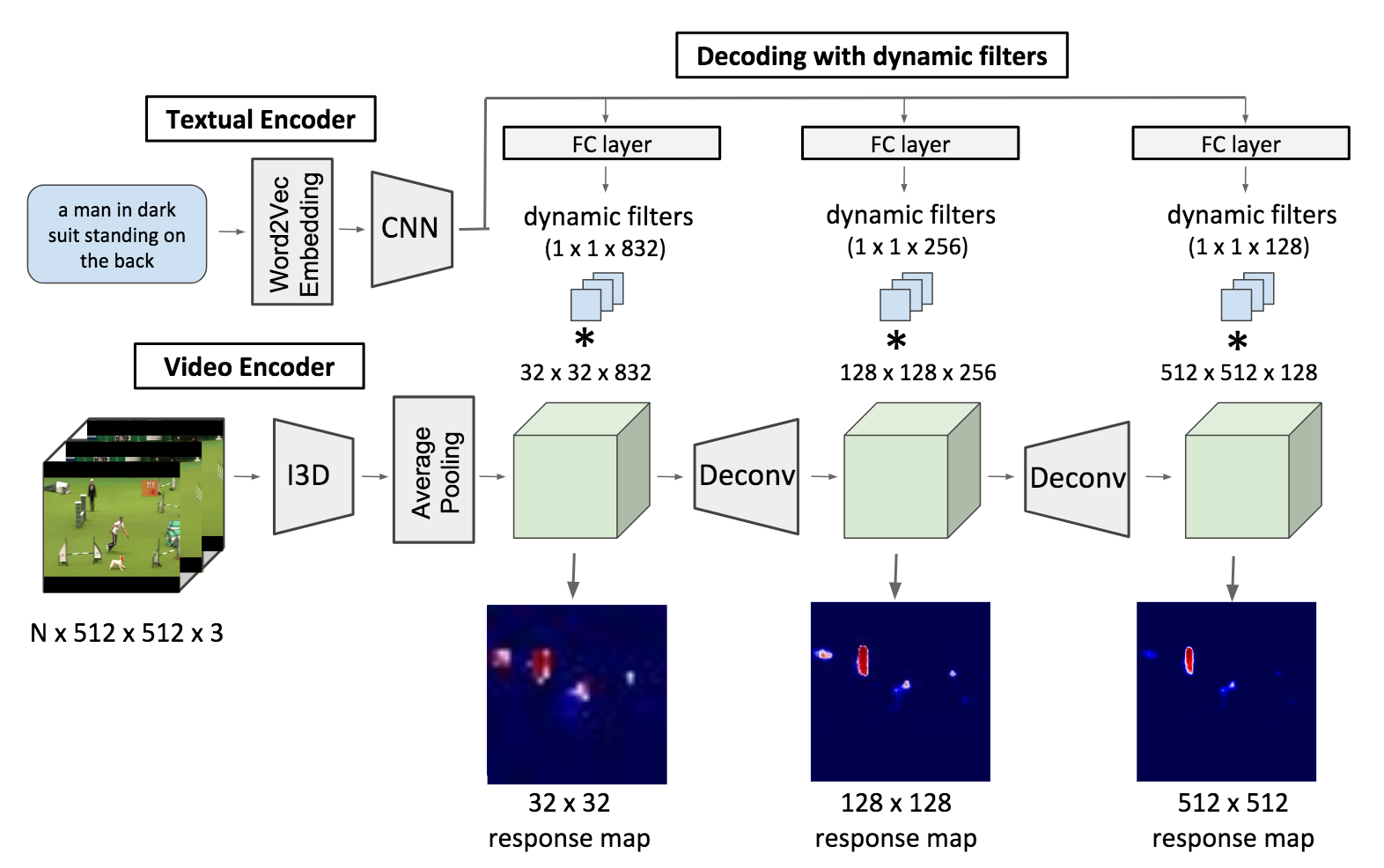
文章(と動画像)の入力から行動者と行動の位置を特定すべくセグメンテーションを実行するという問題を提起した。また、二つの有名なデータセット(A2D/J-HMDB)を拡張して7,500を超える自然言語表現を含むデータとした。同問題に対してはSoTA。
2Dの似顔絵画像から3Dの似顔絵を作成するためのアルゴリズムの提案。似顔絵画像のテストデータとしてはカリカチュアを使用し、カリカチュア画像の3Dモデルとテクスチャ化された画像を生成する。データは、標準の3D顔の変形を座標系に配置(下図、 xは口の開き具合)し、金のオリジナルデータから線形結合によって白い顔を生成する。

カリカチュアを集めたデータセットを作って学習するのではなく、標準の3D顔のデータセットから実装でき、アプリケーションの柔軟さを推している。
3DMMやFaceWareHouseなどの従来手法と比較して、形の歪みが少なく、従来のものよりも綺麗な3D顔の出力が可能。顔以外にも、概形の予測が可能なオブジェクトなら応用できる?

オクルージョンが発生している場合/複雑な環境下でも簡単な形状がポイントクラウドから検出できる枠組みを提案する。手法は3D楕円形状のフィッティング、3次元空間操作、4点取得により構成。
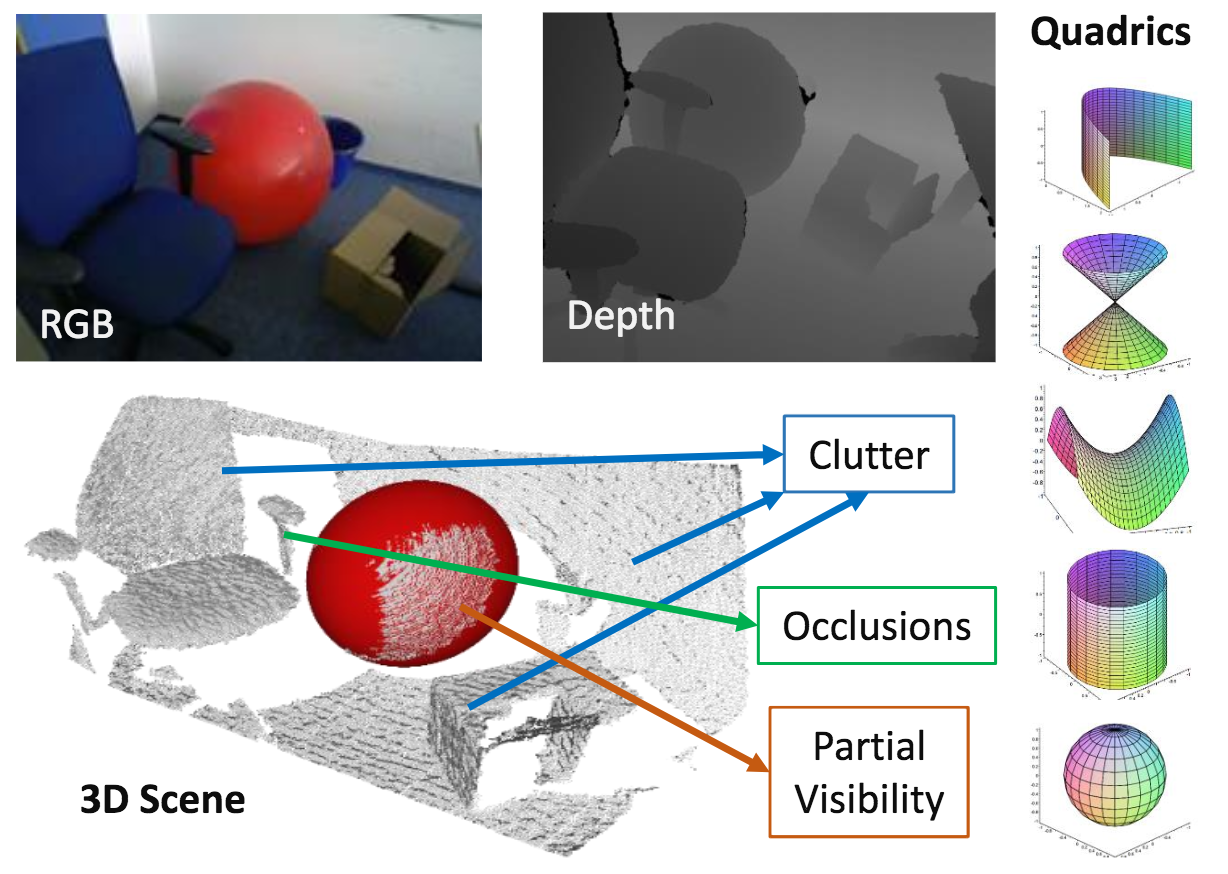
タイプに依存しない3次元の二次曲面(楕円球形状)検出を点群の入力から行う手法を考案した。さらに、4点探索問題を3点探索にしてRANSACベースの手法で解を求めた。モデルベースのアプローチよりはフィッティングの性能がよいが、キーポイントベースの手法よりは劣る。
MSCOCOデータセットに対してThing(もの)やStuff(材質)に関する追加アノテーションを行い、さらにコンテキスト情報も追加したCOCO-Stuffを提案した。このデータセットには主にシーンタイプ、そのものがどこに現れそうかという場所、物理的/材質的な属性などをアノテーションとして付与する。COCO2017をベースにして164Kに対して91カテゴリを付与し、スーパーピクセルを用いた効率的なアノテーションについてもトライした。

材質的なアノテーションは画像キャプションに対して重要であることを確認、相対的な位置関係などデータセットのリッチなアノテーションが重要であること、セマンティックセグメンテーションベースの方法により今回のアノテーションを簡易的に行えたこと、などを示した。
入力フレームだけでなく、ピクセル単位の文脈情報を用いて、高品質の中間フレームを補間するためのコンテキスト認識手法の提案。まず、プレトレインモデルを使用して、入力フレームのピクセルごとのコンテキスト情報を抽出。オプティカルフローを使用して、双方向フローを推定し、入力フレームとそのコンテキストマップの両方をワープする。最後にコンテキストマップをsynthesis networkに入力し、補間フレームを生成。
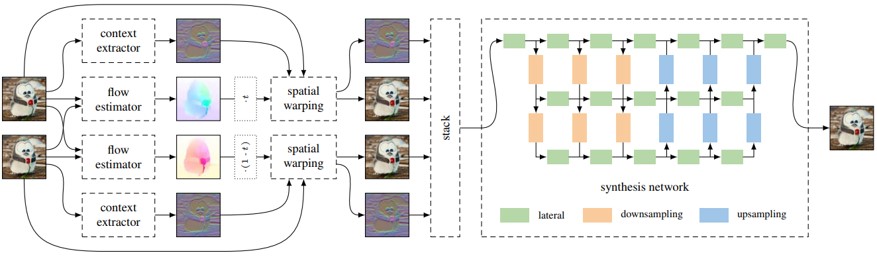
従来のビデオフレーム補間アルゴリズムは、オプティカルフローまたはその変動を推定し、それを用いて2つのフレーム間の中間フレームを生成する。本手法では、 2つの入力フレーム間の双方向フローを推定し、コンテキスト認識という方式をとることで精度向上を図る。
RGB画像から表面の法線とオクルージョン境界を予測し、 RGB-D画像と組み合わせて、欠けている奥行き情報を補完するDeep Depth Completionの提案。また、奥行き画像と対になったRGB-D画像のデータセットであるcompletion benchmark datasetを作成し、性能を評価。これは、低コストのRGB-Dカメラでキャプチャした画像と、高コストの深度センサで同時にキャプチャした画像で構成されている。
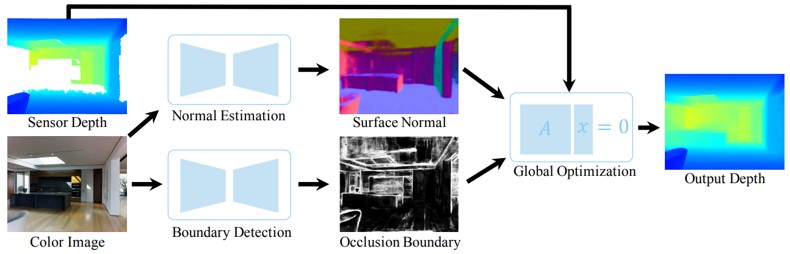
深度カメラは、光沢があり、明るく、透明で、遠い表面の深さを感知しないことが多い。 このような問題を解決するために、本手法ではRGB画像から得た情報と組み合わせて、 RGB-D画像の深度チャネルを完全なものにする。
人物検出と同時に人物行動やその物体とのインタラクションも含めて学習を行うモデルを提案する。本論文では物体候補の中でも特にインタラクションに関係ありそうな物体に特化して認識ができるようにする。さらに、検出された

人間に特化した検出と行動推定の枠組みを提案した。V-COCO(Verbs in COCO)にて、相対的に26%精度が向上(31.8=>40.0)、HICO-DETデータセットにて27%相対的な精度向上が見られた。計算速度は135ms/imageであり、高速に計算が可能である。
Zero-shot learning(ZSL)における、視覚的および意味的インスタンスを別々に表現し学習するLatent Discriminative Features Learning(LDF)の提案。 (1)ズームネットワークにより差別的な領域を自動的に発見することができるネットワークの提案。(2)ユーザによって定義された属性と潜在属性の両方について、拡張空間における弁別的意味表現の学習。
