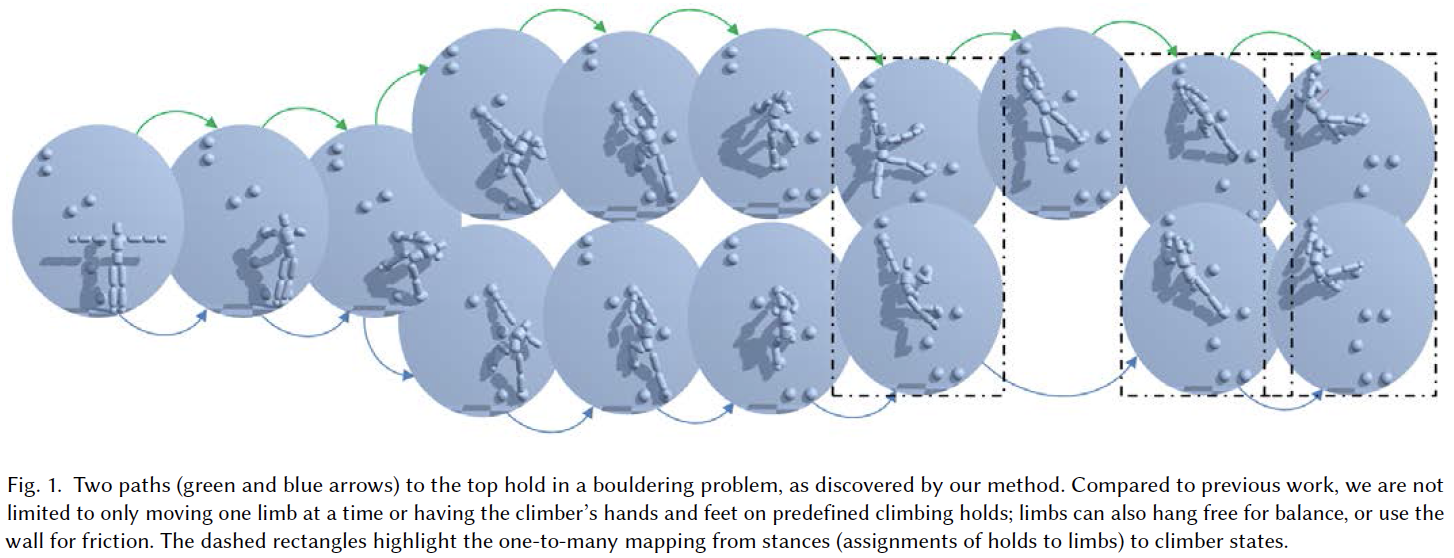
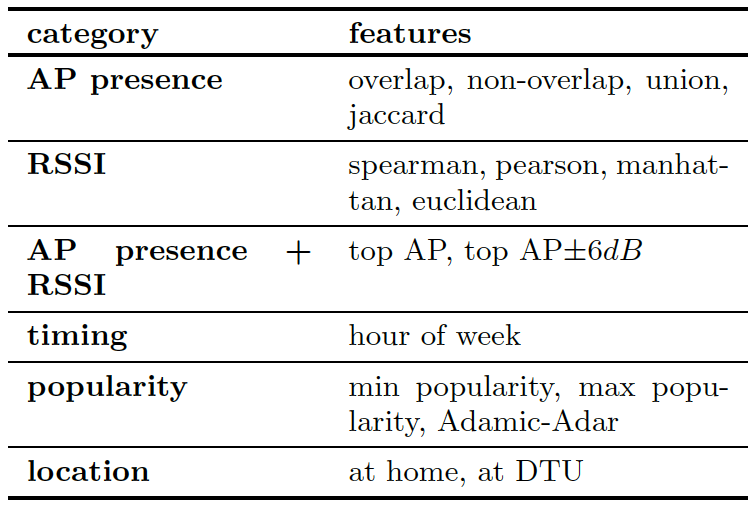
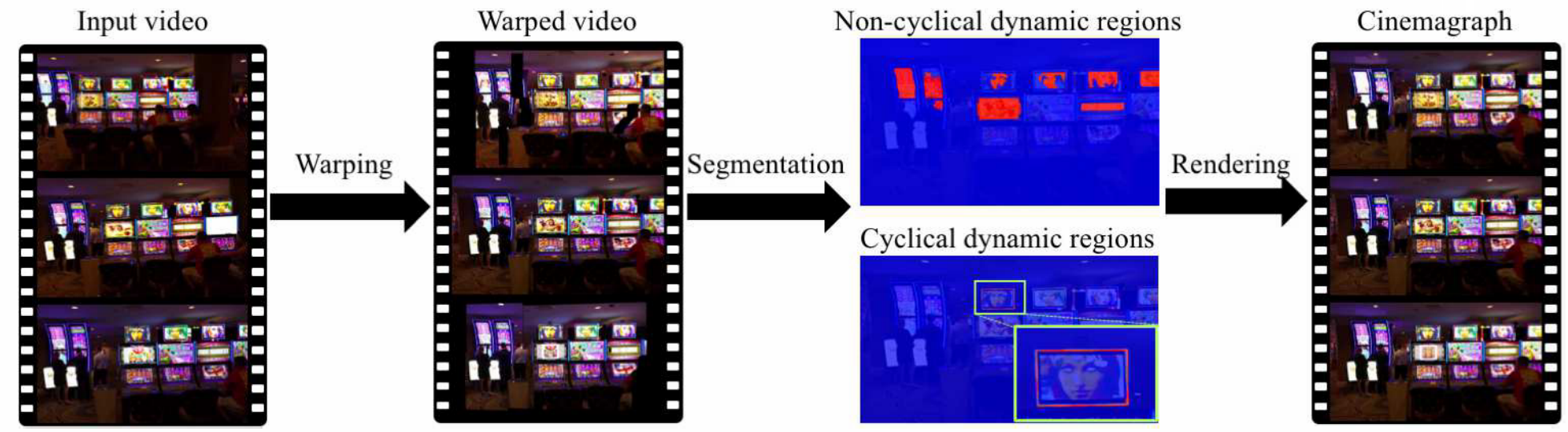
概要
Between-Class learning(BC learn)という画像分類タスクにおける新学習方法の提案。まず、異なるクラスの2枚の画像をランダムな比率で混合したbetween-class imageを作成。そして、画像を波形として扱うためにミキシングを行う。混合画像をモデルに入力し、学習することで混合した比率を出力する。これにより、特徴分布の形状に制約をかけることができるため、汎化性能が向上する。
Between-Class learning(BC learn)という画像分類タスクにおける新学習方法の提案。まず、異なるクラスの2枚の画像をランダムな比率で混合したbetween-class imageを作成。そして、画像を波形として扱うためにミキシングを行う。混合画像をモデルに入力し、学習することで混合した比率を出力する。これにより、特徴分布の形状に制約をかけることができるため、汎化性能が向上する。
もともとは、混合できるデジタル音声のために開発された手法。CNNは“画像を波形として扱っている”という説から、本手法を提案。2つの画像を混合する意味に疑問はあるが、実際にパフォーマンスが向上している。
ラベルノイズを使って、画像分類モデルを学習するCleanNetの提案。人間による“ラベルノイズの低減”という作業を低減する。事前知識として人の手で分類されたクラスの一部の情報だけを使い、ラベルノイズを他のクラスに移すことができる。また、CleanNetとCNNによるクラス分類ネットワークを1つのフレームワークとして統合。ラベルノイズ検出タスクと、統合した画像分類タスクの両方で、ノイジーなデータセットを使って精度検証。
人間がラベルのアノテーションをすると時間がかかり、学習はスケーラブルじゃない。逆に人間に頼らない手法はスケーラブルだが、有効性が低い。少し人間に頼って、あとは自動的にノイズ除去をするというハイブリットな手法。
ビジョンベースのインタフェースにおけるユーザの精神状態検出は最も重要な研究の1つである.本研究は4つの異なる状態を有する有限状態変換器(FST)を使用したフレームベースの精神状態検出システムを提案.カメラセンサを使用した2Dおよび3Dの仮想現実の画像データから,素早く,そして正確にユーザの精神状態(エンゲージメント)を知ることができる.
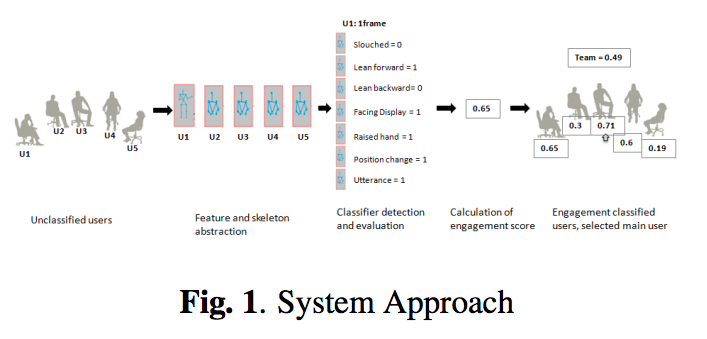
非言語の動きの分類のデータと精神状態の指標を組み合わせることで精神状態(エンゲージメント)を量子的に表示.
2016年に出た他人の顔表情を操るFace2Faceの続編的研究であり、(1)操られた顔を見破る(Real/Fake)識別、(2)操られた顔領域をセグメント、(3)Face2Faceした領域をより自然になるように補正を行なった。同タスクを解決するために、本論文ではリアルの顔表情の変化が含まれる動画とFace2Faceにより作成した1000動画を含むFaceForensics Datasetを作成して識別問題に取り組んだ。識別においてはSVM/CNNを含めベンチマーク的に複数の実装を評価した。セグメンテーションタスクには識別で良好な性能だったXceptionNetを用いた。さらに、RefinementにおいてはAutoencoder構造を用いた。
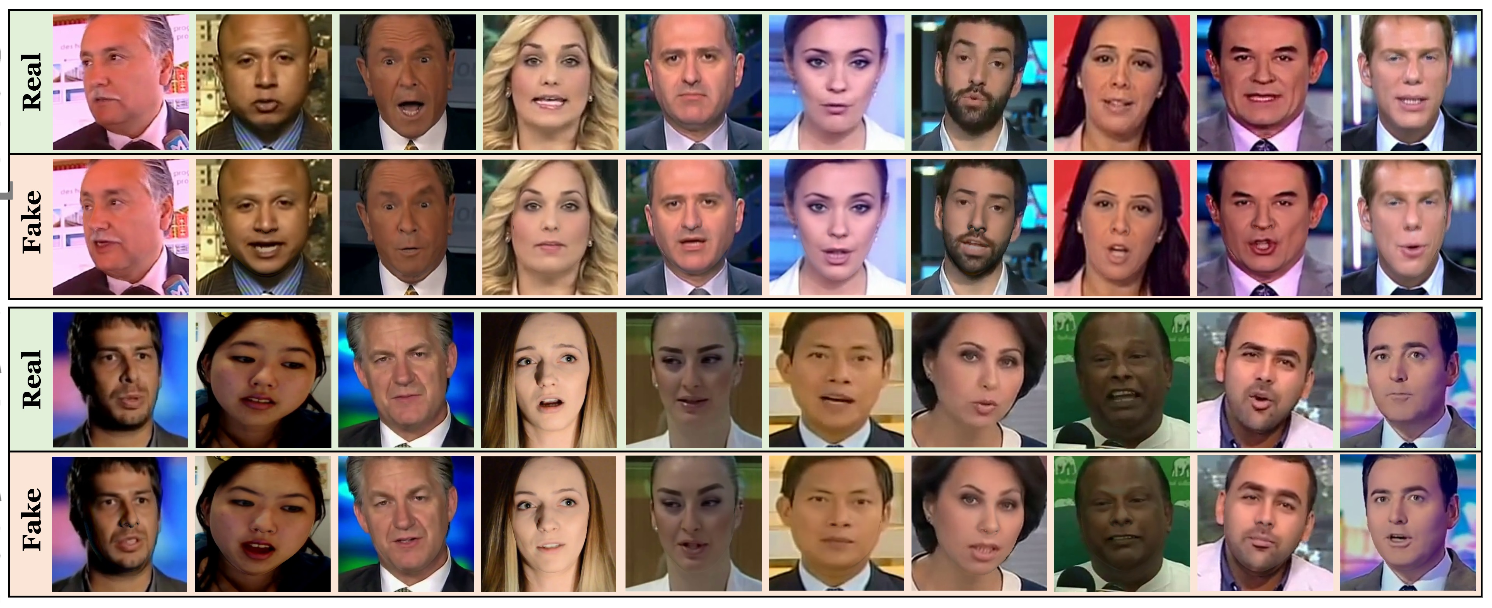
顔表情操作によるフェイク動画を作るのみならず、それを見破る識別器/セグメンテーション/修正器を作成したことが新規性として挙げられる。また、Real/Fakeのペアを多数含むデータセットを構築したことも貢献した。識別では簡単な場面ではほぼ100%、難しい状況でも90%弱くらいでの識別が可能である。詳細な結果はYouTubeの動画を参照されたい。
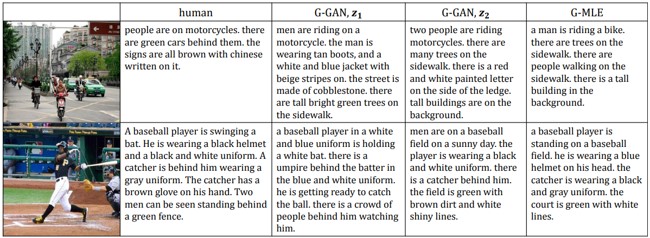
groundtruthキャプションの再生から人間のキャプションンとの見分けが付かないキャプション生成言葉の統計にマッチする偏りのない多様なキャプションの生成 敵対的キャプションジェネレータによるキャプション生成,ハイパーパラメータの調整にGANを使用することで精度も向上

提案されたadversarial modelによって、膨大なボキャブラリーかつ多くの斬新なキャプションを生成することができた
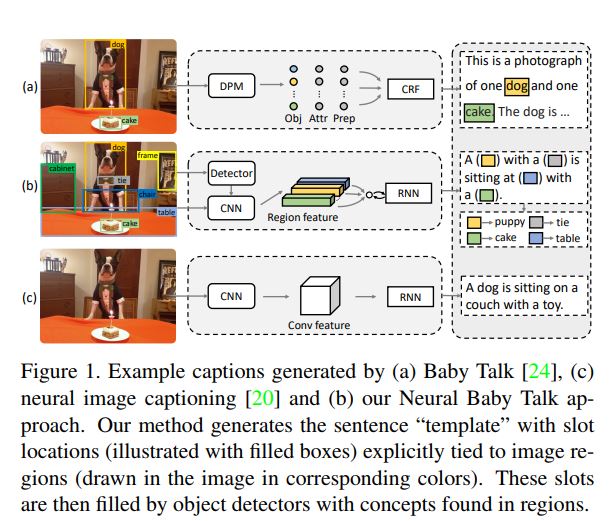
画像から認識された物体から自然言語を生成することが出来るイメージキャプショニングのための新たなフレームワークを作った.画像領域と明らかに関係する言葉と枠を持つテンプレを生成した後,画像領域と一致する物体を認識することで枠に言葉をはめ込む.
VRアプリケーションのためのハプティックデバイスは把持された仮想オブジェクトの剛性及び重量の感覚を正確に提示することが困難である。そこでVR空間上のオブジェクトをつかむためのグリップ力及び重さをシミュレーションするために設計されたGrabityを使った仮想オブジェクトの把持時の力覚フィードバックを提示する手法を提案した。
*非対称な振動の振幅を操作することによる仮想オブジェクトの剛性と重さを提示する
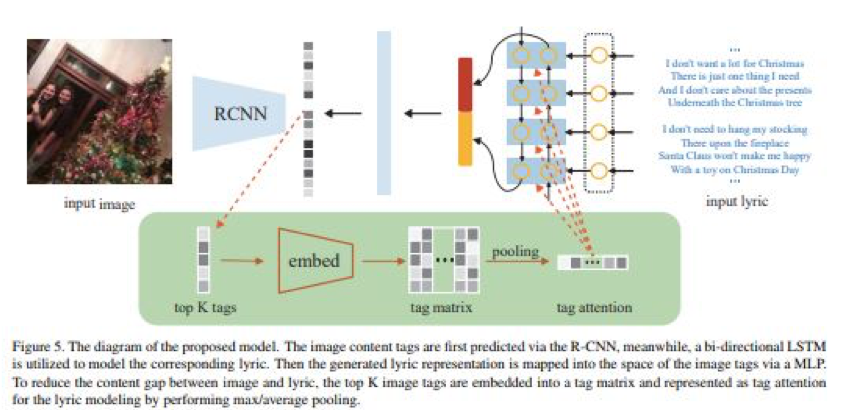
画像のセマンティックごとに関連する曲を自動選択,画像内容と歌詞の単語との間の相互関係を学習する意味ベースでの歌検索フレームワークを構築する.
画像コンテンツタグをR-CNNによって予測,歌詞はLSTMが対応する歌詞をモデル化する.
5つのデータ駆動アプリケーション(デザイン検索,UIレイアウト生成,UIコード生成,UIモデリング,ユーザ知覚推測) での使用を目的とした, モバイルアプリケーションのデザインの大規模データセットを作った. 9,700のアンドロイドアプリ,27カテゴリ.
データセットの作成に当たり,クラウドソーシングと自動生成を組み合わせたシステムを作った.アンドロイドアプリを実行したときにデザインとインタラクションを取ってくる.
UIレイアウトの類似性を評価するオートエンコーダを学習させてみて,デモンストレーションする.
クラウドワーカーのインタフェース
あるUIがあった時に,どのようにUIが使われるかのモデリングを行う分野があるが,そこにもビックデータを効率的に収集したい要請がある. UIデザインのような,少し抽象的なデータ集めの枠組みの作り方は参考にすべきと思う.
実際に学習させてみるところまでやっている.CVPRな研究者は得意そう.
構図のモデル化及び最適化手法の提案。画像からSaliencyを検出し、PCAにより次元を圧縮したものを構図を表す特徴量として扱う。 また、MAP推定によって入力画像を美化するためのクロッピング領域を決定する。

実験の結果、従来手法で扱われている三分割法などを定義することなく表現することに成功。
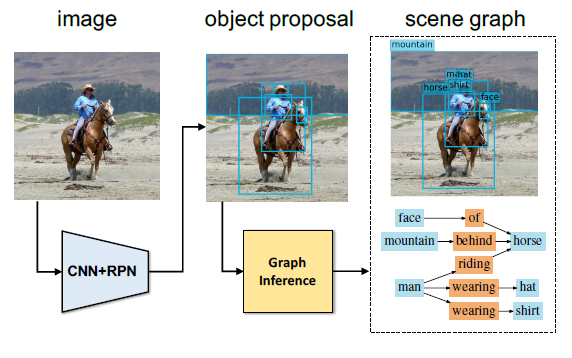
物体同士の関係を表すScene Graphsから画像を生成する手法の提案。従来のテキストから画像を生成する手法よりも物体の数が多く複雑なシーンの画像を生成することができる。 初めに、Scene Graphsを処理するネットワークによってScene Graphsを表現するベクトルを取得し、そこから画像のレイアウトを作成する。 次にレイアウトからCRN(参考文献)を用いて画像を作成する。 作成された画像は、画像全体のリアルさと各物体のリアルさを評価するDiscriminatorによってリアルな画像であるかを評価する。
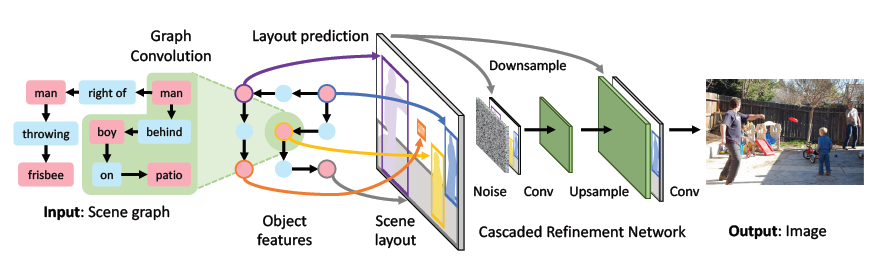
ユーザースタディの結果、StackGANと比較して合成結果が良いと答えた人が68%、認識可能な物体を生成できてると答えた人が59%という結果が得られた。
スケッチ検索のためのディープハッシングフレームワークの提案。3.8mの大規模スケッチデータセットを構築。CNNでスケッチの特徴抽出。RNNでペンストロークの時間情報をモデル化。CNN-RNNでエンコードすることで、スケッチ性質に対応した新しいhashing lossを導入。
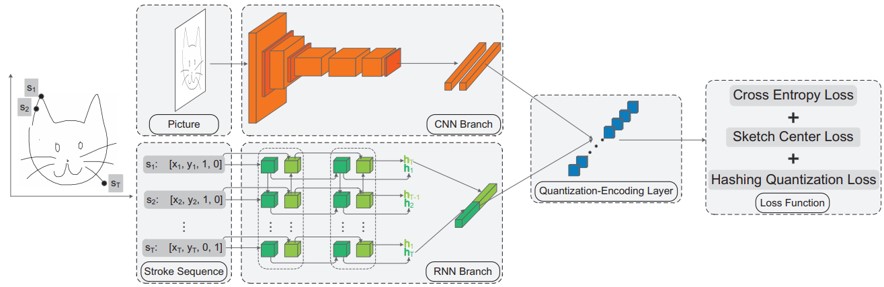
従来のスケッチ認識タスクに従う代わりに、より困難な問題のスケッチハッシュ検索を行う。ネットワークをスケッチ認識のために再利用することもでき、どちらも高パフォーマンス。大規模なデータセットを利用することで、従来の文献ではあまり研究されていなかった、スケッチのユニークな特性を見出す。
ソース画像のメイクをターゲット画像へ転写やメイクの除去をする研究。ターゲット画像とメイク済み画像の2枚を入力としメイクを転写するネットワークGとメイク済み画像らメイクを取り除くネットワークFを考え、2つのネットワークによって元の画像に戻るように学習していく。 その際、Fによってxに付与されたメイクがyのメイクと同じものであるかを評価するロスを加えることでメイクの特徴を捉える。 従来手法ではメイク転写・除去を独立した問題として考えていたが、この研究ではセットとして考えている。

Youtubeのメイクチュートリアルの動画から、1148枚のメイクなし画像と1044枚のメイクあり画像を収集。ユーザースタディによって2つの既存手法と比較し、提案手法が一番いいと答えた人が65.7%(2番目と答えた人が31.4%) 従来手法では肌の色や表情の違いがあると上手くいかないのに対し、ソースとターゲット間でこれらが違ってもうまく転写できる。
2枚の画像の類似度を表す指標は数多く提案されているが、その類似度は必ずしも人間の知覚と一致していない。近年はDNNにより高次の特徴を得ることが可能となっており、人間の知覚に近づいている。 そこで、既存の類似度の評価尺度とDNNベースの類似度判定を比較することでDNNベースの手法がより人間の知覚に近い類似度を表現できることを確認した。 具体的には、ある画像を異なる方法で加工したもの2つを用意し、どちらが元の画像に近いかを人間とコンピュータ両方に判定させることで検証を行った。
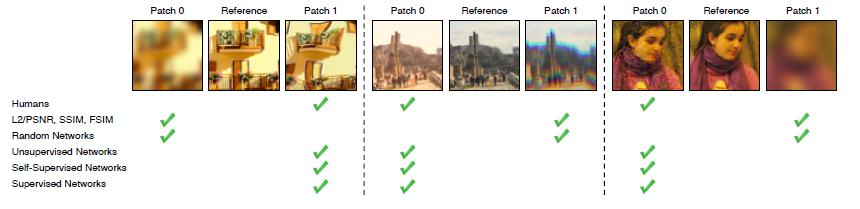
データセットとして、画像に様々な加工を施したデータを人間に類似度を評価してもらったものを作成。加工の例としては、ノイズの付与やオートエンコーダによる画像の復元などが挙げられる。 検証の結果、DNNベースの類似度の方が既存の尺度より人間の知覚に乗っ取ってることを示した。 また、DNNのネットワーク構造そのものは重要ではないことが分かった。
スタイルトランスファーによって画像をより記憶に残るようにする研究。入力画像に対して、どのスタイル画像がMemorablityを上昇するかを調べることによって実現する。 具体的には、Synthesizer、Scorer、Selectorの3つのネットワークを使用する。 Synthesizerはスタイルトランスファーのためのネットワーク、ScorerはMemorabilityを調べるネットワーク、Selectorは適切なスタイル画像を選択するネットワークとなっている。 学習時には、学習データに対してSynthesizerでスタイルの変換を施し、その画像に対してScorerでスコア付けを行い、スタイルを変化させた画像とソース画像のペア及びScorerによって得たスコアを学習データとしてSelectorの学習を行う。
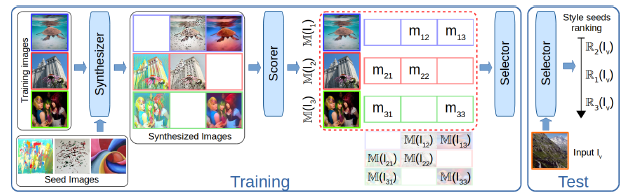
提案手法によって選択したスタイル画像を用いた際のスコア上昇は、全スタイル画像の平均上昇スコアよりも大きいことを示した。
CNNにおいて、入力画像に適用された2次元回転を認識するように学習する、自己管理特徴学習手法を提案。この単純なタスクによって、semantic feature learningの質の向上。
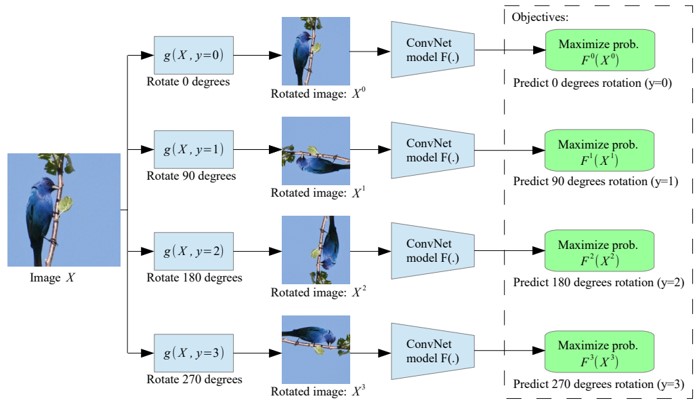
2018年現在、CNNは画像の意味的要素まで学習できるようになってきた。しかし、これには大量のデータが必要なため、教師なし学習に着目。回転を認識させる学習によって、物体認識、物体検出、セグメンテーションなどのさまざまな視覚的認識タスクに有用な意味的特徴を学習させることに成功。
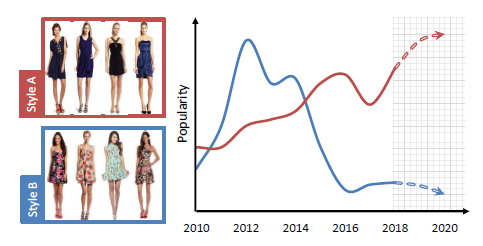
ファッションの流行遷移をCV的アプローチによって予測する研究。オンラインショッピングなどにおいてついているタグは不正確なことが多い。 そこで、画像からファッション特徴を抽出することでトレンドを予測する。 CNNによって画像からファッション特徴を抽出したのち、NMFを用いてスタイルに分解する。 最後にファッションの売り上げデータを用いて近い将来ファッションの人気がどのように遷移するかを予測する。
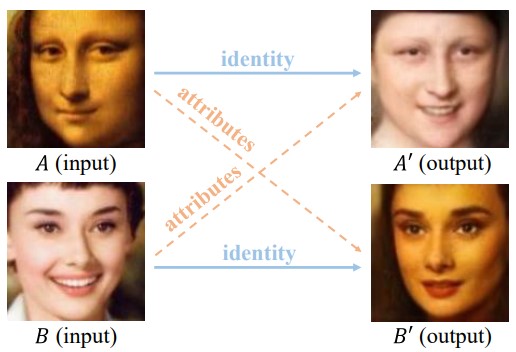
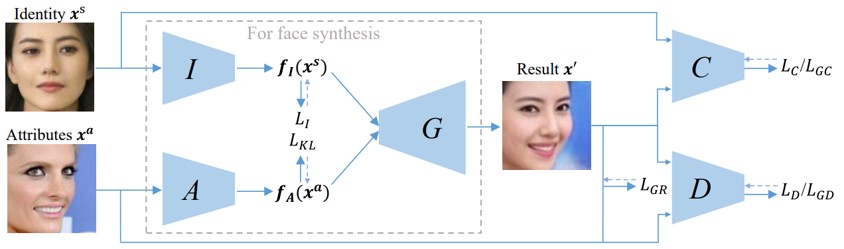
顔画像からidentityとattributesを別々に再構成する、GANに基づいたOpen-Set Identity Generating Adversarial Networkの提案。 face synthesis networkは、ポーズや感情、照明、背景などをキャプチャする属性ベクトルを抽出することができる。図中の2つの入力画像AおよびBから抽出された識別を再結合することによって、A0およびB0を生成することができる。
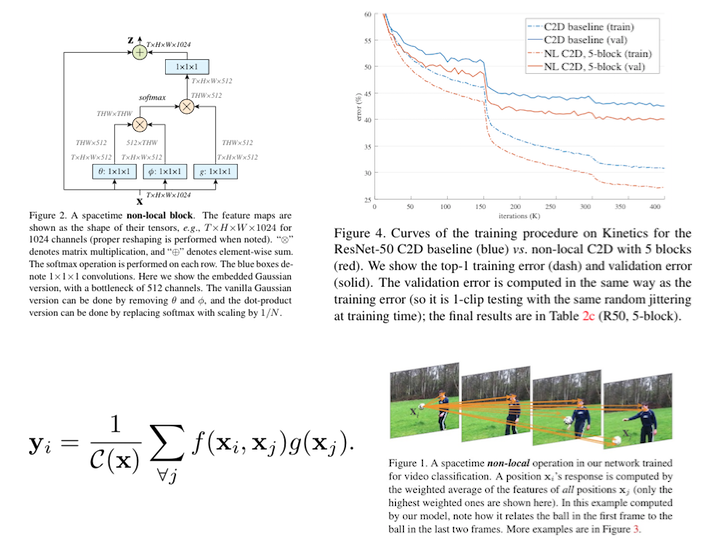
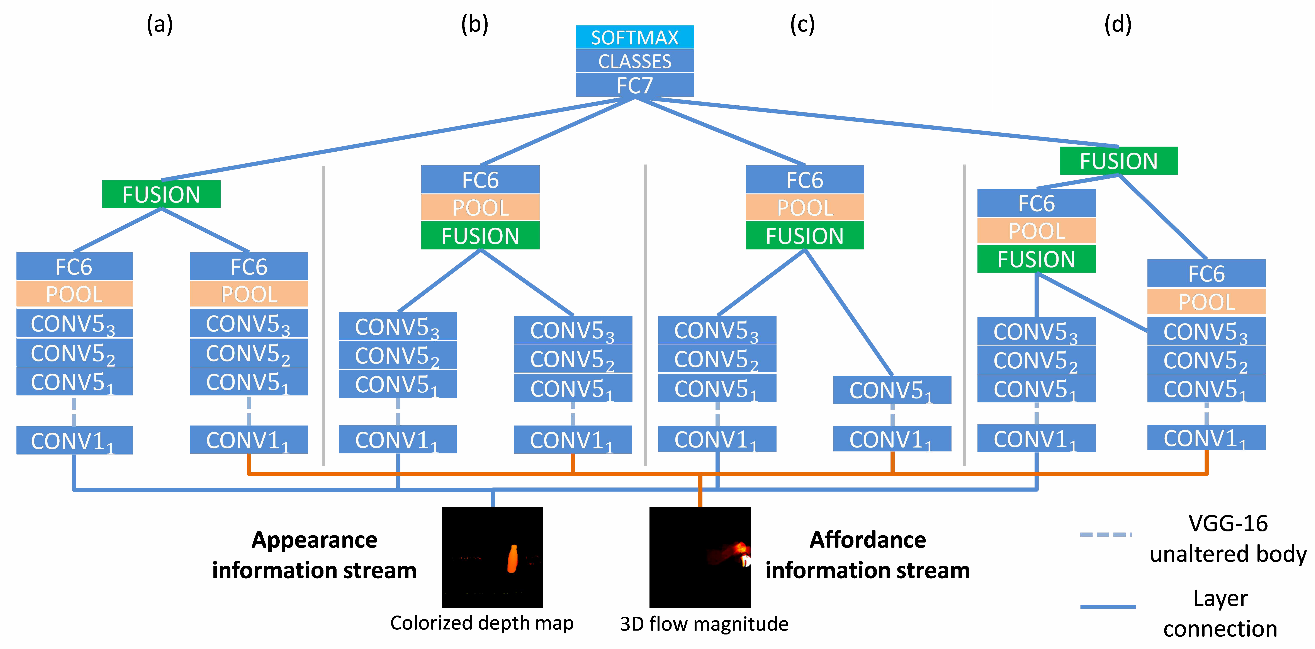
グローバル特徴プールを含む単一の共有ネットワークと、end-to-endで学習可能なタスク固有のsoft-attention modulesで構成された、multi-task learningアーキテクチャであるMulti-Task Attention Network (MTAN)の提案。図の(a)は、セマンティックセグメンテーションと深度推定のタスクのための、学習したアテンションマスクの例。(b)は、MTANの概要。

MTANによって、グローバル・プールからのタスク固有の機能の学習が可能になると同時に、異なるタスク間で機能を共有できる。本アーキテクチャは、任意のfeed-forward neural network上に構築することができ、実装が簡単かつパラメータ効率が良い。
単語を検出された画像の概念に関連付けるための、仮説検定を用いた教師なしTextual grounding手法の提案。ネットワークにはVGG-16を採用し、画像内のオブジェクト/単語の空間情報やクラス情報、およびクラス外の新しい概念を学習できる。
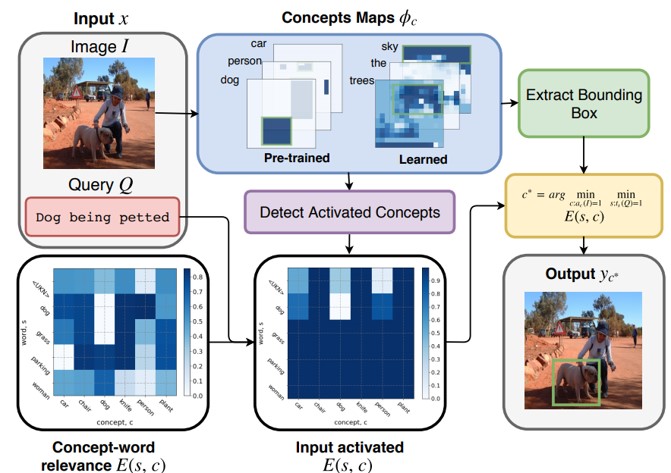
Textual grounding、すなわち画像内のオブジェクトと単語をリンクさせる既存の技法は、教師付きのディープラーニングとして定式化されており、大規模なデータセットを用いてバウンディングボックスを推定する。しかし、データセットの構築には時間やコストがかかるので教師なしの手法を提案。
ビデオQAのための、 Dynamic Memory Network(DMN) のコンセプトに基づいたmotion-appearance comemory networkの提案。本研究の特徴は次の3つである。(1)アテンションを生成するために動きと外観情報の両方を手がかりとして利用する共メモリアテンションメカニズム。(2) multi-level contextual factを生成するための時間的conv-deconv network。(3)異なる質問に対して動的な時間表現を構成するdynamic fact ensemble method。
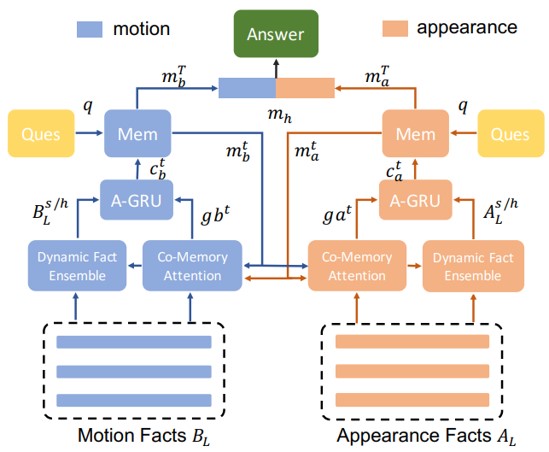
本手法は、次のようなvideo QA特有の属性に基づいている。(1)豊富な情報を含む長い画像シーケンスを扱う。(2)動き情報と出現情報を相互に関連付け、アテンションキューを他の情報に応用できる。(3)答えを推論するために必要なフレーム数は質問によって異なる。
入力フレームだけでなく、ピクセル単位の文脈情報を用いて、高品質の中間フレームを補間するためのコンテキスト認識手法の提案。まず、プレトレインモデルを使用して、入力フレームのピクセルごとのコンテキスト情報を抽出。オプティカルフローを使用して、双方向フローを推定し、入力フレームとそのコンテキストマップの両方をワープする。最後にコンテキストマップをsynthesis networkに入力し、補間フレームを生成。
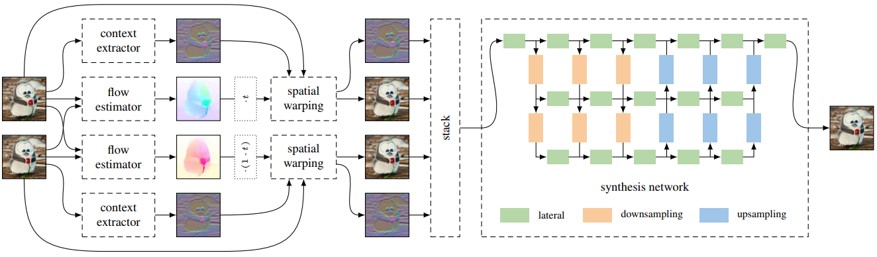
従来のビデオフレーム補間アルゴリズムは、オプティカルフローまたはその変動を推定し、それを用いて2つのフレーム間の中間フレームを生成する。本手法では、 2つの入力フレーム間の双方向フローを推定し、コンテキスト認識という方式をとることで精度向上を図る。
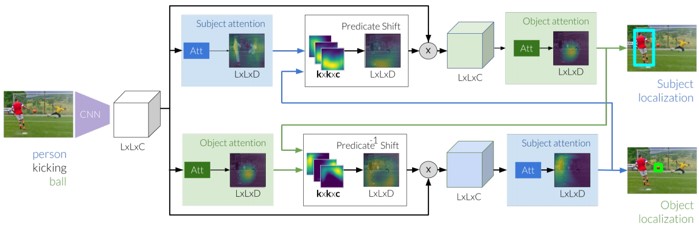
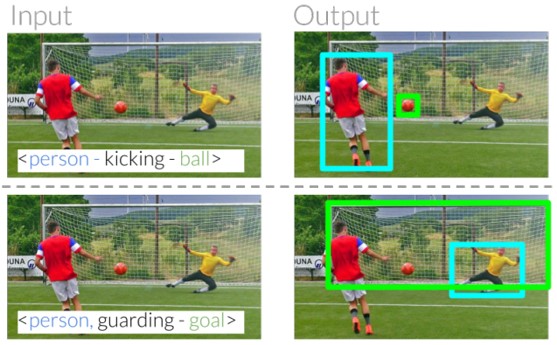
referring relationshipsを利用して同カテゴリのエンティティ間の曖昧さを解消するタスクの提案。特徴抽出後、アテンションを生成。述語を使用することで、アテンションをシフトさせる。この述語シフトモジュールを介して、subjectとobjectの間でメッセージを反復的に渡すことで、2つのエンティティをローカライズ。
テキスト分類のためのDNNアプローチで階層的分類を行うHierarchical Deep Learning for Text classification (HDLTex)の提案。第1段階の分類(図の左側)がDNN。第2段階の分類は、1段階目の出力と接続されている。1段階目の出力がComputer Scienceの場合、2段階目(Ψ1)は全てComputer Scienceの文章のみで学習する。よって、1段階目は全ての出離の文章、2段階目は指定された文章のみで学習する。
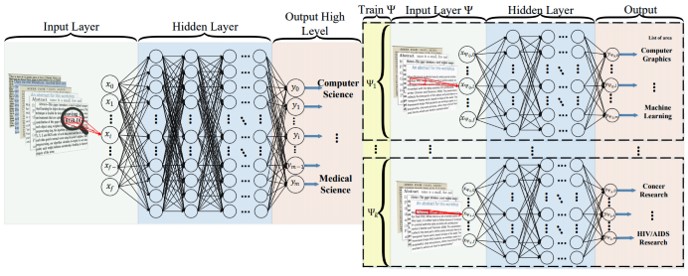
テキストの検索や整理のための情報処理方法の改善が必要となっており、文書分類が重要。従来の分類器の性能は、文書の数が増えるにつれて低下傾向にあり、これはカテゴリ数が増加したためだと指摘。そこで、この問題を多クラス分類と見なす従来の文書分類方法とは異なるアプローチを提案。
犬視点の大規模ビデオデータセットを作成し、このデータを使用した、犬の行動や行動計画のモデル化。次の3つの問題に焦点を当てる。(1)犬の行動予測。(2)入力された画像対から犬のような行動計画を見出す。(3)例えば、歩行可能な表面推定などのタスクについて、学習された表現を利用。