ZSLは、画像表現と意味表現の間の空間を学習することによって、見えない画像カテゴリを認識する。 既存の手法では、視覚と意味空間を合わせたマッピングマトリックスを学習することが中心的課題。提案手法では、差別的に学習するとうアプローチで識別精度向上を図る。
ドメイン変換について、ゲームなどのCG映像から実際の交通シーンに対応して物体検出を行うための学習方法を提案する。本論文では(i) 画像レベルのドメイン変換、(ii) インスタンス(ある物体)に対してのドメイン変換、の二種類の方法を提案し、整合性をとるように正規化する(図のConsistency Regularization; Global/Localな特徴変換を考慮)。ここで、物体検出はFaster R-CNNをベースとしてドメイン変換の手法も二種類(H-divergence、敵対的学習)用意する。
CGで学習し実環境における自動運転などで使えるドメイン変換の手法を提案した。実験はCityscapes, KITTI, SIM10Kなどで行い、ロバストな物体検出を実行することができた。例えばCityscapesとKITTIの相互ドメイン変換でベースラインのFaster R-CNNが30.2 (K->C)、53.5 (C->K)のところ、Domain Adaptive Faster R-CNNでは38.5 (K->C)、64.1 (C->K)であった。
Polygon-RNNのアイデアを踏襲し、ヒューマン・イン・ザ・ループを使って対話的にオブジェクトのポリゴンアノテーションの生成。また、新しいCNNエンコーダアーキテクチャの設計、強化学習によるモデルの効果的な学習、 Graph Neural Networkを使用した出力解像度の向上を行う。これらのアーキテクチャをPolygon-RNN ++と呼ぶ。
アノテーション作成時の負担を軽減。より正確にアノテーションを付加できるため、雑音の多いアノテーターに対しても頑健である。
高い汎化能力となり、既存のピクセルワイズメソッドよりも大幅に改善。ドメイン外のデータセットにも適応可能。
一人称視点の画像からゴールリングに到達するまでのバスケットボール選手の動線を生成する。本論文では3D位置や頭部方向も記録する。同タスクを実行するため、まずは画像空間から12Dのカメラ空間に投影を行うEgoCam CNNを学習。次に予測を行うCNN(Future CNN)を構築、さらに予測位置やゴールまでの位置が正確かどうかを検証するGoal Verifier CNNを用いることでより正確な推定を行うことができる。
複数のネットワークの出力(ここではEgoCamCNNとFutureCNN)を検証するVerification Networkという考え方は面白い。他のネットワークの出力を、検証用のネットワークにより正すというのはあらゆる場面で用いることができる。RNN/LSTM/GANsなどよりも高度な推定ができることが判明した。
元の低解像度画像から高解像度画像を再構築するための、深くてコンパクトなCNNを提案。提案モデルは、特徴抽出ブロック、積み重ね情報蒸留ブロック、再構成ブロックの3部構成。これにより、情報量が豊富かつ効率的に特徴を徐々に抽出できる。
CNNが超解像殿画像を扱うようになってきたが、ネットワークが増大するにつれて、計算上の複雑さとメモリ消費という問題が生じる。これらの問題を解決するためのコンパクトなCNN。
先の(未来の)フレーム予測と異常検知を同時に行う手法を提案する論文。予測したフレームと異常検知の正解値により誤差を計算して最適化を行う。図に本論文で提案するネットワークアーキテクチャの図を示す。U-Netにより画像予測やさらにオプティカルフロー推定を行い、RGB空間、オプティカルフロー空間にて誤差を計算しGANの枠組みでそれらがリアルかフェイクかを判定する。同フレームを用いて異常検知を実施する。
従来は現在フレームを入力として異常検知を行う手法は存在したが、未来フレームを予測して異常検知を行う枠組みは本論文による初めての試みである。異常値の正解値を与えることで画像予測にもフィードバックされるため、画像予測と異常検知の相互学習に良い影響を与える。オープンデータベースにてベンチマークした結果、何れもState-of-the-artな精度を達成。
ラベルの付いていないデータに対して、どの画像にラベルを付けてデータセットを構成すればよいかを判断するguided labelingの提案。ラベル付けを行う必要があるサンプルを見定めることで、データセットの量を大幅に減らすことができる。
大規模データセットにおいて、手動でのラベル付けは大変。選別してラベル付けを行えば、作業を最小限に抑えられる。また、ある意味良いデータを選別できるため、場合によっては精度も向上。
MNISTは、データセットのサイズを1/16に、CIFAR10は1/2に減らすことが可能に。また、MNISTの場合は、全部使った時よりも識別精度が向上した。普遍性を妨げる不必要なデータを取り除けたことが精度向上につながった?
イベントベースカメラにおける、識別アルゴリズムの提案。本研究では、(1)イベントベースのオブジェクト分類のための低レベル表現とアーキテクチャの欠如、(2)実世界における大きなイベントベースのデータセットの欠如、の2つの問題に取り組む。新しい機械学習アーキテクチャ、イベントベースの特徴表現(Histograms of Averaged Time Surfaces)、データセット(N-CARS)を提案。
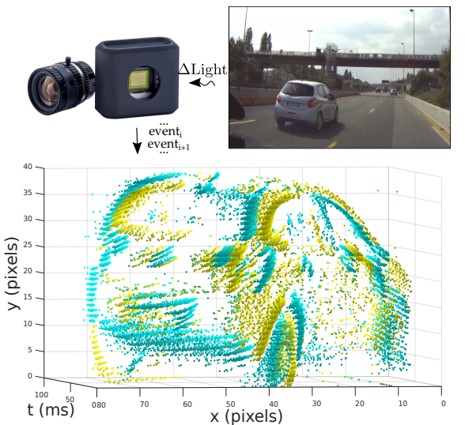
イベントベースのカメラは、従来のフレームベースのカメラと比較して、高時間分解能、低消費電力、高ダイナミックレンジという点で優れており、様々なシーンで応用が利く。しかし、イベントベースのオブジェクト分類アルゴリズムの精度は未だ低い。特徴表現には過去時間の情報を使用。
既存のNon-Max Supressionを改良したFitness NMSの提案。Soft NMSも同時に使用するとより効果的。
勾配降下法の収束特性(滑らかさ、堅牢性など)を維持しつつ、IoUを最大化するという目標により適した損失関数であるBounded IoU Loss の提案。これをRoIクラスタリングと組み合わせることで精度が向上する。
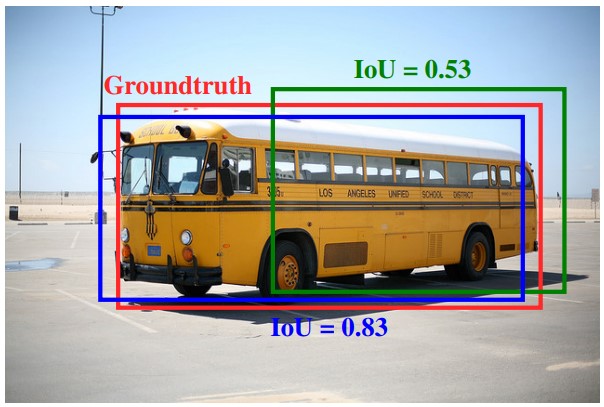
バウンディングボックスのスコアを算出する関数を拡張する。具体的には、グランドトゥルースとのIoUと、クラスの期待値を追加する。これにより、IoUの重なり推定値と、クラス確率の両方が高いバウンディングボックスを優先して学習することができる。
新しいRNN手法であるindependently recurrent neural network (IndRNN)の提案。一枚のレイヤ内のニューロンが独立しており、レイヤ間で接続されている。これにより、勾配消失問題や爆発問題を防ぎ、より長期的なデータを学習することができる。また、IndRNNは複数積み重ねることができるため、既存のRNNよりも深いネットワークを構築できる。
本手法によって下記の従来手法の問題を解決。
RNNは、勾配の消失や爆発の問題、長期パターンの学習が困難である。LSTMやGRUは、上記のRNNの問題を解決すべく開発されたが、層の勾配が減衰してしまう問題がある。また、RNNは全てのニューロンが接続されているため、挙動の解釈が困難。
CNNのような理由を突き止める能力がない認識システムを超えた、反復的なvisual reasoningのための新しいフレームワークの提案。畳み込みベースのローカルモジュールとグラフベースのグローバルモジュールの2コアで構成。2つのモジュールのを繰返し展開し、予測結果を相互にクロスフィードして絞り込む。最後に、両方のモジュールの最高値をアテンションベースのモジュールと組み合わせてプレディクト。
ただ畳み込むだけでなく、Spatial(空間的)およびSemanticの空間を探索することができる。下図のように、「人」は「車」を運転するというSpatialとSemanticの双方を兼ね備えた認識を行うことで精度向上を図る。
通常のCNNと比較して、ADEで8.4%、COCOで3.7%の精度向上。

単一のパースペクティブまたはパノラマ画像から屋内3Dルームレイアウトを推定するLayoutNetの提案。最初に、消失点を分析し、水平になるように画像を整列。これにより、壁と壁の境界が垂直になり、ノイズ低減。画像からコーナー(レイアウト接合点)と境界を、エンコーダ/デコーダ構造のCNNで出力。最後に、3D Layoutパラメータを、予測したコーナーと境界に適合するように最適化する。
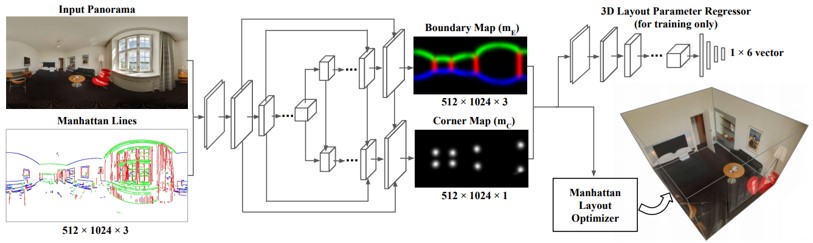
アーキテクチャはRoomNetと似ているが、消失点に基づいて画像を整列させ、複数のレイアウト要素(コーナー、境界線、サイズ、平行移動)を予測し、 “L”形の部屋のような非直方体のマンハッタンレイアウトに対しても適応できる。
画像と音声の入力から、音が画像のどこで鳴っているか(鳴りそうか?)を推定した研究。さらに、人の声なら人の領域、車の音なら車の領域にアテンションがあたるなど物体と音声の対応関係も学習することができる。学習には音源とその対応する物体の位置を対応づけたデータセット(144Kのペアが含まれるSound Source Localization Dataset)を準備した。さらに既存の物体認識と音声を対応づけて(?)Unsupervised/Semi-supervisedに学習することにも成功した。
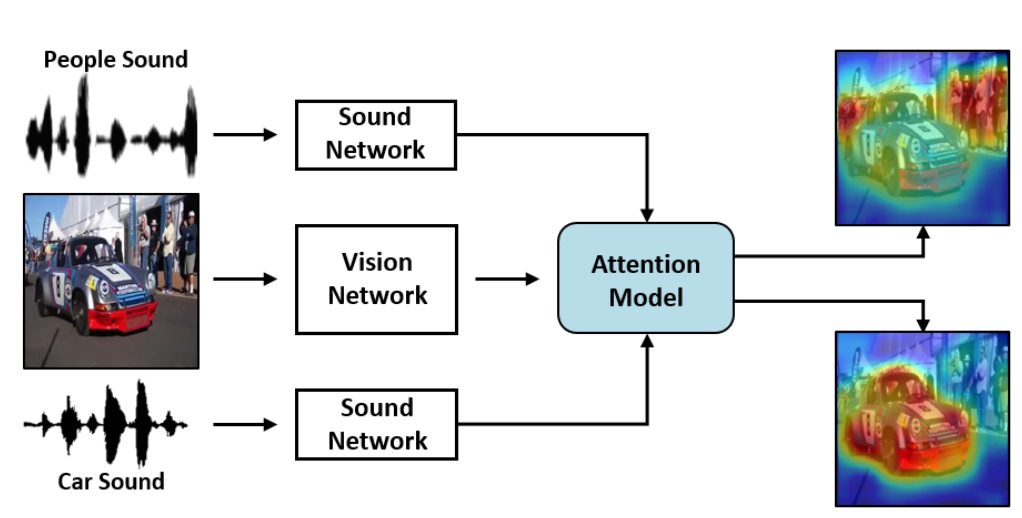
教師あり、教師なし、半教師あり、いずれの枠組みでも音声ー物体の対応関係を学習することができるようにした。音源とそれに対応する物体領域の尤度がヒートマップにて高く表示されている。結果はビデオを参照されたい。教師なし学習はTriplet-lossにより構成され、ビデオと近い/遠い音声の誤差により計算。
ラベルが完全に手に入らない際にでも転移学習が可能なセグメンテーション手法(論文中ではPartially Supervised Training Paradigm, weight transfer functionを紹介)を提案する。条件として、bboxが手に入っている物体に対してセグメンテーション領域を学習可能。Mask R-CNNをベースとしているが、Weight Transfer Functionを追加、セグメントの重みを学習・推定して誤差計算と学習繰り返し。

Visual Genome Datasetから3,000の視覚的概念を獲得、MSCOCOから80のマスクアノテーションを獲得した。
弱教師付き学習が現実的な精度で動作するようになってきた?アノテーションはお金や知識があっても非常に大変なタスクであり、いかに減らすかという方向に研究が進められている。(What's next?ー弱教師/教師なしの先とは?)