視覚情報からintelligent agent(知的エージェント)を直接的にモデリングするタスク。犬の視覚情報を使うことで、行動をモデル化する斬新な取り組み。得られたモデルをAIなどに応用する。特に、歩行可能な表面推定のタスクで良い結果となる。
時系列の行動検出/セグメンテーション(Action Segmentation)に関する問題をWeakly-Supervised(WS学習)に解いた。ここではTemporal Convolutional Feature Pyramid Network (TCFPN)とIterative Soft Boundary Assignment (ISBA)を繰り返すことで行動に関する条件学習ができてくるという仕組み。TCFPNではフレームの行動を予測し、ISBAではそれを検証、それらを繰り返して行動間の境界線を定めながらWS学習の教師としていく。さらに、WS学習を促進するためにより弱い境界として行動間の繋がりを定義することでWS学習の精度を向上させる。学習はビデオ単位の誤差を最適化することで境界についても徐々に定まる(ここがWS学習の所以)ように学習する。
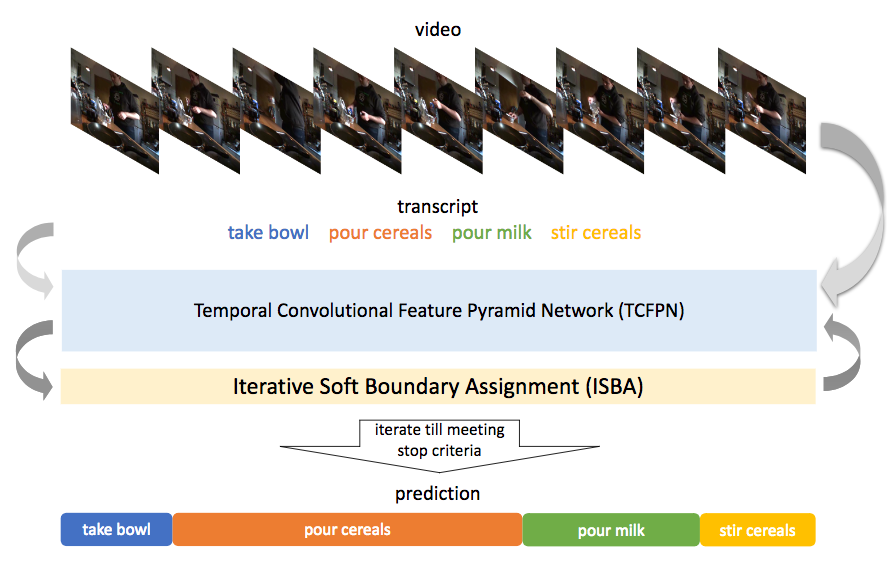
Breakfast dataset, Hollywood extended datasetにて弱教師付き学習とテストを行いState-of-the-artな精度を達成した。
マスクを生成するbinary segmentation netとバウンディングボックスを生成するlocalization net 、2つのネットワークの出力を融合させることでインスタンスレベルのビデオオブジェクトセグメンテーションを行うMaskRNNの提案。時間経過による逆伝搬によってend-to-endで学習でき、2つのネットワークを最適化する。
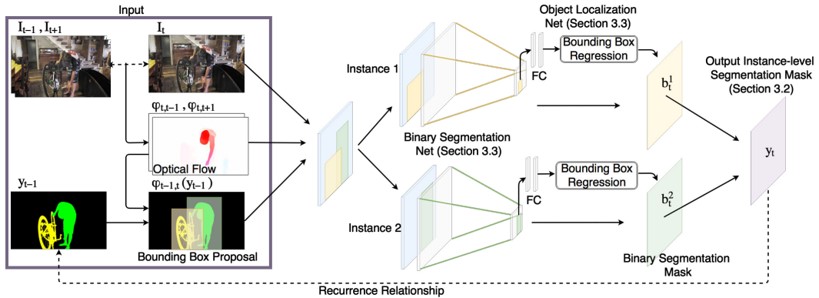
2つのネットワークを使用することで、ビデオデータの長期的な時間的情報を利用でき、ノイズも低減できる。マルチオブジェクトに対応、図は人と自転車の2つのオブジェクトにおける例。
CNNのような理由を突き止める能力がない認識システムを超えた、反復的なvisual reasoningのための新しいフレームワークの提案。畳み込みベースのローカルモジュールとグラフベースのグローバルモジュールの2コアで構成。2つのモジュールのを繰返し展開し、予測結果を相互にクロスフィードして絞り込む。最後に、両方のモジュールの最高値をアテンションベースのモジュールと組み合わせてプレディクト。
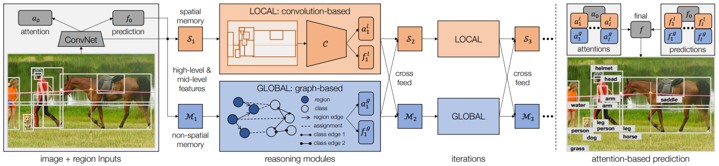
ただ畳み込むだけでなく、Spatial(空間的)およびSemanticの空間を探索することができる。下図のように、「人」は「車」を運転するというSpatialとSemanticの双方を兼ね備えた認識を行うことで精度向上を図る。
通常のCNNと比較して、ADEで8.4%、COCOで3.7%の精度向上。

RGB画像から表面の法線とオクルージョン境界を予測し、 RGB-D画像と組み合わせて、欠けている奥行き情報を補完するDeep Depth Completionの提案。また、奥行き画像と対になったRGB-D画像のデータセットであるcompletion benchmark datasetを作成し、性能を評価。これは、低コストのRGB-Dカメラでキャプチャした画像と、高コストの深度センサで同時にキャプチャした画像で構成されている。
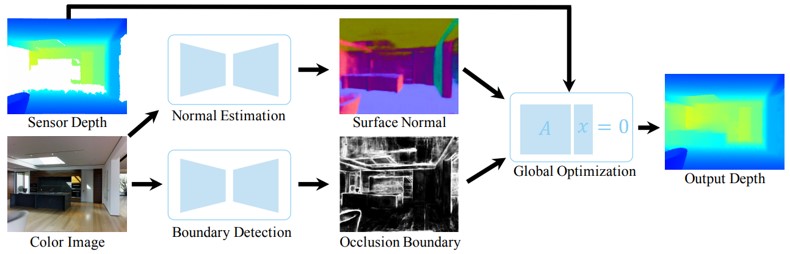
深度カメラは、光沢があり、明るく、透明で、遠い表面の深さを感知しないことが多い。 このような問題を解決するために、本手法ではRGB画像から得た情報と組み合わせて、 RGB-D画像の深度チャネルを完全なものにする。
単一のパースペクティブまたはパノラマ画像から屋内3Dルームレイアウトを推定するLayoutNetの提案。最初に、消失点を分析し、水平になるように画像を整列。これにより、壁と壁の境界が垂直になり、ノイズ低減。画像からコーナー(レイアウト接合点)と境界を、エンコーダ/デコーダ構造のCNNで出力。最後に、3D Layoutパラメータを、予測したコーナーと境界に適合するように最適化する。
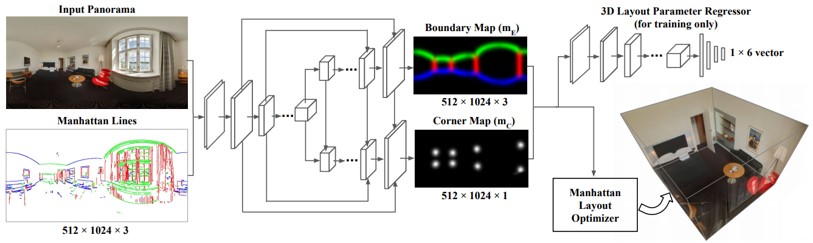
アーキテクチャはRoomNetと似ているが、消失点に基づいて画像を整列させ、複数のレイアウト要素(コーナー、境界線、サイズ、平行移動)を予測し、 “L”形の部屋のような非直方体のマンハッタンレイアウトに対しても適応できる。
VQAタスクにおける、DNNの最後から2番目の層にexplicit reasoning layerを追加する。 これにより、常識的な知識が必要な質問に対する回答が可能となり、出力した回答を人間が解釈できるようなインタフェースを提案。reasoning layerは、視覚的な関係、質問の意味解析、word2vecとConceptNetのオントロジーなどを推論するProbabilistic Soft Logic(PSL)ベースのエンジンとなっている。
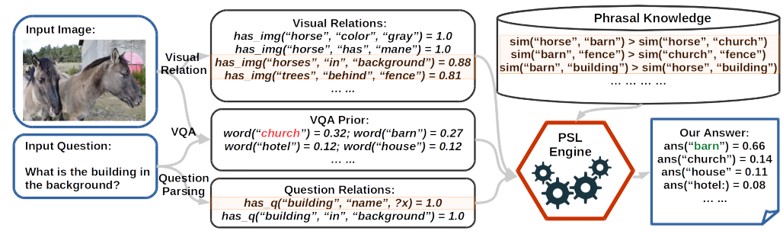
VQAなどのvisionや言語タスクでは、DNNを使用して精度向上を図っている。しかし、更なる精度向上には画像や自然言語処理以外の常識的知識を使った推論が必要とされている。また、このようなシステムは一般に不透明(人間が理解できない)であり、予備知識が必要とされる質問を理解するのは困難。本手法によって、常識的知識を追加し、人間に理解できるインタフェースを提案。
Polygon-RNNのアイデアを踏襲し、ヒューマン・イン・ザ・ループを使って対話的にオブジェクトのポリゴンアノテーションの生成。また、新しいCNNエンコーダアーキテクチャの設計、強化学習によるモデルの効果的な学習、 Graph Neural Networkを使用した出力解像度の向上を行う。これらのアーキテクチャをPolygon-RNN ++と呼ぶ。
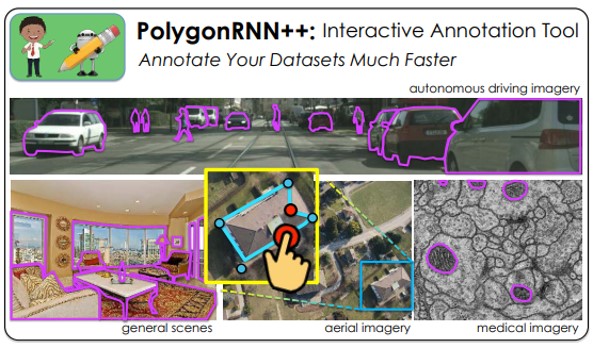
アノテーション作成時の負担を軽減。より正確にアノテーションを付加できるため、雑音の多いアノテーターに対しても頑健である。
高い汎化能力となり、既存のピクセルワイズメソッドよりも大幅に改善。ドメイン外のデータセットにも適応可能。
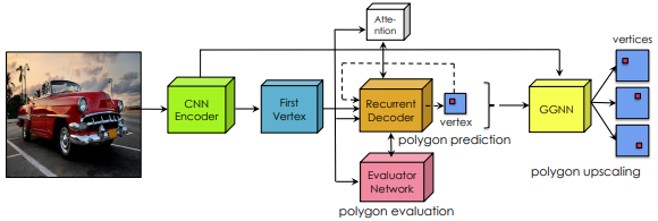
人間の視覚的外観を、人の手によるアノテーションなしかつ、複数のセマンティックレベルで識別因子に分解する Multi-Level Factorisation Net(MLFN)の提案。 MLFNは、複数のブロックで構成されており、各ブロックには、複数の因子モジュールと、各入力画像の内容を解釈するための因子選択モジュールが含まれている。
効果的なRe-IDを目指すには、高低のセマンティックレベルでの人の差別化かつ視界不変性をモデル化することである。 近年(2018)のdeep Re-IDモデルは、セマンティックレベルの特徴表現を学習するか、アノテーション付きデータが必要となる。MLFNではこれらを改善する。
頑健性と効率性を考慮した、 Structure-from-Motionアプローチであるcommunity-based SfM(CSfM)の提案。画像をコミュニティにクラスタ化することで、内側が密、外側は疎になるように接続することができる。まず、エピポーラ幾何学グラフを別々のコミュニティに分割し、各コミュニティで並列に再構成処理を行う。そして、新しいグローバル類似度平均法によってマージする。
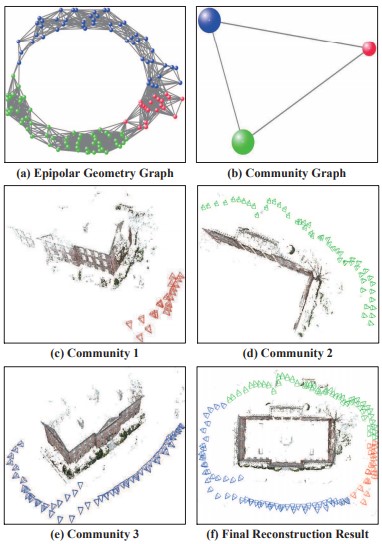
SfMのアプローチは、次の2つのクラスに大きく分けられる。 (1)インクリメンタル方式は外れ値に対して堅牢だが、誤差の蓄積と計算時の負荷が大きい。 (2)グローバルな方法は、すべてのカメラポーズを同時に推定するという利点があるが、通常、エピポーラ幾何学を算出する際に異常値を生じやすい。これらの、従来のSfMの問題を解決。
RGB-Dの顕著な物体の検出のための、深度拡張ネットワークであるPDNetの提案。画像ピクセルのRGB-D値をネットワークに直接送るのではなく、RGB値を処理するためのマスターネットワークと、D値(深度)を組み込むサブネットワークで生成した特徴をマスタネットワークに追加する。ラベル付きRGB-Dデータセットは少ないため、大規模なRGBデータセットを使用してマスターネットワークをプレトレインする。
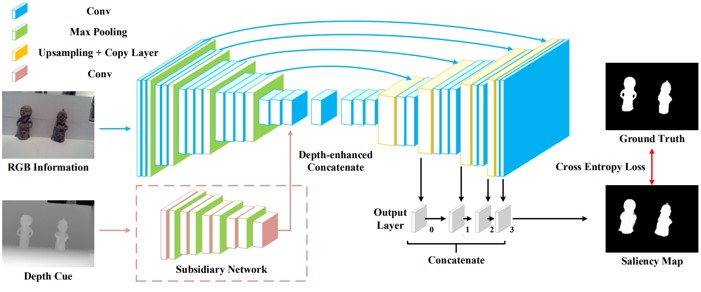
FCNは、多くのタスクにおいて優れているが、顕著性検出において2つの問題があると指摘。 1つ目は、ネットワークを学習するための大規模なラベル付きデータがないこと。2つ目は、ノイズがあるシーンなどにおいて、頑健でないこと。PDNetでは上記を改善。
空間ピラミッドプーリングと3D CNNの2つのモジュールから構成された、ステレオ画像対からの奥行き推定を行うPyramid Stereo Matching Network(PSMNet)の提案。空間ピラミッドプーリングは、異なるスケールおよび位置でコンテキストを集約し、コストボリュームを形成する。 3D CNNは、複数のhourglass networksを重ねて、コストボリュームを規則化することを学習。
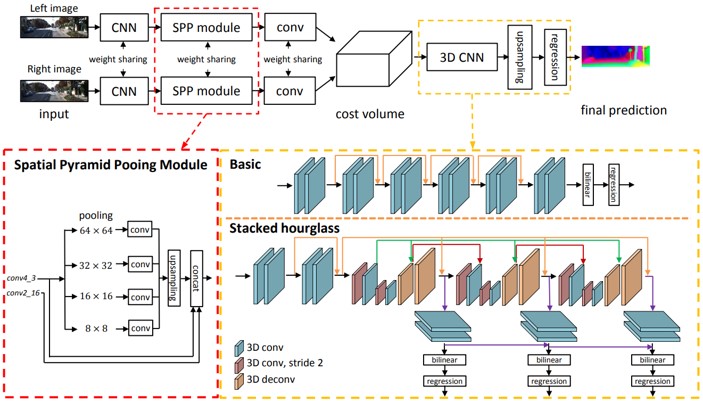
現在(2018)ではステレオ画像からの奥行き推定を、CNNの教師あり学習で解決されてきている。 コンテキスト情報を利用することで精度向上を図る。
2D画像からメッシュ、法線、深度マップなどの3D表現を予測できるフレームワークを提案。人が着用するTシャツのしわなど、表面をより詳細に、正確にモデル化できる。基本的にはShape-from-Shading技術に関連する技術。
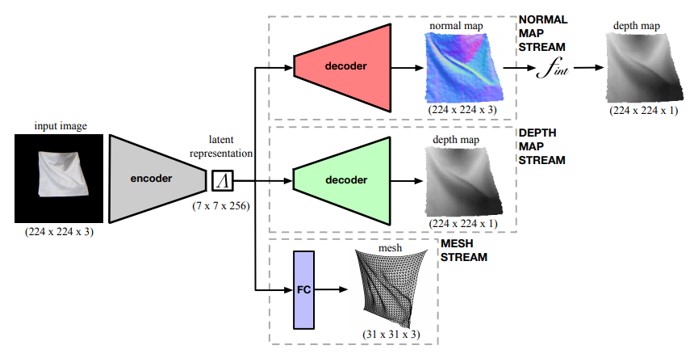
画像から、テクスチャを加えることで表面の3D形状を再現する手法は開発されている。しかし、テクスチャのない表面の3D形状を回復することはできていない。
2つの領域(例えば、骨格と表面、部分的および完全なスキャンデータ)からポイントベースの形状表現に幾何学的変換するための、汎用DNNであるP2P-NETの提案。データから学習された点群に変換、またはその逆の変換を行う双方向点変位ネットワーク。lossは、予測された点集合と目標点集合との間の形状的類似性を比較する幾何学的損失と、逆方向に進む変位ベクトル間の相互正規化項とを組み合わせる。
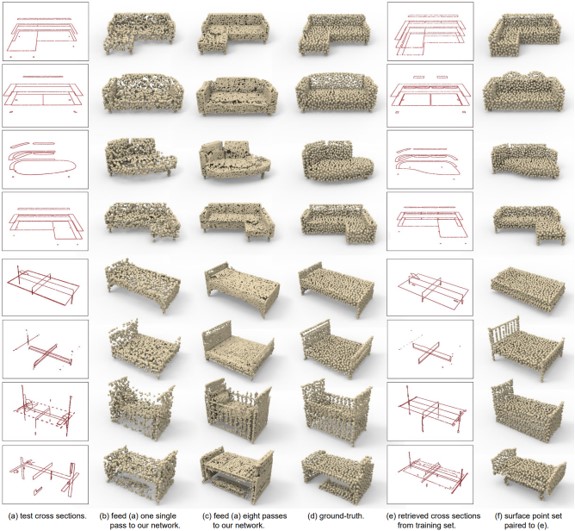
ポイントセットを1つのドメインから別のドメインにマッピングするように学習することにより、2Dまたは3D空間に配置できる。また、マッピングは2Dプロファイルを3D形状に変換することも可能。
元の低解像度画像から高解像度画像を再構築するための、深くてコンパクトなCNNを提案。提案モデルは、特徴抽出ブロック、積み重ね情報蒸留ブロック、再構成ブロックの3部構成。これにより、情報量が豊富かつ効率的に特徴を徐々に抽出できる。
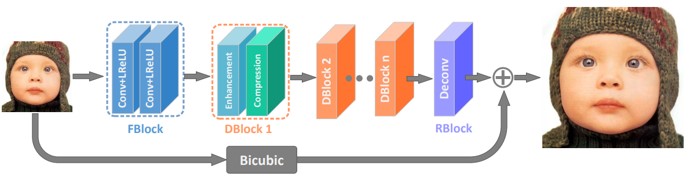
CNNが超解像殿画像を扱うようになってきたが、ネットワークが増大するにつれて、計算上の複雑さとメモリ消費という問題が生じる。これらの問題を解決するためのコンパクトなCNN。
CNNを圧縮するために、低ランク近似を適用する反復アプローチの提案。入力モデルを反復して圧縮していき、構成と重みを出力する。反復の中でノイズ低減をアルゴリズムを追加し、精度低下を避ける。
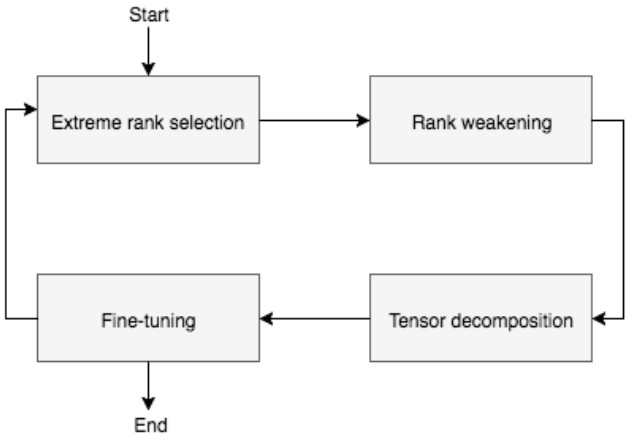
CNNには数千万のパラメータが含まれているため、組み込み機器で効率的に動作することは不可能。AlexNet、VGG-16、YOLOv2、およびTiny YOLOネットワークを圧縮することで、CNNを多様化。
ロボットのジェスチャをワンショットで認識する時,人間と機械でどんな違いがあるのかを見た.ロボットは2腕あるロボット腕のBaxter. 機械側はワンショット骨格情報からHMM,SVM,CRF,DTWで認識.人間側は10人. モーションのサンプルは,動きが大きく変わる顕著な時点を選んだ.
人間は'Shoot'が比較的わかりにくい(3/10人わからなかった).
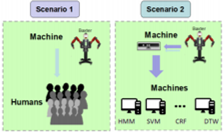
ロボットのジェスチャのワンショット認識をHRIに水平思考しただけだが,HRIとしての話題としてだけ見れば結構面白い. 「選ぶジェスチャとか機械側の手法に大きく依るじゃん」などのツッコミが多々あるが,そこは今後に期待.
生徒にとって、相対的な考えを必要とする星座の日周運動や年周運動を理解することが困難である。
仮想環境内における教員の介入による指導が可能な、没入型天体教材の開発。
3次元ジェスチャ装置によって学習者及び講師の手の動きを認識し,仮想空間に手のCGモデルを表示する。
学習者はHMDを装着(教員は3次元ジェスチャ装置を用いて仮想空間内で手のジェスチャしながら説明)。
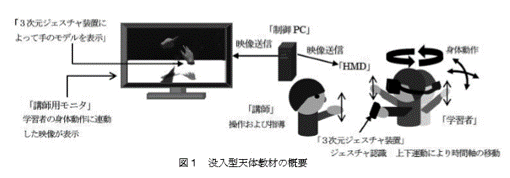
生徒に星座を教えるのに仮想現実(Virtual Reality:以下VR)。
3次元ジェスチャ装置(Leap Motion)を用いて教師の手の動きを認識し、仮想空間に手のCGモデルを表示する。
実験後にアンケートにより回答を得たところ、肯定的な回答では「たのしい・おもしろい」、「没入感があって星の動き・位置が分かりやすい」となった。否定的な回答では「目が痛い・疲れる」、「酔った」、「Leap Motionの位置がわかりずらい」となった。
ニューラルネットによりリアルタイムにキャラクターを操作するPhase-Functioned Neural Networkを提案する。ある動作(ここでは主に歩行、runningという意味で走行、ジャンプ、登る)というのはある周期性を持つと仮定して重みを計算し、ユーザの操作に応じて動作を柔軟に変更することができる。より柔軟な動きにするために、モーションキャプチャのデータを大量に使用してニューラルネットを学習した。

モーキャプデータを大量に使用してニューラルネットを学習することで、ユーザフレンドリな動作表現を実現した。動的な結果についてはYouTubeを参照されたい。
階層的強化学習により、3次元アニメーションにおいて道順さえ教えれば歩行動作を自動で獲得するアルゴリズムを提案した。より速いレートで関節やバランスをコントロールするLLC(Low-level Controller)と道を外れずにゴールを目指すことができるHLC(High-level Controller)を階層的に組み合わせて歩行動作を獲得する。