ソース画像のメイクをターゲット画像へ転写やメイクの除去をする研究。ターゲット画像とメイク済み画像の2枚を入力としメイクを転写するネットワークGとメイク済み画像らメイクを取り除くネットワークFを考え、2つのネットワークによって元の画像に戻るように学習していく。 その際、Fによってxに付与されたメイクがyのメイクと同じものであるかを評価するロスを加えることでメイクの特徴を捉える。 従来手法ではメイク転写・除去を独立した問題として考えていたが、この研究ではセットとして考えている。

Youtubeのメイクチュートリアルの動画から、1148枚のメイクなし画像と1044枚のメイクあり画像を収集。ユーザースタディによって2つの既存手法と比較し、提案手法が一番いいと答えた人が65.7%(2番目と答えた人が31.4%) 従来手法では肌の色や表情の違いがあると上手くいかないのに対し、ソースとターゲット間でこれらが違ってもうまく転写できる。
ビデオQAのための、 Dynamic Memory Network(DMN) のコンセプトに基づいたmotion-appearance comemory networkの提案。本研究の特徴は次の3つである。(1)アテンションを生成するために動きと外観情報の両方を手がかりとして利用する共メモリアテンションメカニズム。(2) multi-level contextual factを生成するための時間的conv-deconv network。(3)異なる質問に対して動的な時間表現を構成するdynamic fact ensemble method。
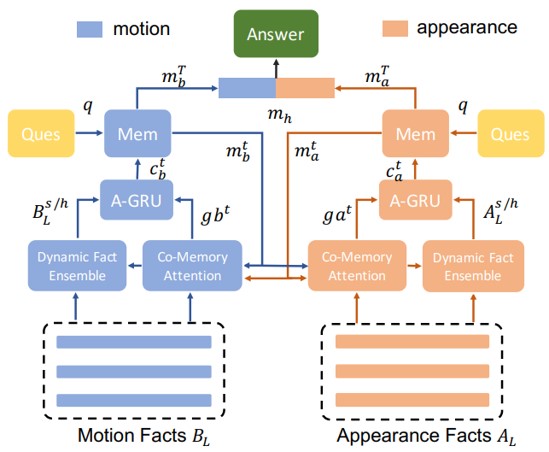
本手法は、次のようなvideo QA特有の属性に基づいている。(1)豊富な情報を含む長い画像シーケンスを扱う。(2)動き情報と出現情報を相互に関連付け、アテンションキューを他の情報に応用できる。(3)答えを推論するために必要なフレーム数は質問によって異なる。
人間の視覚的外観を、人の手によるアノテーションなしかつ、複数のセマンティックレベルで識別因子に分解する Multi-Level Factorisation Net(MLFN)の提案。 MLFNは、複数のブロックで構成されており、各ブロックには、複数の因子モジュールと、各入力画像の内容を解釈するための因子選択モジュールが含まれている。
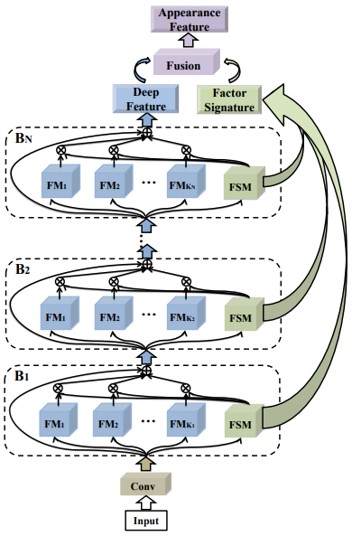
効果的なRe-IDを目指すには、高低のセマンティックレベルでの人の差別化かつ視界不変性をモデル化することである。 近年(2018)のdeep Re-IDモデルは、セマンティックレベルの特徴表現を学習するか、アノテーション付きデータが必要となる。MLFNではこれらを改善する。
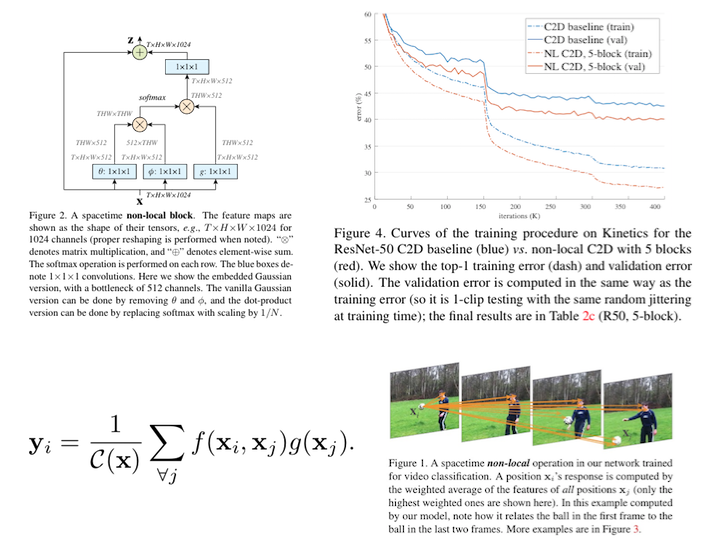
効果のインパクトがすごい。学習曲線からもうまくいっていることが明らか。C2Dに対してspace-timeにnon-local blockを適用すると3Dconvよりも時系列方向への拡大として効果があったのが興味深い。 結局残差を用いたnon-local blockを使用していたので、単純にnon-local layerのみでの性能もきになる。 位置情報の保存は重要でも、局所性はあまり重要ではなかったのかと感じられる。
横顔の認識精度を高めるためにDeep Residual EquivAriant Mapping (DREAM)の提案。正面と側面の顔間のマッピングを行うことで特徴空間を対応付ける。これにより、横顔を正面の姿勢に変換して認識を単純化。