階層的な強化学習(Hierarchical Reinforcement Learning)により歩行動作を自動で獲得した。曲がりくねった道、サッカーボールのドリブル、障害物中の歩行(いずれも図に示されている)などの場面でより自然な歩行動作を獲得した。
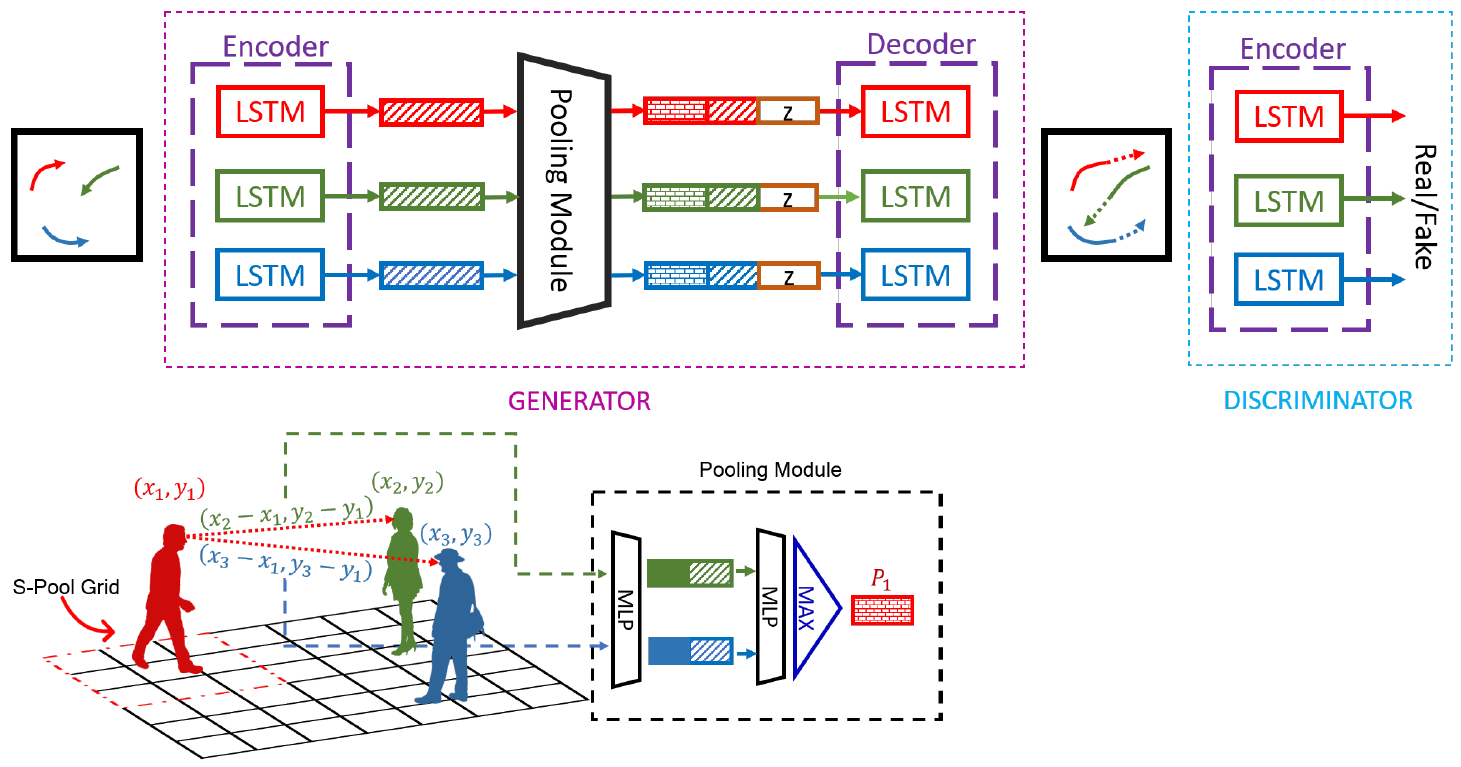
密な3次元サーフェイス同士のマッピング計算に関する研究。より効率的かつ歪みが少ないモデルの生成を実現した。関節情報など意味的な点探索やサーフェイスの対応付けでなく直接的に分散を最適化して対象のサーフェイス間の転移を行う手法(variance-minimizing trannsport plan)を提案。
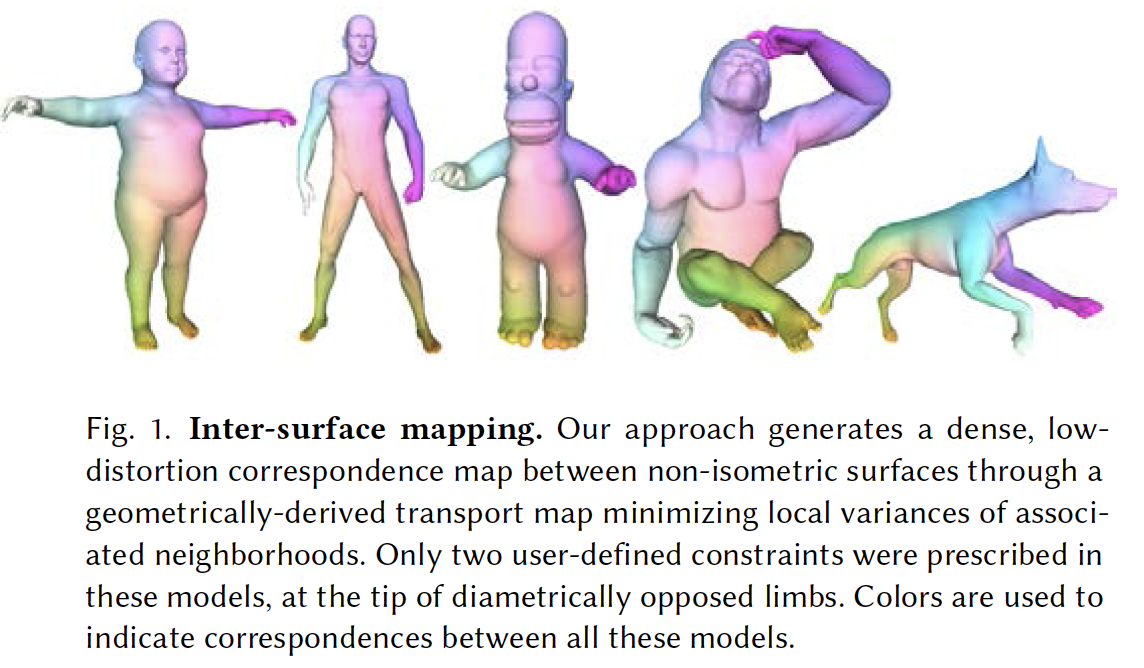
凸最適化によりこれを計算し、なおかつ疎密探索により効率的な計算ができることが判明した。モデルの例は図を参照。
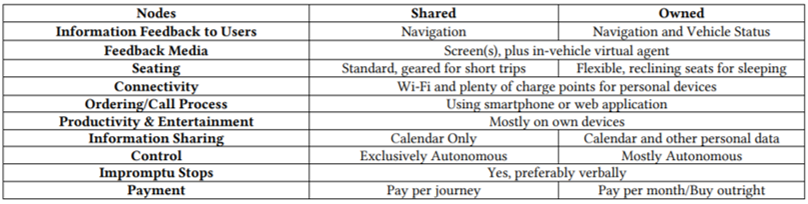
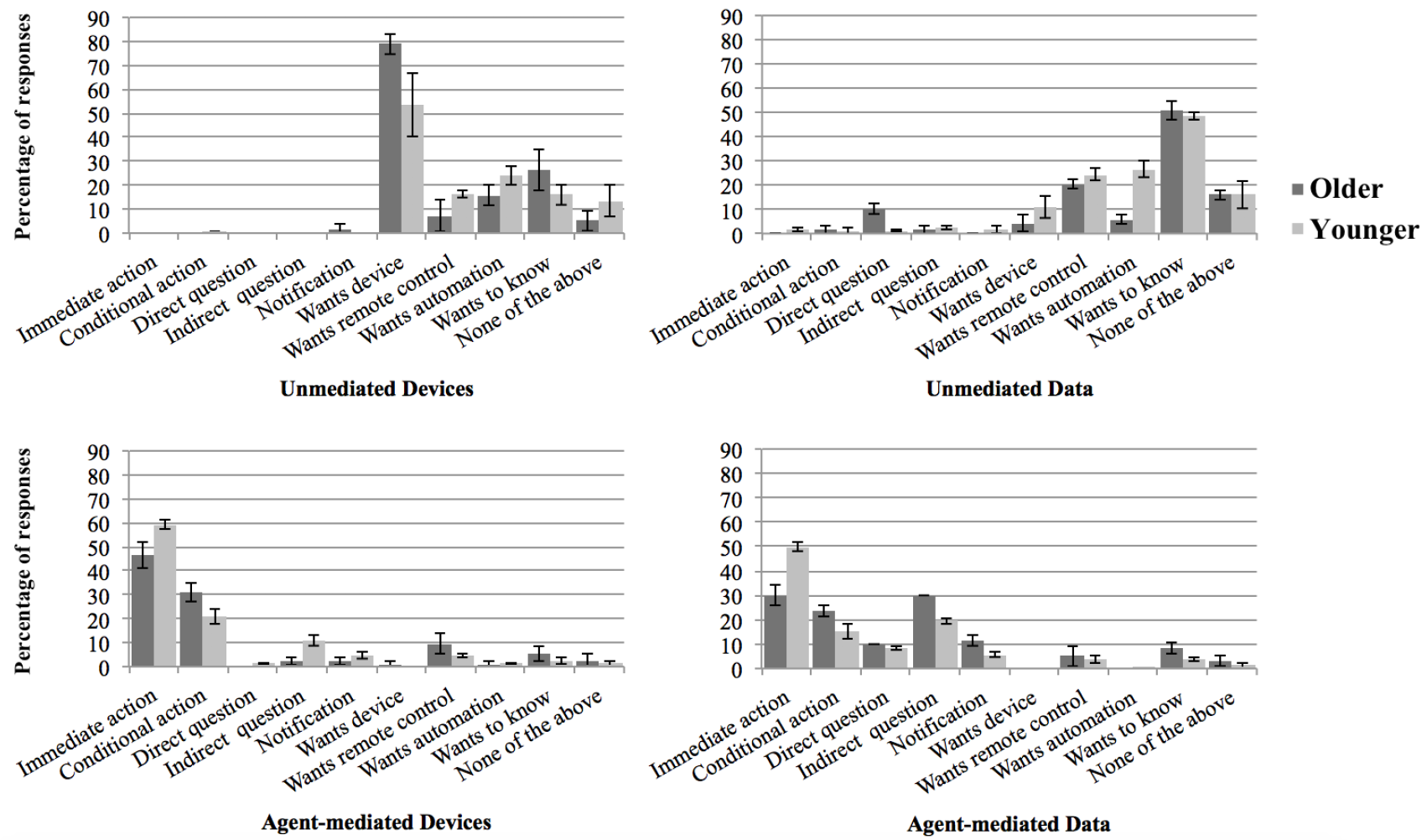
完全自動走行車両のインタフェースに対する要望・期待を調査した.運転できる人,(障害など身体的に)運転できない人に,グーグルの自動走行車両プロトタイプのビデオ映像を見せ, 聞き取り調査を行った. 身体的に運転できない人の利用について様子を見るつもりだったが, 結果,個人所有か共有かでフィードバックしてほしい情報が異なることが分かった(右表). イギリス・ケンブリッジ大学の研究.
遺伝的アルゴリズムを参考にしてニューラルネット構造のシードとその周辺探索を行うNeural Architecture Search (NASNet)を提案。自動でアーキテクチャを探索するという手法を考案し、TensorFlowやGoogleのサービスであるAutoMLに搭載した。
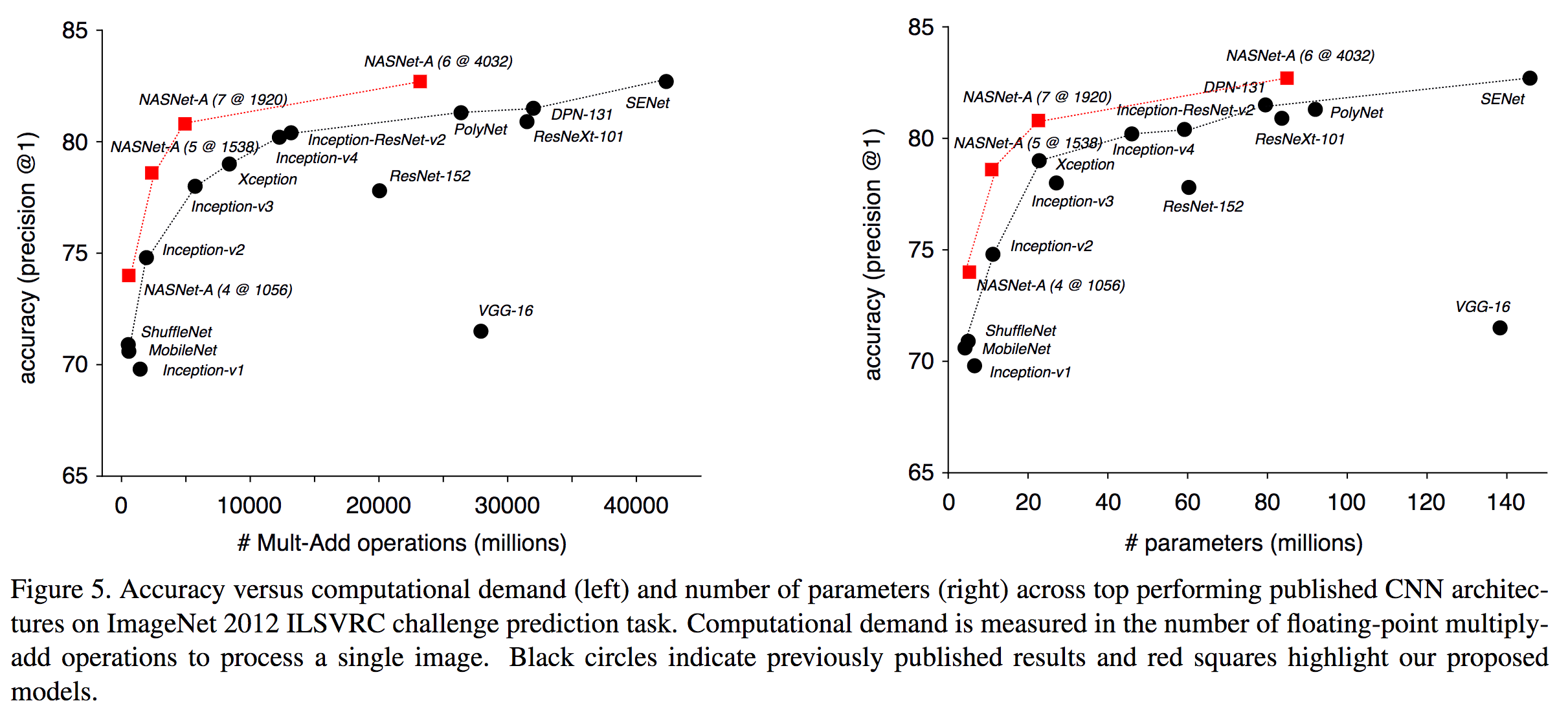
ImageNetの識別にて82.7%(top1)、96.2%(top5)を達成した。この精度は人間が探索したアルゴリズムであるSE-Net(ILSVRC2017勝者)よりも1.2%高い精度である。CIFARにおいても同様にState-of-the-art、さらにFaster R-CNNと組み合わせて物体検出を行った場合でもCOCOにて43.1%でSoTA。
強化学習・遺伝的アルゴリズムによりニューラルネット構造を探索するProgressive Neural Architecture Search (PNAS)の提案。従来法のZoch+,CVPR2018と比較すると5倍も高速な探索アルゴリズムとなった。「探索のための探索」を行うヒューリスティックな探索を実施して簡単なものから複雑な構造への拡張を実施する。Progressive (simple to complex)な探索が効率化と高精度なモデルの発見に寄与した。図はセル(畳み込みの最小ユニットでGoogLeNetのインセプションのようなもの)とセルの組み合わせによるアーキテクチャを示す。従来法であるNASNetと類似する構造になったと主張。
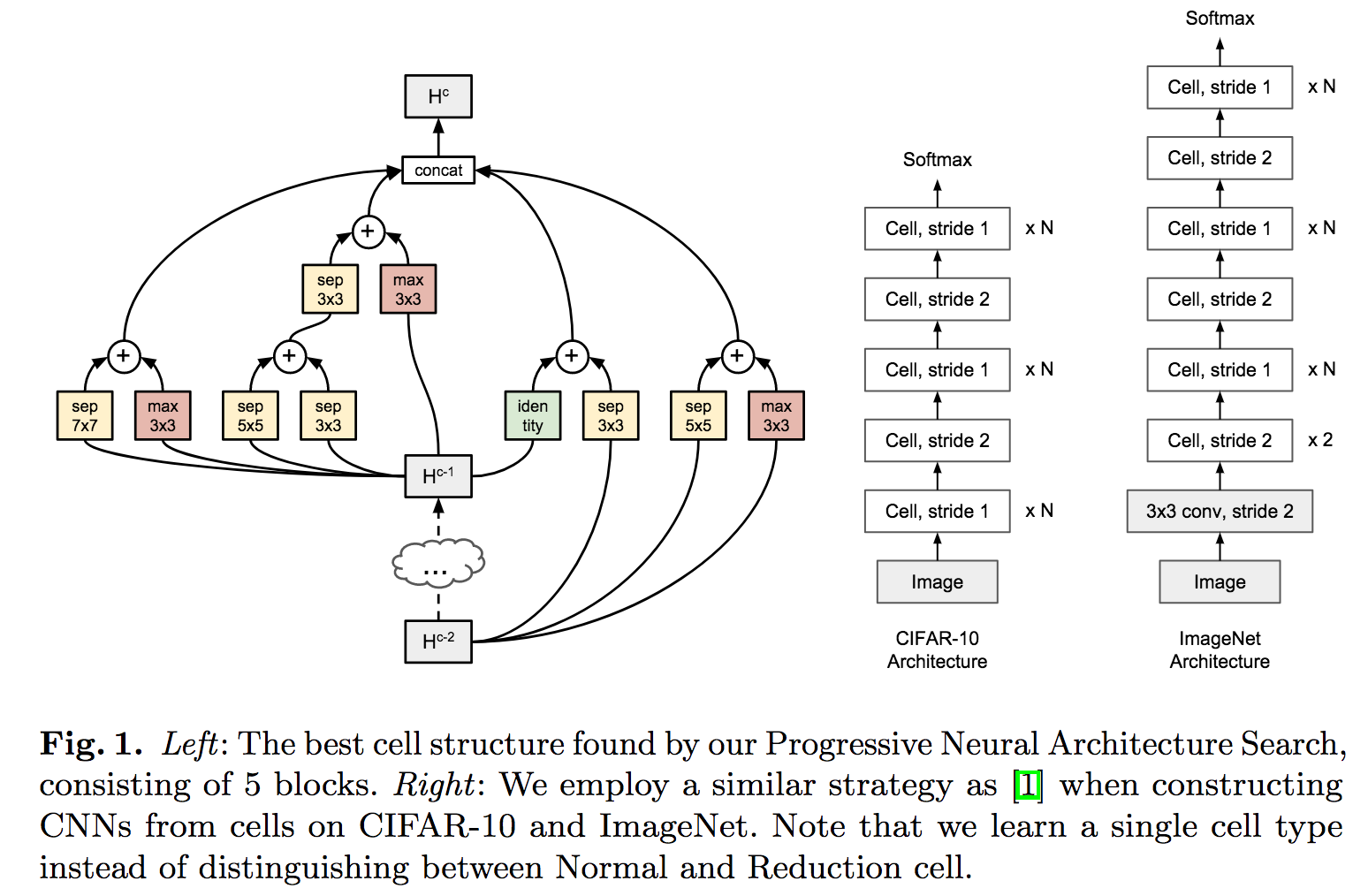
アーキテクチャ探索自体を人間ではなく強化学習に任せることでCIFAR/ImageNetにてstate-of-the-art。より効率的に従来法と類似する構造に行き着くことができた。
データ自体を正則化し重み付けを行い、各データサンプルに重要度を与えて柔軟に学習する仕組みを考案した。データの入力に対して、MentorNetはミニバッチごとにどの程度の重みをつければ良いのかを返却してDeepCNNを学習する。知識蒸留などと同様にMentorNetとStudentNetが存在してCurriculum Learningにより徐々に学習を進める。
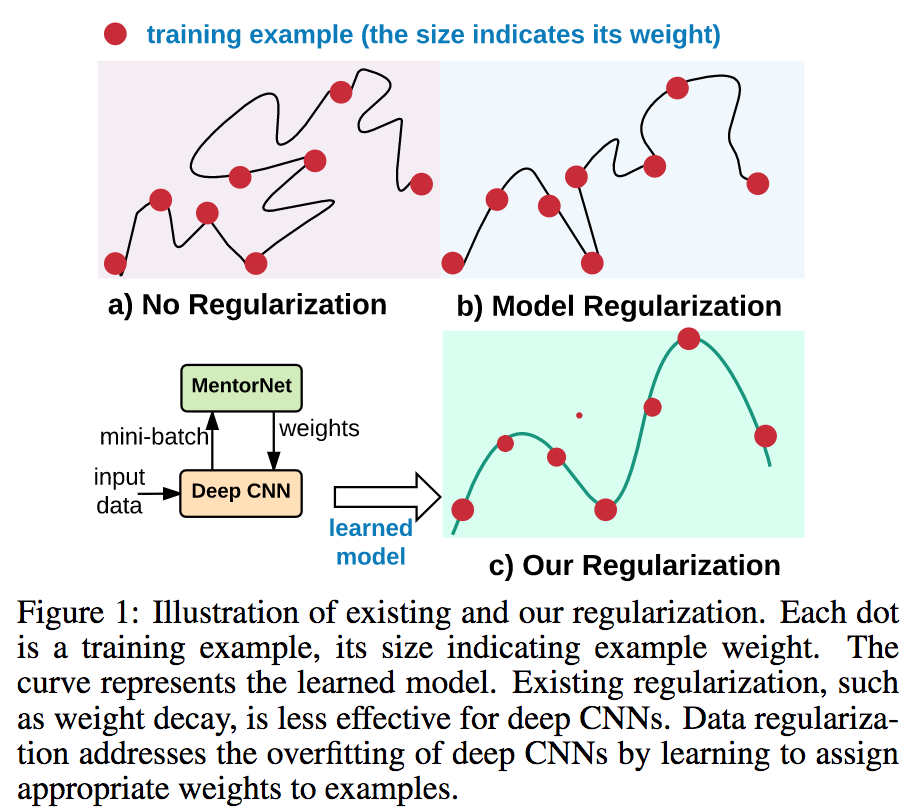
あまり整備されていないデータの場合(e.g. ウェブ画像)にはノイズが誤っていたり、なかったり、崩れていたりするが、本論文で提案のMentorNetではデータに重要度を与えて、どのデータをどの程度信頼して良いのかを与えた。Weakly Supervised学習よりも精度が高いことを示した。
従来データよりも(最低でも2分以上のビデオが含まれる)長期にわたる物体追跡のビデオデータセットを提供、さらには評価用サーバも提供して長期物体追跡の研究に貢献する。同データセットは366シーケンスを含め、14時間以上のビデオ、150万のフレームを含みこれはOTB-100の約26倍のデータサイズである。
![]()
データセットを提供すると同時に、ベンチマークとして代表的なトラッキング手法を実装して精度を算出した。手法はSiamFC、TLD、MDNet、SINT、SiamFC、ECO-HC、EBT、BACF、Staple、LCTを比較した。
人物行動の進行を予測するDNNNのネットワークであるProgressNetを提案する。ProgressNetでは動画の入力において、現在フレームからその後の行動の未来の進行状況を予測する。Faster R-CNNのフレームワークを参照して、さらにLSTMのネットワークを統合してフレームを予測する。

実験はUCF-101とJ-HMDBデータセットにて行った。Faster R-CNN + LSTMベースの手法で従来法よりもよく、行動推定とbbox検出を同時に達成した。
特定のキーワードに関連したFlickr画像を用いて、ユーザーのアノテーションに頼ることなく、自動的でセマンティックセグメンテーションの学習を行うWebSegの提案。(1)ウェブクローラによって、ユーザ定義のキーワードに関連する画像をダウンロード。(2)数種類の低レベルキュー(顕著性、エッジなど)を抽出し、それらを学習のヒューリスティクスとして結合。(3)Noise Filtering Module(NFM)を備えたセマンティックセグメンテーションネットワーク。の3部構成。ベースはDeeplab-Large-FOV。
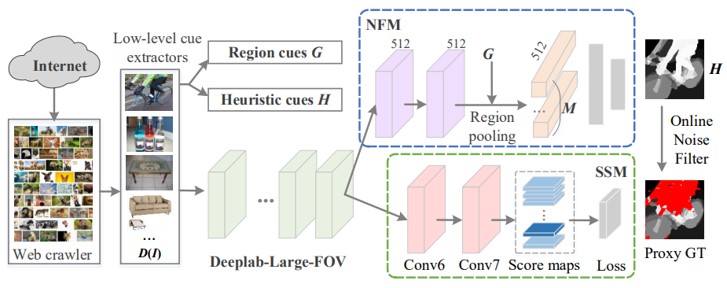
フリーのWeb画像からセマンティックセグメンテーションを学習。ノイズの多いWeb画像と不完全なproxy ground-truthに関して、学習に望ましくないノイズの多い領域を除去するオンラインノイズフィルタリングメカニズムを考案。
顕著性オブジェクトセグメンテーション、スケルトン抽出、エッジ検出など、ピクセル単位のバイナリ問題における類似点を見出し、一つのフレームワークに統一。 CNNをより有効的に活用するために、異なるレベルのフィーチャマップから信号を受け取るtransition nodeという概念を導入している。
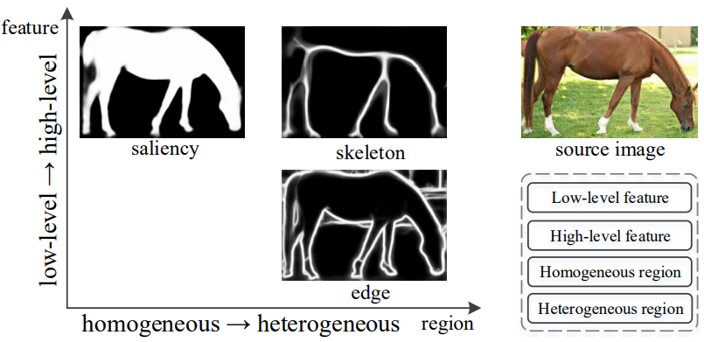
異なるタスクを一つのフレームワークに統一させることで、全てのタスクにおいて精度向上を図っている。他のバイナリピクセルラベリングタスクも統一できる可能性を示している。
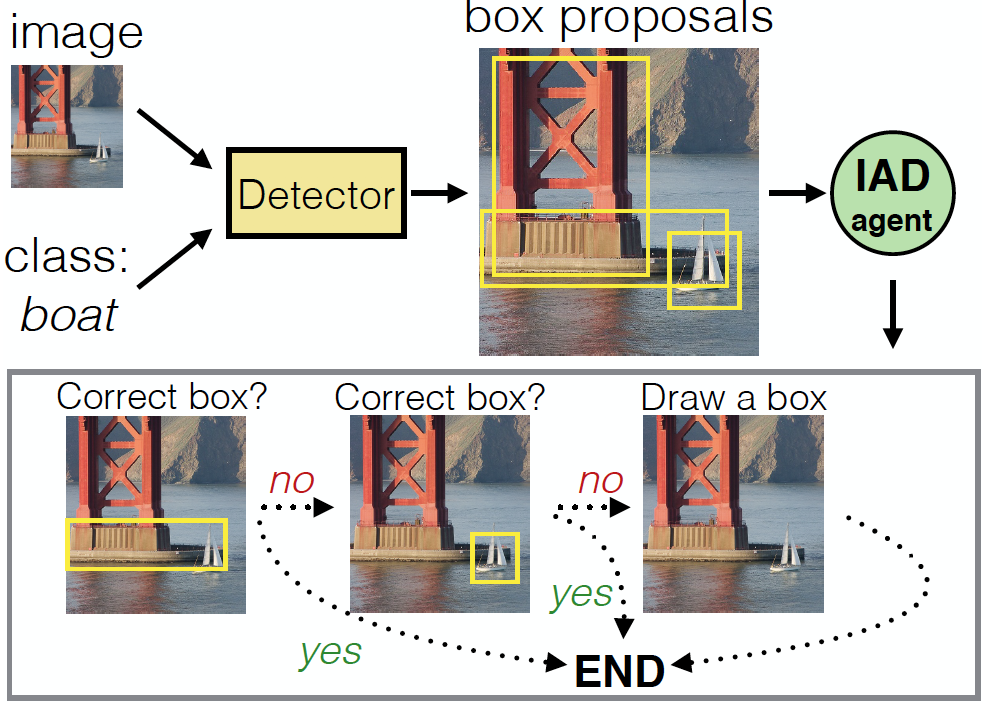
物体検出の課題を考慮し、既存のActive Learning(AL)の欠点を改善することを目的とした、Self-Supervised Sample Mining(SSM)の提案。ラベルなし、もしくは一部ラベルのないデータを使って学習することができる。交差検証後のスコアによってサンプルを選別。低い場合にはユーザによってアノテーション、高い場合にはそのままラベルとして採用。
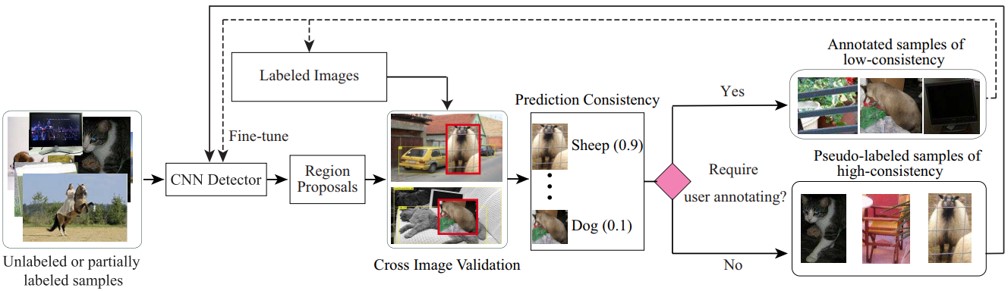
既存のAL法では主に、単一の画像コンテクスト内でサンプル選択基準を定義し、大規模な物体検出において最適ではなく、頑強性および非実用的である。SSMによって、ユーザが必要な部分にだけ介入し、アノテーションの作業を軽減。
画像の意味的変換を施し,画像を再構成する,facenet‘sのユークリッド空間を使ったモデルであるImage-Semantic-Transformation-Reconstruction-Circle(ISTRC)の提案。その名の通り、構造が円になっている。画像を識別するために、FaceNetの最後の層を用いて、画像をユークリッド空間に変換。意味理解のためにユークリッド空間ベクトルを操作し、マッピング。GANを使って、ベクトルから画像を再構成。
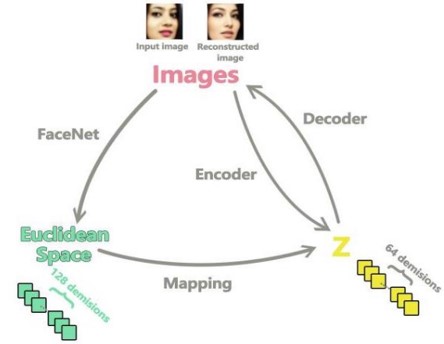
本論文では10種類の変換(「男性と女性」「笑顔を加える」「口を開ける」「大きい/小さい鼻」「年をとる」など)を実施。今後は、種類を拡張し、より高解像度の画像に適応できるように改良予定。

映像のコンテキスト情報を活用した、bject proposal手法であるTpecific Object Proposal Generation(TOPG)の提案。具体的には、対象物体のobject proposalを生成する際に、色とエッジの情報を統合する。これにより,様々な環境に適応することができ、 TOPGのリコールが大幅に増加。また、生成したobject proposalのランク精度を高めるためのランク付け手法を提案。そして、TOPGをvisual trackingに適応したTOPG-based tracker (TOPGT)を提案。

既存のobject proposal手法をビデオなどのタスクに適用したときに発生する、モーションブラー、低コントラスト、変形などの問題を解決。
HDRの画像の明るさを補正するためのブラケット撮影からの距離画像やカメラ姿勢を同時推定する手法を提案する論文。ブラケット撮影とは通常の露出撮影以外に意図的に「少し明るめの写真」と「少し暗めの写真」を同時に撮影。距離画像推定は幾何変換をResidual-flow Networkに統合したモデルにより行う。ここでは学習ベースのMulti-view stereo手法(Deep Multi-View Stereo; DMVS)を幾何推定(Structure-from-Small-Motion; SfSM)と組み合わせる。

距離画像推定において、スマートフォンやDSLRカメラなど種々のデータセットにてSoTAな精度を達成。モバイル環境でも動作するような小さなネットワークと処理速度についても同時に実現した。
CNNにおいて、入力画像に適用された2次元回転を認識するように学習する、自己管理特徴学習手法を提案。この単純なタスクによって、semantic feature learningの質の向上。
2018年現在、CNNは画像の意味的要素まで学習できるようになってきた。しかし、これには大量のデータが必要なため、教師なし学習に着目。回転を認識させる学習によって、物体認識、物体検出、セグメンテーションなどのさまざまな視覚的認識タスクに有用な意味的特徴を学習させることに成功。
自律ロボットにおける、奥行き推定能力を向上させる手法の提案。ロボットが教師あり学習(CNN)でステレオビジョン深度を学習し、静止画像からの深さを推定。このとき、ステレオ視からの深度推定結果だけでなく、単眼深度推定と静止画像をマージすることで精度向上を図る。
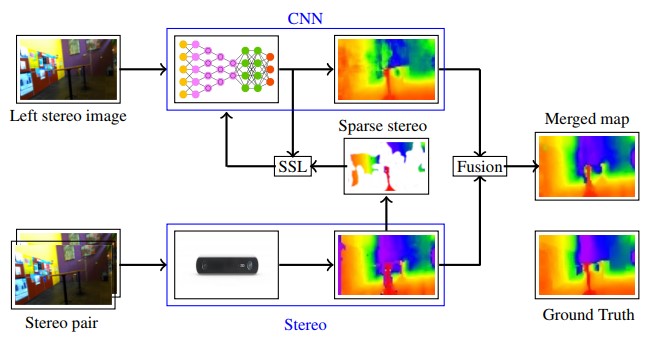
ステレオとモノラルの両方を融合された場合の推定値が、ステレオだけの場合よりも高パフォーマンス。近距離を除くほとんどの距離において、単眼視力よりも立体視がより正確に行える。
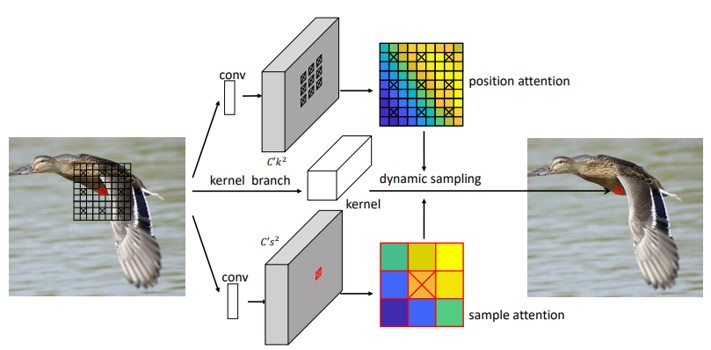
現在の位置だけでなく、動的な位置特有のカーネルを学習させることで、複数の隣接領域の特徴を融合させて学習することができるDynamic Sampling Convolutional Neural Networks (DSCNN)の提案。上図より、kernel branchで位置特有のカーネルを生成。 feature branchで、各位置ごとに畳み込んで特徴を生成。 attention branchで、各サンプルされた隣接領域からフィーチャを融合させるためのアテンション重みを生成。
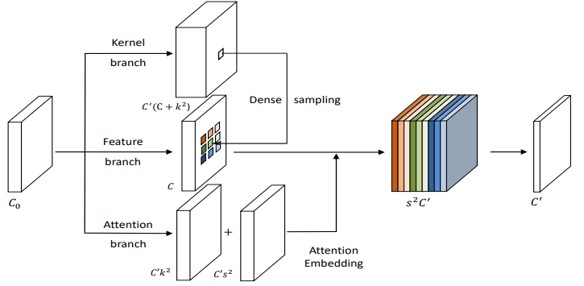
下図より、各位置で、個々のカーネルと各サンプルのアテンションの重みを別々に学習。 次に、これらの学習されたアテンションの重みを使用して、複数のサンプルの特徴を結合。十字の付いたボックスは、アテンションの重みを生成する位置を示し、赤色のものはサンプリング位置を示し、黒色のものはサンプリングされた位置を示す。
Effective Receptive Field(ERF)を拡張できることから、認識精度が向上。一般的な深層学習タスクにおいて有効性を示した。
自己検索モジュールを学習時のガイダンスとし、識別キャプションの生成を促す画像キャプションフレームワークを提案。(1)自己検索ガイダンスによって、キャプションの識別性を評価し、生成されたキャプションの品質を保つ。(2)生成されたキャプションと画像との対応は、アノテーションを伴わない生成プロセスに自然に組み込まれており、大量の未ラベル画像を使用して、面倒なアノテーションを付けを行わずにキャプションのパフォーマンスを向上。
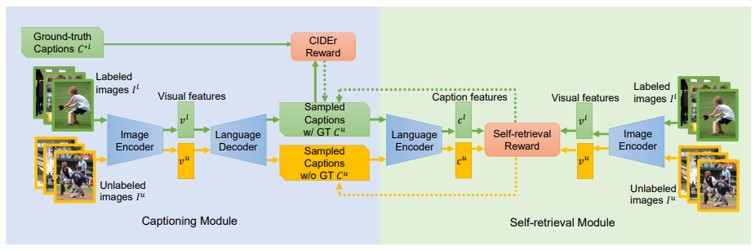
従来の主流なアプローチのほとんどは言語構造パターンを模倣しており、頻繁なフレーズや文章を複製して、各イメージのユニークな側面を無視するというステレオタイプになる傾向。本手法では、似たような画像を入力した場合でも、キャプションの弁別性を向上させることができる。
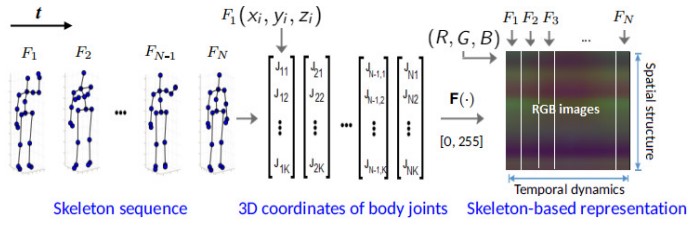
デプスセンサによって得られる骨格情報を用いて人間の行動認識に深いResNetsを適用する。スケルトンシーケンスで、人体関節の3D座標を画像ベースの表現に変換し、RGB画像として格納。これらの画像は、3D運動の空間 - 時間的進化をとらえることができ、D-CNNによって効率的に学習可能。次に、得られた画像ベースの表現から特徴量を学習し、行動クラスに分類するためにResNetsにて学習。
オクルージョンが発生している場合/複雑な環境下でも簡単な形状がポイントクラウドから検出できる枠組みを提案する。手法は3D楕円形状のフィッティング、3次元空間操作、4点取得により構成。
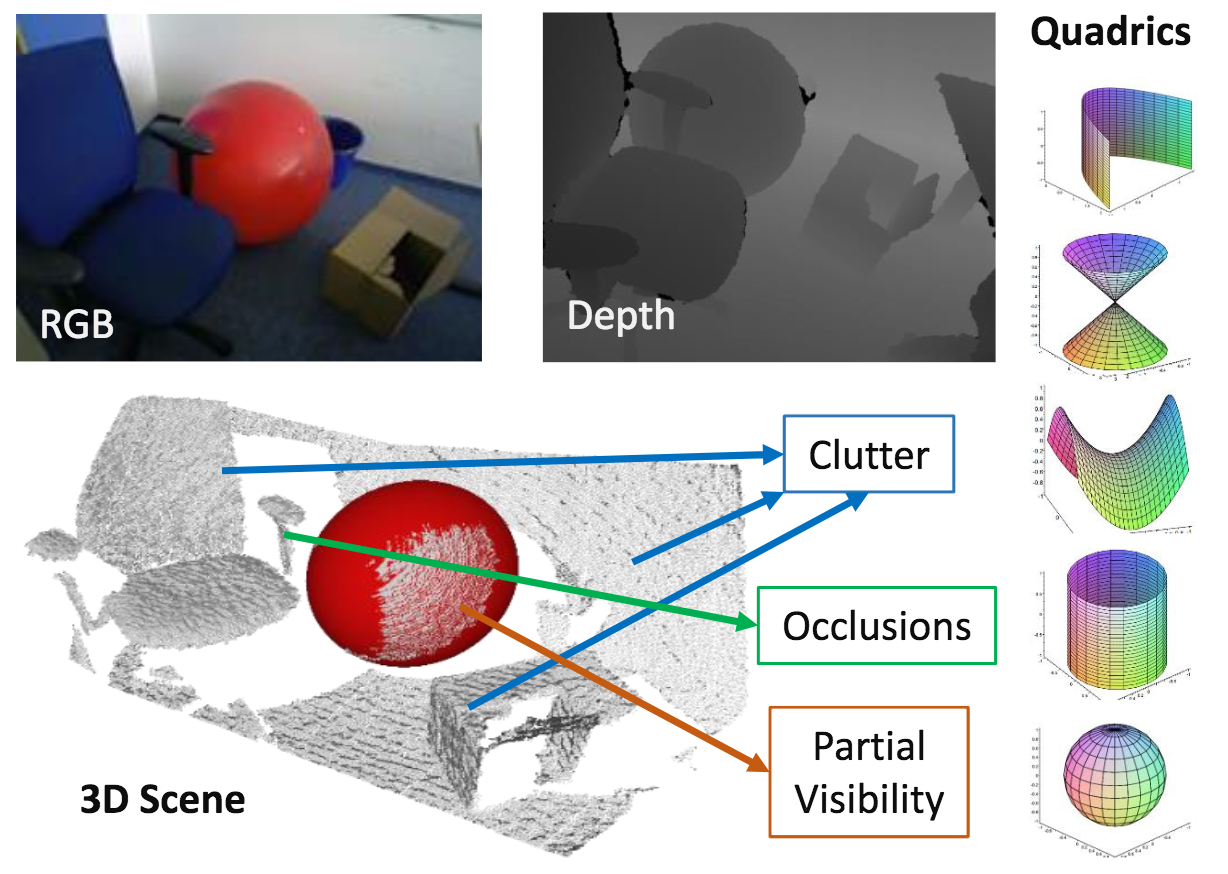
タイプに依存しない3次元の二次曲面(楕円球形状)検出を点群の入力から行う手法を考案した。さらに、4点探索問題を3点探索にしてRANSACベースの手法で解を求めた。モデルベースのアプローチよりはフィッティングの性能がよいが、キーポイントベースの手法よりは劣る。
カテゴリの単語の埋め込みと他のカテゴリとの関係(視覚データが提供される)を使用するだけで、学習例がないカテゴリの分類器を学習するゼロショット認識モデルを提案。 knowledge graph (KG) を入力とし、Graph Convolutional Network(GCN)を基に、セマンティック埋め込みとカテゴリの関係の両方を使用して分類器を予測する。

学習済のKGが与えられると、各ノードに対する意味的埋め込みとして入力を得る。一連のグラフ畳み込みの後、各カテゴリの視覚的分類器を予測する。トレーニング中に、カテゴリの視覚的分類器が与えられ、GCNパラメータを学習。テスト時に、これらのフィルタを使用して、見えないカテゴリの視覚的分類器を予測する。
センテンスの入力から、行動者と行動(Actor and Action)を同時に特定する研究である。複数の同様の物体から特定の人物など、詳細な分類が必要になる。ここではFully-Convolutional(構造の全てが畳み込みで構成される)モデルを適用してセグメンテーションベースで出力を行うモデルを提案。図は提案モデルを示す。I3Dにより動画像のエンコーディング、自然言語側はWord2Vecの特徴をさらにCNNによりエンコーディング。その後、動画像・言語特徴を統合してDeconvを繰り返しセグメントを獲得していく。
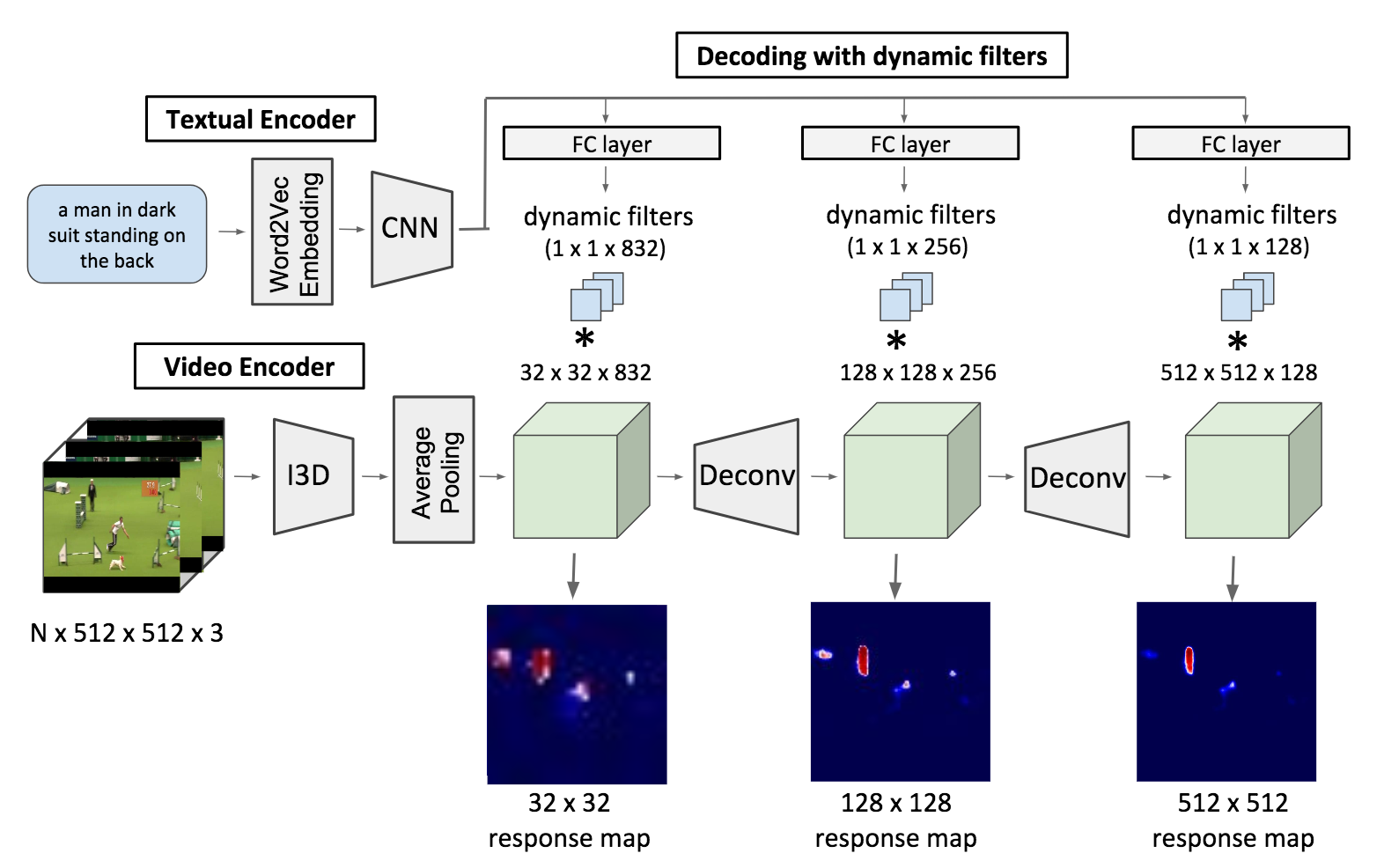
文章(と動画像)の入力から行動者と行動の位置を特定すべくセグメンテーションを実行するという問題を提起した。また、二つの有名なデータセット(A2D/J-HMDB)を拡張して7,500を超える自然言語表現を含むデータとした。同問題に対してはSoTA。
歩行者の時空間パターンを用いた、教師なし学習の人物再同定アルゴリズムであるTFusionを提案。既存の人物再同定アルゴリズムのほとんどは、小サイズのラベル付きデータセットを用いた教師付き学習手法である。そのため、大規模な実世界のカメラネットワークに適応することは困難である。また、そこで、ラベルなしデータセットも用いたクロスデータセット手法によって精度向上を図る。
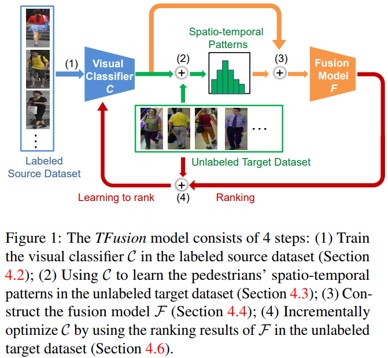
まず、歩行者の空間的-時間的パターンを学習するために、ラベル付きデータセットを用いて学習した視覚的分類器を、ラベルなしデータセットに転送。次に、Bayesian fusion modelによって、学習された時空間パターンを視覚的特徴と組み合わせて、分類器を改善。最後に、ラベルのないデータを用いて分類器を段階的に最適化。
イベントベースカメラにおける、識別アルゴリズムの提案。本研究では、(1)イベントベースのオブジェクト分類のための低レベル表現とアーキテクチャの欠如、(2)実世界における大きなイベントベースのデータセットの欠如、の2つの問題に取り組む。新しい機械学習アーキテクチャ、イベントベースの特徴表現(Histograms of Averaged Time Surfaces)、データセット(N-CARS)を提案。
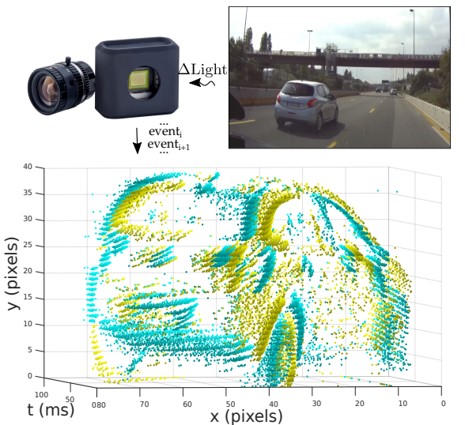
イベントベースのカメラは、従来のフレームベースのカメラと比較して、高時間分解能、低消費電力、高ダイナミックレンジという点で優れており、様々なシーンで応用が利く。しかし、イベントベースのオブジェクト分類アルゴリズムの精度は未だ低い。特徴表現には過去時間の情報を使用。
音声入力から、正確な口パク画像(実写の顔)を生成するための新規アプローチの提案。まず、RNN(LSTM)を用いて、音声特徴から口のランドマーク位置をラベルとして生成。次に、ランドマークからC-GANを用いて顔を生成。これらの2つのネットワークによって、入力オーディオトラックと同期し、自然な顔を生成することが可能。
音声入力から、正確な口パク画像(実写の顔)を生成するための新規アプローチの提案。まず、RNN(LSTM)を用いて、音声特徴から口のランドマーク位置をラベルとして生成。次に、ランドマークからC-GANを用いて顔を生成。これらの2つのネットワークによって、入力オーディオトラックと同期し、自然な顔を生成することが可能。
LSTMとC-GANのネットワークは、独立しているので、ターゲットの人物ではなく、他ソースからのオーディオでターゲットの顔を口パクさせることが可能。 顔の変換、アプリなど、多くの新しいアプリケーションに応用可能。
Cascaded Regression(CR)ベースの顔ランドマーク検出モデルの効率を改善するSelf-Iterative Regression(SIR)の提案。また、各ランドマーク周辺のフィーチャを同時に学習し、全体的な位置増分を取得するLandmarks-Attention Network(LAN)を提案。これにより、一回の回帰分析で反復的にパラメータを更新することができる。
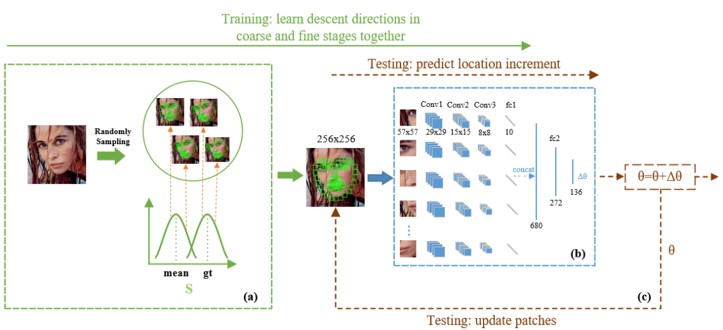
CRは、細かい段階と荒い段階で別々に学習することができるが、以前の回帰の出力が次の回帰時のデータとなるので十分に頑強とは言えない。さらに、複数の回帰を学習するにはかなりのリソースが必要。SIRはこれらの問題を解決できる。
学習済みデータと新しいドメイン(ground-truthなし)の両方を用いて、ディープステレオマッチングを行うZoom and Lean(ZOLE)の提案。これにより,他のドメインに一般化できるプレトレインモデルを作成することができる。一般化に際する不具合を抑制しながらアップサンプリングを行う、反復最適化問題を定式化する。

ground-truthデータが不足しているため、CNNを用いたステレオマッチングでは学習済みステレオモデルを新規ドメインに一般化することが困難とされていた。CNN学習時のイテレーションごとに最適化していくイメージ。
2Dの似顔絵画像から3Dの似顔絵を作成するためのアルゴリズムの提案。似顔絵画像のテストデータとしてはカリカチュアを使用し、カリカチュア画像の3Dモデルとテクスチャ化された画像を生成する。データは、標準の3D顔の変形を座標系に配置(下図、 xは口の開き具合)し、金のオリジナルデータから線形結合によって白い顔を生成する。

カリカチュアを集めたデータセットを作って学習するのではなく、標準の3D顔のデータセットから実装でき、アプリケーションの柔軟さを推している。
3DMMやFaceWareHouseなどの従来手法と比較して、形の歪みが少なく、従来のものよりも綺麗な3D顔の出力が可能。顔以外にも、概形の予測が可能なオブジェクトなら応用できる?

顔の記述に特化し、より具体的に記載できるイメージキャプショニングの提案。シーン記述のようなオブジェクトやその関係性などではなく、画像から得られた属性に依存した記述となる。データはクラウドソーシングを使ってアノテーションを収集し(The Face2Text dataset)、アノテーションの解析まで行う。

“顔についてのキャプション”という新しいテーマのデータセットを提案、およびその解析。
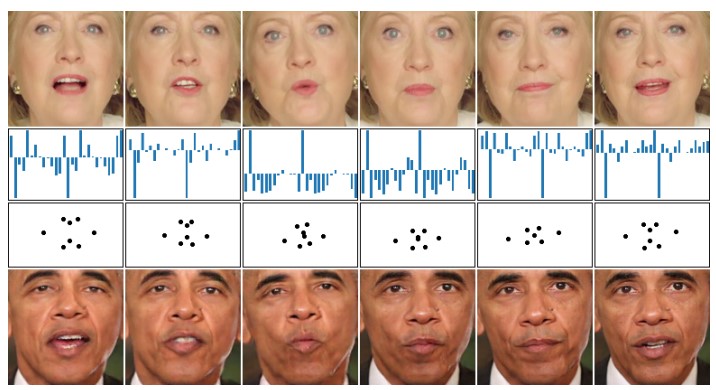
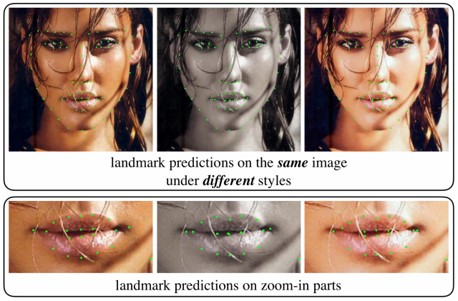
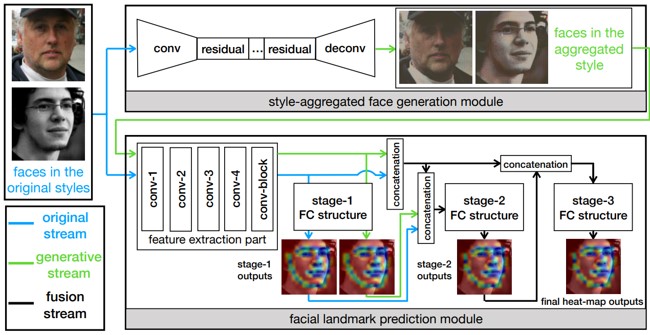
顔のランドマーク検出。顔そのもののばらつきの他に、グレースケールやカラー画像、明暗などの画像スタイルが変わっても同様に検出できるStyle Aggregated Network(SAN)の提案。まず、(1)入力画像をさまざまなスタイルに変換し、スタイルを集約し、(2)顔のランドマーク予測する。(2)は、元画像とスタイルを集約した特徴の両方を入力し、融合してカスケード式のヒートマップ予測を生成する。
フレーズベースでの画像キャプショニングを行うphrase-based hierarchical Long Short-Term Memory (phi-LSTM)の提案。(1)画像に関連した名詞句を生成(低レベル)、(2)コーパス内のフレーズと他の単語から適切なキャプションを生成(高レベル)、それぞれの処理に専念するRNNモデルを実装することでフレーズベースを実現している。
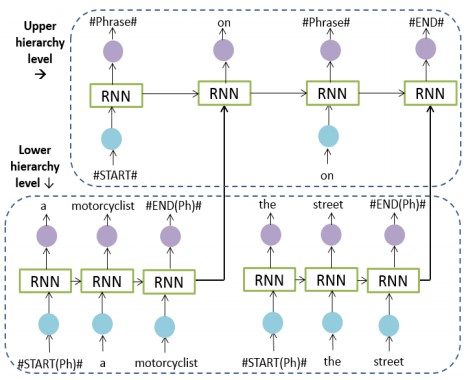
従来までは、オブジェクトを検出/名前付けし、その属性を記述して、その関係/相互作用を認識するモデルが提案されている。従来研究では単語のシーケンスだけでキャプションを生成していたが、本研究ではフレーズと単語の組み合わせのシーケンスとして文章をエンコードする。
Zero-shot learning(ZSL)における、視覚的および意味的インスタンスを別々に表現し学習するLatent Discriminative Features Learning(LDF)の提案。 (1)ズームネットワークにより差別的な領域を自動的に発見することができるネットワークの提案。(2)ユーザによって定義された属性と潜在属性の両方について、拡張空間における弁別的意味表現の学習。
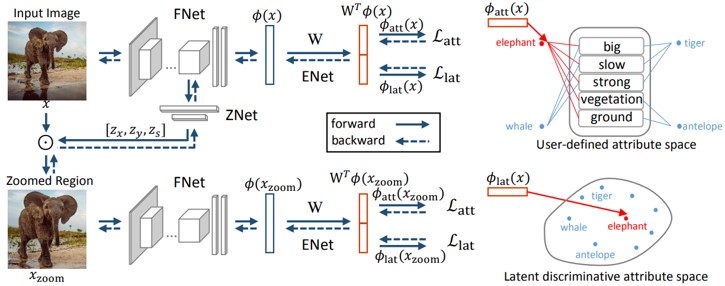
ZSLは、画像表現と意味表現の間の空間を学習することによって、見えない画像カテゴリを認識する。 既存の手法では、視覚と意味空間を合わせたマッピングマトリックスを学習することが中心的課題。提案手法では、差別的に学習するとうアプローチで識別精度向上を図る。
自然画像から文字を検出する。単なる検出ではなく、文字の方向を考慮したバウンディングボックスによる検出手法であるRotation-sensitive Regression Detector (RRD)の提案。回帰ブランチによって、畳み込みフィルタを回転させて回転感知特徴を抽出。分類ブランチによって、回転感性特徴をプーリングすることによって回転不変特徴を抽出。

文字をテーマにした研究では(1)テキストの向きを無視した分類方法と,(2)向きを考慮したバウンディングボックスによる回帰がある。従来研究では、両方のタスクの共有の特徴を使用していたが、互換性がなかったためにパフォーマンスが低下(図b)。そこで、異なる2つのネットワークから抽出した、異なる特性の特徴を分類および回帰することを提案(図d,e)。
ICDAR 2015、MSRA-TD500、RCTW-17およびCOCO-Textを含む3つのシーンテキストのデータセットで最先端のパフォーマンスを達成。向きがある一般物体検出にも応用可能?
時系列の行動検出/セグメンテーション(Action Segmentation)に関する問題をWeakly-Supervised(WS学習)に解いた。ここではTemporal Convolutional Feature Pyramid Network (TCFPN)とIterative Soft Boundary Assignment (ISBA)を繰り返すことで行動に関する条件学習ができてくるという仕組み。TCFPNではフレームの行動を予測し、ISBAではそれを検証、それらを繰り返して行動間の境界線を定めながらWS学習の教師としていく。さらに、WS学習を促進するためにより弱い境界として行動間の繋がりを定義することでWS学習の精度を向上させる。学習はビデオ単位の誤差を最適化することで境界についても徐々に定まる(ここがWS学習の所以)ように学習する。
Breakfast dataset, Hollywood extended datasetにて弱教師付き学習とテストを行いState-of-the-artな精度を達成した。
MSCOCOデータセットに対してThing(もの)やStuff(材質)に関する追加アノテーションを行い、さらにコンテキスト情報も追加したCOCO-Stuffを提案した。このデータセットには主にシーンタイプ、そのものがどこに現れそうかという場所、物理的/材質的な属性などをアノテーションとして付与する。COCO2017をベースにして164Kに対して91カテゴリを付与し、スーパーピクセルを用いた効率的なアノテーションについてもトライした。

材質的なアノテーションは画像キャプションに対して重要であることを確認、相対的な位置関係などデータセットのリッチなアノテーションが重要であること、セマンティックセグメンテーションベースの方法により今回のアノテーションを簡易的に行えたこと、などを示した。
画像キャプションの研究においてSelf-Retrieval(自己検索?)の機能を追加して学習時の教示することで識別性に優れたキャプションの生成に成功した。Self-Retrievalの効果により、欠損のある画像ーキャプションの対応関係ラベルデータにおいても効率的に学習ができることを示した。識別性に優れたキャプションの生成により、画像中の物体を発見する能力が向上し、より表現力のあるキャプション生成となった。

図を参照。強化学習の枠組みによりSelf-Retrievalの報酬を定義してラベルに欠損を含む状態でもキャプショニングの精度を向上させた。
物体検出手法であるYOLO(You Only Look Once)に関する続報であり早くもv3となった。OpenImagesの使用、bboxのスケール間での推定結果統合、スキップコネクション適用や畳み込み層の増加(Darknet-53)など軽微な改良を行ってYOLO自体の精度を向上させ速度を維持した。また、TechReport中にはやってもうまくいかなったこと(Anchor box x, y offset predictions, Linear x,y predictions instead of logistic, Focal loss, Dual IOU threshold and truth assignment)が書かれている。
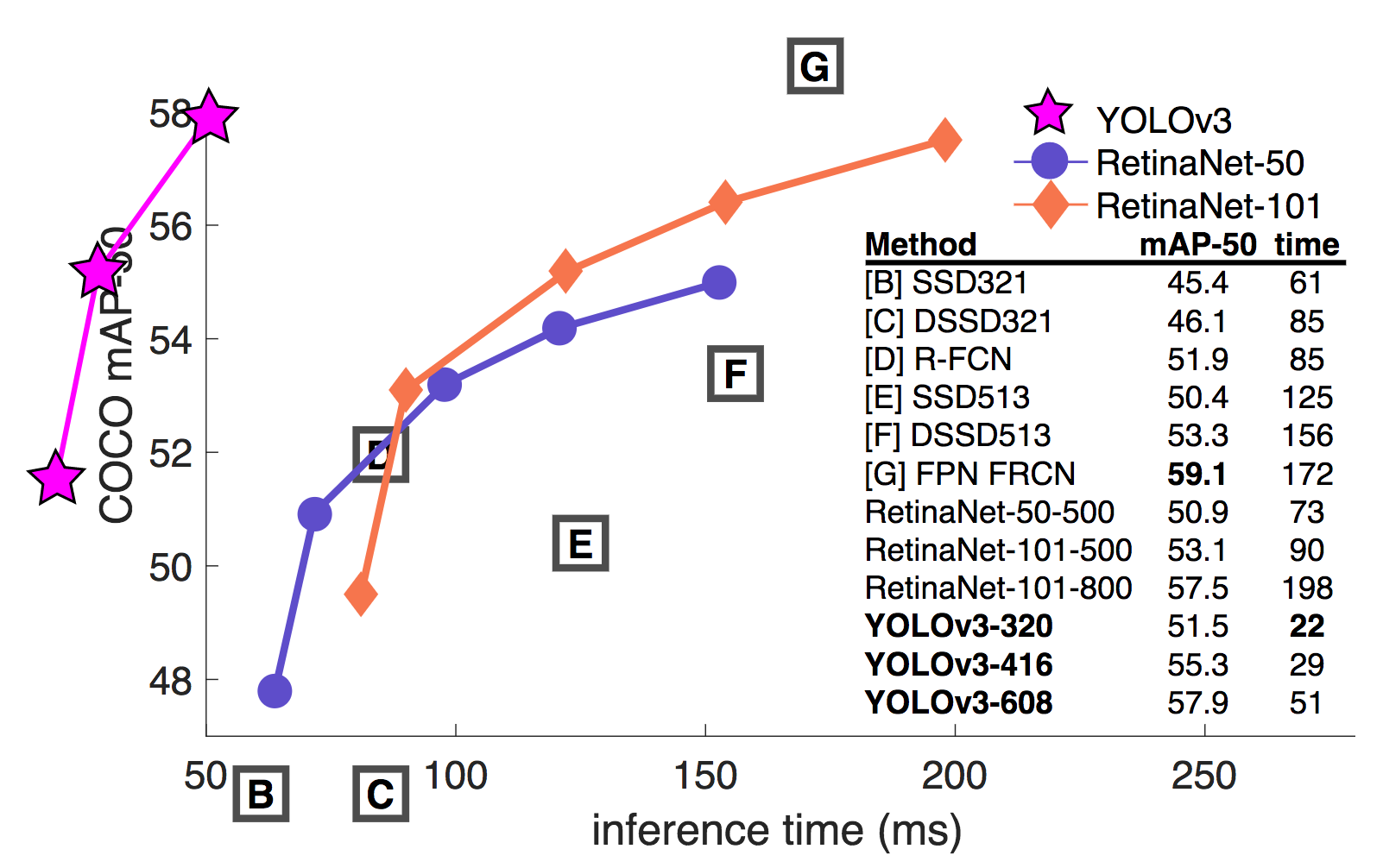
精度はSSDとほぼ同等でかつ3倍の速さを実現した。また、Focal Lossを用いて学習したRetina Netとも同等で3倍以上の速さを実現した(YOLOv3-608 57.9 mAP, 51 ms/img vs. RetinaNet-101 57.5, 198 ms/img)。
ロボット操作者と対話相手のモデレーションをする遠隔コミュニケーション支援ロボットにおいて,ビデオチャット通信とロボット操作通信の両方を用意するのは, 通信品質を保ちにくく,規模も大きくなり,扱いが難しい. そこで,ビデオチャットの映像に,人間にも直観的に解釈可能なアイコン画像として 遠隔ロボットへのコマンドを埋め込んでしまおうという新たな視点を提案.

ロボットがハートの動きをしている,と人間が知覚しやすくなる.人間とロボットがモーダル・認知を共有しつつ,通信の規模も抑えて実装しやすくする (信頼度の高い既に用意されているビデオチャット通信回線1本あればいい)という一石二鳥の視点が面白い.
深層強化学習により,人対人インタラクションの高度なダイナミクスにおける一般化ルールの抽出を行う枠組みを提案.音声およびカメラ画像の疎な時系列を入力とし,2エージェント間の動きの介入セッションを規定する規則のセットの学習を行う.
インタラクションのルール付けが深層学習でできるというのが感慨深い.
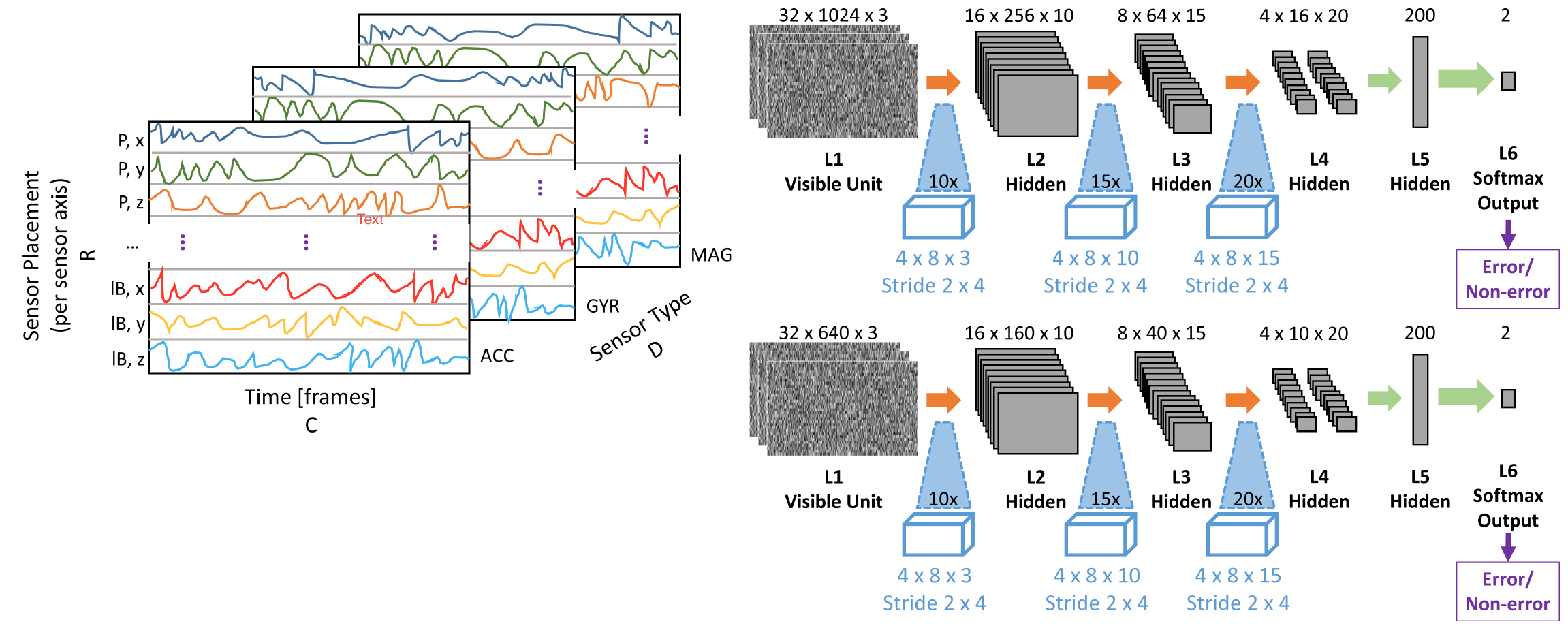
動くロボットの頭部に載せたマイクで音声認識する場合,ロボットのノイズや環境によるエコーの影響などの認識率低下の要素が多い. そこで,自動音声認識に,音声入力だけでなく,ユーザの音響情報,ロボットの情報,環境情報も与えると, DNN-HMM,少ない学習データでも精度が良くなる.
DNN-HMM+ロボット+音響考慮
(なんか読みづらい)
透明物体の切り抜き(Transparent Object Matting; TOM)と反射特性を推定することが可能なネットワークTOM-Netを提案する。TOM-Netにより、物体の反射特性を保存しながら他の画像にレンダリングして、同画像のテクスチャを反映させることができる。同問題を反射フローの推定問題と捉えてDNNのモデルを構築することで解決した。荒い部分は多階層のEncoder-Decorderで推定し、詳細な部分はResidualNetで調整する。この問題を解決するために、データセットを構築した。
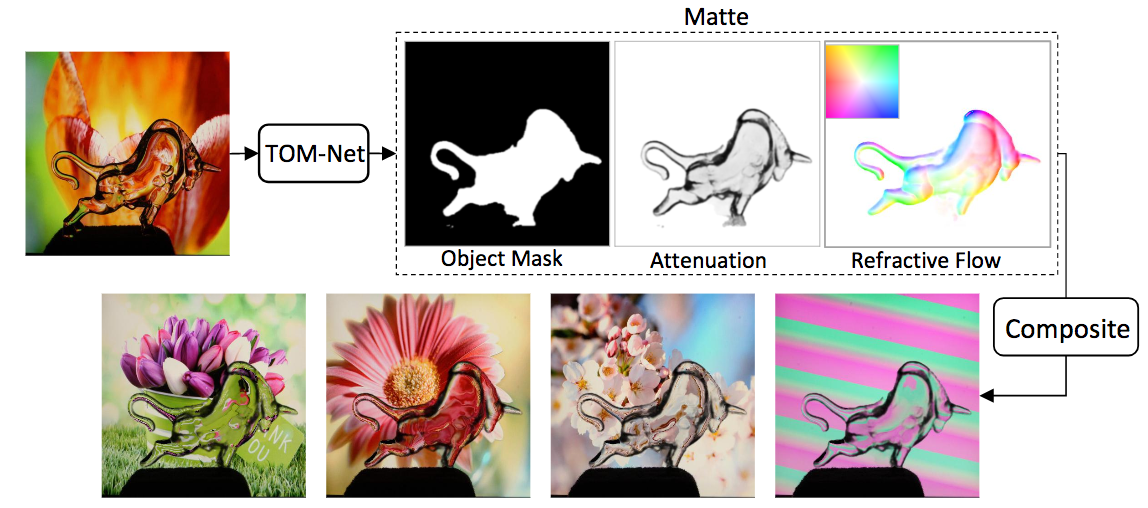
178Kの画像を含むデータセットを構築した。同DBには876サンプル、14の透明物体、60種の背景を含む。透明物体の推定と反射特性のレンダリングはGitHubページを参照。
単語の特徴表現(Word Embedding)を獲得するための手法としてCount-based(カウント手法)とPredict-based(推定手法)があるが両者を比較して各タスクにて比較を行った。結果は推定手法が総合的に高い精度を記録することが明らかとなった。
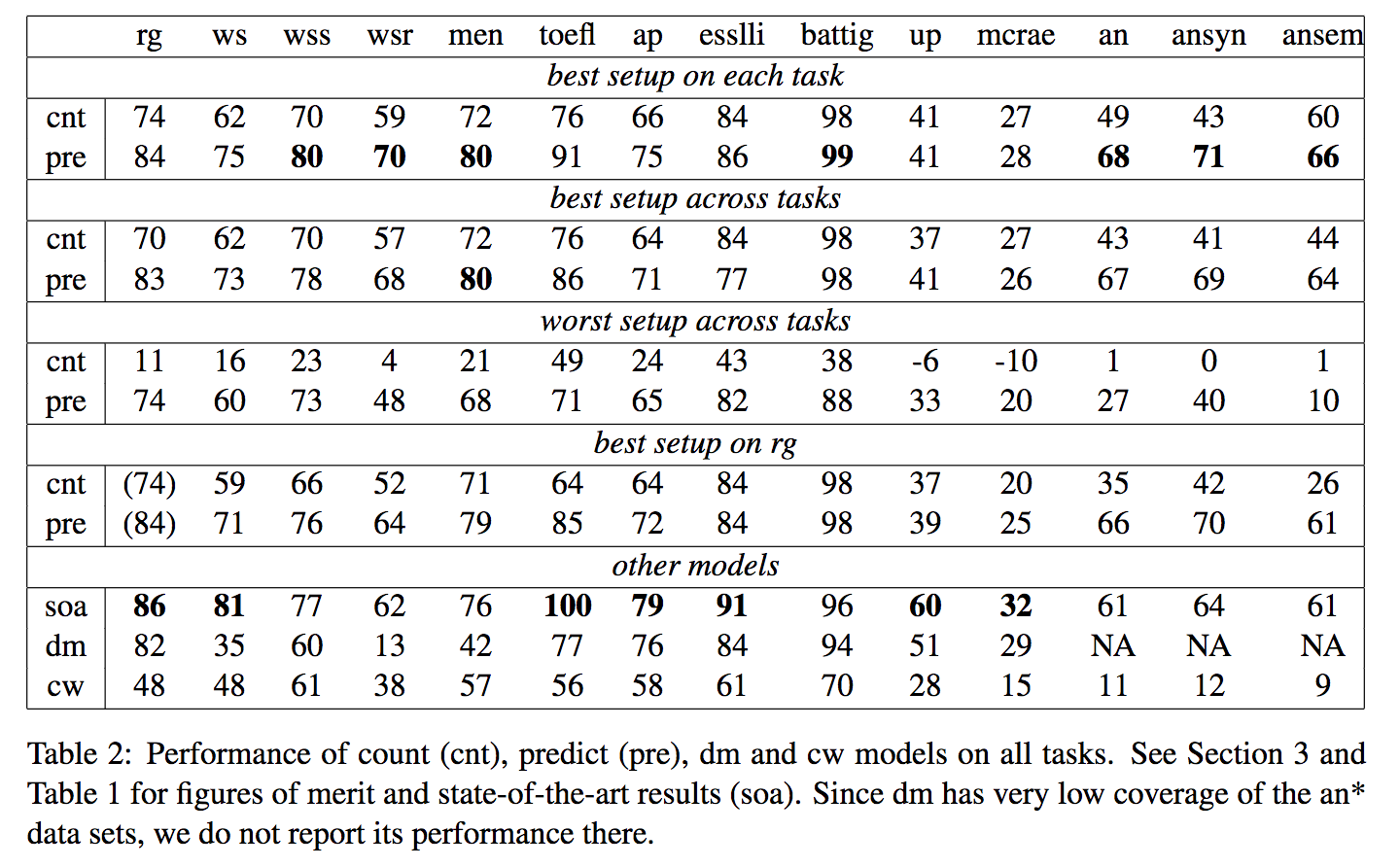
結果は右に示すとおりである。count(cnt)とpredict(pre)において、大体においてpreの方が高い精度である。
自然言語処理におけるコンテキスト学習に関する論文。局所的かつ大域的に文章のコンテキストを捉え、ワードに関する特徴表現(Word Embeddings)をニューラルネットで学習する。ワードに着目した際には複数の表現方法を獲得できるようにも改良。目的関数にはあるワードとその前後の単語の文脈から誤算関数を定義して、着目した単語が有効に学習できるように設定。この問題を解決するため、データセットも新規に提案した。
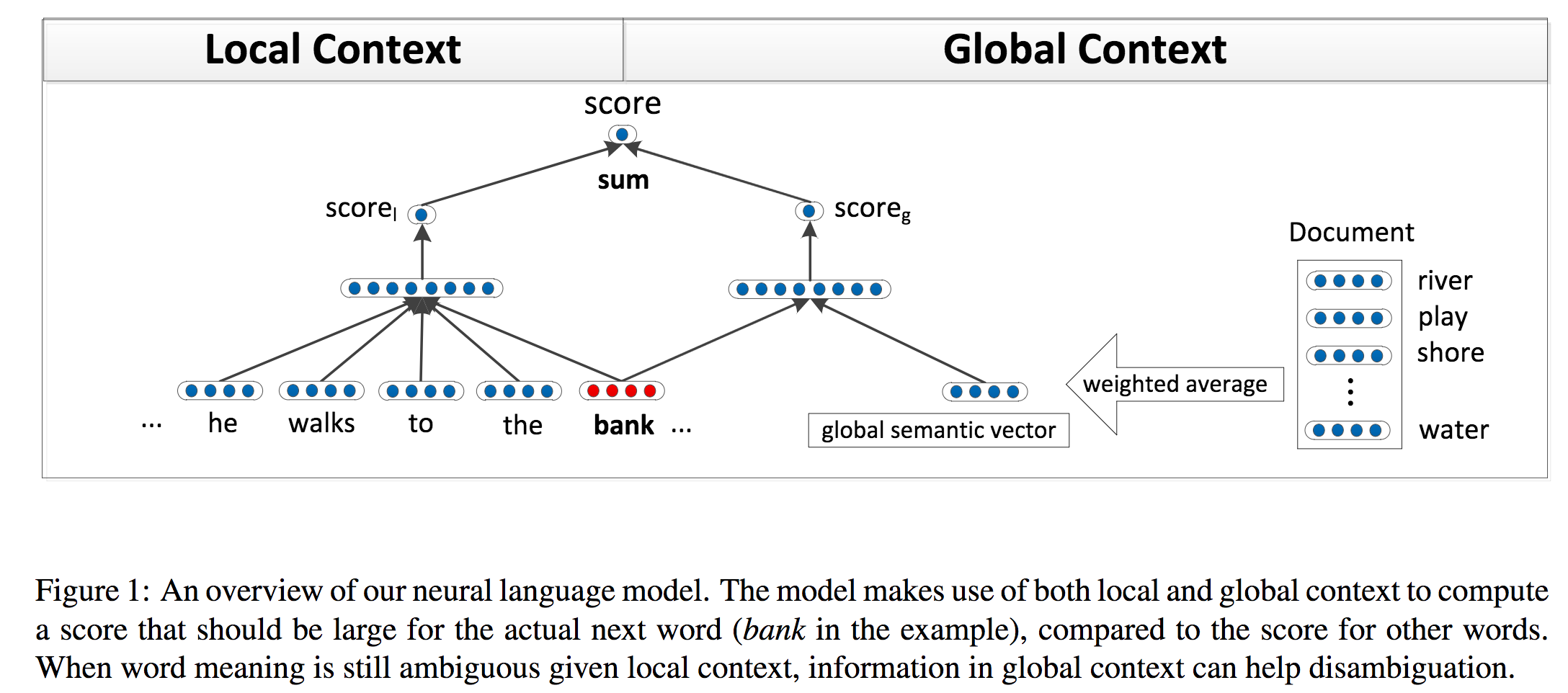
従来のコンテキスト学習はある単語とその周辺単語のコンテキストのみしか学習していなかったが、本論文ではよりグローバルなコンテキストを学習できるようにニューラルネットの表現方法を考案。
OMICSコーパスに書いてあるシンプルなストーリー展開から常識を教師なしで学習。コーパスには「手紙を受け取る」「ベッドメイクする」などの日常生活における手続きを英語のナレーションで記述している。異なる文脈で同じイベントが発生した場合にも時系列的な階層構造を構築してイベント/サブイベント間の関係性を把握。
論文にはコンピュータが「常識」のような知識をいかに自然言語から獲得するかが記述されている。
オクルージョンが発生している場合/複雑な環境下でも簡単な形状がポイントクラウドから検出できる枠組みを提案する。手法は3D楕円形状のフィッティング、3次元空間操作、4点取得により構成。
タイプに依存しない3次元の二次曲面(楕円球形状)検出を点群の入力から行う手法を考案した。さらに、4点探索問題を3点探索にしてRANSACベースの手法で解を求めた。モデルベースのアプローチよりはフィッティングの性能がよいが、キーポイントベースの手法よりは劣る。
センテンスの入力から、行動者と行動(Actor and Action)を同時に特定する研究である。複数の同様の物体から特定の人物など、詳細な分類が必要になる。ここではFully-Convolutional(構造の全てが畳み込みで構成される)モデルを適用してセグメンテーションベースで出力を行うモデルを提案。図は提案モデルを示す。I3Dにより動画像のエンコーディング、自然言語側はWord2Vecの特徴をさらにCNNによりエンコーディング。その後、動画像・言語特徴を統合してDeconvを繰り返しセグメントを獲得していく。
文章(と動画像)の入力から行動者と行動の位置を特定すべくセグメンテーションを実行するという問題を提起した。また、二つの有名なデータセット(A2D/J-HMDB)を拡張して7,500を超える自然言語表現を含むデータとした。同問題に対してはSoTA。
ラベルなし、ドメインが異なる環境に対して人物再同定を行う手法を提案する。モデルであるTFusionは4ステップにより構築(1)教師あり学習により識別器を構築(2)ターゲットであるラベルなしデータにより時空間特徴パターン(Spatio-temporal Pattern)を学習(3)統合モデルFを学習(4)ラベルなしのターゲットデータにて徐々に識別器を学習する(1〜4は図に示されている)。Bayesian Fusionを提案して、時空間特徴パターンと人物のアピアランス特徴を統合してドメイン変換を行う。
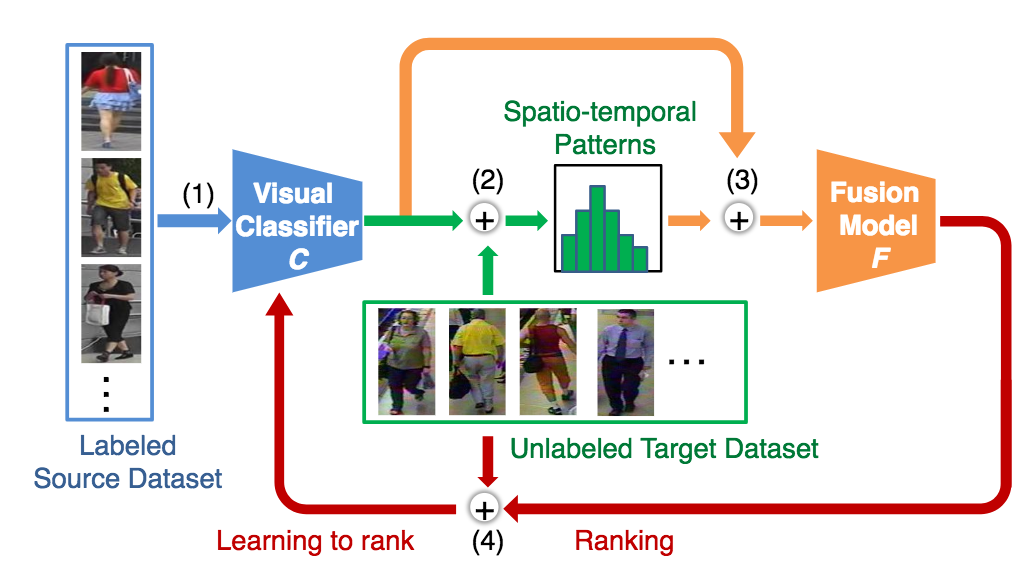
従来の人物再同定の設定では比較的小さいデータセットであり、完全に教師ありの環境を想定していたが、本論文ではラベルなし、ドメインが異なる環境に対して人物再同定を実行するため、非常に難しい問題となる。
学習画像がなくても行動認識を実現する「Unseen Action Recognition (UAR)」についての研究。UARの問題をMIL(Multiple Instance Learning)の一般化(GMIL)として扱い、ActivityNetなど大規模動画データから分布推定して表現を獲得。図は提案手法であるCross-Domain UAR (CD-UAR)である。ビデオから抽出したDeep特徴はGMILによりカーネル化される。Word2Vecとの投稿によりURを獲得し、ドメイン変換により新しい概念を獲得する。
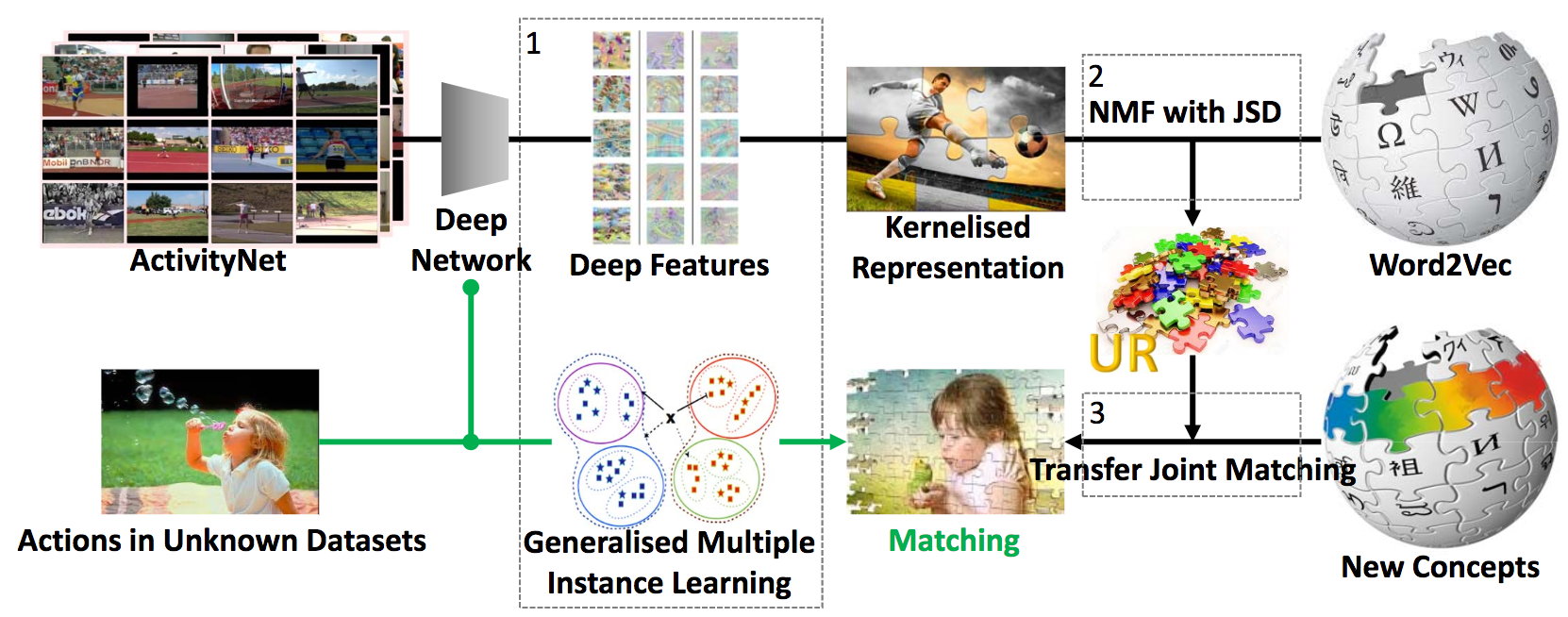
従来法では見た/見てないの対応関係をデータセット中に含ませていたが、本論文での提案はUniversal Representation(ユニバーサル表現)を獲得して同タスクを解決する。
HDRの画像の明るさを補正するためのブラケット撮影からの距離画像やカメラ姿勢を同時推定する手法を提案する論文。ブラケット撮影とは通常の露出撮影以外に意図的に「少し明るめの写真」と「少し暗めの写真」を同時に撮影。距離画像推定は幾何変換をResidual-flow Networkに統合したモデルにより行う。ここでは学習ベースのMulti-view stereo手法(Deep Multi-View Stereo; DMVS)を幾何推定(Structure-from-Small-Motion; SfSM)と組み合わせる。
距離画像推定において、スマートフォンやDSLRカメラなど種々のデータセットにてSoTAな精度を達成。モバイル環境でも動作するような小さなネットワークと処理速度についても同時に実現した。
画像の色を特定の感情を想起するように変換する手法。入力は画像と感情を表す単語であり、入力感情を表すように画像の色が変換される。感情形容詞に対してカラーパレットが定義付けられたデータを使用し、色と感情の距離を計算することで画像に適用する。