空間ピラミッドプーリングと3D CNNの2つのモジュールから構成された、ステレオ画像対からの奥行き推定を行うPyramid Stereo Matching Network(PSMNet)の提案。空間ピラミッドプーリングは、異なるスケールおよび位置でコンテキストを集約し、コストボリュームを形成する。 3D CNNは、複数のhourglass networksを重ねて、コストボリュームを規則化することを学習。
現在(2018)ではステレオ画像からの奥行き推定を、CNNの教師あり学習で解決されてきている。 コンテキスト情報を利用することで精度向上を図る。
referring relationshipsを利用して同カテゴリのエンティティ間の曖昧さを解消するタスクの提案。特徴抽出後、アテンションを生成。述語を使用することで、アテンションをシフトさせる。この述語シフトモジュールを介して、subjectとobjectの間でメッセージを反復的に渡すことで、2つのエンティティをローカライズ。
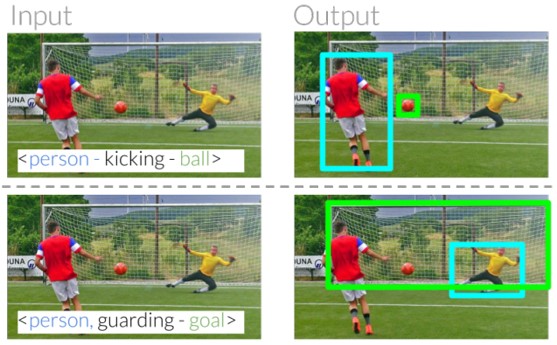
本論文ではLarge-margin Gaussian Mixture (L-GM) Lossを提案して画像識別タスクに応用する。Softmax Lossとの違いは、学習セットにおけるディープ特徴の混合ガウス分布をフォローしつつ仮説を設定するところである。識別境界や尤度正則化においてL-GM Lossは非常に高いパフォーマンスを実現している。
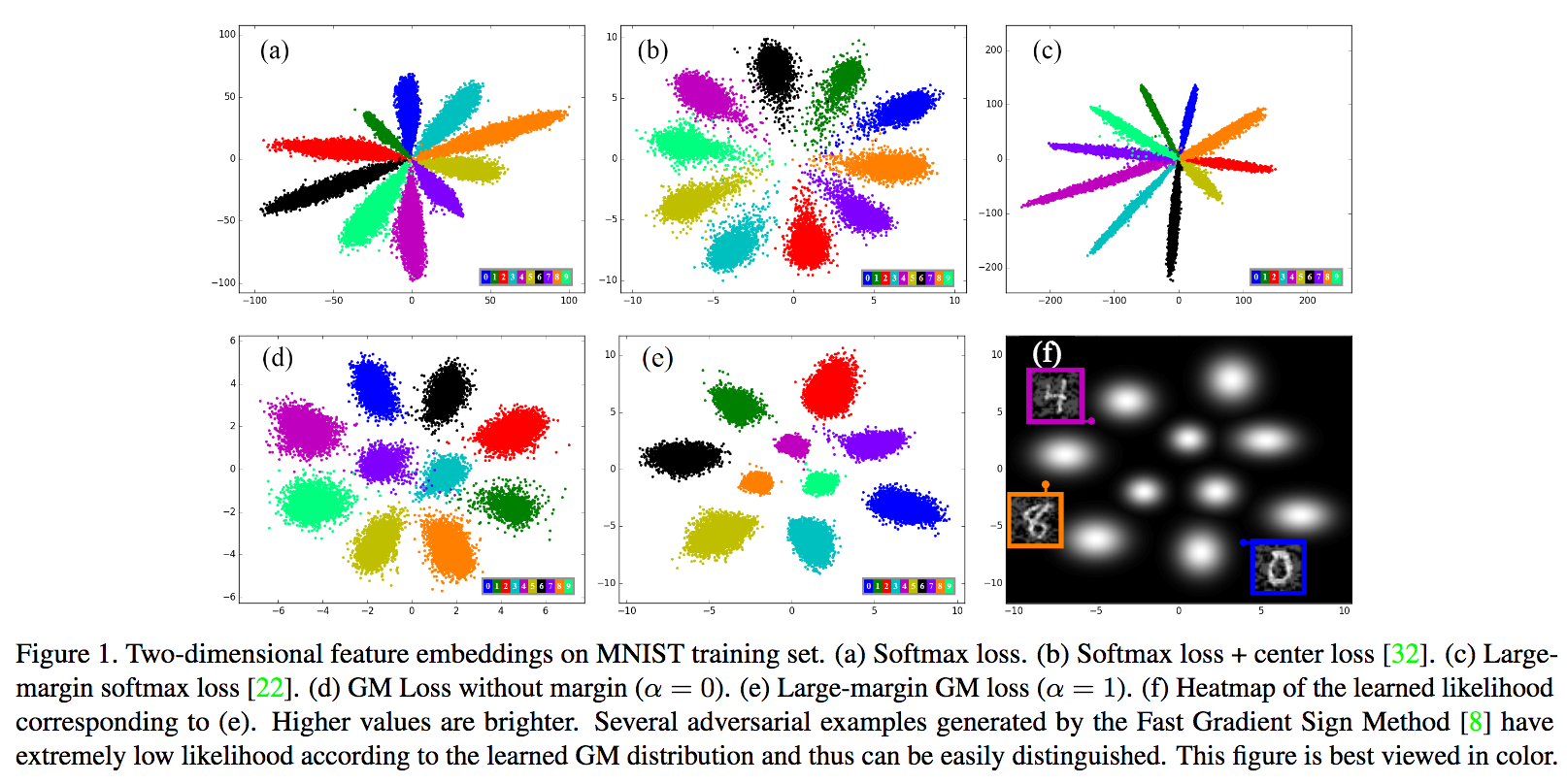
L-GM Lossは画像識別においてSoftmax Lossよりも精度が高いことはもちろん、特徴分布を考慮するため例えばAdversarial Examples(摂動ノイズ)などにおいても対応できる。MNIST, CIFAR, ImageNet, LFWにおける識別や摂動ノイズを加えた実験においても良好な性能を確かめた。
HDRの画像の明るさを補正するためのブラケット撮影からの距離画像やカメラ姿勢を同時推定する手法を提案する論文。ブラケット撮影とは通常の露出撮影以外に意図的に「少し明るめの写真」と「少し暗めの写真」を同時に撮影。距離画像推定は幾何変換をResidual-flow Networkに統合したモデルにより行う。ここでは学習ベースのMulti-view stereo手法(Deep Multi-View Stereo; DMVS)を幾何推定(Structure-from-Small-Motion; SfSM)と組み合わせる。

距離画像推定において、スマートフォンやDSLRカメラなど種々のデータセットにてSoTAな精度を達成。モバイル環境でも動作するような小さなネットワークと処理速度についても同時に実現した。
自然画像から文字を検出する。単なる検出ではなく、文字の方向を考慮したバウンディングボックスによる検出手法であるRotation-sensitive Regression Detector (RRD)の提案。回帰ブランチによって、畳み込みフィルタを回転させて回転感知特徴を抽出。分類ブランチによって、回転感性特徴をプーリングすることによって回転不変特徴を抽出。

文字をテーマにした研究では(1)テキストの向きを無視した分類方法と,(2)向きを考慮したバウンディングボックスによる回帰がある。従来研究では、両方のタスクの共有の特徴を使用していたが、互換性がなかったためにパフォーマンスが低下(図b)。そこで、異なる2つのネットワークから抽出した、異なる特性の特徴を分類および回帰することを提案(図d,e)。
ICDAR 2015、MSRA-TD500、RCTW-17およびCOCO-Textを含む3つのシーンテキストのデータセットで最先端のパフォーマンスを達成。向きがある一般物体検出にも応用可能?