1024x768の画像を1秒以下で生成可能。提案手法によって生成された画像と、アーティストによって作成された作品を、1)入力感情が表されているか、2)画像の見た目として自然か、という観点でユーザに採点を行ってもらったところ、提案手法が優位な結果となった。
単語間の距離を学習しているため、トレーニングデータセットにない単語の入力も可能。感情から5色のカラーパレットへ変換するが、入力画像が6種類以上の色相を持つ場合には生成画像が不自然になる。適応的に色数を変更していきたい、と主張。
人物検出と同時に人物行動やその物体とのインタラクションも含めて学習を行うモデルを提案する。本論文では物体候補の中でも特にインタラクションに関係ありそうな物体に特化して認識ができるようにする。さらに、検出された

人間に特化した検出と行動推定の枠組みを提案した。V-COCO(Verbs in COCO)にて、相対的に26%精度が向上(31.8=>40.0)、HICO-DETデータセットにて27%相対的な精度向上が見られた。計算速度は135ms/imageであり、高速に計算が可能である。
複数の人物に関する、パーツごとのセマンティック/インスタンスセグメンテーションを提案する。この問題に対してデータセットであるMultiple Human Parsing (MHP)データセットや認識のモデルを同時に提案する。データセットに関しては人物に関する18カテゴリ(7が人体、11が服装に関するカテゴリ)、4,980画像、2~16人/画像、計14,969人で構成される。モデルであるMH-ParserはDeepLab-ResNet-101によりパージング、graph-GANによりAffinity Mapを推定してセマンティックのみならずインスタンスのセグメンテーションを高度に解決する。

従来のデータセットであるLIPやATRなどと比較すると人物数が多いわけではないが、「複数人」が1画像に映り込んでいるという意味で利点がある。Mask R-CNNとの比較において、全てのデータを含んだ精度ではComparativeであるが、Top-20/-5の精度ではMH-Parserが高い精度を実現した。
画像と音声の入力から、音が画像のどこで鳴っているか(鳴りそうか?)を推定した研究。さらに、人の声なら人の領域、車の音なら車の領域にアテンションがあたるなど物体と音声の対応関係も学習することができる。学習には音源とその対応する物体の位置を対応づけたデータセット(144Kのペアが含まれるSound Source Localization Dataset)を準備した。さらに既存の物体認識と音声を対応づけて(?)Unsupervised/Semi-supervisedに学習することにも成功した。
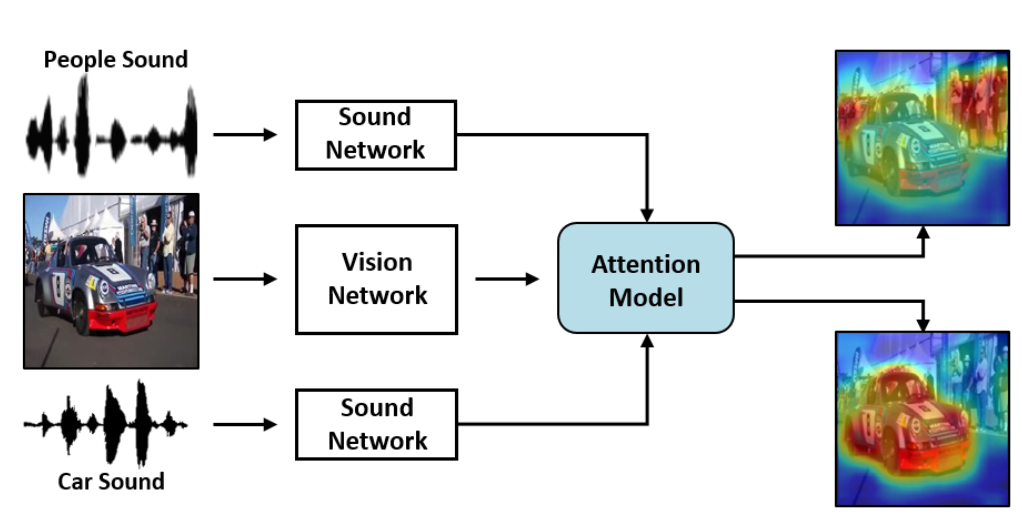
教師あり、教師なし、半教師あり、いずれの枠組みでも音声ー物体の対応関係を学習することができるようにした。音源とそれに対応する物体領域の尤度がヒートマップにて高く表示されている。結果はビデオを参照されたい。教師なし学習はTriplet-lossにより構成され、ビデオと近い/遠い音声の誤差により計算。
セマンティックセグメンテーションに関して異なる複数のデータセットを統合して学習する枠組み(Heterogeneous Learningと呼ぶ)を提案する。本稿ではCityscapes, GTSDB, Mapillary Vistasという公開DBを統合してモデルを学習。また、階層的モデルは畳み込み特徴を共有し、各データセットからそれぞれラベルを学習して誤差をフィードバックしながらモデルを学習する(これによりデータセット間でラベルのあり/なしを相殺しながら学習、カテゴリ数が異なる場合にも学習を強化できる)。
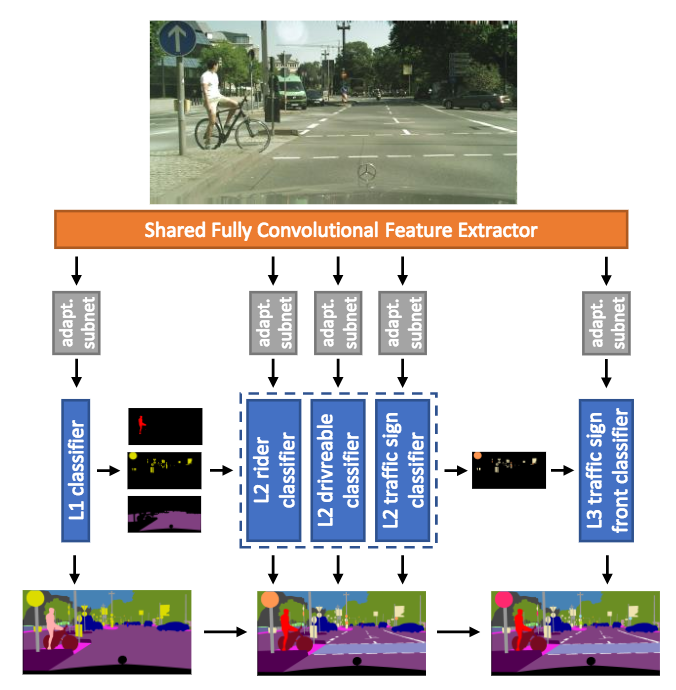
3つの異なるデータベースから知識を(Heterogeneous学習で)統合することにより、最終的には108カテゴリの階層的な分類をセマンティックセグメンテーションの枠組みで行うことができた。
ファッションにおいて各年のコレクションから収集したファッションスナップをデータベース化。服装も含めた人物領域のセグメンテーションや8カテゴリ(2008~2015)のYearを識別する問題に落とし込んだ。この問題を解決するため、多階層の特徴抽出を行い、統合することによりセグメントとラベルを判断した。
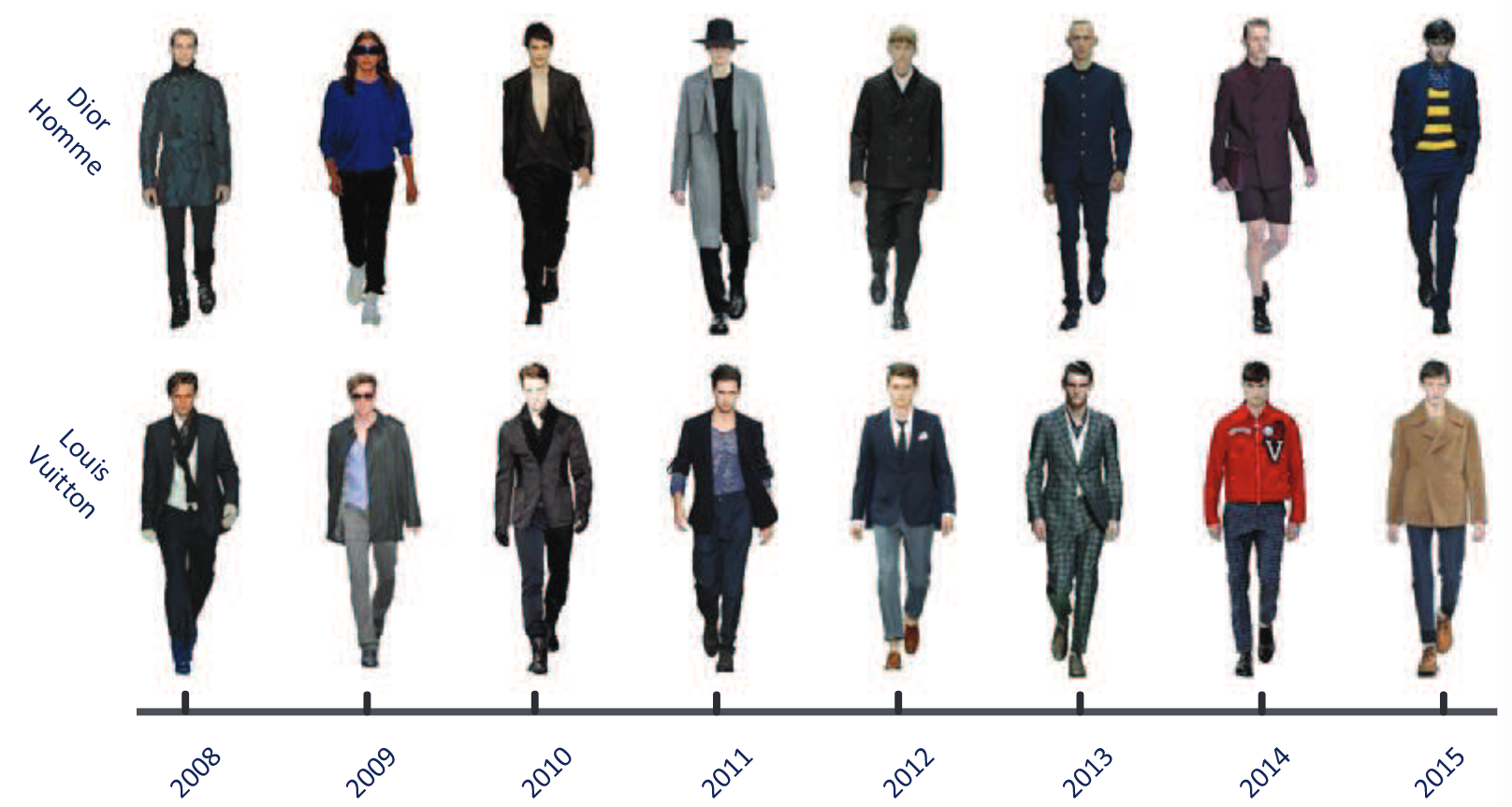
全9339枚の画像から構成される8年分のファッションDB、Fashion8を提案、ファッションセグメンテーションや識別を行うためにEnd-to-End/Multi-scaleのアーキテクチャを提案。
一枚絵の画像から3次元形状、カメラパラメータ、テクスチャを推定して物体の構造を再現するという研究。シルエット、3次元キーポイント、テクスチャを推定して誤差を計算、ネットワークを学習する。Neural 3D Mesh Rendererに発想が近い研究である。
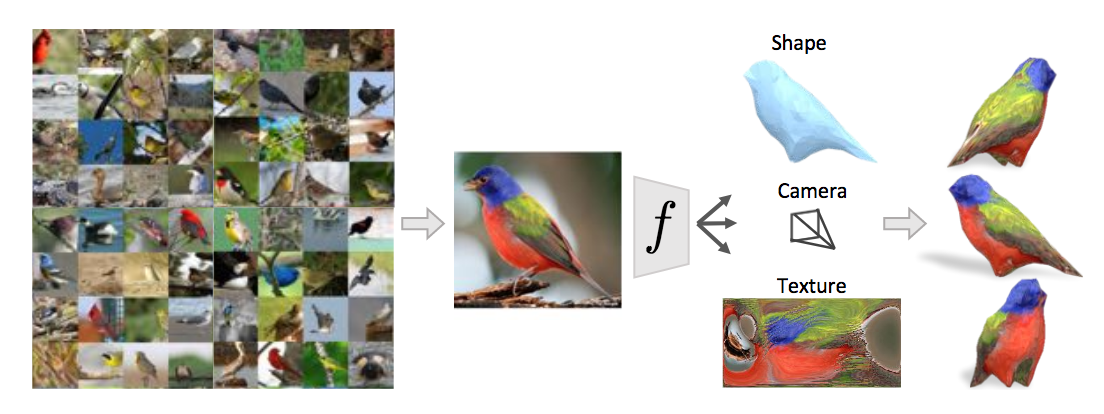
右図を参照。3次元形状(shape)、カメラパラメータ(camera)、テクスチャ(texture)の推定を統合して形状のみならず色やその構造まで復元できている。
図は,テーブルに腕を近づける動きをさせているが,意図せずコップの向きも変えてしまっている.このままではロボットはこの二つを同時に学習してしまうが,本来は対テーブルの動きのみ学習すべきである. そこで,意図しない動きを抜いた動きを使ってロボットの動きを学習しようという試み.
意図する動きがメジャーを取っているという仮定のもと,その時々で,ロボットの軌跡の修正に関わる特徴のうち一つだけを使って,あとはゼロにしてしまう(One feature at a time)ことで実現する.

簡単だが面白いアイデアで,しかも実際にうまくできているという大変興味深い論文.まさに真理を突いた研究といえる.

昼夜問わず歩行者を検出する枠組みを考察する。本稿ではRGBや温度センサの入力から、いかにネットワークを構築して良好な特徴を評価するかについて、6つのネットワーク((a) Input Fusion, (b) Early Fusion(c) Halfway Fusion (d) Late Fusion (e) Score Fusion I (f) Score Fusion II)を比較した。この枠組みの中でさらに、Illumination-aware Faster R-CNN(IAF R-CNN; 右図)を提案して夜間の歩行者検出でも良好な精度を実現した。なお、本論文ではKAIST Multispectral Pedestrian Benchmarkを用いて検証をおこなった。
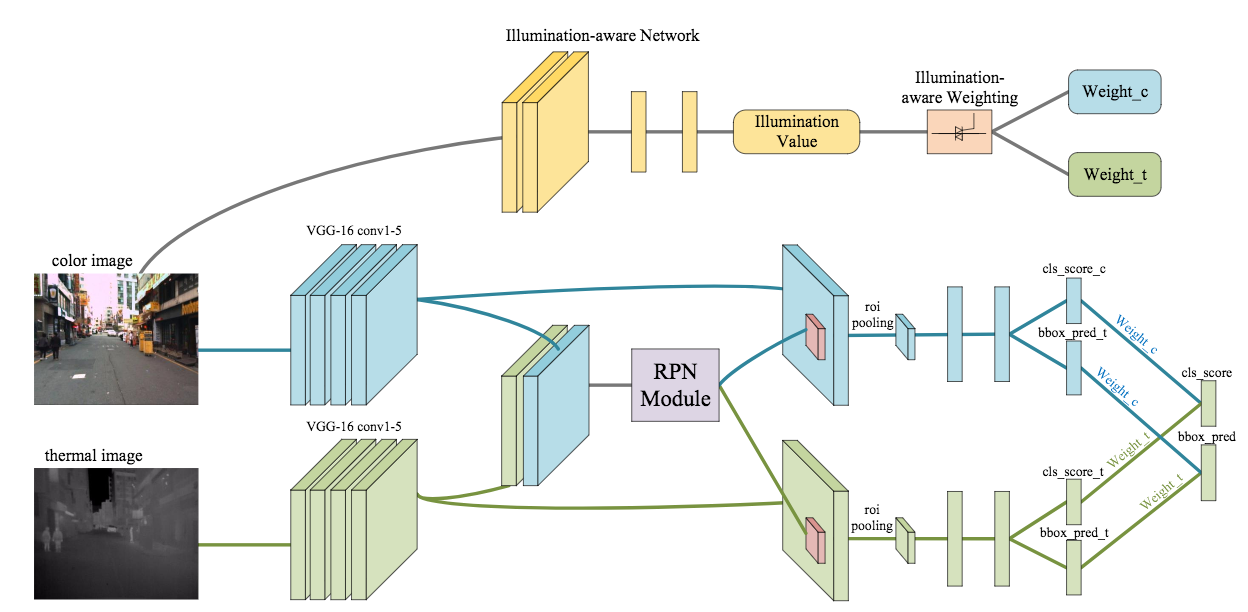
Halfway fusion(Error-rate: 17.57%), Score Fusion I(17.43%)あたりが性能が良かった。IAF R-CNNではエラー率16.22%であった。
自動運転では昼夜問わずの歩行者検知が重要である(ということは言うまでもないが意外とできていない)。データセットを作成する際には温度カメラやステレオ、レーダセンサとRGBカメラを組み合わせるのが一般的になってきた?
所望の機能をロボットに学習させるにあたり,軌跡表示はよい情報提供となるものの,ユーザに見せるには難しい.ただの比較クエリへの回答(どっちの軌跡が良いか?)はユーザには大分簡単なので,効果的な代替手法として使われてきた. しかし,比較は情報量に乏しい.やっぱりもっとリッチな情報が欲しい.
特徴クエリによる比較の拡張に焦点を行ってみる.
シミュレーションと本物ユーザ両方で試した.リッチで特徴拡張なクエリは早くて,よりマッチしたユーザ選択を導くことが分かった.
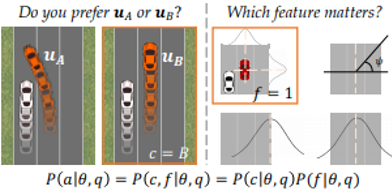
ユーザに特徴を追加した(情報量増やした)クエリを作るという形式は,インタラクションとしては挑戦的に感じる.「無回答(わからない)」を回答してもよいとか,同じクエリに毎回異なる回答をするユーザを想定するところがちゃんとやっている感じがする.
イントロでContribution並べているCVPR感.

タスク実行に関する,自然言語によるユーザー表現のモデル化を行うアクティブラーニングの枠組みを提案.タスクの時系列に対する素人ユーザの表現を学習する. 以下のような質問を行い,ディリクレ多項モデルなどでモデル化し,逐次アップデートしていく.

他手法に比べ,時系列変化を考慮に入れていることが新しい点とのこと.
ロボットとの対話の中で,ロボットとの協議でユーザの傾向を測るのは,あるべきパラダイムであろう.時変化という制約を付けたことでインタラクション的にも機械学習的にもうまくいくデザインが見つかったのは価値があると思う.



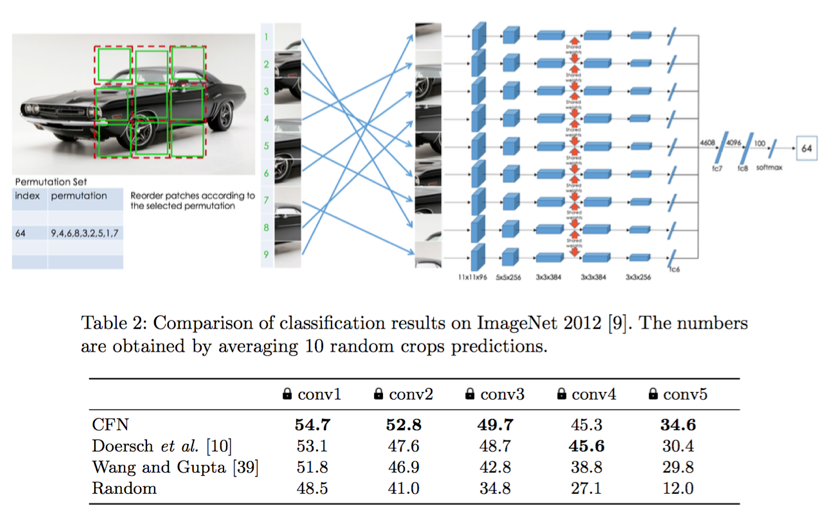
一枚画像から作成されるジグソーパズルを解くことで表現学習を行う。SiameseNetを用い、9×9のpermutationの識別を解く(実際にはハミング距離などが考慮された1000通りのpermutationに限定)。タイルの境界部分などの低レベルな特徴によってとかないよう、境界を消すような前処理を行う。
既存手法として中心タイルからの相対位置8クラス分類などの表現学習方法が存在したが、難度が高すぎた。本手法ではpermutationの限定、すべてのタイルを入力として使用することで難度を調整している。様々なタスクの表現学習においてSoTA。
フレームレートを修正できるカメラDynamic Vision Sensors (DVS)により行動認識を行う。DVSはピクセル値の変化のみによりON/OFFを切り替え画素値を記録する仕組みで、フレーム間差分を撮像するような画像を入力できる。HD画像を記録した場合でもストレージの消費が抑えられる。本論文ではモーションを記録するために画像スライス(x-y, x-t, y-tの空間)を記録する。

Motion boudary histogram (MBH)との統合により良好な精度を実現した。UCF11にて0.6727, MBHとの統合により0.7513(RGB画像では0.7933)。DVS gesture datasetではMBHとの統合により0.9880。
先の(未来の)フレーム予測と異常検知を同時に行う手法を提案する論文。予測したフレームと異常検知の正解値により誤差を計算して最適化を行う。図に本論文で提案するネットワークアーキテクチャの図を示す。U-Netにより画像予測やさらにオプティカルフロー推定を行い、RGB空間、オプティカルフロー空間にて誤差を計算しGANの枠組みでそれらがリアルかフェイクかを判定する。同フレームを用いて異常検知を実施する。
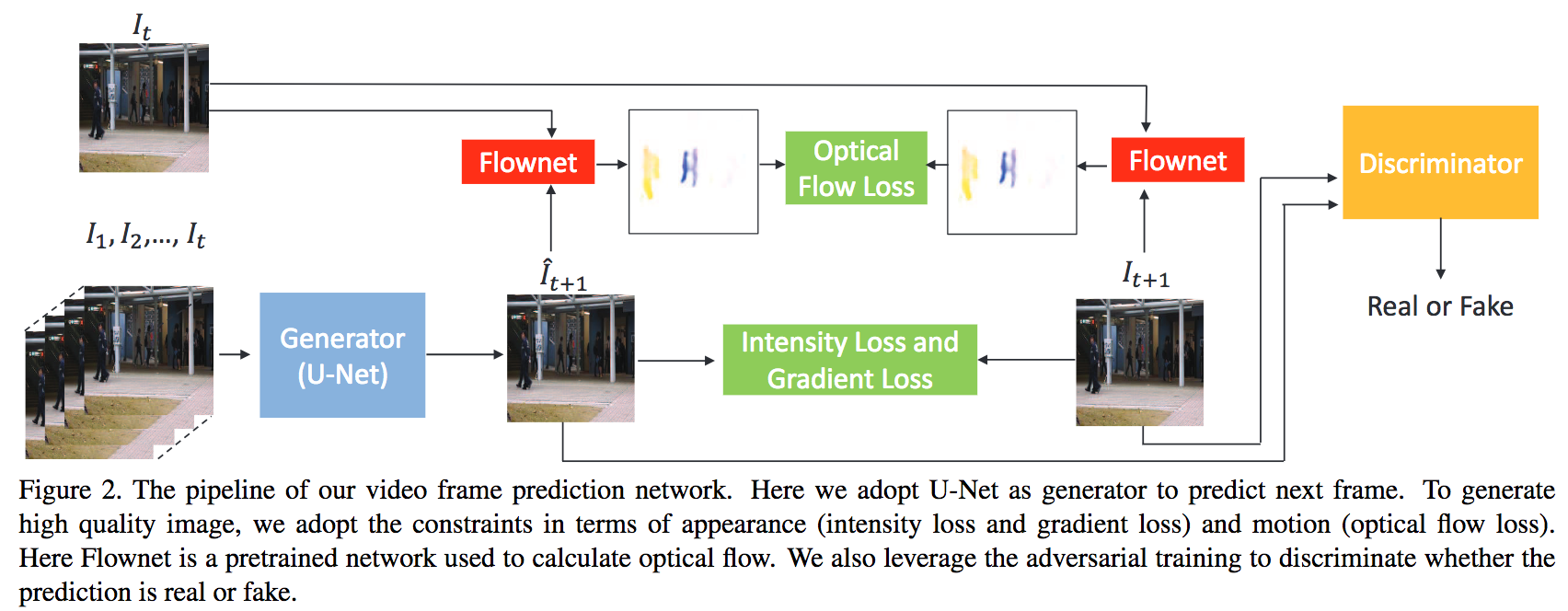
従来は現在フレームを入力として異常検知を行う手法は存在したが、未来フレームを予測して異常検知を行う枠組みは本論文による初めての試みである。異常値の正解値を与えることで画像予測にもフィードバックされるため、画像予測と異常検知の相互学習に良い影響を与える。オープンデータベースにてベンチマークした結果、何れもState-of-the-artな精度を達成。
RGB-Dセンサによる入力から、人物の3次元キーポイントを検出して、可能であれば手領域の法線ベクトルを抽出する。手領域はロボット操作に活用してデモンストレーションを実行する。図に示すアーキテクチャでは、主に姿勢推定(2D Keypoint Detector)、3次元への投影(VoxelPoseNet)、手領域の法線ベクトル推定(HandNormalNet)から構成される。姿勢推定はOpenPoseを活用、VoxelPoseNetは3次元のL2ノルム誤差により計算する。
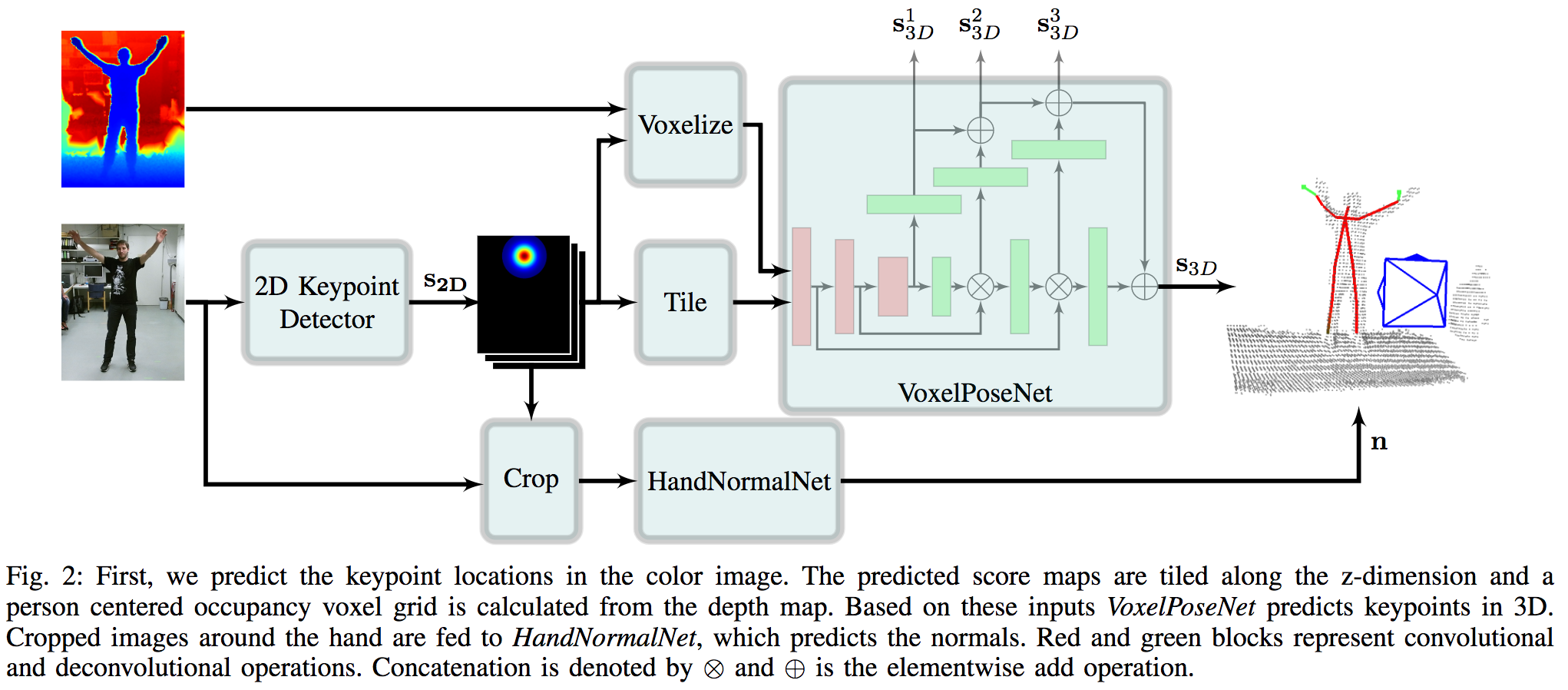
実環境におけるデモンストレーションではロボットPR2を用いて人物の把持行動を教師としてマニピューレーションタスクを模倣した。実験はMulti View Kinect DatasetやCaptury Datasetにておこなった。
新しいRNN手法であるindependently recurrent neural network (IndRNN)の提案。一枚のレイヤ内のニューロンが独立しており、レイヤ間で接続されている。これにより、勾配消失問題や爆発問題を防ぎ、より長期的なデータを学習することができる。また、IndRNNは複数積み重ねることができるため、既存のRNNよりも深いネットワークを構築できる。
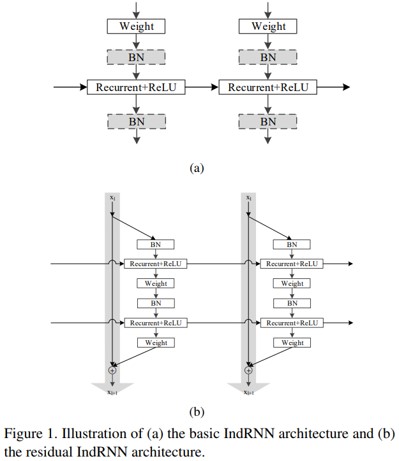
本手法によって下記の従来手法の問題を解決。
RNNは、勾配の消失や爆発の問題、長期パターンの学習が困難である。LSTMやGRUは、上記のRNNの問題を解決すべく開発されたが、層の勾配が減衰してしまう問題がある。また、RNNは全てのニューロンが接続されているため、挙動の解釈が困難。
既存のNon-Max Supressionを改良したFitness NMSの提案。Soft NMSも同時に使用するとより効果的。
勾配降下法の収束特性(滑らかさ、堅牢性など)を維持しつつ、IoUを最大化するという目標により適した損失関数であるBounded IoU Loss の提案。これをRoIクラスタリングと組み合わせることで精度が向上する。
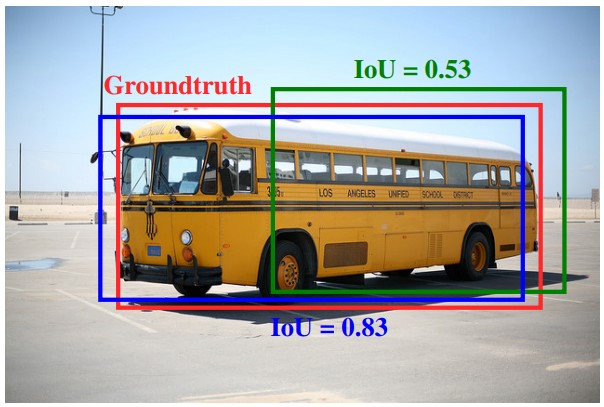
バウンディングボックスのスコアを算出する関数を拡張する。具体的には、グランドトゥルースとのIoUと、クラスの期待値を追加する。これにより、IoUの重なり推定値と、クラス確率の両方が高いバウンディングボックスを優先して学習することができる。
物体認識を行う際にコンテキスト情報(ここでは背景領域の特徴)が少なからずヒントとして効いているのでは?という疑問を解決するための検証。通常の物体検出データセット(OrigSet)をbboxのアノテーションを参考にして前景領域(FGSet)と背景領域(BGSet)に分けて精度を確認した。コンテキスト情報は特徴として非常に強く、物体が隠されている場面でも物体認識ができることを示唆した。
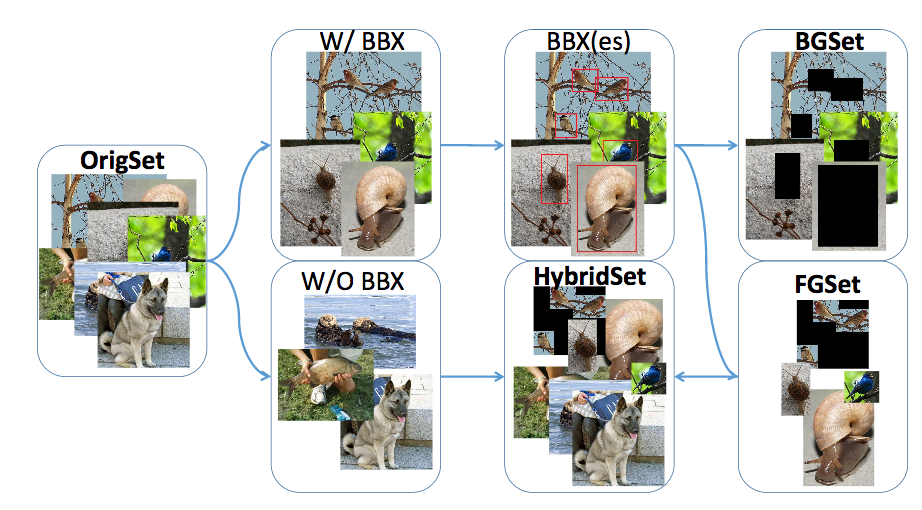
AlexNetを用いた場合、OrigSetよりもBGSet(背景領域のみ)の方が精度が高いこともあることが判明した。さらに、BGSetはFGSet(前景領域のみ)よりも大体において良好な性能を実現している。このことからも背景領域におけるコンテキストは無視できないものとなった。
行動認識における調査"Human Action Recognition without Human"も合わせて読んでおきたい。
本論文ではLarge-margin Gaussian Mixture (L-GM) Lossを提案して画像識別タスクに応用する。Softmax Lossとの違いは、学習セットにおけるディープ特徴の混合ガウス分布をフォローしつつ仮説を設定するところである。識別境界や尤度正則化においてL-GM Lossは非常に高いパフォーマンスを実現している。
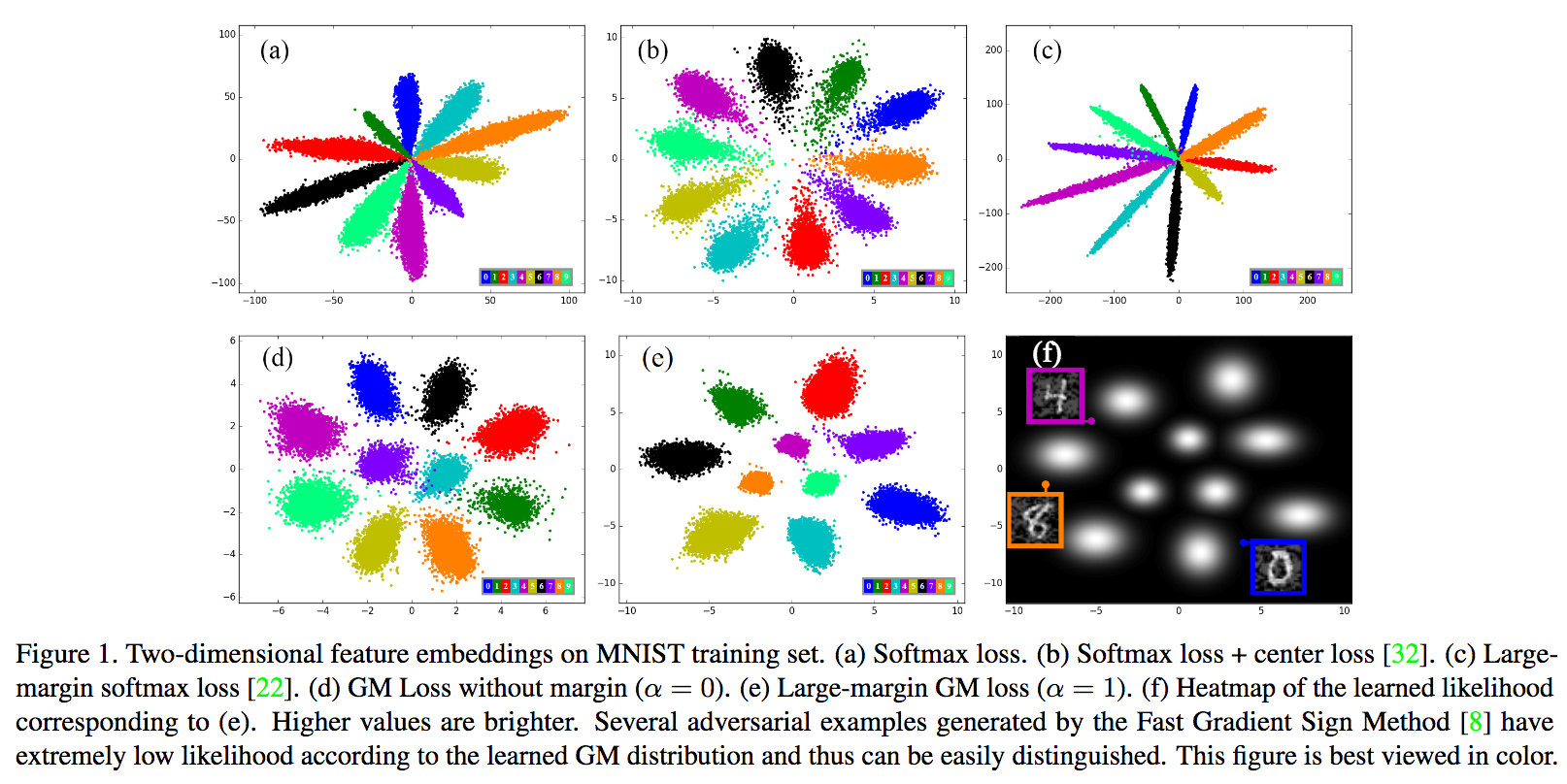
L-GM Lossは画像識別においてSoftmax Lossよりも精度が高いことはもちろん、特徴分布を考慮するため例えばAdversarial Examples(摂動ノイズ)などにおいても対応できる。MNIST, CIFAR, ImageNet, LFWにおける識別や摂動ノイズを加えた実験においても良好な性能を確かめた。
ドメイン変換について、ゲームなどのCG映像から実際の交通シーンに対応して物体検出を行うための学習方法を提案する。本論文では(i) 画像レベルのドメイン変換、(ii) インスタンス(ある物体)に対してのドメイン変換、の二種類の方法を提案し、整合性をとるように正規化する(図のConsistency Regularization; Global/Localな特徴変換を考慮)。ここで、物体検出はFaster R-CNNをベースとしてドメイン変換の手法も二種類(H-divergence、敵対的学習)用意する。
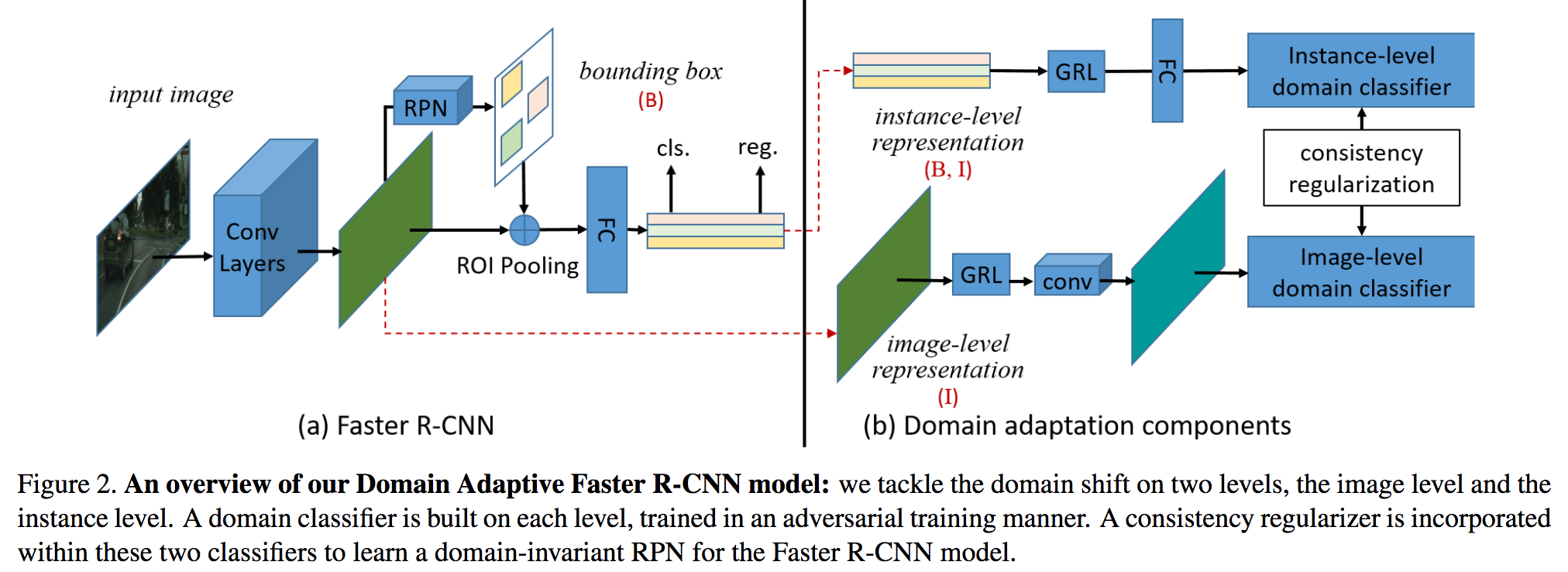
CGで学習し実環境における自動運転などで使えるドメイン変換の手法を提案した。実験はCityscapes, KITTI, SIM10Kなどで行い、ロバストな物体検出を実行することができた。例えばCityscapesとKITTIの相互ドメイン変換でベースラインのFaster R-CNNが30.2 (K->C)、53.5 (C->K)のところ、Domain Adaptive Faster R-CNNでは38.5 (K->C)、64.1 (C->K)であった。
ラベルの付いていないデータに対して、どの画像にラベルを付けてデータセットを構成すればよいかを判断するguided labelingの提案。ラベル付けを行う必要があるサンプルを見定めることで、データセットの量を大幅に減らすことができる。
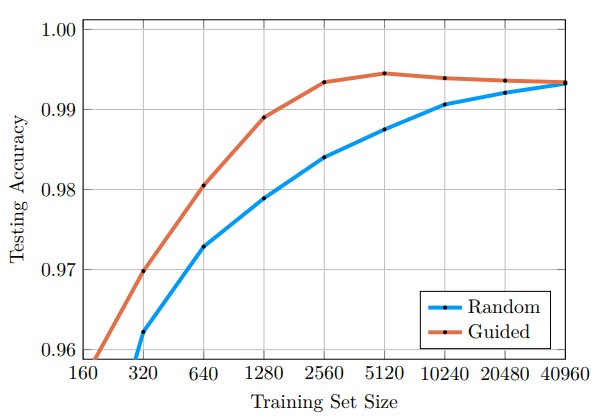
大規模データセットにおいて、手動でのラベル付けは大変。選別してラベル付けを行えば、作業を最小限に抑えられる。また、ある意味良いデータを選別できるため、場合によっては精度も向上。
MNISTは、データセットのサイズを1/16に、CIFAR10は1/2に減らすことが可能に。また、MNISTの場合は、全部使った時よりも識別精度が向上した。普遍性を妨げる不必要なデータを取り除けたことが精度向上につながった?
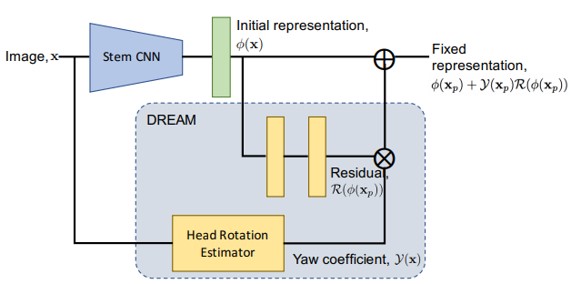
横顔の認識精度を高めるためにDeep Residual EquivAriant Mapping (DREAM)の提案。正面と側面の顔間のマッピングを行うことで特徴空間を対応付ける。これにより、横顔を正面の姿勢に変換して認識を単純化。

画像の意味や内容が、キャプション評価の重要な要素であると仮定し、シーングラフへのマッピングを用いて評価するSemantic Propositional Image Caption Evaluation(SPICE)の提案。これにより、出力したキャプションがオブジェクト、属性およびそれらの関係をいかに表現できていいるかを測ることができる。
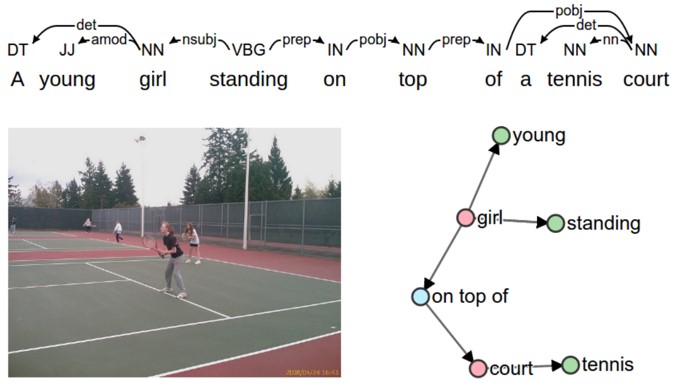
既存の評価では、主に人間によるキャプションに近いかどうかをシミュレートするタスクとしては微妙なところ。
図中の、上の依存性解析ツリーからオブジェクト(赤色)、属性(緑色)、および関係(青色)を取得し、右のシーングラフにマッピングする。候補シーングラフと参照シーングラフのタプルで計算されたFスコアを用いてキャプションのクオリティを算出。
Bleu、METEOR、ROUGE-L、CIDErなどの既存のn-gramメトリクスよりも、人間が判断したかのように評価することができる。しかし、課題はまだまだある。
意味的概念(タグ)を画像から取得し、各タグの確率をLSTMのパラメータとして使用することでイメージキャプショニングを行うSemantic Compositional Network (SCN)の提案。SCNは、LSTMの重みをタグの情報を含んだ重みに拡張する。タグには確率が設けてあり、大きければ大きいほどタグをLSTMに反映させる。
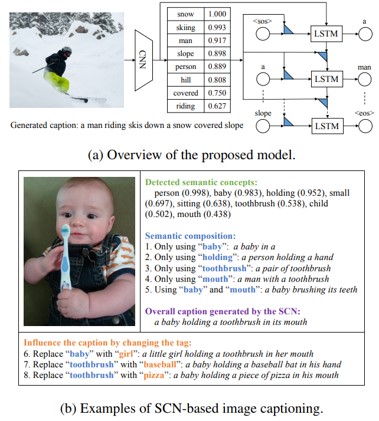
従来のRNNに、意味的特徴を追加したイメージ。LSTMに“単語”と“状態”を入力する際に、意味的特徴を追加していく。通常の入力と意味的情報を追加したものを重み行列のアンサンブルと呼んでいる。
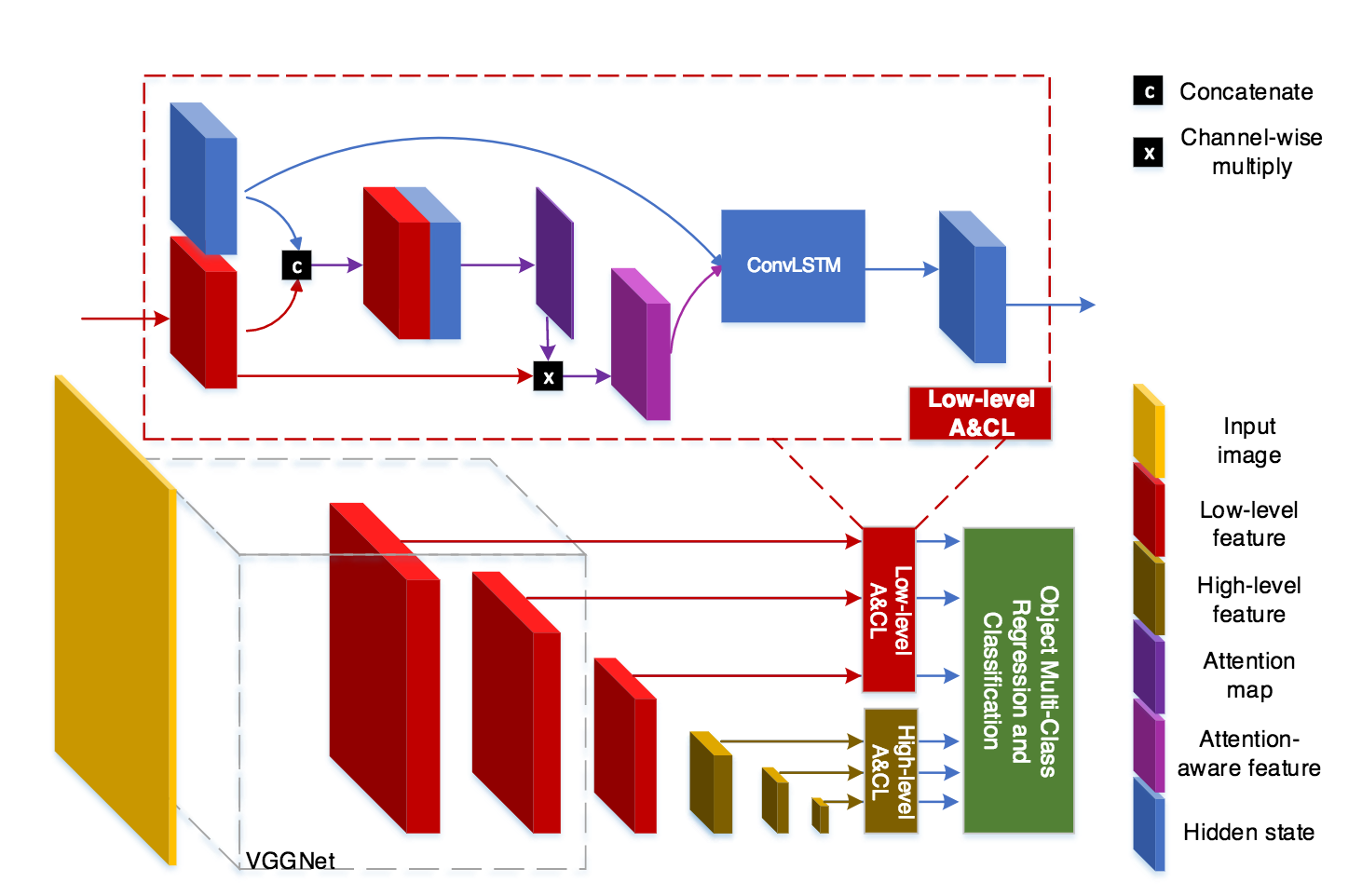
アテンションとConvLSTM構造を参考にして時系列のROI検出器であるTemporal Single-Shot Detector (TSSD)を構築して、ロボットビジョンに応用する。ConvLSTMでは階層的な時系列特徴を取り扱い、High-levelからLow-levelな特徴を処理できるようにした。
CNN-RNNのキャプション生成モデルに、属性推定を追加したLong Short-Term Memory with Attributes(LSTM-A)を提案。属性間の相関を、 Multiple Instance Learning(MIL)で統合することにより、属性間相関を探索し、文章生成。
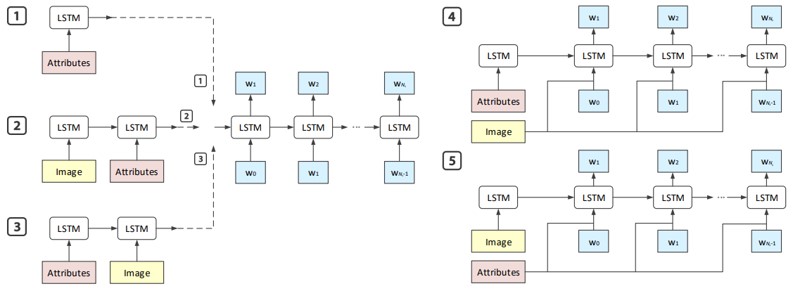
LSTM-Aの5つの変種について研究。
3つのモデルは属性をどこに追加するか:LSTM-A1は属性のみを利用、LSTM-A2は最初に画像表現を挿入する、LSTM-A3は最初に属性を供給。
2つのモデルはLSTMに属性や画像表現をどのタイミングで入力するか: LSTMA4は各時間ステップでの画像表現の入力、LSTM-A5は各時間ステップでの属性の入力。
人間によるキャプションに匹敵するキャプション生成モデルの提案。人間のキャプションに近づけるために、ガンベル分布を組み込み、GANを採用。ガンベル分布を使用してソフトマックス分布からソフトサンプルを取得し、サンプルをバックプロパゲーションする。
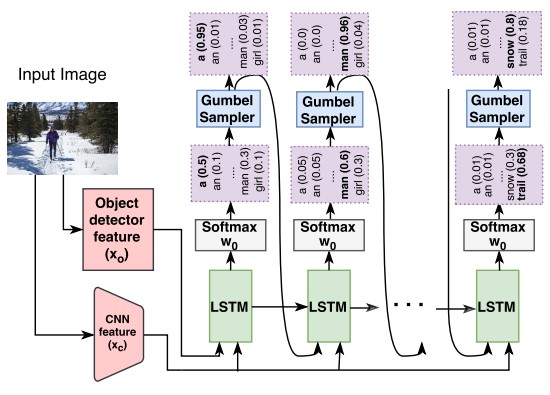
生成された単語の分布、語彙のサイズの欠如、頻繁なキャプションに対するジェネレータの偏りなど、従来のイメージキャプショニング手法と人間によるキャプションの差がある。そこで、イメージキャプショニングの学習目的を、正解キャプション生成から、人間のキャプションと区別できないキャプションの出力に変更。
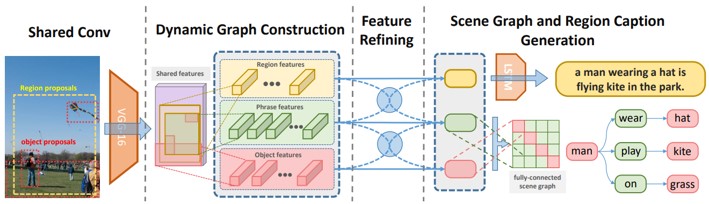
物体検出、フレーズ、キャプショニングの3つのタスクを共同で学習し、シーン理解を行うMulti-level Scene Description Network(MSDN)の提案。入力画像から異なる意味を持つ領域間をリンクさせるために、グラフを動的に構築。これにより、様々なタスクを整理しながら学習する。
CNNでイメージキャプショニングを行う言語モデルの提案。1つの単語と状態(state)に基づいて時系列的に次の単語を予測するRNNとは異なり、Language CNNは以前に推定された全ての単語を入力とすることで、画像キャプションとして重要な単語の長期依存性をモデル化できる。
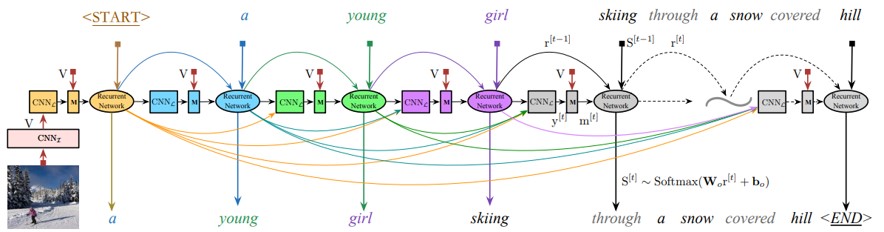
以前の単語の忘却を防ぐために、RNNにCNNLを追加して文章を生成する。全ての時間枠で重みが共有されるのがミソ。
画像特徴抽出のためのCNNI、言語モデリングのためCNNL、CNNIとCNNLを接続するマルチモーダル層(M)、単語予測のための再帰ネットワーク(RNNやLSTMなど)の4部構成。
Far Infrared(FIR)カメラを用いて昼夜問わず歩行者を検出するための取り組み。同タスクを解決すべく、FIRカメラによる歩行者検出データベースを構築、複数の歩行者検出モデルーHolistic, Part-basedアプローチ, Patch-basedアプローチーを比較してベンチマークした。また、RGB画像、FIR画像、その両方を用いて歩行者検出を試行した。

識別器としてSVM/DPM/RF、特徴量はHOG/LBP/HOG+LBP、Day/Night、Visible/FIRの組み合わせを調査した。Day/Night問わずエラー率はFIRが良く、特徴を組み合わせるHOG+LBPの方が良い結果を示した。Dayの場合にはHOG+LBP+RF(ランダムフォレスト)が、Nightの場合にはHOG+LBP+SVMがもっとも精度がよかった。
ビデオ中の事象の検出と記述、両方を含む高密度キャプションイベントのタスク。つまり、ビデオ内で検出された複数のイベントを自然言語で同時に記述しながら、全てのイベントを識別できる新しいモデルを提案。ビデオ内のイベント間の依存関係を取得するために、過去と未来のイベントのコンテキスト情報を使用し、すべてのイベントを共同して記述するキャプションモジュールを導入。高密度キャプションイベントの大規模データセットのActivityNet Captionsも提案。
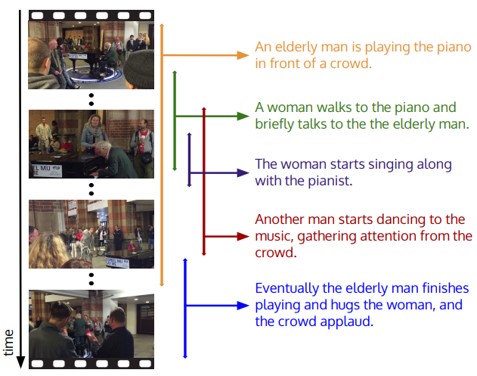
ビデオには多数のイベントが含まれている。例えば、「ピアノを弾く男」のビデオでは、「別の男の踊り」や「群衆の拍手」が含まれてたりなど。これらすべてのイベントについて、ビデオを1回パスするだけで記述する。
ActivityNetには、100kのキャプション、849時間の動画20k本が含まれる。
Common Subspace for Model and Similarity (CoSMoS)によるフレーズの学習方法の提案。
1.同一フレーズに関連付けられたすべての特徴ベクトルを近接するようにマッピング
2.各フレーズの分類子を学習
3.フレーズ間でトレーニングサンプルが共有される部分空間を得る
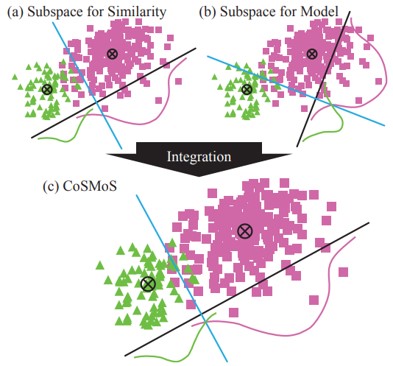
“単語”ではなく、オブジェクト、属性、イベント、およびそれらの関係を表現する“フレーズ”に着目している。フレーズ数はさまざまな単語の組み合わせであるため、シングルワードの数よりはるかに多くなる。よって、フレーズはトレーニングサンプルが少なく、正確な推定が困難。そこで、モデルと類似性の共通部分空間を学習する。
監視カメラ映像などにおいて人物領域のde-anonymization(匿名にしていた情報をオープンにされること?)を防ぐための研究。RoIに対して実行することで人物再同定(Person Re-identification)の精度を落とすことに成功している。

本提案手法であるAdaptive Scrambling enabling Privacy Protection and Intelligibility (ASePPI)により、匿名性が保たれることが明らかになった。これは、従来法よりも優れている。
遠隔操作ロボットのための,ロボットカメラの自動姿勢決定.作業野を見やすくするカメラ姿勢を自動で決定する.
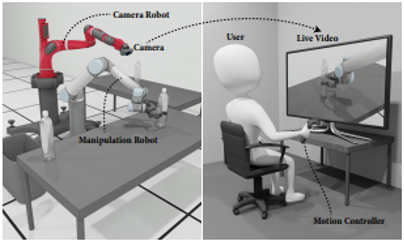
外科手術などに実用性ありそうでいい.
適切なロボット動作のダイナミクスを定義して実装し,ユーザ評価もちゃんと行っている.
BestPaper Nominee.ところで被験者に1時間拘束で10ドル払ってるらしい.
他人に情報が拡散しないよう、「ブラー」と「ブロック」というふたつの(人間に対する)難読化法を検証。53名のユーザについて画像の満足度、情報量などの側面から調査した。

結果から、ブロック(blocking)の方がブラー(blurring)よりも特定されにくいということが判明した。しかし、画像の質やSNSなどに投稿するための満足度(e.g. satisfaction, enjoyment, social presence, likability)としては欠落してしまう。将来的にはユーザのプライバシーを保護するための手法が求められる。
ロボットの移動意思をARで伝える方法について,図の4種類の方法を実装して比較してみた.
ロボットの身体の方向のみに関連した情報提示がベースラインよりも作業効率を顕著に向上させた. また,ロボットとの共同作業感と動きのわかりやすさの間にトレードオフが発生することも 分かった.

(a) 経路のチェックポイントを見せる(b) 経路を矢印で書く (c) ARエージェントが移動方向を見てる (d) ユーザに対するロボットの位置を示唆する
移動方向の表示に関する研究は継続的に行われているが,AR上での表示における調査をちゃんと(網羅的に)行っていることと, 結果が面白い.
BestPaper Nominee.
ロボットの意思決定に,人間とロボットの共同作業の信頼度を組み込んだ.手法的には,部分観測可能マルコフ決定過程(POMDP)の機械学習に信頼度をパラメータとして混ぜた. それにより,ロボットは (1)人からの信頼度を推定 (2)人の行動における自分の行動の影響の理由付け (3)長期的にみたチームパフォーマンス最大化可能な行動の選択 が可能に.
実際にパフォーマンスを高められることを確認した.なお,信頼度を最大化してもパフォーマンスは改善しなかった.

信頼度という観点が面白く,理論モデルに基づく実装までこぎつけているのがよい.信頼度最大化がパフォーマンスを改善しないことも面白い.
BestPaper Nominee.



間接言語行為(ISA)の有無によって,タスクベースの人間-ロボット間対話においてどれほど役に立つのか,ISAの理解能力なしにロボットはどれだけ機能するか調査した.
WoZによる実験をしてみた.各条件について,人によるISAの使われっぷりを見る.
人がロボットに対してどう非言語行動をとるかについてはまだまだ未調査の部分が多いが,そのうちの一つ,ISAについての道を示した重要な論文.
BestPaper Nominee.
理学療法,スポーツリハビリ等の各種セラピーに支援ロボットを導入した場合にどうインタラクションしたらよいかについて,セラピストへのヒアリングを基に論じる.
ロボットのセラピーへの従事の利益があるという我々の仮説を裏付けるため,まず下の二つを聞いてみた.
さらに,有効なHRI戦略を導くため,聞いてみた.
ロボットは,患者の自律的エクササイズへの意識の低さに対して支援を行える.スマホなどの既存手法よりも先回り的な支援を行える.
この結果を踏まえ,HRI戦略のデザインの方法論を示す.
聞き取り調査の結果を論文にしたいならこの論文を読むのがよい.
BestPaper Nominee.
LSTMの拡張するgLSTMの提案。画像から抽出された意味情報をLSTMの各ユニットに入力として追加し、モデルと画像コンテンツを密接に結合させる。また、短い文に偏らないように、ビーム探索時に正規化。
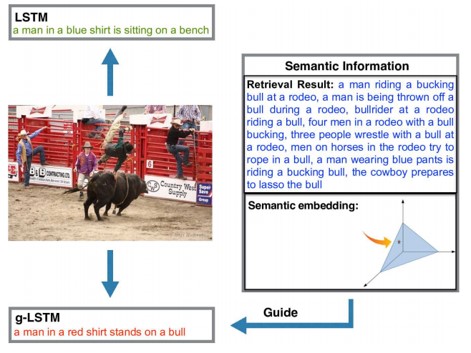
LSTMは畳み込みで得られた画像情報から単語ごとに文章を生成する。しかし、長い分の場合には、プロセスが継続するにつれて画像情報が薄くなる。これは、シーケンスの最初に出力された単語も同様。そこで、ゲートとセル状態の計算にグローバルな意味情報を追加。意味情報は、画像とその説明から抽出し、単語列生成の過程でガイドとして使用する。
一人称視点カメラによるライフログをアニメ調に変換することでプライバシー性を高める研究。セグメンテーションとブレンディングのみならず、エッジ強調、さらには物体(e.g. テレビ、本)をクリップアートに置き換えることでより理解しやすくプライバシーを保護するアニメ調に変換。

AMTによりユーザスタディも行なった結果、プライバシーを保ちつつ視覚的にも理解しやすい(e.g. 行動認識)動画ストリーミングを流すことに成功した。
入力画像に対して非読性を高めるため、ノイズを付与して内容がわからないように加工する(入力と出力は図を参照)。同タスクに対してGenerative Adversarial Networks (GANs)の枠組みを導入した。提案法をAdversarial Pertubation Mechanismと名付け、攻撃ネットワーク(A)と攻撃者を欺く難読化ネットワーク(O)の敵対的学習により学習を進める。学習においてプライバシーとユーティリティ(オープン化)のトレードオフはパラメータにより調整可能である。基本的な構造はDCGANに基づいていて、OはDenoising AutoEncoder。

攻撃は画像中にQRコードが埋め込まれているかどうかで決まり、いかに敵対的ネットがQRコードの位置を検出できるかどうかで評価する。精度は75%(エラー率25%)となった。
人物のセグメンテーションにより人物の検索性を低くする研究(Person De-identification)。服装レベルでのセグメンテーションについてもうまくいっている。本論文で提供するモデルは顔認識のみでなく服装や髪型といった特徴についても非読性を向上させる。手法はGANを参考に構築されており、(物体検出も組み合わせつつ)セグメンテーションを実行する。広義には人物を中心とした背景差分を行なっている。さらに、DCGANにより予め顔画像を学習する。

Clothing Co-Parsing (CCP)のファッションアイテムのセグメンテーション、Human3.6M datasetの背景マスクを正解として学習を行なった。結果の例は図に示すとおりである。
生活雑音で活動量を測り,活動量を共有することのできるソーシャルネットワークなロボットを提案.生活雑音を取るだけならプライバシーに配慮できて良いし,多対多でもいい感じに働く. 友人間ソーシャルコミュニケーションの実験してみて,プライバシー侵害を感じずに繋がってる感が出ることを確認した. ついでにちゃんとしたものも作った.
うまくやってる感.これってロボットインタラクションなのかな?
BestPaper Nominee.
著者らが作った,擬人ロボットのコレクションデータベースABOTを活用して,擬人ロボットの見た目について分析する. ABOTは200の現実の擬人ロボットの,画像,パーツリスト,4つの観点 (Body-Manipulators, Surface Look, Facial Features, Mechanical Locomotion) におけるスコアを含む.
本研究では,調査のうえ先述の見た目に関する4つの観点を定義し,またロボットの擬人性を推定しやすい特徴について解明した. そのスコアリングシステムはWebで公開する.