スケッチ検索のためのディープハッシングフレームワークの提案。3.8mの大規模スケッチデータセットを構築。CNNでスケッチの特徴抽出。RNNでペンストロークの時間情報をモデル化。CNN-RNNでエンコードすることで、スケッチ性質に対応した新しいhashing lossを導入。
従来のスケッチ認識タスクに従う代わりに、より困難な問題のスケッチハッシュ検索を行う。ネットワークをスケッチ認識のために再利用することもでき、どちらも高パフォーマンス。大規模なデータセットを利用することで、従来の文献ではあまり研究されていなかった、スケッチのユニークな特性を見出す。
顔のランドマーク検出。顔そのもののばらつきの他に、グレースケールやカラー画像、明暗などの画像スタイルが変わっても同様に検出できるStyle Aggregated Network(SAN)の提案。まず、(1)入力画像をさまざまなスタイルに変換し、スタイルを集約し、(2)顔のランドマーク予測する。(2)は、元画像とスタイルを集約した特徴の両方を入力し、融合してカスケード式のヒートマップ予測を生成する。
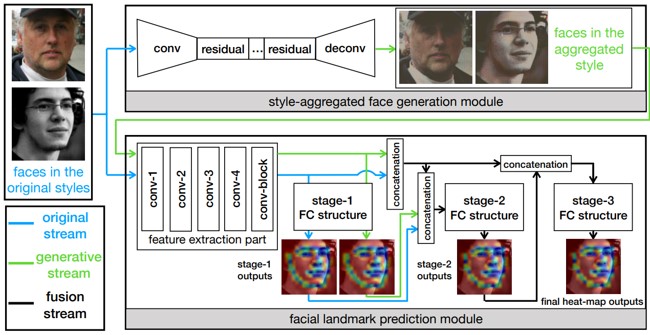
2枚の画像の類似度を表す指標は数多く提案されているが、その類似度は必ずしも人間の知覚と一致していない。近年はDNNにより高次の特徴を得ることが可能となっており、人間の知覚に近づいている。 そこで、既存の類似度の評価尺度とDNNベースの類似度判定を比較することでDNNベースの手法がより人間の知覚に近い類似度を表現できることを確認した。 具体的には、ある画像を異なる方法で加工したもの2つを用意し、どちらが元の画像に近いかを人間とコンピュータ両方に判定させることで検証を行った。
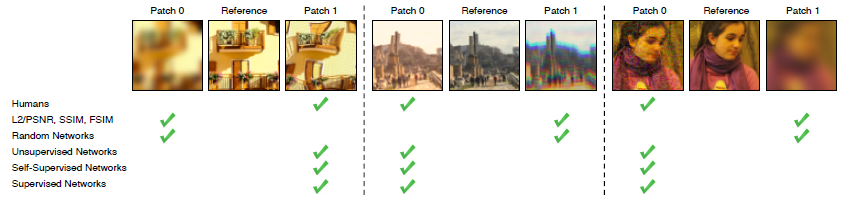
データセットとして、画像に様々な加工を施したデータを人間に類似度を評価してもらったものを作成。加工の例としては、ノイズの付与やオートエンコーダによる画像の復元などが挙げられる。 検証の結果、DNNベースの類似度の方が既存の尺度より人間の知覚に乗っ取ってることを示した。 また、DNNのネットワーク構造そのものは重要ではないことが分かった。
透明物体の切り抜き(Transparent Object Matting; TOM)と反射特性を推定することが可能なネットワークTOM-Netを提案する。TOM-Netにより、物体の反射特性を保存しながら他の画像にレンダリングして、同画像のテクスチャを反映させることができる。同問題を反射フローの推定問題と捉えてDNNのモデルを構築することで解決した。荒い部分は多階層のEncoder-Decorderで推定し、詳細な部分はResidualNetで調整する。この問題を解決するために、データセットを構築した。
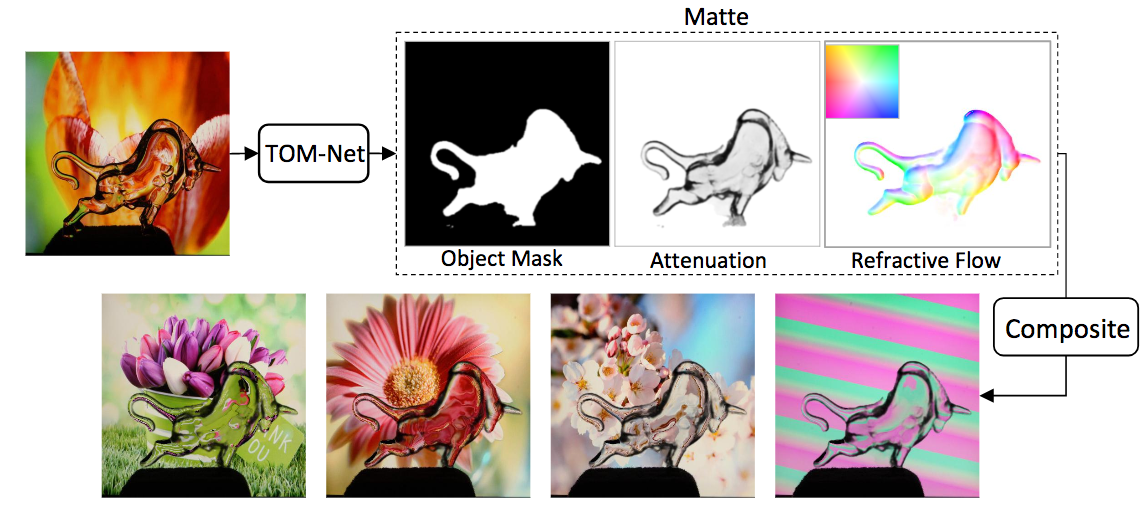
178Kの画像を含むデータセットを構築した。同DBには876サンプル、14の透明物体、60種の背景を含む。透明物体の推定と反射特性のレンダリングはGitHubページを参照。
物体検出の課題を考慮し、既存のActive Learning(AL)の欠点を改善することを目的とした、Self-Supervised Sample Mining(SSM)の提案。ラベルなし、もしくは一部ラベルのないデータを使って学習することができる。交差検証後のスコアによってサンプルを選別。低い場合にはユーザによってアノテーション、高い場合にはそのままラベルとして採用。
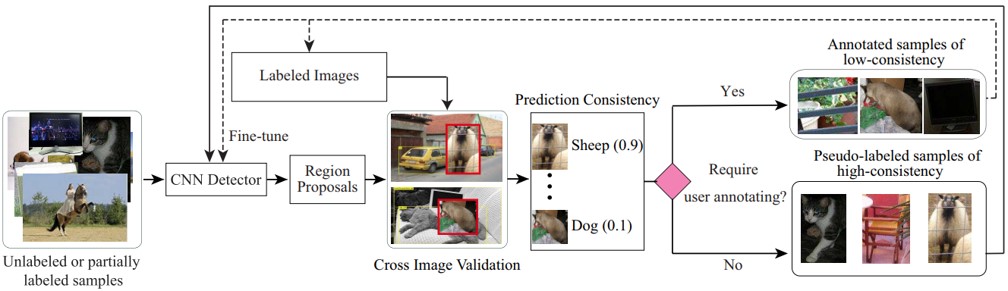
既存のAL法では主に、単一の画像コンテクスト内でサンプル選択基準を定義し、大規模な物体検出において最適ではなく、頑強性および非実用的である。SSMによって、ユーザが必要な部分にだけ介入し、アノテーションの作業を軽減。
顔画像からidentityとattributesを別々に再構成する、GANに基づいたOpen-Set Identity Generating Adversarial Networkの提案。 face synthesis networkは、ポーズや感情、照明、背景などをキャプチャする属性ベクトルを抽出することができる。図中の2つの入力画像AおよびBから抽出された識別を再結合することによって、A0およびB0を生成することができる。
学習画像がなくても行動認識を実現する「Unseen Action Recognition (UAR)」についての研究。UARの問題をMIL(Multiple Instance Learning)の一般化(GMIL)として扱い、ActivityNetなど大規模動画データから分布推定して表現を獲得。図は提案手法であるCross-Domain UAR (CD-UAR)である。ビデオから抽出したDeep特徴はGMILによりカーネル化される。Word2Vecとの投稿によりURを獲得し、ドメイン変換により新しい概念を獲得する。
従来法では見た/見てないの対応関係をデータセット中に含ませていたが、本論文での提案はUniversal Representation(ユニバーサル表現)を獲得して同タスクを解決する。
歩行者の時空間パターンを用いた、教師なし学習の人物再同定アルゴリズムであるTFusionを提案。既存の人物再同定アルゴリズムのほとんどは、小サイズのラベル付きデータセットを用いた教師付き学習手法である。そのため、大規模な実世界のカメラネットワークに適応することは困難である。また、そこで、ラベルなしデータセットも用いたクロスデータセット手法によって精度向上を図る。
まず、歩行者の空間的-時間的パターンを学習するために、ラベル付きデータセットを用いて学習した視覚的分類器を、ラベルなしデータセットに転送。次に、Bayesian fusion modelによって、学習された時空間パターンを視覚的特徴と組み合わせて、分類器を改善。最後に、ラベルのないデータを用いて分類器を段階的に最適化。
ラベルなし、ドメインが異なる環境に対して人物再同定を行う手法を提案する。モデルであるTFusionは4ステップにより構築(1)教師あり学習により識別器を構築(2)ターゲットであるラベルなしデータにより時空間特徴パターン(Spatio-temporal Pattern)を学習(3)統合モデルFを学習(4)ラベルなしのターゲットデータにて徐々に識別器を学習する(1〜4は図に示されている)。Bayesian Fusionを提案して、時空間特徴パターンと人物のアピアランス特徴を統合してドメイン変換を行う。
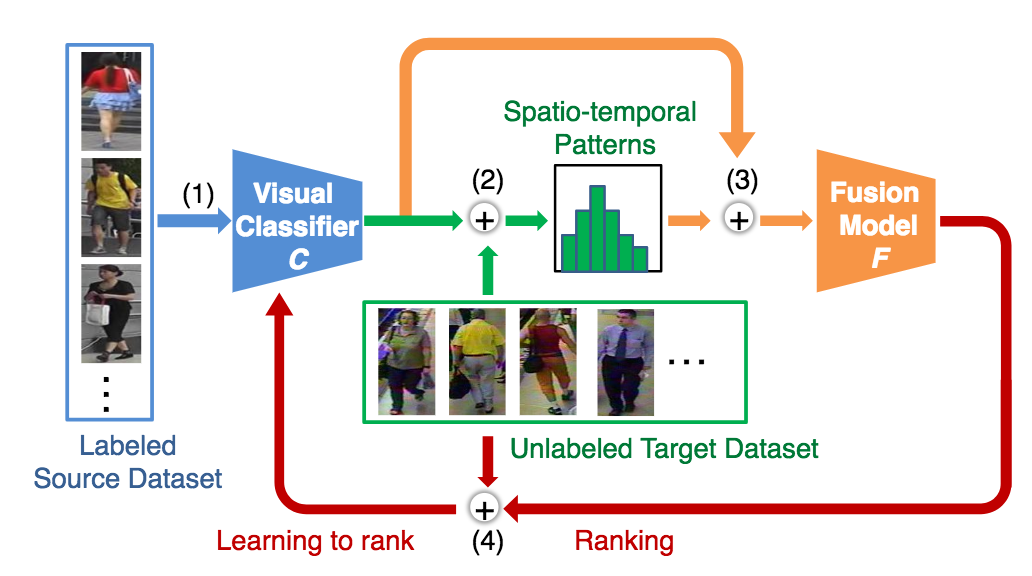
従来の人物再同定の設定では比較的小さいデータセットであり、完全に教師ありの環境を想定していたが、本論文ではラベルなし、ドメインが異なる環境に対して人物再同定を実行するため、非常に難しい問題となる。
単語を検出された画像の概念に関連付けるための、仮説検定を用いた教師なしTextual grounding手法の提案。ネットワークにはVGG-16を採用し、画像内のオブジェクト/単語の空間情報やクラス情報、およびクラス外の新しい概念を学習できる。
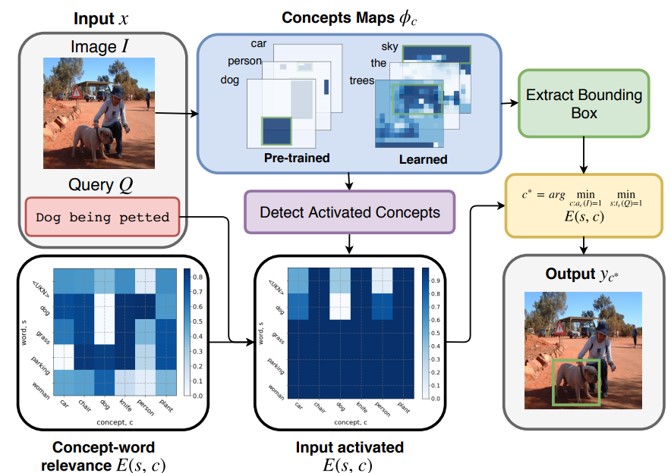
Textual grounding、すなわち画像内のオブジェクトと単語をリンクさせる既存の技法は、教師付きのディープラーニングとして定式化されており、大規模なデータセットを用いてバウンディングボックスを推定する。しかし、データセットの構築には時間やコストがかかるので教師なしの手法を提案。
自然言語のナビゲーションを入力として、実空間の中をロボットが動き目的地に到達できるかどうかを競うベンチマーク(Visually-grounded natural language navigation in real buildings)を提案。データセットは3Dのシミュレータによりキャプチャされ、22Kのナビゲーション、文章の平均単語数は29で構成される。

(1) Matterport3Dデータセットを強化学習を行えるように拡張。(2) 同タスクが行えるようなベンチマークであるRoom-to-Room (R2R)を提案して言語と視覚情報から実空間にてナビができるようにした。(3) seq-to-seqをベースとしたニューラルネットによりベンチマークを構築。VQAをベースにしていて、ナビゲーション(VQAでいう質問文)と移動アクション(VQAでいう回答)という組み合わせで同問題を解決する。
自然言語の問題はキャプションや質問回答の枠を超えて実空間、さらにいうとロボットタスクに導入されつつある。この研究はビジョン側からのアプローチだが、ロボット側のアプローチが現在どこまでできているか気になる。すでに屋内環境をある程度自由に移動するロボットが実現しているとこの実現可能性が高くなる。SLAMとの組み合わせももう実行できるレベルにある?