盛りだくさん.
BestPaper Nominee.ところで被験者に0.5ドル払ったらしい.
“レンダリングされた”ロボット顔のデザインを仕分け.デザイン空間を定義し,分布を調査する. 157のロボット顔を76属性のデザイン空間に落とす. 文脈に応じてどのようなリアルさ・具体性が好まれるのか, また顔の重要なパーツの有無に対する,適したロボットの作業について論じる.
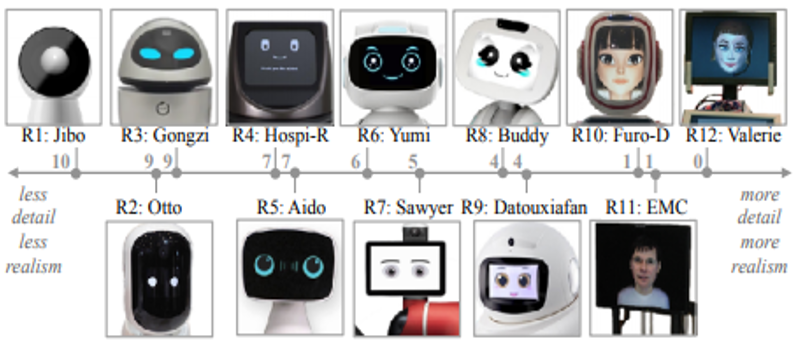
いろんなロボット顔のサーベイが大変なのは言うまでもないが,ちゃんとシステマチックに論じているところが偉い. まさしくワシントン大的貢献.
BestPaper Nominee.
既知の視覚的概念の分類子を構成するために、コンテクストの依存性に着目した手法を提案。コアアイデアは、複数の単純な概念を組み合わせることによる複雑なコンセプトの開発。赤ワインの赤と、トマトの赤では意味は異なる。形容詞(赤)と物体(ワイン、トマト)の間にはコンテクスト依存性がある。このようなコンテクストを全てビックデータで学習することはナンセンスなため、独立した識別器を合成する。
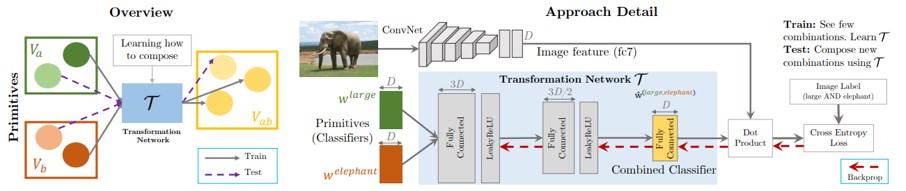
学習: primitive(大きい、象)などの組み合わせのセットにアクセス。これらのprimitiveの各々を線形分類器(w)を学習することによってモデル化。これらの分類器を合成し、その組み合わせの分類器を生成する変換ネットワークを学習。
ロボットのできないことを伝える.何をやろうとしてダメで,なぜダメなのかを伝える. 動きの軌跡の最適化問題とみなし,成功パターンと失敗パターンの 類似性と差の大きさの評価を提案.
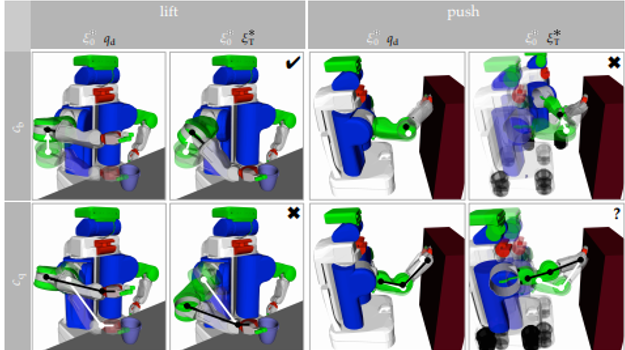
運動学を解くという割と確立された(けどちゃんと検討するのは面倒な)手法的な面を水平思考して,ロボットの失敗談を伝えるという面白さにつなげている.
BestPaper Nominee.
解説動画(お料理動画)におけるアクションとエンティティ間をリンクさせる教師なし学習を提案。グラフ表現によって、言語および視覚的モデルを共有することで、ビデオ内の視覚的・言語的曖昧さを回避する。映像中の作業に対して、言語と動画の2つのワークフローを出力し、最適化を施す。WhatsCookinデータセットより、2000の字幕付き動画を使用。
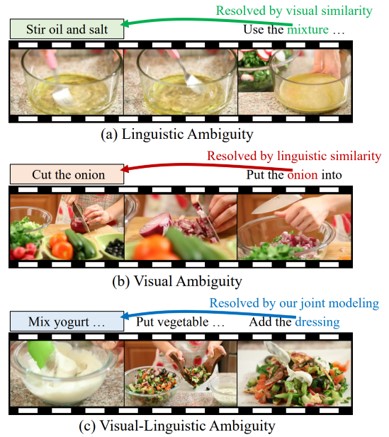
曖昧さ回避
図は、動画中の曖昧なアクションとエンティティを示す。(c)の場合、3つ目のフレームで“ドレッシングを加える”とあるが、果たしてどのドレッシングなのか?というあいまいさが生じる。この場合のドレッシングはヨーグルトを混ぜたものになる。つまり、“ドレッシング”をエンティティ、“混ぜる”をアクションとしてこの2つをリンクさせる。
操作者と遠隔ロボットが部屋レイアウトを共有する空間において,ロボットの遠隔操作をARで支援する方法論についてプロトタイピングし,議論.飛行ドローンの動きを簡単にわかるようにするには?図(a)視体積の表示,図(b)ロボットの吹き出し的にカメラ映像表示,図(c)端にカメラ映像を固定表示. 結果,3方式はカメラ映像をただ見ただけよりも遠隔操作効率が顕著に向上した. また,カメラ映像を見せる方式(b),(c)はカメラ映像とロボットの注視が分散してしまい,比較的遠隔操作効率が悪かった.

特にハッとする面白さは感じないが,各方面がなんとなくやっていたことについて,改めて調査に取り組み, サーベイと実験をちゃんとやって,定量的・定性的評価をちゃんとやった点が評価されたか. 実験デザインも特に面白く感じないが,当たり前のことをやってちゃんと結果が出るようなデザインをしている.
BestPaper Nominee.
ブラックボックスのAdversarial Attacks(敵対的攻撃、摂動ノイズ)を提案する。本論文での画像攻撃は局所的探索により数値的近似を行い、ネットワークの勾配に埋め込むことである。

画像が結果例である。複数の画像識別が誤りを含んでいる。
動画認識タスクにおいて、Google Cloud APIの認識を騙すため動画像に対して意図的に画像挿入を行う攻撃を仕掛ける。攻撃はN秒間に一度、(動画の内容とは全く異なる)任意の画像を埋め込むことで、Google Cloud APIの出力を騙すことに成功した。
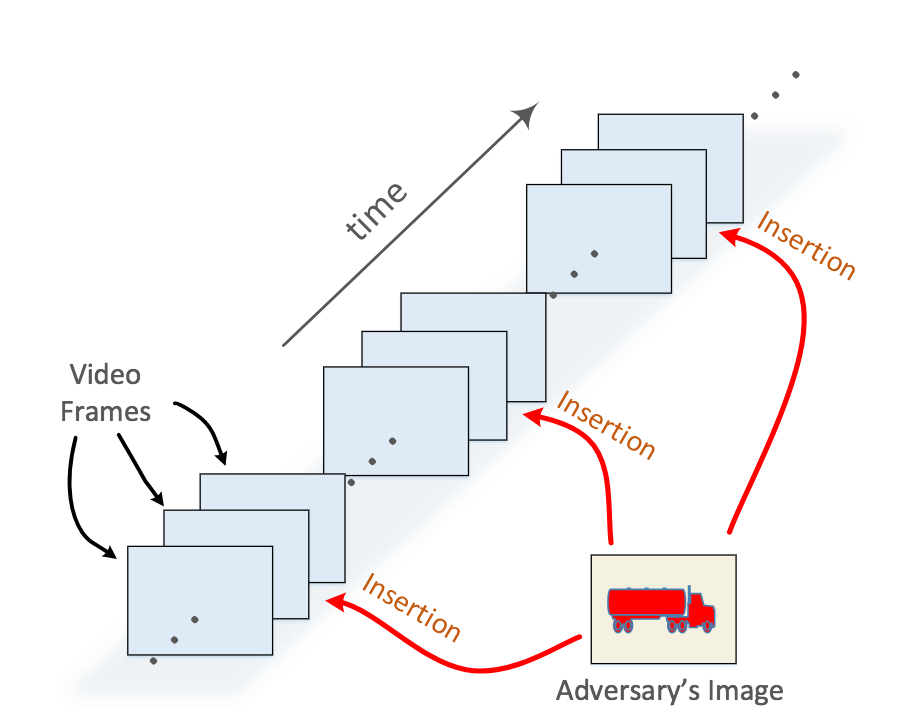
実験の結果、2秒間に一度、画像挿入攻撃を仕掛けると認識誤りを引き起こすことが判明した。動画像は25FPSで構成されるため、50フレームに一度攻撃を仕掛ければ十分であった。
本論文のような攻撃をYouTubeに埋め込まれると動画タグが自動でつけられなくなるという恐れがある一方で、例えばFacebookなどの動画に意図的かつ人の目にはわからないように画像を埋め込めると(プライバシー保護の面で)外部からは検索しづらくなる。(やはり使い方次第ということか)
タイトルの通り、Cut, Paste and Learn(物体の切り抜き、任意画像への埋め込みにより物体検出の学習を実行)により自動アノテーションを行い、学習画像を大量に生成することに成功。ここで問題になるのは切り抜いた物体と画像埋め込みの際のアーティファクト(artifact)であり、自然な埋め込みのみならずアーティファクトを無視して学習する手法を提案した。CutのフェーズではFully-Convolutional Networks (FCN)を用いてセグメンテーションを実行するがさらに後処理にて境界線を綺麗にした。PasteのフェーズではGaussian/Poisson Blendingによりアーティファクトをできる限り削減した状態で背景画像に対して埋め込みを行う。データ拡張についても、2次元3次元の回転、オクルージョンなど行う。

Blendingにおいては{なし, Gaussian, Poisson}の全てを混ぜる手法が最もよくオリジナル画像のみと比較して8AP向上。データ拡張についても全ての拡張{2D rotation, 3D rotation, Truncation, Occlusion, Distractor}を行う拡張が最も良かった。ベンチマークに対して相対的に21%の向上が見られた。クロスドメインの学習においても10%の向上が見られたと報告。
既存の画像キャプションデータセットには存在しないオブジェクトカテゴリを記述できるNovel Object Captioner (NOC)の提案。物体認識データセットからの画像と、ラベル付けされていないテキストから抽出された外部ソースからの意味的情報を利用。 MSCOCOにはないImageNetのオブジェクトカテゴリのキャプションを生成。
画像とキャプションが対になっていないデータや、様々なソースを使って学習することができる。
pre-training済みモデルのembedding空間を使用できるようにし、zero-shotなデータでもキャプションを生成できる。
CNNベースの認識モデル、LSTMベースの言語モデル、キャプションモデルは、別々のソースで同時に学習。しかし、パラメータを共有することで、未知のオブジェクトのキャプションが可能となる。
シーンの全体理解。オブジェクトの数とそのカテゴリ、ポーズ、位置などの情報をエンコードし、シーンのコンパクトかつ表現力豊に解釈可能な表現の提案。decoderとencoderにより、XML形式の言語表現を実現。特に、encoderは、Renderingの逆であるDe-renderingを実行することで、入力画像をscene XMLに変換する。
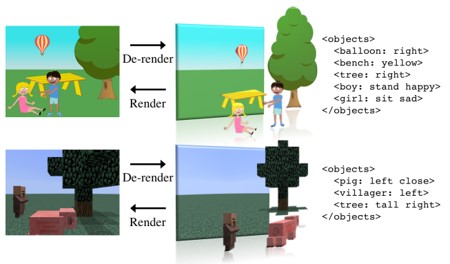
従来研究では、encorderとdecoderベースの深層学習を使用した画像表現を提案してたが、その出力は解釈不可能であるかシーン単一のオブジェクトのみの説明である。そこで、シーン全体かつ解釈可能な表現を出力するモデルの提案。
マインクラフトベースの新しいデータセット。
de-rendering:入力画像からセグメントを生成し、オブジェクトのプロパティを解釈。推測結果を統合し、元の画像を再構成する。
Visual Diarog:AIエージェントが人間と、画像に関した対話をするタスクを目標とする。エージェントが、画像に対する質問に、対話履歴から文脈を推測し正確に回答する。チャットデータ収集プロトコルを開発し、Visual Dialogデータセット(VisDial)を作成。COCOの120kの画像に10の質問と回答ペアを含む1つのダイアログが含まれており、合計は1.2Mのダイアログ質問回答ペア。
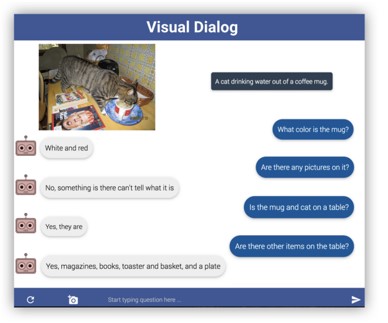
VQAとは異なる、Visual Dialogタスク。
3つのエンコーダ2つのデコーダからなるVisual Diarogモデル。
コード、モデル、データセット、ビジュアルチャットボックスを公開中。
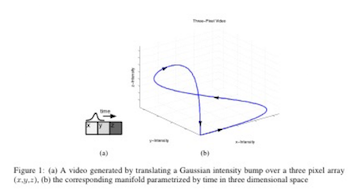
「動画は単一画像を表す特徴空間上におけるManifoldとして表すことができる」という考えをもとにしている。その場合、線形な時間変化に対して各フレームを表す特徴量も線形な変位をするのが妥当であり、制約を加えることでそのような特徴空間への埋め込みを学習させる。
t-1, t の埋め込みベクトルzt, zt-1からt+1の埋め込みベクトルzt+1を予測し、それからt+1の画像復元を行うモデルを考えるが、以下の3つの要素を加える。(1)zの時間的変位のcos類似度が近くなるようにする、(2)max-pooling(出力m)とargmax-pooling (出力p)を行い、t+1のz(=(m, p))を求める際は、pを線形外挿により求める、(3)未来の不確実性の対処として、潜在変数δを定義。 argmax-poolingはソフトな近似関数を定義することで逆伝搬可能にし、δは学習時はサンプルごとにSGDにより最適化し、テスト時はランダムサンプリング。

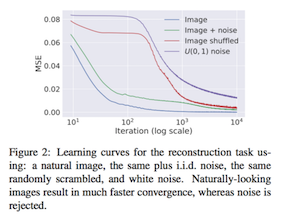
「CNNは理論上任意の関数を近似できるが、その構造自体に汎化性能をあげるようなPriorが含まれている」という考えのもと、ランダム初期化されたCNNを用いて高いレベルの画像復元、ノイズ除去などを行った。 また、CNNのPrior をさらに裏付けるものとして、自然画像を復元するより、ノイズ画像を復元する学習の方がiteration数がかかることも示された。深いネットワークの方が復元性能が高かった。
ノイズ画像zをencoder-decoderモデルに入力して、生成された画像を欠損画像にMSEを近づけるように学習。 注意点として、完全に学習仕切ってしまうと欠損画像と同じものが出るだけなので、学習をある程度のiterationで止めると、復元された画像が得られる。 CNNのPrior をさらに裏付けるものとして、自然画像を復元するより、ノイズ画像を復元する学習の方がiteration数がかかる。


動画キャプションのため、動画中から時系列のRegions-of-Interest(RoI)を獲得する。動画中のアテンションを獲得するDual Memory Recurrent Model(DMRM)を提案して時系列の大域的構造/特徴とRoI特徴を対応づける。これにより、人間のように動画を粗く流し見することに相当するモデルが構築できる。さらに詳細に特徴を評価するため、意味的な教示(semantic supervision)を行う。
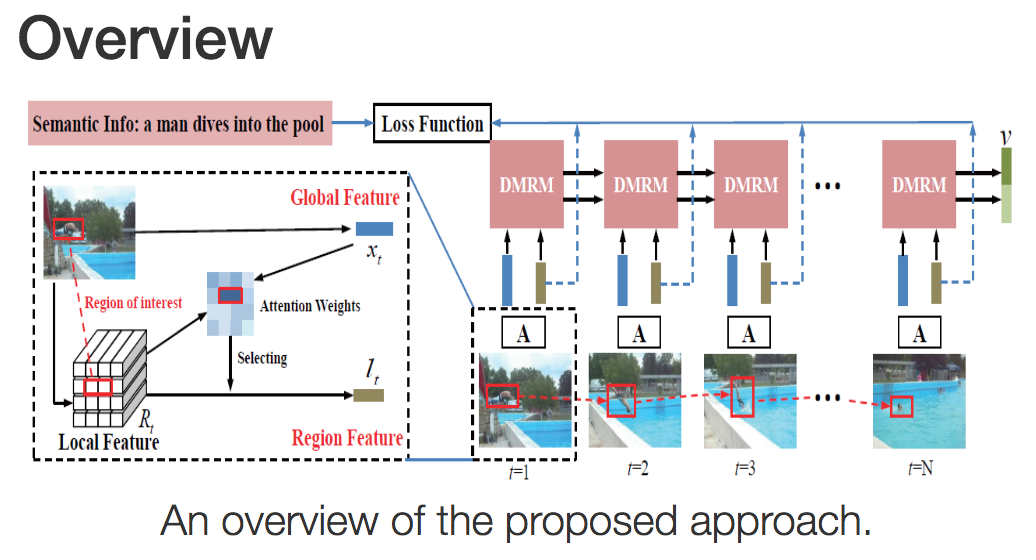
評価にはMicrosoft Video Description Corpus (MSVD)やMotreal Video Annotation (M-VAD)を採用。動画キャプショニングにおける評価法、BLEU-4, CIDEr, METEORにてState-of-the-artな精度を得た。
時系列の理由付け、(物体や人物行動などの)関連性を学習するTemporal Relation Network (TRN)を提案する。TRNはフレーム数を変えながら特徴表現を行い、前後の時系列を対応づけることで理由付けを行う。このネットワークを学習して時系列の対応付けを行うため、3つの動画データベースーSomething-Something(ビデオ数108,499), Jester(148,092), Charades(9,848)ーを用いた。
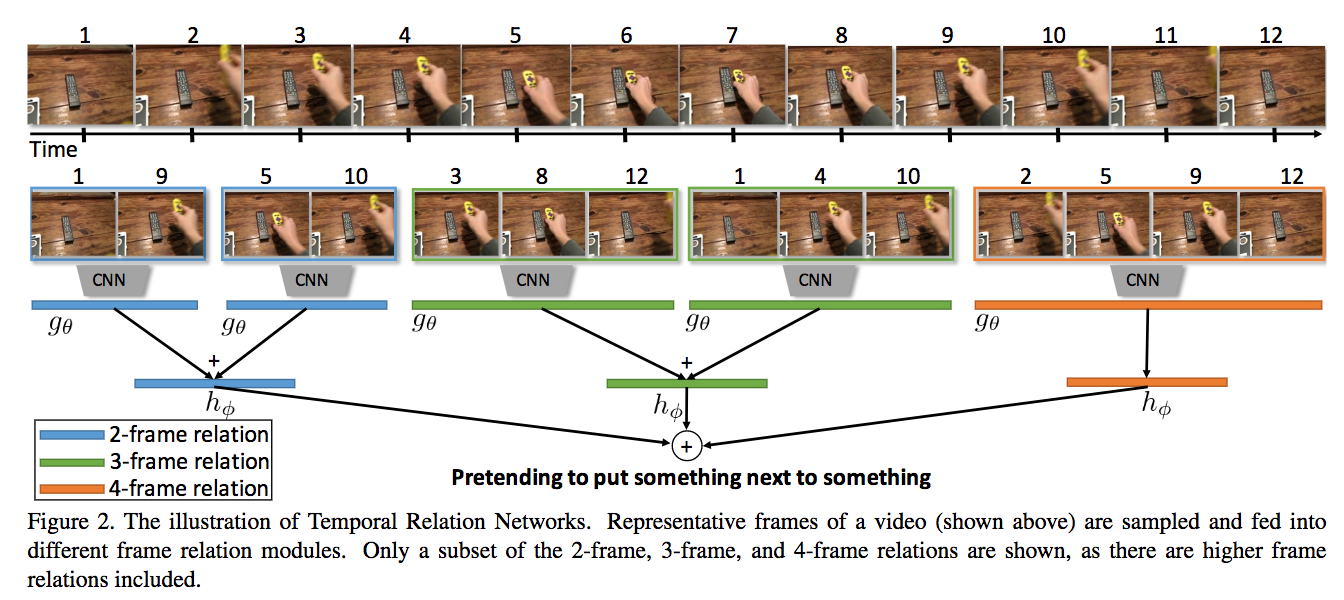
TRNは場面によりC3DやTwo-Stream ConvNetsよりも高精度。ビジュアルの結果は動画を参照。
一人称視点の画像からゴールリングに到達するまでのバスケットボール選手の動線を生成する。本論文では3D位置や頭部方向も記録する。同タスクを実行するため、まずは画像空間から12Dのカメラ空間に投影を行うEgoCam CNNを学習。次に予測を行うCNN(Future CNN)を構築、さらに予測位置やゴールまでの位置が正確かどうかを検証するGoal Verifier CNNを用いることでより正確な推定を行うことができる。
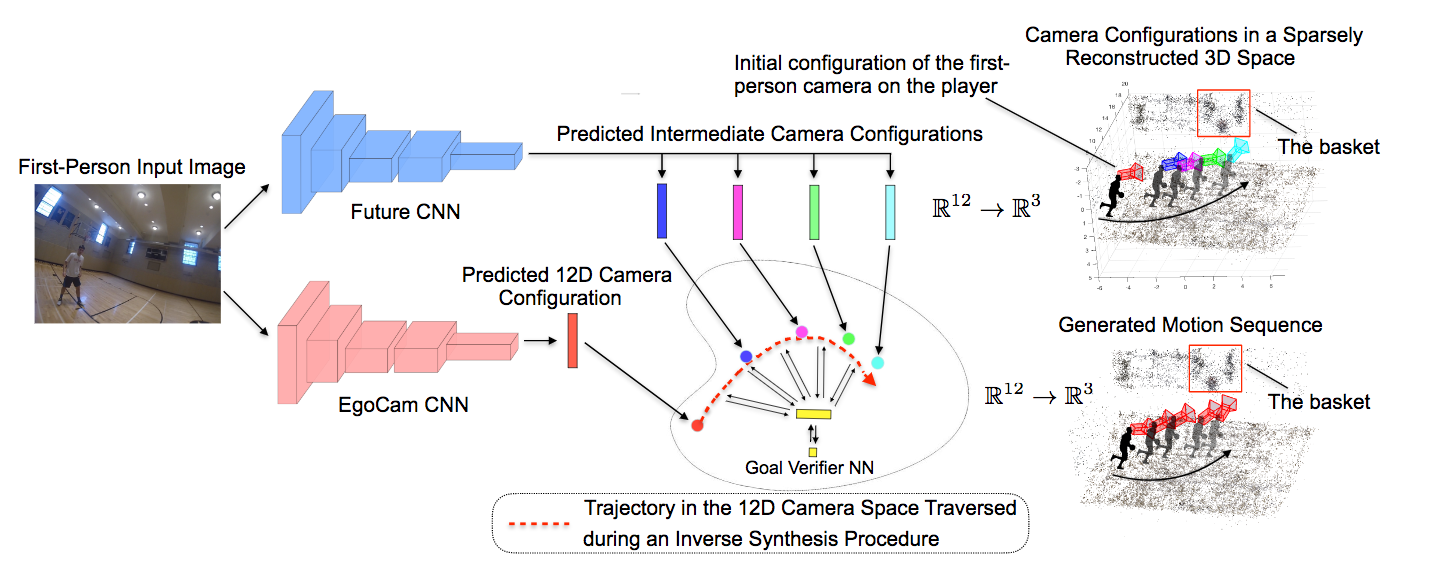
複数のネットワークの出力(ここではEgoCamCNNとFutureCNN)を検証するVerification Networkという考え方は面白い。他のネットワークの出力を、検証用のネットワークにより正すというのはあらゆる場面で用いることができる。RNN/LSTM/GANsなどよりも高度な推定ができることが判明した。
Finding Tiny Facesを元ネタにして、画像中から微小な顔を検出する手法を提案。元ネタではコンテキストから小さな顔を検出していたが、本論文では画像の類似性(顔は大小に関わらず特徴が類似する)を考慮して極小な顔を検出した。手法としては、画像中から意味的に類似する領域を計算するためのMetric Learning(特徴空間の距離学習)を用いる。
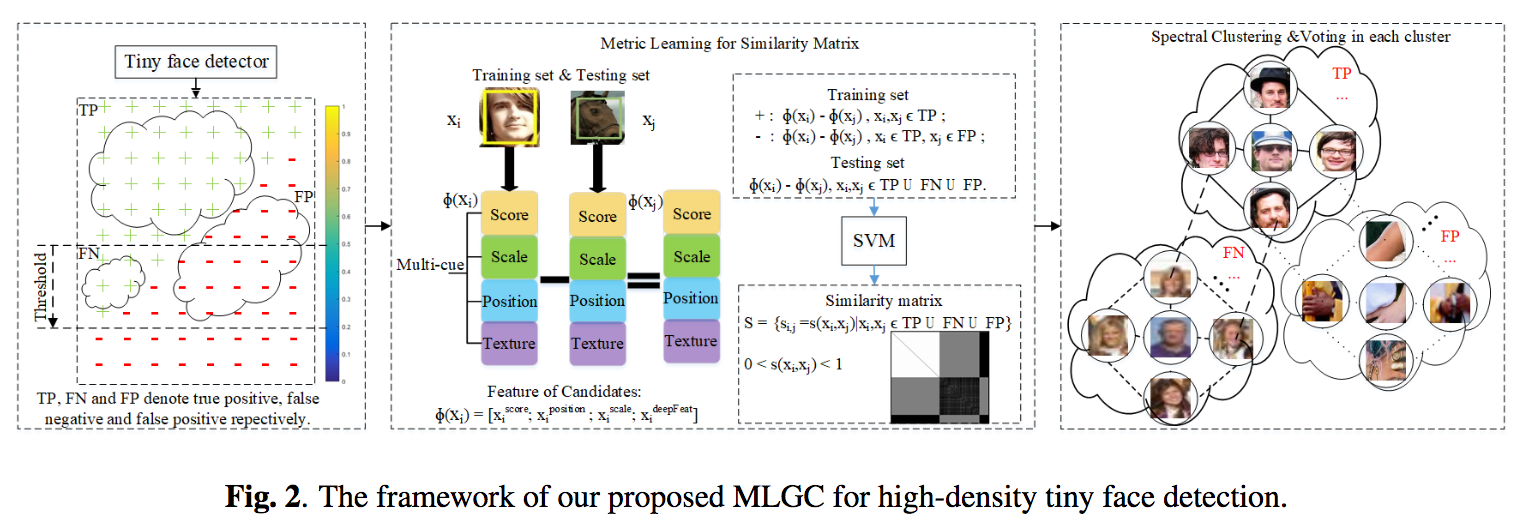
3つの著名な公開データに対して精度を向上させState-of-the-art(と主張しているが、結果のグラフが18/03/07現在論文に埋め込まれていない)。
ピクセル同士の画像対応を行い、画像変換を実行するBicycle GANを提案。従来のImage-to-Image (pix2pix)ではone-to-oneマッピングだったが、本提案ではマルチモーダル、すなわちある画像からあらゆるピクセルの対応関係を考慮した変換をおこなう(例として、図に示すような夜画像の入力からあらゆる日中の画像に変換するなど)。このアルゴリズムを構築するためにVAEベースやLatent RegressorのGANを組み合わせる。

pix2pixと比較して複数の結果を出力する表現力が向上した。マルチモーダルで出力しても結果画像が崩れることなく画像生成を実現した。

AAAIに採択された、行動認識の研究。(1)より精緻な特徴量抽出、(2)異なるチャンネルの入力からの非同時性(asynchrony)を考慮して公開データベースに対する認識精度を向上させた。Coarse-, Middle-, Fine-levelの特徴量を統合して識別を実行する、さらにはそれぞれ異なる時間とチャンネル(e.g. rgb at time t & flow at time t+2)からの特徴組み合わせにより参照する尺度を変更し、特徴量をさらに強化した。
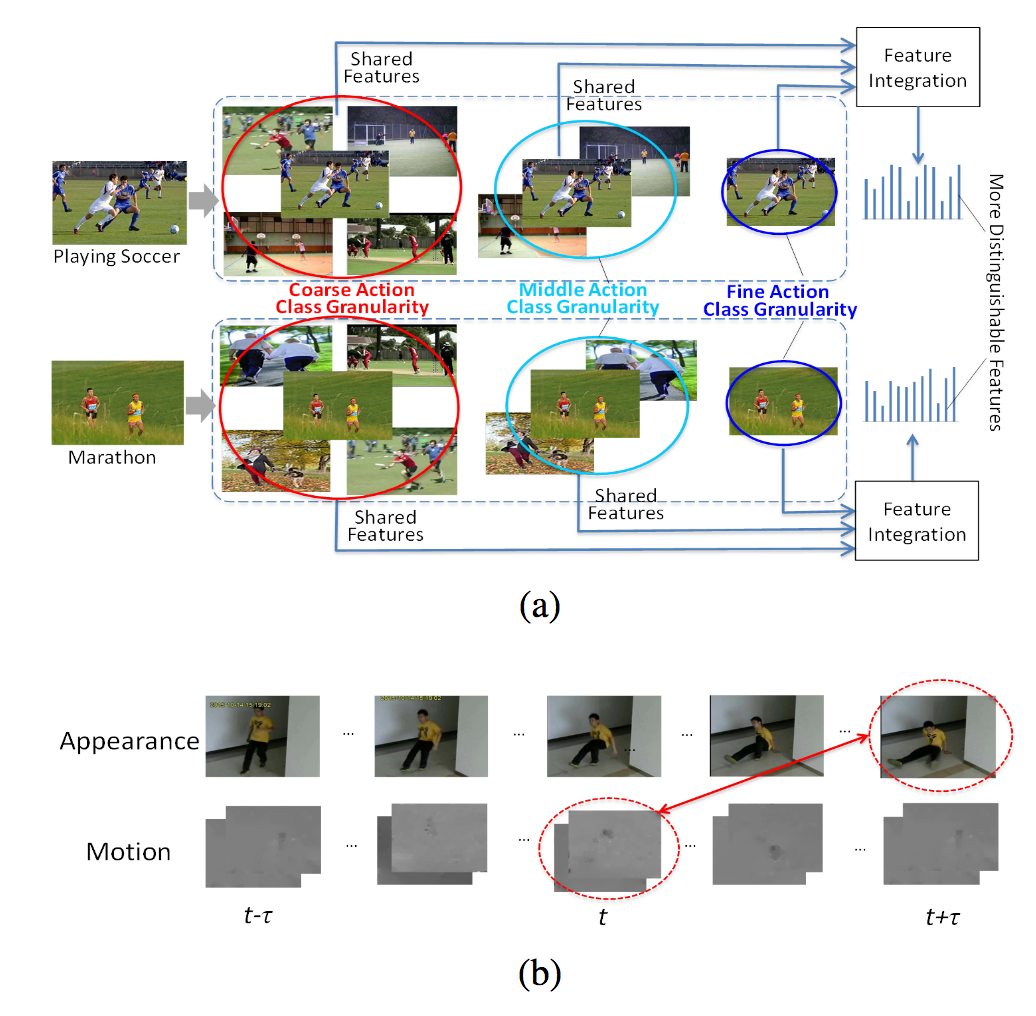
多階層の特徴量の組み合わせや非同時性を考慮した特徴抽出により手法を構成、UCF101にて95.2%、HMDB51にて72.6%を達成した。
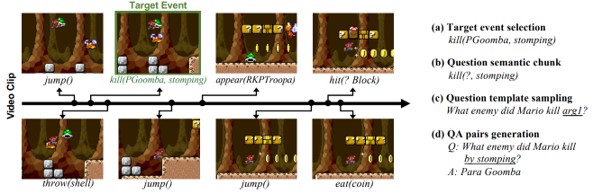
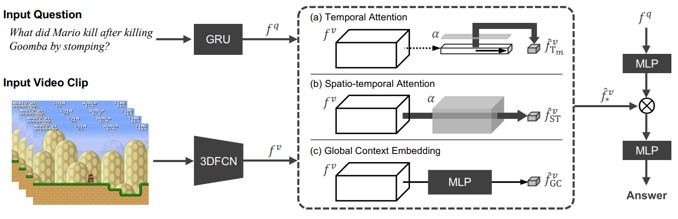
動画によるVideoQA。マリオのプレイ動画から、発生するイベントの質疑応答を行うMarioQAを提案。イベントログを含むビデオクリップを収集し、抽出されたイベントから自動的にQAペアを生成してデータセットを構築。敵を倒す、死ぬ、ジャンプ、キック、持つなどの11個のアクションパラメータを、動画と対応させたコマンド形式で時系列にまとめたものを学習。
3秒以内のラベル付けされた動画像が100万以上含まれるデータセットMoments in Time Datasetを提案。今まで動画DBでありがちであった人物のみに偏ることなく、物体や動物、自然現象なども積極的に含んでいる。

3秒以内の瞬間的な動画にすることでノイズを含まない動画になりやすく、クラス間/クラス内のDIVERSITYを考慮、人物のみに限定せず動画像を汎用的に収集、動き自体の転移を考慮してカテゴリを定義している。
自然言語のナビゲーションを入力として、実空間の中をロボットが動き目的地に到達できるかどうかを競うベンチマーク(Visually-grounded natural language navigation in real buildings)を提案。データセットは3Dのシミュレータによりキャプチャされ、22Kのナビゲーション、文章の平均単語数は29で構成される。

(1) Matterport3Dデータセットを強化学習を行えるように拡張。(2) 同タスクが行えるようなベンチマークであるRoom-to-Room (R2R)を提案して言語と視覚情報から実空間にてナビができるようにした。(3) seq-to-seqをベースとしたニューラルネットによりベンチマークを構築。VQAをベースにしていて、ナビゲーション(VQAでいう質問文)と移動アクション(VQAでいう回答)という組み合わせで同問題を解決する。
自然言語の問題はキャプションや質問回答の枠を超えて実空間、さらにいうとロボットタスクに導入されつつある。この研究はビジョン側からのアプローチだが、ロボット側のアプローチが現在どこまでできているか気になる。すでに屋内環境をある程度自由に移動するロボットが実現しているとこの実現可能性が高くなる。SLAMとの組み合わせももう実行できるレベルにある?
「2D画像」と「物体位置」の入力から「3D物体姿勢」と「カテゴリラベル」を出力する研究。ResNetベースのアーキテクチャを採用している。物体カテゴリが既知/未知の場合の両方で3次元物体姿勢の推定ができる。物体の回転とカテゴリ推定の同時誤差を計算する関数も定義。
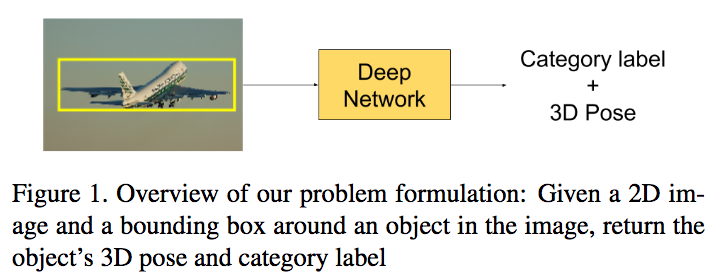
3次元物体姿勢推定とカテゴリ推定の同時回帰問題において、Pascal3D+ datasetでState-of-the-artな精度。物体カテゴリが未知の場合でもカテゴリを推定しながら3次元姿勢推定を実行することができる。
Adversarial Examples(ネットワークを騙す摂動ノイズ)に関する研究だが、特に物体識別や質問対応(Visual Question Answering)への問題を扱う。さらに、従来の問題では2D画像を取り扱っていたが、本論文では3Dレンダリングとその2D平面投影画像に拡張する。ひとつの摂動ノイズは誤差逆伝播のエラーを直接出力の2D空間に投影すること、もうひとつは敵対的ノイズを予め2D画像に構築して物理空間からレンダリングすることである。
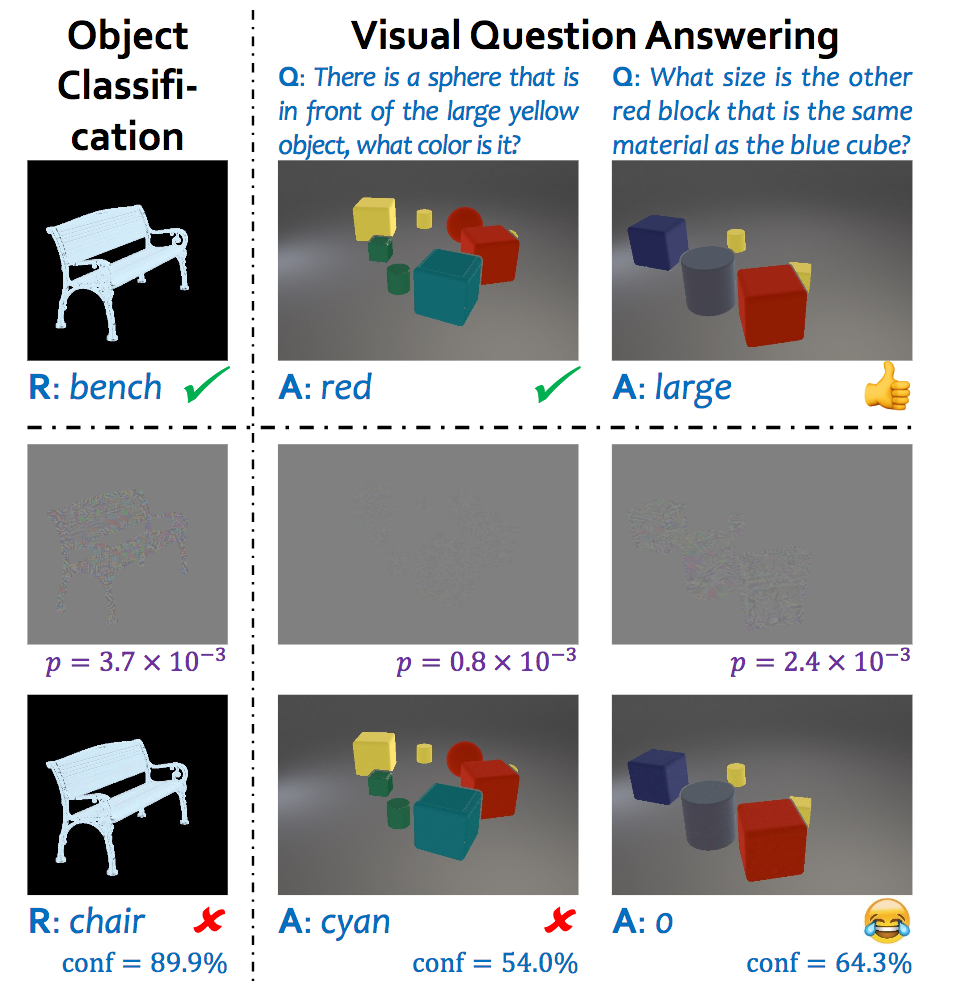
ここでは(1)3次元的な物理的空間を想定して摂動ノイズを加えることができるかどうかについて言及、(2)ノイズを含んだ攻撃画像が与えられた際に、それら攻撃から守るような適切な物理空間を構成できるかどうかを検討した。3次元的な物理空間の攻撃は、法線方向・光源・材質などを考慮しつつ出力に対して防衛可能であるため、2次元の画像空間よりも攻撃が難しいと主張。
画像空間を超えてボリュームデータに対する摂動ノイズが議論され始めた。どんな空間でも埋め込める攻撃や、それらから防衛可能な手法を汎用的に考えてみたい。また、セキュリティ分野の知見はCVにもっと導入されるべき?