時系列の行動検出/セグメンテーション(Action Segmentation)に関する問題をWeakly-Supervised(WS学習)に解いた。ここではTemporal Convolutional Feature Pyramid Network (TCFPN)とIterative Soft Boundary Assignment (ISBA)を繰り返すことで行動に関する条件学習ができてくるという仕組み。TCFPNではフレームの行動を予測し、ISBAではそれを検証、それらを繰り返して行動間の境界線を定めながらWS学習の教師としていく。さらに、WS学習を促進するためにより弱い境界として行動間の繋がりを定義することでWS学習の精度を向上させる。学習はビデオ単位の誤差を最適化することで境界についても徐々に定まる(ここがWS学習の所以)ように学習する。
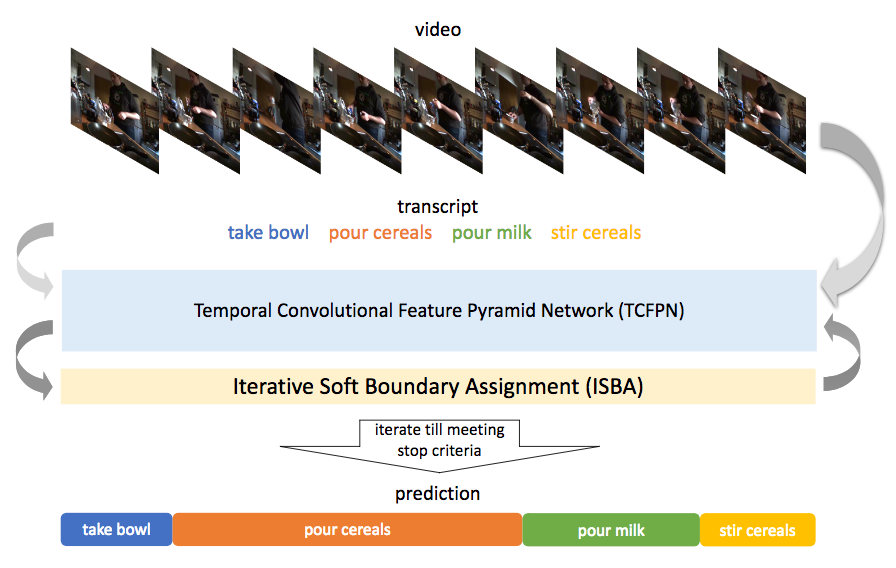
Breakfast dataset, Hollywood extended datasetにて弱教師付き学習とテストを行いState-of-the-artな精度を達成した。
犬視点の大規模ビデオデータセットを作成し、このデータを使用した、犬の行動や行動計画のモデル化。次の3つの問題に焦点を当てる。(1)犬の行動予測。(2)入力された画像対から犬のような行動計画を見出す。(3)例えば、歩行可能な表面推定などのタスクについて、学習された表現を利用。
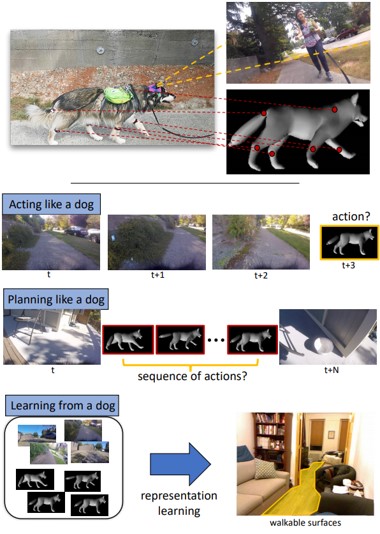
視覚情報からintelligent agent(知的エージェント)を直接的にモデリングするタスク。犬の視覚情報を使うことで、行動をモデル化する斬新な取り組み。得られたモデルをAIなどに応用する。特に、歩行可能な表面推定のタスクで良い結果となる。
カテゴリの単語の埋め込みと他のカテゴリとの関係(視覚データが提供される)を使用するだけで、学習例がないカテゴリの分類器を学習するゼロショット認識モデルを提案。 knowledge graph (KG) を入力とし、Graph Convolutional Network(GCN)を基に、セマンティック埋め込みとカテゴリの関係の両方を使用して分類器を予測する。

学習済のKGが与えられると、各ノードに対する意味的埋め込みとして入力を得る。一連のグラフ畳み込みの後、各カテゴリの視覚的分類器を予測する。トレーニング中に、カテゴリの視覚的分類器が与えられ、GCNパラメータを学習。テスト時に、これらのフィルタを使用して、見えないカテゴリの視覚的分類器を予測する。
学習済みデータと新しいドメイン(ground-truthなし)の両方を用いて、ディープステレオマッチングを行うZoom and Lean(ZOLE)の提案。これにより,他のドメインに一般化できるプレトレインモデルを作成することができる。一般化に際する不具合を抑制しながらアップサンプリングを行う、反復最適化問題を定式化する。

ground-truthデータが不足しているため、CNNを用いたステレオマッチングでは学習済みステレオモデルを新規ドメインに一般化することが困難とされていた。CNN学習時のイテレーションごとに最適化していくイメージ。
5分先までのアクションとそのアクションの持続時間を予測するためのモデルを2通り(RNN or CNN)提案。はじめに、両手法共にRNN-HMMより観測した動画中のアクション認識を行う。次にRNNモデルでは観測したアクションより得られた予測結果を再帰的に入力データとしたRNNを構築することで長期的な予測を可能とする。CNNモデルでは、アクションラベルとそのアクションの時間的長さをマトリクス化した入力データをCNNに与え、予測結果を出力する。
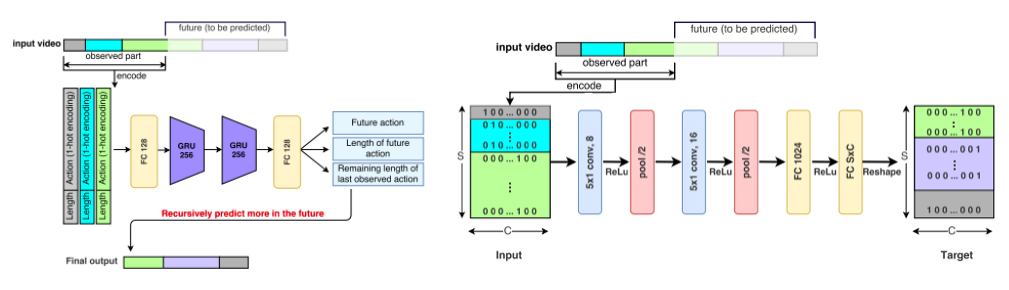
従来のアクティビティ予測手法は数秒先の予測を行う手法がほとんどだったのに対し、本論文では5分先までのアクティビティ予測がRNN/CNN両モデルにおいて可能となった。両モデルともに既存手法に対し複数のデータセットで有用な結果が出ており、予測対象が20秒以内の事象の場合、RNNモデルの方が良い結果が出た。
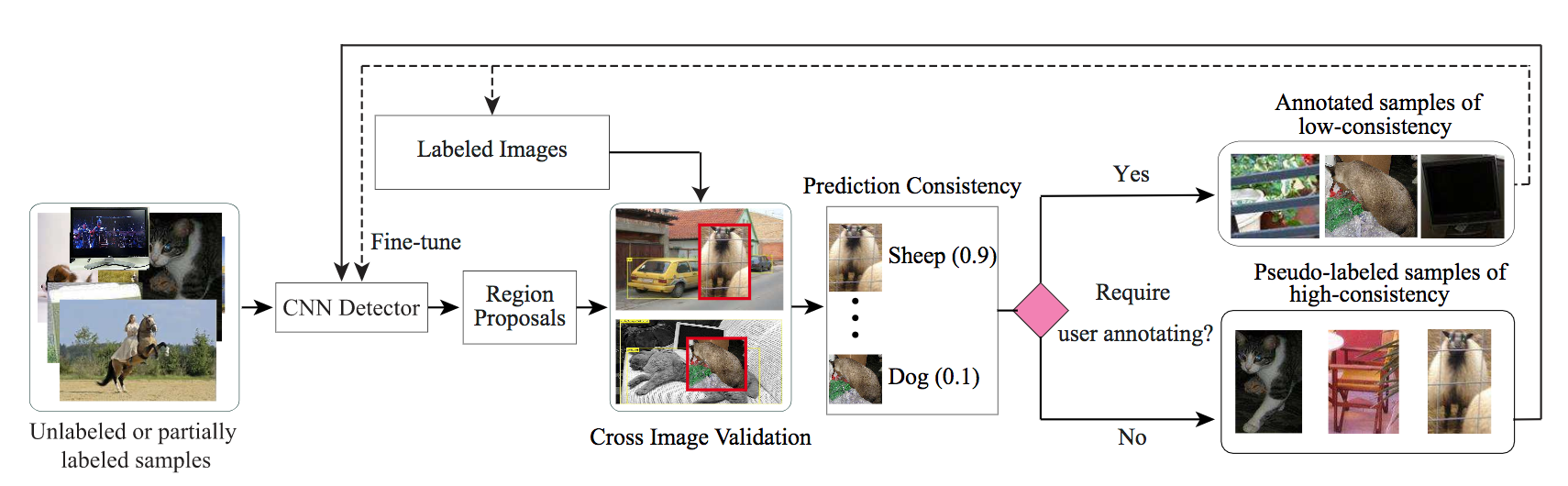
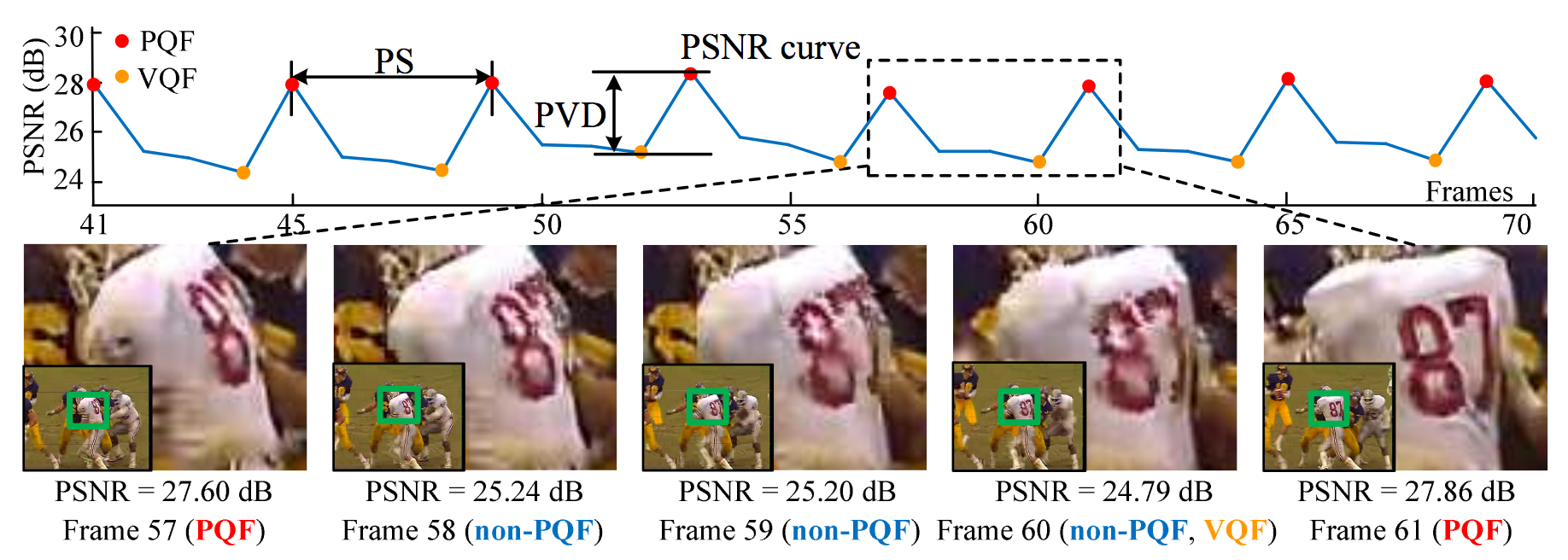
{kind=link}