マルチエージェント間の対話による言語学習を提案。SenderエージェントとReceiverエージェント間で簡単な画像当てゲームを実施。ゲームの正解のためにより良質なコミュニケーションが必要となり、言語を学習していく。また、ゲーム環境を変化させることで、単語の意味と画像がより良く対応するようになる。
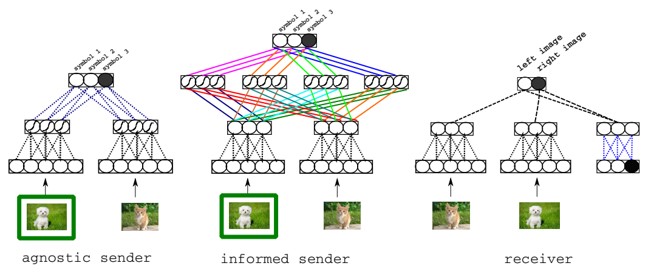
Senderエージェントは、2枚の画像のうち1枚がtargetであると伝えられる。そして、これを伝えるためにReceiverエージェントにsymbol(メッセージ)を送信する。Receiverエージェントは、受信したsymbolの情報のみから、どちらの画像がtargetであるかを当てる。
SenderとReceiverに見せる画像を変える実験や、人がゲームを実施する実験を行った。
人間と生産的にコミュニケーションできるAIの開発に貢献できる。言語の習得には、大量のデータだけでなく、他者との対話が重要。また、Senderが出力したsymbol(Image Netのラベルに対応したもの)を人間に見せると68%の正解率となった。
大規模でマルチモーダルの映画ストーリー理解のためのMovieQA を解く。新しいメモリネットワークモデルのRWMN(ReadWrite Memory Network)を提案。一連のフレームを段階的に抽象化して、より高レベルの順次情報を取得し、それをメモリスロットに格納していく。CNNを多用し、読み取りネットワークと書き込みネットワークを設計。これにより、メモリの読み書き操作に高い容量と柔軟性を持たせることができる。
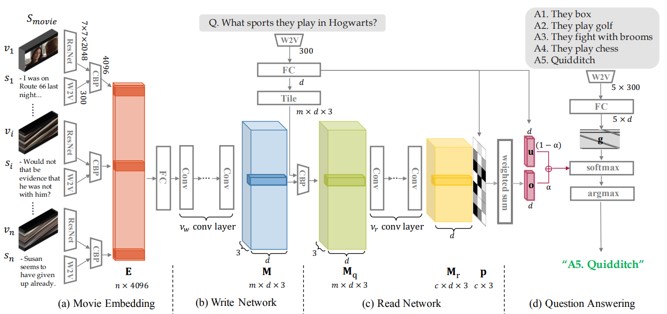
Embedding:ResNetとWord2Vecを用いて映画の埋め込みを行う。
Write: CNNを書き込みネットワークとして利用し、メモリテンソルを出力。
Read: CNNを使用して、一連のシーン全体をつなぎ合わせて関連付けるために、シーケンシャルメモリスロットにチャンクごとにアクセス。構成されたメモリMrを得る。
QA: 5つの候補中から最も信頼度のが高い回答を選ぶ。
ビデオのキャプションを生成するためのend-to-endかつ、sequence-to-sequenceモデルの提案。本手法のS2VTによって、一連のフレームを一連の単語に直接マッピングし、学習することができる。入力フレームの可変数の扱い、ビデオの時間構造を学習、自然な文法文の生成、この3点が本研究のコントリビューション。
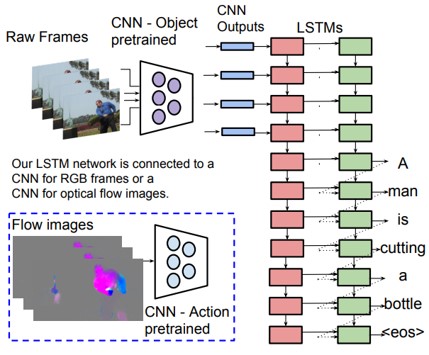
各フレームのCNNの出力と、連続したLSTMに入力する。また、ビデオの時間構造をモデル化するためにオプティカルフローを算出し、フロー画像もCNNを介してLSTMに入力する。全てのフレームを読み込んだ後に、単語単位で文章を生成する。
使用データセット:MSVD, M-VAD, MPII Movie Description
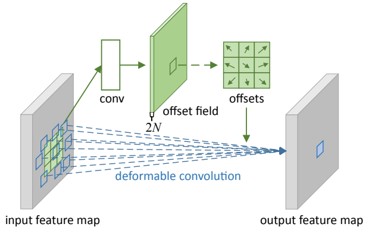
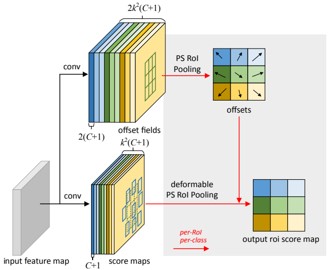
CNNの表現力の向上を図る。CNNによる物体検出などでは、矩形を用いるために検出対象の物体だけでなく、余計な背景も含んでしまい精度低下につながる。可変可能な畳み込みとRoIプーリングを提案。これにより、画像の畳み込みを行う際に、重みに加えてセルの位置も学習する。特に、物体検出やセマンティックセグメンテーションなどのタスクに効果的。
画像キャプショニングの中でも、画像上にはない形容詞で表現された“感情”についてのキャプションに焦点を当てる。センチメントタームを用いた画像キャプションモデルを提案。これにより、センチメントの主観的性質に対応するマルチラベル学習を実現。FlickrとDeviantArtから、2.5Mの画像と28Mのコメントを収集し,感情に対するデータセットを構築。“コメント”はキャプションとは性質が異なるが、感情を表現するために適している(否定や不適切を除く)。
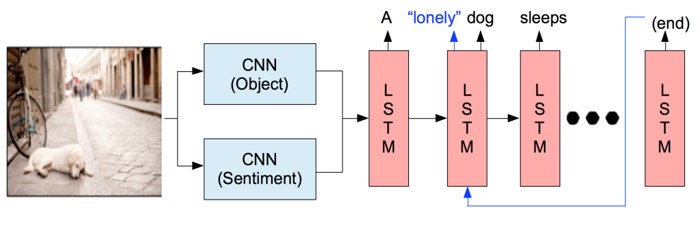
CNN→LSTMという一般的な画像キャプションの流れに、センチメント分析を行うCNNを追加する。SentiWordNetの正または負のスコアが0.5以上の単語を感情単語とする。
SentiWordNet:意見聴衆のための語彙リソース。正、負、客観性の3つの感情スコアを算出。
キャプションが適切出るかどうかと、キャプションのランク付けの2つの人間による評価。モデルからのキャプションがイメージの感情に関してより適切であるという結果となった。
「画像内のprimitiveを認識できることは高次の特徴を掴んでいる」という考えを基にした、self-supervisedな特徴表現学習手法。 画像のオリジナルとそれらを各タイルに分割したものを同じNNに入力し、出力されるタイルのprimitive数の和とオリジナルのprimitive数が一致するように学習する。 しかしそれでは出力を単に小さくするように学習することで損失を0にできてしまうので異なる画像も含めたcontrastiveな損失を用いる。
画像識別、物体検出、意味領域分割などのタスクで評価を行っており、識別ではSoTA。 学習したNNからの出力を確認すると、ノルムが大きいものは高次な物体が含まれる画像、小さいものは低次なテクスチャしか含まない画像が得られた。 これからNNが高次なprimitiveをcountしていることが考察できる。


アルバムのような時系列画像でキャプション生成を行うためのデータセット。ストーリ性のある画像キャプションデータセット:SINDを構築。10,117個のFlickrアルバム、210,819枚の写真。各アルバムは平均20.8枚。
descriptions for images in isolation (DII):画像一枚の記述
descriptions of images in sequence (DIS):連続画像
stories for images in sequence (SIS):ストーリー


理由に基づいたVQA。既存の手法では,入力を出力に直接マッピングしているため,視覚的推論の学習というよりも,データの偏りを学習しているといえる。そこで,理由を伴った視覚的推論モデルを提案。モデルは、プログラムジェネレータと実行エンジンの2部構成。CLEVRベンチマークを使用し評価。回答の柔軟性、拡張性の向上。
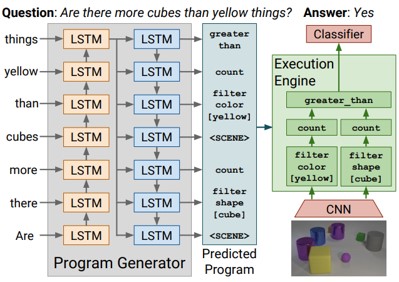
プログラムジェネレータは、質問の読み取り、単語の羅列として表現される質問から質問に答えるためのプログラムを生成する。基本的にはLSTMのsequence-to-sequenceの考え方。
実行エンジンは、予測されたプログラムをミラーリングするニューラルモジュールネットワークを構成し、実行することで画像から回答を生成。

教師モデルと生徒モデルを分けていた従来の蒸留に対してモデル同士の相互学習を提案。ハードラベルによる交差エントロピーと対象モデル以外のモデルの出力とのKL距離を最小化するように学習する。様々なモデル同士の相互学習実験や通常の蒸留との比較、相互学習を行った場合の解がより高い汎化性能を保有していることの検証実験も行っている。
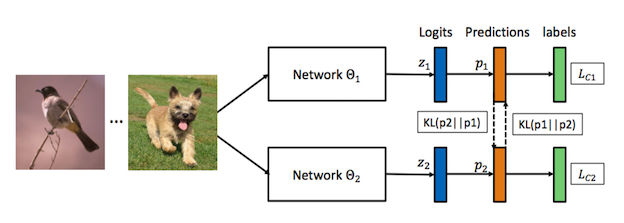
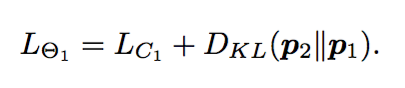
画像識別において通常の蒸留を行うよりも精度が良くなった。生徒モデルの中で相対的に小規模なモデルのみならず大規模なモデルも独立で学習を行うより精度が良かった。さらに相互学習を行うことで、wider minimaに収束しているという実験結果も得られた。特に出力される事後確率のエントロピーが大きくなるように学習されることがwider minimaへの収束を促していることがいわれている。
動き特徴を利用した前景(物体)領域情報は汎用的な表現学習に役立つという考えから、NLCなどのhand-craftな手法を組み合わせて擬似的な動体領域を作成し、それを教師として領域分割をCNNに解かせることで表現特徴を得る。物体検出、物体・行動認識、意味領域分割の問題設定において評価を行った。表現学習のデータとしてYFCCを用いている。

Pascal VOCの物体検出において教師なし表現学習でSoTA。特にfine-tuningに利用するデータが少量の場合と多くの層のパラメータを固定してfine-tuinigした場合で大きな効果を発揮した。しかし、物体・行動認識、意味領域分割においては従来手法より劣っている。
実験は丁寧に行われてる印象。表現学習の設定自体が物体検出を意識しているようにも感じられ(単一物体が写っている画像を優先的に取り出している?など)、物体検出でうまくいくのは当たり前な気もした。
しかし、意味領域分割で精度が出ない原因がよくわからなかった(物体部分はできているが背景の分割ができていない?)。1-stage物体検出手法の精度向上を図る。 YOLOやSSDなどは,矩形領域における前景と背景の面積が不均衡であるため,2-stage物体検出手法に勝てないと推測。この問題を解決するためにクロスエントロピーを再構築したFocal Lossを提案。学習時のネガティブサンプルの影響を減らすことができる。
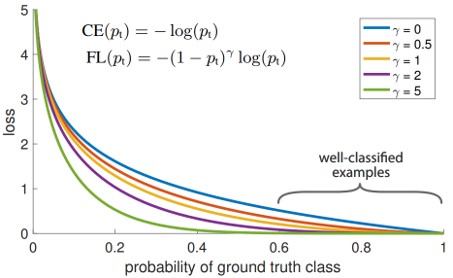
Focal Loss
クロスエントロピーに重みを追加
→正解になりやすい背景に引っ張られなくなる
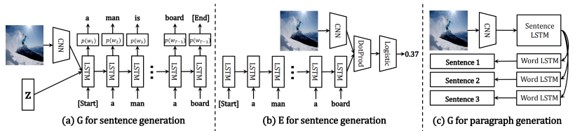
画像キャプショニングの性能向上を図る。従来のロバスト性が低いRNNに代わって,GANのフレームワークを採用することで,自然性と多様性を向上。図より,ジェネレータ(G)が文を生成し,ディスクリミネータ(E)が文や段落がどれだけうまく記述されているかを評価する。GとEを同時に学習させることにより,自然な文章を生成。
ラベルが完全に手に入らない際にでも転移学習が可能なセグメンテーション手法(論文中ではPartially Supervised Training Paradigm, weight transfer functionを紹介)を提案する。条件として、bboxが手に入っている物体に対してセグメンテーション領域を学習可能。Mask R-CNNをベースとしているが、Weight Transfer Functionを追加、セグメントの重みを学習・推定して誤差計算と学習繰り返し。

Visual Genome Datasetから3,000の視覚的概念を獲得、MSCOCOから80のマスクアノテーションを獲得した。
弱教師付き学習が現実的な精度で動作するようになってきた?アノテーションはお金や知識があっても非常に大変なタスクであり、いかに減らすかという方向に研究が進められている。(What's next?ー弱教師/教師なしの先とは?)
ワンショットで人間の教示を模倣するロボットのための学習「One-shot Imitation Learning」を提案。人間が物体を把持するなど動作を教示するとロボットが特徴や動作を学習してタスクをこなす様子を学習。Model-Agnostic Meta-Learning(MAML; ICML2017)を応用したモデルを提案し、(VR空間、人間のデモによる)教示から動作を学習する。アーキテクチャはCNNをベースとしてRGB入力から特徴を抽出、中間層(全結合層直前)からロボットの動作やバイアス項を入力してロボットの行動(pre-/post-update)を出力する。

ロボットの把持タスクをシミュレーション/実空間にておこなった。シミュレーションでは提案法のMILが1ショットで85.81%、5ショットで88.75%(従来法LSTMでは各78.38%, 83.11%)。実空間では90%を実現(従来法LSTM/contextualでは25%)。詳細にはプロジェクトページやプレゼンのビデオを参照。
CVにおけるデータセットでは,写真に対するラベル付けが一般的。写真だけでなく,イラストや風景画などに対して,以下の3属性のラベルを付加。

Behance Artistic Media Dataset
物体検出とアフォーダンス(というよりは機能?)のセグメントを同時に回帰するネットワーク、AffordanceNetに関する論文。ロボットへの把持位置/機能教示を行うことができる。基本的なモデルはMask R-CNNを適用していて、物体検出のためのbboxと物体に対する機能セグメントを正解として学習する。多タスクの誤差関数は物体カテゴリ、座標、機能セグメントの3つに関するものである。

従来、物体検知と機能推定は別個に学習・認識されていたが、本研究では多タスク学習の枠組みで、単一モデルにてEnd-to-End学習した。IIT-AFF Datasetにて73.35(SoTAは69.62)、UMD Datasetにて79.9(SoTAは77.0)。モデルも公開されており、誰もがAffordanceNetを実装できるようにしている。
画像識別における知識蒸留(Knowledge Distillation)の内容である。本論文ではある概念(e.g. 動物認識、人工物認識)ごとに教師となる識別器を事前学習しておき、それらの知識を単一の識別器に学習(これをKnowledge Concentrationと呼称)する。いわば複数の先生がある生徒に教えるという流れで学習する。
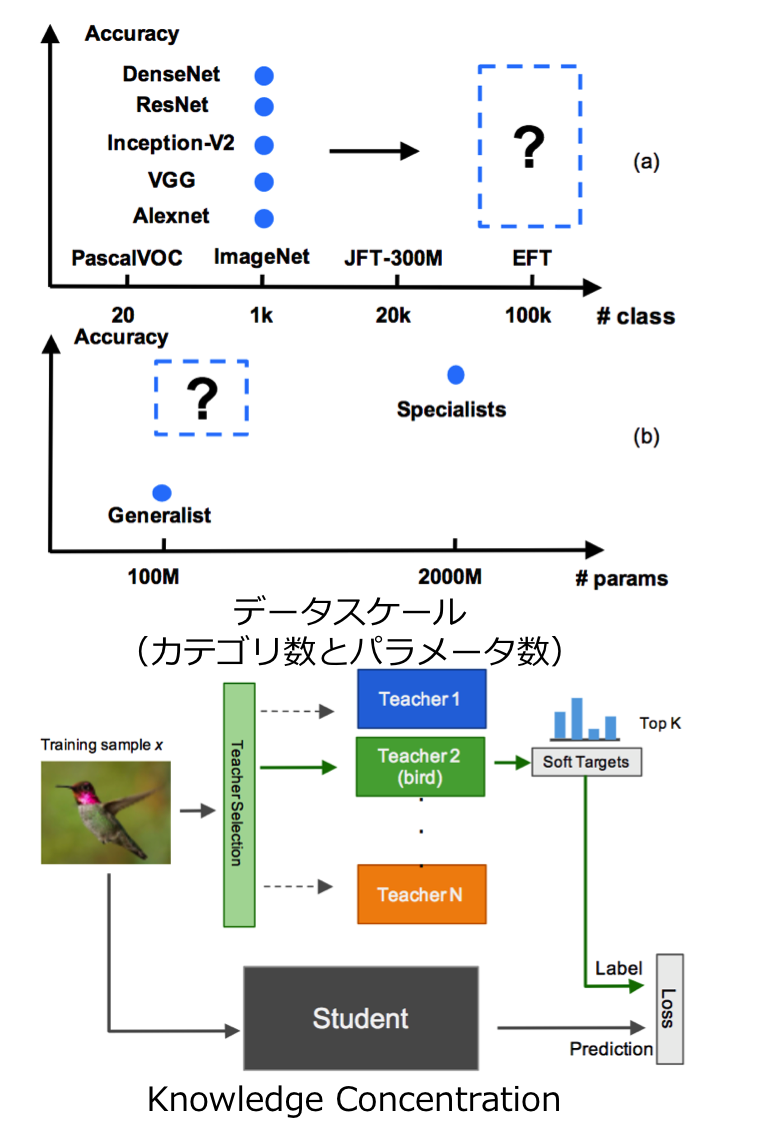
よくも悪くも、現状のCVはImageNetの1,000カテゴリに頼っているが、これを100倍の100,000カテゴリに増やして学習したらどうか?また、いかにしたら効率よく学習ができるかを検討した。結果はSingle Model(従来のようなCNNによるカテゴリ識別学習)にするよりも複数のスペシャリスト識別器から知識蒸留を行う方が効率よく、精度よく学習ができた。本論文で使用したEFT(Entity-Foto-Tree)データセットはカテゴリ数でImageNetの100倍、JFT-300Mの5倍である。
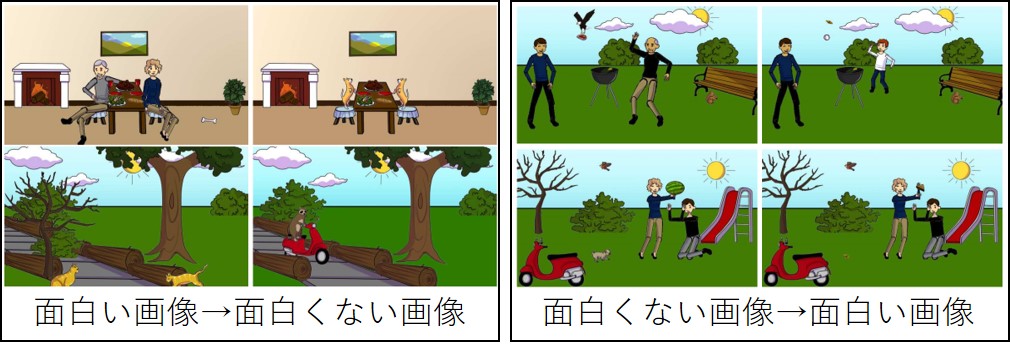
面白さ推定
面白い画像・面白くない画像の変換
結果:特に人や動物などのオブジェクトが面白さに影響
オーバーラップが少ない複数視点カメラから自動車の3次元姿勢や形状を復元する研究。CNNにより自動車のキーポイントや姿勢/3次元形状を出力する。これら情報をヒントに、カメラ視点を推定する。2D画像上でのキーポイント推定にはconv-de-convを4回繰り返すhourglassアーキテクチャを採用、3次元姿勢や形状の推定にはCross Projection Optimization (CPO)を採用し2D-3Dの投影誤差を最小化した。
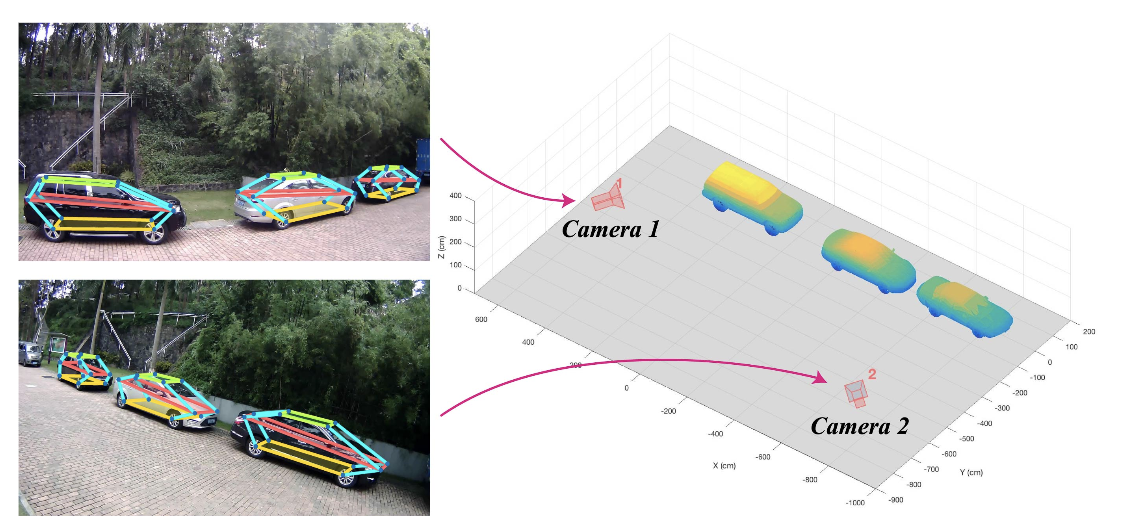
物体のキーポイント検出においてState-of-the-art。6DoF推定手法 (Pavlakos, ICRA17)では12キーポイントの平均誤差が37.88であったが、提案手法では10.48まで低減した。また、回転/並進誤差も3DVP (Xiang+, CVPR15)では11.18/N/Aであったが、2.87/4.73まで向上させた。
End-to-Endでイベント検出(行動の時系列セグメント化)とキャプショニングを実行するタスクを提供する。モデルには3D Convolutionや階層的LSTM(two-level hierarchical LSTM)を採用した。基本的にはDense Captioning Events in Videosをベースにして研究を行なっているが、{Controller, Captioner} LSTMの二段階により前の候補のセンテンスやビデオコンテキストを考慮しつつ状態を更新(Controller LSTM)し、候補領域の特徴を参照しつつキャプションを生成(Captioner LSTM)する。時系列候補領域とキャプションはmulti-task学習、End-to-Endで学習される。
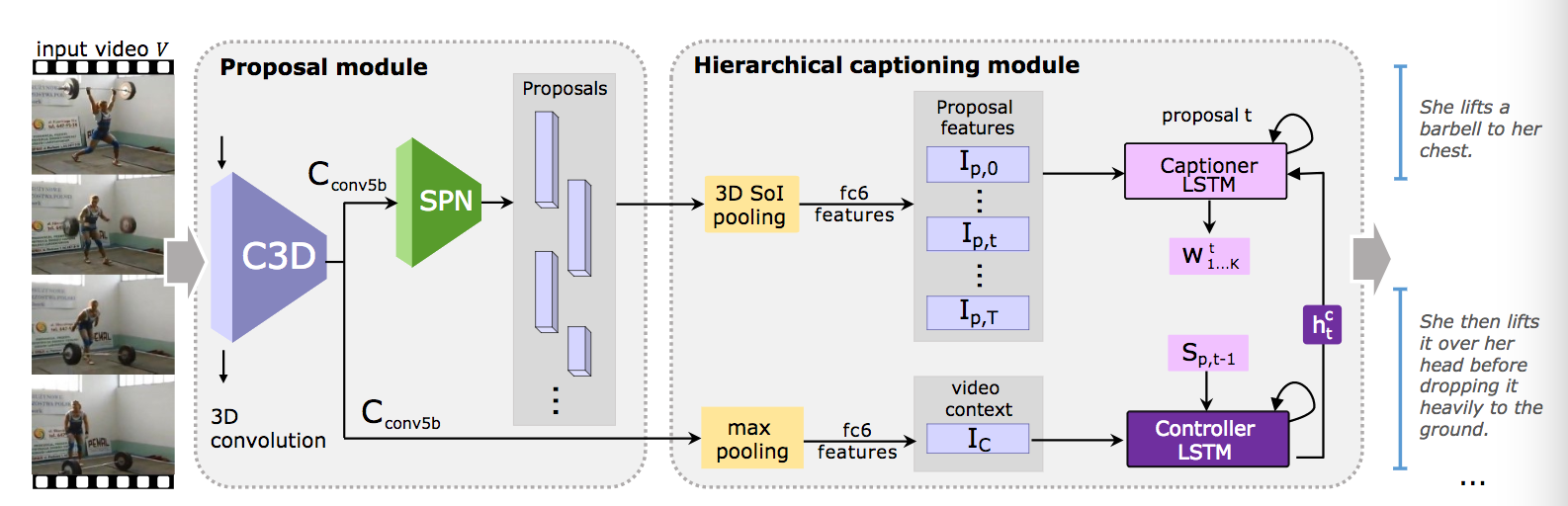
候補領域生成やキャプショニングの精度を検証した。また、データセットにはActivityNet CaptionsやTACoS Datasetを用いた。候補領域については従来法のDAPが30, multi-scale DAPが38 @AUC (IoU>0.8)に対して提案法であるJEDDi-Netは58.21を記録した。また、キャプショニングについては従来法が{17.95, 4.82, 17.29} (各BLEU1, METEOR, CIDEr)の問題に対して{19.97, 8.58, 19.88}を記録した。
動画のタスクはカテゴリのみでなく言語やより表現力豊かな認識ができなければいけない時期になって来た?時系列表現にもまだまだ課題が多いので、これからさらに動画認識にチャレンジすべき。また、キャプショニングの問題は感性評価に対する知見や確固たる評価方法が確立されるとさらに面白くなるのではないか。
AIが写真の感性評価やコメント生成を行なってくれる。写真とそのコメントが対応づけられた大規模DBであるAVA-Reviews dataset(52,118画像、312,708コメント)を学習することで写真を入力して図の(1)Predictionや(2)Commentsのようなものが得られる。モデルはCNNにより感性評価(Low-/High-Aesthetic category)を、CNN+LSTM(RNN)によりコメント(e.g. Fastastic colors)を出力する。

(i) 人間のような画像に対する感性評価(image aesthetics)をコンピュータに実装した。(ii)自然言語の出力により人間の高次な認知能力を実現。(iii) 画像-言語の組み合わせによるデータセットAVA-Reviews datasetを新規に構築した。
深層学習の解釈性に関する論文であり、畳み込み層の特徴マップの応答を外的に解析して対応する反応を可視化。畳み込みの各フィルタが異なる部位(e.g. 馬の耳や目)に反応するので、グラフにより解析して元画像の対象位置にアクセス。
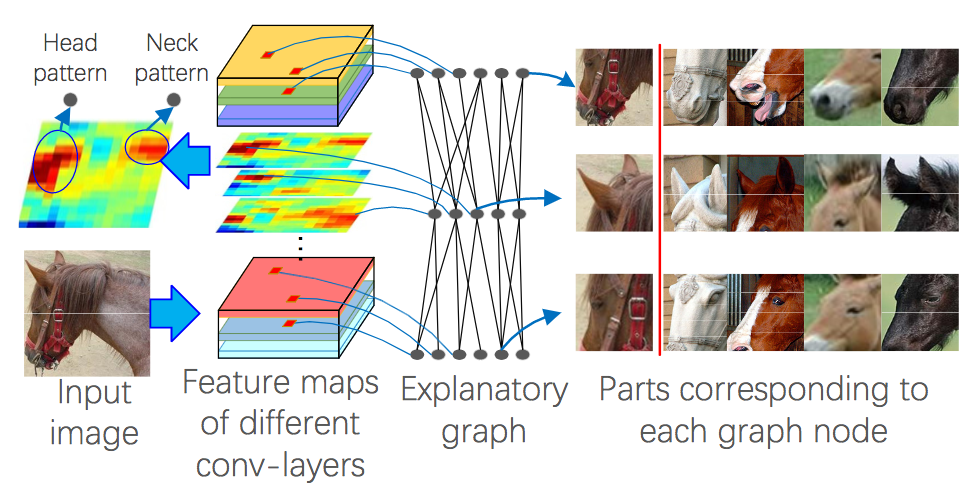
Ground-truthなしに各部位に関する解釈性を与えたことが新規性である。図に示すように入力画像に対するパーツごとの解析をフィルタの反応やグラフの解析から可視化することができる。 さらに、異なる画像間においても一貫性のある反応を得ることができた。
深層学習は教師なしによる解釈性を獲得しているが、まだ反応している部分の可視化や部分ごとの解析が進んでいるにすぎない。さらなる発展のためには、言語的な解釈や人間にわかりやすい加工(イラストとか?)が必要になるのではないだろうか。
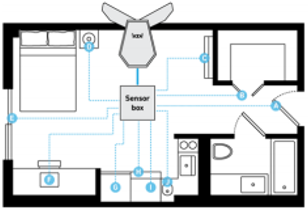
スマホカメラを使って非侵襲なヘモグロビン濃度の測定を実現.血中の酸素飽和度の測定などはこれまでにもあったがヘモグロビン濃度まで測定できているものはなかった. 照明条件とRGBの変化からヘモグロビン濃度を推定するためのアルゴリズムを提案.
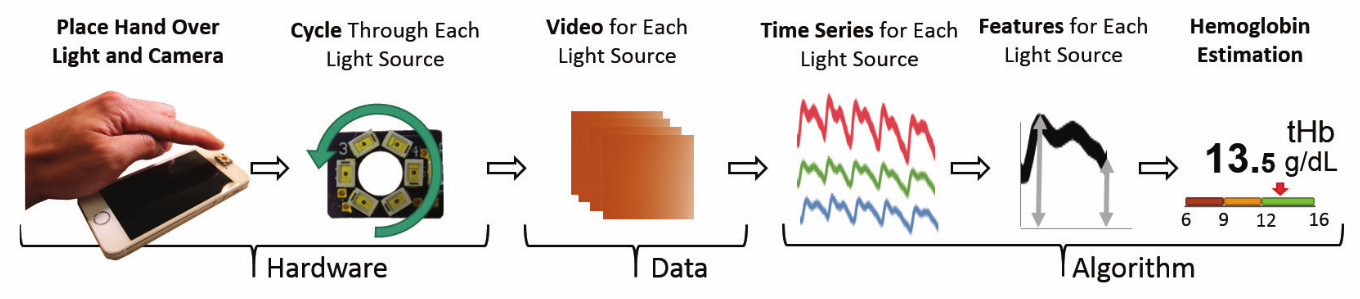
特別な装置を使うことなく簡単にスマホカメラでヘモグロビン濃度測定を実現した点.
システムやユーザスタディの完成度や完全に実現できたときの有用性が評価された?

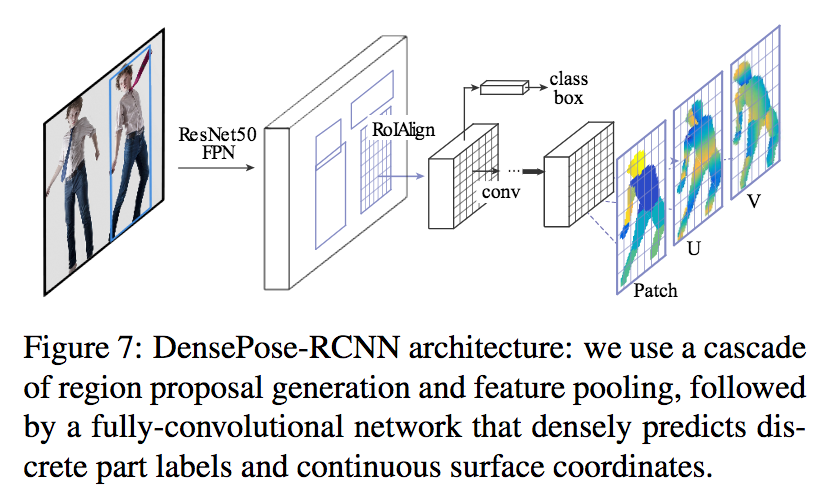

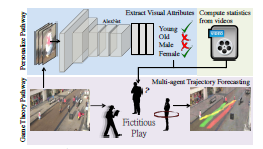

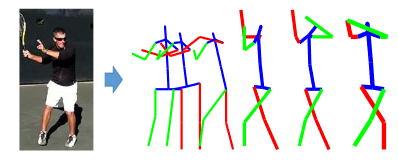
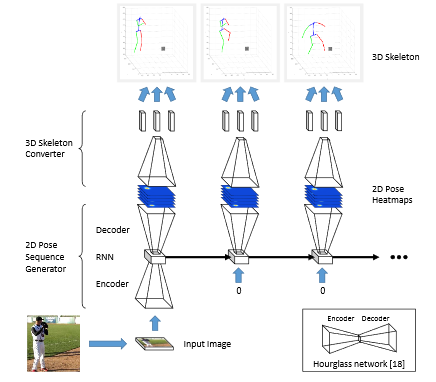
2つのCNNを用いた高速かつ頑強な物体追跡手法を提案. 1つ目のCNN(MagicPoint)で入力画像から特徴点を抽出し, 2つ目のCNN(MagicWarp)で抽出された特徴点の位置情報のみから2つの画像間のホモグラフィー行列の推定を行う.
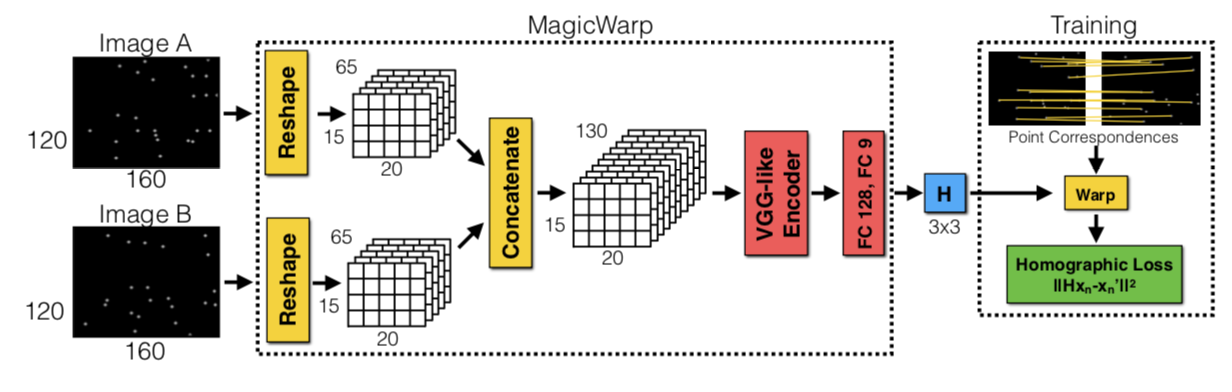
MagicPointは幾何学的に安定した点(物体の角や辺など)のみを抽出するため, ノイズに頑強である. また, MagicWarpを用いることで従来手法のように特徴量の記述子(descriptor) を計算する必要がなくなるため, 高速な動作が可能となった. 作成した単純形状のデータセット(Synthetic Shapes Dataset)では FAST, Haris, Shi よりも高精度.